使用fake为数据库生成随机数据
参考https://cloud.tencent.com/developer/article/1663417
增加了自己的代码,使得只需要构建内容映射字典,然后根据字典就可以直接将数据插入到数据库中
from faker import Faker
import pandas as pd
from urllib import parse
# from pymongo import MongoClient
import pymysql
import random
import numpy as np
import traceback
import sysfake = Faker('zh_CN')def yes_or_no():return np.random.choice([0,1]) def money():return round(random.uniform(10,10000),4)# 定义fakedic,后续的所有数据都基于这个规则来生成和新建
fake_dic = {"iana_id":fake.iana_id, # 唯一id"date_time":fake.date_time, # 时间"yes_or_no": yes_or_no, # 1 或者 0"name":fake.name, # 名字"text":fake.text, # 随机文本"money":money, # 钱(10~10000)"class":fake.ipv4_network_class # 类别
}lc_bill_dic = {
"id": "iana_id", # 唯一id"create_by":"name",# 名字"create_time":"date_time",# 创建日期"deteled":"yes_or_no", # 状态
"class": "class", # 类别
"rent": "money",# 日租金
"text": "text",# 备注}def get_df(data_dic, need_nums):# 根据传入参数只做数据# need_nums = 10data_list = []for i in range(need_nums):data_row = {}for key, value in data_dic.items():data_row[key] = fake_dic[value]()if isinstance(data_row[key], str):data_row[key] = data_row[key].replace("\n","")[:64]data_list.append(data_row)return pd.DataFrame(data_list)# 插入数据库
def deal_mysql(table_name, data_df):# 打开数据库连接db = pymysql.connect(host="localhost", user="root", password="root", database="MyTest")# 使用cursor()方法获取操作游标cursor = db.cursor()# SQL 插入语句## 拼接sql插入语句columns = list(data_df.columns)sql_columns = f""" `{"`,`".join(columns)}` """sql_placeholder = ",".join(["'%s'"] * len(columns))for each in data_df.to_dict("index").values():sql_data = tuple([each[column] for column in columns])# print(sql_placeholder)# print(sql_data)sql = f"insert into {table_name} ({sql_columns}) value ({sql_placeholder})"%sql_dataa = sql# print(sql)try:# 执行sql语句cursor.execute(sql)# 执行sql语句db.commit()print("insert ok")except:# 发生错误时回滚exc_type, exc_value, exc_traceback = sys.exc_info()print("exc_type:",exc_type)print("exc_value:",exc_value)print("exc_traceback:",exc_traceback)db.rollback()# 关闭数据库连接cursor.close()deal_mysql("bill", get_df(lc_bill_dic, 20))相关文章:

使用fake为数据库生成随机数据
参考https://cloud.tencent.com/developer/article/1663417 增加了自己的代码,使得只需要构建内容映射字典,然后根据字典就可以直接将数据插入到数据库中 from faker import Faker import pandas as pd from urllib import parse # from pymongo import…...

树结构转List
使用LinkedList效率更高 1、单个顶级节点 public static List<CmsStudentOutline> getTreeList(CmsStudentOutline root) {List<CmsStudentOutline> list new ArrayList<>();Queue<CmsStudentOutline> queue new LinkedList<>();if (root nu…...

Android复习(Android基础-四大组件)——Broadcast
1. 广播分类 广播的发送方式:标准广播、有序广播、粘性广播广播的类型:系统广播、本地广播 1.1 标准广播 完全异步,无序的广播发出后,所有的广播接收器几乎都会在同一时间收到消息。(异步)但是消息无法截…...

Ubuntu下mysql8开启远程连接
环境 mysql8ubuntu22.04 更改配置文件 vim /etc/mysql/mysql.conf.d/mysqld.conf找到 bind-address 127.0.0.1 mysqlx-bind-address 127.0.0.1 把这两行注释掉,保存退出即可 修改mysql配置 登录mysql创建一个远程连接账户,名字任意,密码任意,用户名…...
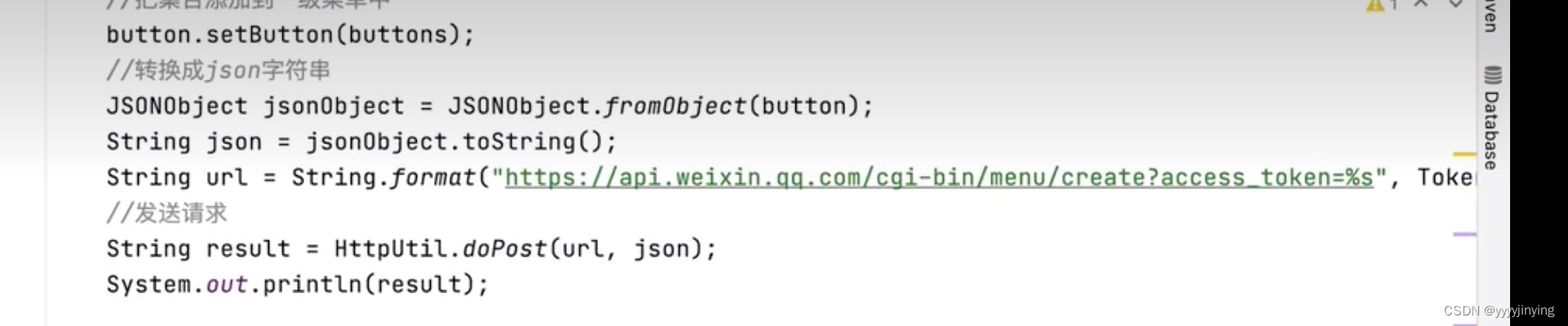
java对象和json类型转换
fastjson参考 参考:http://doc.yaojieyun.com/www.runoob.com/w3cnote/java-json-instro.html 参考: http://doc.yaojieyun.com/www.runoob.com/w3cnote/fastjson-intro.html 序列化:JSON.toJSONString(person)将Java 对象转换为 JSON 字符串…...
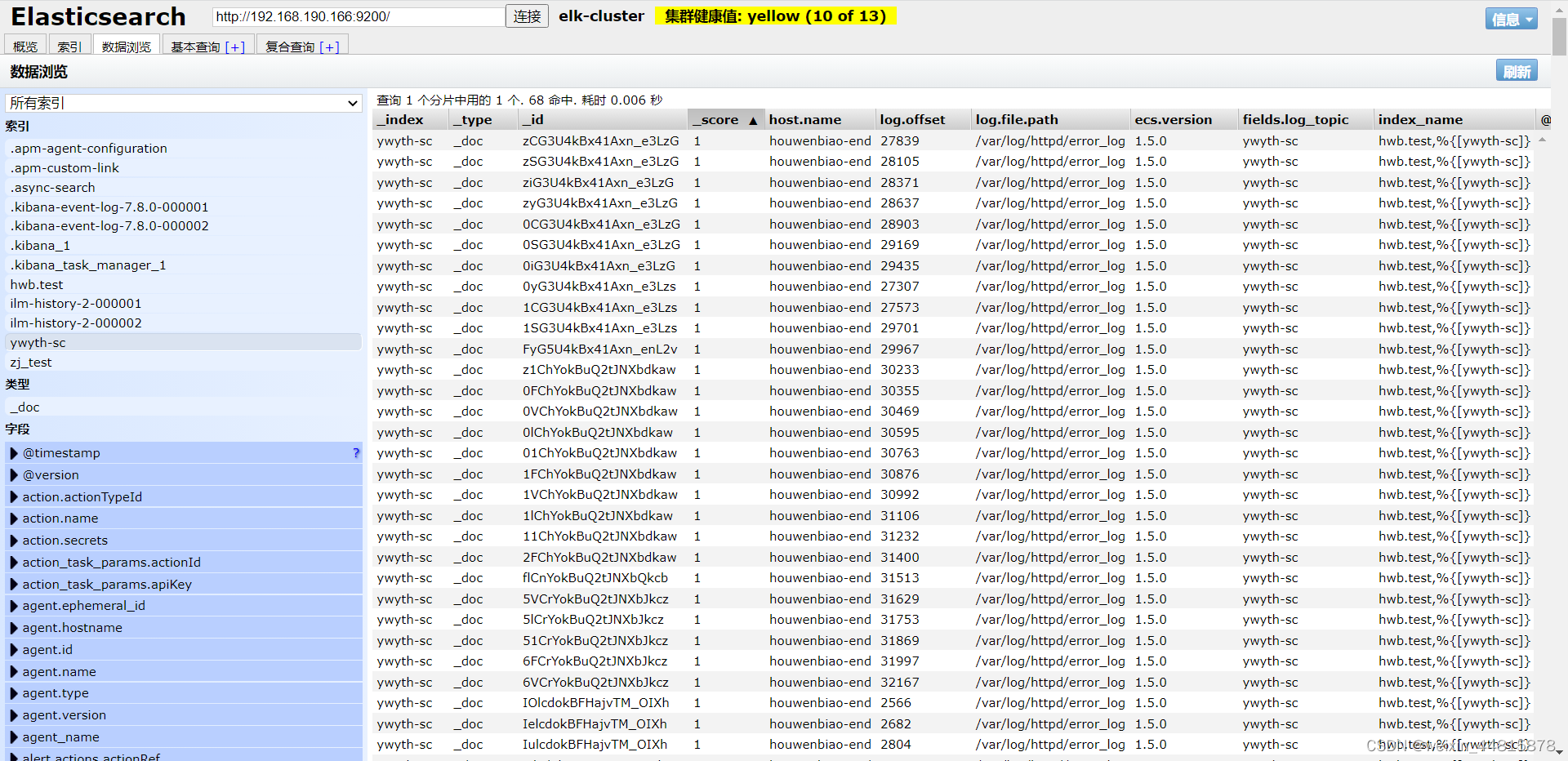
elasticsearch-head 插件
1、elastic 插件说明 **Head** 是第三方提供的一款很优秀的插件,集监控、查询、配置一体的web功能系统,可以在系统中进行创建、删除索引 、文档。以及查询、配置索引等功能,深受广大开发者的喜爱 **Kopf** 是另一个第三方提供的一款很优秀…...

Neo4j之FOREACH基础
在 Neo4j 中,FOREACH 语句用于在查询中对一组元素执行某些操作,通常是在创建或更新节点关系时。它常常与 CREATE 或 SET 等操作结合使用。 创建多个关系: MATCH (p:Person), (m:Movie) WHERE p.name Alice AND m.title The Matrix FOREAC…...
【SpringBoot】| 接口架构风格—RESTful
目录 一:接口架构风格—RESTful 1. 认识RESTful 2. RESTful 的注解 一:接口架构风格—RESTful 1. 认识RESTful (1)接口 ①接口: API(Application Programming Interface,应用程序接口&…...
——CentOS7定时任务)
CentOS系统环境搭建(十)——CentOS7定时任务
centos系统环境搭建专栏🔗点击跳转 使用CentOS系统环境搭建(九)——centos系统下使用docker部署项目的项目做定时任务。 CentOS7定时任务 查看现有的定时任务 crontab -l编辑定时任务 crontab -e示例 每天凌晨两点运行脚本 清理内存 0 2 *…...
如何在安卓设备上安装并使用 ONLYOFFICE 文档
您可以使用文档安卓版应用,在移动设备上访问存在您 ONLYOFFICE 帐号中的文件。阅读本文,了解如何操作。 什么是 ONLYOFFICE 文档安卓版 适用于 Android 系统的 ONLYOFFICE 文档是一款全面的办公工具,您可以使用它,查看、创建、编…...
【制作npm包1】申请npm账号、认识个人包和组织包
概述 在开发当中经常有一种现象,重复代码写了N多遍,再次写同样的逻辑就再次翻查以前的代码逻辑。效率低下且容易出错,封装一个npm包的价值也不仅仅是给别人用,封装一套属于自己或者本部门的npm包也是相当有必要。 也许经常看到一…...
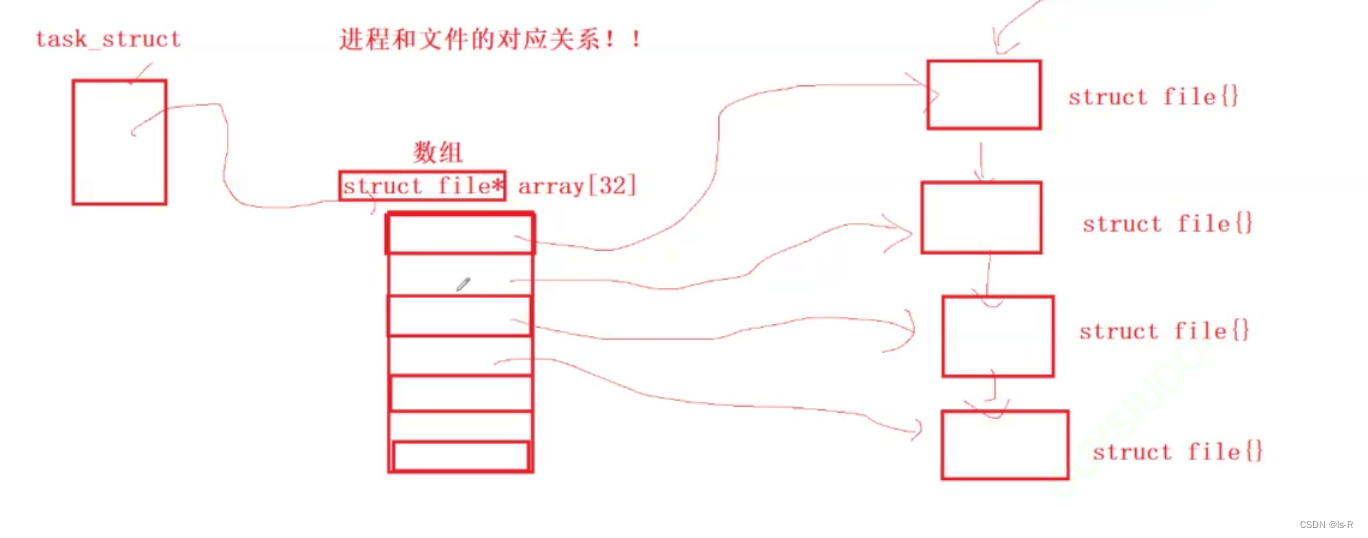
linux学习(文件描述符)[11]
一切皆文件 用代码创建的文件,默认路径在可执行文件同级目录下(本质是进程通过系统接口创建的) 文件宏 在Linux下,有一些与文件操作相关的宏可以用于处理文件描述符和文件权限。以下是一些常用的文件宏: STDIN_FIL…...

影响力再度提升,Smartbi多次蝉联Gartner、IDC等权威认可
近期,思迈特软件捷报频传,Smartbi凭借技术创新实力和产品能力,成功入选Gartner中国增强数据分析代表厂商及自助分析代表厂商,同时,连续三年蝉联“IDC中国FinTech 50”榜单。 Part.1 再次被Gartner提名 Smartbi深度融…...
【动态map】牛客挑战赛67 B
登录—专业IT笔试面试备考平台_牛客网 题意: 思路: 考虑动态的map 可以先定义一个状态,然后用map统计前缀这个状态的出现次数 在这里,定义{a,b}为cnt1 - cnt0和cnt2 - cnt0 当cnt0 和 cnt1都和cnt2相同时,统计贡献…...
)
mysql(2)
1.ACID 关系型数据库都有ACID特性 原子性(Atomicity) : 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;一致性(Consistency):…...

介绍 Apache Spark 的基本概念和在大数据分析中的应用
Apache Spark是一种基于内存计算的大数据处理框架,它支持分布式计算,并且能够处理比传统处理框架更大量的数据。以下是Apache Spark的一些基本概念和在大数据分析中的应用: RDD (Resilient Distributed Dataset):RDD是Spark的核心…...
Vue CLI创建Vue项目详细步骤
🚀 一、安装Node环境(建议使用LTS版本) 在开始之前,请确保您已经安装了Node.js环境。您可以从Node.js官方网站下载LTS版本,以确保稳定性和兼容性。 中文官网下载 确认已安装 Node.js。可以在终端中运行 node -v 命令…...

机器学习算法之-逻辑回归(2)
为什么需要逻辑回归 拟合效果太好 特征与标签之间的线性关系极强的数据,比如金融领域中的 信用卡欺诈,评分卡制作,电商中的营销预测等等相关的数据,都是逻辑回归的强项。虽然现在有了梯度提升树GDBT,比逻辑回归效果更…...

【业务功能篇65】maven加速 配置settings.xml文件 镜像
maven加速 添加阿里镜像仓 <?xml version"1.0" encoding"UTF-8"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additi…...
题目:售货员的难题(状压dp)
售货员的难题 题目描述输入输出格式输入格式:输出格式: 输入输出样例输入样例#1:输出样例#1: 思路AC代码: 题目描述 某乡有n个村庄( 1 < n < 16 ),有一个售货员,他要到各个村庄去售货&am…...

Visual Studio Code搭建c语言编译环境下载c/c++ Runner插件编译报错问题
安装版本默认是最新插件。下载如果无法编译就换版本。最后换到1.5.5版本就编译成功了。耗时2小时解决无法编译报错。process_begin: CreateProcess(NULL, ./build\Debug/outDebug "", ...) failed. make (e2): 系统找不到指定的文件。...

3步完成B站缓存视频转换:m4s转MP4的终极免费解决方案
3步完成B站缓存视频转换:m4s转MP4的终极免费解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站视频下架而痛心不…...

从碎片化到知识体系:微信读书笔记助手如何重塑你的数字阅读体验
从碎片化到知识体系:微信读书笔记助手如何重塑你的数字阅读体验 【免费下载链接】wereader 一个浏览器扩展:主要用于微信读书做笔记,对常使用 Markdown 做笔记的读者比较有帮助。 项目地址: https://gitcode.com/gh_mirrors/wer/wereader …...

Flask核心进阶:路由、模板与静态文件实战
在掌握Flask入门知识后,想要开发出更具实用性和美观度的Web应用,就需要深入学习其核心进阶功能,其中路由、模板与静态文件是最基础也是最常用的三个模块,三者协同工作,构成了Flask Web应用的前端展示与请求分发体系。路…...

终极免费离线OCR解决方案:Umi-OCR完整使用指南
终极免费离线OCR解决方案:Umi-OCR完整使用指南 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 …...

WandEnhancer技术解密:如何通过本地化增强重新定义游戏修改体验
WandEnhancer技术解密:如何通过本地化增强重新定义游戏修改体验 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否曾经面对游戏修改工具…...

防火门安装与验收要点|闭门器、密封条、顺序器缺一不可
防火门安装与验收要点一、必备配件(缺一不可)闭门器:自动关门,火灾常态闭合防火密封条:遇火膨胀,隔烟阻火顺序器:双扇门专用,保证先后闭合二、安装要点门框墙体嵌实牢固,…...

Go语言静态站点生成器Zeuxis:极简架构与高性能构建实践
1. 项目概述:一个轻量级、高性能的静态站点生成器最近在折腾个人博客和文档站点,发现市面上的静态站点生成器虽然多,但要么配置复杂、学习曲线陡峭,要么过于臃肿,启动和构建速度慢得让人抓狂。直到我遇到了bnomei/zeux…...

Unity区域加载系统:实现开放世界无缝加载与内存优化
1. 项目概述:一个高效、可扩展的Unity区域加载系统 最近在做一个开放世界风格的项目,场景大了之后,加载卡顿和内存管理就成了老大难问题。传统的Unity场景加载,要么一股脑全塞进内存,要么就得自己写一堆脚本来手动控制…...

深度解析VS Code Live Server:高效前端开发实时预览配置秘籍
深度解析VS Code Live Server:高效前端开发实时预览配置秘籍 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-live-serv…...