计算机竞赛 python 爬虫与协同过滤的新闻推荐系统
1 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 python 爬虫与协同过滤的新闻推荐系统
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
由于网络信息科技的不断进步和数据量的快速增长每天会产生巨大的信息量,使得互联网上的数据信息越来越庞大、系统变得越来越臃肿,这些庞大的海量信息给用户寻找自己感兴趣的内容带来了极大的困难,往往会导致用户迷失在信息迷宫中,从而无法找到自己真正感兴趣的内容。因此,高效快速的进行新闻推荐变得极其重要。
本项目使用前后端分离,前端是基于Vue设计的界面,后端基于python Django框架建立。
2 实现效果
整体软件结构
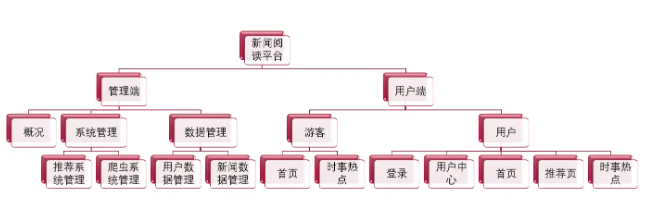
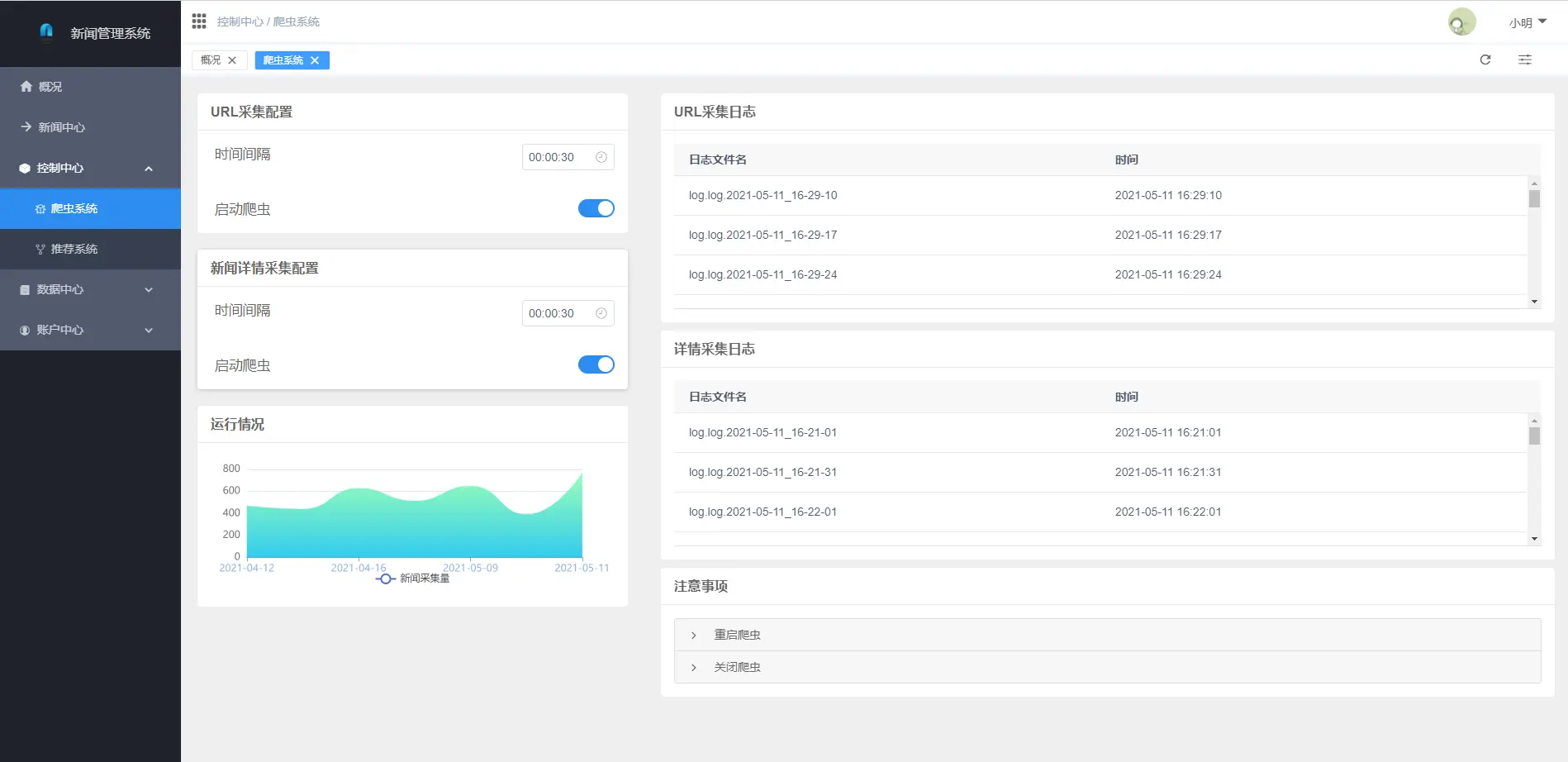
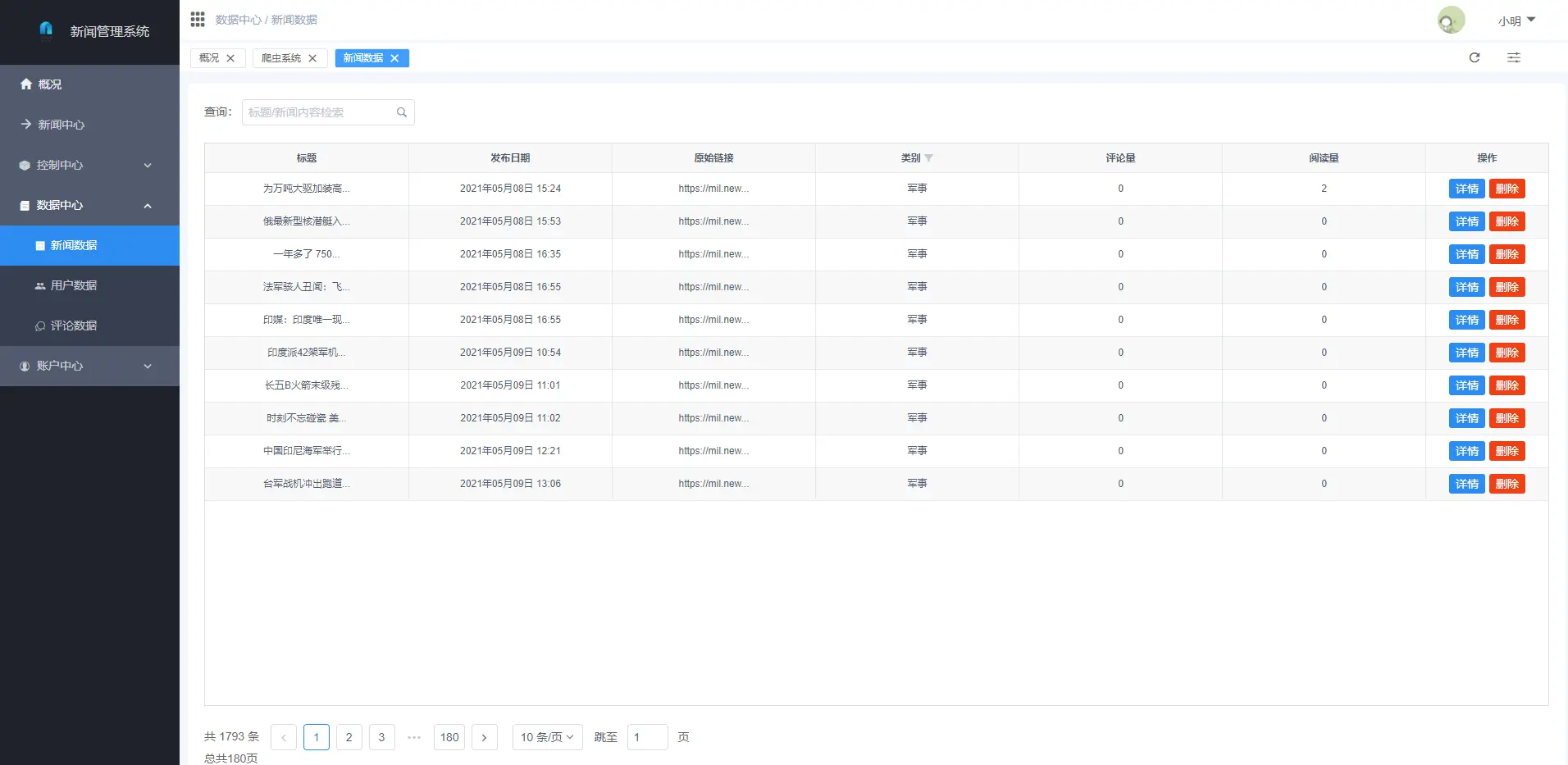
2.1 用户端
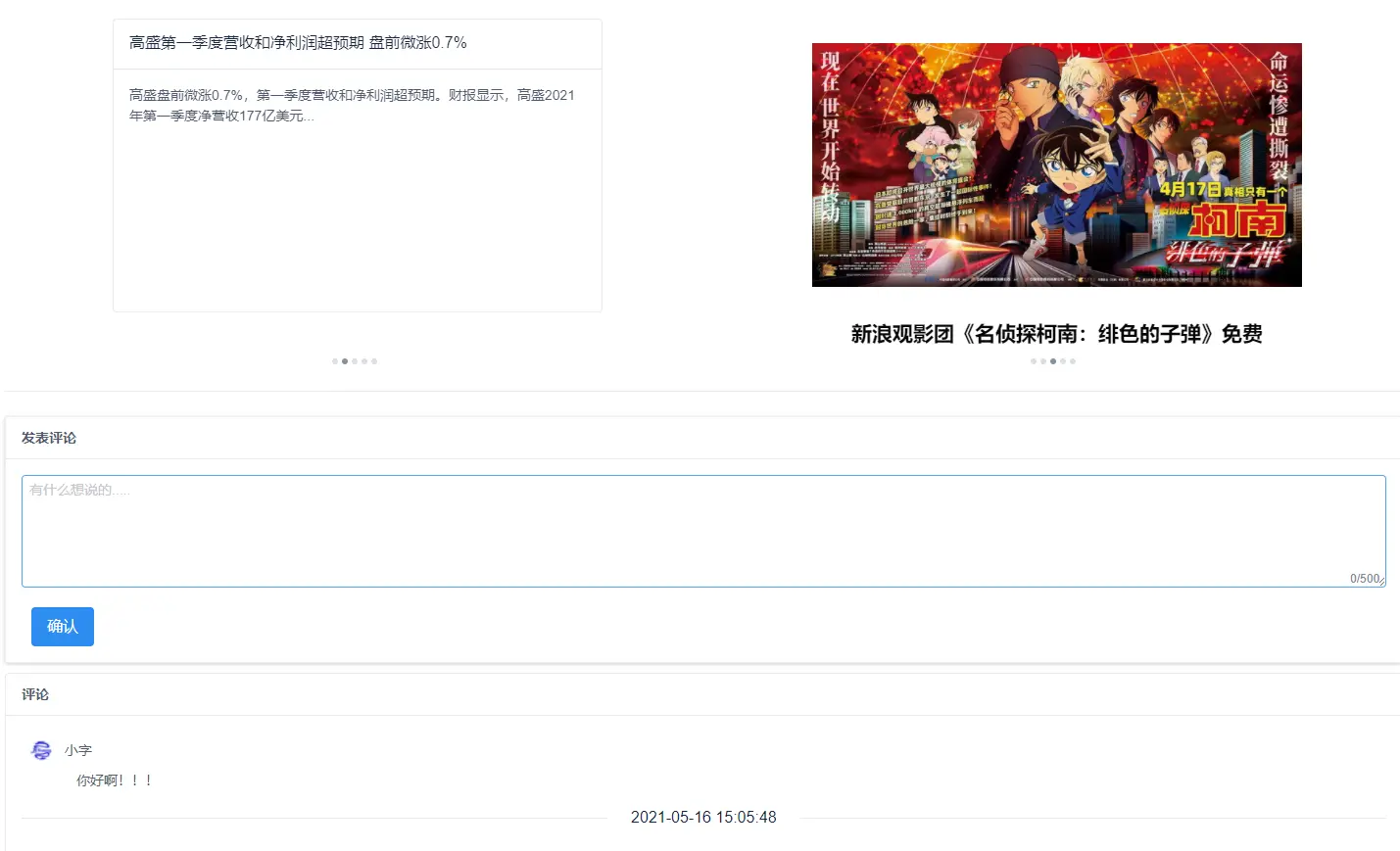
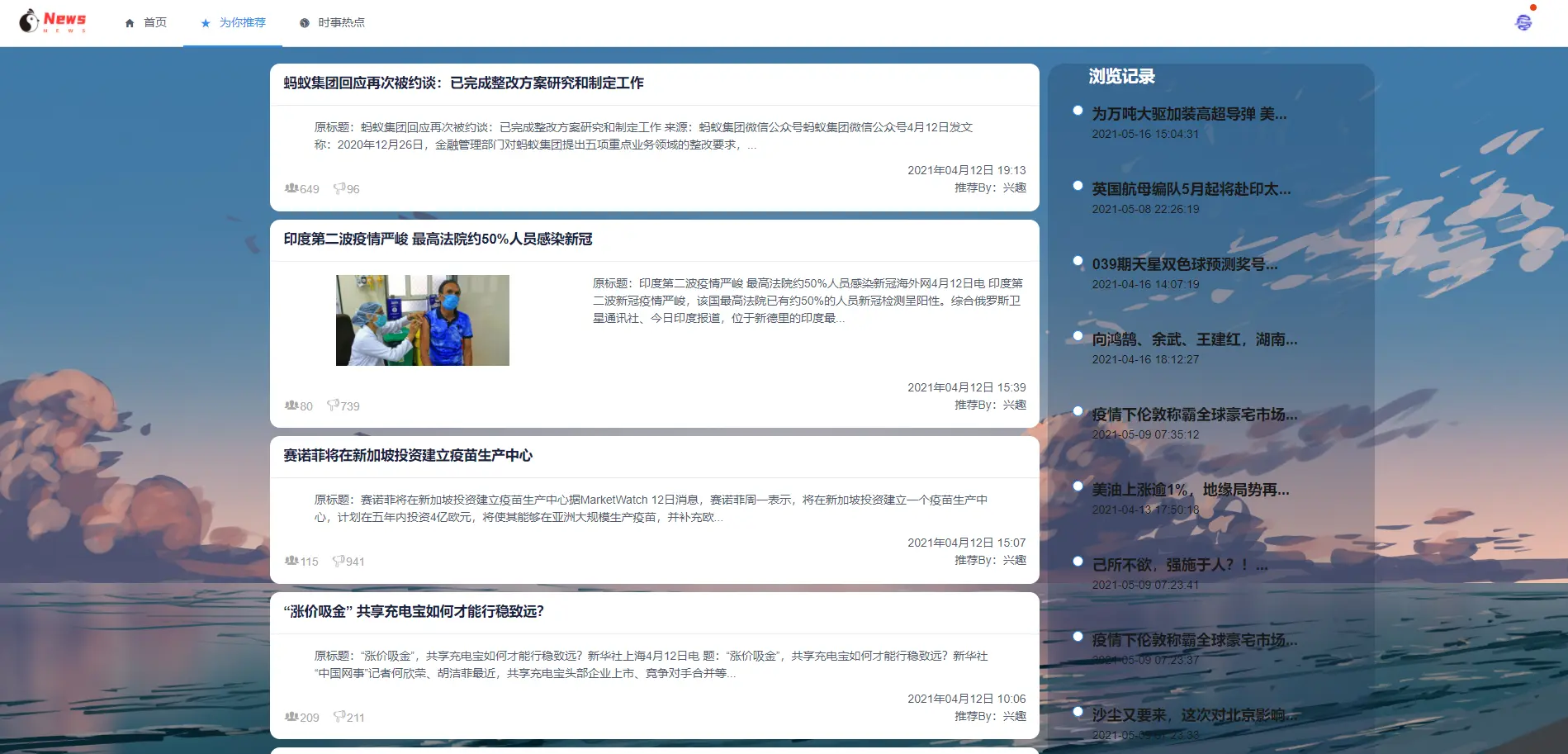
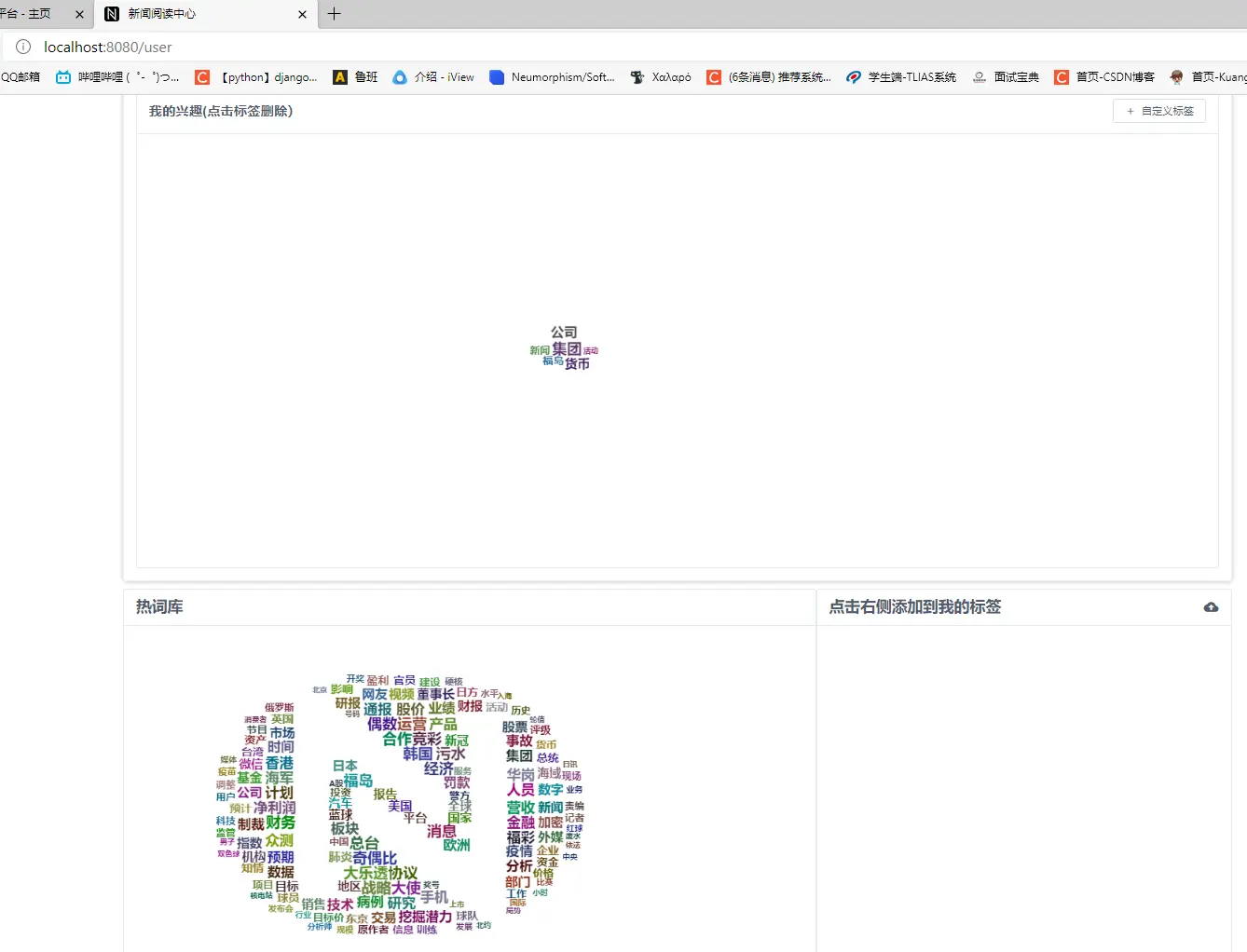
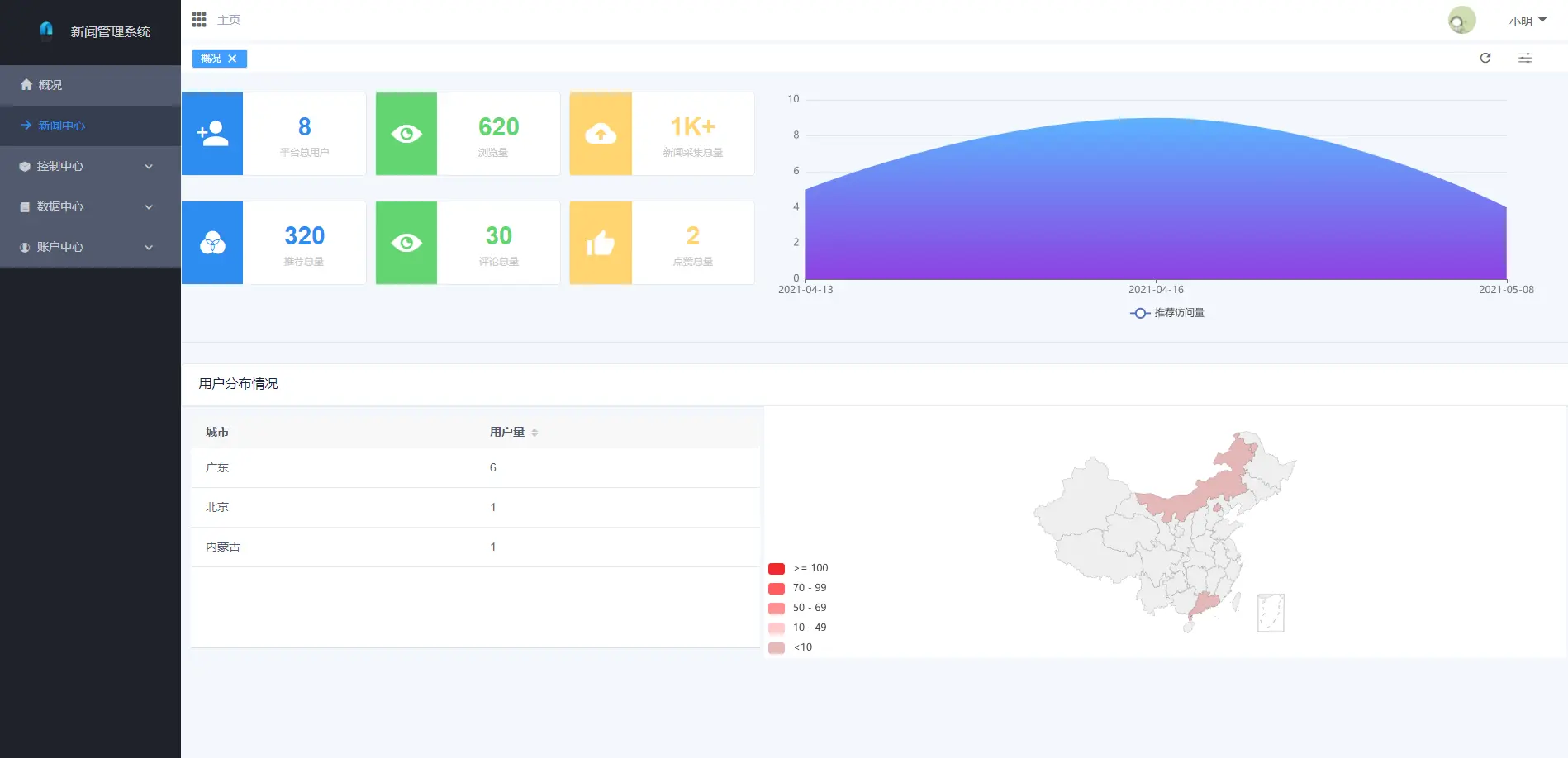
2.2 管理端
3 Django
简介
Django是一个基于Web的应用框架,由python编写。Web开发的基础是B/S架构,它通过前后端配合,将后台服务器的数据在浏览器上展现给前台用户的应用。Django本身是基于MVC模型,即Model(模型)+View(视图)+
Controller(控制器)设计模式,View模块和Template模块组成了它的视图部分,这种结构使动态的逻辑是剥离于静态页面处理的。
Django框架的Model层本质上是一套ORM系统,封装了大量的数据库操作API,开发人员不需要知道底层的数据库实现就可以对数据库进行增删改查等操作。Django强大的QuerySet设计能够实现非常复杂的数据库查询操作,且性能接
安装
pip install django
使用
#!/usr/bin/env python
'''Django's command-line utility for administrative tasks.'''
import os
import sys
def main():
'''Run administrative tasks.'''
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'newsServer.settings')
try:
from django.core.management import execute_from_command_line
except ImportError as exc:
raise ImportError(
"Couldn't import Django. Are you sure it's installed and "
"available on your PYTHONPATH environment variable? Did you "
"forget to activate a virtual environment?"
) from exc
execute_from_command_line(sys.argv)
if __name__ == '__main__':
main()
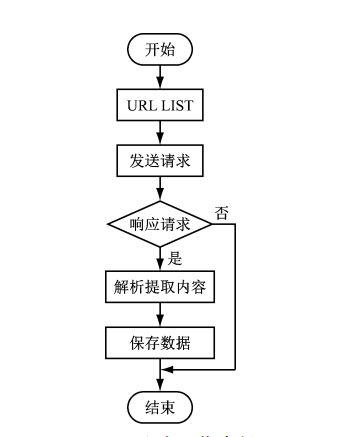
4 爬虫
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。爬虫对某一站点访问,如果可以访问就下载其中的网页内容,并且通过爬虫解析模块解析得到的网页链接,把这些链接作为之后的抓取目标,并且在整个过程中完全不依赖用户,自动运行。若不能访问则根据爬虫预先设定的策略进行下一个
URL的访问。在整个过程中爬虫会自动进行异步处理数据请求,返回网页的抓取数据。在整个的爬虫运行之前,用户都可以自定义的添加代理,伪 装
请求头以便更好地获取网页数据。爬虫流程图如下:
相关代码
def getnewsdetail(url):
# 获取页面上的详情内容并将详细的内容汇集在news集合中
result = requests.get(url)
result.encoding = 'utf-8'
soup = BeautifulSoup(result.content, features="html.parser")
title = getnewstitle(soup)
if title == None:
return None
date = getnewsdate(soup)
mainpage, orimainpage = getmainpage(soup)
if mainpage == None:
return None
pic_url = getnewspic_url(soup)
videourl = getvideourl(url)
news = {'mainpage': mainpage,
'pic_url': pic_url,
'title': title,
'date': date,
'videourl': videourl,
'origin': orimainpage,
}
return news
def getmainpage(soup):
'''
@Description:获取正文部分的p标签内容,网易对正文部分的内容通过文本前部的空白进行标识\u3000
@:param None
'''
if soup.find('div', id='article') != None:
soup = soup.find('div', id='article')
p = soup.find_all('p')
for numbers in range(len(p)):
p[numbers] = p[numbers].get_text().replace("\u3000", "").replace("\xa0", "").replace("新浪", "新闻")
text_all = ""
for each in p:
text_all += each
logger.info("mainpage:{}".format(text_all))
return text_all, p
elif soup.find('div', id='artibody') != None:
soup = soup.find('div', id='artibody')
p = soup.find_all('p')
for numbers in range(len(p)):
p[numbers] = p[numbers].get_text().replace("\u3000", "").replace("\xa0", "").replace("新浪", "新闻")
text_all = ""
for each in p:
text_all += each
logger.info("mainpage:{}" + text_all)
return text_all, p
else:
return None, None
def getnewspic_url(soup):
'''
@Description:获取正文部分的pic内容,网易对正文部分的图片内容通过div中class属性为“img_wrapper”
@:param None
'''
pic = soup.find_all('div', class_='img_wrapper')
pic_url = re.findall('src="(.*?)"', str(pic))
for numbers in range(len(pic_url)):
pic_url[numbers] = pic_url[numbers].replace("//", 'https://')
logging.info("pic_url:{}".format(pic_url))
return pic_url
5 Vue
简介
Vue是一套用于构建用户界面的渐进式框架。其核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。Vue框架主要有以下三个特点:
-
遵循MVVM模式
MVVM是Model-View-ViewModel的简写,它本质上是MVC的改进版。MVVM的主要目的是分离视图(View)和模型(Model)。如图所示。
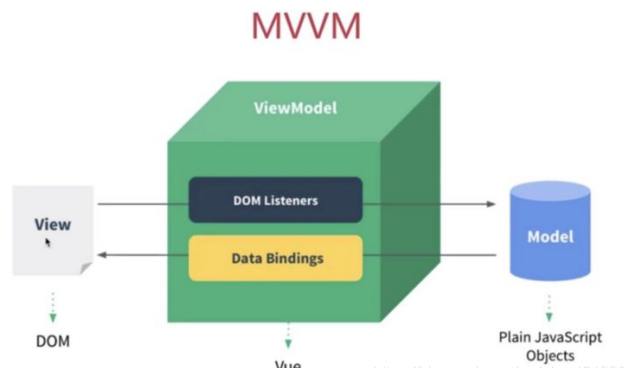
-
组件化
组件系统允许我们使用小型、独立和通常可复用的组件构建大型应用。几乎任意类型的应用界面都可以抽象为一个组件树,如图所示。
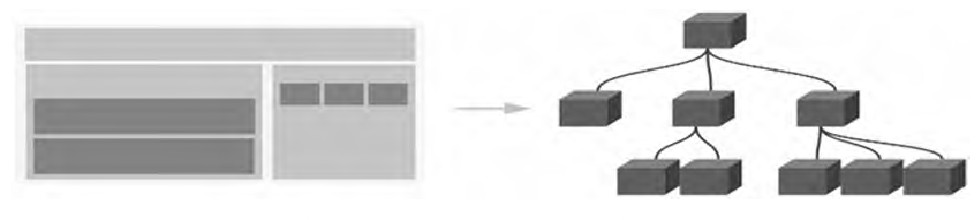
-
虚拟DOM
频繁操作操作真实DOM会出现页面卡顿,影响用户体验。Vue的虚拟DOM不会立即操作DOM,而是将多次操作保存起来,进行合并计算,减少真实DOM的渲染计算次数,提升用户体验。
6 推荐算法(Recommendation)
基于协同过滤的推荐算法(Collaborative Filtering Recommendations)
协同过滤(Collaborative Filtering)推荐算法是最经典、最常用的推荐算法。
所谓协同过滤, 基本思想是根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品(基于对用户历史行为数据的挖掘发现用户的喜好偏向,
并预测用户可能喜好的产品进行推荐),一般是仅仅基于用户的行为数据(评价、购买、下载等),
而不依赖于项的任何附加信息(物品自身特征)或者用户的任何附加信息(年龄, 性别等)。目前应用比较广泛的协同过滤算法是基于邻域的方法,
而这种方法主要有下面两种算法:
- 基于用户的协同过滤算法(UserCF): 给用户推荐和他兴趣相似的其他用户喜欢的产品
- 基于物品的协同过滤算法(ItemCF): 给用户推荐和他之前喜欢的物品相似的物品
代码实现
def itemcf_sim(df):"""文章与文章之间的相似性矩阵计算:param df: 数据表:item_created_time_dict: 文章创建时间的字典return : 文章与文章的相似性矩阵思路: 基于物品的协同过滤(详细请参考上一期推荐系统基础的组队学习), 在多路召回部分会加上关联规则的召回策略"""
user_item_time_dict = get_user_item_time(df)
# 计算物品相似度i2i_sim = {}item_cnt = defaultdict(int)for user, item_time_list in tqdm(user_item_time_dict.items()):# 在基于商品的协同过滤优化的时候可以考虑时间因素for i, i_click_time in item_time_list:item_cnt[i] += 1i2i_sim.setdefault(i, {})for j, j_click_time in item_time_list:if(i == j):continuei2i_sim[i].setdefault(j, 0)i2i_sim[i][j] += 1 / math.log(len(item_time_list) + 1)i2i_sim_ = i2i_sim.copy()for i, related_items in i2i_sim.items():for j, wij in related_items.items():i2i_sim_[i][j] = wij / math.sqrt(item_cnt[i] * item_cnt[j])# 将得到的相似性矩阵保存到本地pickle.dump(i2i_sim_, open(save_path + 'itemcf_i2i_sim.pkl', 'wb'))return i2i_sim_
7 APScheduler框架
简介
Advanced Python Scheduler (APScheduler) 是一个 Python 库,可让您安排 Python
代码稍后执行,可以只执行一次,也可以定期执行。您可以随意添加新工作或删除旧工作。如果您将任务存储在数据库中,它们也将在调度器重新启动后幸存下来并保持其状态。当调度器重新启动时,它将运行它在离线时应该运行的所有任务。
除此之外,APScheduler 可以用作跨平台、特定于应用程序的平台特定调度器的替代品,例如 cron 守护程序或 Windows
任务调度器。但是请注意,APScheduler
本身不是守护程序或服务,也不附带任何命令行工具。它主要用于在现有应用程序中运行。也就是说,APScheduler
确实为您提供了一些构建块来构建调度器服务或运行专用调度器进程。
安装
pip安装:
pip install apscheduler
本项目相关使用:
from apscheduler.schedulers.blocking import BlockingScheduler
from Recommend.NewsRecommendByCity import beginrecommendbycity
from Recommend.NewsRecommendByHotValue import beginrecommendbyhotvalue
from Recommend.NewsRecommendByTags import beginNewsRecommendByTags
from Recommend.NewsKeyWordsSelect import beginSelectKeyWord
from Recommend.NewsHotValueCal import beginCalHotValue
from Recommend.NewsCorrelationCalculation import beginCorrelation
from Recommend.HotWordLibrary import beginHotWordLibrary
sched = BlockingScheduler()sched2 = BlockingScheduler()
def beginRecommendSystem(time):
'''
@Description:推荐系统启动管理器(基于城市推荐、基于热度推荐、基于新闻标签推荐)
@:param time --> 时间间隔
'''
sched.add_job(func=beginrecommendbycity, trigger='interval', max_instances=1, seconds=int(time),
id='NewsRecommendByCity',
kwargs={})
sched.add_job(beginrecommendbyhotvalue, 'interval', max_instances=1, seconds=int(time),
id='NewsRecommendByHotValue',
kwargs={})
sched.add_job(beginNewsRecommendByTags, 'interval', max_instances=1, seconds=int(time), id='NewsRecommendByTags',
kwargs={})
sched.start()
def stopRecommendSystem():
'''
@Description:推荐系统关闭管理器
@:param None
'''
sched.remove_job('NewsRecommendByCity')
sched.remove_job('NewsRecommendByHotValue')
sched.remove_job('NewsRecommendByTags')
def beginAnalysisSystem(time):
'''
@Description:数据分析系统启动管理器(关键词分析、热词分析、新闻相似度分析、热词统计)
@:param time --> 时间间隔
'''
sched2.add_job(beginSelectKeyWord, trigger='interval', max_instances=1, seconds=int(time),
id='beginSelectKeyWord',
kwargs={"_type": 2})
sched2.add_job(beginCalHotValue, 'interval', max_instances=1, seconds=int(time),
id='beginCalHotValue',
kwargs={})
sched2.add_job(beginCorrelation, 'interval', max_instances=1, seconds=int(time), id='beginCorrelation',
kwargs={})
sched2.add_job(beginHotWordLibrary, 'interval', max_instances=1, seconds=int(time), id='beginHotWordLibrary',
kwargs={})
sched2.start()
def stopAnalysisSystem():'''@Description:数据分析系统关闭管理器@:param None'''sched2.remove_job('beginSelectKeyWord')sched2.remove_job('beginCalHotValue')sched2.remove_job('beginCorrelation')sched2.remove_job('beginHotWordLibrary')sched2.shutdown()
7 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机竞赛 python 爬虫与协同过滤的新闻推荐系统
1 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 python 爬虫与协同过滤的新闻推荐系统 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 该项目较为新颖&…...

如何使用Kali Linux进行密码破解?
今天我们探讨Kali Linux的应用,重点是如何使用它来进行密码破解。密码破解是渗透测试中常见的任务,Kali Linux为我们提供了强大的工具来帮助完成这项任务。 1. 密码破解简介 密码破解是一种渗透测试活动,旨在通过不同的方法和工具来破解密码…...
【Freertos基础教程】任务管理之基本使用
文章目录 前言一、freertos任务管理是什么?二、任务管理涉及到的一些概念1.任务状态2.优先级3.栈(Stack)4.事件驱动5.协助式调度(Co-operative Scheduling) 二、任务的基本操作1.创建任务什么是任务 2.创建任务3.任务的删除4.任务的调度3.简单示例 总结 前言 本fre…...

VMware安装BC-linux-eluer 21.10,配置网络
参考配置:https://hiworld.blog.csdn.net/article/details/121608950 /etc/sysconfig/network-scripts/ifcfg-ens33 配置内容如下: TYPEEthernet PROXY_METHODnone BROWSER_ONLYno BOOTPROTOstatic DEFROUTEyes IPV4_FAILURE_FATALno IPV6INITyes IPV6_…...
2023最新Windows编译ffmpeg详细教程,附msys2详细安装配置教程
安装MSYS2 msys2是一款跨平台编译套件,它模拟linux编译环境,支持整合mingw32和mingw64,能很方便的在windows上对一些开源的linux工程进行编译运行。 类似的跨平台编译套件有:msys,cygwin,mingw 优势&…...

【SpringBoot】87、SpringBoot中集成Redisson实现Redis分布式锁
1、Redisson 介绍 Redisson 是架设在 Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid)。Redisson 在基于 NIO 的 Netty 框架上,充分的利用了 Redis 键值数据库提供的一系列优势,在 Java 实用工具包中常用接口的基础上,为使用者提供了一系列具有分布式特性的…...

宝藏级画图工具-drawio
今天推荐一款非常好用的免费开源画图工具drawio. Drawio即可以下载安装到本地,也可以在线编辑,在线编辑网址为 https://app.diagrams.net/。 本地版下载地址为https://github.com/jgraph/drawio-desktop/releases 1、支持各类图形 Drawio可以非常便捷…...

36_windows环境debug Nginx 源码-使用 VSCode 和WSL
文章目录 配置 WSL编译 NginxVSCode 安装插件launch.json配置 WSL sudo apt-get -y install gcc cmake sudo apt-get -y install pcre sudo apt-get -y install libpcre3 libpcre3-dev sudo apt-get...

海康威视iVMS综合安防系统任意文件上传(0Day)
漏洞描述 攻击者通过请求/svm/api/external/report接口任意上传文件,导致获取服务器webshell权限,同时可远程进行恶意代码执行。 免责声明 技术文章仅供参考,任何个人和组织使用网络应当遵守宪法法律,遵守公共秩序,尊重社会公德,不得利用网络从事危害国家安全、荣誉和…...

SOME/IP通信对数据包的大小有要求
SOME/IP通信对数据包的大小有要求,因为SOME/IP是基于UDP协议的,而UDP协议有一个最大传输单元(MTU)的限制,即每个数据包的大小不能超过MTU的值。 不同的网络环境下,MTU的值可能不同,一般在1500字节到9000字节之间。 如果SOME/IP数据包的大小超过了MTU的值,那么就需要进…...
苹果电脑会自动清理垃圾吗 苹果电脑系统垃圾怎么清除
苹果电脑是很多人喜欢使用的一种电脑,它有着优美的外观,流畅的操作系统,丰富的应用程序和高效的性能。但是,随着时间的推移,苹果电脑也会产生一些不必要的文件和数据,这些文件和数据就是我们常说的垃圾。那…...
资源初始化之获取IPV4套接字地址信息(2))
【0216】stats collector(统计信息收集器)资源初始化之获取IPV4套接字地址信息(2)
相关阅读: 【0215】stats collector(统计信息收集器)工作原理之资源初始化(1) 1. 如何获取ipv4套接字地址信息 在【0215】stats collector(统计信息收集器)工作原理之资源初始化(1)一文的2.1.3节中讲解了stats collector进程会创建UDP,与其他进程进行通信,从而实现…...
)
uni-app 面容、指纹识别插件(uni-face-login)
面容、指纹识别插件(uni-face-login) 介绍 人脸指纹登录授权,可以使用手机自带的人脸、指纹进行生物识别,进而判断是否机主本人,从而进行授权验证,适配安卓、iOS、鸿蒙设备 猛戳这里去插件市场看看 使用 该插件支持鸿蒙、安卓…...
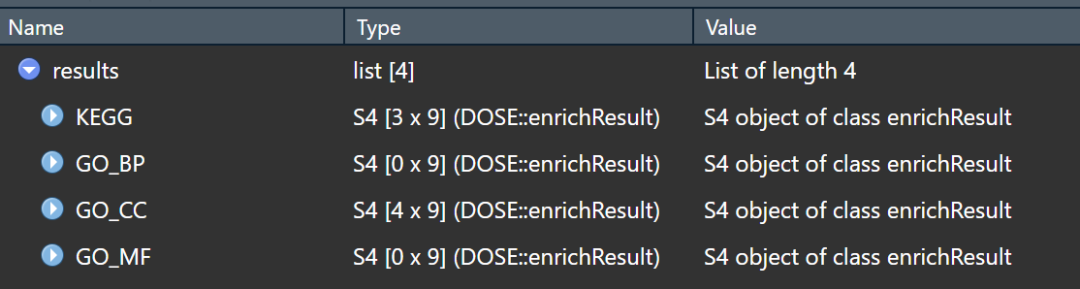
专治疗懒病:GO、KEGG富集分析一体函数
之前我们写过GO、KEGG的富集分析,参见:补充更新:GO、KEGG(批量分组)分析及可视化。演示了差异基因KEGG或者GO的分析流程。其实差异基因的富集分析输入的文件只需要一组基因就可以了。所以我们发挥了专治懒病的优良传统…...
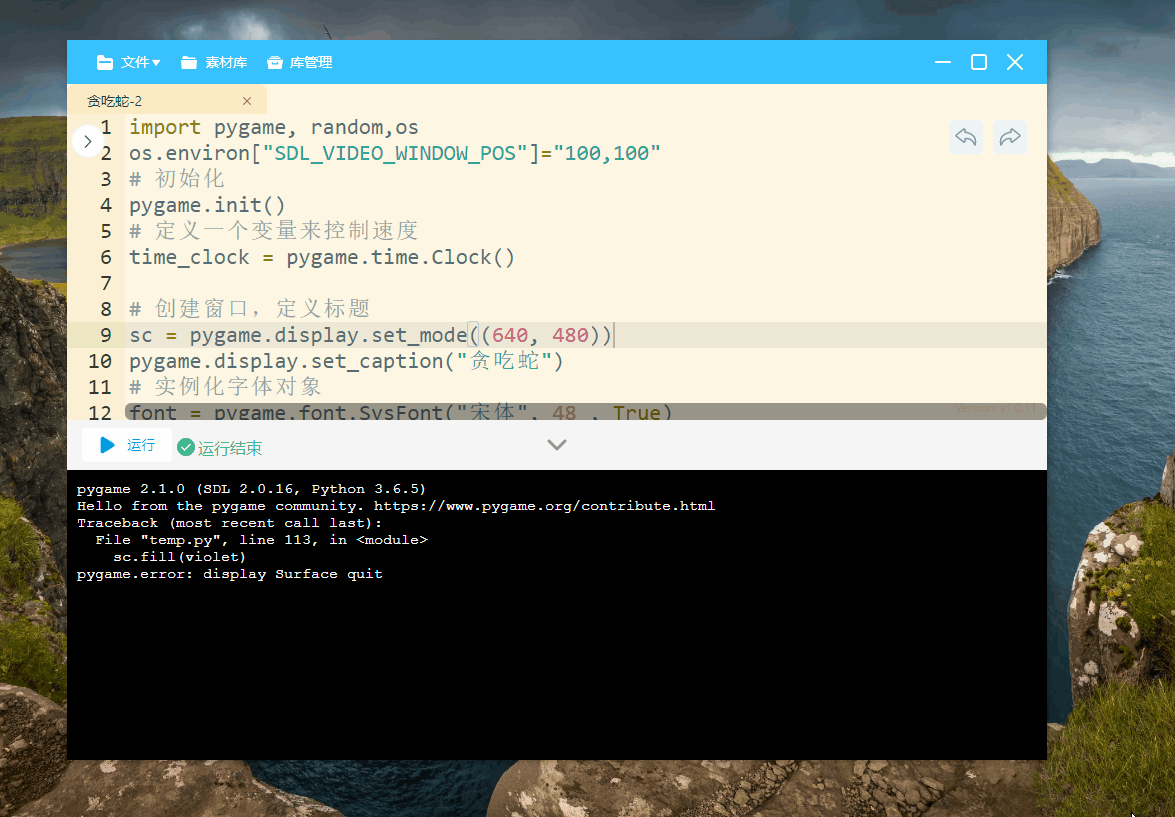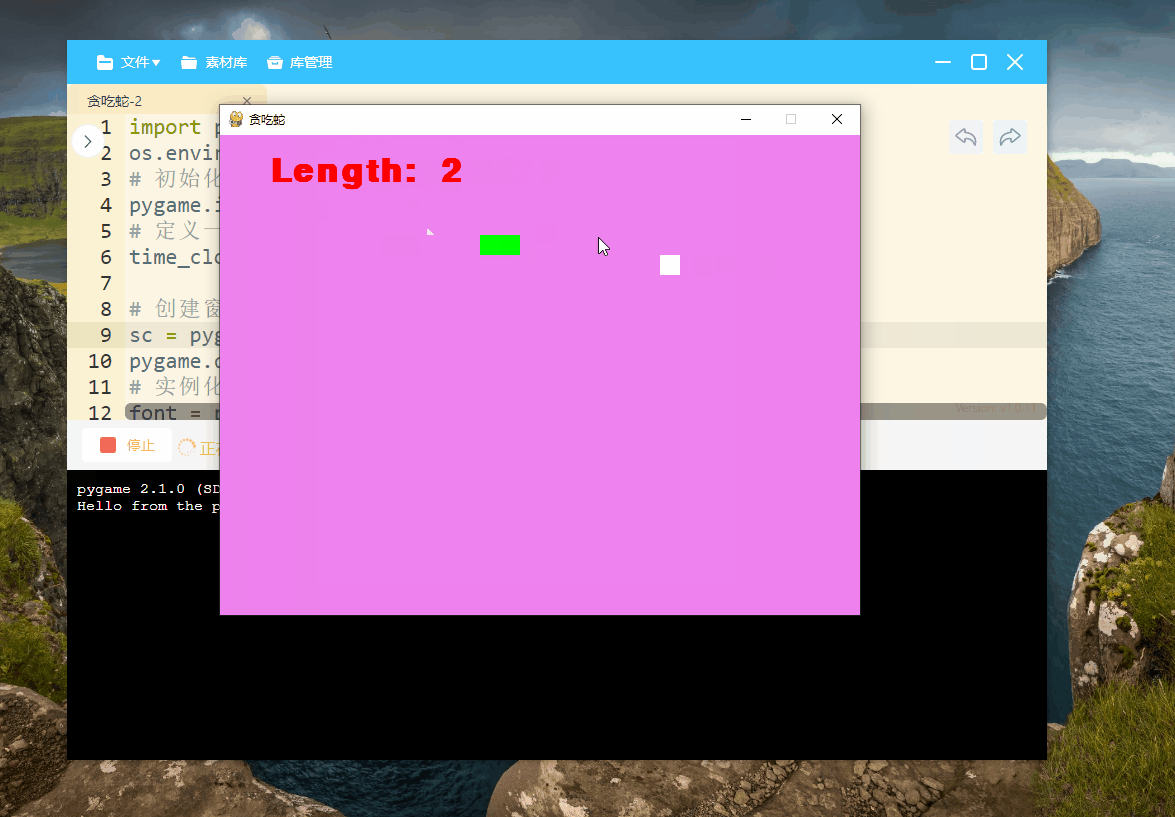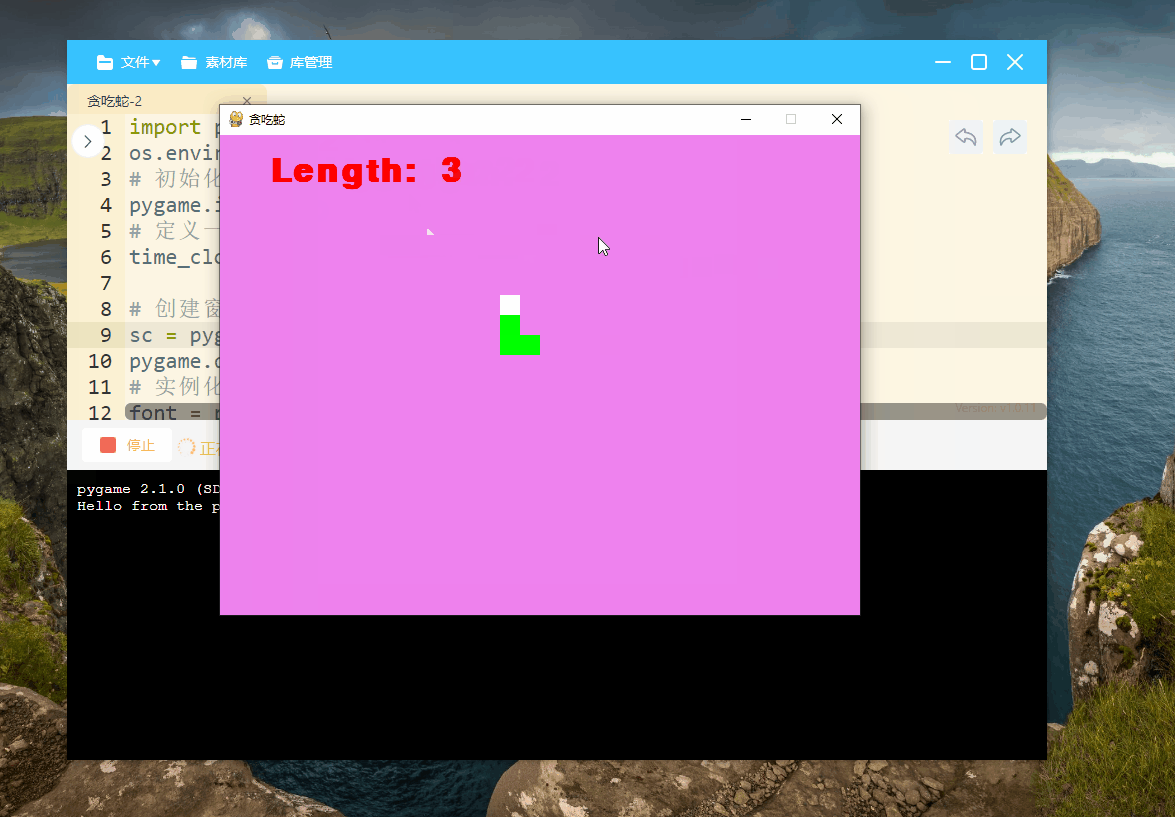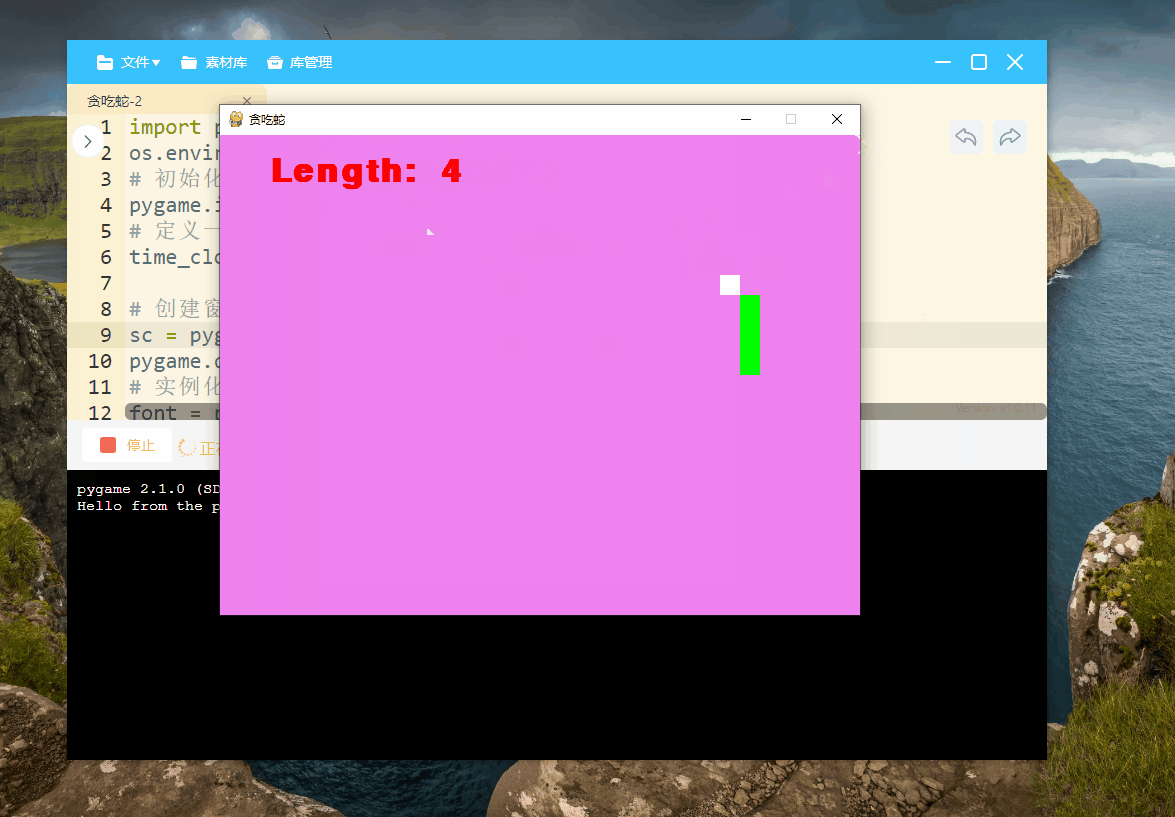
pygame第6课——贪吃蛇小游戏
今天我们开始Pygame的第六课,前几节课的内容在这里【点我】,欢迎大家前去考古: 今天我们一起来学习制作一个小游戏【贪吃蛇】,这是一个非常经典的小游戏,那么我们一起开始吧 1、游戏准备工作 import pygame, random,o…...
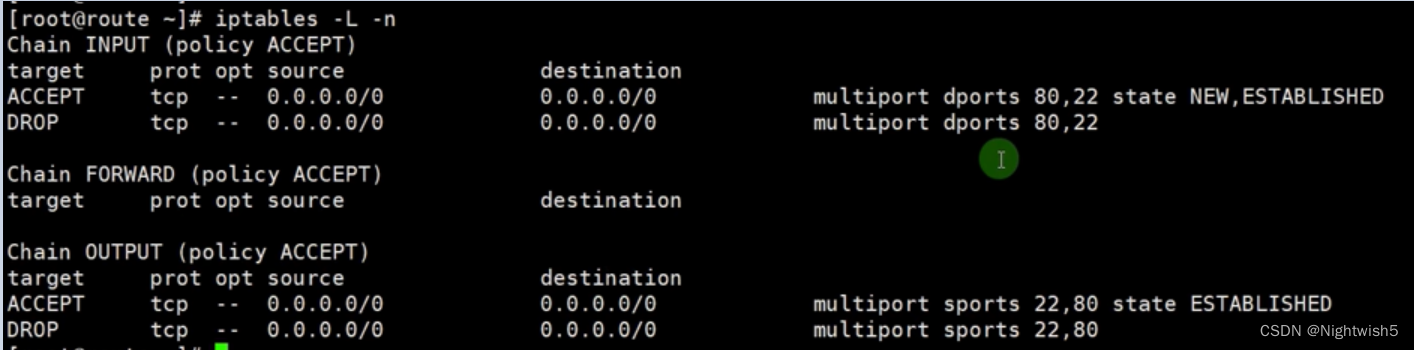
iptables之iptables表、链、规则 、匹配模式、扩展模块、连接追踪模块(一)
一、iptables的链 1.请求到达本机: PREROUTING --> INPUT --> Local Process (本机) 2.请求经过本机: PREROUTING --> FORWARD --> POSTROUTING 3.请求从本机发出:local Process(本机…...

Mac 卸载appium
安装了最新版的appium 2.0.1,使用中各种问题,卡顿....,最终决定回退的。记录下卸载的过程 1.打开终端应用程序 2.卸载全局安装的 Appium 运行以下命令以卸载全局安装的 Appium: npm uninstall -g appium 出现报错:Error: EACCES: permiss…...

数据结构----哈夫曼树
这里写目录标题 基本概念引子基本概念各种路径长度各种带权路径长度结点的带权路径长度树的带权路径长度哈夫曼树 哈夫曼树的构造理论基础构造思想总结 哈夫曼树的实现哈夫曼编码前缀编码哈夫曼编码的思想案例代码实现 编码与解码 基本概念 引子 哈夫曼树就是寻找构造最优二叉…...
--使用/教程/实例)
Spring之Aop切面---日志收集(环绕处理、前置处理方式)--使用/教程/实例
Spring之Aop切面---日志收集(环绕处理、前置处理方式)--使用/教程/实例 简介系统登录日志类LoginLogEntity .java 一、环绕处理方式1、自定义注解类LoginLogAop.class2、切面处理类LogoutLogAspect.java 二、前置处理方式:1、自定义注解类Log…...

UE4/UE5 照明构建失败 “Lightmass crashed”解决“数组索引越界”
在构建全局光照时,经常会出现“Lightmass crashed”的错误,导致光照构建失败。本文将分析这一问题的原因,并给出解决建议。 UE4 版本4.26 报错如下: <None> Lightmass crashed: Assertion failed: (Index > 0) & (Index < ArrayNum) [File:d:\bu…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器
3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为热门PC游戏不支…...

LaTeX公式一键转Word:3步告别数学公式编辑烦恼
LaTeX公式一键转Word:3步告别数学公式编辑烦恼 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为Word文档中的数学公式编辑而抓狂…...

php有什么版本,php语言有几个版本
php有什么版本,php语言有几个版本PHP的大版本主要分四支:PHP4/PHP5/PHP6/PHP7 其中,PHP4由于太古老、对OO支持不力已基本被淘汰,请无视PHP4。 PHP6由于基本没有生产线上的应用,还基本只是一款概念产品,很多功能已在PHP…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...
)
微信聊天图片丢了别慌!保姆级教程:找回并解密DAT文件(支持新旧版微信路径)
微信DAT图片恢复实战:从文件定位到批量解密的完整指南 微信聊天记录中的图片突然消失?别急着放弃!那些看似无法打开的DAT文件里,可能藏着您的重要回忆或工作资料。本文将带您深入微信存储机制,手把手完成从文件定位到…...

5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南
5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS…...

CentOS 8/Stream 8系统DNF换源后,安装软件还是慢?试试这几个排查命令和优化技巧
CentOS 8/Stream 8系统DNF换源后安装缓慢的深度排查与优化指南当你已经按照教程将CentOS 8/Stream 8的DNF源切换为国内镜像,却发现软件安装速度依然不尽如人意时,这种体验确实令人沮丧。作为长期使用CentOS系统的技术专家,我完全理解这种&quo…...