深度学习笔记(kaggle课程《Intro to Deep Learning》)
一、什么是深度学习?
深度学习是一种机器学习方法,通过构建和训练深层神经网络来处理和理解数据。它模仿人脑神经系统的工作方式,通过多层次的神经网络结构来学习和提取数据的特征。深度学习在图像识别、语音识别、自然语言处理等领域取得了重大突破,并被广泛应用于人工智能技术中。
深度学习原理概括
深度学习的原理可以简单地概括为以下几点:
-
神经网络结构:深度学习使用一种称为神经网络的结构。神经网络由许多称为神经元的节点组成,这些节点按层次排列。每个神经元接收来自前一层神经元的输入,并通过权重进行加权处理后传递给下一层神经元。通过多层次的连接和处理,神经网络可以学习和提取数据的复杂特征。
-
前向传播:在深度学习中,输入数据通过神经网络的各个层次,逐层进行处理和转换。这个过程称为前向传播。每一层的神经元根据输入数据和权重计算输出,并将输出传递给下一层。这样,数据的表示逐渐变得更加抽象和高级。
-
反向传播:在训练神经网络时,使用一种称为反向传播的方法来调整网络的参数。首先,通过将输入数据传递到网络中,得到预测结果。然后,将预测结果与真实标签进行比较,计算预测误差。接下来,误差以相反的方向从网络的输出层传播回输入层,更新每个神经元的权重,使得误差逐渐减小。这个过程不断重复,直到网络的预测结果足够准确。
-
梯度下降:反向传播的核心是使用梯度下降算法来调整网络的参数。梯度是指误差对于每个参数的变化率,表示了误差下降最快的方向。通过计算梯度,可以确定如何更新每个参数,使得误差逐渐减小。梯度下降算法不断迭代地调整参数,直到达到最优的参数配置,使得网络的预测结果最好。
-
大量数据和计算能力:深度学习的成功离不开大量的标记数据和强大的计算能力。通过使用大量的数据来训练神经网络,网络可以学习到更广泛、更准确的模式和特征。同时,利用并行计算和高性能硬件(如GPU)的能力,可以加速深度学习模型的训练过程。
总的来说,深度学习利用神经网络的层次结构和反向传播算法,通过大量数据和梯度下降的优化过程,学习和提取数据的复杂特征,并用于预测、分类和生成等任务。
二、如何理解神经网络?
神经网络是深度学习的核心组件,它是一种数学模型,用于模拟和处理数据的方式类似于人脑中的神经元网络。
我们可以将神经网络想象成一系列节点的集合,这些节点被称为神经元。神经元之间通过连接进行信息传递。每个神经元接收一些输入数据,对这些输入进行加权处理,并生成一个输出结果。
神经网络由多个层组成,通常包括输入层、隐藏层和输出层。输入层接收原始数据作为输入,隐藏层和输出层根据输入进行一系列计算,生成最终的输出结果。
在每个神经元中,输入数据通过权重进行加权相加,并经过一个非线性函数(例如ReLU、Sigmoid)进行激活,得到神经元的输出。这个输出将成为下一层神经元的输入,以此类推,直到最终输出层生成最终的预测结果。
训练神经网络的过程涉及调整神经元之间的权重和偏置,使得网络能够产生准确的输出。这个调整过程是通过反向传播算法来实现的,它根据预测结果与真实结果之间的差异,逐层地更新网络参数,以减小误差。
通过调整神经网络的权重和偏置,它可以逐渐学习到数据中的模式和规律,从而进行准确的预测和分类。
总的来说,神经网络是一种模拟人脑神经系统的数学模型,通过节点之间的连接和权重调整来处理和理解数据。它是深度学习的基础,用于实现数据的特征提取、模式识别和预测等任务。
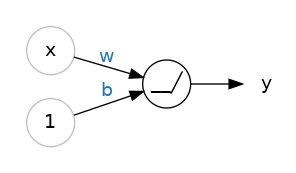
单个神经元
以图示来表示,具有一个输入的神经元(或单元)如下:
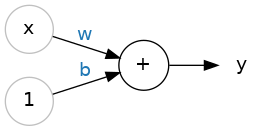
其中,
- 输入为x,权重为w,b是偏置,输出结果为y;
- 用公式表示为 y = w x + b y=wx+b y=wx+b。
也可以有多个输入, 例如这个神经元的公式 y = w 0 x 0 + w 1 x 1 + w 2 x 2 + b y=w_{0}x_{0}+w_{1}x_{1}+w_{2}x_{2}+b y=w0x0+w1x1+w2x2+b:
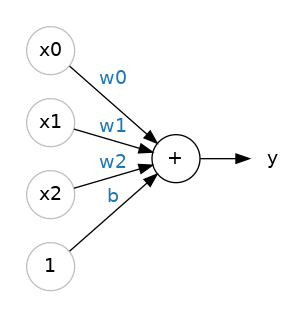
层
神经网络通常将其神经元组织成层级。当我们将具有共同输入的线性单元集合在一起时,我们得到一个稠密层。
稠密层(Dense Layer),也称为全连接层(Fully Connected Layer)或线性层,是深度神经网络中最常见的一种层。在稠密层中,每个神经元都与前一层的所有神经元相连接,从而实现了全连接。
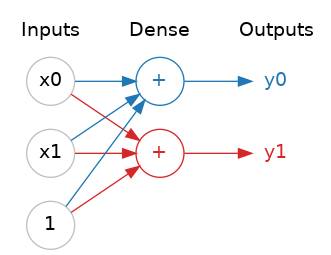
你可以将神经网络中的每一层视为执行某种相对简单的变换。通过深层堆叠的层,神经网络可以以越来越复杂的方式对其输入进行变换。在训练良好的神经网络中,每一层都是一个使我们离解决方案更接近一点的变换。
多种类型的层级
在Keras中,一个“层级”是一种非常通用的东西。实际上,一个层级可以是任何种类的数据转换。许多层级,比如卷积层和循环层,通过神经元对数据进行转换,它们的主要区别在于它们形成的连接模式。而其他一些层级则用于特征工程或者仅仅进行简单的计算。
其他拓展层级资料
激活函数
激活函数是神经网络中的一种函数,它在神经元的输出上施加一个非线性变换。在神经网络中,神经元的输出通常是加权和的结果,而激活函数会对这个加权和进行处理,以产生神经元的最终输出。
激活函数的作用是引入非线性性质,使得神经网络能够学习复杂的关系和模式。如果没有激活函数,多个线性层级的叠加将会等效于单个线性层级,无法捕捉到非线性模式。
修正线性单元 (ReLU)
最常见的激活函数是修正线性单元,max(0, x)。这种函数的特点是在输入为负时输出为零,而在输入为正时输出与输入相等。
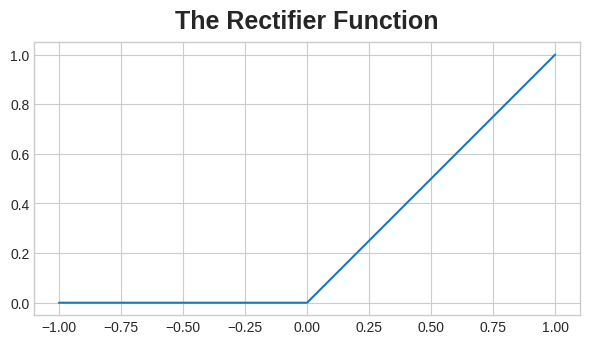
修正线性单元的图形是一条带有负部分被“修正”为零的直线。将该函数应用于神经元的输出将在数据中产生一个弯曲,使我们远离简单的直线。
当我们将修正线性单元连接到线性单元时,我们得到一个修正线性单元(Rectified Linear Unit,简称ReLU)。因此,通常将修正线性单元函数称为“ReLU函数”。将ReLU激活应用于线性单元意味着输出变为max(0, w * x + b),我们可以在图表中绘制出来:
在神经网络中,其他常用的激活函数包括:
- Sigmoid函数:将输入映射到0到1之间的范围,适用于二分类问题。
- Tanh函数:将输入映射到-1到1之间的范围,类似于Sigmoid函数,但更广的范围可以提供更强的表达能力。
- Leaky ReLU函数:与ReLU类似,但负数部分不是完全截断为0,而是保留一个小的斜率。
- Softmax函数:通常用于多分类问题,将一组输入映射为概率分布,使得所有输出的和为1。
选择合适的激活函数取决于问题的性质和网络的结构,不同的激活函数可以在不同的情况下发挥最佳效果。
堆叠稠密层
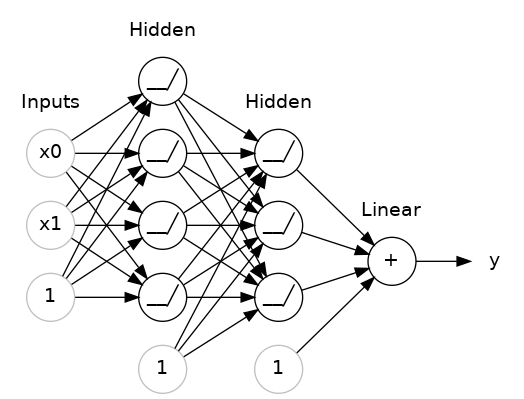
一堆叠稠密层构成了一个“全连接”网络。
输出层之前的这些层有时被称为隐藏层,因为我们无法直接看到它们的输出。
注意到,最后(输出)层是一个线性单元(即没有激活函数)。这使得这个网络适用于回归任务,其中我们尝试预测某个任意的数值。其他任务(比如分类)可能需要在输出上使用激活函数。
【代码实现一】构建Sequential模型
Sequential模型由一系列线性层(layers)组成,每个线性层都按顺序连接在一起,前一层的输出作为后一层的输入。这种线性的层叠方式使得数据在网络中单向流动,没有跳跃或反馈连接,因此称为“序列”模型。在Keras中,一个Sequential模型可以通过添加层来构建。
from tensorflow import keras
from tensorflow.keras import layers# 创建一个Sequential模型
model = keras.Sequential([#第一个隐藏层,包含128个神经元和relu激活函数layers.Dense(units=128, activation='relu', input_shape=[8]),#第二个隐藏层,包含64个神经元和relu激活函数layers.Dense(units=64, activation='relu'),#用于回归任务的线性激活函数layers.Dense(units=1, activation='linear') # Linear activation for regression
])参数解释 :input_shape
input_shape:是指输入数据的维度或形状。
- 如果输入的表格数据,(类似Pandas 中的 dataframe),那么数据集中的每个特征,都算是一个输入,input_shape=[num_columns]。比如,数据集中有8个特征,即8列数据,那么input_shape=[8]
- Keras在这里使用列表的原因是为了允许使用更复杂的数据集。例如,图像数据可能需要三个维度:[高度,宽度,通道]。假设你要训练一个神经网络对手写数字进行分类,输入数据是28x28像素的灰度图像。那么输入形状可以表示为(28, 28, 1),其中前两个维度表示图像的高度和宽度,最后一个维度表示图像的通道数(在本例中为灰度图像,因此通道数为1)。
三、随机梯度下降(Stochastic Gradient Descent)
损失函数(Loss Function)
损失函数衡量了目标的真实值与模型预测值之间的差异。在训练期间,模型将使用损失函数作为指导,找到其权重的正确值(较低的损失更好)。换句话说,损失函数告诉网络它的目标是什么。
回归问题常用的损失函数是平均绝对误差或MAE。此外,还有均方误差(MSE)或Huber损失。
随机梯度下降介绍
随机梯度下降(SGD)是优化算法中模型参数的常见方法。与传统的梯度下降方法相比,随机梯度下降的计算开销较小,因为它只考虑了一个样本(或小批量样本)而不是整个训练集。尽管随机梯度下降的更新可能在迭代过程中不够稳定,但它通常能够在更短的时间内达到良好的解决方案,特别是对于大规模数据集和复杂的模型。
具体步骤如下:
- 从训练数据中抽取一些样本,并将其输入到网络中进行预测。
- 计算预测值与真实值之间的损失。
- 最后,调整权重,使损失减小的方向。
- 然后一直重复这个过程,直到损失达到您期望的小值(或者无法进一步减小为止)。
每次迭代的训练数据样本称为小批量(通常简称为“批次”),而完整的一轮训练数据称为周期。训练的周期数表示网络将看到每个训练样例的次数。
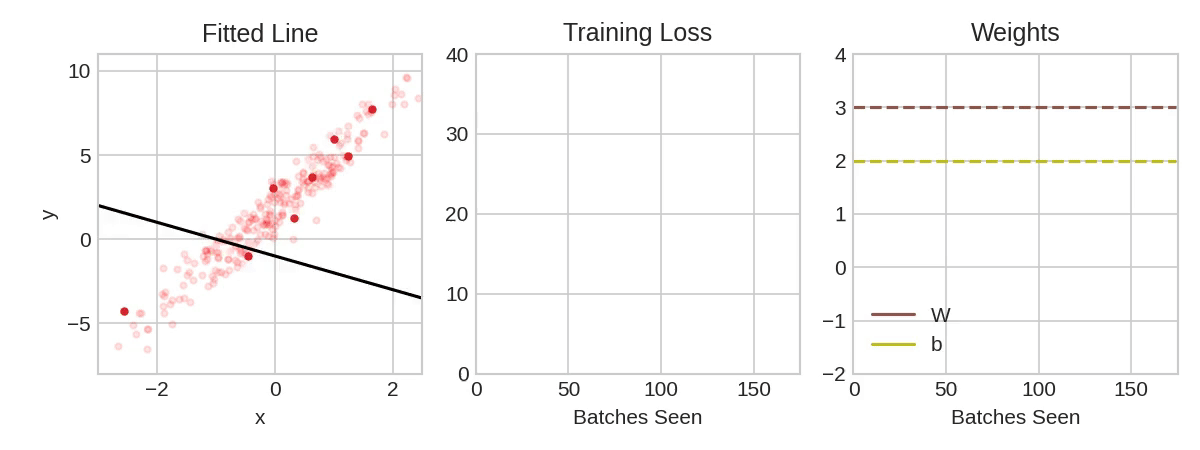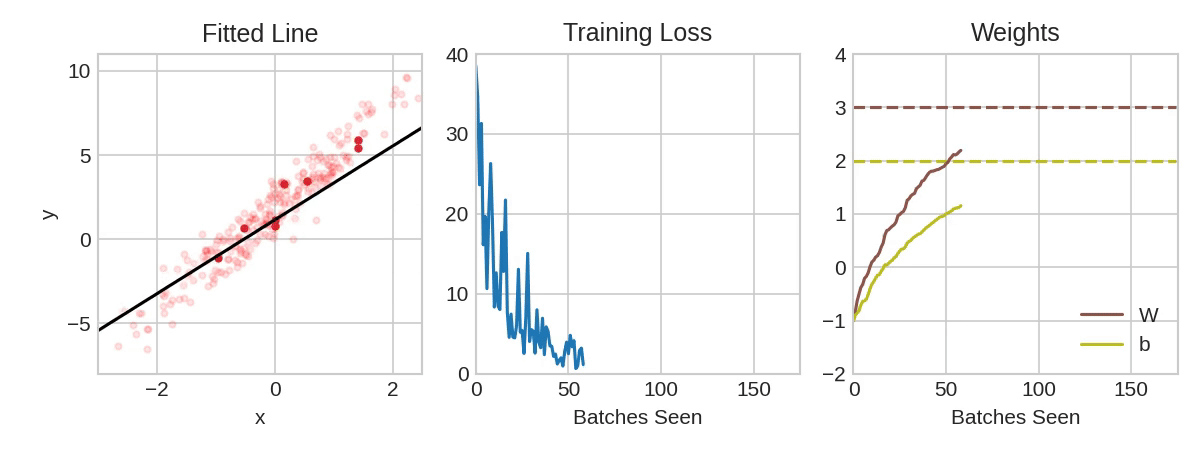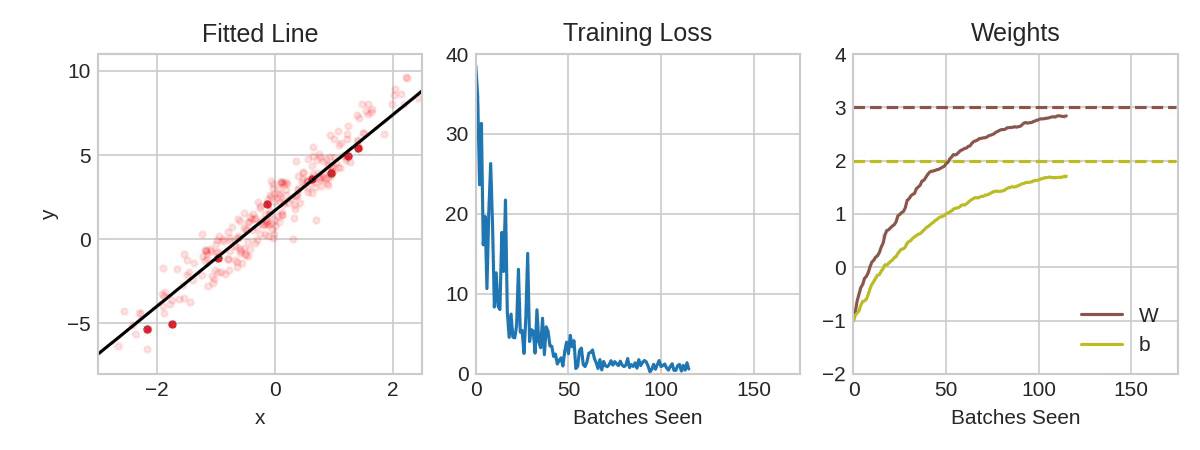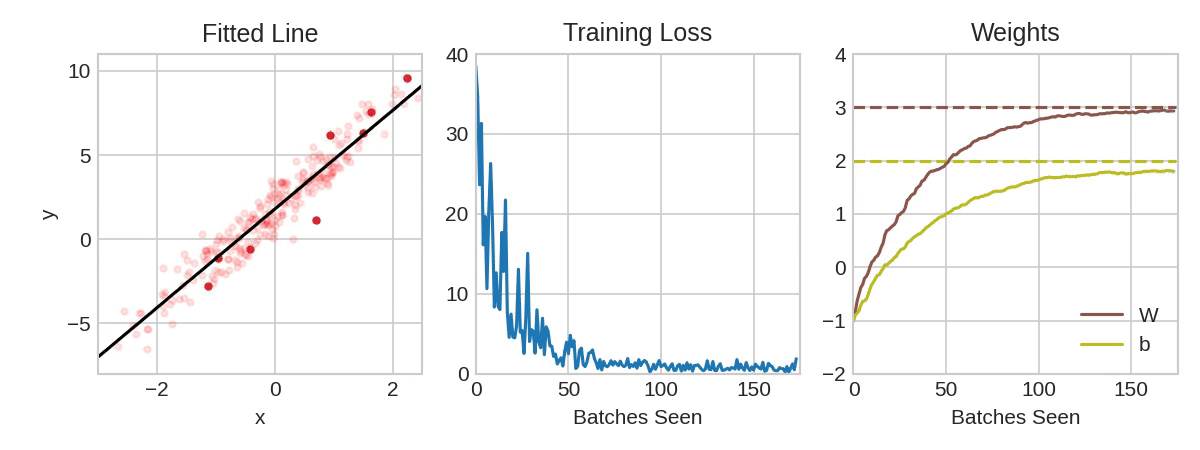
动画展示了一个线性模型如何使用SGD进行训练。淡红色的点表示整个训练集,而实心红色的点则表示小批量。每次SGD看到一个新的小批量时,它将把权重(w是斜率,b是y截距)向其在该批次上的正确值方向调整。一批一批地,直线最终会收敛到最佳拟合。可以看到随着权重接近其真实值,损失会变得更小。
学习率和批量大小(Learning Rate and Batch Size)
请注意,曲线在每个批次的方向上只发生了轻微的移动(而不是一直移动到底)。这些移动的大小由学习率决定。较小的学习率意味着网络需要看到更多的小批量数据,才能使其权重收敛到最佳值。
学习率和小批量的大小是影响随机梯度下降(SGD)训练过程最大的两个参数。
幸运的是,对于大多数工作来说,通常不需要进行大量的超参数搜索以获得令人满意的结果。
【代码实现二】添加损失函数和优化器
在定义模型之后,可以通过模型的compile方法添加损失函数和优化器:
model.compile(optimizer="adam", #优化算法使用adamloss="mae", #损失函数使用mae
)
可以只使用字符串来指定损失函数和优化器。如果想要调整参数,也可以直接通过Keras API访问它们。
参数解释:Adam
Adam(Adaptive Moment Estimation)是一种具有自适应学习率的SGD算法,适用于大多数问题,无需进行任何参数调整(从某种意义上说,它是“自调节”的)。Adam是一个很好的通用优化器。
四、过拟合和欠拟合(Overfitting and Underfitting)
过拟合和欠拟合
对于深度学习模型来说,同样存在过拟合和欠拟合的问题。
简单来说,过拟合是指模型在训练数据上表现很好,但在未见过的新数据上表现较差,过多地记住了训练数据的噪声和细节。欠拟合是指模型无法很好地适应训练数据,无法捕捉数据中的模式和关系。
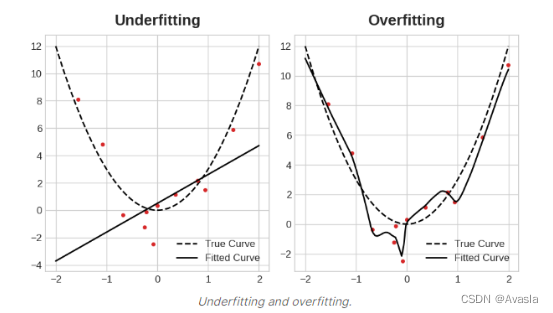
接下来,我们将讨论如何避免或者降低这两个问题对模型带来的影响。
容量(Capacity)
模型的容量是指它能够学习的模式的大小和复杂性。对于神经网络,在很大程度上由它拥有多少个神经元以及它们如何相互连接来决定。如果你觉得你的网络对数据的拟合不足,你可以尝试增加它的容量。
可以通过使网络变得更宽(向现有层添加更多单元)或通过使网络变得更深(添加更多层)来增加网络的容量。更宽的网络更容易学习更多的线性关系,而更深的网络更倾向于学习更多的非线性关系。哪种方式更好取决于数据集的情况。
例如:
#原始模型
model = keras.Sequential([layers.Dense(16, activation='relu'),layers.Dense(1),
])#加宽模型
wider = keras.Sequential([layers.Dense(32, activation='relu'),layers.Dense(1),
])#加深模型
deeper = keras.Sequential([layers.Dense(16, activation='relu'),layers.Dense(16, activation='relu'),layers.Dense(1),
])
提前终止(Early Stopping)
我们提到,当模型过于学习噪声时,验证损失可能在训练过程中开始增加。为了防止这种情况,我们可以在似乎验证损失不再减小时立即停止训练。这种中断训练的方式称为提前终止。
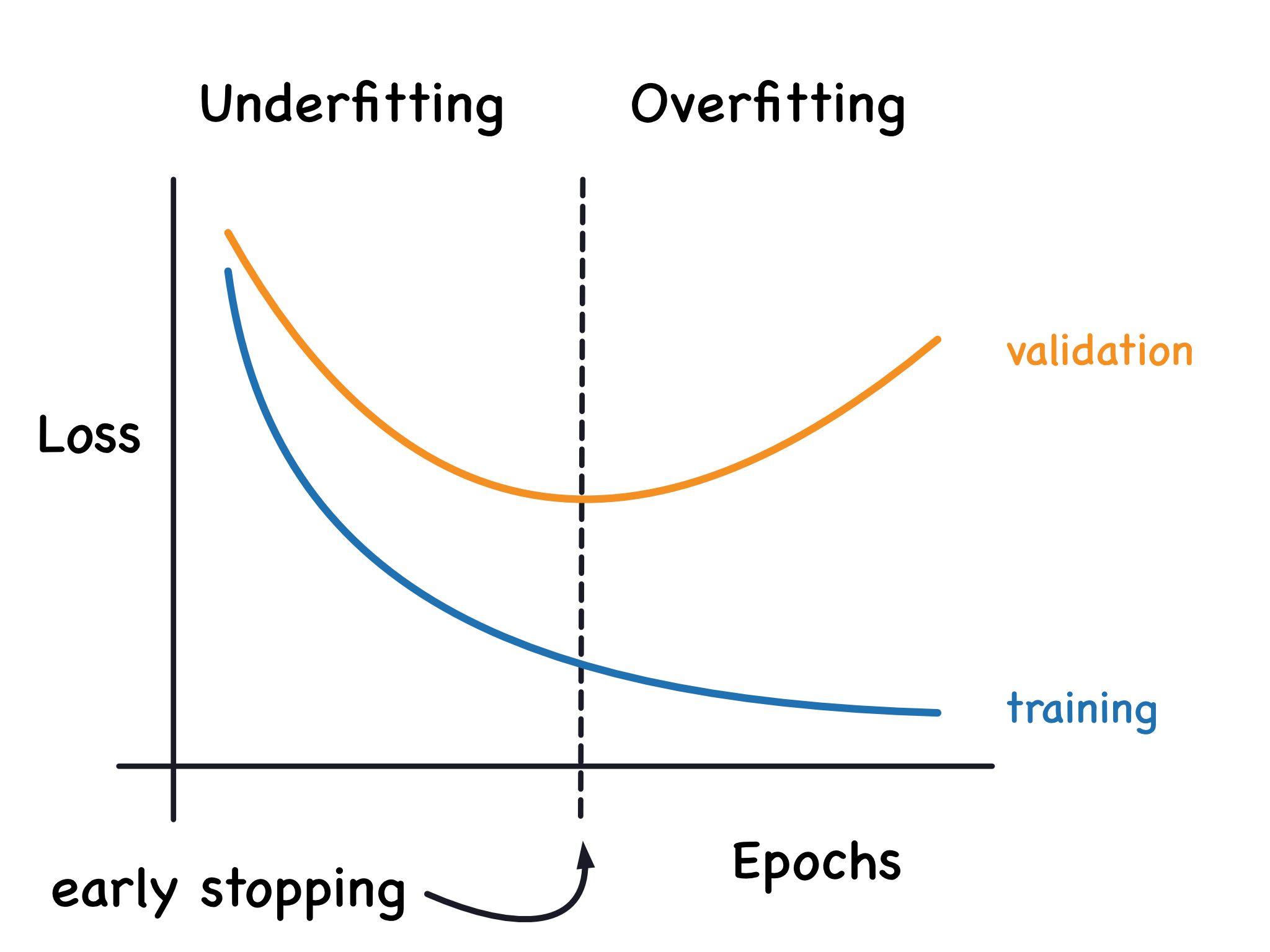
我们保留验证损失最小的模型。
一旦我们发现验证损失再次开始上升,我们可以将权重重置为最小值出现的位置。这确保模型不会继续学习噪声并过拟合数据。
这也意味着我们不太可能在网络完成学习信号之前过早地停止训练。因此,除了防止过长的训练导致过拟合外,提前终止还可以防止因为训练时间不足而出现欠拟合。
【代码实现三】添加提前终止功能
在Keras中,我们通过回调(callback)将提前停止功能添加到训练中。回调只是在网络训练过程中定期运行的函数。提前停止回调将在每个周期后运行。(Keras预定义了各种有用的回调,但也可以定义自己的回调。)
from tensorflow.keras.callbacks import EarlyStoppingearly_stopping = EarlyStopping(min_delta=0.001, # 被视为改进的最小变化量patience=20, # 在停止之前等待的周期数restore_best_weights=True, # 是否恢复到最佳权重
)
这些参数表示:“如果在之前的20个周期内,验证损失没有改善至少0.001,那么停止训练并保留你找到的最佳模型。”有时很难判断验证损失的上升是由于过拟合还是由于随机批次变化。这些参数允许我们在何时停止训练时设置一些允许范围。
正如我们在下面红酒示例中将看到的,我们将把这个回调与损失和优化器一起传递给fit方法。
【代码实现四】红酒数据集示例
示例数据集包含了大约1600瓶红葡萄酒的测量数据。还包括了每瓶酒的品质评分。需要从测量数据中预测出一瓶酒的品质分数。(也可以替换成类似的预测数据集。)
数据示例如下:

import pandas as pd
from IPython.display import display# 读取红酒数据集
red_wine = pd.read_csv('../input/dl-course-data/red-wine.csv')# 创建训练和验证集拆分
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)
display(df_train.head(4))# 缩放到 [0, 1] 范围
max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)
df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)# 拆分特征和目标
X_train = df_train.drop('quality', axis=1)
X_valid = df_valid.drop('quality', axis=1)
y_train = df_train['quality']
y_valid = df_valid['quality']from tensorflow import keras
from tensorflow.keras import layers, callbacks# 提前停止回调
early_stopping = callbacks.EarlyStopping(min_delta=0.001, # 被视为改进的最小变化值patience=20, # 在停止之前等待的周期数restore_best_weights=True,
)# 创建模型
model = keras.Sequential([layers.Dense(512, activation='relu', input_shape=[11]),layers.Dense(512, activation='relu'),layers.Dense(512, activation='relu'),layers.Dense(1),
])# 添加损失函数和优化器
model.compile(optimizer='adam',loss='mae',
)
# 训练模型
history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=256,epochs=500,callbacks=[early_stopping], # 将回调函数放在列表中verbose=0, # 关闭训练日志
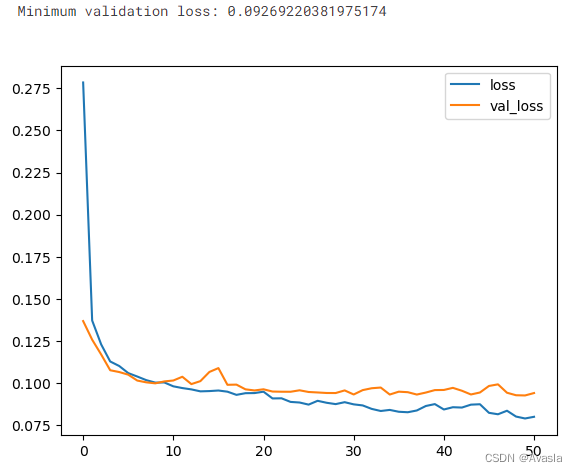
)history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();
print("最小验证损失:{}".format(history_df['val_loss'].min()))
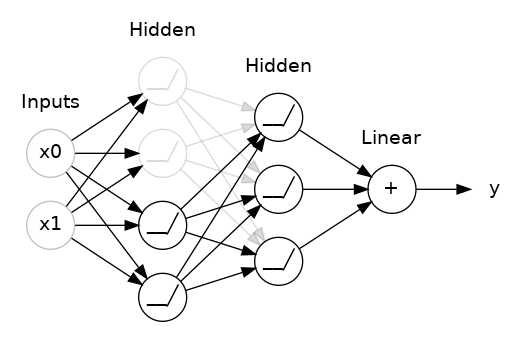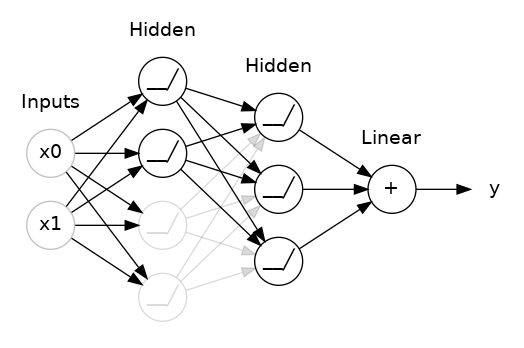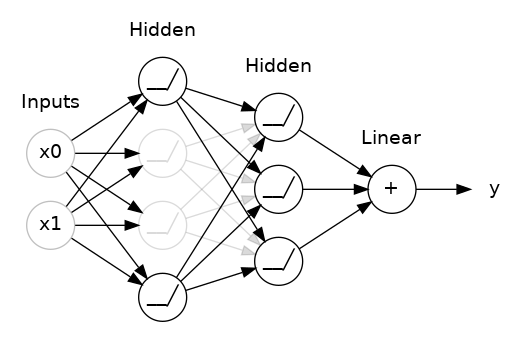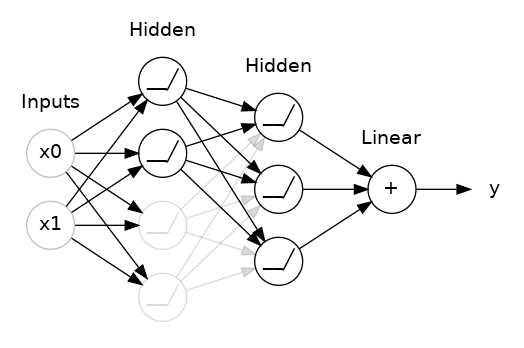
五、Dropout & Batch Normalization
Dropout
Dropout提供了正则化一大类模型的方法,它可以帮助纠正过拟合问题。
原理是在训练过程中,随机地丢弃(即设置为零)一部分神经元的输出,使得网络无法过于依赖某些特定神经元的信息,从而迫使网络学习更加鲁棒的特征。通过这种方式,每个神经元都有一定的概率被丢弃,使得网络在不同的训练迭代中都会看到不同的神经元组合,从而减少过拟合风险。在实际预测时,不进行神经元丢弃,而是使用所有神经元的输出,以获得更稳定的预测结果。
在下面动图中,两个隐藏层之间添加了50%的Dropout。
参考资料:
花书《7.12 Dropout》中文版 p159
英文版: 《Chapter 7Regularization for Deep Learning》
批标准化(Batch Normalization)
批标准化(Batch Normalization,或称为“批归一化”),它可以帮助纠正训练过程变慢或不稳定的情况。
在神经网络中,可以使用像scikit-learn的StandardScaler或MinMaxScaler之类的方法对数据进行标准化处理,使输入分布保持在一个合适的范围内,从而提高模型的稳定性。
如果在数据进入网络之前进行标准化是有益的,那么在网络内部进行标准化也许会更好!实际上,我们有一种特殊的层可以实现这一点,那就是批标准化层。批标准化层会在每个批次输入时进行操作,首先使用批次的均值和标准差对批次进行标准化,然后使用两个可训练的重新缩放参数将数据放在一个新的尺度上。批标准化实际上对其输入执行了一种协调的重新缩放。
批标准化通常是为了优化过程而添加的辅助功能(尽管有时它也可以改善预测性能)。使用批标准化的模型通常需要更少的周期来完成训练。此外,批标准化还可以解决可能导致训练“卡住”的各种问题。可以考虑在模型中添加批标准化,尤其是在训练过程中遇到问题时。
参考资料:
花书《8.7优化策略和元算法》p194
英文版: 《Chapter 8Optimization for Training DeepModels》
【代码实现五】添加Dropout层和批标准化层
# Dropout
keras.Sequential([# ...layers.Dropout(rate=0.3), # 随机丢弃30%下一层的输入layers.Dense(16),# ...
])# 如果将批标准化层添加为网络的第一层,它可以作为一种自适应的预处理器,类似于Sci-Kit Learn的StandardScaler的作用。# 在一层后面添加Batch Normalization
layers.Dense(16, activation='relu'),
layers.BatchNormalization(),# 在一层与其激活函数之间使用 Batch Normalization
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),
六、二分类问题
二分类问题
将数据分为两个类别是常见的机器学习问题。比如预测客户是否有可能购买商品,信用卡交易是否存在欺诈,深空信号是否显示了新的行星证据,或者医学测试是否显示了某种疾病证据。这些都是二分类问题。
在原始数据中,类别可以用字符串表示,比如"Yes"和"No",或者"Dog"和"Cat"。在使用这些数据之前,我们会给它们分配一个类别标签:一个类别将被标记为0,另一个类别将被标记为1。分配数值标签将数据转化为神经网络可以使用的形式。
准确率和交叉熵
准确率是用于衡量分类问题成功度的众多度量之一。准确率是正确预测的数量与总预测数量的比率:准确率 = 正确预测数 / 总数。如果一个模型总是预测正确,它的准确率得分将为1.0。其他条件相同的情况下,准确率是一个合理的度量标准,适用于数据集中的类别出现频率大致相同的情况。
准确率(以及大多数其他分类度量)的问题在于它不能作为损失函数来使用。随机梯度下降(SGD)需要一个能够平滑变化的损失函数,而准确率作为计数比率在变化时会产生"跳跃"。因此,我们需要选择一个代替品作为损失函数,这个代替品就是交叉熵函数。
回顾一下,损失函数在训练过程中定义了网络的目标。
- 对于回归问题,我们的目标是最小化期望结果与预测结果之间的距离。我们选择了平均绝对误差(MAE)来衡量这个距离。
- 对于分类问题,我们希望的是概率之间的距离,这就是交叉熵是——一种从一个概率分布到另一个概率分布的距离度量。
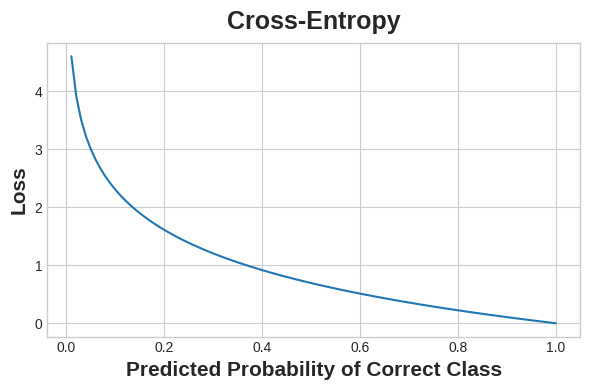
交叉熵对错误的概率预测进行惩罚。
我们的想法是,我们希望网络以概率1.0预测正确的类别。预测概率与1.0的差距越大,交叉熵损失就越大。
我们使用交叉熵的技术原因可能有点微妙,但从本节中主要可以得出一个结论:对于分类损失,使用交叉熵;其他您可能关心的指标(如准确率)通常会随着交叉熵的改善而提高。
交叉熵作为损失函数的一个重要特点是,它在梯度计算时能够有效地促使神经网络的权重进行调整,从而改进预测结果。相对于准确率等离散指标,交叉熵是一个连续、平滑的函数,适用于梯度下降等优化算法,这使得网络的训练更加稳定。
总之,当您面临二分类问题时,可以将交叉熵作为损失函数,它能够有效地衡量预测概率分布之间的差距,同时在训练中促使神经网络调整权重以获得更好的预测性能。
使用Sigmoid函数生成概率
交叉熵和准确率函数都需要概率作为输入,也就是从0到1的数值。为了将密集层生成的实值输出转化为概率,我们会使用一种新的激活函数,即Sigmoid激活函数。
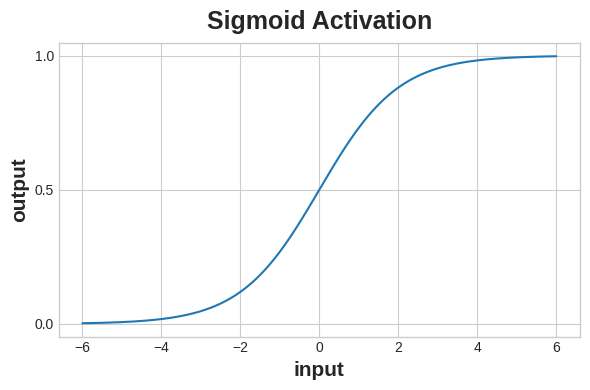
Sigmoid函数将实数映射到区间[0,1]。
为了得到最终的类别预测,我们定义了一个阈值概率。通常这个阈值为0.5,这样四舍五入就会给我们正确的类别:小于0.5意味着属于标签0的类别,0.5或以上意味着属于标签1的类别。0.5的阈值是Keras在默认情况下使用的准确率指标。
【代码示例六】
Ionosphere 数据集包含从聚焦于地球大气层电离层的雷达信号中获取的特征。任务是确定信号是否显示出某个物体的存在,或者只是空气。
import pandas as pd
from IPython.display import displayion = pd.read_csv('../input/dl-course-data/ion.csv', index_col=0)
display(ion.head())df = ion.copy()
df['Class'] = df['Class'].map({'good': 0, 'bad': 1})df_train = df.sample(frac=0.7, random_state=0)
df_valid = df.drop(df_train.index)max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)
df_train.dropna(axis=1, inplace=True) # drop the empty feature in column 2
df_valid.dropna(axis=1, inplace=True)X_train = df_train.drop('Class', axis=1)
X_valid = df_valid.drop('Class', axis=1)
y_train = df_train['Class']
y_valid = df_valid['Class']
我们将像对回归任务那样定义模型,除了在最后一层添加一个 'sigmoid' 激活函数,以便模型能够产生类别概率。
from tensorflow import keras
from tensorflow.keras import layersmodel = keras.Sequential([layers.Dense(4, activation='relu', input_shape=[33]),layers.Dense(4, activation='relu'), layers.Dense(1, activation='sigmoid'),
])
使用 compile 方法为模型添加交叉熵损失和准确率指标。对于二分类问题,确保使用 'binary' 版本的损失函数。(多类别问题会稍有不同。)Adam 优化器在分类问题中也表现出色,因此我们将继续使用它。
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['binary_accuracy'],
)
在这个特定问题中,模型可能需要相当多的 epochs 才能完成训练,因此我们将添加早停(early stopping)回调以方便管理。
early_stopping = keras.callbacks.EarlyStopping(patience=10,min_delta=0.001,restore_best_weights=True,
)history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=512,epochs=1000,callbacks=[early_stopping],verbose=0, # hide the output because we have so many epochs
)
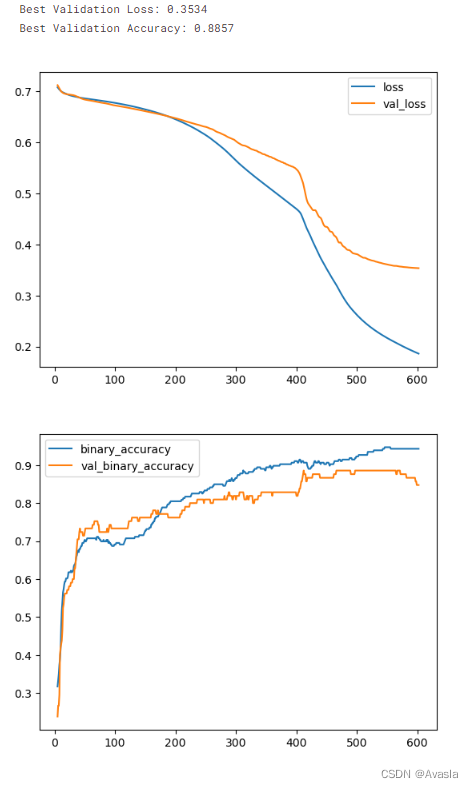
最后,查看学习曲线,并检查我们在验证集上获得的损失和准确率的最佳值。
history_df = pd.DataFrame(history.history)
# 从第 5 个 epoch 开始绘制图形
history_df.loc[5:, ['loss', 'val_loss']].plot()
history_df.loc[5:, ['binary_accuracy', 'val_binary_accuracy']].plot()print(("Best Validation Loss: {:0.4f}" +\"\nBest Validation Accuracy: {:0.4f}")\.format(history_df['val_loss'].min(), history_df['val_binary_accuracy'].max()))
这将帮助我们了解模型的训练进展以及在验证集上的表现。最终的最佳验证损失和准确率值将在输出中显示。
参考链接:https://www.kaggle.com/learn/intro-to-deep-learning
相关文章:
深度学习笔记(kaggle课程《Intro to Deep Learning》)
一、什么是深度学习? 深度学习是一种机器学习方法,通过构建和训练深层神经网络来处理和理解数据。它模仿人脑神经系统的工作方式,通过多层次的神经网络结构来学习和提取数据的特征。深度学习在图像识别、语音识别、自然语言处理等领域取得了…...

windows下载任意版本php
zzwindows.php.net - /downloads/releases/archives/ windows下载php,记录一下...

Linux命令
操作系统管理硬件设备,并为用户和应用程序提供一个简单的接口,以便于使用。(作为中间人,连接软件和硬件)不同应用领域的主流操作系统 桌面操作系统 Windows系列::用户群体大 macOS:适合于开发人…...

TDD(测试驱动开发)?
01、前言 很早之前,曾在网络上见到过 TDD 这 3 个大写的英文字母,它是 Test Driven Development 这三个单词的缩写,也就是“测试驱动开发”的意思——听起来很不错的一种理念。 其理念主要是确保两件事: 确保所有的需求都能被照…...

C/C++
const 作用 修饰变量,说明该变量不可以被改变;修饰指针,分为指向常量的指针(pointer to const)和自身是常量的指针(常量指针,const pointer);修饰引用,指向…...

CCF C³ 走进百度:大模型与可持续生态发展
2023年8月10日,由CCF CTO Club发起的第22期C活动在百度北京总部进行,以“AI大语言模型技术与生态发展”主题,50余位企业界、学界专家、研究人员就此进行深入探讨。 CCF C走进百度 本次活动,CCF秘书长唐卫清与百度集团副总裁、深…...

Vue使用html2canvas将DOM节点生成对应的PDF
要通过Vue使用html2canvas将DOM节点生成对应的PDF,您需要安装html2canvas和jspdf这两个库。html2canvas用于将DOM节点转换为Canvas,而jspdf用于将Canvas转换为PDF。以下是一个简单的示例代码,展示了如何使用html2canvas和jspdf生成PDF文件&am…...

专访阿里云席明贤,视频云如何运用大模型与小模型来破茧升级2.0
不久前,LiveVideoStack与阿里云视频云负责人席明贤(花名右贤)展开一场深度的对话,一个是圈内专业的社区媒体,一个是20年的IT老兵,双方有交集、有碰撞、有火花。 面对风云变幻的内外环境,阿里云…...
Vue 2的计算属性与侦听器
计算属性 vs 方法 vs 侦听器 计算属性的出现是为了解决模板内表达式太过复杂而变得难以维护。 假设我们知道长和宽,要计算一个矩形的面积,如果没有计算属性,我们可能像下面这样处理: <div id"app"><input t…...

JavaScript基础:学习JavaScript语言的基本语法和常用操作,了解网页交互的基本原理
JavaScript是一种广泛应用于网页开发中的脚本语言,它可以与HTML和CSS一起使用,实现网页交互及动态效果。 以下是JavaScript的基本语法和常用操作: 变量声明:使用var、let或const关键字声明变量。 var name "John";let …...

网络每日一练
吴泽彬 C Ip 网络层 Tcp udp 传输层, Http 应用层 收起 1 回复 发布于 2019-10-11 12:07 举报 fighting2016 Java A类地址中的私有地址和保留地址: ①10.0.0.0到10.255.255.255是私有地址(所谓的私有地址就是在互联网上不使用,而被…...

asp.net core读取request内容
在Startup.cs中定义Middleware,设置缓存Http请求的Body数据。代码如下。自定义Middleware请放到Configure方法的最前面。 app.Use(next > new RequestDelegate(async context > {context.Request.EnableBuffering();await next(context);})); GET请求 HttpC…...
)
笔记:移植xenomai到nuc972(2)
接下来的测试,出现了两个问题 第一个问题是demo程序启动不了,这是上一篇文章忘记说的事,启动不了的原因是权限问题,提示需要root, 但我是用busybox搭的文件系统,直接就是root,不存在权限问题,所以问题出在应用上,经过一番调试后发现,问题出在xenomai的应用库上,具体位置在xen…...

记忆正则表达式的基本元件
正则常见的三种功能,它们分别是:校验数据的有效性、查找符合要求的文本以及对文本进行切割和替换等操作。 正则表达式,简单地说就是描述字符串的规则。在正则中,普通字符表示的还是原来的意思,比如字符 a,…...

低代码是什么?解决哪些问题?什么业务场景适合用低码开发?
目录 一、低代码是什么? 二、低代码解决方案的主要特点 01.可视化开发环境 02.预构建的组件和模板 03.集成的开发和测试工具 04.跨平台兼容性 05.可伸缩性和可扩展性 三、开发工具中的强者 四、你所在企业为什么要关心低代码开发? 五、什么业务场景适…...

SOA架构
SOA架构 Service-Oriented Architecture,SOA是一种软件架构模式,旨在将应用程序的不同功能划分为一组可重用的、自治的、可互操作的服务。 每个服务表示一个特定的业务功能,并通过定义明确的接口和协议来实现与其他服务的通信。 SOA的主要目…...

“深入探索JVM内部机制:解密Java虚拟机“
标题:深入探索JVM内部机制:解密Java虚拟机 摘要:本篇博客将深入剖析Java虚拟机(JVM)的内部机制,包括类加载、内存管理、垃圾回收、即时编译等关键组成部分。通过对JVM内部机制的解密,我们可以更…...

PostgreSQL空值的判断
PostgreSQL空值的判断 空值判断非空判断总结 空值判断 -- 查询为空的 is null,sql简写isnull select * from employees where manager_id isnull;select * from employees where manager_id is null;非空判断 -- 查询不为空的 is not null;sql简写notnull select * from empl…...

使用phpunit进行单元测试
使用phpunit进行单元测试 本教程假定您使用 PHP 8.1 或 PHP 8.2。您将学习如何编写简单的单元测试以及如何下载和运行 PHPUnit. PHPUnit 10 的文档 在这。 下载:可以用以下2种方法之一: 1.PHP 存档 (PHAR) 我们分发了一个 PHP存档(PHAR&…...
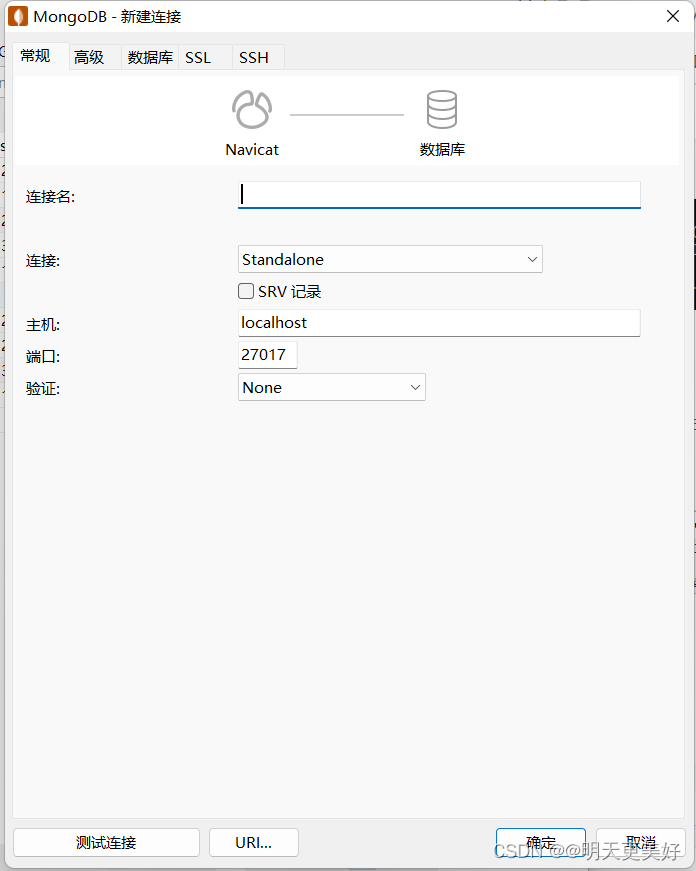
MongoDB 简介
什么是MongoDB ? MongoDB 是由C语言编写的,是一个基于分布式文件存储的开源数据库系统。 在高负载的情况下,添加更多的节点,可以保证服务器性能。 MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。 MongoDB 将数据存储为一个…...
5个关键步骤让zotero-pdf-translate翻译功能重新工作:完整解决方案指南
5个关键步骤让zotero-pdf-translate翻译功能重新工作:完整解决方案指南 【免费下载链接】zotero-pdf-translate Translate PDF, EPub, webpage, metadata, annotations, notes to the target language. Support 20 translate services. 项目地址: https://gitcode…...

iCircuit:iPad上的电子电路仿真神器,从原理到实践全解析
1. 项目概述与核心价值 最近和一位老朋友Alvin聊天,他是一位资深的硬件工程师,我们曾一起合作过一些项目。他兴奋地给我发来一封邮件,强烈推荐了一款他正在使用的iPad应用——iCircuit。这让我立刻提起了兴趣,因为在移动设备上进行…...

局域网监控软件评测:从数据主权视角看企业效能工具的取舍
很多管理者在巡视办公室时,看到员工手指在键盘上飞速跳动,屏幕上代码或表格交织,心中却往往悬着一块石头:他们是在攻克项目难关,还是在处理私人兼职?这种管理上的“黑盒状态”,不仅是效率的损耗…...

Llama.cpp Docker镜像部署指南:快速搭建本地大模型运行环境
1. 项目概述:为什么需要为Llama.cpp准备Docker镜像? 在本地部署和运行大型语言模型(LLM)这件事上,Llama.cpp 几乎成了开源社区的“标准答案”。它用纯C/C编写,通过高效的量化技术,让我们能在消费…...

深入解析Trust Layer:声明式信任管理在微服务架构中的工程实践
1. 项目概述与核心价值最近在开源社区里,一个名为openclawunboxed/trust-layer的项目引起了我的注意。乍一看这个标题,可能会觉得有些抽象——“信任层”?这听起来像是一个偏学术或理论性的概念。但当我深入其代码仓库和设计文档后࿰…...

ZYNQ UltraScale+ MPSoC实战:基于PL端AXI_UART16550 IP核与PS端中断机制,实现RS485多帧长数据可靠接收
1. 工业通信场景下的ZYNQ UltraScale MPSoC实战 在工业自动化领域,RS485总线因其抗干扰能力强、传输距离远等优势,成为设备间通信的主流选择。而ZYNQ UltraScale MPSoC凭借其独特的PSPL架构,能够完美应对工业通信中对实时性和可靠性的严苛要求…...

如何实现Airbyte动态服务发现:从基础到实践的完整指南
如何实现Airbyte动态服务发现:从基础到实践的完整指南 【免费下载链接】airbyte Open-source data movement for ELT pipelines and AI agents — from APIs, databases & files to warehouses, lakes, and AI applications. Both self-hosted and Cloud. 项目…...

全网珍藏网安学习网站大全,一次性整理齐全,错过容易被删速收藏!
我们学习网络安全,很多学习路线都有提到多逛论坛,阅读他人的技术分析帖,学习其挖洞思路和技巧。但是往往对于初学者来说,不知道去哪里寻找技术分析帖,也不知道网络安全有哪些相关论坛或网站,所以在这里给大…...

三星48层3D V-NAND深度拆解:从电荷陷阱架构到存储密度革命
1. 初探三星48层3D V-NAND:一次深度拆解与工艺解析作为一名长期关注半导体存储技术的从业者,每次拿到业界巨头的新品进行物理层面的拆解分析,都像是一次充满惊喜的“寻宝”之旅。2016年初,当三星将其早在2015年8月就已预告的256Gb…...

5G O-RAN中AI驱动的延迟预测系统设计与优化
1. 项目背景与核心价值在5G O-RAN架构中,延迟控制一直是网络优化的核心痛点。传统电信设备厂商采用的黑盒方案,使得运营商难以针对特定场景进行精细化调优。而O-RAN的开放特性虽然带来了灵活性,但也引入了新的挑战——当CU(集中单…...