linux 的swap、swappiness及kswapd原理【转+自己理解】
本文讨论的 swap基于Linux4.4内核代码 。Linux内存管理是一套非常复杂的系统,而swap只是其中一个很小的处理逻辑。
希望本文能让读者了解Linux对swap的使用大概是什么样子。阅读完本文,应该可以帮你解决以下问题:
- swap到底是干嘛的?
- swappiness到底是用来调节什么的?
- kswapd什么时候会进行swap操作?
- 什么是内存水位标记?
- swap分区的优先级(priority)有啥用?
1、什么是SWAP,到底是干嘛的?
我们一般所说的swap,指的是一个交换分区或文件。在Linux上可以使用swapon -s命令查看当前系统上正在使用的交换空间有哪些,以及相关信息:
[root@wsip-70-182-133-152 home]# swapon -s
Filename Type Size Used Priority
/dev/dm-1 partition 4194300 0 -2
从功能上讲,交换分区主要是在内存不够用的时候,将部分内存上的数据交换到swap空间上,以便让系统不会因内存不够用而导致oom或者更致命的情况出现。
所以,当内存使用存在压力,开始触发内存回收的行为时,就可能会使用swap空间。
内核对swap的使用实际上是跟内存回收行为紧密结合的。那么关于内存回收和swap的关系,我们需要思考以下几个问题:
- 为什么要进行内存回收?
- 哪些内存可能会被回收呢?
- 回收的过程中什么时候会进行交换呢?
- 具体怎么交换?
下面我们就从这些问题出发,一个一个进行分析。
为什么要进行内存回收?
内核之所以要进行内存回收,主要原因有两个:
- 内核需要为任何时刻突发到来的内存申请提供足够的内存。所以一般情况下保证有足够的free空间对于内核来说是必要的。 另外,Linux内核使用cache的策略虽然是不用白不用,内核会使用内存中的page cache对部分文件进行缓存,以便提升文件的读写效率。 所以内核有必要设计一个周期性回收内存的机制,以便cache的使用和其他相关内存的使用不至于让系统的剩余内存长期处于很少的状态。
- 当真的有大于空闲内存的申请到来的时候,会触发强制内存回收。 所以,内核在应对这两类回收的需求下,分别实现了两种不同的机制:
所以,内核在应对这两类回收的需求下,分别实现了两种不同的机制:
- 一个是使用 kswapd进程对内存进行周期检查 ,以保证平常状态下剩余内存尽可能够用。
- 另一个是 直接内存回收(directpagereclaim) ,就是当内存分配时没有空闲内存可以满足要求时,触发直接内存回收。
这两种内存回收的触发路径不同:
- 一个是使用 kswapd进程对内存进行周期检查 ,以保证平常状态下剩余内存尽可能够用。
- 另一个是 直接内存回收(directpagereclaim) ,就是当内存分配时没有空闲内存可以满足要求时,触发直接内存回收。
这两种内存回收的触发路径不同:
- 一个是由内核进程kswapd直接调用内存回收的逻辑进行内存回收; 参见mm/vmscan.c中的kswapd()主逻辑
- 另一个是内存申请的时候进入slow path的内存申请逻辑进行回收。 参见内核代码中的mm/page_alloc.c中的__alloc_pages_slowpath方法
这两个方法中实际进行内存回收的过程殊途同归,最终都是 调用shrink_zone() 方法进行针对每个zone的内存页缩减。
这个方法中会再调用shrink_lruvec()这个方法对每个组织页的链表进程检查。找到这个线索之后,我们就可以清晰的看到内存回收操作究竟针对的page有哪些了。
这些链表主要定义在mm/vmscan.c一个enum中:
根据这个enum可以看到,内存回收主要需要进行扫描的链表有如下4个:
- anon的inactive
- anon的active
- file的inactive
- file的active
就是说,内存回收操作主要针对的就是内存中的文件页(file cache)和匿名页。
关于活跃(active)还是不活跃(inactive)的判断内核会使用lru算法进行处理并进行标记,我们这里不详细解释这个过程。
整个扫描的过程分几个循环:
- 首先扫描每个zone上的cgroup组;
- 然后再以cgroup的内存为单元进行page链表的扫描;
- 内核会先扫描anon的active链表,将不频繁的放进inactive链表中,然后扫描inactive链表,将里面活跃的移回active中;
- 进行swap的时候,先对inactive的页进行换出;
- 如果是file的文件映射page页,则判断其是否为脏数据,如果是脏数据就写回,不是脏数据可以直接释放。
这样看来, 内存回收这个行为会对两种内存的使用进行回收:
- 一种是anon的匿名页内存,主要回收手段是swap;
- 另一种是file-backed的文件映射页,主要的释放手段是写回和清空。
因为针对filebased的内存,没必要进行交换,其数据原本就在硬盘上,回收这部分内存只要在有脏数据时写回,并清空内存就可以了,以后有需要再从对应的文件读回来。
内存对匿名页和文件缓存一共用了 四条链表 进行组织,回收过程主要是针对这四条链表进行扫描和操作。
2、swappiness到底是用来调节什么的?
很多人应该都知道 /proc/sys/vm/swappiness 这个文件,是个可以用来调整跟swap相关的参数。这个文件的默认值是60,可以的取值范围是0-100。
这很容易给大家一个暗示:我是个百分比哦!
那么这个文件具体到底代表什么意思呢?我们先来看一下说明
======swappinessThis control is used to define how aggressive the kernel will swap memory pages. Higher values will increase agressiveness, lower values decrease the amount of swap.A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.The default value is 60.======这个文件的值用来定义内核使用swap的积极程度:
- 值越高,内核就会越积极的使用swap;
- 值越低,就会降低对swap的使用积极性。
- 如果这个值为0,那么内存在free和file-backed使用的页面总量小于高水位标记(high water mark)之前,不会发生交换。
在这里我们可以理解file-backed这个词的含义了,实际上就是上文所说的文件映射页的大小。
那么这个swappiness到底起到了什么作用呢?
我们换个思路考虑这个事情。假设让我们设计一个内存回收机制,要去考虑将一部分内存写到swap分区上,将一部分file-backed的内存写回并清空,剩余部分内存出来,我们将怎么设计?
我想应该主要考虑这样几个问题:
- 如果回收内存可以有两种途径(匿名页交换和file缓存清空),那么我应该考虑在本次回收的时候,什么情况下多进行file写回,什么情况下应该多进行swap交换。说白了就是平衡两种回收手段的使用,以达到最优。
- 如果符合交换条件的内存较长,是不是可以不用全部交换出去?比如可以交换的内存有100M,但是目前只需要50M内存,实际只要交换50M就可以了,不用把能交换的都交换出去。
分析代码会发现,Linux内核对这部分逻辑的实现代码在 get_scan_count() 这个方法中,这个方法被 shrink_lruvec() 调用。
get_sacn_count()就是处理上述逻辑的,swappiness是它所需要的一个参数,这个参数实际上是指导内核在清空内存的时候,是更倾向于清空file-backed内存还是更倾向于进行匿名页的交换的。
当然,这只是个倾向性,是指在两个都够用的情况下,更愿意用哪个,如果不够用了,那么该交换还是要交换。
简单看一下get_sacn_count()函数的处理部分代码,其中关于swappiness的第一个处理是:
这里注释的很清楚:
- 如果swappiness设置为100,那么匿名页和文件将用同样的优先级进行回收。 很明显,使用清空文件的方式将有利于减轻内存回收时可能造成的IO压力。 因为如果file-backed中的数据不是脏数据的话,那么可以不用写回,这样就没有IO发生,而一旦进行交换,就一定会造成IO。 所以系统默认将swappiness的值设置为60,这样回收内存时,对file-backed的文件cache内存的清空比例会更大,内核将会更倾向于进行缓存清空而不是交换。
- 这里的swappiness值如果是60,那么是不是说内核回收的时候,会按照60:140的比例去做相应的swap和清空file-backed的空间呢?并不是。 在做这个比例计算的时候,内核还要参考当前内存使用的其他信息。对这里具体是怎么处理感兴趣的人,可以自己详细看get_sacn_count()的实现,本文就不多解释了。 我们在此要明确的概念是: swappiness的值是用来控制内存回收时,回收的匿名页更多一些还是回收的file cache更多一些 。
- swappiness设置为0的话,是不是内核就根本不会进行swap了呢?这个答案也是否定的。 首先是内存真的不够用的时候,该swap的话还是要swap。 其次在内核中还有一个逻辑会导致直接使用swap, 内核代码 是这样处理的:?
3、kswapd什么时候会进行swap操作?
我们回到kswapd周期检查和直接内存回收的两种内存回收机制。
直接内存回收比较好理解,当申请的内存大于剩余内存的时候,就会触发直接回收。
那么kswapd进程在周期检查的时候触发回收的条件是什么呢?
还是从设计角度来看,kswapd进程要周期对内存进行检测,达到一定阈值的时候开始进行内存回收。
这个所谓的阈值可以理解为内存目前的使用压力,就是说,虽然我们还有剩余内存,但是当剩余内存比较小的时候,就是内存压力较大的时候,就应该开始试图回收些内存了,这样才能保证系统尽可能的有足够的内存给突发的内存申请所使用。
4、什么是内存水位标记?(watermark)
那么如何描述内存使用的压力呢?
Linux内核使用水位标记(watermark)的概念来描述这个压力情况。
- Linux为内存的使用设置了三种内存水位标记:high、low、min。他们 所标记的含义分别为:
- 剩余内存在high以上表示内存剩余较多,目前内存使用压力不大;
- high-low的范围表示目前剩余内存存在一定压力;
- low-min表示内存开始有较大使用压力,剩余内存不多了;
- min是最小的水位标记,当剩余内存达到这个状态时,就说明内存面临很大压力。
- 小于min这部分内存,内核是保留给特定情况下使用的,一般不会分配。
内存回收行为就是基于剩余内存的水位标记进行决策的:
当系统剩余内存低于watermark[low]的时候,内核的kswapd开始起作用,进行内存回收。直到剩余内存达到watermark[high]的时候停止。
如果内存消耗导致剩余内存达到了或超过了watermark[min]时,就会触发直接回收(direct reclaim)。
明白了水位标记的概念之后,zonefile + zonefree <= high_wmark_pages(zone)这个公式就能理解了。
这里的zonefile相当于内存中文件映射的总量,zonefree相当于剩余内存的总量。
内核一般认为,如果zonefile还有的话,就可以尽量通过清空文件缓存获得部分内存,而不必只使用swap方式对anon的内存进行交换。
整个判断的概念是说,在全局回收的状态下(有global_reclaim(sc)标记),如果当前的文件映射内存总量+剩余内存总量的值评估小于等于watermark[high]标记的时候,就可以进行直接swap了。
这样是为了防止进入cache陷阱,具体描述可以见代码注释。
这个判断对系统的影响是, swappiness设置为0时,有剩余内存的情况下也可能发生交换。
那么watermark相关值是如何计算的呢?
所有的内存watermark标记都是根据当前内存总大小和一个可调参数进行运算得来的,这个参数是: /proc/sys/vm/min_free_kbytes
- 首先这个参数本身决定了系统中每个zone的watermark[min]的值大小。
- 然后内核根据min的大小并参考每个zone的内存大小分别算出每个zone的low水位和high水位值。
想了解具体逻辑可以参见源代码目录下的该文件:
mm/page_alloc.c
在系统中可以从/proc/zoneinfo文件中查看当前系统的相关的信息和使用情况。
我们会发现以上内存管理的相关逻辑都是以zone为单位的,这里zone的含义是指内存的分区管理。
Linux将内存分成多个区,主要有:
- 直接访问区(DMA)
- 一般区(Normal)
- 高端内存区(HighMemory)
内核对内存不同区域的访问因为硬件结构因素会有寻址和效率上的差别。如果在NUMA架构上,不同CPU所管理的内存也是不同的zone。
相关参数设置
- zone_reclaim_mode:
zone_reclaim_mode模式是在2.6版本后期开始加入内核的一种模式,可以用来管理当一个内存区域(zone)内部的内存耗尽时,是从其内部进行内存回收还是可以从其他zone进行回收的选项,我们可以通过 /proc/sys/vm/zone_reclaim_mode 文件对这个参数进行调整。
在申请内存时(内核的get_page_from_freelist()方法中),内核在当前zone内没有足够内存可用的情况下,会根据zone_reclaim_mode的设置来决策是从下一个zone找空闲内存回收还是在zone内部进行回收。这个值为0时表示可以从下一个zone找可用内存,非0表示在本地回收。
这个文件可以设置的值及其含义如下:
- echo 0 > /proc/sys/vm/zone_reclaim_mode:意味着关闭zone_reclaim模式,可以从其他zone或NUMA节点回收内存。
- echo 1 > /proc/sys/vm/zone_reclaim_mode:表示打开zone_reclaim模式,这样内存回收只会发生在本地节点内。
- echo 2 > /proc/sys/vm/zone_reclaim_mode:在本地回收内存时,可以将cache中的脏数据写回硬盘,以回收内存。
- echo 4 > /proc/sys/vm/zone_reclaim_mode:可以用swap方式回收内存。
不同的参数配置会在NUMA环境中对其他内存节点的内存使用产生不同的影响,大家可以根据自己的情况进行设置以优化你的应用。
默认情况下,zone_reclaim模式是关闭的。这在很多应用场景下可以提高效率,比如文件服务器,或者依赖内存中cache比较多的应用场景。
这样的场景对内存cache速度的依赖要高于进程进程本身对内存速度的依赖,所以我们宁可让内存从其他zone申请使用,也不愿意清本地cache。
如果确定应用场景是内存需求大于缓存,而且尽量要避免内存访问跨越NUMA节点造成的性能下降的话,则可以打开zone_reclaim模式。
此时页分配器会优先回收容易回收的可回收内存(主要是当前不用的page cache页),然后再回收其他内存。
打开本地回收模式的写回可能会引发其他内存节点上的大量的脏数据写回处理。如果一个内存zone已经满了,那么脏数据的写回也会导致进程处理速度收到影响,产生处理瓶颈。
这会降低某个内存节点相关的进程的性能,因为进程不再能够使用其他节点上的内存。但是会增加节点之间的隔离性,其他节点的相关进程运行将不会因为另一个节点上的内存回收导致性能下降。
除非针对本地节点的内存限制策略或者cpuset配置有变化,对swap的限制会有效约束交换只发生在本地内存节点所管理的区域上。
- min_unmapped_ratio:
这个参数只在NUMA架构的内核上生效。这个值表示NUMA上每个内存区域的pages总数的百分比。
在zone_reclaim_mode模式下,只有当相关区域的内存使用达到这个百分比,才会发生区域内存回收。
在zone_reclaim_mode设置为4的时候,内核会比较所有的file-backed和匿名映射页,包括swapcache占用的页以及tmpfs文件的总内存使用是否超过这个百分比。
其他设置的情况下,只比较基于一般文件的未映射页,不考虑其他相关页。
- page-cluster:
page-cluster是用来控制从swap空间换入数据的时候,一次连续读取的页数,这相当于对交换空间的预读。这里的连续是指在swap空间上的连续,而不是在内存地址上的连续。
因为swap空间一般是在硬盘上,对硬盘设备的连续读取将减少磁头的寻址,提高读取效率。
这个文件中设置的值是2的指数。就是说,如果设置为0,预读的swap页数是2的0次方,等于1页。如果设置为3,就是2的3次方,等于8页。
同时,设置为0也意味着关闭预读功能。文件默认值为3。我们可以根据我们的系统负载状态来设置预读的页数大小。
5、swap分区的优先级(priority)有啥用?
在使用多个swap分区或者文件的时候,还有一个优先级的概念(Priority)。
在swapon的时候,我们可以使用-p参数指定相关swap空间的优先级, 值越大优先级越高 ,可以指定的数字范围是-1到32767。
内核在使用swap空间的时候总是先使用优先级高的空间,后使用优先级低的。
当然如果把多个swap空间的优先级设置成一样的,那么两个swap空间将会以轮询方式并行进行使用。
如果两个swap放在两个不同的硬盘上,相同的优先级可以起到类似RAID0的效果,增大swap的读写效率。
另外,编程时使用mlock()也可以将指定的内存标记为不会换出,具体帮助可以参考man 2 mlock。
最后 关于swap的使用建议,针对不同负载状态的系统是不一样的。有时我们希望swap大一些,可以在内存不够用的时候不至于触发oom-killer导致某些关键进程被杀掉,比如数据库业务。
也有时候我们希望不要swap,因为当大量进程爆发增长导致内存爆掉之后,会因为swap导致IO跑死,整个系统都卡住,无法登录,无法处理。
这时候我们就希望不要swap,即使出现oom-killer也造成不了太大影响,但是不能允许服务器因为IO卡死像多米诺骨牌一样全部死机,而且无法登陆。跑cpu运算的无状态的apache就是类似这样的进程池架构的程序。
所以:
- swap到底怎么用?
- 要还是不要?
- 设置大还是小?
- 相关参数应该如何配置?
是要根据我们自己的生产环境的情况而定的。
阅读完本文后希望大家可以明白一些swap的深层次知识。
相关文章:

linux 的swap、swappiness及kswapd原理【转+自己理解】
本文讨论的 swap基于Linux4.4内核代码 。Linux内存管理是一套非常复杂的系统,而swap只是其中一个很小的处理逻辑。 希望本文能让读者了解Linux对swap的使用大概是什么样子。阅读完本文,应该可以帮你解决以下问题: swap到底是干嘛的…...

什么是Java中的适配器模式?
Java中的适配器模式(Adapter Pattern)是一种设计模式,它允许我们将一种类的接口转换成另一种类的接口,以便于使用。适配器模式通常用于在不兼容的接口之间提供一种过渡性的接口,从而使代码更加灵活和可维护。 在Java中…...

MYSQL线上无锁添加索引
在需求上线过程中,经常会往一个数据量比较大的数据表中的字段加索引,一张几百万数据的表,加个索引往往要几分钟起步。在这段时间内,保证服务的正常功能运行十分重要,所以需要线上无锁添加索引,即加索引的语…...
如何实现客户自助服务?打造产品知识库
良好的客户服务始于自助服务。根据哈佛商业评论,81% 的客户在联系工作人员之前尝试自己解决问题。92% 的客户表示他们更喜欢使用产品知识库/帮助中心。 所以本文主要探讨了产品知识库是什么,有哪些优势以及如何创建。 产品知识库是什么 产品知识库是将…...
)
LeetCode环形子数组的最大和(编号918)
目录 一.题目 二.解题思路 三.解题代码 一.题目 918. 环形子数组的最大和 给定一个长度为 n 的环形整数数组 nums ,返回 nums 的非空 子数组 的最大可能和 。 环形数组 意味着数组的末端将会与开头相连呈环状。形式上, nums[i] 的下一个元素是 nums[…...

PhpOffice/PhpSpreadsheet读取和写入Excel
PhpSpreadsheet是一个纯PHP编写的组件库,它使用现代PHP写法,代码质量和性能比PHPExcel高不少,完全可以替代PHPExcel(PHPExcel已不再维护)。使用PhpSpreadsheet可以轻松读取和写入Excel文档,支持Excel的所有…...

jenkins自动化部署Jenkinsfile文件配置
简介 使用jenkins部署时会读取项目中Jenkinsfile文件,文件配置不对会导致部署失败 文件内容 pipeline {agent anyparameters {string(name: project_name, defaultValue: xxx1, description: 项目jar名称)string(name: version, defaultValue: xxx2, description…...
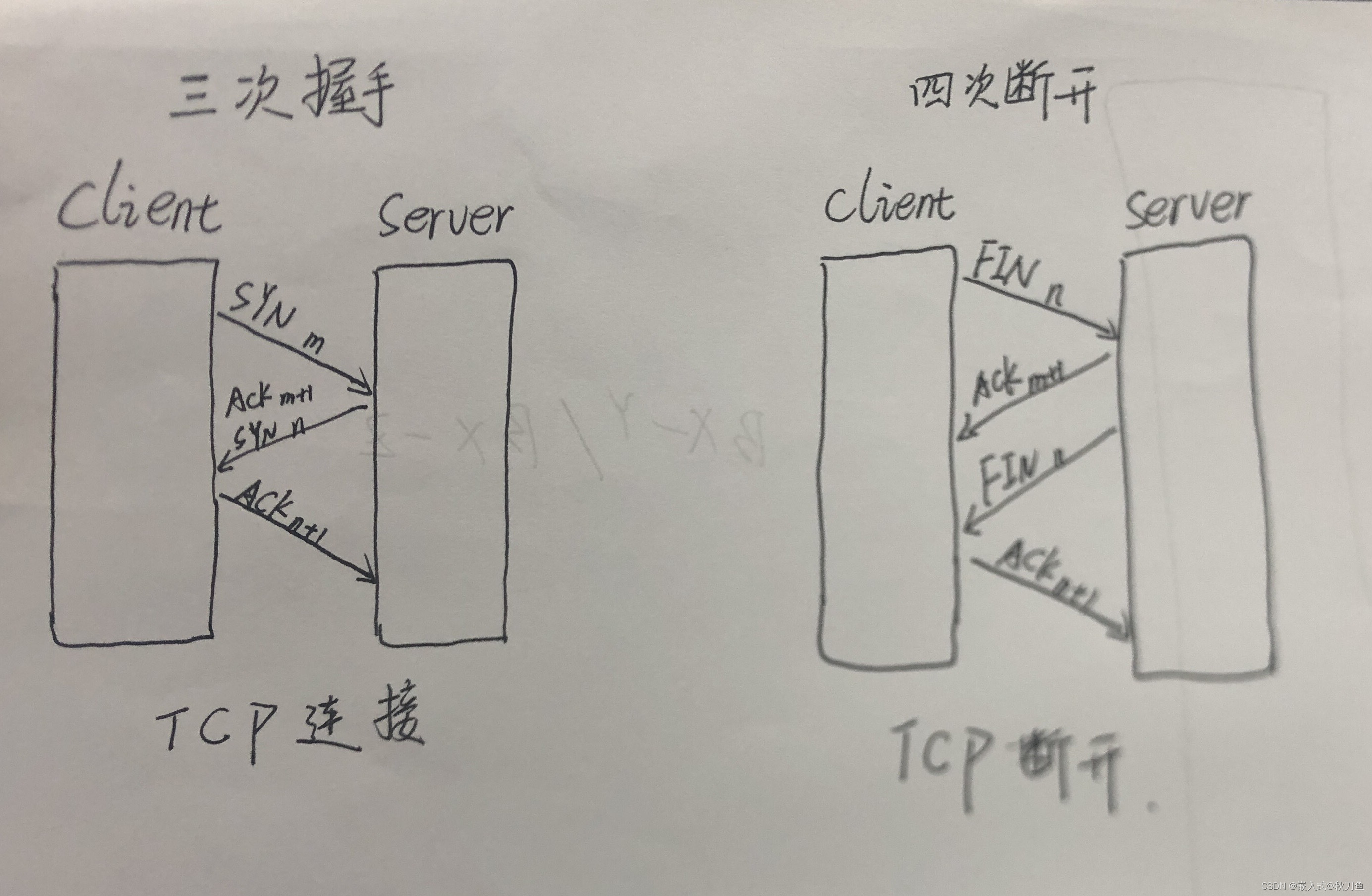
【socket编程简述】TCP UDP 通信总结、TCP连接的三次握手、TCP断开的四次挥手
Socket:Socket被称做 套接字,是网络通信中的一种约定。 Socket编程的应用无处不在,我们平时用的QQ、微信、浏览器等程序.都与Socket编程有关。 三次握手 四次断开 面试可…...
多线程-死锁
/*** 死锁demo*/ public class DeadlockDemo {public static void main(String[] args) {// 创建两个对象final Object resource1 "resource1";final Object resource2 "resource2";// 创建第一个线程Thread t1 new Thread(() -> {// 尝试锁定resour…...

P1006 [NOIP2008 提高组] 传纸条
P1006 [NOIP2008 提高组] 传纸条 题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示 思路四维dp三维dp AC四维代码:AC三维代码: 题目描述 小渊和小轩是好朋友也是同班同学,他们在一起总有谈不完的话题。一次素质拓展活动中&#…...
杭电比赛总结
我们的队伍:team013 另外两队:team014、team015 今天是我第一次打杭电,发现杭电多数都是猜结论题 先给一下我们的提交数据 Submit TimeProblem IDTimeMemoryJudge Status4:59:59101115 MS1692 KWrong Answer4:59:55101115 MS1684 KWrong…...
dom靶场
靶场下载地址: https://www.vulnhub.com/entry/domdom-1,328/ 一、信息收集 获取主机ip nmap -sP 192.168.16.0/24netdiscover -r 192.168.16.0/24端口版本获取 nmap -sV -sC -A -p 1-65535 192.168.16.209开放端口只有80 目录扫描 这里扫描php后缀的文件 g…...

go struct 的常见问题
go struct 的常见问题 1. 什么是struct?2. 如何声明、定义和创建一个struct?3. struct和其他数据类型(如数组、切片、map等)有什么区别?4. 如何访问struct字段?5. struct是否支持继承,是否支持重…...

Linux系统下的性能分析命令
在 Linux 系统下,有许多用于性能分析和调试的命令和工具,可以帮助您识别系统瓶颈、优化性能以及调查问题。本文将介绍在性能分析过程中,可能使用到的一些命令。 以下是一些常用的性能分析命令和工具汇总: 命令功能简述top用于实…...
第十三课:QtCmd 命令行终端应用程序开发
功能描述:开发一个类似于 Windows 命令行提示符或 Linux 命令行终端的应用程序 一、最终演示效果 QtCmd 不是因为它是 Qt 的组件,而是采用 Qt 开发了一个类似 Windows 命令提示符或者 Linux 命令行终端的应用程序,故取名为 QtCmd。 上述演示…...

Jmeter进阶使用:BeanShell实现接口前置和后置操作
一、背景 我们使用Jmeter做压力测试或者接口测试时,除了最简单的直接对接口发起请求,很多时候需要对接口进行一些前置操作:比如提前生成测试数据,以及一些后置操作:比如提取接口响应内容中的某个字段的值。举个最常用…...

【知识分享】高防服务器的防御机制
【知识分享】高防服务器的防御机制 易受到攻击的网站选择接入高防服务更安全,大家对于这个都清楚!但是对于高防服务如何实现防御来保障安全的,又了解多少呢?今天壹基比小源(贰伍壹叁壹叁壹贰玖捌)就来说说高防服务实现防御的常规…...

内网穿透-外远程连接中的RabbitMQ服务
文章目录 前言1.安装erlang 语言2.安装rabbitMQ3. 内网穿透3.1 安装cpolar内网穿透(支持一键自动安装脚本)3.2 创建HTTP隧道 4. 公网远程连接5.固定公网TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址 前言 RabbitMQ是一个在 AMQP(高级消息队列协议)基…...
驱动DAY4 字符设备驱动分步注册和ioctl函数点亮LED灯
头文件 #ifndef __HEAD_H__ #define __HEAD_H__ typedef struct{unsigned int MODER;unsigned int OTYPER;unsigned int OSPEEDR;unsigned int PUPDR;unsigned int IDR;unsigned int ODR; }gpio_t; #define PHY_LED1_ADDR 0X50006000 #define PHY_LED2_ADDR 0X50007000 #d…...

Python爬虫——scrapy_当当网图书管道封装
创建爬虫项目 srcapy startproject scrapy_dangdang进入到spider文件里创建爬虫文件(这里爬取的是青春文学,仙侠玄幻分类) srcapy genspider dang http://category.dangdang.com/cp01.01.07.00.00.00.html获取图片、名字和价格 # 所有的se…...

Wand-Enhancer:三步免费解锁WeMod Pro会员功能的完整指南
Wand-Enhancer:三步免费解锁WeMod Pro会员功能的完整指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否厌倦了WeMod高级功能需要付费…...

终极Windows虚拟手柄驱动配置指南:5步快速上手ViGEmBus
终极Windows虚拟手柄驱动配置指南:5步快速上手ViGEmBus 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想在Windows系统中轻松实现游戏控制器模拟…...

基于WPF开发桌面AI助手:架构设计与实现详解
1. 项目概述:一个开源的WPF桌面AI助手 最近在GitHub上看到一个挺有意思的项目,叫“MayDay-wpf/AIBotPublic”。光看名字,可能有点摸不着头脑,但点进去研究一下,你会发现这其实是一个用WPF(Windows Present…...

从Scratch图形化到Python代码:用树莓派给LeArm机械臂做二次开发实战
从Scratch图形化到Python代码:用树莓派给LeArm机械臂做二次开发实战 当Scratch积木块拼接的机械臂动作开始显得单调时,便是时候揭开底层控制的神秘面纱了。本文将带您跨越图形化编程的舒适区,用树莓派的Python环境重新定义LeArm机械臂的智能—…...

Touchpoint:命令行工具集中管理工作上下文,提升开发效率
1. 项目概述:一个被低估的开发者效率工具如果你和我一样,日常开发工作需要在多个代码仓库、项目管理工具(如Jira、Linear)、文档平台(如Confluence、Notion)和沟通软件(如Slack)之间…...

OpenCore Legacy Patcher终极指南:让老Mac免费运行最新macOS的完整教程
OpenCore Legacy Patcher终极指南:让老Mac免费运行最新macOS的完整教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

碧蓝航线自动化脚本:让游戏管理变得轻松高效
碧蓝航线自动化脚本:让游戏管理变得轻松高效 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你是否厌倦了每天重…...
技术解析与应用前景)
量子私有信息检索(QPIR)技术解析与应用前景
1. 量子私有信息检索技术概述量子私有信息检索(Quantum Private Information Retrieval, QPIR)是密码学领域的一项突破性技术,它允许用户从数据库中检索特定条目而不泄露被查询的是哪个条目。这项技术的核心价值在于解决了隐私保护与数据获取…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...

AI助手API开发资源全指南:从入门到实战的宝藏清单
1. 项目概述:一个为AI助手API开发者量身打造的“藏宝图”如果你正在或打算基于OpenAI的Assistant API、Anthropic的Claude API,或是其他主流AI平台的助手接口来构建应用,那么你大概率会遇到一个经典困境:官方文档虽然详尽…...