repmgr出现双主,并且时间线分叉,删除了最新的时间线节点
遇到的问题如下:
2023-08-17 20:24:21.566 CST [1556001] LOG: database system was interrupted; last known up at 2023-08-17 20:21:41 CST
2023-08-17 20:24:21.770 CST [1556001] LOG: restored log file "00000009.history" from archive
cp: 无法获取'/home/postgres/pgarch/0000000A.history' 的文件状态(stat): 没有那个文件或目录
2023-08-17 20:24:21.771 CST [1556001] LOG: entering standby mode
2023-08-17 20:24:21.772 CST [1556001] LOG: restored log file "00000009.history" from archive
cp: 无法获取'/home/postgres/pgarch/000000090000010200000066' 的文件状态(stat): 没有那个文件或目录
2023-08-17 20:24:21.784 CST [1556001] LOG: restored log file "000000080000010200000066" from archive
2023-08-17 20:24:21.851 CST [1556001] FATAL: requested timeline 9 is not a child of this server's history
2023-08-17 20:24:21.851 CST [1556001] DETAIL: Latest checkpoint is at 102/66000060 on timeline 8, but in the history of the requested timeline, the server forked off from that timeline at 102/580000A0.
2023-08-17 20:24:21.851 CST [1555991] LOG: startup process (PID 1556001) exited with exit code 1
2023-08-17 20:24:21.851 CST [1555991] LOG: aborting startup due to startup process failure
2023-08-17 20:24:21.851 CST [1555991] LOG: database system is shut down
出现上面的原因是repmgr出现了双主。
在db206的主机上修改了shared_preload_libraries = 'pg_stat_statements',试图重启,发现无法启动(没有提前创建pg_stat_statements扩展)导致。
[postgres@db206 data]$ vi postgresql.conf
[postgres@db206 data]$ pg_ctl restart
waiting for server to shut down...... done
server stopped
waiting for server to start....2023-08-17 18:11:53.086 CST [6497] FATAL: could not access file "pg_stat_statements": 没有那个文件或目录
2023-08-17 18:11:53.086 CST [6497] LOG: database system is shut down
stopped waiting
pg_ctl: could not start server
这个时候 vi postgresql.conf 把shared_preload_libraries = 'pg_stat_statements'去掉,再次启动数据库,可以启动,试图创建,这个时候备机已经接管主机了
这个时候想起来先去修改db223的shared_preload_libraries = 'pg_stat_statements'(先在备机上给加上)
[postgres@db223 ~]$ vi pg14/data/postgresql.conf
这个时候发现出现了双主(暂时还不知道为什么会出现双主),这个时候时间线也不一样,新主是9,旧主是8
[postgres@db206 data]$ repmgr -f ~/repmgr/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+----------------------+----------+----------+----------+----------+------------------------------------------------------------------------
1 | db223 | standby | ! running as primary | | default | 100 | 9 | host=db223 dbname=repmgr user=repmgr password=repmgr connect_timeout=2
2 | db206 | primary | * running | | default | 100 | 8 | host=db206 dbname=repmgr user=repmgr password=repmgr connect_timeout=2WARNING: following issues were detected
- node "db223" (ID: 1) is registered as standby but running as primary

试图对从节点进行重新注册操作,提示需要先启动数据库。
[postgres@db206 data]$ repmgr -f /home/postgres/repmgr/repmgr.conf standby unregister
INFO: connecting to local standby
ERROR: connection to database failed
DETAIL:
connection to server at "db206" (172.20.101.206), port 5432 failed: Connection refused
Is the server running on that host and accepting TCP/IP connections?DETAIL: attempted to connect using:
user=repmgr password=repmgr connect_timeout=2 dbname=repmgr host=db206 fallback_application_name=repmgr options=-csearch_path=
启动之后重新执行命令,又提示现在是主节点。
[postgres@db206 data]$ repmgr -f /home/postgres/repmgr/repmgr.conf standby unregister
INFO: connecting to local standby
INFO: connecting to primary database
ERROR: node 2 is not a standby server
然后试图对主节点执行注销操作,又说db233节点仍然将此节点作为其上游节点。提示:使用“repmgr standby follow”确保这些节点遵循当前的主节点。
[postgres@db206 data]$ repmgr -f /home/postgres/repmgr/repmgr.conf primary unregister
ERROR: 1 other node still has this node as its upstream node
HINT: ensure these nodes are following the current primary with "repmgr standby follow"
DETAIL: the affected node(s) are:
db223 (ID: 1)
这个时候对db223重新加入集群,发现不能在正在运行的节点上执行
[postgres@db223 ~]$ repmgr -f ~/repmgr/repmgr.conf node rejoin -d 'host=db206 port=5432 user=repmgr dbname=repmgr password=repmgr'
ERROR: database is still running in state "in production"
HINT: "repmgr node rejoin" cannot be executed on a running node
停止数据库后,再次执行,这个时候没有报错
[postgres@db223 ~]$ repmgr -f ~/repmgr/repmgr.conf node rejoin -d 'host=db206 port=5432 user=repmgr dbname=repmgr password=repmgr' -F
NOTICE: rejoin target is node "db206" (ID: 2)
NOTICE: pg_rewind execution required for this node to attach to rejoin target node 2
HINT: provide --force-rewind
重新启动db223,发现还是作为主节点加入,这就很崩溃了。
pg_ctl start
[postgres@db223 ~]$ repmgr -f ~/repmgr/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+------------------------------------------------------------------------
1 | db223 | primary | * running | | default | 100 | 9 | host=db223 dbname=repmgr user=repmgr password=repmgr connect_timeout=2
2 | db206 | primary | ! running | | default | 100 | 8 | host=db206 dbname=repmgr user=repmgr password=repmgr connect_timeout=2WARNING: following issues were detected
- node "db206" (ID: 2) is running but the repmgr node record is inactive

这个时候加上pg_rewind操作是不是就好了呢,发现还是不行,无法读到时间线9的,不知道为什么要读9的时间线,估计还是作为主节点加入吧。
[postgres@db223 ~]$ repmgr -f ~/repmgr/repmgr.conf node rejoin -d 'host=db206 port=5432 user=repmgr dbname=repmgr password=repmgr' --force-rewind
NOTICE: rejoin target is node "db206" (ID: 2)
NOTICE: executing pg_rewind
DETAIL: pg_rewind command is "/home/postgres/pg14/bin/pg_rewind -D '/home/postgres/pg14/data' --source-server='host=db206 dbname=repmgr user=repmgr password=repmgr connect_timeout=2'"
ERROR: pg_rewind execution failed
DETAIL: pg_rewind: servers diverged at WAL location 102/580000A0 on timeline 8
pg_rewind: error: could not open file "/home/postgres/pg14/data/pg_wal/000000090000010200000058": 没有那个文件或目录
pg_rewind: fatal: could not find previous WAL record at 102/580000A0

最终极的方法是删掉重建,这个时候删掉的是时间线9的,虽然重建好了,但是pg_ctl start无法启动。
[postgres@db223 data]$ rm -rf *
[postgres@db223 data]$ ll
总用量 0
[postgres@db223 data]$ repmgr -h db206 -U repmgr -d repmgr -f /home/postgres/repmgr/repmgr.conf standby clone
NOTICE: destination directory "/home/postgres/pg14/data" provided
INFO: connecting to source node
DETAIL: connection string is: host=db206 user=repmgr dbname=repmgr
DETAIL: current installation size is 12 GB
INFO: replication slot usage not requested; no replication slot will be set up for this standby
NOTICE: checking for available walsenders on the source node (2 required)
NOTICE: checking replication connections can be made to the source server (2 required)
INFO: checking and correcting permissions on existing directory "/home/postgres/pg14/data"
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
INFO: executing:
/home/postgres/pg14/bin/pg_basebackup -l "repmgr base backup" -D /home/postgres/pg14/data -h db206 -p 5432 -U repmgr -X stream
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /home/postgres/pg14/data start
HINT: after starting the server, you need to re-register this standby with "repmgr standby register --force" to update the existing node record
[postgres@db223 data]$ ^C
[postgres@db223 data]$ pg_ctl start
waiting for server to start....2023-08-17 19:48:33.265 CST [1532642] LOG: redirecting log output to logging collector process
2023-08-17 19:48:33.265 CST [1532642] HINT: Future log output will appear in directory "log".
stopped waiting
pg_ctl: could not start server
查看log日志就是开头的,还是要读取时间线9,但是主库db203是没有时间线8的。又崩溃了。。。
2023-08-17 20:24:21.566 CST [1556001] LOG: database system was interrupted; last known up at 2023-08-17 20:21:41 CST
2023-08-17 20:24:21.770 CST [1556001] LOG: restored log file "00000009.history" from archive
cp: 无法获取'/home/postgres/pgarch/0000000A.history' 的文件状态(stat): 没有那个文件或目录
2023-08-17 20:24:21.771 CST [1556001] LOG: entering standby mode
2023-08-17 20:24:21.772 CST [1556001] LOG: restored log file "00000009.history" from archive
cp: 无法获取'/home/postgres/pgarch/000000090000010200000066' 的文件状态(stat): 没有那个文件或目录
2023-08-17 20:24:21.784 CST [1556001] LOG: restored log file "000000080000010200000066" from archive
2023-08-17 20:24:21.851 CST [1556001] FATAL: requested timeline 9 is not a child of this server's history
2023-08-17 20:24:21.851 CST [1556001] DETAIL: Latest checkpoint is at 102/66000060 on timeline 8, but in the history of the requested timeline, the server forked off from that timeline at 102/580000A0.
2023-08-17 20:24:21.851 CST [1555991] LOG: startup process (PID 1556001) exited with exit code 1
2023-08-17 20:24:21.851 CST [1555991] LOG: aborting startup due to startup process failure
2023-08-17 20:24:21.851 CST [1555991] LOG: database system is shut down
这个时候看了看db223的参数,是不是读取的归档路径不对,然后就看到基于时间线恢复recovery_target_timeline参数
archive_mode = on
archive_command = 'scp %p postgres@172.20.101.208:/home/postgres/pgarch/%f'
archive_cleanup_command = 'pg_archivecleanup /home/postgres/pgarch %r'
restore_command = 'cp /home/postgres/pgarch/%f %p'
recovery_target_timeline = 'latest'
修改了recovery_target_timeline = 'current'之后,再次启动db223就好了。
[postgres@db206 ~]$ repmgr -f ~/repmgr/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+------------------------------------------------------------------------
1 | db223 | standby | running | db206 | default | 100 | 8 | host=db223 dbname=repmgr user=repmgr password=repmgr connect_timeout=2
2 | db206 | primary | * running | | default | 100 | 8 | host=db206 dbname=repmgr user=repmgr password=repmgr connect_timeout=2
总结:
1、暂时还不知道为什么会出现双主,这个还需要复现一下。
2、考虑加一个见证节点(不知道能不能预防双主的出现),有待研究。
3、对recovery_target_timeline 知其然而不知所以然,抽空研究一下。
4、对recovery_target_timeline 在备机上修改完current之后,是否还需要再修改成laster(个人认为是不需要的)。
5大概看了一眼如下博客,解决的很顺利????
repmgr 集群双主问题处理
repmgr 集群双主问题处理_repmgr 把主库down 了_瀚高PG实验室的博客-CSDN博客
相关文章:

repmgr出现双主,并且时间线分叉,删除了最新的时间线节点
遇到的问题如下: 2023-08-17 20:24:21.566 CST [1556001] LOG: database system was interrupted; last known up at 2023-08-17 20:21:41 CST 2023-08-17 20:24:21.770 CST [1556001] LOG: restored log file "00000009.history" from archive cp: 无法…...

ThinkPHP中实现IP地址定位
在网站开发中,我们经常需要获取用户的地理位置信息以提供个性化的服务。一种常见的方法是通过IP地址定位。在本文中,我们将介绍如何在ThinkPHP框架中实现IP地址定位。 一、IP地址定位的基本原理 IP地址是Internet上的设备在网络中的标识符。每个设备都有…...

使用Python批量将Word文件转为PDF文件
说明:在使用Minio服务器时,无法对word文件预览,如果有需要的话,可以将word文件转为pdf文件,再存储到Minio中,本文介绍如何批量将word文件,转为pdf格式的文件; 安装库 首先ÿ…...

XDR解决方案成为了新的安全趋势
和当今指数倍增长的安全数据相比,安全人才的短缺带来了潜在的风险。几乎所有的公司,无论规模大小,在安全资源能力上都有限,需要过滤各种告警才能将分析量保持在可接受范围。但这样一来,潜在的威胁线索就可能被埋没&…...
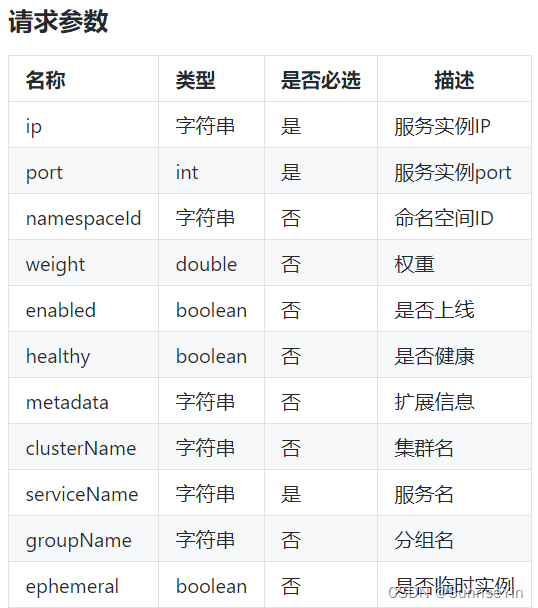
001-Nacos 服务注册
目录 Nacos介绍注册中心架构面临问题源码分析实例注册-接口实例注册-入口实例注册-创建一个(Nacos)Service实例注册-注册(Nacos)Service Nacos 介绍 Dynamic Naming and Configuration Service 动态的命名和配置服务 反正可以实现注册中心的功能 注册中心架构 服务提供者 …...
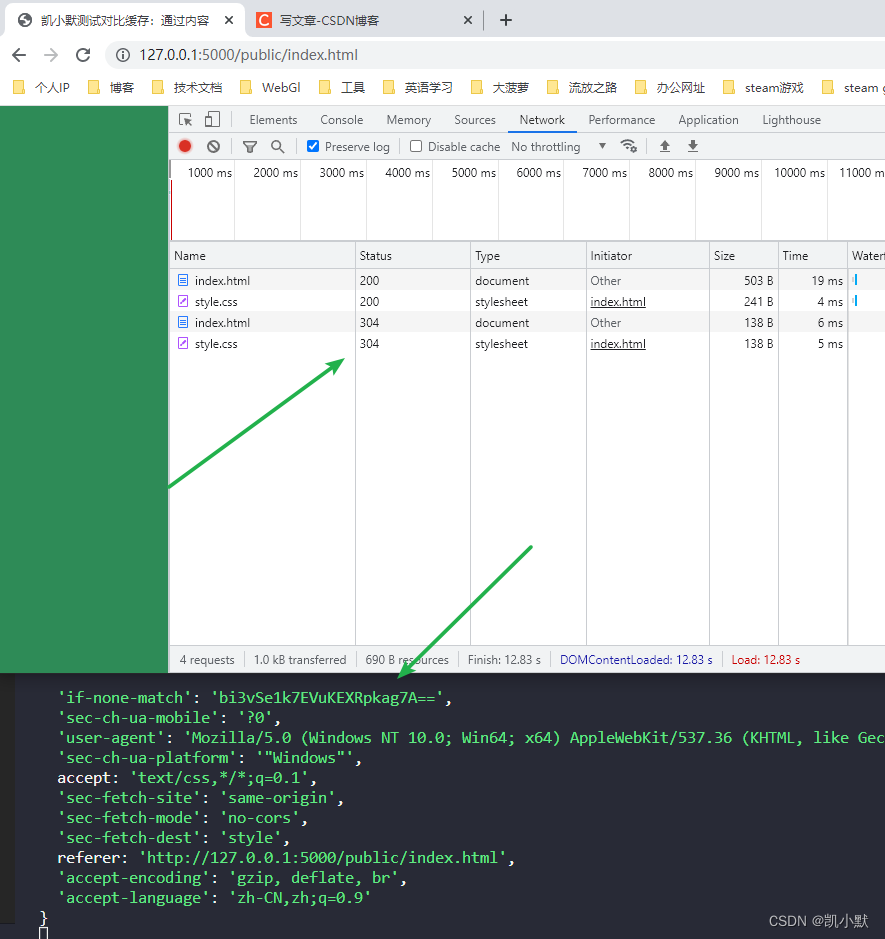
71 # 协商缓存的配置:通过内容
对比(协商)缓存 比较一下再去决定是用缓存还是重新获取数据,这样会减少网络请求,提高性能。 对比缓存的工作原理 客户端第一次请求服务器的时候,服务器会把数据进行缓存,同时会生成一个缓存标识符&#…...

【服务器】Strace显示后台进程输出
今天有小朋友遇到一个问题 她想把2331509和2854637这两个进程调到前台来,以便于在当前shell查看这两个python进程的实时输出 我第一反应是用jobs -l然后fg (参考这里) 但是发现jobs -l根本没有输出: 原因是jobs看的是当前ses…...

centos如何安装libssl-dev libsdl-dev libavcodec-dev libavutil-dev ffmpeg
在 CentOS 系统上安装这些包可以按照以下步骤进行: 打开终端,使用 root 或具有管理员权限的用户登录。 使用以下命令安装 libssl-dev 包: yum install openssl-devel使用以下命令安装 libsdl-dev 包: yum install SDL-devel使用以…...

2022年12月 C/C++(二级)真题解析#中国电子学会#全国青少年软件编程等级考试
第1题:数组逆序重放 将一个数组中的值按逆序重新存放。例如,原来的顺序为8,6,5,4,1。要求改为1,4,5,6,8。 输入 输入为两行:第一行数组中元素的个数n(1 输出 输出为一行:输出逆序后数组的整数,每两个整数之间用空格分隔。 样例输入 5 8 6 5 4 1 样例输出 1 4 5 6 8 以下是…...
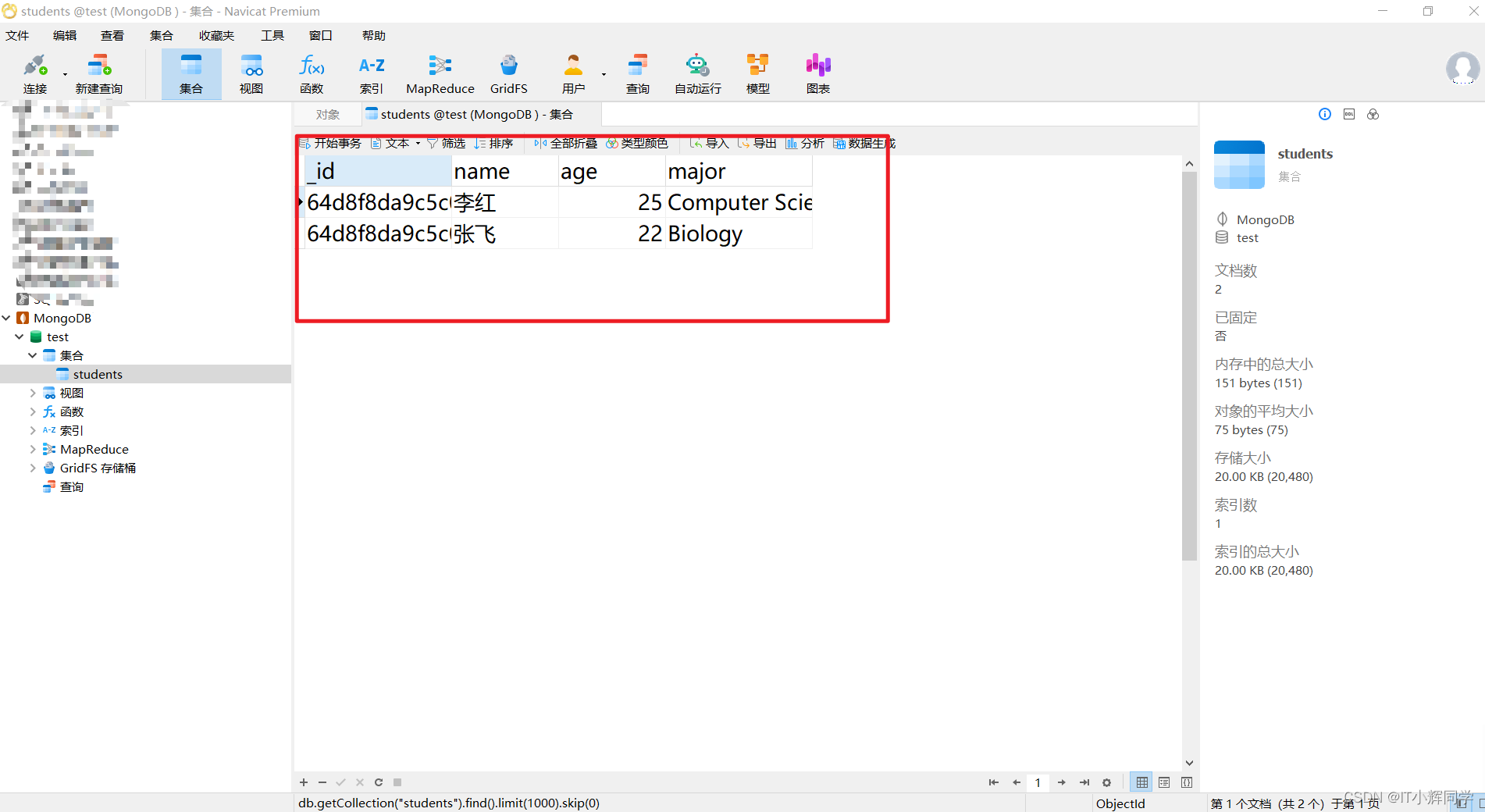
详谈MongoDB的那些事
概念区分 什么是关系型数据库 关系型数据库(Relational Database)是一种基于关系模型的数据库管理系统(DBMS)。在关系型数据库中,数据以表格的形式存储,表格由行和列组成,行表示数据记录&…...
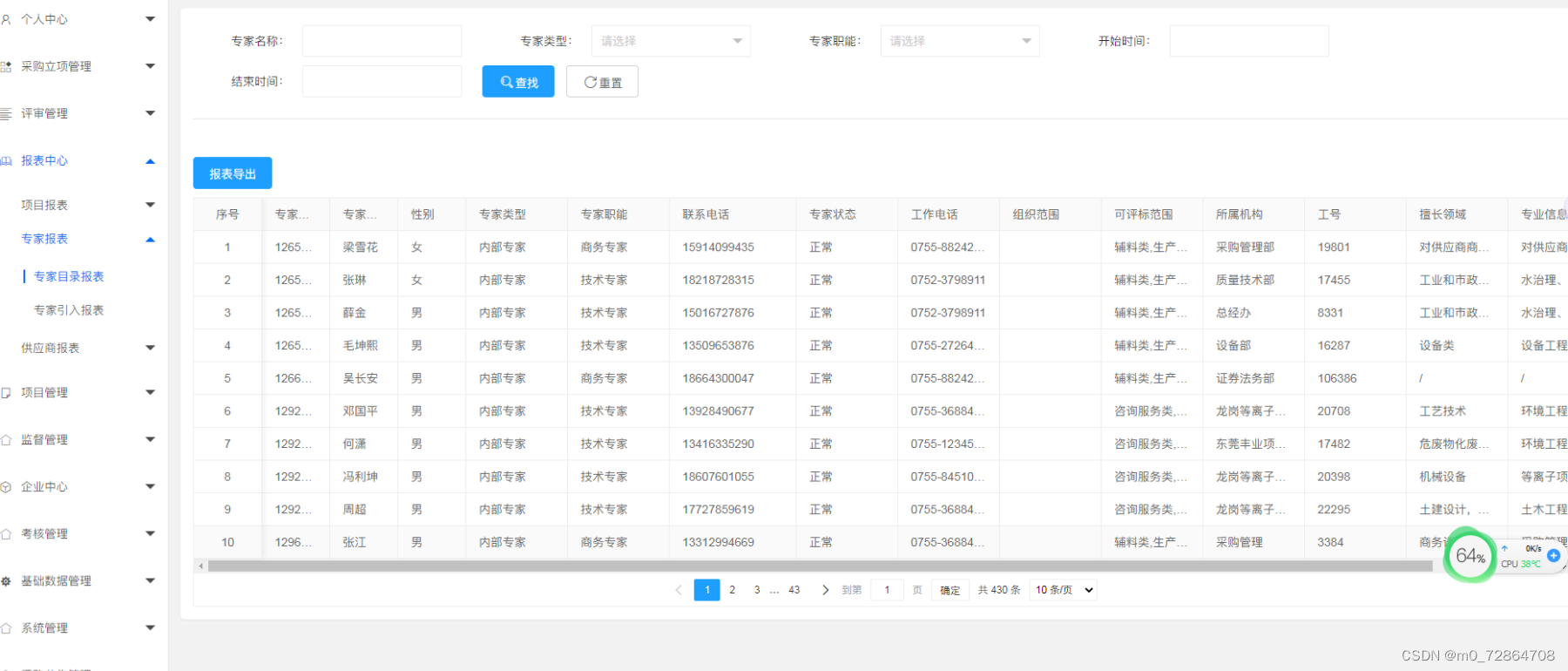
企业电子招投标采购系统源码之电子招投标的组成 tbms
功能模块: 待办消息,招标公告,中标公告,信息发布 描述: 全过程数字化采购管理,打造从供应商管理到采购招投标、采购合同、采购执行的全过程数字化管理。通供应商门户具备内外协同的能力,为…...

Android 13 添加自定义分区,恢复出厂设置不被清除
需求: 客户有些文件或数据,需要做得恢复出厂设置还存在,故需新增一个分区存储客户数据。 要求: a) 分区大小为50M b) 应用层可读可写 c) 恢复出厂设置后不会被清除 d) 不需要打包.img e) 不影响OTA升级 缺点: 1).通过代码在分区创建目录和文件,会涉及到SeLinux权限的修…...
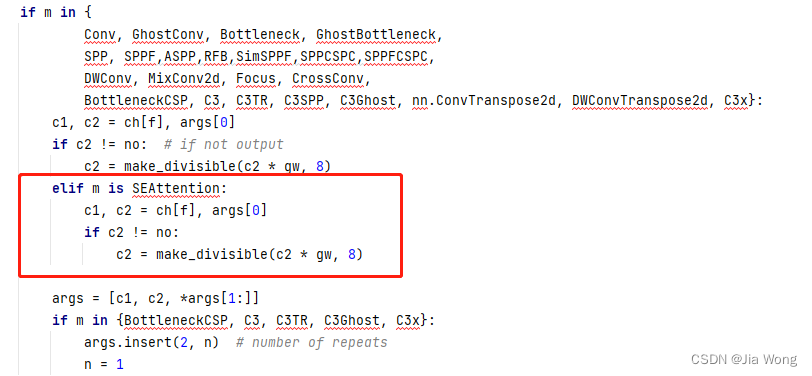
改进YOLO系列:1.添加SE注意力机制
添加SE注意力机制 1. SE注意力机制论文2. SE注意力机制原理3. SE注意力机制的配置3.1common.py配置3.2yolo.py配置3.3yaml文件配置 1. SE注意力机制论文 论文题目:Squee…...
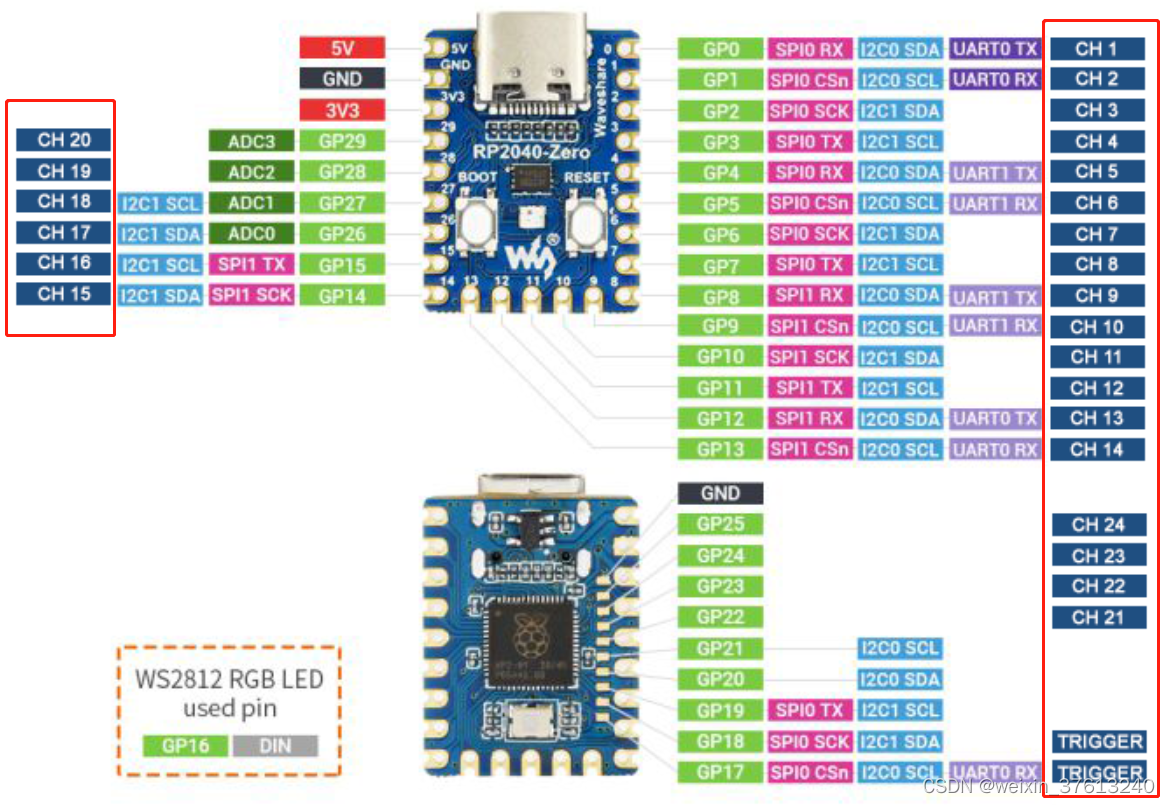
RP2040开发板自制树莓派逻辑分析仪
目录 前言 1 准备工作和前提条件 1.1 Raspberry Pi Pico RP2040板子一个 1.2 Firmware-LogicAnalyzer-5.0.0.0-PICO.uf2固件 1.3 LogicAnalyzer-5.0.0.0-win-x64软件 2 操作指南 2.1 按住Raspberry Pi Pico开发板的BOOTSEL按键,再接上USB接口到电脑 2.2 刷入…...

git clone -b与git pull origin <branch_name>的区别
git clone -b 和 git pull origin <branch_name> 都是用于在 Git 中操作分支的命令,但它们有不同的用途和行为。 git clone -b 这是在克隆仓库时指定要克隆的特定分支的命令。它用于在克隆一个仓库的同时指定要克隆的分支。例如,如果你只想克隆一…...

中期国际:MT4数据挖掘与分析方法:以数据为导向,制定有效的交易策略
在金融市场中,制定有效的交易策略是成功交易的关键。而要制定一份可靠的交易策略,数据挖掘与分析方法是不可或缺的工具。本文将介绍如何以数据为导向,利用MT4进行数据挖掘与分析,从而制定有效的交易策略。 首先,我们需…...
之bzip2)
Linux命令(70)之bzip2
linux命令之bzip2 1.bzip2介绍 linux命令bzip2是用来压缩或解压缩文件名后缀为".bz2"的文件 2.bzip2用法 bzip2 [参数] filename bzip2常用参数 参数说明-d解压缩文件-t测试压缩文件是否正确-k压缩后,保留源文件-z强制压缩-f强制覆盖已存在的文件-v显…...
ubuntu下gif动态图片的制作
Gif图片比视频小, 比静态JPG图片形象生动, 更适用于产品展示和步骤演示等。各种各样的gif动图为大家交流提供很大的乐趣. 这里简单介绍ubuntu系统下gif图的制作。 一、工具安装: kazam和ffmpeg kazam是linux下的一款简单但是功能强大的屏幕录制工具. 它可录制声音并选择全屏录…...

56.linux 进程管理命令和用户管理命令
目录 一、进程管理命令 1.ps 2.pstree 3.kill 4.pkill 5.&后台运行程序 6.jobs 7.fg bg 8.top 二、用户管理命令 1.系统存储用户信息的文件 2.添加新用户 3.修改用户密码 4.删除用户 一、进程管理命令 1.ps 用于查看当前系统中运行的进程信息。它可以…...

Mac os 上的apt-get install 就是brew install
Mac os 上面不支持apt-get install ,但是有个 brew install可以代替。 Homebrew是Mac OS的包管理器,可以方便地安装各种需要的软件。 1.1 安装Homebrew 如果没有安装Homebrew,需要在终端输入以下命令进行安装: /usr/bin/ruby -e "$(…...

金融交易实时风控系统设计与实现
金融交易实时风控系统设计与实现 一、系统架构设计 #mermaid-svg-FlrzCFrNQitt9RUO{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dash…...

【RaddbitMQ 概述】消息中间件核心概念
文章目录1. 前言2. 什么是 MQ2.1 同步通信2.2 异步通信3. MQ 的作用3.1 异步解耦3.2 流量削峰3.3 消息分发3.4 延迟通知4. 为什么选择 RabbitMQ4.1 Kafka4.2 RocketMQ4.3 RabbitMQ5. RabbitMQ介绍1. 前言 Rabbit,兔子的意思。 互联网行业很多公司,都喜…...
)
保姆级教程:如何为海思NNIE优化MobileFaceNet模型(附完整代码)
海思NNIE平台MobileFaceNet模型全流程优化实战指南 在边缘计算设备上部署高效的人脸识别模型一直是工业界的热门需求。本文将手把手带您完成从PyTorch训练到海思NNIE平台部署的完整流程,特别针对MobileFaceNet这一轻量级人脸识别模型进行深度优化。不同于普通的模型…...

Turf.js实战:从零构建一个交互式地理围栏应用
1. 认识Turf.js:地理围栏背后的技术支柱 第一次接触地理围栏需求是在2018年,当时接到一个共享单车项目的开发任务。产品经理要求在电子围栏外停车时自动触发警告,而传统方案要么依赖第三方服务(费用昂贵),要…...

Kook Zimage真实幻想Turbo作品集:这些梦幻场景竟然都是用AI画出来的
Kook Zimage真实幻想Turbo作品集:这些梦幻场景竟然都是用AI画出来的 1. 走进AI幻想艺术世界 你是否曾经幻想过这样的场景:月光下水晶翅膀的精灵在森林中起舞,或是蒸汽朋克风格的机械龙盘旋在未来都市上空?这些曾经只存在于画家笔…...

东方人像生成精度提升300%:Asian Beauty Z-Image Turbo BF16 vs FP16实测对比
东方人像生成精度提升300%:Asian Beauty Z-Image Turbo BF16 vs FP16实测对比 1. 项目简介 Asian Beauty Z-Image Turbo 是一款专门针对东方人像美学优化的本地图像生成工具。基于通义千问Tongyi-MAI Z-Image底座模型,结合Asian-beauty专用权重开发而成…...

避坑指南:Kafka多线程消费中5个最常见的Rebalance问题及解决方案
Kafka多线程消费中的Rebalance陷阱:5个实战避坑指南 当你在深夜被报警短信惊醒,发现Kafka消费者组陷入无尽的Rebalance循环时,那种绝望感就像看着高速公路上的连环追尾——明明每个环节都看似正常,系统却在不断自我崩溃。本文源自…...

Phi-3 Forest Laboratory 环境配置避坑指南:从Anaconda到模型服务
Phi-3 Forest Laboratory 环境配置避坑指南:从Anaconda到模型服务 你是不是也遇到过这种情况:好不容易找到一个心仪的AI模型,比如微软新出的Phi-3,兴致勃勃地准备跑起来试试,结果第一步环境配置就卡住了。Python版本不…...

Comsol 探索变质量注浆理论:压力与沉积颗粒、渗透率的奇妙关联
comsol变质量注浆理论,根据魏建平《裂隙煤体注浆浆液扩散规律及变质量渗流模型研究》,考虑不同注浆压力,进行了不同压力下的注浆封堵模拟,沉积颗粒浓度随着注浆压力增大会变大,渗透率负相关。最近在研究注浆相关的课题…...

【C++算法入门】贪心算法-分糖果问题
本题取自LeetCode 135题 分糖果问题一 原题复现有n个小孩,每个小孩对应一个rating条件:每个小孩至少得到一颗糖,评分高的小孩要比相邻小孩多一颗糖求:最少需要多少糖二 思路分析本题利用贪心算法,需要两次遍历贪心。…...