【编织时空四:探究顺序表与链表的数据之旅】
本章重点
一、链表的分类

实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
1. 单向或者双向

2. 带头或者不带头
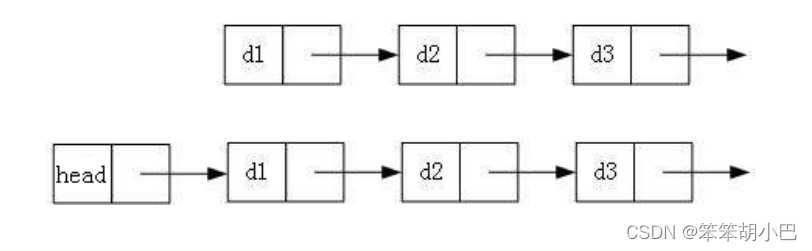 3. 循环或者非循环
3. 循环或者非循环

虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
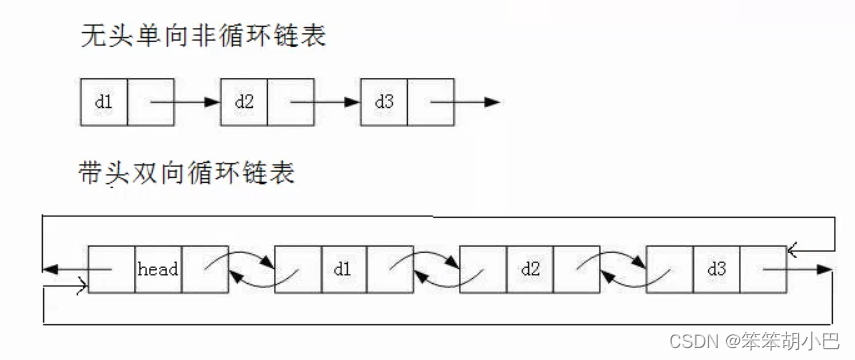
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都 是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带 来很多优势,实现反而简单了,后面我们代码实现了就知道了。

二、带头双向循环链表接口实现
1.申请结点:struct ListNode* BuyLTNode(LTDataType x)
动态申请结点,函数返回的是一个指针类型,用malloc开辟一个LTNode大小的空间,并用node指向这个空间,再判断是否为空,如为空就perror,显示错误信息。反之则把要存的数据x存到newnode指向的空间里面,把指针置为空。
// 申请结点
struct ListNode* BuyLTNode(LTDataType x)
{struct ListNode* node = (struct ListNode*)malloc(sizeof(struct ListNode));if (node == NULL){perror("malloc fail");exit(-1);}node->data = x;node->prev = node;node->next = node;return node;
}
2.初始化:struct ListNode* LTInit()
// 初始化
void LTInit(struct ListNode* phead)
{phead = BuyLTNode(-1);phead->prev = phead;phead->next = phead;
}
我们首先看看这个初始化有什么问题嘛?

phead为空指针,说明我们的初始化没有效果,这是因为phead是函数里面的形参,出了作用域就销毁,plsit仍然是空指针,形参的改变不能影响实参,但是我们可以通过返回phead的地址解决问题。
单链表开始是没有节点的,可以定义一个指向空指针的结点指针,但是此链表不同,需要在初始化函数中创建个头结点,它不用存储有效数据。因为链表是循环的,在最开始需要让头结点的next和pre指向头结点自己。
因为其他函数也不需要用二级指针(因为头结点指针是不会变的,变的是next和pre,改变的是结构体,只需要用结构体针即可,也就是一级指针)为了保持一致此函数也不用二级指针,把返回类型设置为结构体指针类型。
// 初始化 - 改变实参plsit
struct ListNode* LTInit()
{struct ListNode* phead = BuyLTNode(-1);phead->prev = phead;phead->next = phead;return phead;
}3.尾插:void LTPushBack(struct ListNode* phead, LTDataType x)
尾插首先要找到尾结点,再将要尾插的结点与尾结点和带头结点链接,由于是带头结点,所以此处不需要关注头结点为空的问题。
// 尾插
void LTPushBack(struct ListNode* phead, LTDataType x)
{assert(phead);struct ListNode* tail = phead->prev;struct ListNode* newnode = BuyLTNode(x);newnode->prev = tail;tail->next = newnode;newnode->next = phead;phead->prev = newnode;}
4.尾删:void LTPopBack(struct ListNode* phead)
尾删只需要找到尾结点的前驱结点,再把带头结点和前驱结点链接,释放尾结点就完成了尾删。
不过这里需要处理一下只有带头结点的删除,此时真正的链表为空,此时就不能删除了。
// 尾删
void LTPopBack(struct ListNode* phead)
{assert(phead);assert(phead->next != phead);//链表为空struct ListNode* tail = phead->prev;struct ListNode* tailPrev = tail->prev;free(tail);tailPrev->next = phead;phead->next = tailPrev;}
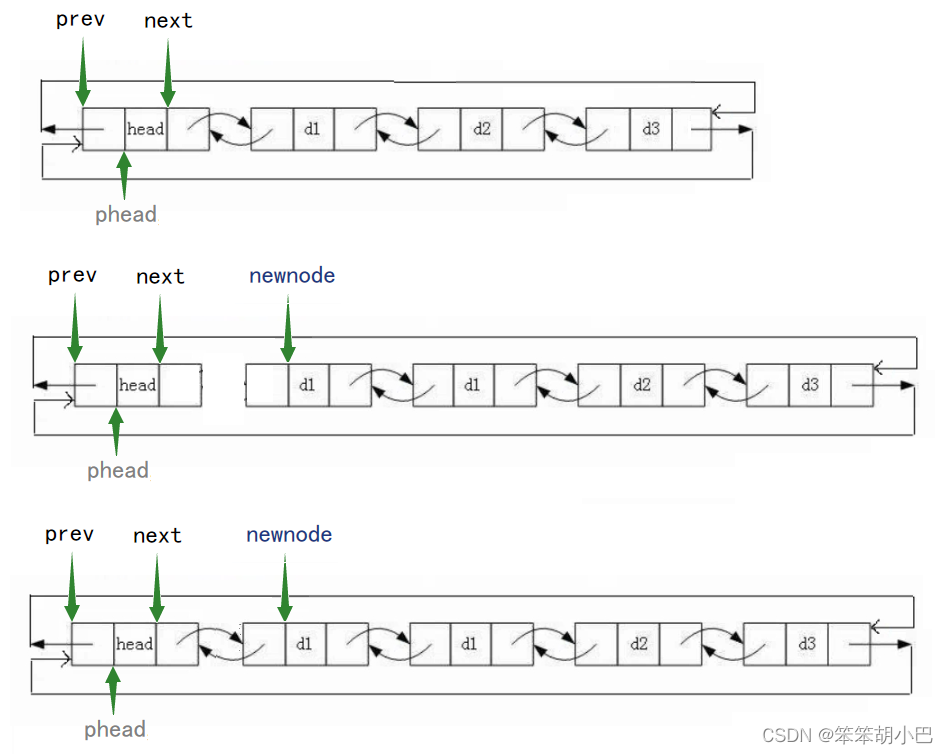
5.头插:void LTPushFront(struct ListNode* phead, LTDataType x)
头插需要注意顺序,如果先让phead和newnode链接,那么就找不到phead结点的后续结点,这样就无法让newnode和phead结点的后续结点链接。
// 头插
void LTPushFront(struct ListNode* phead, LTDataType x)
{assert(phead);struct ListNode* newnode = BuyLTNode(x);//顺序不可颠倒newnode->next = phead->next;phead->next->prev = newnode;phead->next = newnode;newnode->prev = phead;
}
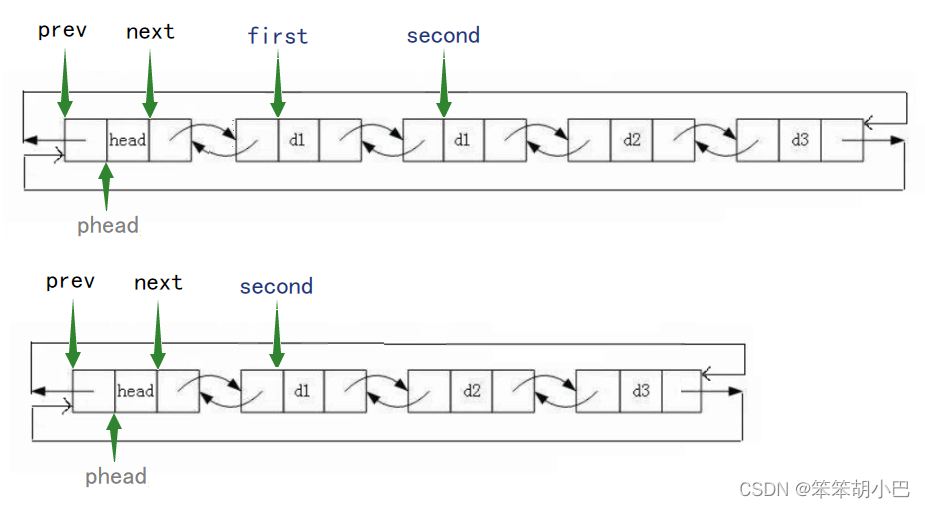
6.头删:void LTPopFront(struct ListNode* phead)
// 头删
void LTPopFront(struct ListNode* phead)
{assert(phead);assert(phead->next != phead);//链表为空struct ListNode* first = phead->next;struct ListNode* second = first->next;free(first);phead->next = second;second->prev = phead;
}
7.链表长度:int LTSize(struct ListNode* phead)
求链表长度,先把头结点下一个结点存到cur中,再用while循环遍历终止条件是cur等于头结点,用size++记录长度,并更新cur,最后返回size,32位机器下是无符号整型size_t。
( 此类型可以提高代码的可移植性,有效性,可读性。此链表长度可能是字符型或者数组整型,他可以提供一种可移植方法来声明与系统中可寻址的内存区域一致的长度,而且被设计的足够大,能表示内存中任意对象的大小)
注意这里求链表长度不需要求带头结点,我们有时也经常看到由于带头结点的数据没有使用,就有的书上会把该数据存储上链表的长度size=phead->data,然后插入数据phead->data++,删除phead->--,但是这有个限制,这种写法只适合int类型,如果我们写出char类型的数据,存储几个数据char就保存不了,char类型的phead->data一直++最后就会溢出,所以不建议这种写法。
// 链表长度
int LTSize(struct ListNode* phead)
{assert(phead);int size = 0;struct ListNode* cur = phead->next;while (cur != phead){size++;cur = cur->next;}return size;
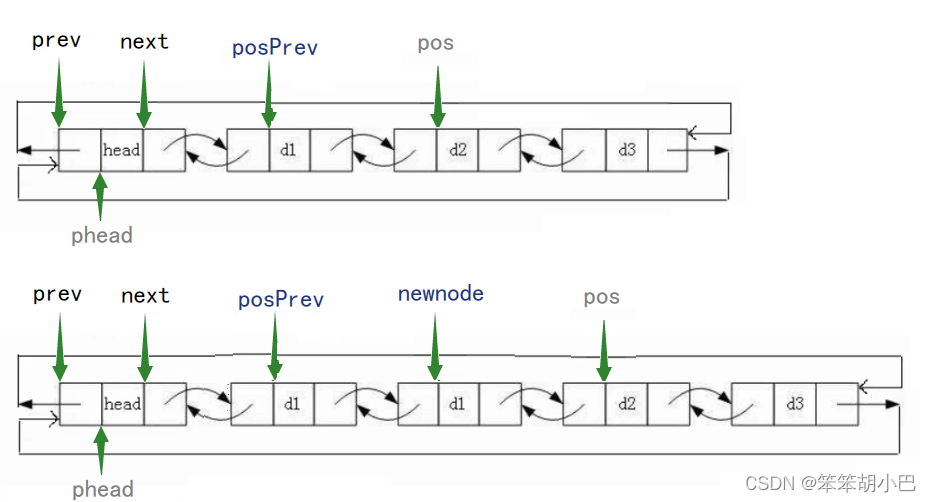
}8.在pos的前面进行插入:void LTInsert(struct ListNode* pos, LTDataType x)
断言pos,不能为空,插入数据先申请一结点放到定义的newnode指针变量中,为了不用考虑插入顺序,先把pos前面的存到posPrev中,然后就可以随意链接:
posPrev指向新节点,新节点前驱指针指向posPrev,新节点指向pos,pos前驱指针指向新节点。
// 在pos的前面进行插入
void LTInsert(struct ListNode* pos, LTDataType x)
{assert(pos);struct ListNode* posPrev = pos->prev;struct ListNode* newnode = BuyLTNode(x);posPrev->next = newnode;newnode->prev = posPrev;newnode->next = pos;pos->prev = newnode;
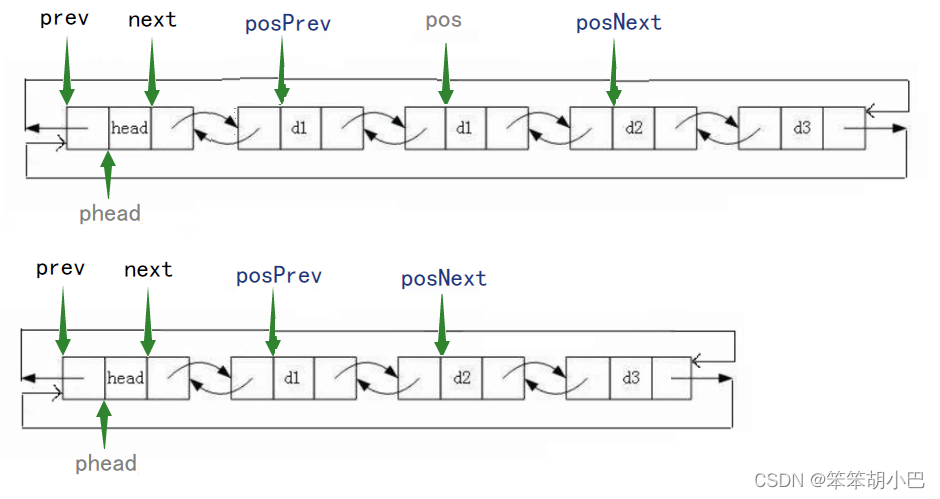
} 9.删除pos位置的结点:void LTErase(struct ListNode* pos)
9.删除pos位置的结点:void LTErase(struct ListNode* pos)
删除把pos位置之前的结点直接指向pos的下一个结点,把pos下一个结点的前驱指针指向pos之前的结点。
// 删除pos位置的结点
void LTErase(struct ListNode* pos)
{assert(pos);struct ListNode* posPrev = pos->prev;struct ListNode* posNext = pos->next;free(pos);posPrev->next = posNext;posNext->prev = posPrev;
} 
10.双向链表查找:struct ListNode* ListFind(struct ListNode* phead, LTDataType x)
查找把头结点下一个结点存到cur,然后用while循环遍历,终止条件是cur等于头结点指针,如果cur等于x,直接返回cur指针,再更新cur,最后遍历完返回NULL,表示没有该数据。
// 双向链表查找
struct ListNode* ListFind(struct ListNode* phead, LTDataType x)
{assert(phead);struct ListNode* cur = phead->next;while (cur != phead){if (cur->data == x)return cur;cur = cur->next;}return NULL;
}11.销毁:void LTDestroy(struct ListNode* phead)
释放链表从头开始释放,把头结点下一个结点存到cur中,再用用while循环,终止条件是cur不等于头指针,在里面把cur下一个指针存到next中,释放掉cur,再把next更新为cur。最后头结点也是申请的,也得释放。
这里需要注意,由于形参的改变不会影响实参,我们在函数内部将phead置空是无意义的,我们需要在函数外面调用LTDestroy函数后,需要手动将phead置空。
// 销毁
void LTDestroy(struct ListNode* phead)
{assert(phead);struct ListNode* cur = phead->next;while (cur != phead){struct ListNode* next = cur->next;free(cur);cur = next;}free(phead);
}12.打印:void LTPrint(struct ListNode* phead)
打印链表,先断言phead,它不能为空,再把头结点下个地址存到cur中,用while循环去遍历,终止条件是等于头指针停止,因为他是循环的,并更新cur。
// 打印
void LTPrint(struct ListNode* phead)
{assert(phead);printf("phead<=>");struct ListNode* cur = phead->next;while (cur != phead){printf("%d<=>", cur->data);cur = cur->next;}
}三、顺序表和链表的区别

| 不同点 | 顺序表 | 链表 |
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定 连续 |
| 随机访问 | 支持O(1) | 不支持:O(N) |
| 任意位置插入或者删除 元素 | 可能需要搬移元素,效率低 O(N) | 只需修改指针指向 |
| 插入 | 动态顺序表,空间不够时需要 扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
| 缓存利用率 | 高 | 低 |
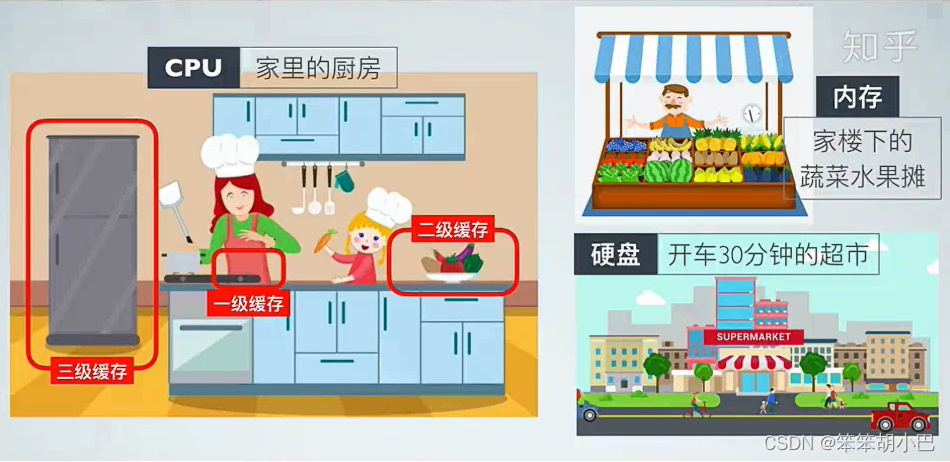
四、缓存利用率参考存储体系结构 以及 局部原理性。
1.存储体系结构

寄存器(Registers):寄存器是CPU内部的最快速存储,用于存储最常用的数据和指令。它们在执行指令时起着重要作用,速度非常快。
高速缓存(Cache):高速缓存是位于中央处理器(CPU)和主存储器之间的一层快速存储,用于临时存放经常访问的数据和指令。它可以分为多个层次,如L1、L2和L3缓存,随着级别的升高,容量逐渐增大,但速度逐渐降低。
主存储器(Main Memory):也称为RAM(Random Access Memory),主存储器是计算机中用于存放运行中程序和数据的地方。它是CPU能够直接访问的存储设备,速度比较快,但容量通常相对有限。
辅助存储器(Secondary Storage):这包括各种长期存储设备,如硬盘驱动器、固态硬盘、光盘、磁带等。这些设备的容量通常很大,但速度较慢,用于持久性存储和备份。
虚拟内存(Virtual Memory):虚拟内存是一种在主存和辅助存储之间创建的抽象层,允许程序使用比主存更大的地址空间。操作系统可以根据需要将数据从主存移到辅助存储,以优化内存使用。
2.局部性原理
存储体系结构的局部性原理是指在计算机程序执行过程中,访问内存的模式往往呈现出一定的规律性,即数据和指令的访问并不是完全随机的,而是倾向于集中在某些特定的内存区域或者特定的数据块上。这个原理分为两种类型:时间局部性和空间局部性。
时间局部性(Temporal Locality):时间局部性指的是一个被访问过的内存位置在未来的一段时间内很可能会再次被访问。这意味着程序在不久的将来可能会多次使用相同的数据或指令。时间局部性的实现依赖于高速缓存,因为缓存可以暂时存储最近使用过的数据,从而在未来的访问中加速存取。
空间局部性(Spatial Locality):空间局部性指的是在访问某个内存位置时,附近的内存位置也很可能会被访问。这种情况在程序中存在连续存储、数组访问等情况下特别明显。空间局部性的实现同样依赖于高速缓存,因为缓存可以在一个较小的区域内存储多个相邻的数据块。
局部性原理对计算机性能具有重要意义。通过充分利用局部性,计算机系统可以更有效地使用高速缓存,减少主存访问次数,从而提高数据访问的速度和效率。这对于减少存储层次之间的数据传输时间以及提高程序的整体性能至关重要。
举例来说,如果一个循环中多次使用相同的数组元素,由于时间局部性,这些数组元素会被缓存在高速缓存中,从而避免了多次访问主存。同样,如果一个算法中需要顺序访问数组的各个元素,由于空间局部性,缓存中可能会存储这些相邻的数据块,从而加速了后续的访问。
3.为什么顺序表的效率比链表效率高
顺序表:顺序表是一种将元素顺序存储在一块连续的内存区域中的数据结构。由于顺序表的元素在内存中是相邻存储的,因此它充分利用了空间局部性。当访问一个元素时,由于它的相邻元素也在内存中,这些相邻元素很可能也会被加载到高速缓存中,从而减少了主存访问的次数。此外,由于顺序表的元素是连续存储的,通过数组索引可以直接计算出元素的地址,避免了链表节点的跳转操作。
链表:链表是一种通过节点和指针连接元素的数据结构,它的元素在内存中不一定是连续存储的。在链表中,每个节点都包含了数据以及指向下一个节点的指针。这种非连续的存储方式可能导致空间局部性较差,因为在访问一个节点时,并不保证它的相邻节点会被加载到高速缓存中。这会导致更频繁的主存访问,从而降低了效率。
综上所述,顺序表相比链表具有更好的空间局部性。它的元素连续存储,使得访问一个元素时,附近的元素也可能在缓存中,从而减少了主存访问的需求,提高了数据访问的速度和效率。而链表的节点之间不一定相邻存储,导致空间局部性不如顺序表,因此链表在访问数据时可能需要更多的主存访问操作,从而效率相对较低。
需要注意的是,对于插入、删除等操作,链表在某些情况下可能更加灵活,因为它们不需要移动大量的数据,而顺序表在插入、删除操作时可能需要进行元素的移动,可能会带来一些开销。所以,在选择使用顺序表还是链表时,需要根据具体的应用场景和操作需求综合考虑。
本章结束啦!!!

相关文章:
【编织时空四:探究顺序表与链表的数据之旅】
本章重点 链表的分类 带头双向循环链表接口实现 顺序表和链表的区别 缓存利用率参考存储体系结构 以及 局部原理性。 一、链表的分类 实际中链表的结构非常多样,以下情况组合起来就有8种链表结构: 1. 单向或者双向 2. 带头或者不带头 3. 循环或者非…...

PHP8的字符串操作1-PHP8知识详解
字符串是php中最重要的数据之一,字符串的操作在PHP编程占有重要的地位。在使用PHP语言开发web项目的过程中,为了实现某些功能,经常需要对某些字符串进行特殊的处理,比如字符串的格式化、字符串的连接与分割、字符串的比较、查找等…...
电脑提示msvcp140.dll丢失的解决方法,dll组件怎么处理
Windows系统有时在打开游戏或者软件时, 系统会弹窗提示缺少“msvcp140.dll.dll”文件 或者类似错误提示怎么办? 错误背景: msvcp140.dll是Microsoft Visual C Redistributable Package中的一个动态链接库文件,它在运行软件时提…...

stable diffusion基础
整合包下载:秋叶大佬 【AI绘画8月最新】Stable Diffusion整合包v4.2发布! 参照:基础04】目前全网最贴心的Lora基础知识教程! VAE 作用:滤镜微调 VAE下载地址:C站(https://civitai.com/models…...

Greiner–Hormann裁剪算法深度探索:C++实现与应用案例
介绍 在计算几何中,裁剪是一个核心的主题。特别是,多边形裁剪已经被广泛地应用于计算机图形学,地理信息系统和许多其他领域。Greiner-Hormann裁剪算法是其中之一,提供了一个高效的方式来计算两个多边形的交集、并集等。在本文中&…...

Automatically Correcting Large Language Models
本文是大模型相关领域的系列文章,针对《Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies》的翻译。 自动更正大型语言模型:综述各种自我更正策略的前景 摘要1 引言2 自动反馈校正LLM的…...
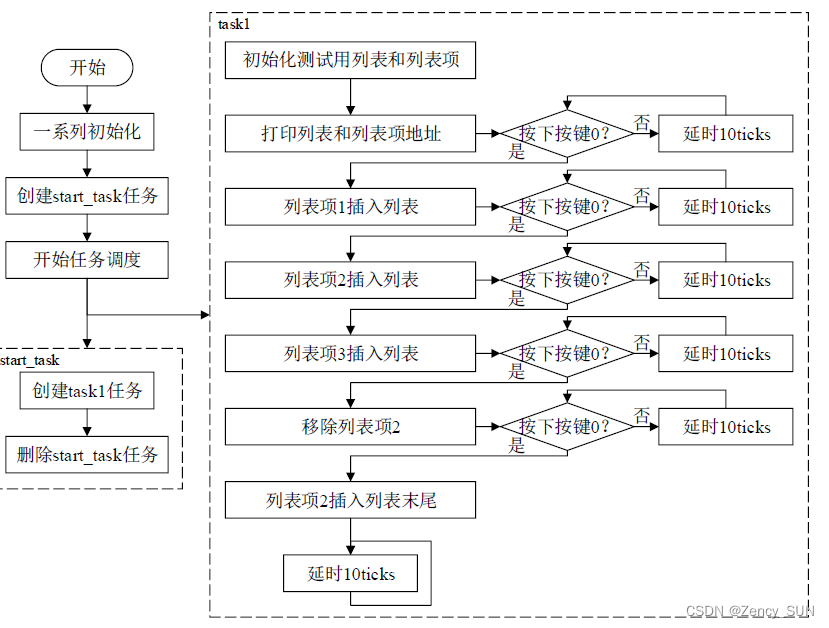
【学习FreeRTOS】第8章——FreeRTOS列表和列表项
1.列表和列表项的简介 列表是 FreeRTOS 中的一个数据结构,概念上和链表有点类似,列表被用来跟踪 FreeRTOS中的任务。列表项就是存放在列表中的项目。 列表相当于链表,列表项相当于节点,FreeRTOS 中的列表是一个双向环形链表列表的…...

分布式图数据库 NebulaGraph v3.6.0 正式发布,强化全文索引能力
本次 v3.6.0 版本,主要强化全文索引能力,以及优化部分场景下的 MATCH 性能。 强化 强化增强全文索引功能,具体 pr 参见:#5567、#5575、#5577、#5580、#5584、#5587 优化 支持使用 MATCH 子句检索 VID 或属性索引时使用变量&am…...
在 ubuntu 18.04 上使用源码升级 OpenSSH_7.6p1到 OpenSSH_9.3p1
1、检查系统已安装的当前 SSH 版本 使用命令 ssh -V 查看当前 ssh 版本,输出如下: OpenSSH_7.6p1 Ubuntu-4ubuntu0.7, OpenSSL 1.0.2n 7 Dec 20172、安装依赖,依次执行以下命令 sudo apt update sudo apt install build-essential zlib1g…...

python中可以处理word文档的模块:docx模块
前言 大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 话不多说,直接开搞,如果有什么疑惑/资料需要的可以点击文章末尾名片领取源码 一.docx模块 Python可以利用python-docx模块处理word文档,处理方式是面向对象的。 也就是说python-docx模块…...

TikTok或将于8月底关闭半闭环、速卖通或将推出“半托管”模式
《出海周报》是运营坛为外贸企业主和外贸人独家打造的重要资讯栏目,聚焦企业出海、海外市场动态、海外监管政策等方面,以简捷的方式,提升读者获取资讯的效率。 接下来运营坛为大家带来第15期出海周报,快来看看这周国内外市场发生了…...

《凤凰架构》第二章——访问远程服务
前言 这章挺难的,感觉离我比较远,不太好懂,简单记录吧。 这章主要讲访问远程服务,主要对比了RPC和REST的区别,可以结合知乎上的文章《既然有 HTTP 请求,为什么还要用 RPC 调用?》 这篇文章进行…...
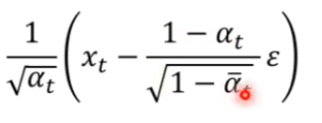
【Diffusion】李宏毅2023机器学习Diffusion笔记
文章目录 1 想法概述2 实际过程阶段1 Add Noise阶段2 Denoise 3 数学原理4 为什么推理时要额外加入noise5 一些不知道对不对的Summary 1 想法概述 从一张充满噪声的图中不断denoise,最终得到一张clear的图片。为了确定当前图片中噪声占比的大小,同时输入…...

CloudEvents—云原生事件规范
我们的系统中或多或少都会用到如下两类业务技术: 异步任务,用于降低接口时延或削峰,提升用户体验,降低系统并发压力;通知类RPC,用于微服务间状态变更,用户行为的联动等场景; 以上两种…...

神经网络基础-神经网络补充概念-51-局部最优问题
概念 局部最优问题是在优化问题中常见的一个挑战,特别是在高维、非凸、非线性问题中。局部最优问题指的是算法在优化过程中陷入了一个局部最小值点,而不是全局最小值点。这会导致优化算法在某个局部区域停止,而无法找到更好的解。 解决方案…...

深度学习中,什么是batch-size?如何设置?
什么是batch-size? batch-size 是深度学习模型在训练过程中一次性输入给模型的样本数量。它在训练过程中具有重要的意义,影响着训练速度、内存使用以及模型的稳定性等方面。 以下是 batch-size 大小的一些影响和意义: 训练速度:较大的 bat…...
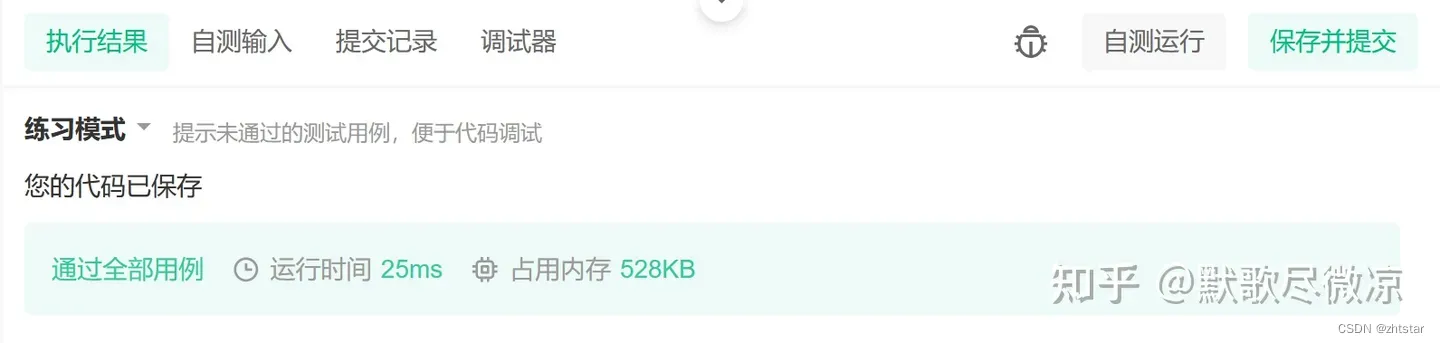
[保研/考研机试] KY26 10进制 VS 2进制 清华大学复试上机题 C++实现
题目链接: 10进制 VS 2进制http://www.nowcoder.com/share/jump/437195121691738172415 描述 对于一个十进制数A,将A转换为二进制数,然后按位逆序排列,再转换为十进制数B,我们称B为A的二进制逆序数。 例如对于十进制…...
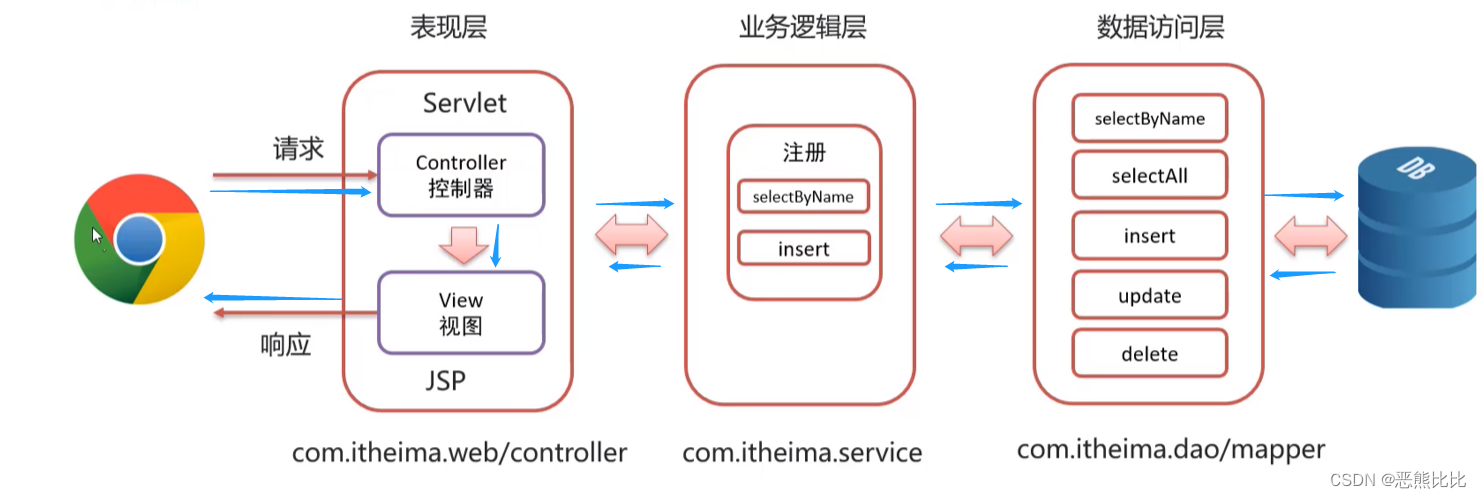
JSP-学习笔记
文章目录 1.JSP介绍2 JSP快速入门3 JSP 脚本3.1 JSP脚本案例3.2 JSP缺点 4 EL表达式4.1 快速入门案例 5. JSTL标签6. MVC模式和三层架构6.1 MVC6.2 三层架构 7. 案例-基于MVC和三层架构实现商品表的增删改查 1.JSP介绍 概念 JSP(JavaServer Pages)是一种…...
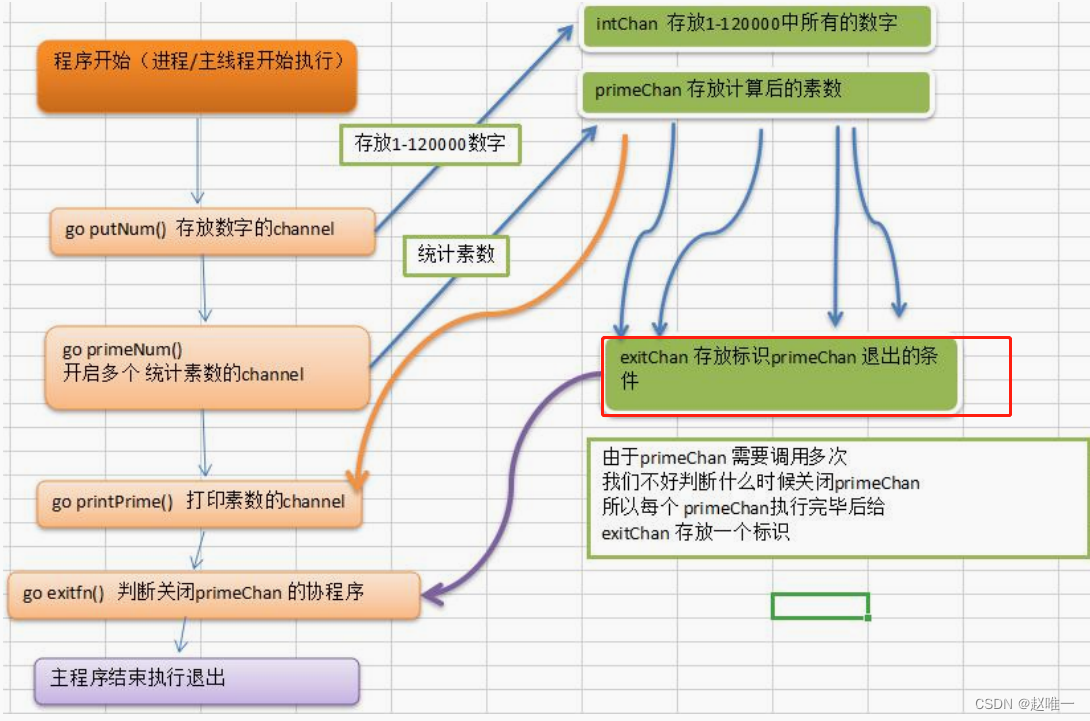
Golang协程,通道详解
进程、线程以及并行、并发 关于进程和线程 进程(Process)就是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位,进程是一个动态概念,是程序在执行过程中分配和管理资源的基本单位,每一…...

unity 之 Vector 数据类型
文章目录 Vector 1Vector 2Vector 3Vector 4 Vector 1 在Unity中,Vector1 并不是一个常见的向量类型。 如果您需要表示标量(单个值)或者只需要一维的数据,通常会直接使用浮点数(float)或整数(in…...

保姆级教程:用CH34xSerCfg修改USB转串口芯片的VID/PID,解决驱动冲突和串口号固定问题
嵌入式开发实战:用CH34xSerCfg定制USB转串口设备标识与驱动管理 当你的工作台上同时连接着五个相同型号的USB转TTL模块,Windows设备管理器里COM端口像走马灯一样随机变换编号时;当团队协作开发中,每个成员需要固定识别自己的调试设…...
)
告别迷茫!在嵌入式Linux上用libwebsockets v4.0实现WebSocket客户端(含SSL配置避坑)
嵌入式Linux实战:libwebsockets v4.0客户端开发与SSL避坑指南 当树莓派的GPIO引脚需要与云端实时同步数据时,WebSocket往往是嵌入式开发者的首选协议。但面对内存仅512MB的ARMv7开发板,选用一个既支持SSL加密又能兼容C99标准的轻量级库&#…...

柔性LED灯丝DIY:从电路原理到创意饰品制作全攻略
1. 项目概述:当生日遇上柔性LED灯丝给孩子的生日派对准备一份独一无二的、会发光的惊喜,是很多家长和手工爱好者的心愿。这次,我们不买现成的塑料灯牌,而是亲手做一个能戴在头上或挂在脖子上的“生日数字灯冠”。这个项目的核心&a…...

【避坑指南】VSCode+EIDE+Keil混合开发环境:从零搭建到项目无缝迁移
1. 为什么需要VSCodeEIDEKeil混合开发环境? 作为一名嵌入式开发者,我深知Keil这个老牌IDE在开发效率上的痛点:代码补全弱、界面老旧、多窗口管理混乱。但直接完全迁移到VSCode又面临工程兼容性问题,特别是对传统AC5编译器的支持。…...

终极Windows Defender移除指南:13项核心服务的完整卸载方案
终极Windows Defender移除指南:13项核心服务的完整卸载方案 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirror…...

免费额度即将失效?ElevenLabs 2024.6.1新规生效前,必须完成的5项额度迁移准备
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs免费额度机制的本质解析 ElevenLabs 的免费额度并非按“每月重置”的静态配额,而是一种基于账户生命周期的动态信用池(Credit Pool),其底层由实…...

Aurora框架解析:一体化高性能云原生开发平台的设计与实践
1. 项目概述与核心价值如果你在开源社区里混迹过一段时间,尤其是对现代化、高性能的Web开发框架感兴趣,那么“Aurora”这个名字你大概率不会陌生。它不是一个简单的库或者工具,而是一个由社区驱动的、旨在构建下一代企业级应用开发平台的雄心…...

SyntaxUI:基于原子设计与Web组件的现代UI库开发实践
1. 项目概述:一个为开发者而生的现代UI组件库 如果你是一名前端开发者,或者正在构建一个需要用户界面的应用,那么你肯定经历过这样的场景:为了一个按钮的样式、一个表格的交互,或者一个模态框的动画,反复在…...

量化交易强化学习环境TradingGym:从Gym接口到实战策略训练
1. 项目概述:一个为量化交易策略量身定制的强化学习训练场如果你正在尝试将强化学习(Reinforcement Learning, RL)应用到股票、期货或加密货币的量化交易中,大概率会遇到一个共同的困境:环境太难搭了。市面上的回测框架…...

Pro Trinket:Arduino UNO的紧凑型替代方案与双模编程实战
1. Pro Trinket:当Arduino遇上“口袋工程学”如果你和我一样,在创客圈子里摸爬滚打多年,肯定经历过这样的场景:一个基于Arduino UNO的酷炫原型在面包板上运行得风生水起,但当你试图把它塞进一个精致的3D打印外壳&#…...