Python爬虫——scrapy_当当网图书管道封装
- 创建爬虫项目
srcapy startproject scrapy_dangdang
- 进入到spider文件里创建爬虫文件(这里爬取的是青春文学,仙侠玄幻分类)
srcapy genspider dang http://category.dangdang.com/cp01.01.07.00.00.00.html
- 获取图片、名字和价格
# 所有的seletor的对象,都可以再次调用xpath方法
li_list = response.xpath('//div[@id="search_nature_rg"]//li')for li in li_list:# 获取图片src = li.xpath('.//img/@data-original').extract_first()# 第一张图片和其他图片的标签的属性不一样# 第一张图片的src是可以使用的,其他图片的地址在data-original里if src:src = srcelse:src = li.xpath('.//img/@src').extract_first()# 获取名字name = li.xpath('.//img/@alt').extract_first()# 获取价格price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()print(src, name, price)
- 在items里定义要下载的数据
import scrapyclass ScrapyDangdang39Item(scrapy.Item):# 要下载的数据都有什么# 图片src = scrapy.Field()# 名字name = scrapy.Field()# 价格price = scrapy.Field()
- 在dang.py里导入items
from ..items import ScrapyDangdang39Item
- 在parse方法里定义一个对象book,然后把获取到的值传递到pipelines
book = ScrapyDangdang39Item(src=src, name=name, price=price)# 获取一个book就将book传递给pipelines
yield book
- 开启管道
在settings中,把这几行代码取消注释

管道可以有很多个,但是管道是有优先级的,优先级的范围是1到1000 值越小,优先级越高 - 下载数据
打开piplines.py
class ScrapyDangdang39Pipeline:# 方法1# 在爬虫文件执行前执行的一个方法def open_spider(self, spider):self.fp = open('book.json', 'w', encoding='utf-8')def process_item(self, item, spider):# item就是yield后面的book对象# 1.write方法必须要写一个字符串,而不是其他的对象# 2.w模式,每一个对象都会打开一次文件,然后覆盖之前的内容,所以使用a模式with open('book.json', 'a', encoding='utf-8')as fp:fp.write(str(item))return item
但是这种模式不推荐,因为每传递过来一个数据,就要打开一次文件,对文件的操作太过频繁
换一种方法
class ScrapyDangdang39Pipeline:# 在爬虫文件执行前执行的一个方法def open_spider(self, spider):self.fp = open('book.json', 'w', encoding='utf-8')def process_item(self, item, spider):# item就是yield后面的book对象self.fp.write(str(item))return item# 在爬虫文件执行完后执行的一个方法def close_spider(self, spider):self.fp.close()
- 运行dang.py文件就可以把数据保存到本地了
完整代码
dang.py
import scrapy
from ..items import ScrapyDangdang39Itemclass DangSpider(scrapy.Spider):name = "dang"allowed_domains = ["category.dangdang.com"]start_urls = ["http://category.dangdang.com/cp01.01.07.00.00.00.html"]def parse(self, response):# 所有的seletor的对象,都可以再次调用xpath方法li_list = response.xpath('//div[@id="search_nature_rg"]//li')for li in li_list:# 获取图片src = li.xpath('.//img/@data-original').extract_first()# 第一张图片和其他图片的标签的属性不一样# 第一张图片的src是可以使用的,其他图片的地址在data-original里if src:src = srcelse:src = li.xpath('.//img/@src').extract_first()# 获取名字name = li.xpath('.//img/@alt').extract_first()# 获取价格price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()book = ScrapyDangdang39Item(src=src, name=name, price=price)# 获取一个book就将book传递给pipelinesyield book
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass ScrapyDangdang39Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 要下载的数据都有什么# 图片src = scrapy.Field()# 名字name = scrapy.Field()# 价格price = scrapy.Field()
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter# 如果想使用管道,就必须在settings中开启管道
class ScrapyDangdang39Pipeline:# 方法1# 在爬虫文件执行前执行的一个方法def open_spider(self, spider):self.fp = open('book.json', 'w', encoding='utf-8')def process_item(self, item, spider):# item就是yield后面的book对象# 这种模式不推荐# with open('book.json', 'a', encoding='utf-8')as fp:# fp.write(str(item))self.fp.write(str(item))return item# 在爬虫文件执行完后执行的一个方法def close_spider(self, spider):self.fp.close()
相关文章:
Python爬虫——scrapy_当当网图书管道封装
创建爬虫项目 srcapy startproject scrapy_dangdang进入到spider文件里创建爬虫文件(这里爬取的是青春文学,仙侠玄幻分类) srcapy genspider dang http://category.dangdang.com/cp01.01.07.00.00.00.html获取图片、名字和价格 # 所有的se…...
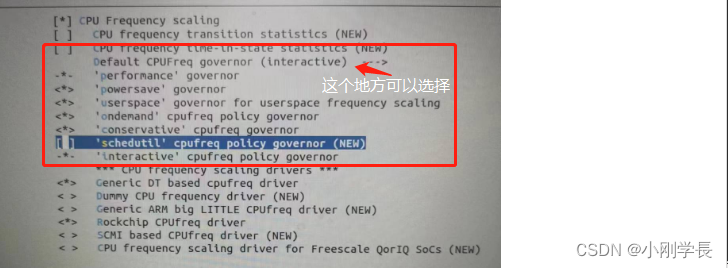
Linux下如何修改CPU 电源工作模式
最近处理一起历史遗留问题,感觉很爽。 现象: 背景:设备采用ARM,即rk3568处理器,采用Linux系统;主要用于视觉后端处理 现象:当软件运行一段时间,大概1个小时(也不是很固定…...
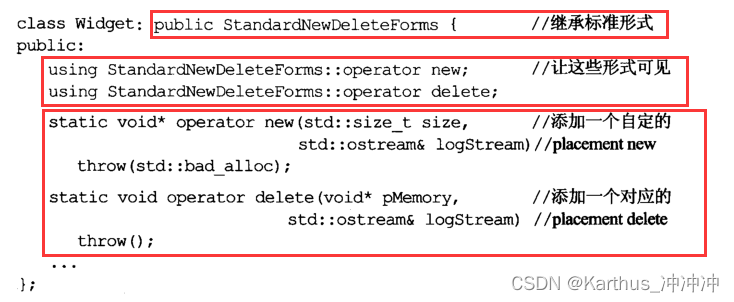
Effective C++学习笔记(8)
目录 条款49:了解new-handler的行为条款50:了解new和delete的合理替换时机条款51:编写new和delete时需固守常规条款52:写了placement new也要写placement delete条款53:不要轻忽编译器的警告条款54:让自己熟…...
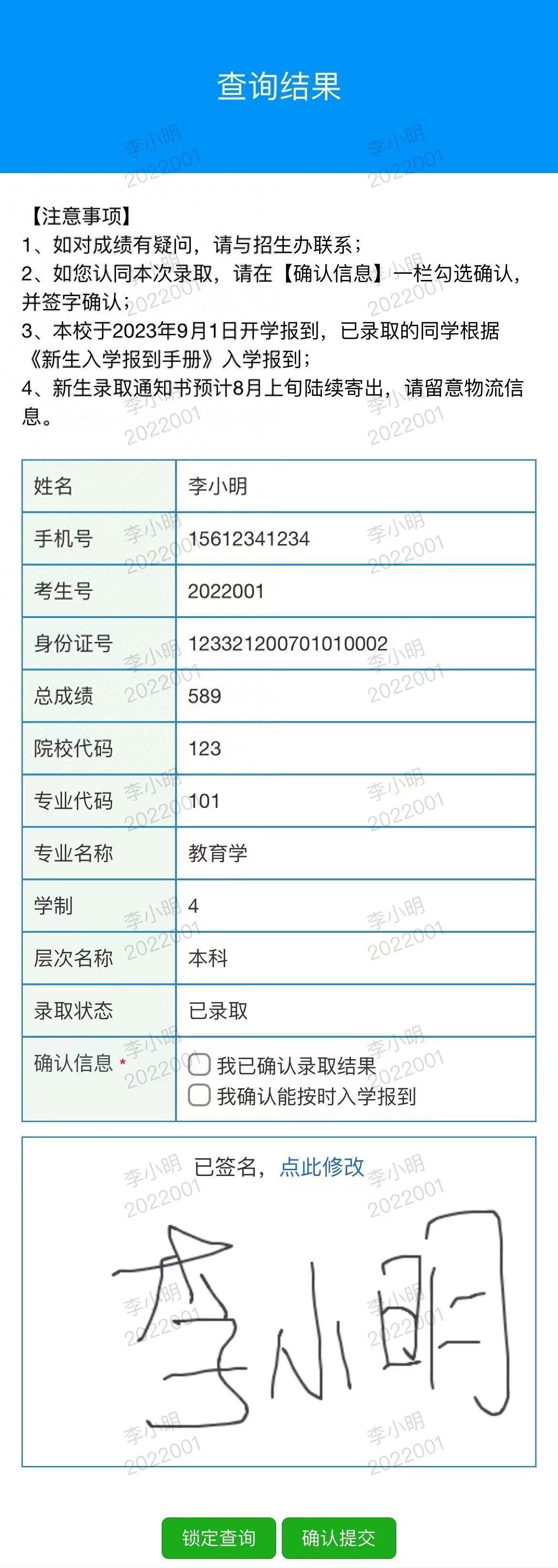
学校如何公布录取情况表?这个不用技术的方法,小白老师都能轻松制作
作为一名教师,我深切了解学生和家长们对录取情况的关注和重视。为了满足他们的需求,我们学校一直致力于改进公布录取情况的方式和效果。在本篇文章中,我将向您介绍我们学校独特的录取查询系统,并分享我们选择这种方式的原因。 我…...

Chart GPT免费可用地址共享资源
GPT4.0: https://gpt4e.ninvfeng.xyz github:https://github.com/ninvfeng/chatgpt4 WeUseAi:https://chatb.weuseai.pro AI.LS:https://n7.gpt03.xyz ChatX (iOS/macOS应用):https://itunes.apple.com/app/id6446304087 ch…...
)
设计模式十八:中介者模式(Mediator Pattern)
在中介者模式中,多个对象之间不再直接相互通信,而是通过一个中介者对象进行通信。这可以减少对象之间的依赖关系,使系统更加模块化。中介者模式适用于当对象之间的通信逻辑变得复杂,导致代码难以维护和理解时。 中介者模式使用场…...

神经网络基础-神经网络补充概念-12-向量化逻辑回归的梯度输出
代码实现 import numpy as npdef sigmoid(z):return 1 / (1 np.exp(-z))def compute_loss(X, y, theta):m len(y)h sigmoid(X.dot(theta))loss (-1/m) * np.sum(y * np.log(h) (1 - y) * np.log(1 - h))return lossdef compute_gradient(X, y, theta):m len(y)h sigmoi…...

2023-08-16力扣每日一题
链接: 2682. 找出转圈游戏输家 题意: 环形1到n,从1开始,每次移动 第i次*k ,当移动到出现过的序号时停下, 求没移动到的数字 解: 简单模拟题,我也以为有数学做法,可…...

耗资170亿美元?三星电子在得克萨斯州建设新的半导体工厂
据报道,三星电子在得克萨斯州泰勒市建设的新的半导体工厂预计将于2024年下半年投入运营。这座工厂将成为三星电子在美国的第二座芯片代工厂,与位于得克萨斯州奥斯汀市的第一座工厂相距不远。 此次投资将耗资约170亿美元,显示了三星电子在半导…...
)
黑马项目一阶段面试58题 Web14题(一)
一、什么是AJAX 异步的JavaScript和XML。用来做前端和后端的异步请求的技术。 异步请求:只更新部分前端界面的请求,做到局部更新。 比如注册,提示用户名已存在而整个页面没有动 比如百度图片搜索美女,进度条越变越短ÿ…...
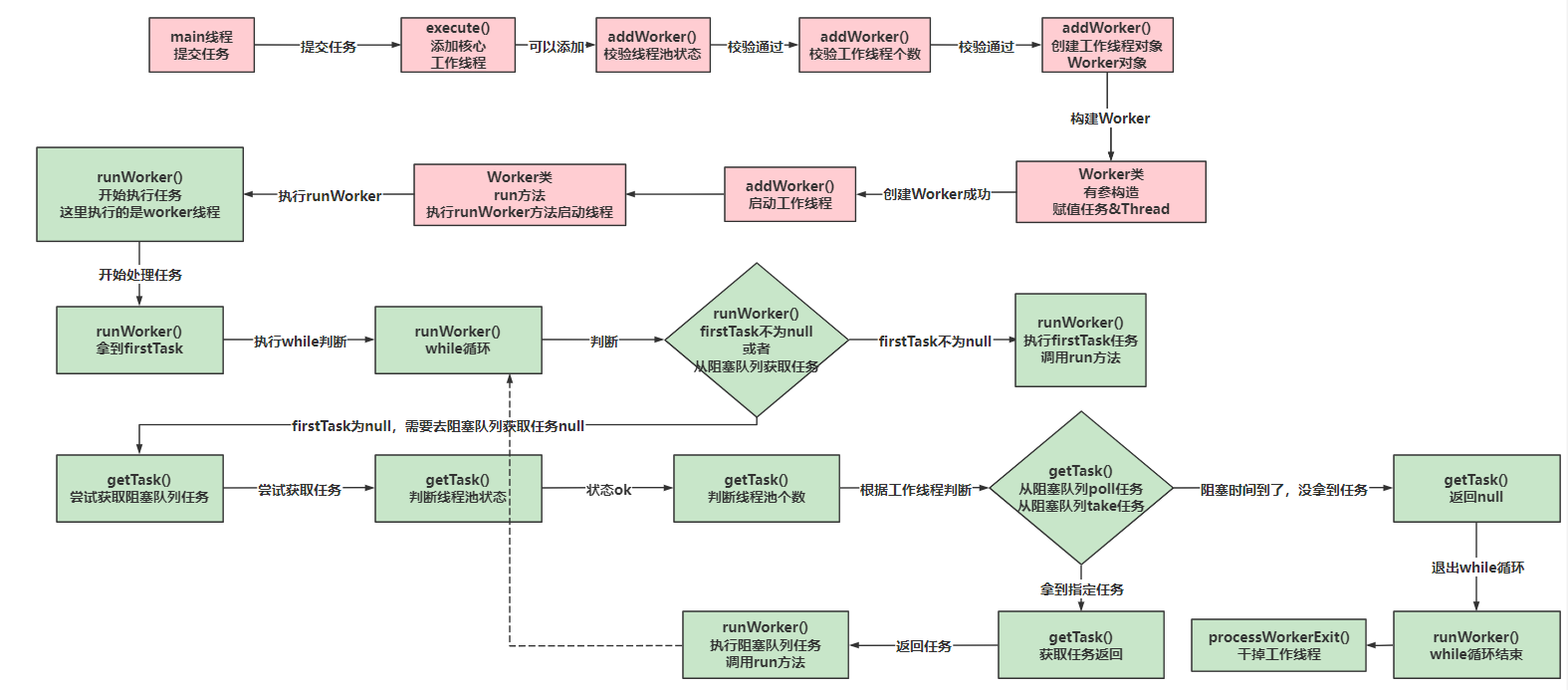
多线程与高并发--------线程池
线程池 一、什么是线程池 在开发中,为了提升效率的操作,我们需要将一些业务采用多线程的方式去执行。 比如有一个比较大的任务,可以将任务分成几块,分别交给几个线程去执行,最终做一个汇总就可以了。 比如做业务操…...

深度学习实战48-【未来的专家团队】基于AutoCompany模型的自动化企业概念设计与设想
大家好,我是微学AI,今天给大家介绍一下深度学习实战48-【未来的专家团队】基于AutoCompany模型的自动化企业概念设计与设想,文本将介绍AutoCompany模型的概念设计,涵盖了AI智能公司的各个角色,并结合了GPT-4接口来实现各个角色的功能,设置中央控制器,公司运作过程会生成…...

深入剖析:如何通过API优化云计算架构?快来看!
在当今数字化时代,云计算已经成为企业实现创新、提高效率和降低成本的核心策略之一。而在构建和管理云计算架构时,API(应用程序编程接口)的作用变得愈发重要。本文将深入探讨如何通过API优化云计算架构,实现更高效、灵…...

基于STM32设计的中药分装系统
一、设计需求 基于STM32设计的中药分装系统 【1】项目背景 中药文化是我国文化瑰宝之一,它具有疗效好、副作用小的优点,而且相对于西药,全天然的中药还具有标本兼治的特点,不仅可以用来治病,更可以对患者身体进行调理,所以格外受到当今一直追求生活质量的人们的追捧&quo…...

消息队列学习笔记
消息队列基础 适合消息队列解决的问题 异步处理:处理完关键步骤后直接返回结果,后续放入队列慢慢处理流量控制: 使用消息队列隔离网关和后端服务,以达到流量控制和保护后端服务的目的。能根据下游的处理能力自动调节流量&#x…...

贝锐蒲公英:助力企业打造稳定高效的智能安防监控网络
随着技术的快速发展和物联网的普及,企业面临着许多安全威胁和风险,如盗窃、入侵、信息泄露等,企业需要建立安防监控系统来保护其资产、员工和业务运营的安全。 然而,企业在搭建安防监控系统的过程中,可能会面临一些难…...

SASS 学习笔记
SASS 学习笔记 总共会写两个练手项目,成品在 https://goldenaarcher.com/scss-study 可以看到,代码在 https://github.com/GoldenaArcher/scss-study。 什么是 SASS SASS 是 CSS 预处理,它提供了变量(虽然现在 CSS 也提供了&am…...
Web菜鸟教程 - Springboot接入认证授权模块
网络安全的重要性不言而喻,如今早已不是以前随便弄个http请求就能爬到数据的时代,而作为一个架构师,网络安全必须在产品开发之初就考虑好。因为在产品开发的后期,一方面是客户增多,压力变大,可供利用的时间…...
【深入理解ES6】块级作用域绑定
1. var声明及变量提升机制 提升(Hoisting)机制:通过关键字var声明的变量,都会被当成在当前作用域顶部生命的变量。 function getValue(condition){if(condition){var value "blue";console.log(value);}else{// 此处…...

使用fake为数据库生成随机数据
参考https://cloud.tencent.com/developer/article/1663417 增加了自己的代码,使得只需要构建内容映射字典,然后根据字典就可以直接将数据插入到数据库中 from faker import Faker import pandas as pd from urllib import parse # from pymongo import…...

别再死记硬背真值表了!用Verilog手搓半减器/全减器,从波形图反推逻辑门设计
从波形图反推逻辑门:Verilog减法器的逆向工程实践 数字电路初学者常陷入"真值表→逻辑表达式→电路实现"的传统学习路径,却难以理解信号流动的本质。本文将以波形图逆向分析为核心,带您用Verilog实现半减器与全减器,掌握…...

闪电网络水龙头与MCP钱包:构建微支付应用的开发实践
1. 项目概述:闪电网络水龙头与MCP钱包的融合最近在捣鼓闪电网络相关的开源项目时,发现了一个挺有意思的仓库:lightningfaucet/lightning-wallet-mcp。光看这个名字,就包含了几个关键元素:“闪电网络”、“水龙头”、“…...

在 Simulink 中搭建 DSOGI 模块和双 PI 环
目录 📐 第一步:理解对称分量法与正负序分离原理 🛠️ 第二步:Simulink 建模核心步骤 📊 第三步:仿真结果与波形分析 在 Simulink 中搭建 DSOGI 模块和双 PI 环 在上一节我们实现了理想电网下的无功补偿…...

Linux高手必备:从安全操作到高效运维的12个核心习惯
1. 为什么说“习惯”是Linux高手的护城河刚接触Linux那会儿,我总觉得高手和菜鸟的区别在于记住了多少命令、会不会写复杂的脚本。后来踩了无数坑、熬了无数夜、甚至搞崩过几次生产环境后,我才恍然大悟:真正的分水岭,其实藏在那些日…...

Taotoken的Token Plan套餐如何帮助个人开发者更可控地规划AI支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的Token Plan套餐如何帮助个人开发者更可控地规划AI支出 对于个人开发者或小型项目团队而言,大模型API的调用成…...
)
一文读懂大模型Agent工作流:小白也能学会的AI新玩法(收藏版)
本文深入解析了AI Agent和Agent工作流的核心概念,阐述了AI代理如何通过工作流实现复杂任务的自动化。文章详细介绍了AI Agent的组成部分,包括推理、工具和记忆,并解释了Agent工作流的组成要素和不同模式。此外,还探讨了Agent工作流…...

Linux发布前检查实战指南
Linux发布前检查实战指南 本文面向具备一定 Linux 基础的技术人员,围绕发布前检查展开,重点讨论依赖确认、容量检查和回滚准备。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起&a…...

CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战
CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战 车牌识别系统中,数据预处理的质量直接影响模型性能。CCPD作为目前最全面的中文车牌数据集,其四点标注特性为透视变换提供了基础,但也暗藏诸多陷阱。本文将手把手带您穿…...

终极指南:Windows平台APK安装器如何让安卓应用无缝运行
终极指南:Windows平台APK安装器如何让安卓应用无缝运行 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在Windows电脑上运行安卓应用曾经是一个技术难题&am…...

如何快速解密网易云NCM文件:终极免费转换工具指南
如何快速解密网易云NCM文件:终极免费转换工具指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲,…...