【数据挖掘】如何保证数据一致性?

一、说明
为了确保数据一切正常,我们需要关注两件事:
- 没有丢失或重复的事件 - >事件和会话数在预期范围内。
- 数据是正确的 - >每个参数的值分布保持不变,另一个版本尚未开始将所有浏览器记录为 Safari 或完全停止跟踪购买。
今天,我想告诉大家我处理这项复杂任务的经历。作为奖励,我将展示 ClickHouse 数组函数的示例。

摄影:Luke Chesser on Unsplash
二、什么是网络分析?
网络分析系统会记录有关网站上事件的大量信息,例如,客户使用的浏览器和操作系统,他们访问了哪些URL,他们在网站上花费了多少时间,甚至他们添加到购物车并购买了哪些产品。所有这些数据都可用于报告(了解有多少客户访问了该网站)或分析(了解痛点并改善客户体验)。您可以在维基百科上找到有关网络分析的更多详细信息。
我们将使用ClickHouse的匿名网络分析数据。描述如何加载它的指南可以在这里找到。
让我们看一下数据。 是会话的唯一标识符,而其他参数是此会话的特征。 看起来像数字变量,但它们是浏览器和操作系统的编码名称。存储这些值(如数字),然后在应用程序级别解码值要高效得多。这种优化非常重要,如果您正在处理大数据,可以为您节省 TB 级。VisitIDUserAgentOS
SELECTVisitID,StartDate,UTCStartTime,Duration,PageViews,StartURLDomain,IsMobile,UserAgent,OS
FROM datasets.visits_v1
FINAL
LIMIT 10┌─────────────VisitID─┬──StartDate─┬────────UTCStartTime─┬─Duration─┬─PageViews─┬─StartURLDomain─────────┬─IsMobile─┬─UserAgent─┬──OS─┐
│ 6949594573706600954 │ 2014-03-17 │ 2014-03-17 11:38:42 │ 0 │ 1 │ gruzomoy.sumtel.com.ua │ 0 │ 7 │ 2 │
│ 7763399689682887827 │ 2014-03-17 │ 2014-03-17 18:22:20 │ 24 │ 3 │ gruzomoy.sumtel.com.ua │ 0 │ 2 │ 2 │
│ 9153706821504089082 │ 2014-03-17 │ 2014-03-17 09:41:09 │ 415 │ 9 │ gruzomoy.sumtel.com.ua │ 0 │ 7 │ 35 │
│ 5747643029332244007 │ 2014-03-17 │ 2014-03-17 04:46:08 │ 19 │ 1 │ gruzomoy.sumtel.com.ua │ 0 │ 2 │ 238 │
│ 5868920473837897470 │ 2014-03-17 │ 2014-03-17 10:10:31 │ 11 │ 1 │ gruzomoy.sumtel.com.ua │ 0 │ 3 │ 35 │
│ 6587050697748196290 │ 2014-03-17 │ 2014-03-17 09:06:47 │ 18 │ 2 │ gruzomoy.sumtel.com.ua │ 0 │ 120 │ 35 │
│ 8872348705743297525 │ 2014-03-17 │ 2014-03-17 06:40:43 │ 190 │ 6 │ gruzomoy.sumtel.com.ua │ 0 │ 5 │ 238 │
│ 8890846394730359529 │ 2014-03-17 │ 2014-03-17 02:27:19 │ 0 │ 1 │ gruzomoy.sumtel.com.ua │ 0 │ 57 │ 35 │
│ 7429587367586011403 │ 2014-03-17 │ 2014-03-17 01:13:14 │ 0 │ 1 │ gruzomoy.sumtel.com.ua │ 1 │ 1 │ 12 │
│ 5195928066127503662 │ 2014-03-17 │ 2014-03-17 01:43:02 │ 1926 │ 3 │ gruzomoy.sumtel.com.ua │ 0 │ 2 │ 35 │
└─────────────────────┴────────────┴─────────────────────┴──────────┴───────────┴────────────────────────┴──────────┴───────────┴─────┘ 您可能会注意到我在表名后指定了修饰符。我这样做是为了确保数据完全合并,并且每个会话只得到一行。final
在ClickHouse引擎中经常使用,因为它允许使用而不是(文档中通常的更多详细信息)。使用这种方法,您可以在更新的情况下每个会话有几行,然后系统在后台将其合并。使用修饰符,我们强制了这个过程。CollapsingMergeTreeinsertsupdatesfinal
我们可以执行两个简单的查询来查看差异。
SELECTuniqExact(VisitID) AS unique_sessions,sum(Sign) AS number_sessions, -- number of sessions after collapsingcount() AS rows
FROM datasets.visits_v1┌─unique_sessions─┬─number_sessions─┬────rows─┐
│ 1676685 │ 1676581 │ 1680609 │
└─────────────────┴─────────────────┴─────────┘SELECTuniqExact(VisitID) AS unique_sessions,sum(Sign) AS number_sessions,count() AS rows
FROM datasets.visits_v1
FINAL┌─unique_sessions─┬─number_sessions─┬────rows─┐
│ 1676685 │ 1676721 │ 1676721 │
└─────────────────┴─────────────────┴─────────┘ 使用在性能上有其自身的缺点。您可以在文档中找到有关它的更多信息。final
三、如何保证数据质量?
验证没有丢失或重复的事件非常简单。你可以找到很多方法来检测时间序列数据中的异常,从朴素的方法(例如,与前一周相比,事件数在 +20% 或 -20% 以内)到 ML 与 Prophet 或 PyCaret 等库。
数据一致性是一项比较棘手的任务。正如我之前提到的,网络分析服务跟踪有关客户在网站上行为的大量信息。它们记录了数百个参数,我们需要确保所有这些值看起来都有效。
参数可以是数字(持续时间或看到的网页数量)或分类(浏览器或操作系统)。对于数值,我们可以使用统计标准来确保分布保持不变——例如,柯尔莫哥罗夫-斯米尔诺夫检验。
因此,在研究了最佳实践之后,我唯一的问题是如何监控分类变量的一致性,是时候讨论它了。
四、分类变量
让我们以浏览器为例。我们的数据中有 62 个浏览器的唯一值。
SELECT uniqExact(UserAgent) AS unique_browsers
FROM datasets.visits_v1┌─unique_browsers─┐
│ 62 │
└─────────────────┘SELECTUserAgent,count() AS sessions,round((100. * sessions) / (SELECT count()FROM datasets.visits_v1FINAL), 2) AS sessions_share
FROM datasets.visits_v1
FINAL
GROUP BY 1
HAVING sessions_share >= 1
ORDER BY sessions_share DESC┌─UserAgent─┬─sessions─┬─sessions_share─┐
│ 7 │ 493225 │ 29.42 │
│ 2 │ 236929 │ 14.13 │
│ 3 │ 235439 │ 14.04 │
│ 4 │ 196628 │ 11.73 │
│ 120 │ 154012 │ 9.19 │
│ 50 │ 86381 │ 5.15 │
│ 79 │ 63082 │ 3.76 │
│ 121 │ 50245 │ 3 │
│ 1 │ 48688 │ 2.9 │
│ 42 │ 21040 │ 1.25 │
│ 5 │ 20399 │ 1.22 │
│ 71 │ 19893 │ 1.19 │
└───────────┴──────────┴────────────────┘ 我们可以将每个浏览器的共享作为数值变量单独监控,但在这种情况下,我们将监控一个字段的至少 12 个时间序列,.每个至少做过一次警报的人都知道,我们监视的变量越少越好。跟踪许多参数时,需要处理大量误报通知。UserAgent
因此,我开始考虑一种可以显示分布之间差异的指标。这个想法是比较现在 () 和之前 () 的浏览器份额。我们可以根据粒度选择上一个周期:T2T1
- 对于分钟数据——你可以看上一点,
- 对于每日数据 - 值得查看一周前的一天,以考虑每周的季节性,
- 对于月度数据 - 您可以查看一年前的数据。
让我们看下面的例子。

我的第一个想法是查看类似于机器学习中使用的L1规范的启发式指标(更多详细信息)。

对于上面的例子,这个公式将给我们以下结果 — 10%。实际上,这个指标是有意义的——它显示了浏览器已更改的分发事件中的最小份额。
![]()
之后,我和我的老板讨论了这个话题,他在数据科学方面有很多经验。他建议我看看Kullback-Leibler或Jensen-Shannon散度,因为这是计算概率分布之间距离的更有效的方法。
如果您不记得这些指标或以前从未听说过它们,请不要担心,我站在你的立场上。所以我用谷歌搜索了公式(本文彻底解释了这些概念)和我们示例的计算值。
import numpy as npprev = np.array([0.7, 0.2, 0.1])
curr = np.array([0.6, 0.27, 0.13])def get_kl_divergence(prev, curr):kl = prev * np.log(prev / curr)return np.sum(kl)def get_js_divergence(prev, curr): mean = (prev + curr)/2return 0.5*(get_kl_divergence(prev, mean) + get_kl_divergence(curr, mean))kl = get_kl_divergence(prev, curr)
js = get_js_divergence(prev, curr)
print('KL divergence = %.4f, JS divergence = %.4f' % (kl, js))# KL divergence = 0.0216, JS divergence = 0.0055如您所见,我们计算的距离差异很大。所以现在我们(至少)有三种方法来计算之前和现在浏览器份额之间的差异,下一个问题是为我们的监控任务选择哪种方式。
五、获胜者是...
估计不同方法性能的最佳方法是查看它们在现实生活中的表现。为此,我们可以模拟数据中的异常并比较效果。
数据中有两种常见的异常情况:
- 数据丢失:我们开始丢失来自其中一个浏览器的数据,并且所有其他浏览器的份额都在增加
- 更改:当来自一个浏览器的流量开始标记为另一个浏览器时。例如,我们现在看到的 10% 的 Safari 事件是未定义的。
我们可以获取实际的浏览器共享并模拟这些异常。为简单起见,我将把所有份额低于 5% 的浏览器分组到组中。browser = 0
WITH browsers AS(SELECTUserAgent,count() AS raw_sessions,(100. * count()) / (SELECT count()FROM datasets.visits_v1FINAL) AS raw_sessions_shareFROM datasets.visits_v1FINALGROUP BY 1)
SELECTif(raw_sessions_share >= 5, UserAgent, 0) AS browser,sum(raw_sessions) AS sessions,round(sum(raw_sessions_share), 2) AS sessions_share
FROM browsers
GROUP BY browser
ORDER BY sessions DESC┌─browser─┬─sessions─┬─sessions_share─┐
│ 7 │ 493225 │ 29.42 │
│ 0 │ 274107 │ 16.35 │
│ 2 │ 236929 │ 14.13 │
│ 3 │ 235439 │ 14.04 │
│ 4 │ 196628 │ 11.73 │
│ 120 │ 154012 │ 9.19 │
│ 50 │ 86381 │ 5.15 │
└─────────┴──────────┴────────────────┘是时候模拟这两种情况了。您可以在 GitHub 上找到所有代码。对我们来说,最重要的参数是实际效果——丢失或改变的事件份额。理想情况下,我们希望我们的指标等于这种效果。
作为模拟的结果,我们得到了两个图表,显示了事实效应和距离指标之间的相关性。
图表中的每个点都显示一个模拟的结果 — 实际效果和相应的距离。


您可以很容易地看到 L1 范数是我们任务的最佳指标,因为它最接近线。Kullback-Leibler和Jensen-Shannon的分歧很大,并且根据用例(哪个浏览器正在失去流量)具有不同的级别。distance = share of affected events

此类指标不适合监控,因为您将无法指定一个阈值,以便在超过 5% 的流量受到影响时向您发出警报。此外,我们无法轻松解释这些指标,而 L1 范数准确地显示了异常的程度。
六、L1范数计算
现在我们知道什么指标将向我们显示数据的一致性,剩下的最后一个任务是在数据库中实现 L1 范数计算(在我们的例子中是 — ClickHouse)。
我们可以为它使用广为人知的窗口函数。
with browsers as (selectUserAgent as param,multiIf(toStartOfHour(UTCStartTime) = '2014-03-18 12:00:00', 'previous',toStartOfHour(UTCStartTime) = '2014-03-18 13:00:00', 'current','other') as event_time,sum(Sign) as eventsfrom datasets.visits_v1where (StartDate = '2014-03-18')-- filter by partition key is a good practiceand (event_time != 'other')group by param, event_time)
selectsum(abs_diff)/2 as l1_norm
from(selectparam,sumIf(share, event_time = 'current') as curr_share,sumIf(share, event_time = 'previous') as prev_share,abs(curr_share - prev_share) as abs_difffrom(selectparam,event_time,events,sum(events) over (partition by event_time) as total_events,events/total_events as sharefrom browsers)group by param)┌─────────────l1_norm─┐
│ 0.01515028932687386 │
└─────────────────────┘ClickHouse有非常强大的数组函数,在支持窗口函数之前,我已经使用了很长时间。所以我想向你展示这个工具的强大功能。
with browsers as (selectUserAgent as param,multiIf(toStartOfHour(UTCStartTime) = '2014-03-18 12:00:00', 'previous',toStartOfHour(UTCStartTime) = '2014-03-18 13:00:00', 'current','other') as event_time,sum(Sign) as eventsfrom datasets.visits_v1where StartDate = '2014-03-18' -- filter by partition key is a good practiceand event_time != 'other'group by param, event_timeorder by event_time, param)
select l1_norm
from(select-- aggregating all param values into arraysgroupArrayIf(param, event_time = 'current') as curr_params,groupArrayIf(param, event_time = 'previous') as prev_params,-- calculating params that are present in both time periods or only in one of themarrayIntersect(curr_params, prev_params) as both_params,arrayFilter(x -> not has(prev_params, x), curr_params) as only_curr_params,arrayFilter(x -> not has(curr_params, x), prev_params) as only_prev_params,-- aggregating all events into arraysgroupArrayIf(events, event_time = 'current') as curr_events,groupArrayIf(events, event_time = 'previous') as prev_events,-- calculating events sharesarrayMap(x -> x / arraySum(curr_events), curr_events) as curr_events_shares,arrayMap(x -> x / arraySum(prev_events), prev_events) as prev_events_shares,-- filtering shares for browsers that are present in both periodsarrayFilter(x, y -> has(both_params, y), curr_events_shares, curr_params) as both_curr_events_shares,arrayFilter(x, y -> has(both_params, y), prev_events_shares, prev_params) as both_prev_events_shares,-- filtering shares for browsers that are present only in one of periodsarrayFilter(x, y -> has(only_curr_params, y), curr_events_shares, curr_params) as only_curr_events_shares,arrayFilter(x, y -> has(only_prev_params, y), prev_events_shares, prev_params) as only_prev_events_shares,-- calculating the abs differences and l1 normarraySum(arrayMap(x, y -> abs(x - y), both_curr_events_shares, both_prev_events_shares)) as both_abs_diff,1/2*(both_abs_diff + arraySum(only_curr_events_shares) + arraySum(only_prev_events_shares)) as l1_normfrom browsers)┌─────────────l1_norm─┐
│ 0.01515028932687386 │
└─────────────────────┘这种方法对于具有pythonic思维的人来说可能很方便。凭借持久性和创造力,可以使用数组函数编写任何逻辑。
七、警报和监控
我们有两个查询,向我们显示浏览器在我们数据中的份额波动。可以使用此方法监视感兴趣的数据。
剩下的唯一一点就是在警报阈值上与团队保持一致。我通常会查看历史数据和以前的异常情况,以获取一些初始级别,然后使用新信息不断调整它们:误报警报或错过的异常。
此外,在实施监控的过程中,我遇到了一些细微差别,我想简要介绍一下:
- 例如,数据中存在在监视中没有意义的参数,或者 ,因此请明智地选择要包含的参数。
UserIDStartDate - 您可能具有高基数的参数。例如,在 Web 分析中,数据具有超过 600K 个唯一值。为其计算指标可能会消耗资源。因此,我建议要么将这些值(例如,采用域或 TLD)存储,要么仅监控顶级值并将其他值分组到单独的组“其他”中。
StartURL - 您可以使用存储桶对数值使用相同的框架。
- 在某些情况下,预计数据会发生重大变化。例如,如果您正在监视应用程序版本字段,则在每个版本发布后都会收到警报。此类事件有助于确保您的监控仍在:)
相关文章:
【数据挖掘】如何保证数据一致性?
一、说明 我曾经在网络分析服务公司担任数据分析师。此类系统可帮助网站收集和分析客户行为数据。 不言而喻,数据是网络分析服务最宝贵的价值。我的主要目标之一是监控数据质量。 为了确保数据一切正常,我们需要关注两件事: 没有丢失或重复的…...

深度学习AIGC问答
文章目录 **.pt 和 .pth 文件区别**.pkl 和 .pth 区别深度学习中.ckpt .h5 文件的区别深度学习中.ckpt .pth 文件的区别TensorFlow框架和keras框架的区别、和关系 Pytorch模型 .pt, .pth的存加载方式 pytorch解析.pth模型文件 .pt 和 .pth 文件区别 在深度学习中,.…...
)
大数据第二阶段测试(二)
1.接到需求之后的开发流程是什么? 参考答案一 接到需求后的开发流程一般包括需求分析、设计、编码、测试和部署等步骤。首先,对需求进行全面的分析,明确需求的背景、目标和功能。然后,根据需求进行系统设计,包括数据库…...
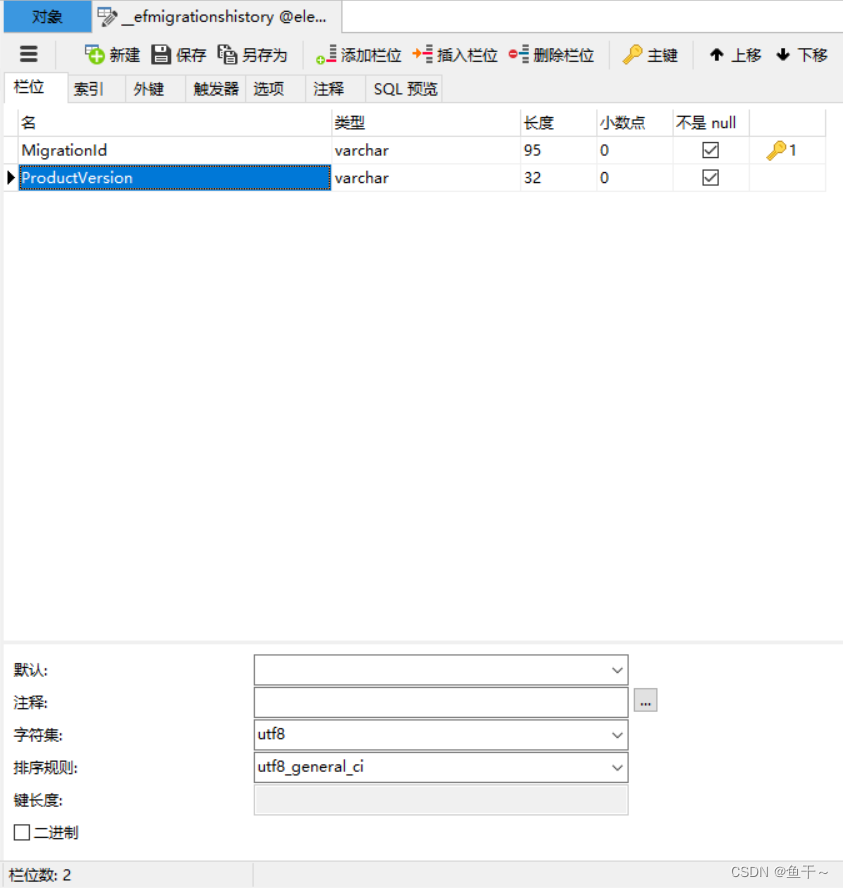
【mysql报错解决】MySql.Data.MySqlClient.MySqlException (0x80004005)或1366
场景:c#使用mysql数据库执行数据库迁移,使用了新增inserter的语句,然后报错 报错如下: 1.MySql.Data.MySqlClient.MySqlException (0x80004005): Incorrect string value: ‘\xE6\x9B\xB4\xE6\x94\xB9…’ for column ‘Migratio…...
Kafka-eagle监控平台
Kafka-Eagle简介 在开发工作中,当业务不复杂时,可以使用Kafka命令来进行一些集群的管理工作。但如果业务变得复杂,例如:需要增加group、topic分区,此时,再使用命令行就感觉很不方便,此时&#x…...

ubuntu16.04制作本地apt源离线安装
一、首先在有外网的服务器安装需要安装的软件,打包deb软件。 cd /var/cache/apt zip -r archives.zip archives sz archives.zip 二、在无外网服务器上传deb包,并配置apt源。 1、上传deb包安装lrzsz、unzip 用ftp软件连接无外网服务器协议选择sftp…...

【Leetcode】91.解码方法
一、题目 1、题目描述 一条包含字母 A-Z 的消息通过以下映射进行了 编码 : A -> "1" B -> "2" ... Z -> "26"要 解码 已编码的消息,所有数字必须基于上述映射的方法,反向映射回字母(可能有多种方法)。例如,"11106" …...

easyx图形库基础:2.基本运动+键盘交互
基本运动键盘交互 一.基本运动1.基本运动:1.如何实现动画:2.实现一个小球从左到右从右到左:(往返运动)3.实现一个五角星的移动:4.实现一个五角星自转和圆周运动的集合:(圆周运动&…...
计算机竞赛 opencv 图像识别 指纹识别 - python
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于机器视觉的指纹识别系统 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 该项目较为新颖,适…...

UI自动化测试常见的Exception
一. StaleElementReferenceException: - 原因:引用的元素已过期。原因是页面刷新了,此时当然找不到之前页面的元素。- 解决方案:不确定什么时候元素就会被刷新。页面刷新后重新获取元素的思路不变,这时可以使用python的…...

魔棒:手机智能无人直播软件多少钱?
无人直播因为直播门槛低,不需要真人出镜,不需要请主播,加上可以24小时直播卖券,效果出奇的好,一时很受广大商家的欢迎,那么,这种ai智能无人直播软件究竟多少钱呢? 当然,…...

网络安全 Day-32 Linux 系统定时任务补充
定时任务补充 1. 定时任务在生产时任务场景2. 定时任务实践 1. 定时任务在生产时任务场景 每天零点对系统数据备份每天我晚上零点统计财务报表每分钟剪口没有人进入计算机 2. 定时任务实践 定时任务服务启动:systemctl start crondsystemctl enable crond查看配置…...

【OpenGauss源码学习 —— 执行算子(hash join 算子)】
执行算子(hash join 算子) 连接算子hash join算子ExecInitHashJoin函数HashJoinState结构体TupleTableSlot 结构体JoinState结构体PlanState结构体ExecInitHashJoin函数部分代码介绍 ExecHashJoin函数调试信息 ExecEndHashJoin函数ExecReScanHashJoin函数…...

[Go版]算法通关村第十二关青铜——不简单的字符串转换问题
目录 题目:转换成小写字母思路分析:大写字母ASCII码 32 小写字母ASCII码Go代码Go代码-优化: 大写字母ASCII码 | 32 小写字母ASCII码 题目:字符串转换整数(atoi)思路分析:去除首部空格 明确正负 读取数…...

十种排序算法(附动图)
排序算法 一、基本介绍 排序算法比较基础,但是设计到很多计算机科学的想法,如下: 1、比较和非比较的策略 2、迭代和递归的实现 3、分而治之思想 4、最佳、最差、平均情况时间复杂度分析 5、随机算法 二、排序算法的分类 …...

【校招VIP】测试类型之兼容性测试分析
考点介绍: 兼容性是测试工作里面比较复杂的一种情况,也是校招里面考察的一个重点,需要从屏幕功能,数据,操作系统等多个维度进行分析。 『测试类型之兼容性测试分析』相关题目及解析内容可点击文章末尾链接查看&#x…...
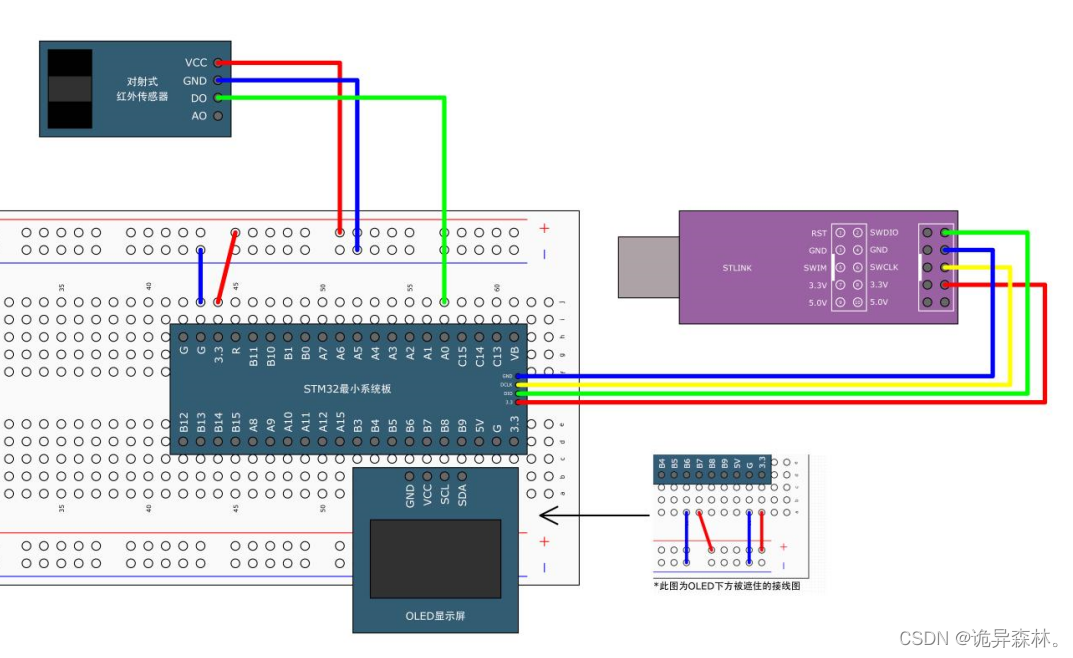
STM32--TIM定时器(1)
文章目录 TIM简介定时器类型 通用定时器预分频器时序计数器时序定时中断基本结构TIM内部中断工程TIM外部中断工程 TIM简介 STM32的TIM(定时器)是一种非常常用的外设,用于实现各种定时和计数功能。它是基于时钟信号进行计数,并在计…...

Android取证——基础知识
目录 一、安卓系统版本 二、安装操作系统UI 三、鉴权码 1.IMEI(手机序列号) 2.ICCID...
【学习心得】安装cuda/cudann和pytorch
一、查看驱动信息 # 进入CMD输入命令 nvidia-smi 也可以右下角图标打开NVIDIA 设置进行查看 二、下载安装CUDA 1、下载 下载地址 https://developer.nvidia.com/ 2、安装 推荐自定义安装。建议只勾选Cuda,只安装这一个就好,以免报错安装失败。 3、验证…...

中电金信通过KCSP认证 云原生能力获权威认可
中电金信通过KCSP(Kubernetes Certified Service Provider)认证,正式成为CNCF(云原生计算基金会)官方认证的 Kubernetes 服务提供商。 Kubernetes是容器管理编排引擎,底层实现为容器技术,是云原…...


煤矿智能化通信网络构建:从极端环境挑战到一体化方案实践
1. 项目概述:一次工业通信技术在传统能源领域的深度赋能实践最近刚结束的北京煤炭展,我们迈威通信的展台算是小火了一把。不少行业内的老朋友和新客户过来,聊得最多的不是我们的交换机、网关又出了什么新型号,而是“你们这套东西&…...

Git提交规范与自动化实践:从Conventional Commits到团队协作
1. 项目概述与核心价值最近在整理团队代码仓库时,发现一个挺普遍的问题:提交记录五花八门,什么“fix bug”、“update”、“test”之类的信息满天飞。这种混乱的提交历史,不仅让后续的代码审查和问题追溯变得异常困难,…...
M.2 SSD系统迁移实战:从克隆到无缝启动)
【玩转Jetson TX2 NX】(四)M.2 SSD系统迁移实战:从克隆到无缝启动
1. 为什么需要将系统迁移到M.2 SSD? Jetson TX2 NX作为一款嵌入式AI计算设备,默认搭载的eMMC存储空间往往捉襟见肘。我在实际项目中发现,16GB的eMMC在安装完JetPack系统后,剩余空间连一个中等规模的深度学习模型都放不下。更不用…...

STM32 的IIC通信接收和发送详解
STM32 的 IIC 通信:IIC 接收和发送详解 1. 前言 IIC,也常写作 I2C,是单片机开发中非常常用的一种同步串行通信协议。 在 STM32 项目中,很多外设模块都会使用 IIC 通信,例如: OLED 显示屏;EEPROM…...

OpenClaw企业微信渠道配置教程|API模式+长连接+全部授权
OpenClaw 连接企业微信完整图文教程 前置准备 下载小龙虾open claw一键装机包(www.totom.top)并安装 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 已安装并登录企业微信客户端。 当前企业微信账号具备创建和管理…...

大型知识竞赛的技术保障:构建服务器、网络与备用方案的坚实堡垒
🏗️ 大型知识竞赛的技术保障:构建服务器、网络与备用方案的坚实堡垒稳定 高效 安全 让技术成为竞赛的隐形支撑🎯 引言:技术保障是竞赛成功的基石一场成功的大型知识竞赛,其精彩纷呈的背后,离不开一套周…...

循迹小车传感器布局与状态机编程避坑指南:从5路红外到精准过直角弯
循迹小车传感器布局与状态机编程避坑指南:从5路红外到精准过直角弯 在智能小车开发领域,循迹功能是最基础也最具挑战性的环节之一。许多创客和学生在完成硬件搭建后,往往会陷入软件调试的泥潭——小车要么频繁偏离轨道,要么在直角…...

如何快速获取全网音乐歌词:免费开源工具的终极指南
如何快速获取全网音乐歌词:免费开源工具的终极指南 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到心爱歌曲的歌词而烦恼吗?163Music…...

嵌入式Linux嵌入式Linux驱动开发:板级DTS实操与完整实战演练——从修改设备树到点亮LED的完整闭环
嵌入式Linux嵌入式Linux驱动开发:板级DTS实操与完整实战演练——从修改设备树到点亮LED的完整闭环 仓库已经开源!所有教程,主线内核移植,跑新版本imx-linux/uboot都在这里,或者一起来尝试跑7.0的Linux!欢迎…...