点云深度学习系列博客(四): 注意力机制原理概述
目录
1. 注意力机制由来
2. Nadaraya-Watson核回归
3. 多头注意力与自注意力
4. Transformer模型
Reference
随着Transformer模型在NLP,CV甚至CG领域的流行,注意力机制(Attention Mechanism)被越来越多的学者所注意,将其引入各种深度学习任务中,以提升性能。清华大学胡世民教授团队近期发表在CVM上的Attention综述 [1],详细介绍了该领域相关研究的进展。对于点云应用,引入注意力机制,设计新的深度学习模型,自然是一个研究热点。本文以注意力机制为对象,概述其发展脉络,以及在点云应用领域的成功应用,为期望在该研究方向有所突破的同学,提供一点参考。
1. 注意力机制由来
参考李沐老师深度学习教材 [2] 关于注意力机制部分的介绍,这里对注意力机制给出一个简单的解释。注意力机制即模拟人类视觉感知下,选择性地筛选信息进行接收和处理的机制。在信息筛选时,如果不提供任何自主性提示,即人在不做任何思考的情况下,阅读一段文本,观察一个场景,或听一段音频时,注意力机制偏重于异常信息,如一个黑白场景下穿红色衣服的女孩,或一段文字中的一个感叹号等。当引入自主性提示时,比如希望阅读和某个名词有关的语句,或有各对象关联的场景时,注意力机制引入这种提示,并且在信息筛选时,提高对这种信息的敏感度。为了对上述过程进行数学建模,注意力机制引入三个基本元素,即查询(Query),键(Key)和值(Value)。这三个元素共同构成了Attention Module的基本处理单元。键(Key)和值(Value)对应信息的输入和输出,查询(Query)对应的自主性提示。Attention Module基本处理单元如下图所示。
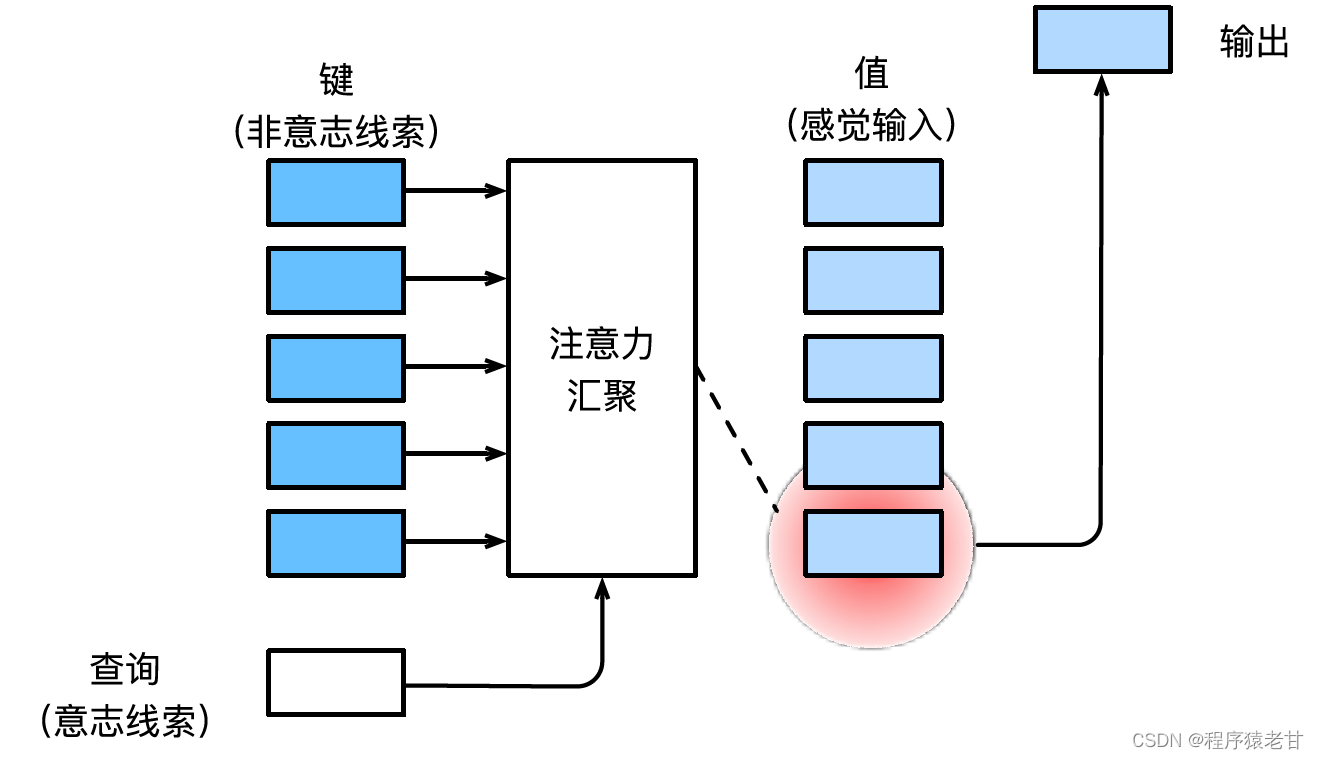
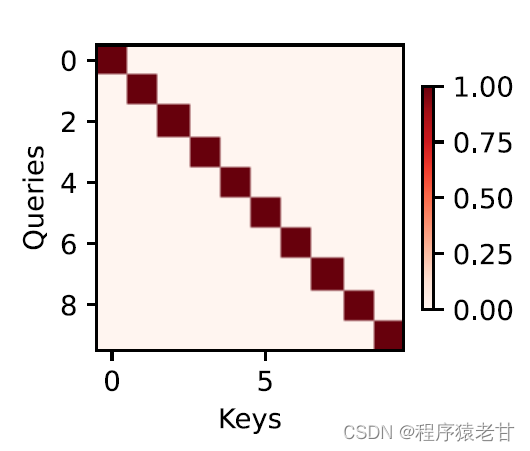
注意力机制通过注意力汇集,将查询和键结合在一起,实现对值的选择倾向。键和值是成对的,就像训练任务中的输入输出,是已知的数据分布,或者类别对应。注意力机制通过在注意力汇聚中输入查询,建立查询到每一个键的权重编码,得到查询与键的关系,进而指导对应值的输出。简而言之,就是当查询越接近某个键时,查询的输出结果就越接近键对应的值。该过程将注意力引入了更接近查询的键值对应关系,以指导符合注意力的输出。如果将查询与键对应建立一个二维的关系矩阵,当值相同时为1,不同时为0,其可视化结果可表示为:
2. Nadaraya-Watson核回归
这里介绍一个经典的注意力机制模型,即Nadaraya-Watson核回归 [3][4],用以理解注意力机制的基本运行逻辑。假设我们我们有一个受函数f控制的键值对应关系数据集{(x1,y1),(x2,y2),...(xi,yi)},学习任务是建立f,并指导对新的x键的求值。在这个任务中,(xi,yi)对应的就是键和值,输入的x表示查询,目标是获得其对应的值。按照注意力机制,需要通过考察x与键值对应关系数据集中每一个键值的相似关系,建立对其值的预测。当输入的x越接近某个xi键时,那么输出的值就越接近yi。这里对键值最简单的估计器是求平均:
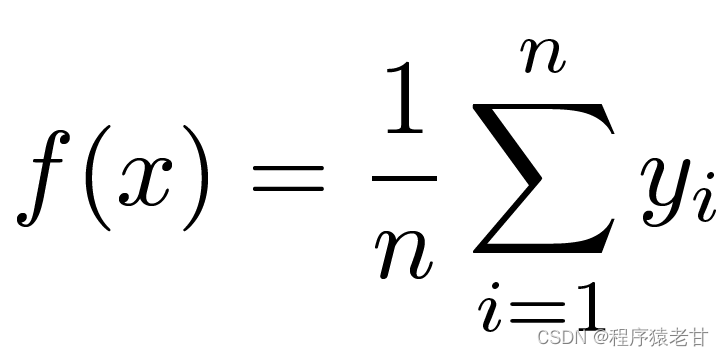
显然,这不是一个好主意。因为平均汇聚忽略了样本在键值分布上的偏离差异。如果将键值的差异引入到求值的过程,那么结果自然会变好。Nadaraya-Watson核回归即使用了这样的思路,提出了基于加权的求值方法:
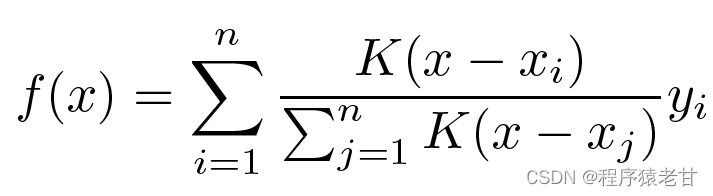
K被认为是核,即被理解为衡量偏离差异的权重。如果将上面公式按照输入与键的差异权重,重写其自身公式,则可得到:
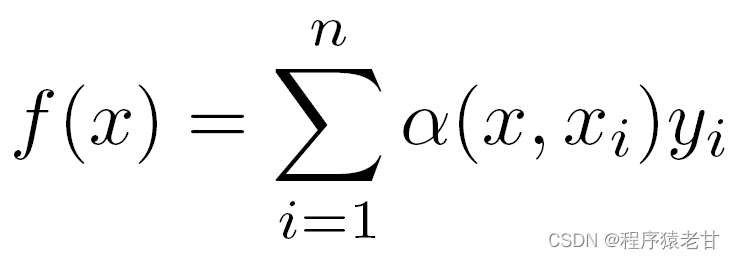
如果把上述权重替换为一个高斯核驱动的高斯权重,那么函数f即可表示为 :
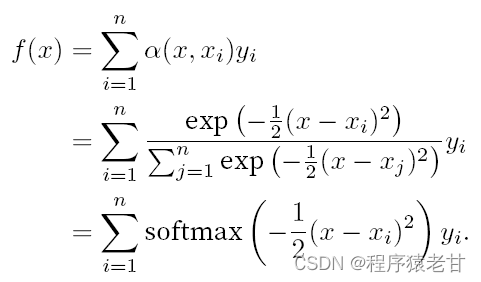
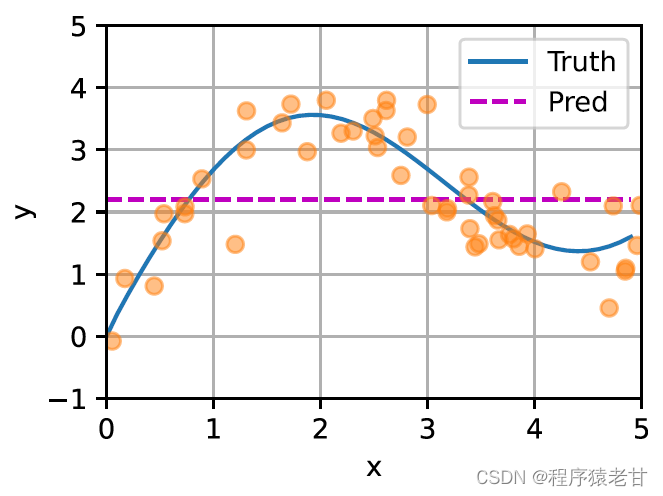
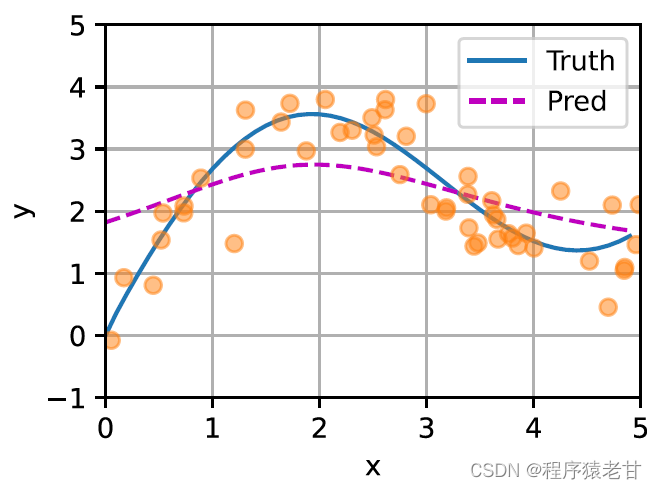
这里给出一个示意图,以对比平均汇聚(左图)和基于高斯核驱动的注意力汇聚(右图)推导出的不同f对于样本键值对的拟合情况。可以看到,后者的拟合性能会好很多。
上述模型是一个无参模型,对于带可学习参数的情况,建议阅读 [2] 注意力机制章节。这里所使用的高斯核及其对应的高斯权重,用来描述查询与键的关系。在注意力机制中,这种关系的量化表示,即为注意力评分。上述对查询值建立预测的过程,可以表示为对查询建立基于键值对的评分,通过对评分赋权,以获得查询值,表示为:
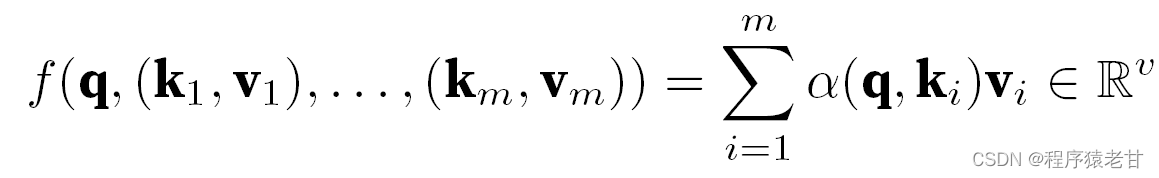
其中α表示权重,q表示查询,kv表示键值对。在教材 [2] 中还介绍了如何处理查询和键长度不匹配时间的加性注意力处理方法以及缩放点积注意力,用于定义注意力评分,这里不再详述。
3. 多头注意力与自注意力
1)多头注意力
多头注意力用来组合使用查询、键值不同的子空间表示,基于注意力机制实现对不同行为的组织,来学习结构化的知识以及数据依赖关系。通过独立学习得到不同的线性投影,来变换查询、键和值。然后,将变换后的查询、键值并行地送到注意力汇聚中,然后将多个注意力汇聚的输出拼接在一起,并且通过另一个可以学习的线性投影进行变换,并产生最终输出。这种设计被称为多头注意力 [5]。下图展示了一个可学习的多头注意力模型:
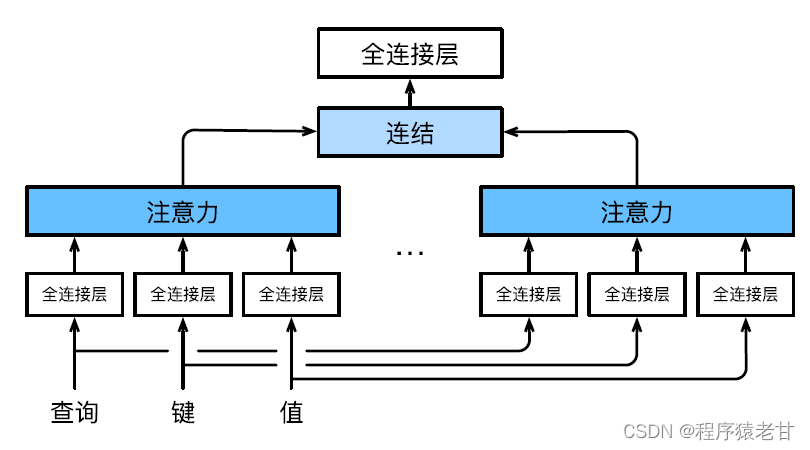
这里给出每个注意力头的数学定义,给定查询q, 键k,值v,每个注意力头h的计算方法为:
![]()
这里的f可以是加性注意力和缩放点积注意力。多头注意力的输出经过另一个线性变换,以连接欸多个注意力机制输出,进而模仿更复杂的函数。
2)自注意力与位置编码
基于注意力机制,将NLP问题中的词元序列输入注意力汇聚,将一组词元同时充当查询、键值。每个查询都会关注所有的键值对并生成一个注意力输出。由于查询、键值均来自同一组输入,因此被称为自注意力机制。这里将给出基于自注意力机制的编码方法。
给定一个词元输入序列x1,x2,...,xn,对应的输出为一个相同的序列y1,y2,...,yn。y表示为:
![]()
这个公式起初我不是很理解。不过结合文本翻译的具体任务,就方便理解了。这里的意思是,一个词元某个位置上的元素,对应了输入和输出。即键值都是这个元素本身。我们需要学习的函数,即通过学习每个词与词元中的所有词汇的权重,来建立对值的预测。
在处理词元时,由于自注意力需要并行计算,而放弃了顺序操作。为了使用序列的顺序信息,可以在输入表示中添加位置编码来注入绝对的或相对的位置信息。通过对输入矩阵添加一个相同形状的位置嵌入矩阵,以实现绝对位置编码,其行列对应的元素表示为:
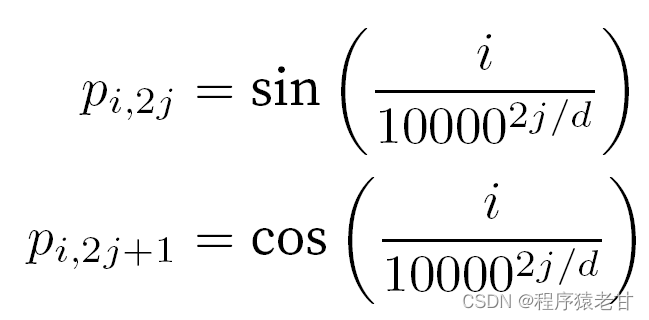
这种基于三角函数方法表示的位置嵌入矩阵元素并不直观。我们只知道编码维度与三角函数驱动的曲线频率存在一种关系。即每个词元内部不同维度的信息,其对应的三角函数曲线频率是不同的,如图表示:
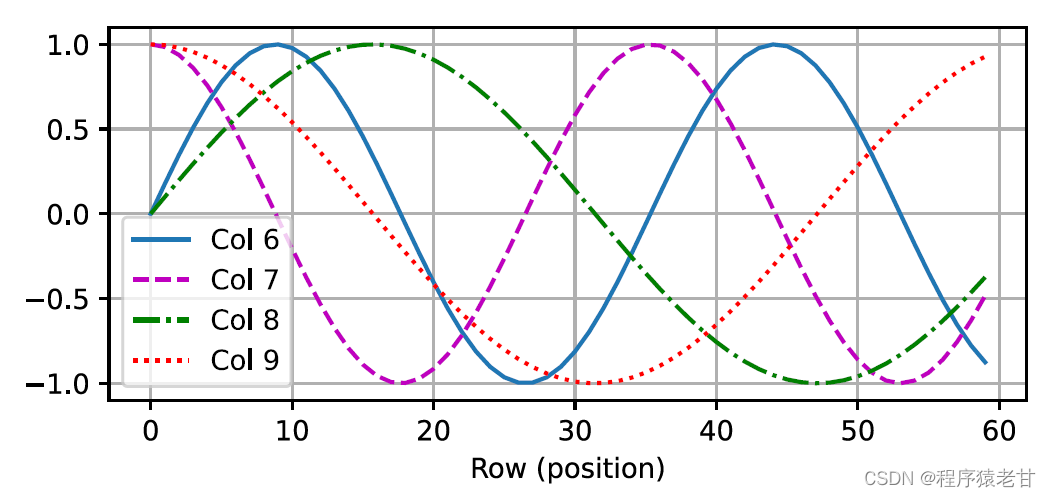
似乎随着每个词元维度的升高,其间隔对应的频率会随之降低。为了搞清楚这种频率变化与绝对位置的关系,这里使用一个例子来解释。这里打印出0-7的二进制表示(右图为频率热图):

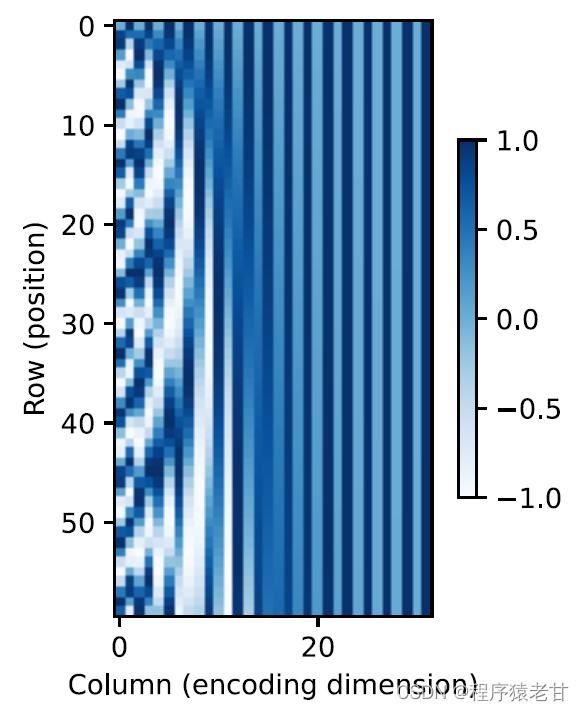
这里较高比特位的交替频率低于较低位。通过使用位置编码,实现词源不同维度基于频率变换的编码,进而实现对位置信息的添加。相对位置编码此处不再详述。
4. Transformer模型
终于到了激动人心的时候了!我们在理解了上述知识之后,就打好了学习Transformer的基础。相比之前依然依赖循环神经网络实现输入表示的自注意力模型,Transformer模型完全基于自注意力机制,没有任何卷积层或循环神经网络层。
Transformer模型是一个编解码架构,整体架构图如下所示:
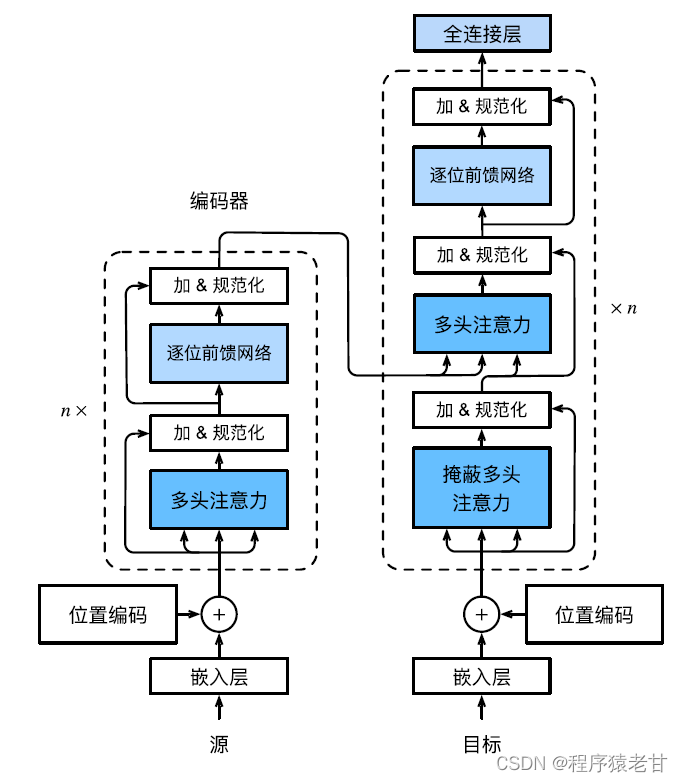
Transformer是由编码器和解码器组成的,基于自注意力模块构建,源(输入)序列和目标(输出)序列嵌入表示将加上位置编码,再分别输入到编码器和解码器中。 编码器是由多个相同的层叠叠加而成的,每个层都有两个⼦层。第一个子层是多头自注意力汇聚,第二个子层是基于位置的前馈网络。编码器层计算的查询,键,值均来自于上一层的输出。每个子层都使用了残差连接。解码器同编码器类似,也是由多个相同的层叠加⽽成,且使用了残差连接和层规范化。除了编码器中描述的两个子层外,解码器还添加了一个中间子层,称为编码器-解码器注意力层。该层中查询来自前一个解码器层的输出,⽽键和值来⾃整个编码器的输出。在解码器自注意力中,查询,键和值都来自上一个解码器层的输出。解码器中的每个位置只能考虑之前的所有位置。这种遮蔽注意力保留了自回归属性,确保预测仅依赖于已生成的输出词元。不同module的具体实现不再详述。
注:以上关于注意力机制的名词解释,原理介绍以及公式,主要参考李沐老师的教材 [2]。
基于上述注意力机制原理,针对点云处理任务的注意力机制深度学习模型被提出。我们将在下篇博客详细介绍相关工作,欢迎持续关注我的博客。
Reference
[1] MH. Guo, TX, Xu, JJ. Liu, et al. Attention mechanisms in computer vision: A survey[J]. Computational Visual Media, 2022, 8(3): 331-368.
[2] A. Zhang, ZC. Lipton, M. Li, and AJ. Smola. 动手学深度学习(Dive into Deep Learning) [B]. https://zh-v2.d2l.ai/d2l-zh-pytorch.pdf.
[3] EA. Nadaraya. On estimating regression[J]. Theory of Probability & Its Applications, 1964, 9(1): 141-142.
[4] GS. Watson. Smooth regression analysis. Sankhyā: The Indian Journal of Statistics, Series A, pp. 359‒372.
[5] A. Vaswani, N. Shazeer, N. Parmar, et al. Attention is all you need. Advances in neural information processing systems, 2017,5998‒6008.
相关文章:
点云深度学习系列博客(四): 注意力机制原理概述
目录 1. 注意力机制由来 2. Nadaraya-Watson核回归 3. 多头注意力与自注意力 4. Transformer模型 Reference 随着Transformer模型在NLP,CV甚至CG领域的流行,注意力机制(Attention Mechanism)被越来越多的学者所注意,将…...

设置Visual Studio 2022背景图
前言 编写代码时界面舒服,自己喜欢很重要。本篇文章将会介绍VS2022壁纸的一些设置,主题的更改以及如何设计界面。 理想的界面应该是这样的 接下来我们来一步步学习如何将界面设计成这样 一、壁纸插件下载 1.拓展->点击拓展管理 2.右上角搜索backgro…...
1. 用Qt开发的十大理由
用Qt的十大理由 原因最主要的是很多大公司都在用,有钱景。 先来看看各大公司的评价: 奔驰:们用 Qt 开发了绝大部分的UI体验和软件,包括屏幕动画,屏幕间的过渡和小组件。 FORMLABS:凭借Qt的快速迭代&…...

俄罗斯方块游戏代码
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的,绽…...

设计模式相关面试题
文章目录面向对象编程中,都有哪些设计原则?设计模式的分类 ?单例模式的特点是什么?单例模式有哪些实现?什么是简单⼯⼚模式什么是抽象⼯⼚模式?什么是⼯⼚⽅法模式?什么是代理模式?S…...
构建Jenkins 2.340持续集成环境
一、前言 本文学习自:2022版Jenkins教程(从配置到实战) 如有不妥,欢迎指正 二、构建资料 已经包括了本文档使用的所有所需的安装包 三、安装docker 1、解压docker docker-20.10.10.tgz2、复制文件 cp docker/* /usr/bin/3、编写启动文…...

Ubuntu/Centos下OpenJ9 POI输出Excel的Bug
项目更换 JDK为 OpenJ9 后, 使用 POI 导出 Excel 遇到的问题 OpenJ9 版本信息 /opt/jdk/jdk-11.0.178/bin/java -version openjdk version "11.0.17" 2022-10-18 IBM Semeru Runtime Open Edition 11.0.17.0 (build 11.0.178) Eclipse OpenJ9 VM 11.0.17.0 (build …...

链接脚本学习笔记
IAR 一般步骤 链接器用于链接过程。它通常执行以下过程(请注意,某些步骤可以通过命令行选项或链接器配置文件中的指令关闭): 1.确定应用程序中要包含哪些模块。始终包含对象文件中提供的模块。仅当库文件中的模块为从包含的模块…...

NLP顶会近三年小众研究领域
ACL 2022 编码器和解码器框架、自然语言生成、知识i神经元、抽取式文本摘要、预训练语言模型、零样本神经机器翻译等。 2021 新闻标题生成任务等。跨语言命名实体识别、代码搜索、音乐生成、Hi-Transformer、预训练语言模型、语义交互等。 EMNLP 2021 代码摘要生成、隐私…...
[electron] 一 vue3.2+vite+electron 项目集成
一 开发环境系统:windows开发工具: git , vscode,termial环境依赖: node, npm 二 步骤2.1 通过vite 创建vue项目通过 终端执行命令,选择 模板 vuenpm init vite cd 项目目录 npm install npm run dev2.2 集成 electro…...
ESP32 Arduino(十二)lvgl移植使用
一、简介LVGL全程LittleVGL,是一个轻量化的,开源的,用于嵌入式GUI设计的图形库。并且配合LVGL模拟器,可以在电脑对界面进行编辑显示,测试通过后再移植进嵌入式设备中,实现高效的项目开发。SquareLine Studi…...

js一数组按照另一数组进行排序
有时我们需要一个数组按另一数组的顺序来进行排序,总结一下方法,同时某些场景也会用到。 首先一个数组相对简单的情况: var arr1 [52,23,36,11,09]; var arr2 [23,09,11,36,52]; // 要求arr1按照arr2的顺序来排序,可以看到两个…...

JavaScript 类继承
JavaScript 类继承是面向对象编程的一个重要概念,它允许一个类从另一个类继承属性和方法。通过使用继承,可以避免代码重复,并可以在现有类的基础上扩展新功能。 在 JavaScript 中,您可以使用关键字 extends 来实现类继承。例如&a…...
MySQL相关面试题
文章目录union 和 unionAll 的区别?drop、delete与truncate的区别 ?sql 语句如何优化 ?什么是事务 ?事务的四个特性(ACID) ?事务的隔离级别?索引主要有哪几种分类 ?什么时候适合添加索引&#x…...
Python创意作品说明怎么写,python创意编程作品集
大家好,小编来为大家解答以下问题,Python创意作品说明怎么写,python创意编程作品集,现在让我们一起来看看吧! 1、有哪些 Python 经典书籍 书名:深度学习入门 作者:[ 日] 斋藤康毅 …...
icomoon字体图标的使用
很久之前就学习过iconfont图标的使用,今天又遇到一个用icomoon字体图标写的案例,于是详细学习了一下,现整理如下。 一、下载 1.网址: https://icomoon.io/#home 2.点击IcoMoon App。 3.点击 https://icomoon.io/app 4.进入IcoM…...
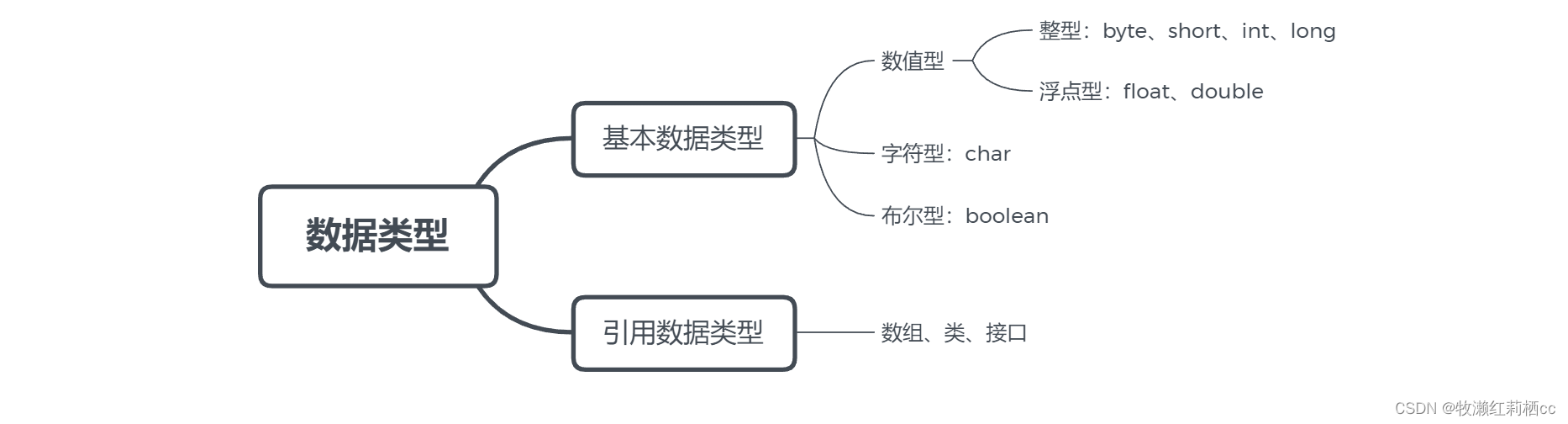
Java · 常量介绍 · 变量类型转换 · 理解数值提升 · int 和 Stirng 之间的相互转换
书接上回 Java 变量介绍 我们继续学习以下内容. 四、常量字面值常量final 关键字修饰的常量五、理解类型转换int 和 long/double 相互赋值int 和 boolean 相互赋值int 字面值常量给 byte 赋值强制类型转换类型转换小结六、理解数值提升int 和 long 混合运算byte 和 byte 的运算…...
JVM从跨平台到跨专业 Ⅲ -- 类加载与字节码技术【下】
文章目录编译期处理默认构造器自动拆装箱泛型集合取值可变参数foreach 循环switch 字符串switch 枚举枚举类try-with-resources方法重写时的桥接方法匿名内部类类加载阶段加载链接初始化相关练习和应用类加载器类与类加载器启动类加载器拓展类加载器双亲委派模式自定义类加载器…...

ucore的字符输出
ucore的字符输出有cga,lpt,和串口。qemu模拟出来显示器连接到cga中。 cga cga的介绍网站:https://en.wikipedia.org/wiki/Color_Graphics_Adapter cga是显示卡,内部有个叫6845的芯片。cga卡把屏幕划分成一个一个单元格,每个单元格显示一个a…...

【ESP 保姆级教程】玩转emqx数据集成篇① ——认识数据集成
忘记过去,超越自己 ❤️ 博客主页 单片机菜鸟哥,一个野生非专业硬件IOT爱好者 ❤️❤️ 本篇创建记录 2023-02-10 ❤️❤️ 本篇更新记录 2023-02-10 ❤️🎉 欢迎关注 🔎点赞 👍收藏 ⭐️留言📝🙏 此博客均由博主单独编写,不存在任何商业团队运营,如发现错误,请…...

iPaaS平台推荐——五款产品能力与适用场景观察
在数字化转型加速推进的当下,iPaaS(集成平台即服务)正成为企业打通数据孤岛、连接应用生态的核心基础设施。面对市场上类型各异的集成平台,如何根据自身需求选择合适的解决方案,成为众多企业关注的重点。本文基于公开资…...
 的6个高阶用法,数据分析师必看)
别再只会用0填充了!Pandas DataFrame.fillna() 的6个高阶用法,数据分析师必看
别再只会用0填充了!Pandas DataFrame.fillna() 的6个高阶用法,数据分析师必看 在数据分析的日常工作中,缺失值处理就像是一道无法回避的数学题。许多刚入行的分析师会条件反射般地输入.fillna(0),这就像用创可贴处理所有伤口——有…...

网盘直链解析工具完整指南:技术实现与高效下载策略
网盘直链解析工具完整指南:技术实现与高效下载策略 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

在新磁盘挂载点/data安装codex
实例是 Oracle Cloud Always Free VM.Standard.E2.1.Micro Linux, /data 目录。 Codex CLI 官方支持用 npm 安装:npm i -g openai/codex,首次运行需要登录 ChatGPT 或配置 API key; 建议:Codex 安装到 /data;bubblewr…...

企业内网虚拟机如何通过Taotoken安全接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内网虚拟机如何通过Taotoken安全接入多模型API 在许多企业的技术架构中,开发与测试环境常部署于内网虚拟机中。这些…...

Avogadro 2:3分钟掌握跨平台分子建模的5大核心价值
Avogadro 2:3分钟掌握跨平台分子建模的5大核心价值 【免费下载链接】avogadroapp Avogadro is an advanced molecular editor designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, and related a…...

全国跨省搬家专业靠谱无套路排行 跨省搬家公司选哪个物流平台便宜省心?哪个搬家公司专业安全保障,没有半路加价?
用户最担心的“半路加价”问题,几乎所有“搬家公司/搬家平台”每天都发生各样“半路加价”问题。本文根据各大社交平台用户避雷贴,统计出搬家公司/搬家平台专业靠谱无套路程度前5名,方便广大需要跨省搬家的用户,接近跨省搬家公司选…...

Sora 2如何“唤醒”3D Gaussian Splatting?:从神经辐射场到毫秒级动态场景生成的4层技术跃迁解析
更多请点击: https://intelliparadigm.com 第一章:Sora 2与3D Gaussian Splatting融合的范式革命 传统视频生成模型受限于体素网格或NeRF隐式表示的计算开销与几何保真度瓶颈,而Sora 2通过引入时空一致性token压缩机制,与3D Gaus…...

基于确定性脚本与LLM决策的AI多智能体自动化监控系统设计与实践
1. 项目概述:一个为AI多智能体协作而生的“自动化监工”如果你正在用OpenClaw这类框架玩多AI智能体协作,大概率会遇到一个头疼的问题:怎么知道这群“数字员工”到底在不在干活?谁在摸鱼?任务到底完成了没有?…...

如何高效使用炉石传说脚本:终极完整指南解决你的自动化难题
如何高效使用炉石传说脚本:终极完整指南解决你的自动化难题 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 你是否厌倦了炉石传说中重复性的…...