“生成音乐“ 【循环神经网络】
前言
本文介绍循环神经网络的进阶案例,通过搭建和训练一个模型,来对钢琴的音符进行预测,通过重复调用模型来进而生成一段音乐;
使用到Maestro的钢琴MIDI文件 ,每个文件由不同音符组成,音符用三个量来表示:音高pitch、步长step、持续时间duration。通过搭建和训练循环神经网络模型,输入一系列音符能预测下一个音符。
下图是一个钢琴MIDI文件,由不同音符组成:
思路流程
- 导入数据集
- 探索集数据,并进行数据预处理
- 构建模型(搭建神经网络结构、编译模型)
- 训练模型(把数据输入模型、评估准确性、作出预测、验证预测)
- 使用训练好的模型
- 优化模型、重新构建模型、训练模型、使用模型
一、导入数据集
使用到Maestro的钢琴MIDI文件 ,每个文件中由不同音轨组成,音轨中包含了一些音符;我们可以通过遍历每个音轨中的音符,获取音符的开始时间、结束时间、音高、音量等信息,进行音乐分析和处理。
我们到Maestro下载maestro-v2.0.0-midi.zip文件,它包含1282个钢琴MIDI文件,大约58M左右;解压后能看到如下的文件。
2004
2006
2008
2009
2011
2013
2014
2015
2017
2018
LICENSE
maestro-v2.0.0.csv
maestro-v2.0.0.json
README
我们可以使用电脑播放器打开文件夹中钢琴MIDI文件,比如:maestro-v2.0.0/2004/MIDI-Unprocessed_SMF_02_R1_2004_01-05_ORIG_MID--AUDIO_02_R1_2004_05_Track05_wav.midi文件,能听到一段钢琴音乐。
二、探索集数据,并进行数据预处理
2.1 解析MIDI文件
我们使用 pretty_midi 库创建和解析MIDI文件,首先安装一下它,执行如下的命令:
!pip install pretty_midi在notebook jupytre中播放MIDI音频文件,需要安装pyfluidsynth库,执行如下的命令:
!sudo apt install -y fluidsynth写一个程序解析MIDI文件,
import glob
import pretty_midi# 加载maestro-v2.0.0目录下的每个midi文件
filenames = glob.glob(str('./maestro-v2.0.0/*/*.mid*'))
print('Number of files:', len(filenames))# 使用pretty_midi库解析单个MIDI文件,并检查音符的格式
sample_file = filenames[1]
print(sample_file)
pm = pretty_midi.PrettyMIDI(sample_file)# 对MIDI文件进行检查
print('Number of instruments:', len(pm.instruments))
instrument = pm.instruments[0]
instrument_name = pretty_midi.program_to_instrument_name(instrument.program)
print('Instrument name:', instrument_name)2.2 提取音符
在训练模型时,将使用三个变量来表示音符:pitch、step 和 duration。
- pitch是音符的音高,以MIDI音高值表示,范围是0到127,0表示最低音高,127表示最高音高。
- step是是从上一个音符或曲目的开始经过的时间。
- duration是音符的持续时间,以“ticks”为单位表示,一个tick表示MIDI时间分辨率中的最小时间单位,具体的时间取决于MIDI文件的时间分辨率参数。
所以我们需要对每个MIDI文件进行提取音符。
上面打开的xxxMIDI文件,查看它的5个音符
# 查看xxxMIDI文件的10个音符
for i, note in enumerate(instrument.notes[:5]):note_name = pretty_midi.note_number_to_name(note.pitch)duration = note.end - note.startprint(f'{i}: pitch={note.pitch}, note_name={note_name},'f' duration={duration:.4f}')能看到如下的信息
0: pitch=78, note_name=F#5, duration=0.0292
1: pitch=66, note_name=F#4, duration=0.0333
2: pitch=71, note_name=B4, duration=0.0292
3: pitch=83, note_name=B5, duration=0.0365
4: pitch=73, note_name=C#5, duration=0.0333
写一个函数来从MIDI文件中提取音符
import pandas as pd
import collections
import numpy as np# 从MIDI文件中提取音符
def midi_to_notes(midi_file: str) -> pd.DataFrame:pm = pretty_midi.PrettyMIDI(midi_file)instrument = pm.instruments[0]notes = collections.defaultdict(list)# 按开始时间对笔记排序sorted_notes = sorted(instrument.notes, key=lambda note: note.start)prev_start = sorted_notes[0].startfor note in sorted_notes:start = note.startend = note.endnotes['pitch'].append(note.pitch)notes['start'].append(start)notes['end'].append(end)notes['step'].append(start - prev_start)notes['duration'].append(end - start)prev_start = startreturn pd.DataFrame({name: np.array(value) for name, value in notes.items()})通过midi_to_notes函数,提取一个MIDI文件中提取音符
raw_notes = midi_to_notes('./xxx.midi')
raw_notes.head()比如,MIDI文件名称为:maestro-v2.0.0/2004/MIDI-Unprocessed_XP_14_R1_2004_01-03_ORIG_MID--AUDIO_14_R1_2004_03_Track03_wav.midi
pitch是音高。duration 是音符将播放多长时间(以秒为单位),是音符结束时间(end)和音符开始时间(start)之间的差值。step 是从前一个音符开始所经过的时间。
| pitch | start | end | step | duration | |
|---|---|---|---|---|---|
| 0 | 78 | 1.066667 | 1.095833 | 0.000000 | 0.029167 |
| 1 | 66 | 1.071875 | 1.105208 | 0.005208 | 0.033333 |
| 2 | 83 | 1.217708 | 1.254167 | 0.145833 | 0.036458 |
| 3 | 71 | 1.220833 | 1.250000 | 0.003125 | 0.029167 |
| 4 | 85 | 1.356250 | 1.407292 | 0.135417 | 0.051042 |
解释音符名称可能比解释音高更容易,可以使用下面的函数将数字音高值转换为音符名称。音符名称显示了音符类型、变音记号和八度数(例如 C#4)。
get_note_names = np.vectorize(pretty_midi.note_number_to_name)
sample_note_names = get_note_names(raw_notes['pitch'])
sample_note_names[:10]输出信息
array(['F#5', 'F#4', 'B5', 'B4', 'C#6', 'C#5', 'D#6', 'B0', 'D#5', 'B1'], dtype='<U3')
2.3 绘制音轨
从MIDI文件中提取音符后,写一个函数来绘制pitch音高、duration持续时间
from matplotlib import pyplot as plt
from typing import Dict, List, Optional, Sequence, Tuple
import seaborn as sns# 绘制pitch音高、duration持续时间
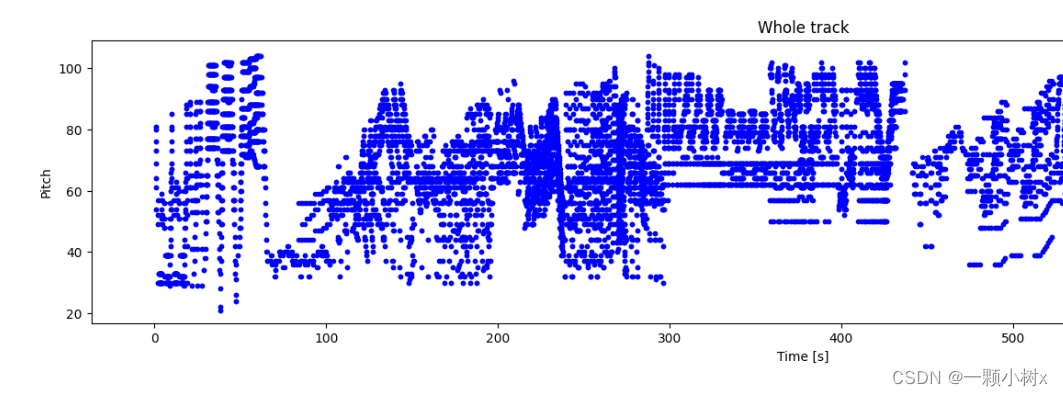
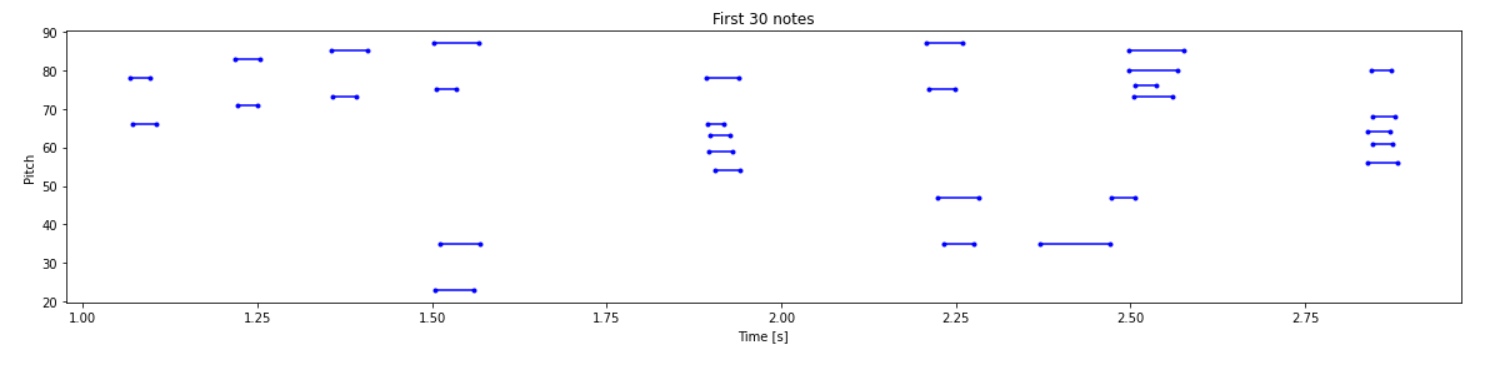
def plot_piano_roll(notes: pd.DataFrame, count: Optional[int] = None):if count:title = f'First {count} notes'else:title = f'Whole track'count = len(notes['pitch'])plt.figure(figsize=(20, 4))plot_pitch = np.stack([notes['pitch'], notes['pitch']], axis=0)plot_start_stop = np.stack([notes['start'], notes['end']], axis=0)plt.plot(plot_start_stop[:, :count], plot_pitch[:, :count], color="b", marker=".")plt.xlabel('Time [s]')plt.ylabel('Pitch')_ = plt.title(title)# 查看MIDI文件30个音符的分布情况
plot_piano_roll(raw_notes, count=30)# 绘制整个音轨的音符
plot_piano_roll(raw_notes)查看MIDI文件50个音高和持续时间的情况
绘制整个音轨的音符
2.4 检查音符分布
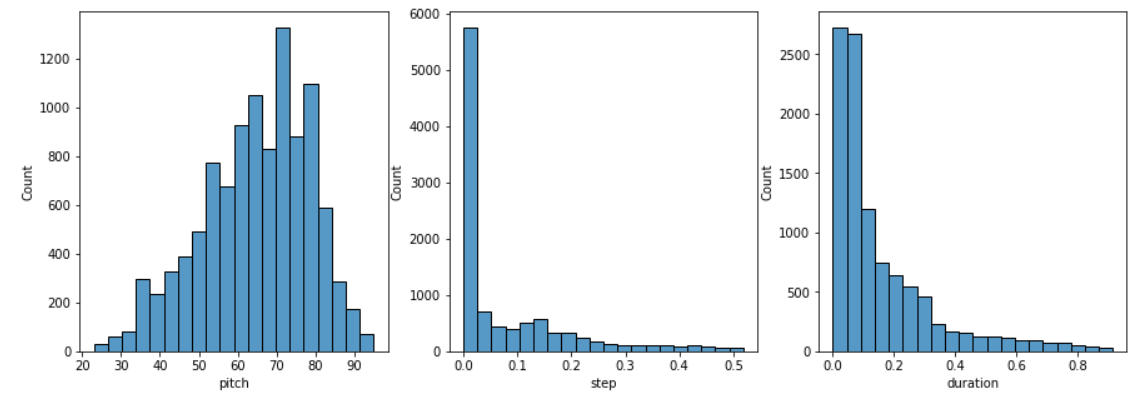
检查每个音符变量的分布,通过如下函数实现
def plot_distributions(notes: pd.DataFrame, drop_percentile=2.5):plt.figure(figsize=[15, 5])plt.subplot(1, 3, 1)sns.histplot(notes, x="pitch", bins=20)plt.subplot(1, 3, 2)max_step = np.percentile(notes['step'], 100 - drop_percentile)sns.histplot(notes, x="step", bins=np.linspace(0, max_step, 21))plt.subplot(1, 3, 3)max_duration = np.percentile(notes['duration'], 100 - drop_percentile)sns.histplot(notes, x="duration", bins=np.linspace(0, max_duration, 21))# 查看音符的分布
plot_distributions(raw_notes)
能看到如下的音符分布:
2.5 创建训练数据集
通过从MIDI文件中提取音符来创建训练数据集,音符用三个变量来表示:pitch(音高)、step(音符名)和 duration(持续时间)。
对于成批的音符序列训练模型;每个样本将包含一系列音符作为输入特征,下一个音符作为标签。通过这种方式,模型将被训练来预测序列中的下一个音符。
以下代码是创建训练数据集的:
key_order = ['pitch', 'step', 'duration']
train_notes = np.stack([all_notes[key] for key in key_order], axis=1)
notes_ds = tf.data.Dataset.from_tensor_slices(train_notes)# 每个示例将由一系列音符组成作为输入特征,并将下一个音符作为标签。
# 通过这种方式,模型将被训练以预测序列中的下一个音符。
def create_sequences(dataset: tf.data.Dataset, seq_length: int,vocab_size = 128,
) -> tf.data.Dataset:seq_length = seq_length+1windows = dataset.window(seq_length, shift=1, stride=1,drop_remainder=True)flatten = lambda x: x.batch(seq_length, drop_remainder=True)sequences = windows.flat_map(flatten)def scale_pitch(x):x = x/[vocab_size,1.0,1.0]return xdef split_labels(sequences):inputs = sequences[:-1]labels_dense = sequences[-1]labels = {key:labels_dense[i] for i,key in enumerate(key_order)}return scale_pitch(inputs), labelsreturn sequences.map(split_labels, num_parallel_calls=tf.data.AUTOTUNE)设置每个示例的序列长度。尝试使用不同的长度(例如,50、100、150),以确定哪种长度最适合数据,或使用超参数调整。词汇表的大小(Vocab_Size)设置为128,表示Pretty_MIDI支持的所有音调。
seq_length = 25
vocab_size = 128
seq_ds = create_sequences(notes_ds, seq_length, vocab_size)
seq_ds.element_specbatch_size = 64
buffer_size = n_notes - seq_length
train_ds = (seq_ds.shuffle(buffer_size).batch(batch_size, drop_remainder=True).cache().prefetch(tf.data.experimental.AUTOTUNE))三、构建模型
模型输入是序列的音符,输出是一个音符;即:通过输入一段连续的音符,预测下一个音符。
输入:输入的维度是nx3,n是指音符的个数长度,3是指音符使用pitch(音高)、step(音符名)和 duration(持续时间)三个变量来表示;
输出:预测一个音符,设置模型输出的维度是3,表示音符的3个变量。
模型主体:LSTM结构。
损失函数:对于pitch和duration,使用基于均方误差的自定义损失函数。
def mse_with_positive_pressure(y_true: tf.Tensor, y_pred: tf.Tensor):mse = (y_true - y_pred) ** 2positive_pressure = 10 * tf.maximum(-y_pred, 0.0)return tf.reduce_mean(mse + positive_pressure)下面是搭建网络的代码:
# 设置输入
input_shape = (seq_length, 3)
learning_rate = 0.005# 模型输入层
inputs = tf.keras.Input(input_shape)# 使用循环神经网络的变体LSTM层
x = tf.keras.layers.LSTM(128)(inputs)# 输出层
outputs = {'pitch': tf.keras.layers.Dense(128, name='pitch')(x),'step': tf.keras.layers.Dense(1, name='step')(x),'duration': tf.keras.layers.Dense(1, name='duration')(x),
}# 构建模型
model = tf.keras.Model(inputs, outputs)# 定义损失函数
loss = {'pitch': tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),'step': mse_with_positive_pressure,'duration': mse_with_positive_pressure,
}# 模型训练的优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)# 编译模型
model.compile(loss=loss,loss_weights={'pitch': 0.05,'step': 1.0,'duration':1.0,},optimizer=optimizer,
)# 设置训练模型时的回调函数
callbacks = [tf.keras.callbacks.ModelCheckpoint(filepath='./training_checkpoints/ckpt_{epoch}',save_weights_only=True),tf.keras.callbacks.EarlyStopping(monitor='loss',patience=5,verbose=1,restore_best_weights=True),
]查看一下网络模型:tf.keras.utils.plot_model(model)
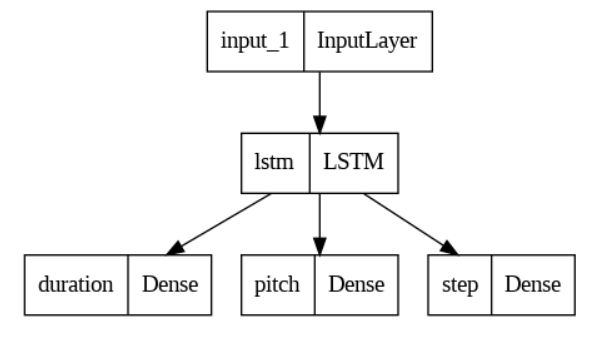
或者用这样方式看看:model.summary()

四、训练模型
这里我们输入准备好的训练集数据,指定训练模型时的回调函数(保存模型权重、自动早停),模型一共训练50轮。
# 模型训练50轮
epochs = 50# 开始训练模型
history = model.fit(train_ds,epochs=epochs,callbacks=callbacks,
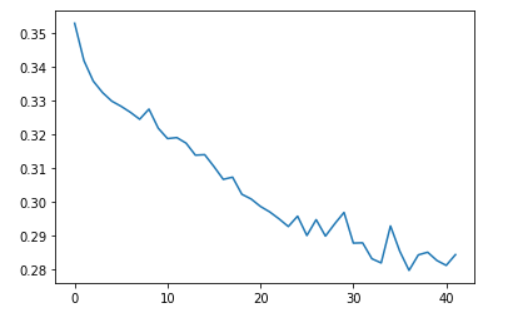
)下图是训练过程的截图,能看到模型训练到42轮时停止了,因为使用EarlyStopping()函数,模型的损失足够小了,就不再训练了。

通常loss越小越好,训练完模型后,画一下损失值的变化过程:
五、使用模型
使用 model.predict( ) 函数,进行预测音符。但要使用模型生成音符,首先需要提供音符的起始序列。
下面的函数,从一系列音符中生成一个音符
def predict_next_note(notes: np.ndarray, keras_model: tf.keras.Model, temperature: float = 1.0) -> int:"""使用经过训练的序列模型生成标签ID"""assert temperature > 0# 添加批次维度inputs = tf.expand_dims(notes, 0)predictions = model.predict(inputs)pitch_logits = predictions['pitch']step = predictions['step']duration = predictions['duration']pitch_logits /= temperaturepitch = tf.random.categorical(pitch_logits, num_samples=1)pitch = tf.squeeze(pitch, axis=-1)duration = tf.squeeze(duration, axis=-1)step = tf.squeeze(step, axis=-1)# `step` 和 `duration` 值应该是非负数step = tf.maximum(0, step)duration = tf.maximum(0, duration)return int(pitch), float(step), float(duration)举一个例子,生成一些音符
temperature = 2.0
num_predictions = 120sample_notes = np.stack([raw_notes[key] for key in key_order], axis=1)# 音符的初始序列; 音高被归一化,类似于训练序列
input_notes = (sample_notes[:seq_length] / np.array([vocab_size, 1, 1]))generated_notes = []
prev_start = 0
for _ in range(num_predictions):pitch, step, duration = predict_next_note(input_notes, model, temperature)start = prev_start + stepend = start + durationinput_note = (pitch, step, duration)generated_notes.append((*input_note, start, end))input_notes = np.delete(input_notes, 0, axis=0)input_notes = np.append(input_notes, np.expand_dims(input_note, 0), axis=0)prev_start = startgenerated_notes = pd.DataFrame(generated_notes, columns=(*key_order, 'start', 'end'))
# 查看成的generated_notes前5个音符
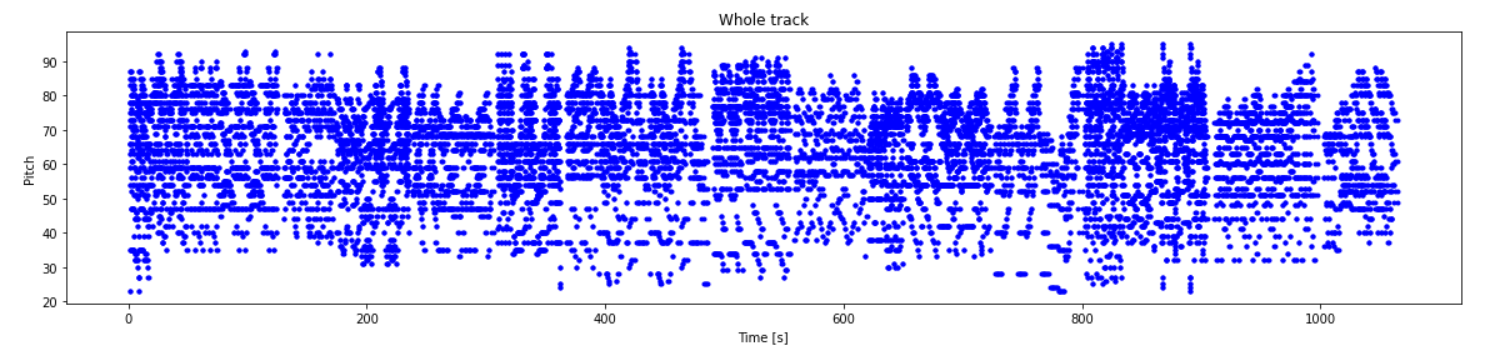
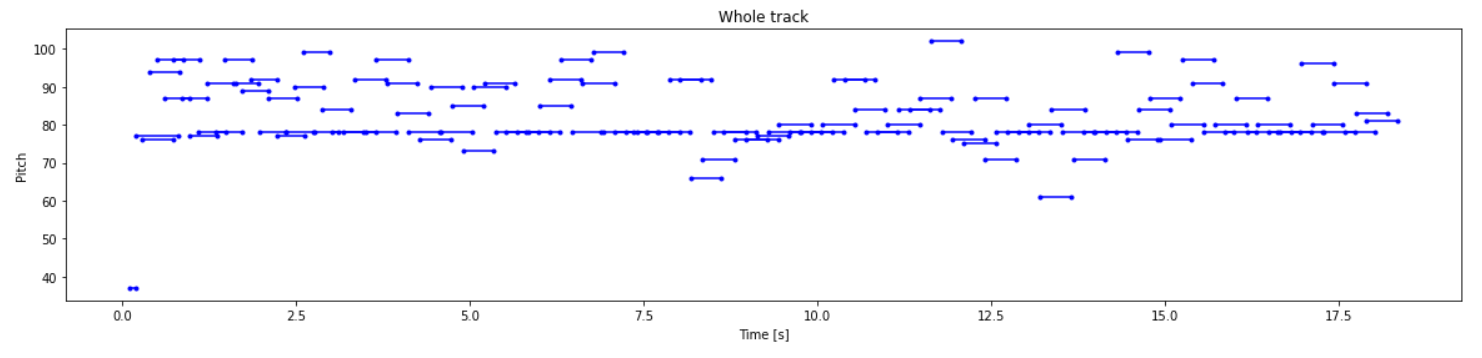
generated_notes.head(5)# 查看成的generated_notes的音轨情况
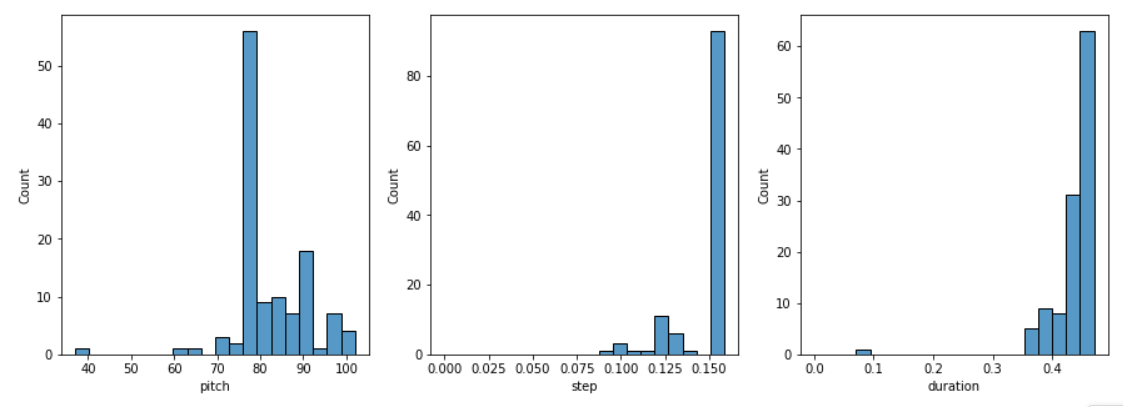
plot_piano_roll(generated_notes)# 查看生成的generated_notes 音符的分布情况
plot_distributions(generated_notes)查看生成的前5个音符,
| pitch | step | duration | start | end | |
|---|---|---|---|---|---|
| 0 | 37 | 0.095633 | 0.092078 | 0.095633 | 0.187710 |
| 1 | 77 | 0.097417 | 0.609462 | 0.193049 | 0.802511 |
| 2 | 76 | 0.089049 | 0.455626 | 0.282099 | 0.737724 |
| 3 | 94 | 0.096575 | 0.443937 | 0.378673 | 0.822611 |
| 4 | 97 | 0.109404 | 0.376604 | 0.488077 | 0.864681 |
查看成的generated_notes的音轨情况
查看生成的generated_notes 音符的分布情况
本文只供大家参考和学习,谢谢~
其它推荐文章:
[1] 【神经网络】综合篇——人工神经网络、卷积神经网络、循环神经网络、生成对抗网络
[2] 手把手搭建一个【卷积神经网络】
[3] “花朵分类“ 手把手搭建【卷积神经网络】
[4] 一篇文章“简单”认识《循环神经网络》
[5] 神经网络学习
相关文章:
“生成音乐“ 【循环神经网络】
前言 本文介绍循环神经网络的进阶案例,通过搭建和训练一个模型,来对钢琴的音符进行预测,通过重复调用模型来进而生成一段音乐; 使用到Maestro的钢琴MIDI文件 ,每个文件由不同音符组成,音符用三个量来表示…...

能否手写vue3响应式原理-面试进阶
(二)响应式原理 利用ES6中Proxy作为拦截器,在get时收集依赖,在set时触发依赖,来实现响应式。 (三)手写实现 1、实现Reactive 基于原理,我们可以先写一下测试用例 //reactive.spe…...
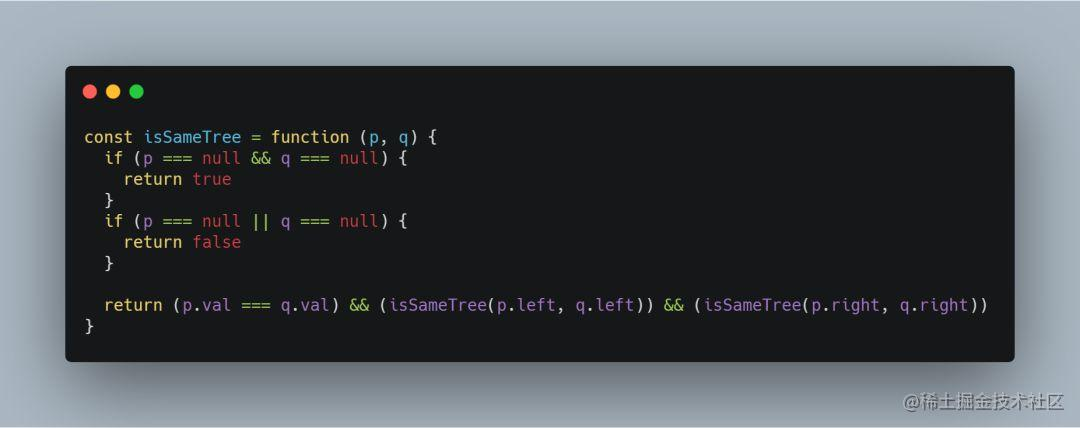
前端工程师leetcode算法面试必备-简单的二叉树
一、前言 本难度的题目主要考察二叉树的基本概念和操作。 1、基本概念 树是计算机科学中经常用到的一种非线性数据结构,以分层的形式存储数据。二叉树是一种特殊的树结构,每个节点最多有两个子树,通常子树被称作“左子树”和“右子树”。 …...

【什么程度叫熟悉linux系统】
一、编译内核 1、Linux系统背景:Ubuntu 2、内核源码kernel.org进行下载 3、解压内核源文件linux-6.1.12.tar.xz、命令:tar -xvf linux-6.1.12.tar.xz 4、进入解压好的文件inux-6.1.12 5、配置内核命令:make menuconfig(需要进…...

编译安装MySQL
MySQL 5.7主要特性 随机root 密码:MySQL 5.7 数据库初始化完成后,会自动生成一个 rootlocalhost 用户,root 用户的密码不为空,而是随机产生一个密码。原生支持:Systemd 更好的性能:对于多核CPU、固态硬盘、…...
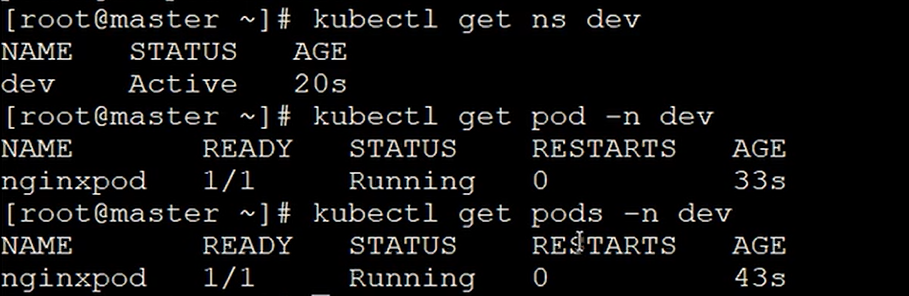
Kubernetes一 Kubernetes之入门
二 Kubernetes介绍 1.1 应用部署方式演变 在部署应用程序的方式上,主要经历了三个时代: 传统部署:互联网早期,会直接将应用程序部署在物理机上 优点:简单,不需要其它技术的参与 缺点:不能为应…...

SQLServer2000 断电后数据库suspect“置疑”处理
SQLServer2000 断电后数据库suspect“置疑”处理 背景介绍: 前些天加班时候,接到小舅子微信,说一个客户的winXP 机器上sql2000的数据库在断电重启后,数据库执行命令时提示suspect“置疑”错误。小舅子电子工程师,对数…...

多模态机器学习入门Tutorial on MultiModal Machine Learning——第一堂课个人学习内容
文章目录课程记录核心技术Core Technical Challengesrepresentation表示alignment对齐转换translationFusion融合co-learning共同学习总结Course Syllabus教学大纲个人总结第一周的安排相关连接课程记录 这部分是自己看视频,然后截屏,记录下来的这部分的…...
Java ~ Collection/Executor ~ LinkedBlockingDeque【总结】
一 概述 简介 LinkedBlockingDeque(链接阻塞双端队列)类(下文简称链接阻塞双端队列)是BlockingDeqeue(阻塞双端队列)接口的唯一实现类,采用链表的方式实现。链接阻塞双端队列与LinkedBlockingQu…...
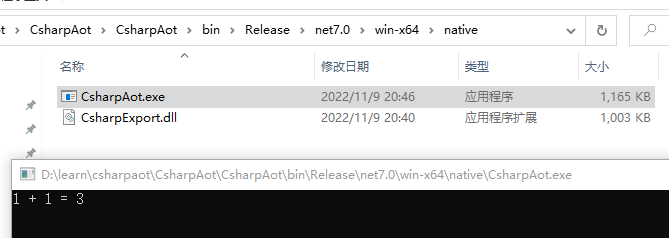
.NET7的AOT的使用
背景其实,规划这篇文章有一段时间了,但是比较懒,所以一直拖着没写。最近时总更新太快了,太卷了,所以借着 .NET 7 正式版发布,熬夜写完这篇文章,希望能够追上时总的一点距离。本文主要介绍如何在…...
分布式缓存的问题
1,Redis缓存穿透问题 Redis缓存穿透问题是指查询一个一定不存在的数据,由于这样的数据缓存一定不命中,所以这样的请求一定会打到数据库上。但是由于数据库里面也没有这样数据,且也没有将这样的null值缓存到数据库,从而造成这样的…...
golang入门笔记——内存管理和编译器优化
静态分析 静态分析:不执行程序代码,推导程序的行为,分析程序的性质 控制流(control flow):程序的执行流程 数据流(data flow):数据在控制流上的传递 通过分析控制流和…...

GEE学习笔记 七十:【GEE之Python版教程四】Python基础编程二
通过上一章的讲解,我们对于python有了初步的了解,这一章就详细讲解一下python的各个变量以及运算规则等内容。 关于测试代码推荐初学者将每一段代码都自己敲入编辑器中在本地运行。 1、数值 这是任何编程中都会有的基本变量,在python支持的…...

股票投资新出发之知识体系构建导论
文章目录前言参考资料如何构建体系实践理论tips前言 自2021年股票开户,投资已有2年左右,但更多的是凭感觉式的拍脑袋投资,没有自己的投资体系,所以开此专栏从零开始构建知识体系,勉励自己不断学习。两年的投资经验让我…...

蓝桥杯算法训练合集 十六 1.首字母变大写2.盾神计科导作业3.Cinema4.接水问题
目录 1.首字母变大写 2.盾神计科导作业 3.Cinema 4.接水问题 1.首字母变大写 问题描述 对一个字符串中的所有单词,如果单词的首字母不是大写字母,则把单词的首字母变成大写字母。在字符串中,单词之间通过空白符分隔,空白符包括…...

密码的世界
网络世界中常见的攻击方法 窃听攻击 窃听攻击是网络世界最常见的一种攻击方式,一些不能泄露的隐私信息,例如银行卡密码,账号密码,如果被窃听泄露的话通常会带来比较严重的后果。 中间人攻击 在中间人攻击中,小明准…...

如何用一句话感动测试工程师?产品和技术都这么说!
测试工程师在公司里的地位一言难尽,产品挥斥苍穹,指引产品前路;开发编写代码实现功能,给产品带来瞩目成就。两者,一个是领航员,一个是开拓者,都是聚光灯照耀的对象,唯独团队中的保障…...


MySQL中使用索引优化
目录 一.使用索引优化 数据准备 避免索引失效应用-全值匹配 避免索引失效应用-最左前缀法则 避免索引失效应用-其他匹配原则 1、 2、 3、 4、 5、 一.使用索引优化 索引是数据库优化最常用也是最重要的手段之一,通过索引通常可以帮助用户解决大多数的MySQL的性能优化…...
Linux C/C++ 多线程TCP/UDP服务器 (监控系统状态)
Linux环境中实现并发TCP/IP服务器。多线程在解决方案中提供了并发性。由于并发性,它允许多个客户端同时连接到服务器并与服务器交互。 Linux多线程编程概述 许多应用程序同时处理多项杂务。服务器应用程序处理并发客户端;交互式应用程序通常在处理后台…...

VSCode配置C++开发环境:OpenCV跨平台实战指南
1. 为什么选择VSCode进行C开发? 很多刚接触C开发的同学都会纠结该用什么开发工具。我在刚入门时也试过各种IDE,从Visual Studio到CLion,最后发现VSCode才是最适合跨平台开发的轻量级选择。VSCode不仅免费开源,而且通过插件系统可以…...
)
BMJ Open与Perplexity深度耦合实验(仅限2024Q3授权机构访问的私有检索协议曝光)
更多请点击: https://intelliparadigm.com 第一章:BMJ Open与Perplexity深度耦合实验的背景与授权边界界定 BMJ Open 作为开放获取、同行评审的综合性医学研究期刊,其元数据 API(v2)支持结构化查询与批量文献摘要拉取…...

开源工具picprose:AI驱动的图片处理与文案生成一体化解决方案
1. 项目概述与核心价值最近在折腾个人博客和内容创作时,我遇到了一个挺普遍但又很烦人的问题:手头有一堆图片,但要么尺寸不合适,要么色调不统一,要么就是缺少一个能吸引眼球的标题。手动处理吧,费时费力&am…...

构建多平台博客数据分析工具:从数据聚合到可视化实践
1. 项目概述:一个为博主量身定制的流量与内容分析工具最近在折腾个人博客和内容创作的朋友,大概都绕不开一个核心问题:我写的东西,到底有多少人看?读者从哪里来?他们对什么内容更感兴趣?如果你在…...
MatrixFlow:Transformer加速的协同设计与矩阵计算优化
1. MatrixFlow:Transformer加速的革命性协同设计在人工智能计算领域,Transformer模型已经成为自然语言处理、计算机视觉等任务的事实标准架构。然而,这些模型的巨大成功背后隐藏着一个关键瓶颈——矩阵乘法操作(GEMM)占据了整体计算时间的99%…...
:Redis分布式限流实战,防止单用户高频调用拖垮服务)
Pytorch图像去噪实战(八十二):Redis分布式限流实战,防止单用户高频调用拖垮服务
Pytorch图像去噪实战(八十二):Redis分布式限流实战,防止单用户高频调用拖垮服务 一、问题场景:一个用户疯狂调用接口,把所有人都拖慢了 前面我们做了用户配额系统,限制每日调用量。 但每日额度不能解决所有问题。 比如某个用户一天有 1000 次额度,但他在 1 分钟内全…...

【Vivado】从零到一:深入解析Clock IP核的配置与实战应用
1. 初识Vivado Clock IP核:你的数字电路"心跳发生器" 想象一下,数字电路就像一个人体,而时钟信号就是维持生命的心跳。在FPGA设计中,Clock IP核就是专门负责生成这种"心跳"的智能模块。我第一次接触Vivado的C…...

NsEmuTools终极指南:如何15分钟搞定NS模拟器完整配置
NsEmuTools终极指南:如何15分钟搞定NS模拟器完整配置 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 还在为Switch模拟器的复杂配置而头疼吗?NsEmuTools作为一款专…...

如何使用Knife4j为mall-swarm微服务生成漂亮的可视化API文档
如何使用Knife4j为mall-swarm微服务生成漂亮的可视化API文档 【免费下载链接】mall-swarm mall-swarm是一套微服务商城系统,采用了 Spring Cloud Alibaba、Spring Boot 3.2、Sa-Token、MyBatis、Elasticsearch、Docker、Kubernetes等核心技术,同时提供了…...

The Gentlemen勒索软件深度技术分析:1570+受害者背后的黑色工业化帝国
引言 2026年5月,Check Point Research(CPR)发布了一份震惊全球网络安全界的研究报告:安全团队在一次企业事件响应中,意外渗透了The Gentlemen勒索软件组织的核心C2服务器,导出了完整的内部运营数据库。数据…...