Spark SQL 介绍
文章目录
- Spark SQL
- 1、Hive on SparkSQL
- 2、SparkSQL 优点
- 3、SparkSQL 特点
- 1) 容易整合
- 2) 统一的数据访问
- 3) 兼容 Hive
- 4) 标准的数据连接
- 4、DataFrame 是什么
- 5、DataSet 是什么
Spark SQL
Spark SQL 是 Spark 用于结构化数据(structured data) 处理的Spark模块。
1、Hive on SparkSQL
SparkSQL 的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具。
Hive 是早期唯一运行在Hadoop 上的SQL-on-Hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop 工具开始产生,其实表现较为突出的是:
-
Drill
-
Impala
-
Shark
其中 Shark 是伯克利实验室 Spark 生态环境的组件之一,是基于Hive 所开发的工具,它修改了内存管理,物理计划,执行三个模块,并使之能运行在Spark引擎上。Shark 的出现,使得SQL-on-Hadoop 的性能比 Hive 有了10-100倍的提高。
但是,随着Spark 的发展,对于野心勃勃的 Spark 团队来说,Shark 对于 Hive 的太多依赖(如采用Hive的语法解析器,查询优化器等等),制约了 Spark 的 One Stack Rule Them All 的既定方针,制约了 Spark 各个组件的相互集成,所以提出了SparkSQL 项目。SparkSQL 抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Colummnar Storage)、Hive 兼容性等,重新开发了SparkSQL代码,由于摆脱了对Hive的依赖性,SparkSQL 无论在数据兼容,性能优化,组件扩展方面都得到了极大的方便。 -
数据兼容方面:SparkSQL 不但兼容 Hive,还可以从RDD,parquet 文件,JSON 文件中怕哪个获取数据,未来版本甚至支持获取RDBMS 数据 、以及cassandra 等 NoSQL 数据。
-
性能优化方面:除了采取In-Menory Columnar Storage,byte-code generation 等优化技术外,将会引进Cost Model 对查询进行动态评估,获取最佳物理计划等等。
-
组件扩展方面:无论是SQL的语法解析器,分析器还是优化器都可以重新定义,进行扩展。
2、SparkSQL 优点
SparkSQL 作为Spark生态圈的一员继续发展,而不再受限于Hive,只是兼容Hive,而Hive on Spark 是一个Hive 的发展计划,该计划将Spark 作为 Hive 的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce,Tez,Spark 等引擎。
对于开发人员来讲,SparkSQL 可以简化 RDD 的开发,提高开发效率,且执行效率非常快,所以实际工作中,基本上采用的就是SparkSQL,Spark SQL 为了简化RDD的开发,提高开发效率,提供了2个编程抽象,类似SparkCore中的RDD。
DataFrame 和 DataSet
3、SparkSQL 特点
1) 容易整合
无缝的整合了 SQL 查询和 Spark 编程。
2) 统一的数据访问
使用相同的方式连接不同的数据源。比如:MYSQL啊,Hbase,Hive之类的。
3) 兼容 Hive
在已有的仓库上直接运行 SQL 或者 HiveSQL
4) 标准的数据连接
通过 JDBC 或者 ODBC。
4、DataFrame 是什么
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式是数据集,类似于传统数据库中的二维表格。DataFrame 与 RDD 的主要区别在于,前者带有 schema 元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型。这使得 Spark SQL 得以洞察更多的结构信息,从而对藏于 DataFrame 背后的数据源以及作用于 DataFrame 之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观 RDD,由于无从得知所存数据元素的具体内部结构,Spark Core 只能在 stage 层面进行简单,通用的流水线优化。
同时,与 Hive 类似,DataFrame 也支持嵌套数据类型(struct,array,和 map )从API易容性的角度上看,DataFrame API 提供的是一套高层的关系操作,比函数式的RDD API 要更加友好,门槛更低。
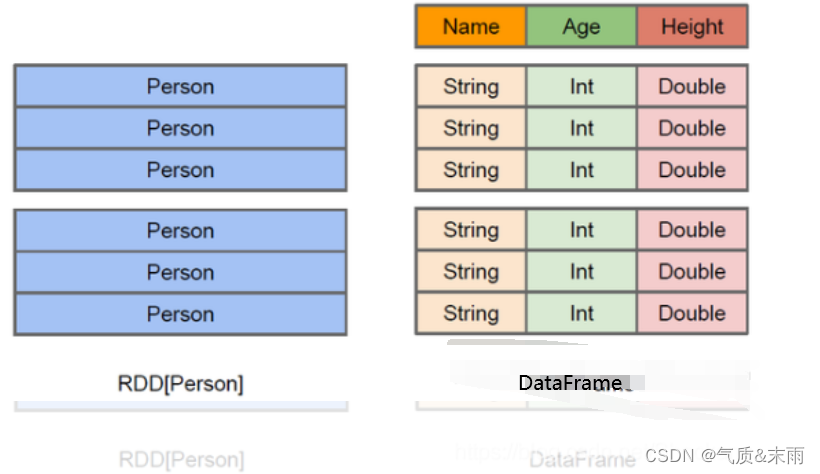
上面这张图直观地体现了 DataFrame 和 RDD的区别。
左侧的 RDD[Person] 虽然以 Person 为参数类型,但 Spark 框架本身不了解 Person 类的内部结构。而右侧的DataFrame 却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
DataFrame 是为数据提供了Schema(元数据)的视图。可以把它当做数据库中的一张表来对待,DataFrame 也是懒执行的,但性能上比RDD 要高,主要原因:优化的执行计划,即查询计划通过 Spark catalyst optimiser 进行优化。
5、DataSet 是什么
DataSet 分布式数据集合。DateSet 是Spark1.6 中添加的一个新抽象,是DataFrame 的一个扩展。它提供了 RDD 的优势(强类型,使用强大的lamba函数的能力)以及 Spark SQL 优化执行引擎的特点。DataSet 也可以使用功能性的转换(操作map,flatMap,fliter 等等)。
- DataSet 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象
- 用户友好的API风格,既具有类型安全检查也具有 DataFrame 的查询优化特性
- 用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到 DataSet 中的字段名称
- DataSet 是强类型的。比如可以有DataSet[Car],DataSet[Person]。
- DataFrame 是 DataSet 的特例,DataFrame=DataSet[Row] ,所以可以通过 as 方法将DataFrame 转换为 DataSet。Row 是一个类型,跟 Car,Person 这些的类型都一样,所有的表结构信息都用Row来表示。获取数据时需要制定顺序。
相关文章:
Spark SQL 介绍
文章目录Spark SQL1、Hive on SparkSQL2、SparkSQL 优点3、SparkSQL 特点1) 容易整合2) 统一的数据访问3) 兼容 Hive4) 标准的数据连接4、DataFrame 是什么5、DataSet 是什么Spark SQL Spark SQL 是 Spark 用于结构化数据(structured data) 处理的Spark模块。 1、Hive on Spa…...

升级到 CDP 后Hive on Tez 性能调整和故障排除指南
优化Hive on Tez查询永远不能以一种万能的方法来完成。查询的性能取决于数据的大小、文件类型、查询设计和查询模式。在性能测试期间,要评估和验证配置参数和任何 SQL 修改。建议在工作负载的性能测试期间一次进行一项更改,并且最好在生产环境中使用它们…...

理解HDFS工作流程与机制,看这篇文章就够了
HDFS(The Hadoop Distributed File System) 是最初由Yahoo提出的分布式文件系统,它主要用来: 1)存储大数据 2)为应用提供大数据高速读取的能力 重点是掌握HDFS的文件读写流程,体会这种机制对整个分布式系统性能提升…...

Intel处理器分页机制
分页模式 Intel 64位处理器支持3种分页模式: 32-bit分页PAE分页IA-32e分页 32-bit分页 32-bit分页模式支持两种页面大小:4KB以及4MB。 4KB页面的线性地址转换 4MB页面的线性地址转换 PAE分页模式 PAE分页模式支持两种页面大小:4KB以及…...
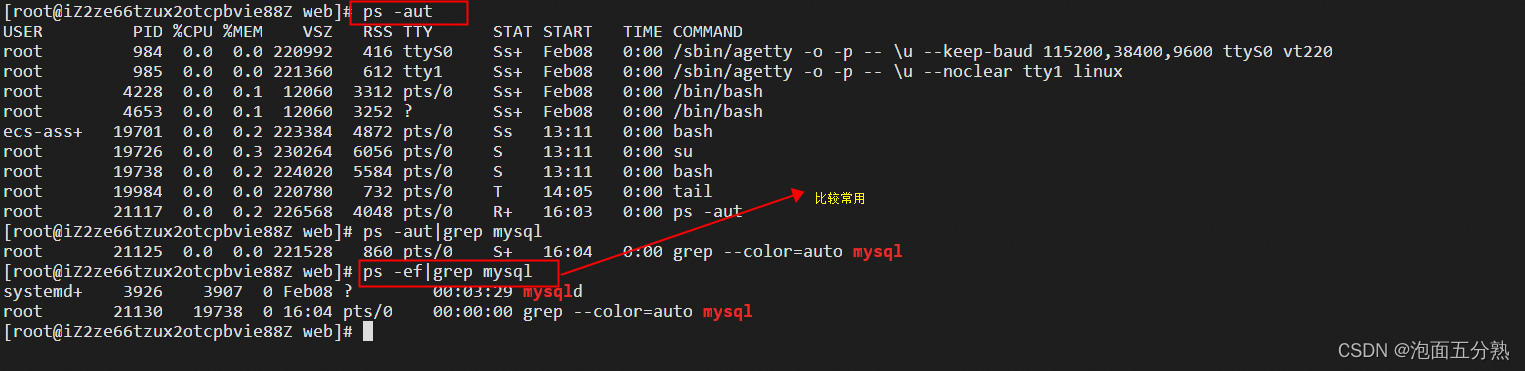
Linux常用命令
linux常用命令创建一个目录mkdir 命令可以创建新目录。mkdir 是 make directory 的缩写。[rootiZ2ze66tzux2otcpbvie88Z ~]# ls [rootiZ2ze66tzux2otcpbvie88Z ~]# mkdir web [rootiZ2ze66tzux2otcpbvie88Z ~]# ls web [rootiZ2ze66tzux2otcpbvie88Z ~]# 创建一个文件2.1 在 Li…...

基于STM32设计的音乐播放器
一、项目背景与设计思路 1.1 项目背景 时代进步,科学技术的不断创新,促进电子产品的不断更迭换代,各种新功能和新技术的电子产品牵引着消费者的眼球。人们生活水平的逐渐提高,对娱乐消费市场需求日益扩大,而其消费电子产品在市场中的占有份额越来越举足轻重。目前消费电…...

微服务开发
目录 微服务配置管理 权限认证 批处理 定时任务 异步 微服务调用 (协议)...
【(C语言)数据结构奋斗100天】二叉树(上)
【(C语言)数据结构奋斗100天】二叉树(上) 🏠个人主页:泡泡牛奶 🌵系列专栏:数据结构奋斗100天 本期所介绍的是二叉树,那么什么是二叉树呢?在知道答案之前,请大家思考一下…...
Java 验证二叉搜索树
验证二叉搜索树中等给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。有效 二叉搜索树定义如下:节点的左子树只包含 小于 当前节点的数。节点的右子树只包含 大于 当前节点的数。所有左子树和右子树自身必须也是二叉搜索树。示例 1&…...

C/C++单项选择题标准化考试系统[2023-02-09]
C/C单项选择题标准化考试系统[2023-02-09] ©3.17 单项选择题标准化考试系统 【难度系数】5级 【任务描述】 设计一个单项选择题的考试系统,可实现试题维护、自动组卷等功能。 【功能描述】 (1)管理员功能: 试题管理:每个试题包括题干、四个备选答案标准答案…...
爱了爱了,这些顶级的 Python 工具包太棒了
Python 语言向来以丰富的第三方库而闻名,今天来介绍几个非常nice的库,有趣好玩且强大!推荐好好学习。 文章目录技术交流数据采集AKShareTuShareGoPUPGeneralNewsExtractor爬虫playwright-pythonawesome-python-login-modelDecryptLoginScylla…...
【Explain详解与索引优化最佳实践】
摘要 explain命令是查看MySQL查询优化器如何执行查询的主要方法,可以很好的分析SQL语句的执行情况。每当遇到执行慢(在业务角度)的SQL,都可以使用explain检查SQL的执行情况,并根据explain的结果相应的去调优SQL等。 …...
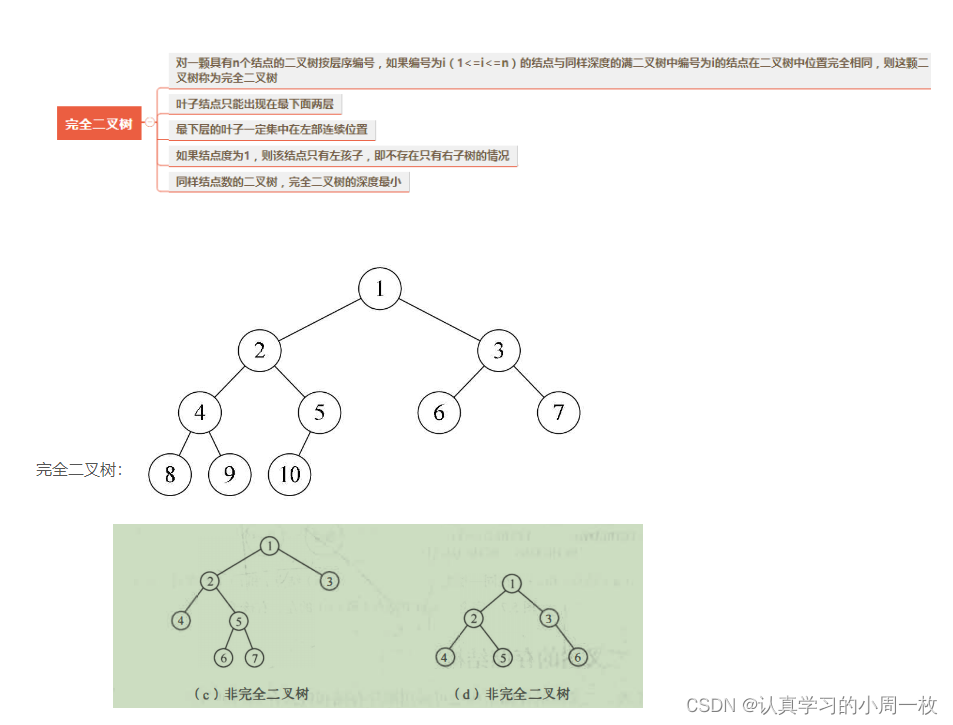
【树和二叉树】数据结构二叉树和树的概念认识
前言:在之前,我们已经把栈和队列的相关概念以及实现的方法进行了学习,今天我们将认识一个新的知识“树”!!! 目录1.树概念及结构1.1树的概念1.2树的结构1.3树的相关概念1.4 树的表示1.5 树在实际中的运用&a…...

通达信收费接口查询可申购新股c++源码分享
有很多股民在做股票交易时为了实现盈利会借助第三三方炒股工具帮助自己,那么通达信收费接口就是人们常用到的,今天小编来分享一下通达信收费接口查询可申购新股c源码: std::cout << " 查询可申购新股: category 12 \n"; c…...
。)
【C#设计模式】创建型设计模式 (单例,工厂)。
c# 创建型设计模式 1.单例设计模式c# 单例JS 单例(ES6)c# 扩展方法c# 如果窗体非单例(tips:窗口可以容器化)2.工厂设计模式JS 简单工厂(ES6)C# 简单工厂C# params关键词(自定义参数个数)JS 手写JQuery(委托,工厂方式隐藏细节)JS ...四种用法C# 偷懒工厂1.单例设计模式 …...
Ubuntu 22.04 LTS 入门安装配置优化、开发软件安装一条龙
Ubuntu 22.04 LTS 入门安装配置&优化、开发软件安装 例行前言 最近在抉择手上空余的笔记本(X220 i7-2620M,Sk Hynix ddr3 8G*2 ,Samsung MINISATA 256G)拿来运行什么系统比较好,早年间我或许还会去继续使用Win…...
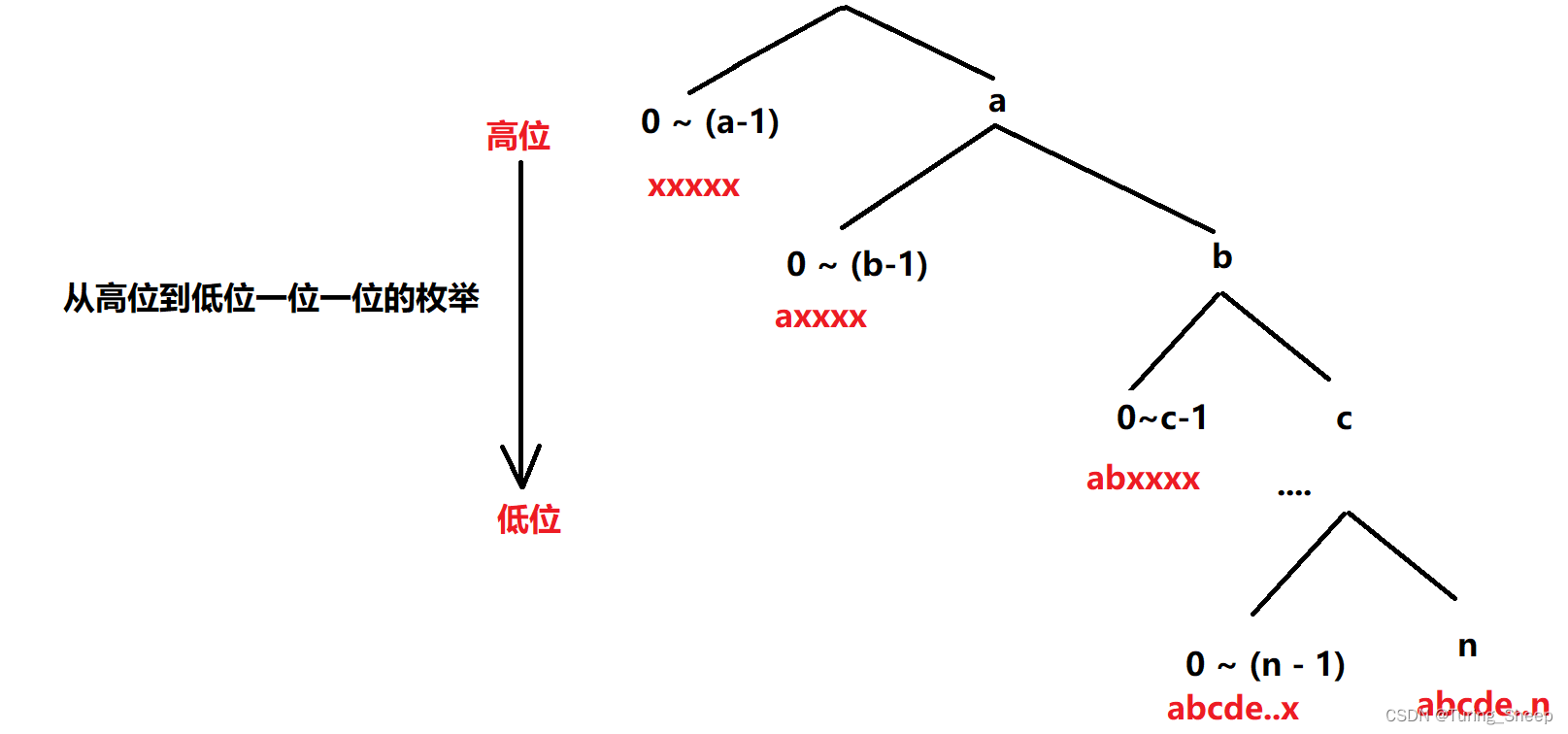
第五十章 动态规划——数位DP模型
第五十章 动态规划——数位DP模型一、什么是数位DP数位DP的识别数位DP的思路二、例题1、AcWing 1083. Windy数(数位DP)2、AcWing 1082. 数字游戏(数位DP)3、AcWing 1081. 度的数量(数位DP)一、什么是数位DP…...
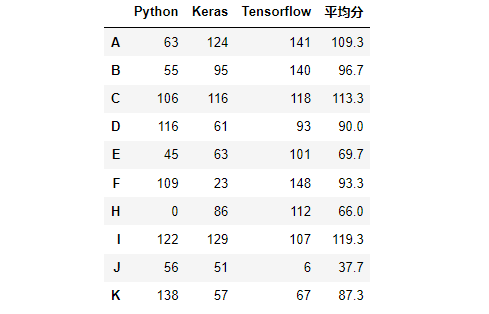
02- pandas 数据库 (机器学习)
pandas 数据库重点: pandas 的主要数据结构: Series (一维数据)与 DataFrame (二维数据)。 pd.DataFrame(data np.random.randint(0,151,size (5,3)), # 生成pandas数据 index [Danial,Brandon,softpo,Ella,Cindy], # 行索引 …...

学Qt想系统的学习,看哪本书?
Qt 是一个跨平台应用开发框架(framework),它是用 C语言写的一套类库。使用 Qt 能为 桌面计算机、服务器、移动设备甚至单片机开发各种应用(application),特别是图形用户界面 (graphical user in…...
)
2023年网络安全比赛--跨站脚本攻击②中职组(超详细)
一、竞赛时间 180分钟 共计3小时 二、竞赛阶段 1.访问服务器网站目录1,根据页面信息完成条件,将获取到弹框信息作为flag提交; 2.访问服务器网站目录2,根据页面信息完成条件,将获取到弹框信息作为flag提交; 3.访问服务器网站目录3,根据页面信息完成条件,将获取到弹框信息…...

3分钟掌握Krita AI抠图:点一下就能完成的智能选区革命
3分钟掌握Krita AI抠图:点一下就能完成的智能选区革命 【免费下载链接】krita-vision-tools Krita plugin which adds selection tools to mask objects with a single click, or by drawing a bounding box. 项目地址: https://gitcode.com/gh_mirrors/kr/krita-…...

基于GAN的端到端ISP:用AI学习从RAW到RGB的图像处理革命
1. 项目概述:从“拍”到“算”的ISP革命在计算机视觉和图像处理领域,图像信号处理器(ISP)一直扮演着“幕后英雄”的角色。它负责将相机传感器捕捉到的原始、未经处理的RAW Bayer数据,转换为我们手机相册里那些色彩鲜艳…...

终极指南:如何使用Cherry MX键帽3D模型库打造你的专属机械键盘
终极指南:如何使用Cherry MX键帽3D模型库打造你的专属机械键盘 【免费下载链接】cherry-mx-keycaps 3D models of Chery MX keycaps 项目地址: https://gitcode.com/gh_mirrors/ch/cherry-mx-keycaps 想要打造一把真正属于自己的机械键盘吗?厌倦了…...

AI模型评估实战:从原理到实践,用Evaliphy简化评测全流程
1. 项目概述:当AI测试遇上“简化”难题最近和几个做AI应用开发的朋友聊天,大家不约而同地提到了同一个痛点:模型效果评估太折腾了。这让我想起自己去年折腾一个文本分类项目时的经历——为了评估模型在几个不同测试集上的表现,我写…...

别再用眼睛猜阈值了!Halcon threshold函数实战:5分钟搞定车牌字符分割
工业视觉实战:Halcon阈值分割在车牌识别中的精准应用 在机器视觉领域,车牌识别系统是典型的工业应用场景之一。而字符分割作为识别流程中的关键环节,直接影响最终识别准确率。许多初学者往往陷入一个误区——仅凭肉眼观察随意设置阈值参数&am…...

PortProxyGUI:Windows端口转发图形化管理终极指南
PortProxyGUI:Windows端口转发图形化管理终极指南 【免费下载链接】PortProxyGUI A manager of netsh interface portproxy which is to evaluate TCP/IP port redirect on windows. 项目地址: https://gitcode.com/gh_mirrors/po/PortProxyGUI 在Windows网络…...

为OpenClaw配置Taotoken实现高效AI智能体工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw配置Taotoken实现高效AI智能体工作流 OpenClaw 是一个流行的开源AI智能体框架,它允许开发者快速构建和编排复…...

Backlink Pilot:开源SEO自动化工具,提升外链建设效率
1. 项目概述:一个被低估的SEO自动化利器如果你在独立站、内容营销或者SEO领域摸爬滚打过一段时间,肯定对“外链建设”这四个字又爱又恨。爱的是,它确实是搜索引擎排名算法中一个极其重要的权重因子;恨的是,这个过程枯燥…...

CANdela Studio配置避坑指南:从10服务到Data Type,这些细节别踩雷
CANdela Studio配置避坑指南:从10服务到Data Type,这些细节别踩雷 在汽车电子诊断功能开发中,CANdela Studio作为诊断数据库(CDD)的核心编辑工具,其配置精度直接影响着诊断协议栈的生成质量。许多工程师能够完成基础配置ÿ…...

ML:SARSA 的基本原理与实现
在强化学习中,智能体(Agent)并不是一次性从已有标签中学习答案,而是在环境(Environment)中不断尝试动作、观察结果、获得奖励,并根据经验逐步调整行为策略。在 Q 学习中,智能体可以通…...