深入浅出Pytorch函数——torch.nn.Linear
分类目录:《深入浅出Pytorch函数》总目录
对输入数据做线性变换 y = x A T + b y=xA^T+b y=xAT+b
语法
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
参数
in_features:[int] 每个输入样本的大小out_features:[int] 每个输出样本的大小bias:[bool] 若设置为False,则该层不会学习偏置项目,默认值为True
变量形状
- 输入变量: ( N , in_features ) (N, \text{in\_features}) (N,in_features)
- 输出变量: ( N , out_features ) (N, \text{out\_features}) (N,out_features)
变量
weight:模块中形状为 ( out_features , in_features ) (\text{out\_features}, \text{in\_features}) (out_features,in_features)的可学习权重项bias:模块中形状为 out_features \text{out\_features} out_features的可学习偏置项
实例
>>> m = nn.Linear(20, 30)
>>> input = torch.randn(128, 20)
>>> output = m(input)
>>> print(output.size())
torch.Size([128, 30])
函数实现
class Linear(Module):r"""Applies a linear transformation to the incoming data: :math:`y = xA^T + b`This module supports :ref:`TensorFloat32<tf32_on_ampere>`.On certain ROCm devices, when using float16 inputs this module will use :ref:`different precision<fp16_on_mi200>` for backward.Args:in_features: size of each input sampleout_features: size of each output samplebias: If set to ``False``, the layer will not learn an additive bias.Default: ``True``Shape:- Input: :math:`(*, H_{in})` where :math:`*` means any number ofdimensions including none and :math:`H_{in} = \text{in\_features}`.- Output: :math:`(*, H_{out})` where all but the last dimensionare the same shape as the input and :math:`H_{out} = \text{out\_features}`.Attributes:weight: the learnable weights of the module of shape:math:`(\text{out\_features}, \text{in\_features})`. The values areinitialized from :math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})`, where:math:`k = \frac{1}{\text{in\_features}}`bias: the learnable bias of the module of shape :math:`(\text{out\_features})`.If :attr:`bias` is ``True``, the values are initialized from:math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})` where:math:`k = \frac{1}{\text{in\_features}}`Examples::>>> m = nn.Linear(20, 30)>>> input = torch.randn(128, 20)>>> output = m(input)>>> print(output.size())torch.Size([128, 30])"""__constants__ = ['in_features', 'out_features']in_features: intout_features: intweight: Tensordef __init__(self, in_features: int, out_features: int, bias: bool = True,device=None, dtype=None) -> None:factory_kwargs = {'device': device, 'dtype': dtype}super().__init__()self.in_features = in_featuresself.out_features = out_featuresself.weight = Parameter(torch.empty((out_features, in_features), **factory_kwargs))if bias:self.bias = Parameter(torch.empty(out_features, **factory_kwargs))else:self.register_parameter('bias', None)self.reset_parameters()def reset_parameters(self) -> None:# Setting a=sqrt(5) in kaiming_uniform is the same as initializing with# uniform(-1/sqrt(in_features), 1/sqrt(in_features)). For details, see# https://github.com/pytorch/pytorch/issues/57109init.kaiming_uniform_(self.weight, a=math.sqrt(5))if self.bias is not None:fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0init.uniform_(self.bias, -bound, bound)def forward(self, input: Tensor) -> Tensor:return F.linear(input, self.weight, self.bias)def extra_repr(self) -> str:return 'in_features={}, out_features={}, bias={}'.format(self.in_features, self.out_features, self.bias is not None)
相关文章:

深入浅出Pytorch函数——torch.nn.Linear
分类目录:《深入浅出Pytorch函数》总目录 对输入数据做线性变换 y x A T b yxA^Tb yxATb 语法 torch.nn.Linear(in_features, out_features, biasTrue, deviceNone, dtypeNone)参数 in_features:[int] 每个输入样本的大小out_features :…...

Vue3.2+TS的defineExpose的应用
defineExpose通俗来讲,其实就是讲子组件的方法或者数据,暴露给父组件进行使用,这样对组件的封装使用,有很大的帮助,那么defineExpose应该如何使用,下面我来用一些实际的代码,带大家快速学会defi…...

牛客网Python入门103题练习|【08--元组】
⭐NP62 运动会双人项目 描述 牛客运动会上有一项双人项目,因为报名成功以后双人成员不允许被修改,因此请使用元组(tuple)进行记录。先输入两个人的名字,请输出他们报名成功以后的元组。 输入描述: 第一…...
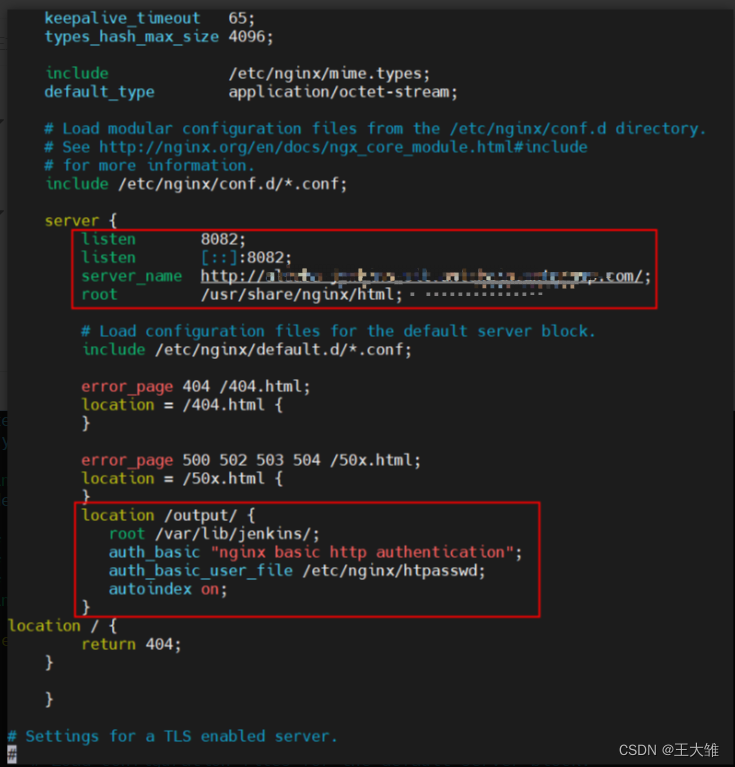
Jenkins改造—nginx配置鉴权
先kill掉8082的端口进程 netstat -natp | grep 8082 kill 10256 1、下载nginx nginx安装 EPEL 仓库中有 Nginx 的安装包。如果你还没有安装过 EPEL,可以通过运行下面的命令来完成安装 sudo yum install epel-release 输入以下命令来安装 Nginx sudo yum inst…...
VisionOS平台概述)
(二)VisionOS平台概述
2.VisionOS平台概述 1. VisionOS平台概述 Unity 对VisionOS的支持将 Unity 编辑器和运行时引擎的全部功能与RealityKit提供的渲染功能结合起来。Unity 的核心功能(包括脚本、物理、动画混合、AI、场景管理等)无需修改即可支持。这允许游戏和应用程序逻…...

菜单中的类似iOS中开关的样式
背景是我们有需求,做类似ios中开关的按钮。github上有一些开源项目,比如 SwitchButton, 但是这个项目中提供了很多选项,并且实际使用中会出现一些奇怪的问题。 我调整了下代码,把无关的功能都给删了,保留核…...

Vue 2 动态组件和异步组件
先阅读 【Vue 2 组件基础】中的初步了解动态组件。 动态组件与keep-alive 我们知道动态组件使用is属性和component标签结合来切换不同组件。 下面给出一个示例: <!DOCTYPE html> <html><head><title>Vue 动态组件</title><scri…...
MongoDB升级经历(4.0.23至5.0.19)
MongoDB从4.0.23至5.0.19升级经历 引子:为了解决MongoDB的两个漏洞决定把MongoDB升级至最新版本,期间也踩了不少坑,在这里分享出来供大家学习与避坑~ 1、MongoDB的两个漏洞 漏洞1:MongoDB Server 安全漏洞(CVE-2021-20330) 漏洞2…...
iPhone上的个人热点丢失了怎么办?如何修复iPhone上不见的个人热点?
个人热点功能可将我们的iPhone手机转变为 Wi-Fi 热点,有了Wi-Fi 热点后就可以与附近的其他设备共享其互联网连接。 一般情况下,个人热点打开就可以使用,但也有部分用户在升级系统或越狱后发现 iPhone 的个人热点消失了。 iPhone上的个人热点…...
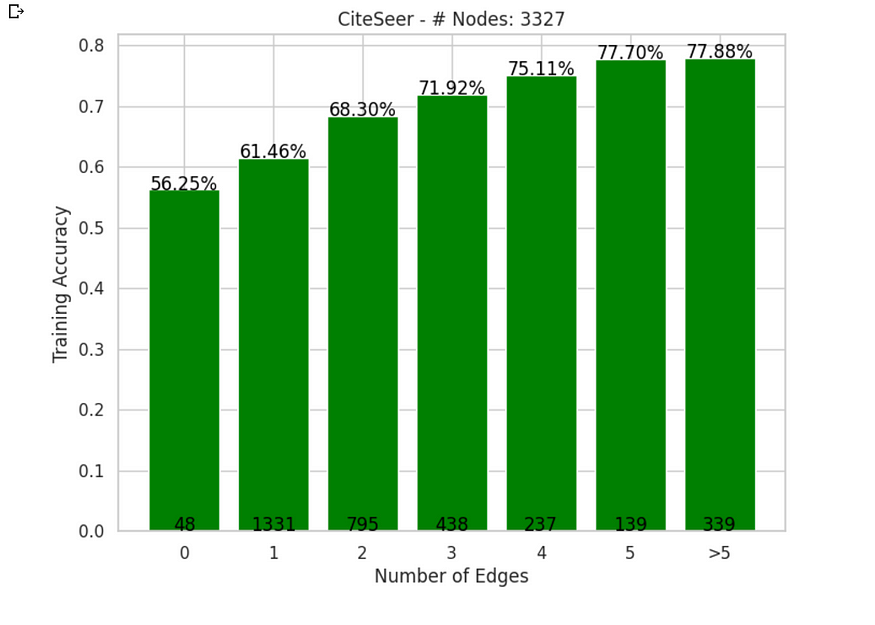
AI 媒人:为什么图形神经网络比 MLP 更好?
一、说明 G拉夫神经网络(GNN)!想象他们是人工智能世界的媒人,通过探索他们的联系,不知疲倦地帮助数据点找到朋友和人气。数字派对上的终极僚机。 现在,为什么这些GNN如此重要,你问?好…...

信息学奥赛一本通 1984:【19CSPJ普及组】纪念品 | 洛谷 P5662 [CSP-J2019] 纪念品
【题目链接】 ybt 1984:【19CSPJ普及组】纪念品 洛谷 P5662 [CSP-J2019] 纪念品 【题目考点】 1. 动态规划:完全背包 【解题思路】 由于小伟每天都可以买卖物品无限次,我们可以假想每天开始时,他把所有的商品都卖出ÿ…...

JVM——JVM参数指南
文章目录 1.概述2.堆内存相关2.1.显式指定堆内存–Xms和-Xmx2.2.显式新生代内存(Young Ceneration)2.3.显示指定永久代/元空间的大小 3.垃圾收集相关3.1.垃圾回收器3.2.GC记录 1.概述 在本篇文章中,你将掌握最常用的 JVM 参数配置。如果对于下面提到了一些概念比如…...

马上七夕到了,用各种编程语言实现10种浪漫表白方式
目录 1. 直接表白:2. 七夕节表白:3. 猜心游戏:4. 浪漫诗句:5. 爱的方程式:6. 爱心Python:7. 心形图案JavaScript 代码:8. 心形并显示表白信息HTML 页面:9. Java七夕快乐:…...
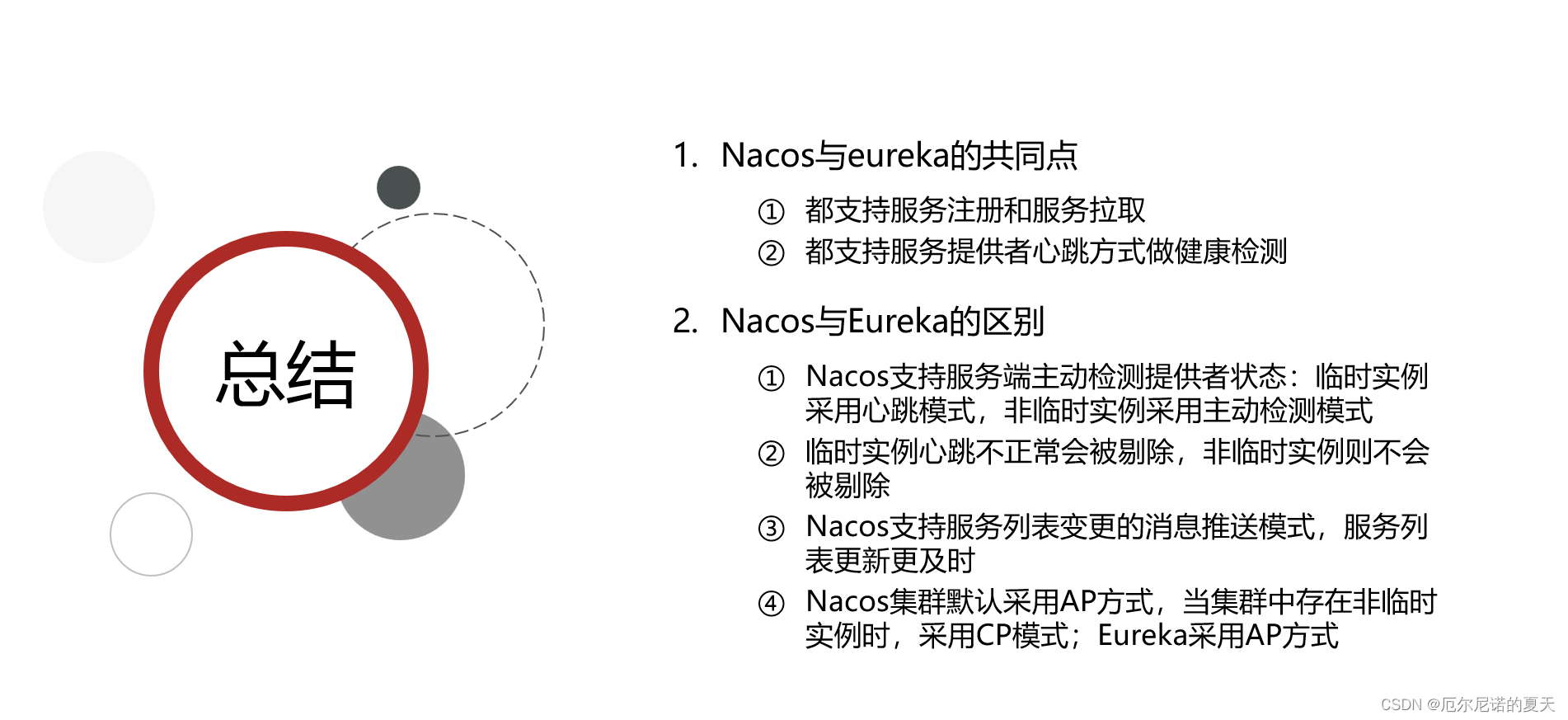
Spring Clould 注册中心 - Eureka,Nacos
视频地址:微服务(SpringCloudRabbitMQDockerRedis搜索分布式) Eureka 微服务技术栈导学(P1、P2) 微服务涉及的的知识 认识微服务-服务架构演变(P3、P4) 总结: 认识微服务-微服务技…...

使用appuploader工具发布证书和描述性文件教程
使用APPuploader工具发布证书和描述性文件教程 之前用AppCan平台开发了一个应用,平台可以同时生成安卓版和苹果版,想着也把这应用上架到App Store试试,于是找同学借了个苹果开发者账号,但没那么简单,还要用到Mac电脑的…...
【面试八股文】每日一题:谈谈你对IO的理解
谈谈你对IO的理解 每日一题-Java核心-谈谈你对对IO的理解【面试八股文】 1.Java基础知识 Java IO(Input/Output)是Java编程语言中用于处理输入和输出的一组类和接口。它提供了一种在Java程序中读取和写入数据的方法。 Java IO包括两个主要的部分&#x…...

200. 岛屿数量
思路:遍历整个矩阵,对每个格子执行以下操作: 如果格子是陆地(‘1’),则将其标记为已访问(‘0’),并从当前位置开始进行深度优先搜索,将与当前格子相邻的陆地都…...

【LeetCode】581.最短无序连续子数组
题目 给你一个整数数组 nums ,你需要找出一个 连续子数组 ,如果对这个子数组进行升序排序,那么整个数组都会变为升序排序。 请你找出符合题意的 最短 子数组,并输出它的长度。 示例 1: 输入:nums [2,6…...

曲面(弧面、柱面)展平(拉直)瓶子标签识别ocr
瓶子或者柱面在做字符识别的时候由于变形,识别效果是很不好的 或者是检测瓶子表面缺陷的时候效果也没有展平的好 下面介绍两个项目,关于曲面(弧面、柱面)展平(拉直) 项目一:通过识别曲面的6个点…...
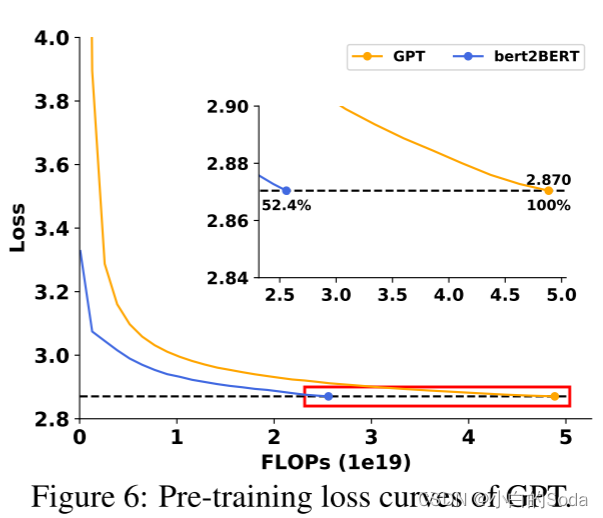
知识继承概述
文章目录 知识继承第一章 知识继承概述1.背景介绍第一页 背景第二页 大模型训练成本示例第三页 知识继承的动机 2.知识继承的主要方法 第二章 基于知识蒸馏的知识继承预页 方法概览 1.知识蒸馏概述第一页 知识蒸馏概述第二页 知识蒸馏第三页 什么是知识第四页 知识蒸馏的核心目…...

如何免费下载百度文库文档:三步搞定PDF保存的终极指南
如何免费下载百度文库文档:三步搞定PDF保存的终极指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要下载券…...

【低功耗蓝牙】④ 蓝牙MIDI协议:从ESP32 MicroPython代码到智能乐器DIY
1. 蓝牙MIDI协议入门:从音乐小白到智能乐器开发者 第一次听说蓝牙MIDI协议时,我正盯着桌上的ESP32开发板发呆。作为一个只会弹几个和弦的编程爱好者,完全没想到自己能用代码"演奏"音乐。蓝牙MIDI就像音乐世界的通用语言,…...

iOS越狱终极指南:解锁iPhone隐藏功能的3个关键步骤
iOS越狱终极指南:解锁iPhone隐藏功能的3个关键步骤 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址: ht…...

百度网盘直链解析终极指南:如何实现高速下载的完整技术方案
百度网盘直链解析终极指南:如何实现高速下载的完整技术方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在云存储服务普及的今天,百度网盘作为国内用…...

All in Token,移动,电信,联通,百度,阿里,字节,华为,Token战争,Token无用:李彦宏用DAA终结了AI的度量衡之争
今年4月,AI行业出现了一组让投资人坐立难安的数据:Anthropic年化营收突破300亿美元,正式超过OpenAI的约250亿美元。但反常的是,据第三方机构估算,Claude的月活用户仅约为ChatGPT的2.44%。以及,Anthropic的模…...

从零构建情感大语言模型:基于EmoLLM的实践指南
1. 项目概述:当大语言模型学会“察言观色”最近在折腾一个挺有意思的开源项目,叫SmartFlowAI/EmoLLM。光看名字你可能就猜到了,这玩意儿跟“情绪”和“大语言模型”有关。没错,它的核心目标就是让冷冰冰的LLM(Large La…...

5分钟快速上手:Windows虚拟显示器终极指南,轻松实现多屏扩展
5分钟快速上手:Windows虚拟显示器终极指南,轻松实现多屏扩展 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 还在为单显示器工作效率低下而烦恼吗…...

Agent Framework 中的 Workflow Composition
在前面的文章中,我们已经介绍了 Agent Framework 中如何定义流程节点,以及 Workflow 的流式执行事件。 如果你对这些概念还不太熟悉,可以先回顾上一篇文章: Agent Framework 定义流程节点以及节点的流式输出 这一节我们来介绍 Wor…...

基于MCP协议构建Reddit社区趋势分析工具:架构、部署与应用
1. 项目概述:一个实时洞察社区脉搏的利器最近在做一个社区运营相关的项目,需要实时追踪几个特定话题在Reddit上的讨论热度变化。手动刷帖、统计关键词频率这种笨办法效率太低,而且很难量化趋势。就在我琢磨着是不是要自己写个爬虫加分析脚本的…...

LoRA模型合并实战指南:多技能融合与vLLM部署
1. 项目概述:LoRA模型合并的“瑞士军刀”最近在折腾大语言模型微调的朋友,估计对LoRA(Low-Rank Adaptation)这个词都不陌生。它就像给预训练好的大模型“打补丁”,用极小的参数量(通常只有原模型的0.1%到1%…...