python爬虫7:实战1
python爬虫7:实战1
前言
python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。
申明
本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好影响。
目录结构
文章目录
- python爬虫7:实战1
- 1. 目标
- 2. 详细流程
- 2.1 找到目标小说
- 2.2 获取小说章节目录
- 2.3 获取小说内容
- 2.4 完整代码
- 3. 总结
1. 目标
这次爬虫实战,采用的库为:requests + lxml,这次以爬取一部小说为目标,具体的网站老规矩就不给了,大家学习思路最重要。
再次说明,案例本身并不重要,重要的是如何去使用和分析,另外为了避免侵权之类的问题,我不会放涉及到网站的图片,希望能理解。
2. 详细流程
2.1 找到目标小说
第一步,确定get请求的url
假设我们的网站为:https://xxxxxxx.com,那么,我们首先需要找到搜索框,然后随意搜索几本小说,比如这里我搜索的是圣墟、万族之劫,那么观察网页上的url变化,如下:
https://xxxxx?q=圣墟
https://xxxxx?q=万族之劫
可以看出,这里是get请求,并且参数名为q。
第二步,正确请求网页
我们可以写下第一个代码了,目标是获取想要的小说,代码如下:
# 都要用到的参数
HEADERS = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}# 获取搜索某小说后的页面
def get_search_result():# 网址url = 'xxxxx'# 请求参数search = input('请输入想要搜索的小说:')params = {'q' : search}# 请求response = requests.get(url,headers=HEADERS,params=params)# 把获取到的网页保存到本地with open('search.html','w',encoding='utf-8') as f:f.write(response.content.decode('utf-8'))
结果如下:

可以看出,获取到正确的网页,说明这一步我们完成了。
正确解析网页,以获取小说链接
上面,我们已经把网页源码存放到了本地一个名为search.html的文件,下面我们来解析它。
解析它,首先需要明确我们要获取什么节点、什么值。看下面:

可以看出,我们的目标标签位于div[class="mshow"]下的table[class="grid"]下的td下的a标签,并且我们需要获取这个a标签的href属性和文本值。除此之外,href属性值只是部分地址,需要跟网站根地址xxxx.com拼凑再一起。
基于此,可以完成代码:
# 解析网页
def parse_search_result():# 打开文件,读取文件with open('search.html','r',encoding='utf-8') as f:content = f.read()# 基础urlbase_url = 'xxxxxx.com/'# 初始化lxmlhtml = etree.HTML(content)# 获取目标节点href_list = html.xpath('//div[@class="show"]//table[@class="grid"]//td//a/@href')text_list = html.xpath('//div[@class="show"]//table[@class="grid"]//td//a/text()')# 处理内容值url_list = [base_url+href for href in href_list]# 选择要爬取的小说for i,text in enumerate(text_list):print('当前小说名为:',text)decision = input('是否爬取它(只能选择一本),Y/N:')if decision == 'Y':return url_list[i],text
运行结果如下:

2.2 获取小说章节目录
第一步,请求页面
首先,我们去请求上面获取的网页,这里就比较简单了,基本上把上面的请求代码拷贝过来修改修改即可:
# 请求目标小说网站
def get_target_book(url):# 请求response = requests.get(url,headers=HEADERS)# 保存源码with open('book.html','w',encoding='utf-8') as f:f.write(response.content.decode('utf-8'))
可以看到保存到本地的结果如下:

可以看出,这一步成功了。
第二步,解析上面的网页,获取不同章节的链接
这一步,主要的难点在于解析网页,首先,看下面:

由于该网页小说章节都分为两个部位,第一个为最新章节,第二个为全部章节,而第二个才是我们需要获取的,因此xpath语法应该为:
//div[@class="show"]//div[contains(@class,'showBox') and position()=3]//ul//a
那么,可以完成代码如下:
# 解析章节网页
def parse_chapter(base_url):# 打开文件,读取内容with open('book.html','r',encoding='utf-8') as f:content = f.read()# 初始化html = etree.HTML(content)# 解析href_list = html.xpath('//div[@class="show"]//div[contains(@class,"showBox") and position()=3]//ul//a/@href')text_list = html.xpath('//div[@class="show"]//div[contains(@class,"showBox") and position()=3]//ul//a/text()')# 处理:拼凑出完整网页url_list = [base_url+url for url in href_list]# 返回结果return url_list,text_list
运行结果如下:

2.3 获取小说内容
这里我们就不分开了,直接获取源码后直接解析。那么这里说明一下解析原理,看下面:

可以轻松知道xpath语法:
//div[contains(@class,'book')]//div[@id='content']//text()
那么,代码如下:
# 请求小说页面
def get_content(url,title):# 请求response = requests.get(url,headers=HEADERS)# 获取源码content = response.content.decode('utf-8')# 初始化html = etree.HTML(content)# 解析text_list = html.xpath('//div[contains(@class,"book")]//div[@id="content"]//text()')# 后处理# 首先,把第一个和最后一个的广告信息去掉text_list = text_list[1:-1]# 其次,把里面的空白字符和\xa0去掉text_list = [text.strip().replace('\xa0','') for text in text_list]# 最后,写入文件即可with open(title+'.txt','w',encoding='utf-8') as g:for text in text_list:g.write(text+'\n')
运行结果如下:

可以看出,成功实现。
2.4 完整代码
完整代码如下:
# author : 自学小白菜
# -*- coding:utf-8 -*-'''
# File Name : 7 lxml_novel.py
# Create Time : 2023/8/5 22:04
# Version : python3.7
# Description : 实战1:爬取小说
'''# 导包
import requests
from lxml import etree# 都要用到的参数
HEADERS = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}# 获取搜索某小说后的页面
def get_search_result():# 网址url = 'https://www.iwurexs.net/so.html'# 请求参数search = input('请输入想要搜索的小说:')params = {'q' : search}# 请求response = requests.get(url,headers=HEADERS,params=params)# 把获取到的网页保存到本地with open('search.html','w',encoding='utf-8') as f:f.write(response.content.decode('utf-8'))# 解析网页
def parse_search_result():# 打开文件,读取文件with open('search.html','r',encoding='utf-8') as f:content = f.read()# 基础urlbase_url = 'https://www.iwurexs.net/'# 初始化lxmlhtml = etree.HTML(content)# 获取目标节点href_list = html.xpath('//div[@class="show"]//table[@class="grid"]//td//a/@href')text_list = html.xpath('//div[@class="show"]//table[@class="grid"]//td//a/text()')# 处理内容值url_list = [base_url+href for href in href_list]# 选择要爬取的小说for i,text in enumerate(text_list):print('当前小说名为:',text)decision = input('是否爬取它(只能选择一本),Y/N:')if decision == 'Y':return url_list[i],text# 请求目标小说网站
def get_target_book(url):# 请求response = requests.get(url,headers=HEADERS)# 保存源码with open('book.html','w',encoding='utf-8') as f:f.write(response.content.decode('utf-8'))# 解析章节网页
def parse_chapter(base_url):# 打开文件,读取内容with open('book.html','r',encoding='utf-8') as f:content = f.read()# 初始化html = etree.HTML(content)# 解析href_list = html.xpath('//div[@class="show"]//div[contains(@class,"showBox") and position()=3]//ul//a/@href')text_list = html.xpath('//div[@class="show"]//div[contains(@class,"showBox") and position()=3]//ul//a/text()')# 处理:拼凑出完整网页url_list = [base_url+url for url in href_list]# 返回结果return url_list,text_list# 请求小说页面
def get_content(url,title):# 请求response = requests.get(url,headers=HEADERS)# 获取源码content = response.content.decode('utf-8')# 初始化html = etree.HTML(content)# 解析text_list = html.xpath('//div[contains(@class,"book")]//div[@id="content"]//text()')# 后处理# 首先,把第一个和最后一个的广告信息去掉text_list = text_list[1:-1]# 其次,把里面的空白字符和\xa0去掉text_list = [text.strip().replace('\xa0','') for text in text_list]# 最后,写入文件即可with open(title+'.txt','w',encoding='utf-8') as g:for text in text_list:g.write(text+'\n')if __name__ == '__main__':# 第一步,获取到搜索页面的源码# get_search_result()# 第二步,进行解析target_url,name = parse_search_result()# 第三步,请求目标小说页面get_target_book(target_url)# 第四步,解析章节网页url_list,text_list = parse_chapter(target_url)for url,title in zip(url_list,text_list):# 第五步,请求小说具体的某个章节并直接解析get_content(url,title)break
3. 总结
上面代码还不完善,存在一定优化的地方,比如代码有些地方可以解耦,另外,必须限制访问速度,不然后期容易被封掉IP,除此之外,可以考虑代理池构建等操作。
相关文章:
python爬虫7:实战1
python爬虫7:实战1 前言 python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。 申明 本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好…...
uniApp引入vant2
uniApp引入vant2 1、cnpm 下载:cnpm i vantlatest-v2 -S2、main.js文件引入 import Vant from ./node_modules/vant/lib/vant;Vue.use(Vant);3.app.vue中引入vant 样式文件 import /node_modules/vant/lib/index.css;...
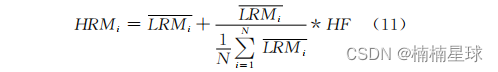
如何大幅提高遥感影像分辨率(Python+MATLAB)
前言: 算法:NSCT算法(非下采样变换) 数据:Landsat8 OLI 遥感图像数据 编程平台:MATLAB+Python 论文参考:毛克.一种快速的全色和多光谱图像融合算法[J].测绘科学,2016,41(01):151-153+98.DOI:10.16251/j.cnki.1009-2307.2016.01.028. 左图:未进行融合的多光谱真彩色合…...

nginx php-fpm安装配置
nginx php-fpm安装配置 nginx本身不能处理PHP,它只是个web服务器,当接收到请求后,如果是php请求,则发给php解释器处理,并把结果返回给客户端。 nginx一般是把请求发fastcgi管理进程处理,fascgi管理进程选…...

通过ip获取地理位置信息
GeoLite2-City.mmdb 文件是 MaxMind 公司提供的一个免费的 IP 地址与城市地理位置映射数据库文件。它包含了 IP 地址范围与对应的城市、地区、国家、经纬度等地理位置信息的映射。这种数据库文件可以用于识别访问您的应用程序或网站的用户的地理位置,从而实现针对不…...

数据库索引优化策略与性能提升实践
文章目录 什么是数据库索引?为什么需要数据库索引优化?数据库索引优化策略实践案例:索引优化带来的性能提升索引优化规则1. 前导模糊查询不适用索引2. 使用IN优于UNION和OR3. 负向条件查询不适用索引4. 联合索引最左前缀原则5. 范围条件查询右…...
))详细介绍】)
【ARM 嵌入式 编译系列 11.1 -- GCC __attribute__((aligned(x)))详细介绍】
文章目录 __attribute__((aligned(x)))详细介绍其它对齐方式上篇文章:ARM 嵌入式 编译系列 11 – GCC attribute((packed))详细介绍 attribute((aligned(x)))详细介绍 __attribute__((aligned(x))) 是 GCC 编译器的一个特性,它可以用于变量或类型,用来指定它们在内存中的…...

【计算机视觉|生成对抗】逐步增长的生成对抗网络(GAN)以提升质量、稳定性和变化
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处 标题:Progressive Growing of GANs for Improved Quality, Stability, and Variation 链接:[1710.10196] Progressive Growing of GANs for Improved Quality, Stability, and Vari…...
 condition_variable、wait、notify_one、notify_all)
C++11并发与多线程笔记(8) condition_variable、wait、notify_one、notify_all
C11并发与多线程笔记(8) condition_variable、wait、notify_one、notify_all 1、条件变量condition_variable、wait、notify_one、notify_all1.1 std::condition_variable1.2 wait()1.3 notify_one()1.4 notify_all() 2、深入思考 1、条件变量condition_…...

C语言——通讯录详解(动态版)
通讯录详解 前言:一、定义一个通讯录二、初始化三、增加联系人3.1 给通讯录扩容3.2增加联系人 四、释放内存五、完整代码 前言: 我们已经学过了通讯录的静态版,但是它的缺点很明显,通讯录满了就添加不了联系人了啦。我再让通讯录升…...

【云原生】kubernetes应用程序包管理工具Helm
Helm 什么是 Helm 安装 Helm 重要概念 使用 Helm 1 简介 官网地址: Helm Helm是一个Kubernetes应用程序包管理工具,它允许你轻松管理和部署Kubernetes应用程序。Helm通过使用称为Charts的预定义模板来简化Kubernetes应用程序的部署和管理。Chart包含了一组Ku…...
蓝牙资讯|苹果Apple Watch可手势操控Mac和Apple TV等设备
根据美国商标和专利局(USPTO)公示的清单,苹果公司近日获得了一项技术专利,概述了未来的 Apple Watch 手表,使用手势等操控 Mac 和 Apple TV 等设备。 该专利描述未来 Apple Watch 可以交互实现编辑图像、绘图、处理文…...
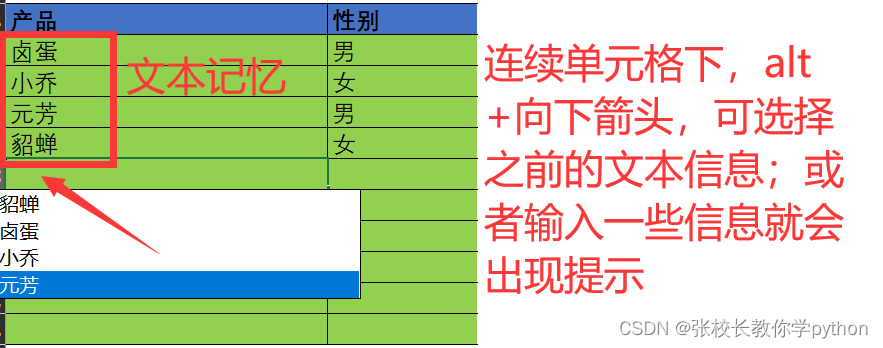
认识excel篇2之如何快速输入数据
一、快速输入数据(快捷键功能的使用) 1、鼠标左键填充:复制填充、等差序列填充(行、列是一样的) 步骤:选中单元格,鼠标放置到单元格右下角待鼠标箭头变成实心十字架,左键向下拖拽&…...

将eNSP Pro部署在华为云是什么体验
eNSP Pro简介 eNSP Pro 是华为公司数据通信产品线新推出的数通设备模拟器,主要应用在数据通信技能培训,为使用者提供华为数据通信产品设备命令行学习环境。 具备的能力 多产品模拟能力:支持数据通信产品线NE路由器、CE交换机、S交换机、AR…...
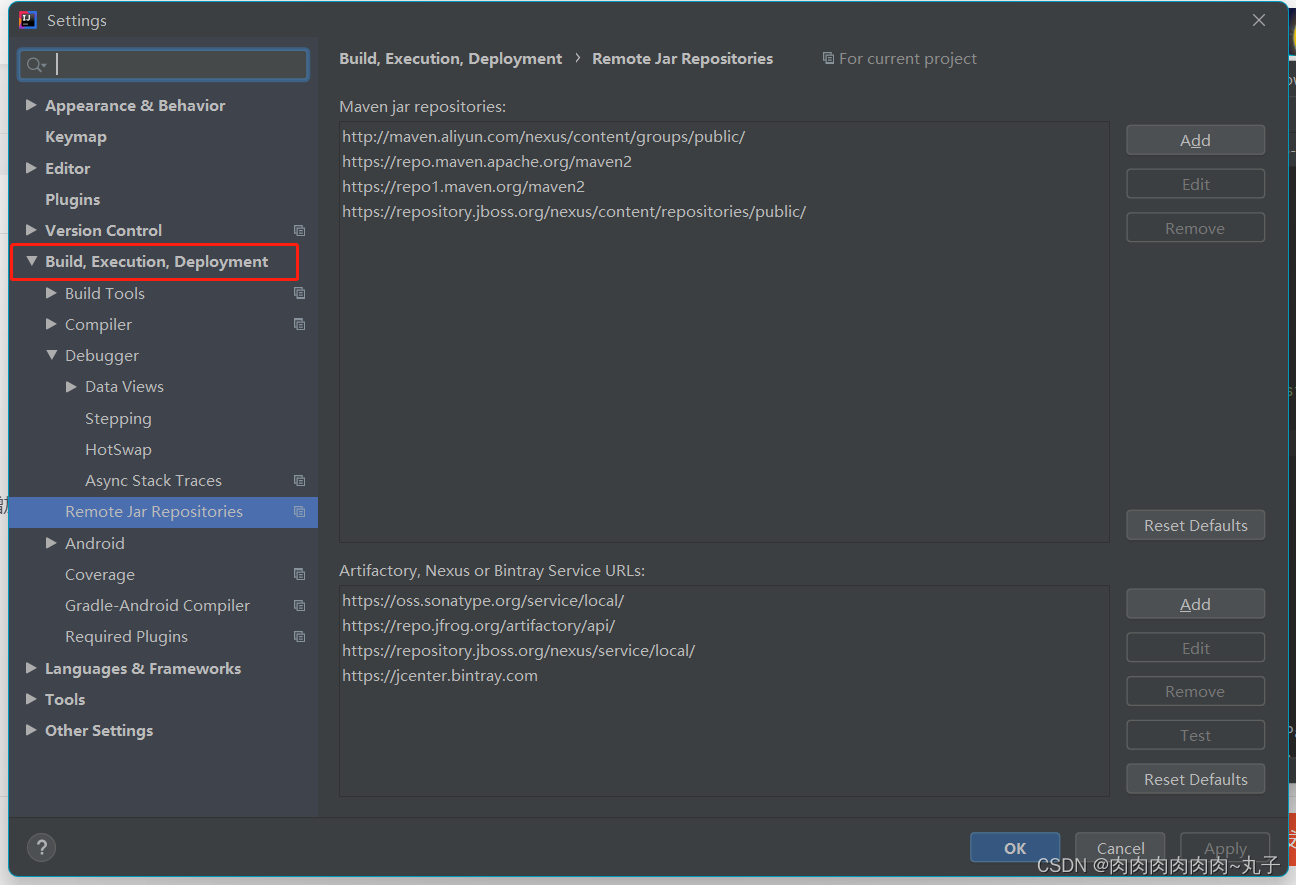
Intelij IDEA 配置Tomcat解决Application Server不显示的问题
今天搭建war工程时部署项目发现,IDEA的控制台没有Application Servers,在网上查了一下,总结几个比较好的解决方法,为了方便自己和其他人以后碰到相同的问题,不再浪费时间再次寻找解决办法。 Intelij IDEA 配置Tomcat时…...
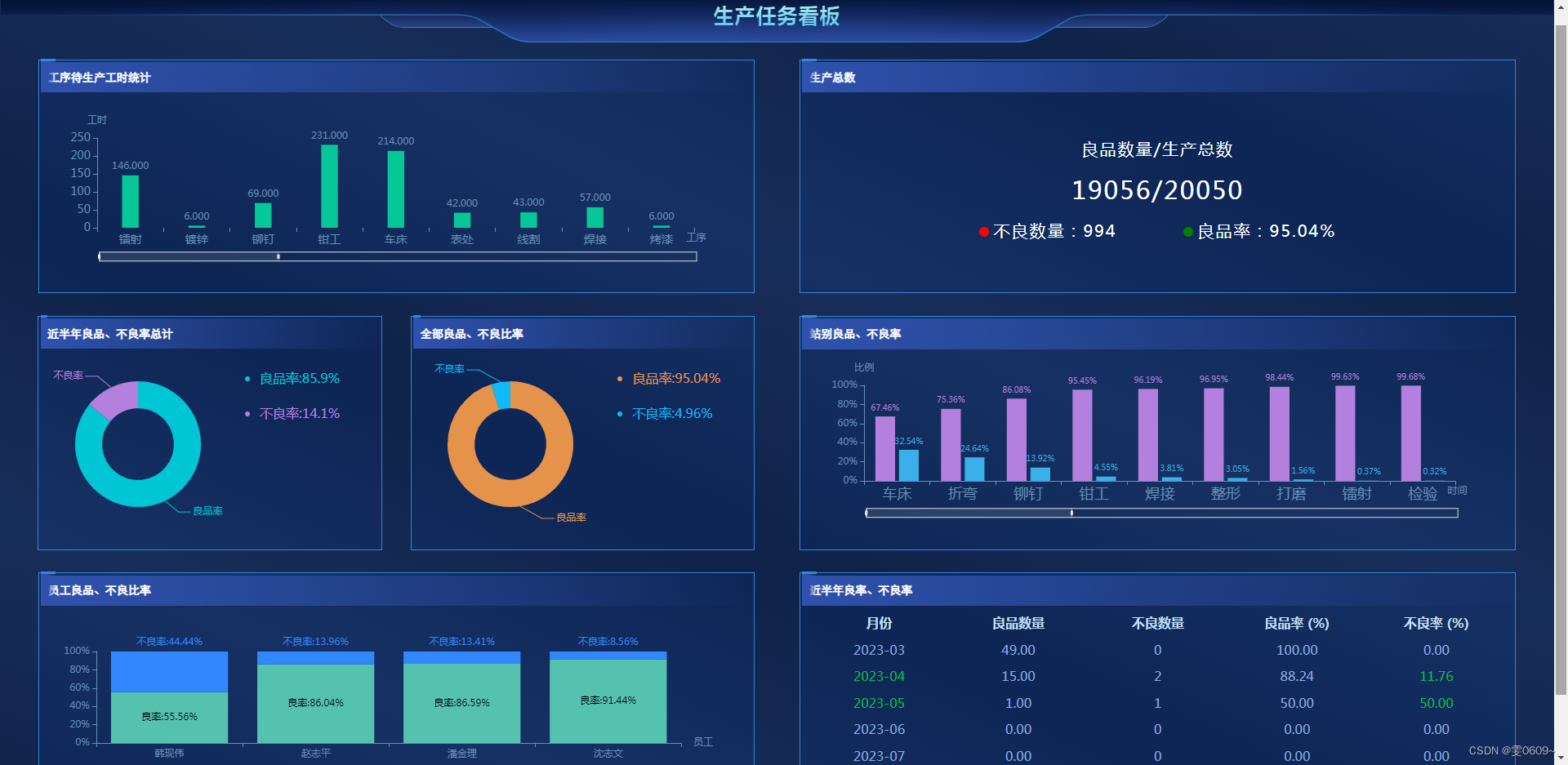
php+echarts实现数据可视化实例
效果: 代码: php <?php include(includes/session.inc); include(includes/SQL_CommonFunctions.inc); ?> <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta http-equiv&quo…...
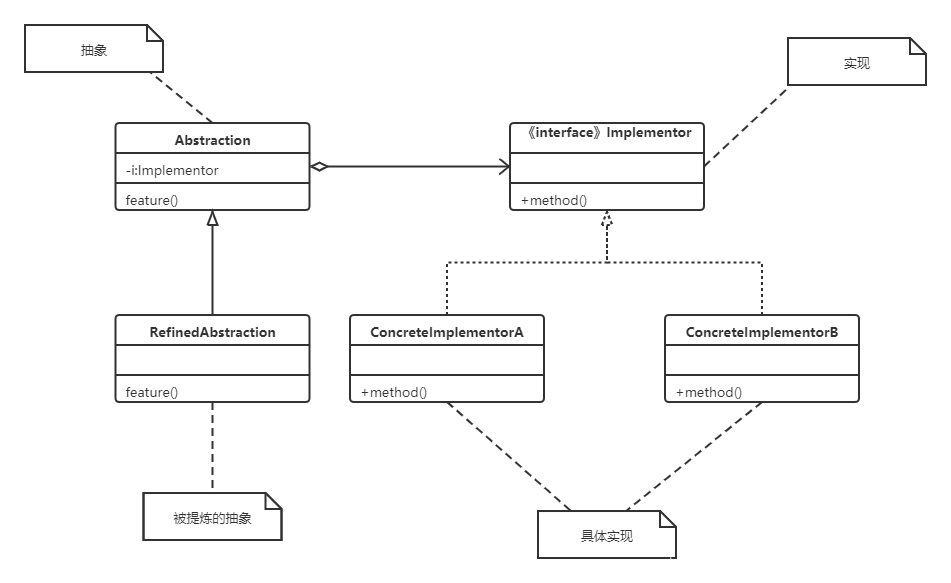
Kotlin~Bridge桥接模式
概念 抽象和现实之间搭建桥梁,分离实现和抽象。 抽象(What)实现(How)用户可见系统正常工作的底层代码产品付款方式定义数据类型的类。处理数据存储和检索的类 角色介绍 Abstraction:抽象 定义抽象接口&…...
【ES6】箭头函数和普通函数的区别
它们之间的区别: (1)箭头函数没有自己的this。 (2)不可以当作构造函数,不可以对箭头函数使用new命令,否则抛出错误。 (3)不可以使用arguments对象,该对象在函…...

【网络基础实战之路】VLAN技术在两个网段中的实际应用详解
系列文章传送门: 【网络基础实战之路】设计网络划分的实战详解 【网络基础实战之路】一文弄懂TCP的三次握手与四次断开 【网络基础实战之路】基于MGRE多点协议的实战详解 【网络基础实战之路】基于OSPF协议建立两个MGRE网络的实验详解 【网络基础实战之路】基于…...
密码学学习笔记(十九):密码学关键术语的解释1
数据加密标准(DES) 数据加密标准是使用最广泛的加密体制,它于1977年被美国国家标准和技术研究所(NIST)采纳为联邦信息处理标准FIPS PUB 46。 DES3DESAES明文分组长度(位)6464128密文分组长度(位)6464128密钥长度&…...

共享茶室智能系统与运营全解析:从空间设计到自动化管理
1. 项目概述:为什么“共享茶室”正在重塑传统茶饮消费如果你最近留意过城市里的新业态,可能会发现一种名为“共享茶室”的空间正在悄然兴起。它不像传统的茶馆那样需要高昂的消费和复杂的社交礼仪,也不像奶茶店那样主打快节奏的“即买即走”。…...

【MYSQL】在Centos7和ubuntu22.04环境下安装
一.MYSQL在Centos7下的安装注意:安装与卸载中,⽤⼾全部切换成为root初期练习,mysql不进⾏⽤⼾管理,全部使⽤root进⾏1.卸载内置环境1-1卸载不要的环境[rootVM-0-3-centos ~]$ ps ajx |grep mariadb # 先检查是否有mariadb存在 131…...

音乐歌词获取终极指南:如何3分钟搞定全网歌曲歌词的完整方案
音乐歌词获取终极指南:如何3分钟搞定全网歌曲歌词的完整方案 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 你是否曾经为了找到一首心爱歌曲的完整歌词而花费…...

HPM6750 CAN FD实战:从波特率配置到高效收发,避坑指南
1. 项目概述:从经典CAN到CAN FD的实战入门作为一名长期在嵌入式领域摸爬滚打的开发者,我深知现场总线技术,尤其是CAN总线,在工业控制、汽车电子等领域的核心地位。随着数据吞吐量需求的激增,经典CAN的1Mbps带宽逐渐捉襟…...

Contextcore:轻量高性能的框架无关状态管理核心
1. 项目概述:一个为现代前端应用量身定制的状态管理核心 如果你正在开发一个中大型的React、Vue或任何现代前端应用,并且对现有状态管理库的复杂性、样板代码量或者性能优化感到头疼,那么 lucifer-ux/Contextcore 这个项目很可能就是你一直…...

ThinkPad风扇控制革命:TPFanCtrl2如何让你的笔记本更安静、更凉爽
ThinkPad风扇控制革命:TPFanCtrl2如何让你的笔记本更安静、更凉爽 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾经在深夜工作时被ThinkPad风扇的…...

PVE模板迁移踩坑实录:从‘本地光盘错误’到一键克隆入池的完整避坑指南
PVE模板迁移实战指南:从错误排查到资源池高效管理 在Proxmox VE(PVE)虚拟化环境中,模板迁移是日常运维中的高频操作,也是容易踩坑的重灾区。许多管理员都遇到过这样的场景:精心制作的模板在迁移时突然报错&…...

Swagger2Word终极指南:3种方法实现API文档自动化转换
Swagger2Word终极指南:3种方法实现API文档自动化转换 【免费下载链接】swagger2word 项目地址: https://gitcode.com/gh_mirrors/swa/swagger2word 还在为手动编写API文档而烦恼吗?Swagger2Word为你提供了一站式自动化解决方案,将Swa…...

打造便携式Kali Linux安全评估工具:OpenClaw USB定制全攻略
1. 项目概述:一个便携式安全评估工具的诞生 在安全研究、渗透测试或者应急响应的现场,你经常会遇到一个经典困境:目标环境可能是一台物理隔离的机器,或者是一台你无法安装任何软件的“干净”主机。你需要一个功能强大、即插即用的…...

别再手动算位宽了!Vivado FIR IP核的位宽计算逻辑与配置避坑指南
Vivado FIR IP核位宽计算实战:从黑盒解析到精准配置 在FPGA数字信号处理领域,FIR滤波器作为基础构建模块,其性能表现直接影响整个系统的信号处理质量。而位宽配置这个看似简单的参数,往往成为项目后期调试阶段的"隐形杀手&qu…...