Wordcloud | 风中有朵雨做的‘词云‘哦!~
1写在前面
今天可算把key搞好了,不得不说🏥里手握生杀大权的人,都在自己的能力范围内尽可能的难为你。😂
我等小大夫也是很无奈,毕竟奔波霸、霸波奔是要去抓唐僧的。 🤐
好吧,今天是词云(Wordcloud)教程,大家都说简单,但实际操作起来又有一些难度,一起试试吧。😋
2用到的包
rm(list = ls())
library(tidyverse)
library(tm)
library(wordcloud)
3示例数据
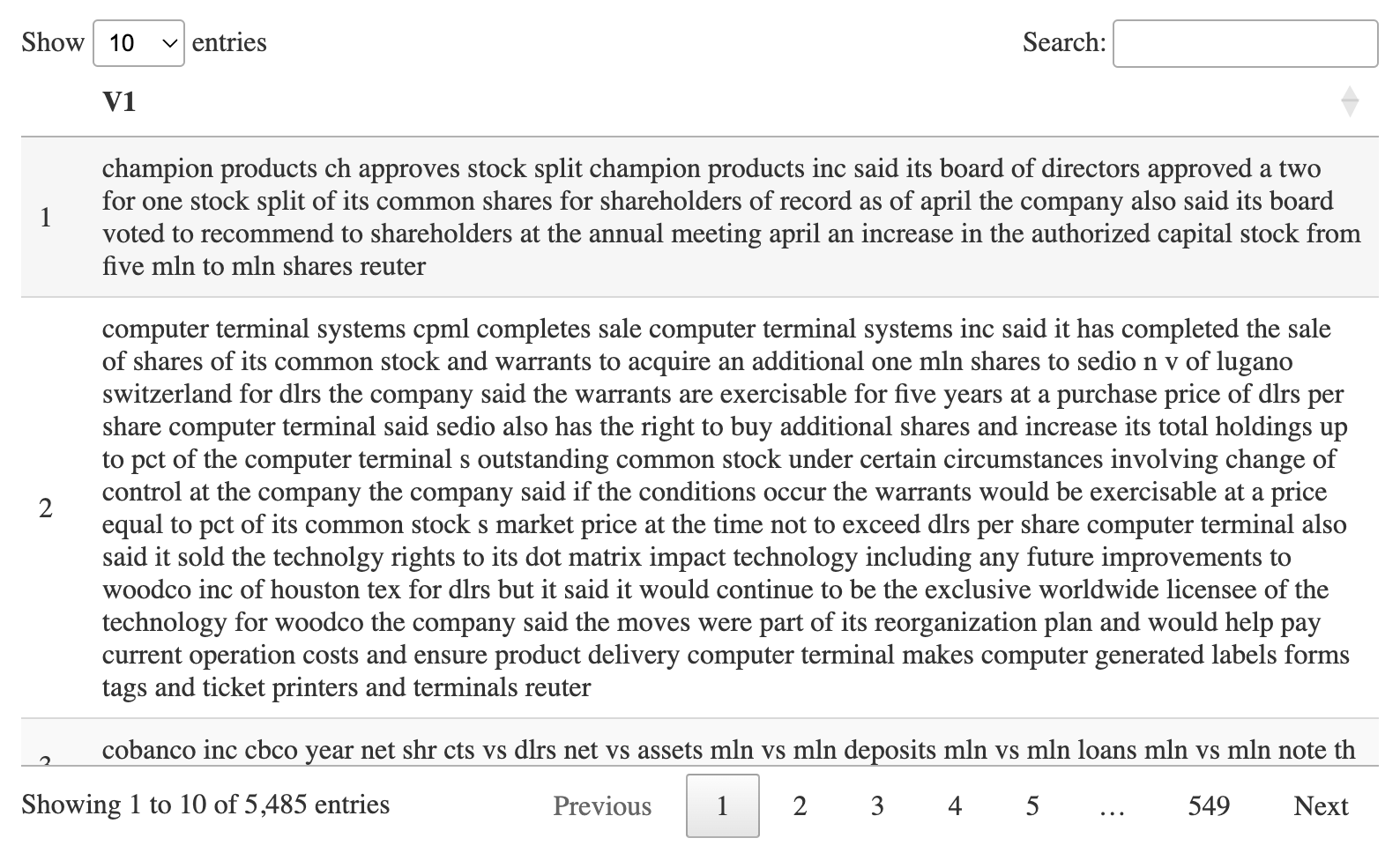
这里我准备好了2个文件用于绘图,首先是第一个文件,每行含有n个词汇。🤣
dataset <- read.delim("./wordcloud/dataset.txt", header=FALSE)
DT::datatable(dataset)
接着是第2个文件,代表dataset文件中每一行的label。🥸
dataset_labels <- read.delim("./wordcloud/labels.txt",header=FALSE)
dataset_labels <- dataset_labels[,1]
dataset_labels_p <- paste("class",dataset_labels,sep="_")
unique_labels <- unique(dataset_labels_p)
unique_labels

4数据初步整理
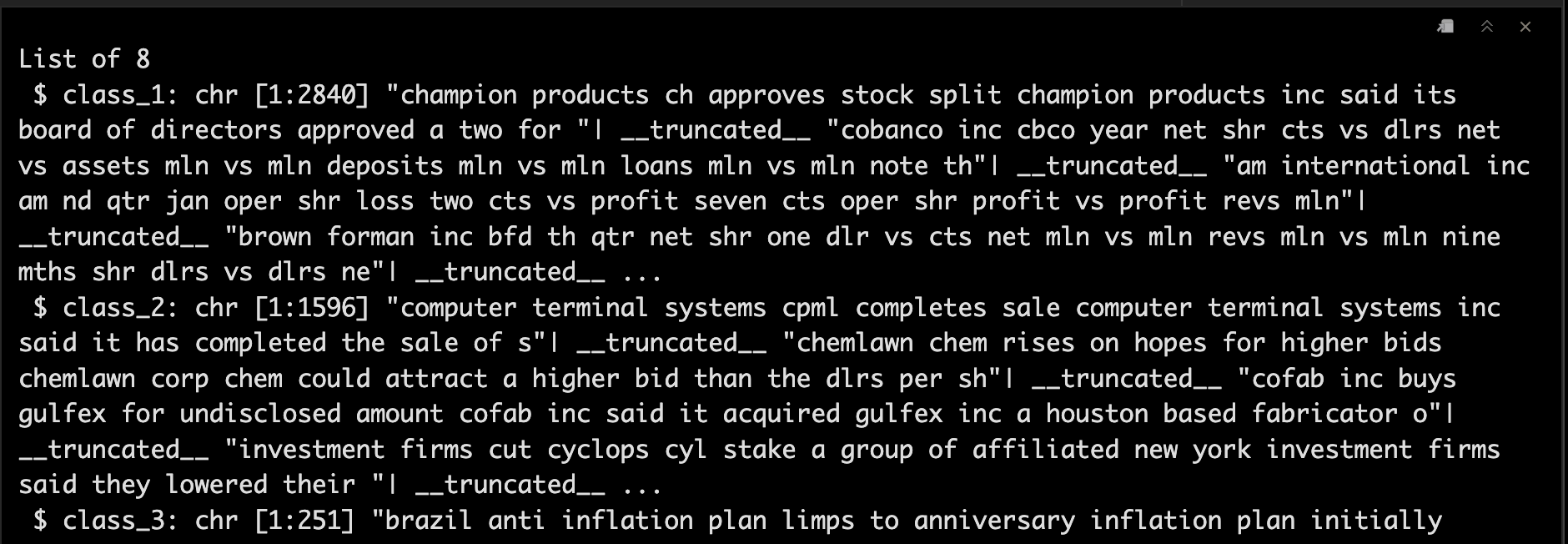
然后我们利用sapply函数把数据整理成list。😘
可能会有小伙伴问sapply和lapply有什么区别呢!?😂
ok, sapply()函数与lapply()函数类似,但返回的是一个简化的对象,例如向量或矩阵。😜
如果应用函数的结果具有相同的长度和类型,则sapply()函数将返回一个向量。
如果结果具有不同的长度或类型,则sapply()函数将返回一个矩阵。😂
dataset_s <- sapply(unique_labels,function(label) list( dataset[dataset_labels_p %in% label,1] ) )
str(dataset_s)
5数据整理成Corpus
接着我们把上面整理好的list中每个元素都整理成一个单独的Corpus。🤩
dataset_corpus <- lapply(dataset_s, function(x) Corpus(VectorSource( toString(x) )))
然后再把Cporus合并成一个。🧐
dataset_corpus_all <- dataset_corpus
6去除部分词汇
修饰一下, 去除标点、数字、无用的词汇等等。😋
dataset_corpus_all <- lapply(dataset_corpus_all, tm_map, removePunctuation)
dataset_corpus_all <- lapply(dataset_corpus_all, tm_map, removeNumbers)
dataset_corpus_all <- lapply(dataset_corpus_all, tm_map, function(x) removeWords(x,stopwords("english")))
words_to_remove <- c("said","from","what","told","over","more","other","have",
"last","with","this","that","such","when","been","says",
"will","also","where","why","would","today")
dataset_corpus_all <- lapply(dataset_corpus_all, tm_map, function(x)removeWords(x, words_to_remove))
7计算term matrix并去除部分词汇
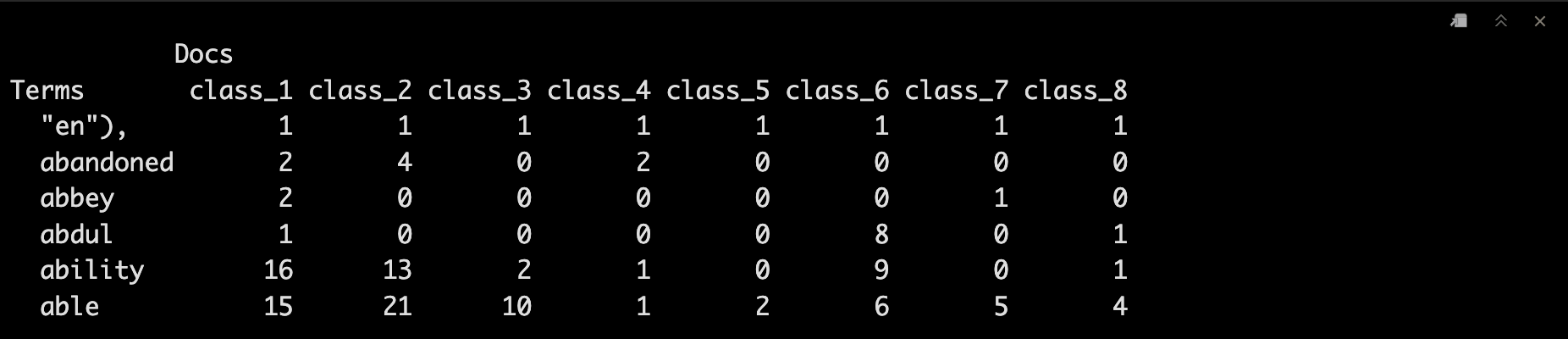
document_tm <- TermDocumentMatrix(dataset_corpus_all)
document_tm_mat <- as.matrix(document_tm)
colnames(document_tm_mat) <- unique_labels
document_tm_clean <- removeSparseTerms(document_tm, 0.8)
document_tm_clean_mat <- as.matrix(document_tm_clean)
colnames(document_tm_clean_mat) <- unique_labels
# 去除长度小于4的term
index <- as.logical(sapply(rownames(document_tm_clean_mat), function(x) (nchar(x)>3) ))
document_tm_clean_mat_s <- document_tm_clean_mat[index,]
head(document_tm_clean_mat_s)
8可视化
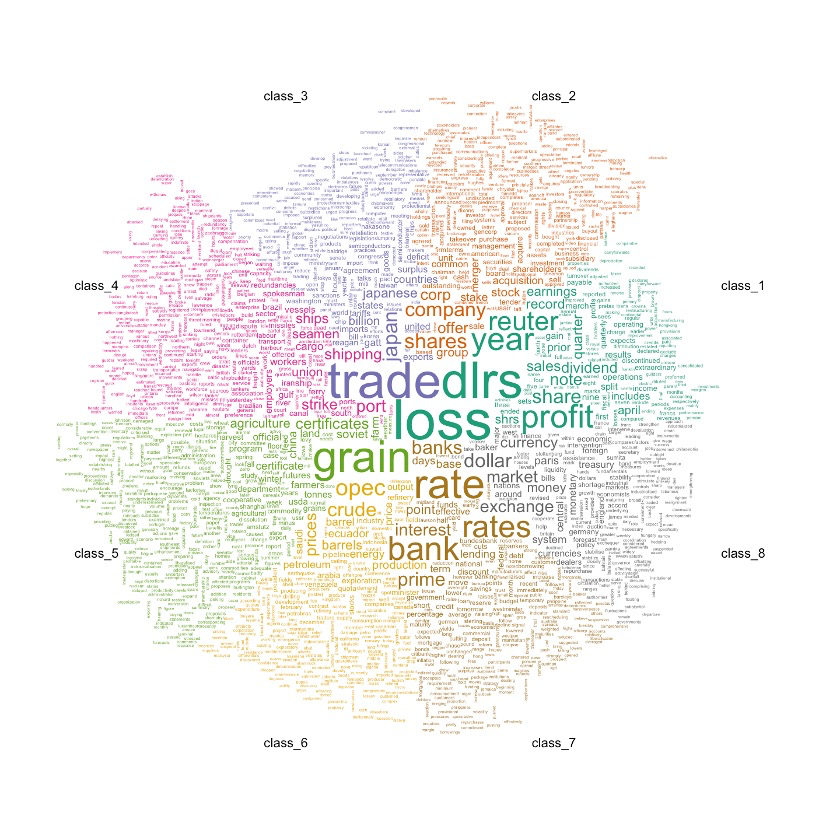
8.1 展示前500个词汇
comparison.cloud(document_tm_clean_mat_s,
max.words=500,
random.order=F,
use.r.layout = F,
scale = c(10,0.4),
title.size=1.4,
title.bg.colors = "white"
)

8.2 展示前2000个词汇
comparison.cloud(document_tm_clean_mat_s,
max.words=2000,
random.order=F,
use.r.layout = T,
scale = c(6,0.4),
title.size=1.4,
title.bg.colors = "white"
)
8.3 展示前2000个common词汇
commonality.cloud(document_tm_clean_mat_s,
max.words=2000,
random.order=F)


点个在看吧各位~ ✐.ɴɪᴄᴇ ᴅᴀʏ 〰
📍 🤩 LASSO | 不来看看怎么美化你的LASSO结果吗!?
📍 🤣 chatPDF | 别再自己读文献了!让chatGPT来帮你读吧!~
📍 🤩 WGCNA | 值得你深入学习的生信分析方法!~
📍 🤩 ComplexHeatmap | 颜狗写的高颜值热图代码!
📍 🤥 ComplexHeatmap | 你的热图注释还挤在一起看不清吗!?
📍 🤨 Google | 谷歌翻译崩了我们怎么办!?(附完美解决方案)
📍 🤩 scRNA-seq | 吐血整理的单细胞入门教程
📍 🤣 NetworkD3 | 让我们一起画个动态的桑基图吧~
📍 🤩 RColorBrewer | 再多的配色也能轻松搞定!~
📍 🧐 rms | 批量完成你的线性回归
📍 🤩 CMplot | 完美复刻Nature上的曼哈顿图
📍 🤠 Network | 高颜值动态网络可视化工具
📍 🤗 boxjitter | 完美复刻Nature上的高颜值统计图
📍 🤫 linkET | 完美解决ggcor安装失败方案(附教程)
📍 ......
本文由 mdnice 多平台发布
相关文章:
Wordcloud | 风中有朵雨做的‘词云‘哦!~
1写在前面 今天可算把key搞好了,不得不说🏥里手握生杀大权的人,都在自己的能力范围内尽可能的难为你。😂 我等小大夫也是很无奈,毕竟奔波霸、霸波奔是要去抓唐僧的。 🤐 好吧,今天是词云&#x…...

《孤注一掷》现实版:29万打水漂,华为程序员也躲不过的诈骗
明天周五,约吗? 不管怎样,反正播妞已经订好了《孤注一掷》的电影票。不为别的,《孤注一掷》太敢拍了!!! 美女荷官在线发牌,高知程序员在线养“猪”,诈骗头目“虔诚”拜…...

C语言库函数之 qsort 讲解、使用及模拟实现
引入 我们在学习排序的时候,第一个接触到的应该都是冒泡排序,我们先来复习一下冒泡排序的代码,来作为一个铺垫和引入。 代码如下: #include<stdio.h>void bubble_sort(int *arr, int sz) {int i 0;for (i 0; i < sz…...

Maven之mirrorof范围
mirrorOf 是 central 还是 * 的问题 在配置阿里对官方中央仓库的镜像服务器时,我们使用到了 <mirror> 元素。 <mirror><id>aliyunmaven</id><mirrorOf>central</mirrorOf><name>阿里云公共仓库</name><url>…...
游戏中的UI适配
引用参考:感谢GPT UI适配原理以及常用方案 游戏UI适配是确保游戏界面在不同设备上以不同的分辨率、屏幕比例和方向下正常显示的关键任务。下面是一些常见的游戏UI适配方案: 1.分辨率无关像素(Resolution-Independent Pixels)&a…...

【Linux命令详解 | gzip命令】 gzip命令用于压缩文件,可以显著减小文件大小
文章标题 简介一,参数列表二,使用介绍1. 基本压缩和解压2. 压缩目录3. 查看压缩文件内容4. 测试压缩文件的完整性5. 强制压缩6. 压缩级别7. 与其他命令结合使用8. 压缩多个文件9. 自动删除原文件 总结 简介 在Linux中,gzip命令是一款强大的文…...

IP 协议的相关特性和数据链路层相关知识总结
目录 IP 协议的相关特性 一、IP协议的特性 二、 IP协议数据报格式 三、 IP协议的主要功能 1. 地址管理 动态分配 IP地址 NAT机制 NAT背景下的通信 IPV6 2. 路由控制 3.IP报文的分片与重组 数据链路层相关知识 1、以太网协议(Ethernet) 2.M…...

探索C语言中的常见排序算法
探索C语言中的常见排序算法 排序算法是计算机科学中至关重要的基础知识之一,它们能够帮助我们对数据进行有序排列,从而更高效地进行搜索、插入和删除操作。在本篇博客中,我们将深入探讨C语言中的一些常见排序算法,包括它们的工作…...
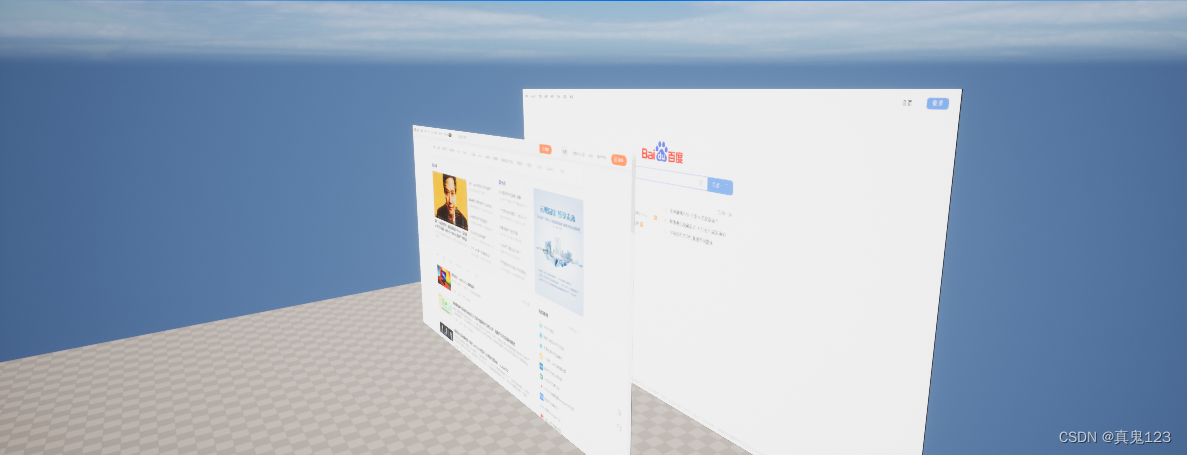
【UE】Web Browser内嵌网页在场景中的褪色问题
使用WebBrowser放置在场景中时,网页颜色会出现异常的褪色。 这是因为 Web 浏览器插件以 sRGB 格式输出其颜色数据,而 Widget/3D Widget 需要线性 RGB 格式的数据。 可以通过创建在 3D Widget 中使用的新材质(而不是默认的 Widget3DPassthr…...

rust入门系列之Rust介绍及开发环境搭建
Rust教程 Rust基本介绍 网站: https://www.rust-lang.org/ rust是什么 开发rust语言的初衷是: 在软件发展速度跟不上硬件发展速度,无法在语言层面充分的利用硬件多核cpu不断提升的性能和 在系统界别软件开发上,C出生比较早,内…...

embed mongodb 集成spring
在property文件下添加 de.flapdoodle.mongodb.embedded.version5.0.5 spring.mongodb.embedded.storage.oplog-size0不指定数据库,会使用test, port默认是0,随机端口号。 oplog-size mac默认是192mb, 其他系统会使用5%的磁盘可用空间&#x…...

ssh远程连接服务器
一、远程连接服务器简介 二、连接加密技术简介 三、ssh服务配置 四、用户登录ssh服务 Enforcing会强制限制,如端口为22,可以访问,如果是2000端口,不能使用 Permissive是宽容的模式,不限制使用端口 Enforcing会重启失败…...
性能分析之MySQL慢查询日志分析(慢查询日志)
一、背景 MySQL的慢查询日志是MySQL提供的一种日志记录,他用来记录在MySQL中响应的时间超过阈值的语句,具体指运行时间超过long_query_time(默认是10秒)值的SQL,会被记录到慢查询日志中。 慢查询日志一般用于性能分析时开启,收集慢SQL然后通过explain进行全面分析,一…...
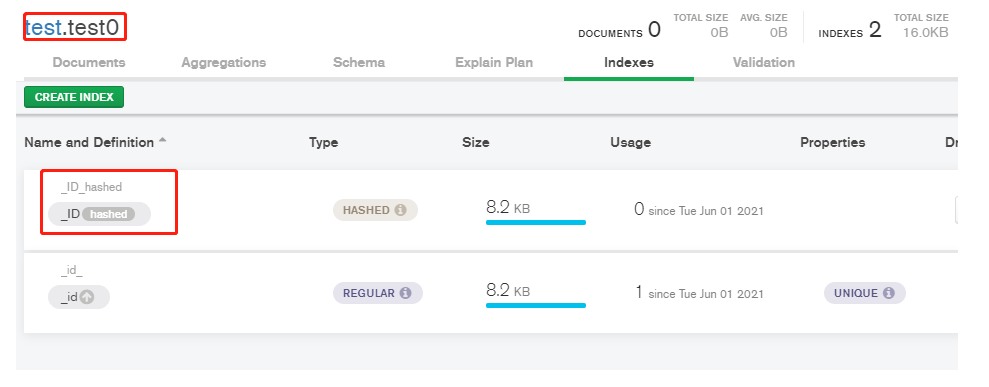
每日一练 | mongo集群如何创建分片键
文章目录 MongoDB是什么什么是分片键环境如何设置分片键 MongoDB是什么 MongoDB 是一个基于分布式文件存储的数据库 什么是分片键 分片:每个分片包含分片数据的一部分。每个分片可以部署为副本集。 而分片键的作用就是把数据按一定的条件分布到各个分片中&#…...
Postman
Postman 简介下载安装 简介 Postman 是一款用于测试和开发 API(应用程序编程接口)的工具,它提供了用户友好的界面和丰富的功能,帮助开发者轻松地创建、测试、调试和文档化各种类型的 API。无论是在构建 Web 应用、移动应用还是其…...
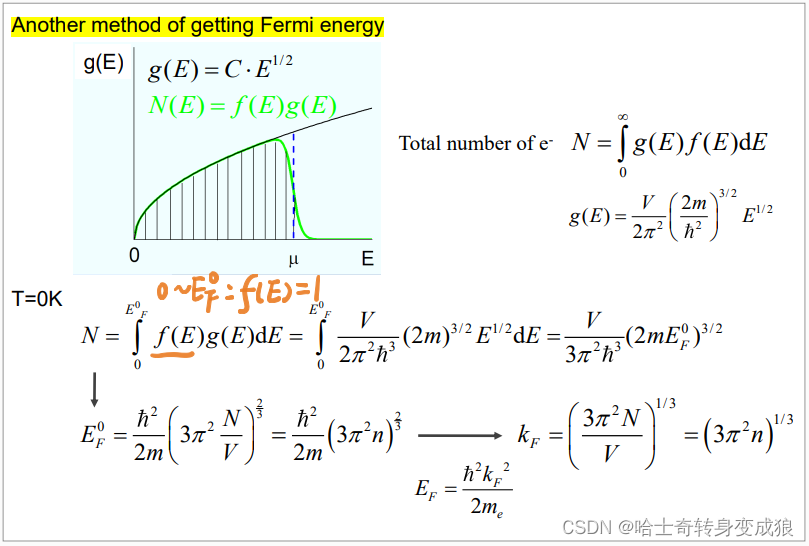
chapter 3 Free electrons in solid - 3.1 自由电子模型
3.1 自由电子模型 Free electron model 研究晶体中的电子: 自由电子理论:不考虑离子实能带理论:考虑离子实(周期性势场)的作用 3.1.1 德鲁德模型 Drude Model - Classical Free Electron Model (1)德鲁德模型 德鲁…...

搭建博客时前端美化内容CSS推荐
一、背景 在搭建博客的时候,发现对其markdown文章内容进行渲染的时候,样式调整比较花费时间 二、解决思路 自己适配样式 缺点:ROI不高 使用开源的markdown的样式:github-markdown-css 三、实现教程 1、NPM安装 npm install …...

Linux中 socket编程中多进程/多线程TCP并发服务器模型
一、循环服务器(while)【不常用】 一次只能处理一个客户端的请求,等这个客户端退出后,才能处理下一个客户端。缺点:循环服务器所处理的客户端不能有耗时操作。 模型 sfd socket(); bind(); listen(); while(1) {newfd accept();while(1){r…...
【内网穿透】如何实现在外web浏览器远程访问jupyter notebook服务器
文章目录 前言1. Python环境安装2. Jupyter 安装3. 启动Jupyter Notebook4. 远程访问4.1 安装配置cpolar内网穿透4.2 创建隧道映射本地端口 5. 固定公网地址 前言 Jupyter Notebook,它是一个交互式的数据科学和计算环境,支持多种编程语言,如…...
win10下如何安装ffmpeg
安装ffmpeg之前先安装win10 绿色软件管理软件:scoop. Scoop的基本介绍 Scoop是一款适用于Windows平台的命令行软件(包)管理工具,这里是Github介绍页。简单来说,就是可以通过命令行工具(PowerShell、CMD等…...

RakkasJS深度解析:基于Bun的全栈React框架性能与迁移实践
1. 项目概述:下一代全栈React框架的探索如果你和我一样,在过去几年里深度使用过Next.js、Remix或者SvelteKit这类全栈框架,那你肯定对它们带来的开发体验又爱又恨。爱的是它们统一了前后端,让全栈开发变得前所未有的顺畅ÿ…...

如何快速解决AKShare股票数据获取失败:完整的数据采集优化指南
如何快速解决AKShare股票数据获取失败:完整的数据采集优化指南 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirror…...
)
Linux蓝牙SPP连接保姆级教程:从手机App到开发板双向通信实战(Android/iOS)
Linux蓝牙SPP连接实战:手机与开发板双向通信全指南 当智能家居控制面板需要无线接收手机指令,或是工业传感器数据要通过移动设备实时查看时,蓝牙串口协议(SPP)便成为最便捷的桥梁。不同于常见的蓝牙音频传输,SPP提供了稳定的数据通…...

为什么83%的用户误读NotebookLM引用溯源?一文讲透证据链完整性校验四步法
更多请点击: https://intelliparadigm.com 第一章:为什么83%的用户误读NotebookLM引用溯源?一文讲透证据链完整性校验四步法 NotebookLM 的“引用溯源”功能并非传统意义上的文献标注,而是一套基于语义锚点与片段置信度的轻量级证…...

QT开发避坑指南:用setWindowFlags搞定自定义标题栏,别再为窗口移动发愁了
QT自定义标题栏实战:从事件重写到优雅封装的完整解决方案 当开发者决定为QT应用打造一套独特的视觉风格时,第一个拦路虎往往是系统默认标题栏的去除与自定义实现。这看似简单的需求背后,隐藏着窗口管理、事件处理、用户体验等一系列技术挑战。…...

如何5分钟搭建个人离线小说库:番茄小说下载器终极指南
如何5分钟搭建个人离线小说库:番茄小说下载器终极指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾经遇到过这样的情况:在通勤路上网络突然中断…...

双机并联自适应虚拟阻抗下垂控制仿真模型附Simulink仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

ESP32硬件IIC驱动SHT30:从零构建温湿度监测组件
1. ESP32与SHT30传感器入门指南 第一次接触ESP32和SHT30温湿度传感器时,我完全被各种专业术语搞晕了。后来在实际项目中摸爬滚打才发现,这套组合其实特别适合物联网开发新手。ESP32就像个全能型选手,自带Wi-Fi和蓝牙,而SHT30则是瑞…...

实景复刻:动态目标实时映射与轨迹溯源平台
实景复刻:动态目标实时映射与轨迹溯源平台技术定位:实景动态复刻体系构建者 时空轨迹全链路溯源范式开创者执行摘要在数字孪生、视频孪生从静态可视化向动态可计算演进的关键阶段,物理世界与数字世界时空不同步、虚实不精准、动态不连续、轨…...
)
告别Xilinx思维:用Microsemi Libero为SmartFusion FPGA创建你的第一个工程(附资源清单)
告别Xilinx思维:用Microsemi Libero为SmartFusion FPGA创建你的第一个工程(附资源清单) 当习惯了Xilinx Vivado或Intel Quartus的工程师第一次打开Microsemi Libero时,那种感觉就像突然被扔进了一个陌生的城市——所有的路标都似…...