英伟达结构化剪枝工具Nvidia Apex Automatic Sparsity [ASP](1)——使用方法
英伟达结构化剪枝工具Nvidia Apex Automatic Sparsity [ASP](1)——使用方法
Apex是Nvdia维护的pytorch工具库,包括混合精度训练和分布式训练,Apex的目的是为了让用户能够更早的使用上这些“新鲜出炉”的训练工具。ASP(Automatic Sparsity)是Nvidia Apex模块中用于模型稀疏剪枝的算法,
项目地址:NVIDIA/apex: A PyTorch Extension: Tools for easy mixed precision and distributed training in Pytorch (github.com)
本文主要介绍的是ASP中的一个用于模型剪枝的模块:ASP(Automatic sparsity),该模块仅仅向python模型训练文件中添加两行代码来实现模型的2:4稀疏剪枝,同时还可以通过开启通道置换算法将绝对值较大的参数进行保留,以求对模型精度的影响最小化。
项目地址:项目
论文链接:论文
Installation
从github clone源码安装需要checkout到23.05的tag
git clone https://github.com/NVIDIA/apex.git
cd apex
git checkout 23.05
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" --global-option="--permutation_search" ./
Usage
使用ASP对模型进行稀疏化只需要两步:
# 1. 导入sparsity模块
from apex.contrib.sparsity import ASP
# 2. 使用ASP来模型和优化器进行稀疏化
ASP.prune_trained_model(model, optimizer)
prune_trained_model函数会计算出稀疏mask并将其施加在模型的权重上。
整体而言,通常需要在对模型稀疏化后重新进行训练,整个过程可以表示为:
ASP.prune_trained_model(model, optimizer)x, y = DataLoader(args)
for epoch in range(epochs):y_pred = model(x)loss = loss_function(y_pred, y)loss.backward()optimizer.step()torch.save(...)
非标准用法:
ASP还可以用来为模型生成稀疏的随机化参数,从而进行更加复杂高级的实验,如果在两个step之间重新计算权重的稀疏矩阵,可以通过在训练的step之间调用ASP.recompute_sparse_masks函数来为模型重新生成稀疏mask。
Channel Permutation
该项目还可以通过开启通道置换算法,来为结构化稀疏后的模型保留最大的精度值。
通道置换算法,顾名思义,就是通过沿着权重矩阵的通道维度进行置换,并对其周围的模型层进行适当调整。
如果开启通道置换算法,那么最终的模型精度与置换算法的质量之间存在很大关系,置换的过程可以通过Apex CUDA拓展来进行加速,否则时间会非常的久。
在Installation步骤中,参数--global-option="--permutation_search"即是用于安装permutation search CUDA extension 。
如果不希望开启通道置换算法,可以在ASP.init_model_for_pruning方法中将参数allow_permutation的值设置为False即可,这一点在后续的源代码分析中也会提到。
需要注意的是,当使用多个GPU时,需要为所有的GPU设置相同的随机种子,通过permutation_lib.py中的 set_identical_seed来进行设置。
import torch
import numpy
import randomtorch.manual_seed(identical_seed)
torch.cuda.manual_seed_all(identical_seed)
numpy.random.seed(identical_seed)
random.seed(identical_seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
Tips:
- 在使用ASP对一个新的(未经过稀疏的)推理模型启用结构化稀疏时需要同时调用
init_model_for_pruning和compute_sparse_masks方法。 init_model_for_pruning会为模型层添加新的mask buffer,用于保存compute_sparse_masks生成的mask,因此调用了compute_sparse_masks后的模型的state_dict会比之前多出一些数据,这些数据均以_mma_mask结尾的名字进行命名。- 对于已经使用ASP enable了结构化稀疏的模型,在保存后重新加载时,需要先创建一个新的模型,并调用
init_model_for_pruning方法为模型添加mask buffer后再load模型的state_dict,否则因为新模型的state_dict和之前保存的state_dict不同而报错。
Example:
写了一个简单的Conv-FC网络,训练后使用ASP进行剪枝,随后再次进行训练
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from apex.contrib.sparsity import ASP# 定义卷积神经网络模型
class ConvNet(nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv1 = nn.Conv2d(1, 16, 3, padding=1)self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(16, 32, 3, padding=1)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(2, 2)self.fc1 = nn.Linear(32 * 7 * 7, 128)self.relu3 = nn.ReLU()self.fc2 = nn.Linear(128, 10)self.sig = nn.Sigmoid()def forward(self, x):x = self.pool1(self.relu1(self.conv1(x)))x = self.pool2(self.relu2(self.conv2(x)))x = x.view(-1, 32 * 7 * 7)x = self.relu3(self.fc1(x))x = self.fc2(x)x = self.sig(x)return xdef train_loop(model, optimizer, criterion):num_epochs = 1for epoch in range(num_epochs):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = data[0].to(device), data[1].to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()if i % 100 == 99:print(f'Epoch [{epoch+1}/{num_epochs}], Batch [{i+1}/{len(trainloader)}], Loss: {running_loss/100:.4f}')running_loss = 0.0def val(model):correct = 0total = 0model.eval()with torch.no_grad():for images, labels in testloader:images, labels = images.to(device), labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = correct / total * 100print("Test Accuracy :{}%".format(accuracy))return accuracydef main():# 训练网络print('Begin to train the dense network!')train_loop(model, optimizer, criterion)print('Finish training the dense network!')accuracy_dense = val(model)print('The accuracy of the trained dense network is : {}'.format(accuracy_dense))torch.save(model.state_dict(), 'model_weights.pth')ASP.prune_trained_model(model, optimizer)accuracy_sparse = val(model)print('The accuracy of the truned network is : {}'.format(accuracy_sparse))print('Begin to train the sparse network!')train_loop(model, optimizer, criterion)print('Finish training the sparse network!')accuracy_sparse = val(model)print('The accuracy of the trained sparse network is : {}'.format(accuracy_sparse))torch.save(model.state_dict(), 'model_weights_sparse.pth')print('Training finished!')if __name__ == '__main__':transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))])trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = ConvNet().to(device)print('original weights has been saved!')criterion = nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)main()
运行结果
root:/home/shanlin/cnn_demo# python train.py
Found permutation search CUDA kernels
[ASP][Info] permutation_search_kernels can be imported.
original weights has been saved!
Begin to train the dense network!
The accuracy of the trained dense network is : 94.77...The accuracy of the truned network is : 94.15...The accuracy of the trained sparse network is : 96.6
Training finished!
root:/home/shanlin/cnn_demo#
可以看出,第一次训练后accuracy达到了94.77,剪枝后下降到了94.15,再次训练后重新上升到了96.6,比第一次训练还高,应该是因为模型是随便写的且数据集太简单的原因,
相关文章:
——使用方法)
英伟达结构化剪枝工具Nvidia Apex Automatic Sparsity [ASP](1)——使用方法
英伟达结构化剪枝工具Nvidia Apex Automatic Sparsity [ASP](1)——使用方法 Apex是Nvdia维护的pytorch工具库,包括混合精度训练和分布式训练,Apex的目的是为了让用户能够更早的使用上这些“新鲜出炉”的训练工具。ASP࿰…...

接口测试,负载测试,并发测试,压力测试区别
接口测试 1.定义:接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。 2.目的…...

WebRTC +Signal + ICE
在 WebRTC 中,ICE(Interactive Connectivity Establishment)服务是用于解决网络地址转换(NAT)和防火墙障碍的关键组件。以下是一些常见的开源 ICE 服务框架,可以用于搭建 ICE 服务器来支持 WebRTC 连接&…...
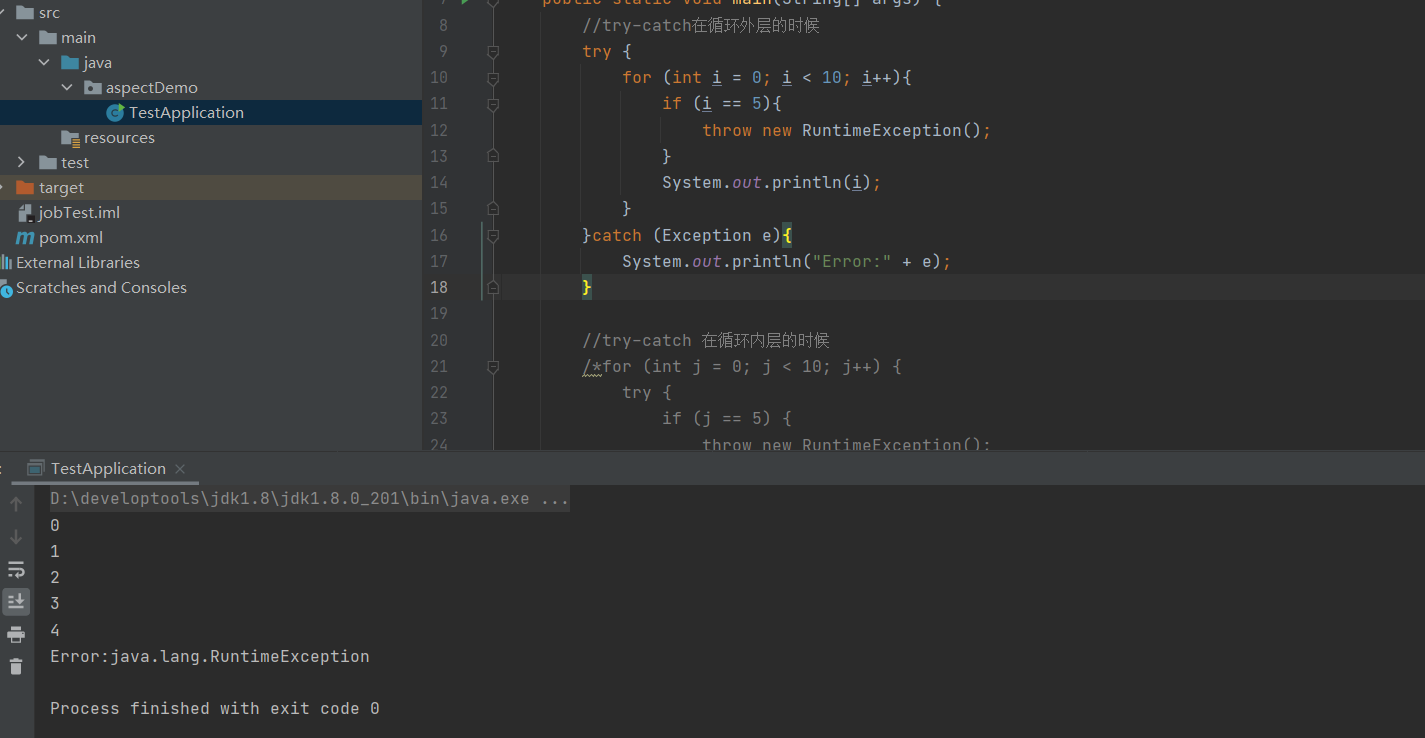
循环内的try-catch 跟循环外的try-catch有什么不一样
起因:一位面试管突然问了这么一道基础的面试题,反而秀了面试者一脸,经常用的却被问到时不知道怎么回答,所以我们平时在写代码的时候,要多注意细节跟原理。也许你不服:不就是先这样,再那样&#…...

C语言实现Java三大特性
// 前言 面向对象的java语言有着多种设计模式与特性。比如封装、继承、多态等等。 在这篇文章中,我会使用java的代码思路,实现C语言版的JAVA三大特性。 并从写代码的角度,从0开始构建。 定义结构体(对象) 设计了一…...

GBU812-ASEMI新能源专用整流桥GBU812
编辑:ll GBU812-ASEMI新能源专用整流桥GBU812 型号:GBU812 品牌:ASEMI 封装:GBU-4 恢复时间:>50ns 正向电流:80A 反向耐压:1200V 芯片个数:4 引脚数量ÿ…...
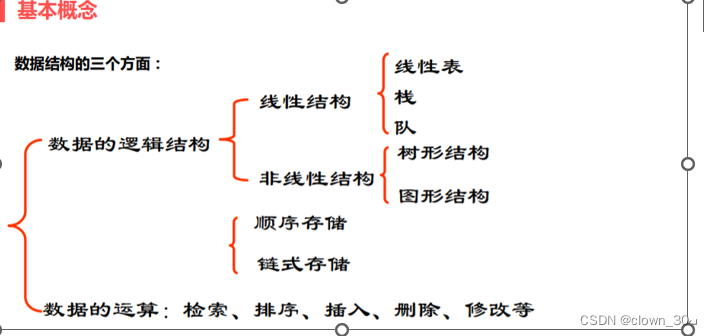
数据结构,线性表与线性结构关系,顺序表与顺序结构关系,线性表与顺序表关系
学习数据结构会出现很多的概念如顺序结构,非线性结构,顺序表,顺序结构,顺序表,链表,栈,队列,堆等。今天来小讲以下其中的线性表与线性结构,顺序表与顺序结构的关系。 在数…...
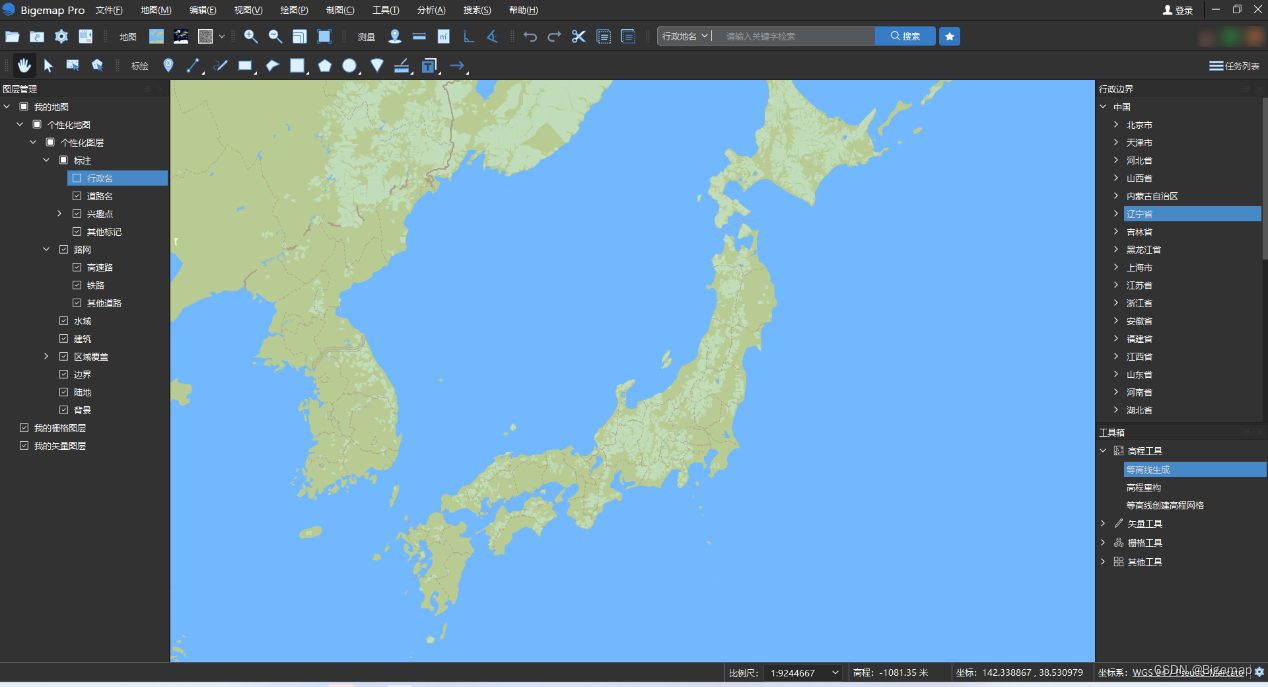
Bigemap Pro国产基础软件介绍——一款多源数据处理软件
一、软件简介 Bigemap Pro是由成都比格图数据处理有限公司(下称”BIGEMAP”)开发和发行的国产大数据处理基础软件。Bigemap Pro是在BIGEMAP GIS Office基础上,经过十年的用户积累与反馈和技术更新迭代出的新一代基础软件产品。Bigemap Pro国产基础软件集成了数据采…...

算法练习Day49|● 121. 买卖股票的最佳时机 ● 122.买卖股票的最佳时机II
LeetCode: 121. 买卖股票的最佳时机 121. 买卖股票的最佳时机 - 力扣(LeetCode) 1.思路 暴力解法、贪心也算比较符合思维,动规不容易想到,且状态处理不易处理 股票每天的状态为持有或不持有:声明dp数组:…...
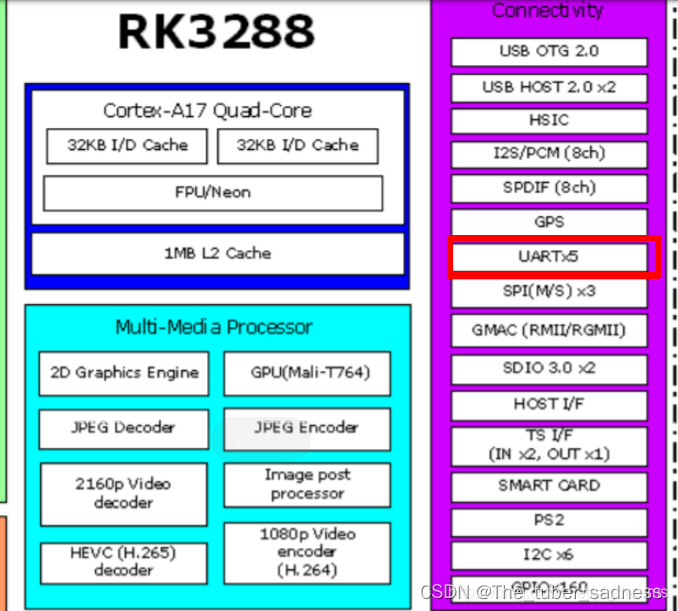
【Android Framework (十二) 】- 智能硬件设备开发
文章目录 前言智能硬件的定义与应用智能硬件产品开发流程智能硬件开发所涉及的技术体系概述关于主板选型主板CPU芯片的选择关于串口通信 总结 前言 针对我过往工作经历,曾在一家智能科技任职Android开发工程师,简单介绍下关于任职期间接触和开发过的一些…...
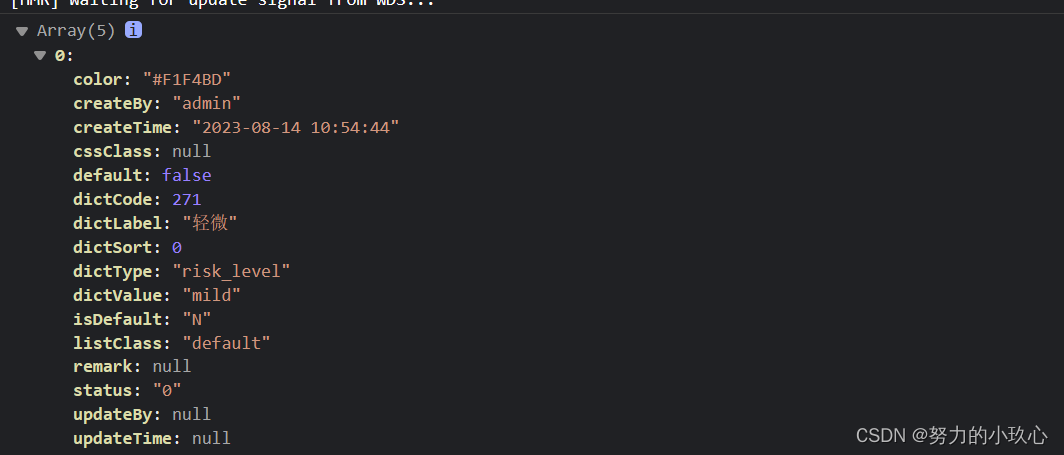
若依框架给字典字段新增color值,并且实现下拉列表选项进行颜色设置
首先获取所要新增的字典,并且根据字典的value值选取对应的颜色参数 this.getDicts("risk_level").then(response > {const color {mild:#F1F4BD,moderate:#EEC920,severe:#FF6C0D,very_severe:#FF0000,no_harm:green};const res response.data.map(…...
JDK 8 升级 JDK 17 全流程教学指南
JDK 8 升级 JDK 17 首先已有项目升级是会经历一个较长的调试和自测过程来保证允许和兼容没有问题。先说几个重要的点 遇到问题别放弃仔细阅读报错,精确到每个单词每一行,不是自己项目的代码也要点进去看看源码到底是为啥报错明确你项目引入的包&#x…...
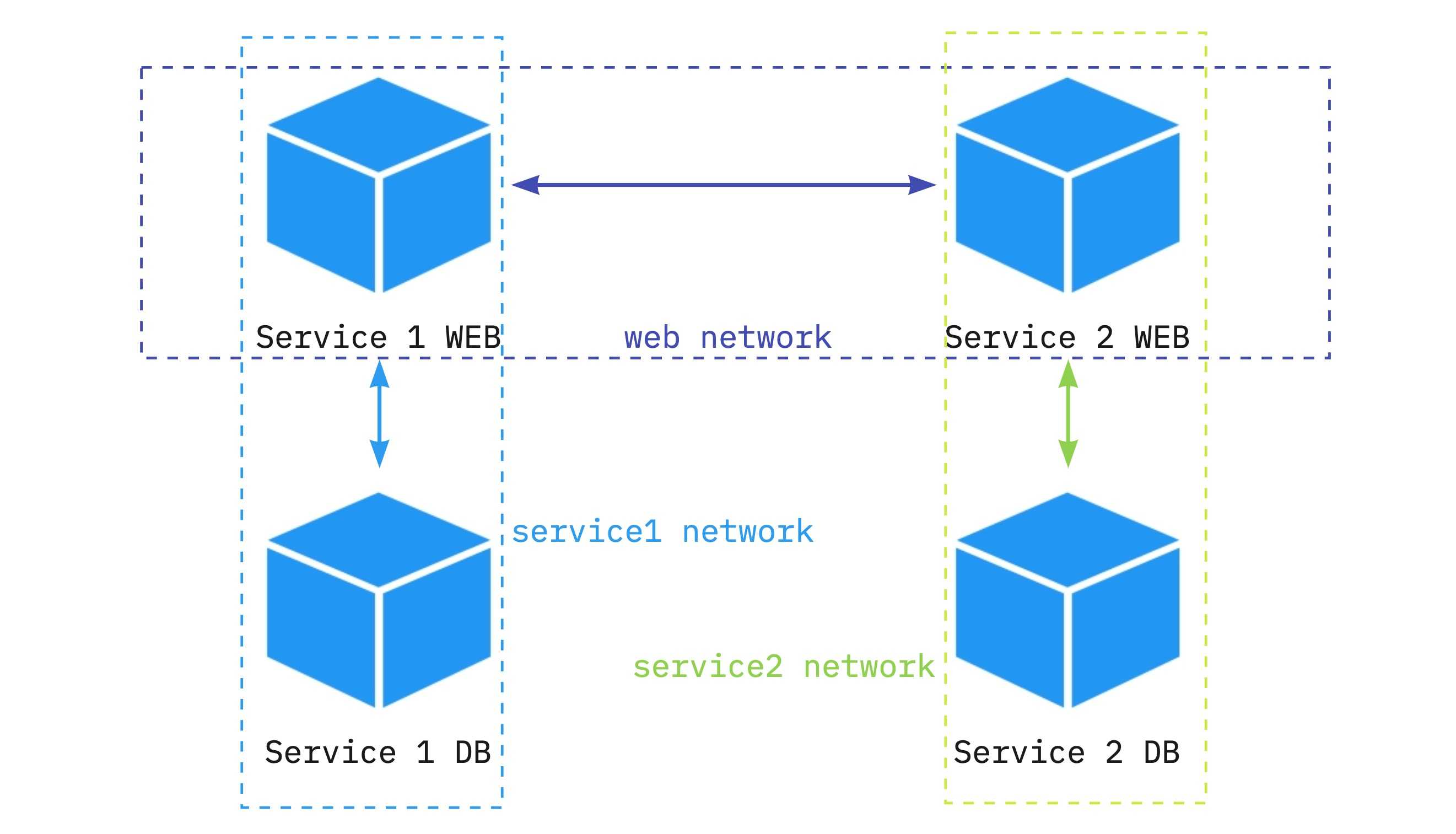
Docker 网络之 ipvlan 和 macvlan
Docker ipvlan 和 macvlan 引言 本文讲解了Docker 网络模式中的 ipvlan 和 macvlan 的区别,目前自己在生产环境中使用的 ipvlan 模式非常问题.也解决了实际业务问题. IPvlan L2 mode example ipvlan 无需网卡混杂模式 , 运行如下命令后可以生成一个 vlan 子接口 , 会和主网卡…...
【Rust】Rust学习 第十三章Rust 中的函数式语言功能:迭代器与闭包
Rust 的设计灵感来源于很多现存的语言和技术。其中一个显著的影响就是 函数式编程(functional programming)。函数式编程风格通常包含将函数作为参数值或其他函数的返回值、将函数赋值给变量以供之后执行等等。 更具体的,我们将要涉及&#…...

【Linux操作系统】详解Linux系统编程中的管道进程通信
在Linux系统编程中,管道是一种常用的进程间通信方式。它可以实现父子进程之间或者兄弟进程之间的数据传输。本文将介绍如何使用管道在Linux系统中进行进程通信,并给出相应的代码示例。 文章目录 1. 管道的概念2. 管道的创建和使用2.1 原型2.2 示例 3. 父…...

【Redis从头学-4】Redis中的String数据类型实战应用场景之验证码、浏览量、点赞量、Json格式存储
🧑💻作者名称:DaenCode 🎤作者简介:啥技术都喜欢捣鼓捣鼓,喜欢分享技术、经验、生活。 😎人生感悟:尝尽人生百味,方知世间冷暖。 📖所属专栏:Re…...

linux 统计命令
统计命令 使用wc来进行统计 # wc [选项] 文件名wc -l a 2 awc -w a 8 a---------------l 统计行数-w 统计单词数-m 统计字符数-c 统计字节数 https://zhhll.icu/2021/linux/基础/统计命令/ 本文由 mdnice 多平台发布...

docker部署springboot应用
一、下载安装docker curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun 启动:systemctl start docker 二、配置国内镜像源 (1)在/etc/docker目录中添加daemon.json文件,内容如下: { …...
YOLO v5、v7、v8 模型优化
YOLO v5、v7、v8 模型优化 魔改YOLOyaml 文件解读模型选择在线做数据标注 YOLO算法改进YOLOv5yolo.pyyolov5.yaml更换骨干网络之 SwinTransformer更换骨干网络之 EfficientNet优化上采样方式:轻量化算子CARAFE 替换 传统(最近邻 / 双线性 / 双立方 / 三线…...

回归预测 | MATLAB实现SSA-BP麻雀搜索算法优化BP神经网络多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现SSA-BP麻雀搜索算法优化BP神经网络多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现SSA-BP麻雀搜索算法优化BP神经网络多输入单输出回归预测(多指标,多图)效果一览基本…...

Arduino Audio Tools终极指南:从音频新手到专业开发者的完整解决方案
Arduino Audio Tools终极指南:从音频新手到专业开发者的完整解决方案 【免费下载链接】arduino-audio-tools Arduino Audio Tools (a powerful Audio library not only for Arduino) 项目地址: https://gitcode.com/gh_mirrors/ar/arduino-audio-tools 在嵌入…...

掌握高效B站会员购抢票技巧:biliTickerBuy实战指南
掌握高效B站会员购抢票技巧:biliTickerBuy实战指南 【免费下载链接】biliTickerBuy b站会员购购票辅助工具 项目地址: https://gitcode.com/GitHub_Trending/bi/biliTickerBuy biliTickerBuy是一款专为B站会员购平台设计的开源抢票辅助工具,通过P…...

为你的 AI Agent 项目选择并接入性价比更高的多模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的 AI Agent 项目选择并接入性价比更高的多模型服务 在构建 AI Agent 应用时,开发者常常面临一个两难选择…...
)
告别安装报错!Windows 10/11 保姆级 MySQL 5.7.44 配置指南(含my.ini文件详解)
Windows 10/11 下 MySQL 5.7.44 终极安装指南:从避坑到精通配置 每次在Windows系统上安装MySQL,总会有那么几个"经典"错误让人抓狂——服务启动失败、初始化报错、环境变量配置无效... 作为一个经历过无数次安装折磨的老手,我决定…...

Dell R730 2U服务器实战:解锁Nvidia P4计算卡在虚拟化环境下的AI训练潜能
1. 硬件准备与安装避坑指南 Dell PowerEdge R730作为一款经典的2U机架式服务器,在二手市场上性价比极高。我最近给实验室淘了两台二手R730,准备搭建AI训练集群。这次重点分享如何在这台服务器上安装Nvidia Tesla P4计算卡的经验。 先说说为什么选P4这张卡…...

从原理到实战:压敏电阻关键参数解析与精准选型指南
1. 压敏电阻的本质:电路中的"电压保险丝" 第一次接触压敏电阻时,我把它当成了普通电阻,结果在电源防护设计上栽了跟头。这种蓝色圆片状的小器件,实际上是电子工程师最常用的过压保护元件之一。它的工作原理很像保险丝&a…...

Ubuntu 18.04.6 从零到一:新手避坑与高效配置实战指南
1. 为什么选择Ubuntu 18.04.6? Ubuntu 18.04.6是长期支持版本(LTS)的最终更新,特别适合需要稳定系统的用户。相比最新版本,它的软件生态更成熟,社区支持更完善。我实测发现,这个版本对老硬件兼容…...

超越基础扫描:实战解析Tessent ATPG中的Clock PO与RAM Sequential Patterns如何提升故障覆盖率
超越基础扫描:实战解析Tessent ATPG中的Clock PO与RAM Sequential Patterns如何提升故障覆盖率 在数字电路测试领域,达到95%以上的故障覆盖率曾是许多DFT工程师的终极目标,直到他们遇到了时钟驱动输出和嵌入式RAM模块。这些特殊结构如同电路…...

数字图像处理入门:像素、通道与卷积操作的核心原理与实践
1. 项目概述:为什么“基本知识”是数字图像处理的基石刚入行做图像处理那会儿,我犯过一个典型的“新手错误”:拿到一张图,二话不说就开始调OpenCV的函数,什么高斯模糊、边缘检测、二值化,一顿操作猛如虎&am…...

为Claude Code配置Taotoken作为备用API服务商防止中断
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken作为备用API服务商防止中断 当您依赖Claude Code作为编程助手时,可能会遇到服务暂时不可用或…...