SpringBoot3集成ElasticSearch
标签:ElasticSearch8.Kibana8;
一、简介
Elasticsearch是一个分布式、RESTful风格的搜索和数据分析引擎,适用于各种数据类型,数字、文本、地理位置、结构化数据、非结构化数据;
在实际的工作中,历经过Elasticsearch从6.0到7.0的版本升级,而这次SpringBoot3和ES8.0的集成,虽然脚本的语法变化很小,但是Java客户端的API语法变化很大;
二、环境搭建
1、下载安装包
需要注意的是,这些安装包的版本要选择对应的,不然容易出问题;
软件包:elasticsearch-8.8.2-darwin-x86_64.tar.gz
分词器工具:elasticsearch-analysis-ik-8.8.2.zip
可视化工具:kibana-8.8.2-darwin-x86_64.tar.gz
2、服务启动
不论是ES还是Kibana,在首次启动后,会初始化很多配置文件,可以根据自己的需要做相关的配置调整,比如常见的端口调整,资源占用,安全校验等;

1、启动ES
elasticsearch-8.8.2/bin/elasticsearch本地访问:localhost:92002、启动Kibana
kibana-8.8.2/bin/kibana本地访问:http://localhost:5601# 3、查看安装的插件
http://localhost:9200/_cat/plugins -> analysis-ik 8.8.2
三、工程搭建
1、工程结构
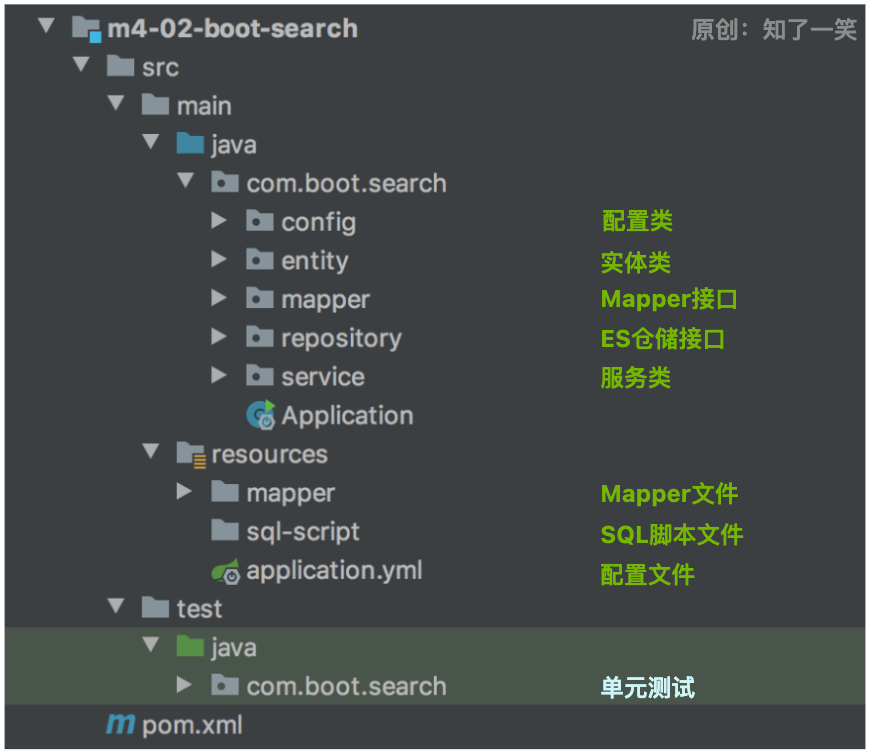
2、依赖管理
在starter-elasticsearch组件中,实际上依赖的是elasticsearch-java组件的8.7.1版本;
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId><version>${spring-boot.version}</version>
</dependency>
3、配置文件
在上面环境搭建的过程中,已经禁用了用户和密码的登录验证,配置ES服务地址即可;
spring:# ElasticSearch配置elasticsearch:uris: localhost:9200
四、基础用法
1、实体类
通过Document和Field注解描述ES索引结构的实体类,注意这里JsonIgnoreProperties注解,解决索引中字段和实体类非一一对应的而引起的JSON解析问题;
@JsonIgnoreProperties(ignoreUnknown = true)
@Document(indexName = "contents_index", createIndex = false)
public class ContentsIndex implements Serializable {private static final long serialVersionUID=1L;@Field(type= FieldType.Integer)private Integer id;@Field(type= FieldType.Keyword)private String title;@Field(type= FieldType.Keyword)private String intro;@Field(type= FieldType.Text)private String content;@Field(type= FieldType.Integer)private Integer createId;@Field(type= FieldType.Keyword)private String createName;@Field(type= FieldType.Date,format = DateFormat.date_hour_minute_second)private Date createTime;
}
2、初始化索引
基于ElasticsearchTemplate类和上述实体类,实现索引结构的初始化,并且将tb_contents表中的数据同步到索引中,最后通过ID查询一条测试数据;
@Service
public class ContentsIndexService {private static final Logger log = LoggerFactory.getLogger(ContentsIndexService.class);@Resourceprivate ContentsService contentsService ;@Resourceprivate ElasticsearchTemplate template ;/*** 初始化索引结构和数据*/public void initIndex (){// 处理索引结构IndexOperations indexOps = template.indexOps(ContentsIndex.class);if (indexOps.exists()){boolean delFlag = indexOps.delete();log.info("contents_index exists,delete:{}",delFlag);indexOps.createMapping(ContentsIndex.class);} else {log.info("contents_index not exists");indexOps.createMapping(ContentsIndex.class);}// 同步数据库表记录List<Contents> contentsList = contentsService.queryAll();if (contentsList.size() > 0){List<ContentsIndex> contentsIndexList = new ArrayList<>() ;contentsList.forEach(contents -> {ContentsIndex contentsIndex = new ContentsIndex() ;BeanUtils.copyProperties(contents,contentsIndex);contentsIndexList.add(contentsIndex);});template.save(contentsIndexList);}// ID查询ContentsIndex contentsIndex = template.get("10",ContentsIndex.class);log.info("contents-index-10:{}",contentsIndex);}
}
3、仓储接口
继承ElasticsearchRepository接口,可以对ES这种特定类型的存储库进行通用增删改查操作;在测试类中对该接口的方法进行测试;
// 1、接口定义
public interface ContentsIndexRepository extends ElasticsearchRepository<ContentsIndex,Long> {
}// 2、接口测试
public class ContentsIndexRepositoryTest {@Autowiredprivate ContentsIndexRepository contentsIndexRepository;@Testpublic void testAdd (){// 单个新增contentsIndexRepository.save(buildOne());// 批量新增contentsIndexRepository.saveAll(buildList()) ;}@Testpublic void testUpdate (){// 根据ID查询后再更新Optional<ContentsIndex> contentsOpt = contentsIndexRepository.findById(14L);if (contentsOpt.isPresent()){ContentsIndex contentsId = contentsOpt.get();System.out.println("id=14:"+contentsId);contentsId.setContent("update-content");contentsId.setCreateTime(new Date());contentsIndexRepository.save(contentsId);}}@Testpublic void testQuery (){// 单个ID查询Optional<ContentsIndex> contentsOpt = contentsIndexRepository.findById(1L);if (contentsOpt.isPresent()){ContentsIndex contentsId1 = contentsOpt.get();System.out.println("id=1:"+contentsId1);}// 批量ID查询Iterator<ContentsIndex> contentsIterator = contentsIndexRepository.findAllById(Arrays.asList(10L,12L)).iterator();while (contentsIterator.hasNext()){ContentsIndex contentsIndex = contentsIterator.next();System.out.println("id="+contentsIndex.getId()+":"+contentsIndex);}}@Testpublic void testDelete (){contentsIndexRepository.deleteById(15L);contentsIndexRepository.deleteById(16L);}
}
4、查询语法
无论是ElasticsearchTemplate类还是ElasticsearchRepository接口,都是对ES常用的简单功能进行封装,在实际使用时,复杂的查询语法还是依赖ElasticsearchClient和原生的API封装;
这里主要演示七个查询方法,主要涉及:ID查询,字段匹配,组合与范围查询,分页与排序,分组统计,最大值查询和模糊匹配;更多的查询API还是要多看文档中的案例才行;
public class ElasticsearchClientTest {@Autowiredprivate ElasticsearchClient client ;@Testpublic void testSearch1 () throws IOException {// ID查询GetResponse<ContentsIndex> resp = client.get(getReq ->getReq.index("contents_index").id("7"), ContentsIndex.class);if (resp.found()){ContentsIndex contentsIndex = resp.source() ;System.out.println("contentsIndex-7:"+contentsIndex);}}@Testpublic void testSearch2 () throws IOException {// 指定字段匹配SearchResponse<ContentsIndex> resp = client.search(searchReq -> searchReq.index("contents_index").query(query -> query.match(field -> field.field("createName").query("张三"))),ContentsIndex.class);printResp(resp);}@Testpublic void testSearch3 () throws IOException {// 组合查询:姓名和时间范围Query byName = MatchQuery.of(field -> field.field("createName").query("王五"))._toQuery();Query byTime = RangeQuery.of(field -> field.field("createTime").gte(JsonData.of("2023-07-10T00:00:00")).lte(JsonData.of("2023-07-12T00:00:00")))._toQuery();SearchResponse<ContentsIndex> resp = client.search(searchReq -> searchReq.index("contents_index").query(query -> query.bool(boolQuery -> boolQuery.must(byName).must(byTime))),ContentsIndex.class);printResp(resp);}@Testpublic void testSearch4 () throws IOException {// 排序和分页,在14条数据中,根据ID倒序排列,从第5条往后取4条数据SearchResponse<ContentsIndex> resp = client.search(searchReq -> searchReq.index("contents_index").from(5).size(4).sort(sort -> sort.field(sortField -> sortField.field("id").order(SortOrder.Desc))),ContentsIndex.class);printResp(resp);}@Testpublic void testSearch5 () throws IOException {// 根据createId分组统计SearchResponse<ContentsIndex> resp = client.search(searchReq -> searchReq.index("contents_index").aggregations("createIdGroup",agg -> agg.terms(term -> term.field("createId"))),ContentsIndex.class);Aggregate aggregate = resp.aggregations().get("createIdGroup");LongTermsAggregate termsAggregate = aggregate.lterms();Buckets<LongTermsBucket> buckets = termsAggregate.buckets();for (LongTermsBucket termsBucket : buckets.array()) {System.out.println(termsBucket.key() + " : " + termsBucket.docCount());}}@Testpublic void testSearch6 () throws IOException {// 查询最大的IDSearchResponse<ContentsIndex> resp = client.search(searchReq -> searchReq.index("contents_index").aggregations("maxId",agg -> agg.max(field -> field.field("id"))),ContentsIndex.class);for (Map.Entry<String, Aggregate> entry : resp.aggregations().entrySet()){System.out.println(entry.getKey()+":"+entry.getValue().max().value());}}@Testpublic void testSearch7 () throws IOException {// 模糊查询title字段,允许1个误差Query byContent = FuzzyQuery.of(field -> field.field("title").value("设计").fuzziness("1"))._toQuery();SearchResponse<ContentsIndex> resp = client.search(searchReq -> searchReq.index("contents_index").query(byContent),ContentsIndex.class);printResp(resp);}private void printResp (SearchResponse<ContentsIndex> resp){TotalHits total = resp.hits().total();System.out.println("total:"+total);List<Hit<ContentsIndex>> hits = resp.hits().hits();for (Hit<ContentsIndex> hit: hits) {ContentsIndex contentsIndex = hit.source();System.out.println(hit.id()+":"+contentsIndex);}}
}
五、参考源码
文档仓库:
https://gitee.com/cicadasmile/butte-java-note源码仓库:
https://gitee.com/cicadasmile/butte-spring-parent
相关文章:
SpringBoot3集成ElasticSearch
标签:ElasticSearch8.Kibana8; 一、简介 Elasticsearch是一个分布式、RESTful风格的搜索和数据分析引擎,适用于各种数据类型,数字、文本、地理位置、结构化数据、非结构化数据; 在实际的工作中,历经过Ela…...

详解23种设计模式优缺点以及解决方案
1. 单例模式(Singleton Pattern): 优点:确保一个类只有一个实例,提供全局访问点,节省资源。缺点:可能引入全局状态,难以扩展和测试。解决方法:使用依赖注入来替代直接访…...

Oracle 数据库中删除表空间的详细步骤与示例
系列文章目录 文章目录 系列文章目录前言一、查看表空间二、数据迁移和备份三、下线表空间中的对象四、删除表空间五、删除完成后的操作总结前言 在 Oracle 数据库中,表空间是存储数据的逻辑容器。有时候,我们可能需要删除不再使用的表空间以释放空间或进行数据库重组。本文…...

<kernel>kernel 6.4 笔记
<kernel>kernel 6.4 笔记 1、kernel 与用户层通信过程 (1) kernel 通过uevent事件 通知 用户层; 第一步:准备同事事件的参数键值对存到环境变量中; 第二步 :准备环境变量数据 ACTION、DEVPATH、SUBSYSTEM…...

介绍一些编程语言— Perl 语言
介绍一些编程语言— Perl 语言 Perl 语言 简介 Perl 是一种动态解释型的脚本语言。 最初的设计者为拉里・沃尔,它于 1987 1987 1987 年 12 12 12 月 18 18 18 日发表。Perl 借取了 C、sed、awk、shell scripting 以及很多其他编程语言的特性。其中最重要的特性…...

原型与继承
原型与继承 在 JavaScript 中,对象有一个特殊的隐藏属性 [[Prototype]](如规范中所命名的),它要么为 null,要么就是对另一个对象的引用。该对象被称为“原型。 当我们从 object 中读取一个缺失的属性时,Jav…...
:PyFlink Tabel API之SQL查询)
Flink流批一体计算(14):PyFlink Tabel API之SQL查询
举个例子 查询 source 表,同时执行计算 # 通过 Table API 创建一张表: source_table table_env.from_path("datagen") # 或者通过 SQL 查询语句创建一张表: source_table table_env.sql_query("SELECT * FROM datagen&quo…...
JRebel插件扩展-mac版
前言 上一篇分享了mac开发环境的搭建,但是欠了博友几个优化的债,今天先还一个,那就是idea里jRebel插件的扩展。 一、场景回眸 这个如果在win环境那扩展是分分钟,一个exe文件点点就行。现在在mac环境就没有这样的dmg可以执行的&…...

C语言中常见的一些语法概念和功能
常用代码: 程序入口:int main() 函数用于定义程序的入口点。 输出:使用 printf() 函数可以在控制台打印输出。 输入:使用 scanf() 函数可以接收用户的输入。 条件判断:使用 if-else 语句可以根据条件执行不同的代码…...

Python土力学与基础工程计算.PDF-钻探泥浆制备
Python 求解代码如下: 1. rho1 2.5 # 黏土密度,单位:t/m 2. rho2 1.0 # 泥浆密度,单位:t/m 3. rho3 1.0 # 水的密度,单位:t/m 4. V 1.0 # 泥浆容积,单位:…...
【机器学习】— 2 图神经网络GNN
一、说明 在本文中,我们探讨了图神经网络(GNN)在推荐系统中的潜力,强调了它们相对于传统矩阵完成方法的优势。GNN为利用图论来改进推荐系统提供了一个强大的框架。在本文中,我们将在推荐系统的背景下概述图论和图神经网…...

QT的布局与间隔器介绍
布局与间隔器 1、概述 QT中使用绝对定位的布局方式,无法适用窗口的变化,但是,也可以通过尺寸策略来进行 调整,使得 可以适用窗口变化。 布局管理器作用最主要用来在qt设计师中进行控件的排列,另外,布局管理…...

深入浅出Pytorch函数——torch.nn.Linear
分类目录:《深入浅出Pytorch函数》总目录 对输入数据做线性变换 y x A T b yxA^Tb yxATb 语法 torch.nn.Linear(in_features, out_features, biasTrue, deviceNone, dtypeNone)参数 in_features:[int] 每个输入样本的大小out_features :…...

Vue3.2+TS的defineExpose的应用
defineExpose通俗来讲,其实就是讲子组件的方法或者数据,暴露给父组件进行使用,这样对组件的封装使用,有很大的帮助,那么defineExpose应该如何使用,下面我来用一些实际的代码,带大家快速学会defi…...

牛客网Python入门103题练习|【08--元组】
⭐NP62 运动会双人项目 描述 牛客运动会上有一项双人项目,因为报名成功以后双人成员不允许被修改,因此请使用元组(tuple)进行记录。先输入两个人的名字,请输出他们报名成功以后的元组。 输入描述: 第一…...
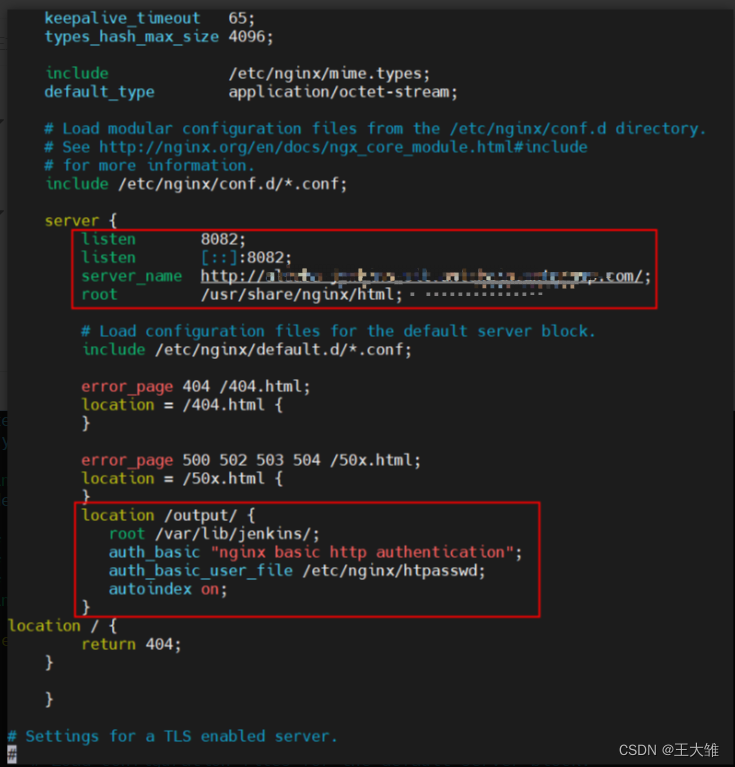
Jenkins改造—nginx配置鉴权
先kill掉8082的端口进程 netstat -natp | grep 8082 kill 10256 1、下载nginx nginx安装 EPEL 仓库中有 Nginx 的安装包。如果你还没有安装过 EPEL,可以通过运行下面的命令来完成安装 sudo yum install epel-release 输入以下命令来安装 Nginx sudo yum inst…...
VisionOS平台概述)
(二)VisionOS平台概述
2.VisionOS平台概述 1. VisionOS平台概述 Unity 对VisionOS的支持将 Unity 编辑器和运行时引擎的全部功能与RealityKit提供的渲染功能结合起来。Unity 的核心功能(包括脚本、物理、动画混合、AI、场景管理等)无需修改即可支持。这允许游戏和应用程序逻…...

菜单中的类似iOS中开关的样式
背景是我们有需求,做类似ios中开关的按钮。github上有一些开源项目,比如 SwitchButton, 但是这个项目中提供了很多选项,并且实际使用中会出现一些奇怪的问题。 我调整了下代码,把无关的功能都给删了,保留核…...

Vue 2 动态组件和异步组件
先阅读 【Vue 2 组件基础】中的初步了解动态组件。 动态组件与keep-alive 我们知道动态组件使用is属性和component标签结合来切换不同组件。 下面给出一个示例: <!DOCTYPE html> <html><head><title>Vue 动态组件</title><scri…...
MongoDB升级经历(4.0.23至5.0.19)
MongoDB从4.0.23至5.0.19升级经历 引子:为了解决MongoDB的两个漏洞决定把MongoDB升级至最新版本,期间也踩了不少坑,在这里分享出来供大家学习与避坑~ 1、MongoDB的两个漏洞 漏洞1:MongoDB Server 安全漏洞(CVE-2021-20330) 漏洞2…...

LearningX:构建结构化开发者知识体系,从基础到架构的实践指南
1. 项目概述:一个面向开发者的系统性学习仓库最近在GitHub上看到一个挺有意思的项目,叫“LearningX”。光看名字,你可能会觉得这又是一个普通的“Awesome-XXX”列表,或者是一堆学习资料的简单堆砌。但当我点进去,花了一…...

【技术解析】基于主成分分析与神经网络的航空安全风险建模:从QAR数据预处理到实时预警仿真
1. 航空安全风险建模的技术背景 每次坐飞机时,你可能都好奇过:机长是如何确保飞行安全的?其实背后有一整套数据驱动的安全体系在支撑。QAR(快速存取记录器)就像飞机的"黑匣子",记录了上百项飞行参…...

如何用nmrpflash拯救你的Netgear路由器:从“变砖“到重生的完整指南
如何用nmrpflash拯救你的Netgear路由器:从"变砖"到重生的完整指南 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器固件升级失败、意外断电或系统崩溃后无法启动…...

从分布式到可分发:大规模软件制品分发架构设计与实践
1. 项目概述:从“分布式”到“可分发”的思维跃迁最近在梳理团队内部的基础设施时,又翻出了distr-sh/distr这个项目。说实话,第一次看到这个仓库名,我下意识地把它归类为又一个“分布式系统”框架。但当我真正点进去,花…...

猫抓插件:5分钟掌握浏览器资源嗅探的终极武器
猫抓插件:5分钟掌握浏览器资源嗅探的终极武器 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容无处不在的今天,你…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...

SVG与CSS变量驱动的自动化品牌视觉生成技术实践
1. 项目概述:一分钟品牌塑造的实践宝库在品牌营销和创意设计领域,一个常见的痛点是如何快速、高效地生成高质量的视觉品牌资产。无论是初创公司需要一个临时的Logo,还是内容创作者想为新的系列视频设计一个统一的片头,传统的品牌设…...
)
告别命令行恐惧:用Docker Compose一键部署EMQX集群(附Web控制台和端口映射配置)
告别命令行恐惧:用Docker Compose一键部署EMQX集群(附Web控制台和端口映射配置) 在物联网和分布式系统开发中,EMQX作为高性能的MQTT消息服务器,已经成为连接海量设备与后端服务的核心枢纽。然而,传统安装方…...

ESP32-S2 Reverse TFT Feather开发板深度解析:从核心硬件到物联网项目实战
1. 项目概述:为什么选择ESP32-S2 Reverse TFT Feather?如果你正在寻找一款能让你快速搭建物联网设备原型,尤其是那些需要一块漂亮屏幕来交互或显示信息的项目,那么ESP32-S2 Reverse TFT Feather绝对是一个值得你花时间研究的开发板…...

Noto Emoji:专业解决跨平台表情符号渲染难题的终极方案
Noto Emoji:专业解决跨平台表情符号渲染难题的终极方案 【免费下载链接】noto-emoji Noto Emoji fonts 项目地址: https://gitcode.com/gh_mirrors/no/noto-emoji 在现代数字通信中,表情符号已成为不可或缺的语言元素,然而跨平台表情符…...