使用 BERT 进行文本分类 (02/3)

一、说明
在使用BERT(1)进行文本分类中,我向您展示了一个BERT如何标记文本的示例。在下面的文章中,让我们更深入地研究是否可以使用 BERT 来预测文本是使用 PyTorch 传达积极还是消极的情绪。首先,我们需要准备数据,以便使用 PyTorch 框架进行分析。
二、什么是 PyTorch
PyTorch 是用于构建深度学习模型的框架,深度学习模型是一种机器学习,通常用于图像识别和语言处理等应用程序。它由Facebook的人工智能研究小组于2016年开发,由于其灵活性,易用性和动态计算图构建而广受欢迎。
PyTorch 提供了一个基于 Python 的科学计算包,它使用图形处理单元 (GPU) 的强大功能来加速张量运算的计算。它具有简单直观的API,允许开发人员快速构建和训练深度学习模型。PyTorch 还支持自动微分,使用户能够计算任意函数的梯度。
三、准备我们的数据集
首先,让我们从Github下载我们的数据。这里有一个关于如何从Github下载CSV文件的小提醒。只需继续并单击以下链接:
github.com
然后,右键单击“原始”,然后左键单击“将链接文件下载为...”。您将看到“垃圾邮件.csv”并下载它。下载后,将其保存到您的首选文件夹中以供以后使用。
现在,让我们导入数据。我们看到一条错误消息,告诉我们部分数据未采用 UTF-8 编码。
import pandas as pd
df = pd.read_csv("spam.csv")ERROR:
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 606-607: invalid continuation byte我们可以通过了解数据包含的字符编码并在读取数据时调用该编码来修复此错误。
# Use chardet to know the character encoding
import chardet
with open("spam.csv", 'rb') as rawdata:result = chardet.detect(rawdata.read(100000))
resultOutput:
{'encoding': 'Windows-1252', 'confidence': 0.7270322499829184, 'language': ''}似乎我们的数据是在“Windows-1252”中编码的。那让我们再读一遍。它奏效了!
df = pd.read_csv("spam.csv", encoding = 'Windows-1252')
df.head()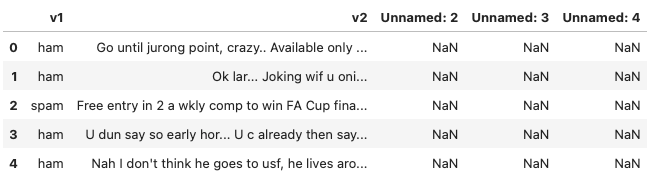
如我们所见,我们实际上并不需要“v1”和“v2”以外的列。此外,如果我们将“v1”和“v2”重命名为“类别”和“消息”,则更容易理解。
df = df.loc[:, ['v1', 'v2']]
df = df.rename(columns={'v1': 'Category', 'v2': 'Message'})
df.head()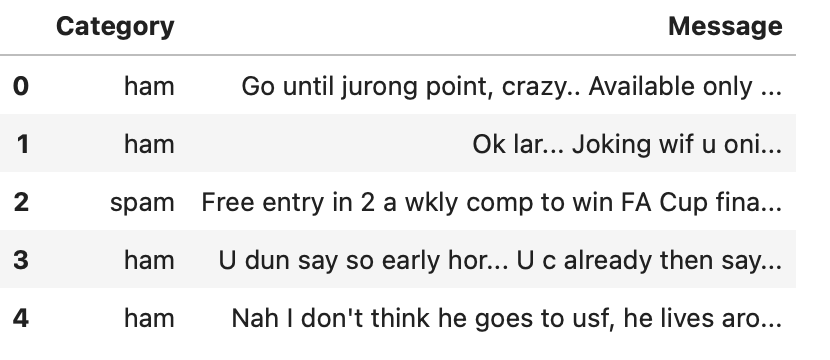
现在,我们应该看看我们的数据集,看看每个类别中有多少条消息。
df['Category'].value_counts()Output:
ham 4825
spam 747
Name: Category, dtype: int64四、创建平衡数据集
事实证明,正常邮件比垃圾邮件多。构建机器学习模型时,如果数据集不平衡,其中一个类中的数据数量明显多于另一个类,则可能会对模型的性能产生各种影响。一些潜在的后果。例如:
-1 有偏差模型:如果数据集不平衡,模型可能会偏向多数类,而对少数类表现不佳。这是因为模型更有可能预测多数类,这将导致少数类的准确性较差。
-2 泛化不良:不平衡的数据集可能导致模型泛化不良。这是因为该模型将在不代表数据真实世界分布的数据集上进行训练,因此它可能无法很好地概括看不见的数据。
-3 评估不准确:如果使用准确性作为指标评估模型,则可能会产生误导性结果。例如,始终预测不平衡数据集中多数类的模型可能具有很高的准确性,但对少数类没有用。
-4 过拟合:由于数据点数量较多,模型可能会过度拟合多数类,从而导致测试数据的性能不佳。
为了解决这些问题,可以使用各种技术来平衡数据集,例如对少数类进行过采样,对多数类进行欠采样,或同时使用两者的组合。在这篇文章中,我将使用欠采样方法。
df_spam = df[df['Category']=='spam']
df_ham = df[df['Category']=='ham']
df_ham_downsampled = df_ham.sample(df_spam.shape[0])
df_balanced = pd.concat([df_ham_downsampled, df_spam])
df_balanced['Category'].value_counts()Output:
ham 747
spam 747
Name: Category, dtype: int64五、标记数据
当数据表示为数字而不是分类为用于训练和测试的模型时,机器学习算法在准确性和其他性能指标方面表现更好。我们需要用数值对分类值进行标签编码。在这里,我们创建了一个新列“标签”,如果邮件是垃圾邮件,我们将其标记为 1,否则为 0。
df_balanced['Label']=df_balanced['Category'].apply(lambda x: 1 if x=='spam' else 0)
df_balanced = df_balanced.reset_index(drop=True)display(df_balanced)
由作者创建
六、训练、验证和测试数据集:谁是谁
要记住的一件事是,当我们使用 train_test_split 库来训练模型时,我们实际上是将数据集拆分为 TRAINING 数据集和 VALIDATION 数据集,而不是 TRAINING 数据集和 TESTING 数据集。下面提醒一下这些数据集的含义。
- 训练集:用于构建我们的模型。我们将使用训练集来找到具有反向传播规则的“最佳”权重和偏差。在此阶段,我们通常会创建多个算法,以便在交叉验证阶段比较它们的性能。
- 交叉验证集:此数据集用于比较基于训练集创建的预测算法的性能。我们选择性能最佳的算法。
- 测试集:这是“未来”数据集。现在我们已经选择了我们喜欢的预测算法,但我们还不知道它将如何在完全看不见的真实世界数据上执行。因此,我们将我们选择的预测算法应用于我们的测试集,以查看它将如何执行,以便我们可以了解我们的算法在野外的性能。
因此,在测试集中,我们没有数据的标签,而是使用我们的模型来预测标签。我们只能将手头的数据集拆分为训练集和验证集,因为我们还没有“未来”数据。
七、拆分为训练数据集和验证数据集
现在我们了解了这三种类型的数据的真正含义,我们可以使用scikit-learn的train_test_split来拆分数据。
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(df_balanced['Message'],df_balanced['Label'], stratify=df_balanced['Label'], test_size=.2)X_train.head()Output:
708 ;-) ok. I feel like john lennon.
1386 Cashbin.co.uk (Get lots of cash this weekend!)...
1492 REMINDER FROM O2: To get 2.50 pounds free call...
119 Back in brum! Thanks for putting us up and kee...
89 Sorry, I can't help you on this.
Name: Message, dtype: object八、总结
我们已经学会了如何下载和拆分数据。在下一篇文章中,我们将首先对其进行标记,并使用DistilBERT训练分类器。达门·
相关文章:
使用 BERT 进行文本分类 (02/3)
一、说明 在使用BERT(1)进行文本分类中,我向您展示了一个BERT如何标记文本的示例。在下面的文章中,让我们更深入地研究是否可以使用 BERT 来预测文本是使用 PyTorch 传达积极还是消极的情绪。首先,我们需要准备数据…...

基于Hadoop的表级监管
现状 大数据平台中,采用hadoop的方式存储数据,hdfs本质上是文件系统,而文件系统对数据的监管能力有限,但是数据安全领域问题日渐凸显,现目前,大数据平台一般以分层结构进行授权,但是对于一线开发人员而言,是能够接触到整个大数据平台中的所有表的,那么如何实现这样一…...

【学习日记】【FreeRTOS】延时列表的实现
前言 本文在前面文章的基础上实现了延时列表,取消了 TCB 中的延时参数。 本文是对野火 RTOS 教程的笔记,融入了笔者的理解,代码大部分来自野火。 一、如何更高效地查找延时到期的任务 1. 朴素方式 在本文之前,我们使用了一种朴…...

LeetCode解法汇总833. 字符串中的查找与替换
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 描述: 你会得到一…...
ide internal errors【bug】
ide internal errors【bug】 前言版权ide internal errors错误产生相关资源解决1解决2 设置虚拟内存最后 前言 2023-8-15 12:36:59 以下内容源自《【bug】》 仅供学习交流使用 版权 禁止其他平台发布时删除以下此话 本文首次发布于CSDN平台 作者是CSDN日星月云 博客主页是h…...

阿里云与中国中医科学院合作,推动中医药行业数字化和智能化发展
据相关媒体消息,阿里云与中国中医科学院的合作旨在推动中医药行业的数字化和智能化发展。随着互联网的进步和相关政策的支持,中医药产业受到了国家的高度关注。这次合作将以“互联网 中医药”为载体,致力于推进中医药文化的传承和创新发展。…...

【Redis】Redis 的学习教程(五)之 SpringBoot 集成 Redis
在前几篇文章中,我们详细介绍了 Redis 的一些功能特性以及主流的 java 客户端 api 使用方法。 在当前流行的微服务以及分布式集群环境下,Redis 的使用场景可以说非常的广泛,能解决集群环境下系统中遇到的不少技术问题,在此列举几…...
github以及上传代码处理
最近在github上传代码的时候出现了: /video_parser# git push -u origin main Username for https://github.com: gtnyxxx Password for https://gtny2010github.com: remote: Support for password authentication was removed on August 13, 2021. remote: Plea…...
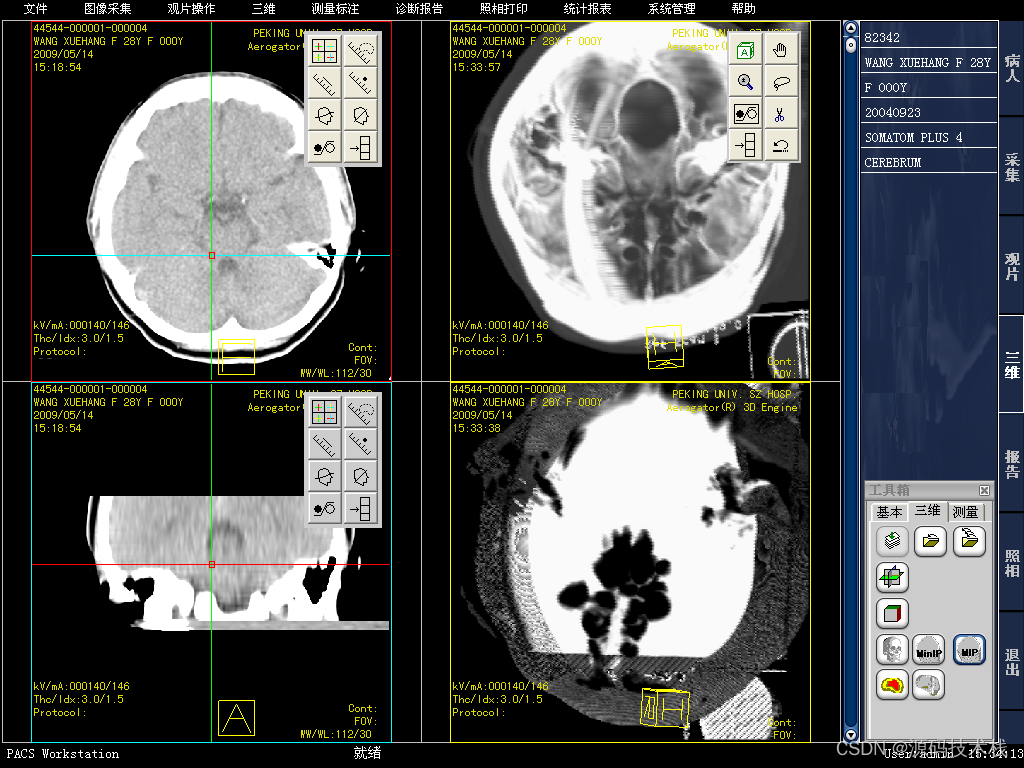
【PACS源码】认识PACS的架构和工作流程
(一)PACS系统的组成及架构 PACS系统的基本组成部分包括:数字影像采集、通讯和网络、医学影像存储、医学影像管理、各类工作站五个部分。 而目前PACS系统的软件架构选型上看,主要有C/S和B/S两种形式。 C/S架构,即Client…...

【C++】开源:跨平台Excel处理库-libxlsxwriter配置使用
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍Excel处理库-libxlsxwriter配置使用。 无专精则不能成,无涉猎则不能通。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下&…...

前端-轮询
一、轮询定义 轮询是指在一定的时间间隔内,定时向服务器发送请求,获取最新数据的过程。轮询通常用于从服务器获取实时更新的数据。 二、轮询和长轮询区别 轮询是在固定的时间间隔内向服务器发送请求,即使服务器没有数据更新也会继续发送请求…...
Python “贪吃蛇”游戏,在不断改进中学习pygame编程
目录 前言 改进过程一 增加提示信息 原版帮助摘要 pygame.draw pygame.font class Rect class Surface 改进过程二 增加显示得分 改进过程三 增加背景景乐 增加提示音效 音乐切换 静音切换 mixer.music.play 注意事项 原版帮助摘要 pygame.mixer pygame.mix…...

Linux网络编程_Ubuntu环境配置安装
文章目录: 一:基于vmware虚拟机安装Ubuntu系统(虚拟机) 1.vmware下载 2.Ubuntu系统下载 3.配置 3.1 无法连网:这里很容易出现问题 3.2 更换国内源 3.3 无法屏幕适配全屏 3.4 汉化 二:直接安装Ubun…...

gradle java插件
gradle java插件 1. 由来 Gradle是一种现代化的构建工具,Java插件是Gradle官方提供的插件,用于支持和管理Java项目的构建过程。 2. 常见五种示例和说明 示例1:配置源代码目录和编译选项 plugins {id java }sourceSets {main {java {srcD…...

神经网络基础-神经网络补充概念-48-rmsprop
概念## 标题 RMSProp(Root Mean Square Propagation)是一种优化算法,用于在训练神经网络等机器学习模型时自适应地调整学习率,以加速收敛并提高性能。RMSProp可以有效地处理不同特征尺度和梯度变化,对于处理稀疏数据和…...
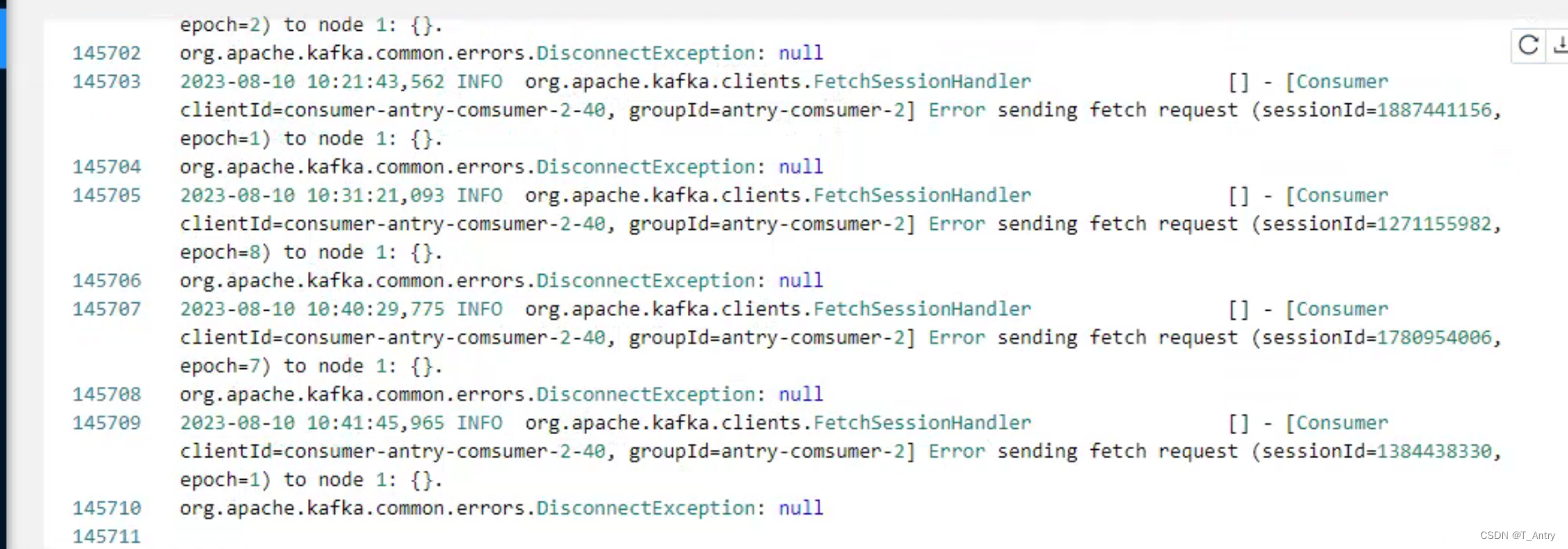
分析Flink,源和算子并行度不一致时,运行一段时间后,看似不再继续消费的问题,提供解决思路。
文章目录 背景分析 问题来了比较一开始的情况解决方式 背景 之前有分析过一次类似问题,最终结论是在keyby之后,其中有一个key数量特别庞大,导致对应的subtask压力过大,进而使得整个job不再继续运作。在这个问题解决之后ÿ…...
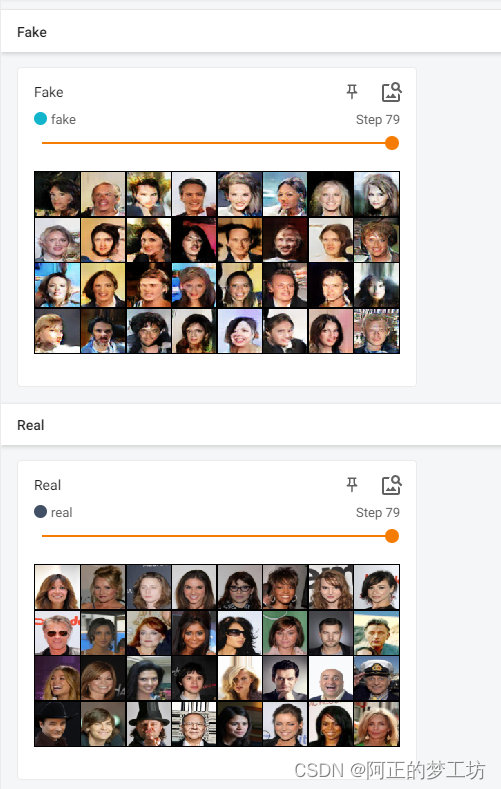
PyTorch训练深度卷积生成对抗网络DCGAN
文章目录 DCGAN介绍代码结果参考 DCGAN介绍 将CNN和GAN结合起来,把监督学习和无监督学习结合起来。具体解释可以参见 深度卷积对抗生成网络(DCGAN) DCGAN的生成器结构: 图片来源:https://arxiv.org/abs/1511.06434 代码 model.py impor…...

Spring-4-掌握Spring事务传播机制
今日目标 能够掌握Spring事务配置 Spring事务管理 1 Spring事务简介【重点】 1.1 Spring事务作用 事务作用:在数据层保障一系列的数据库操作同成功同失败 Spring事务作用:在数据层或业务层保障一系列的数据库操作同成功同失败 1.2 案例分析Spring…...
[PyTorch][chapter 49][创建自己的数据集 1]
前言: 后面几章主要利用DataSet 创建自己的数据集,实现建模, 训练,迁移等功能。 目录: pokemon 数据集深度学习工程步骤 一 pokemon 数据集介绍 1.1 pokemon: 数据集地址: 百度网盘路径: https://pan.baidu.com/s/1…...
中间件(二)dubbo负载均衡介绍
一、负载均衡概述 支持轮询、随机、一致性hash和最小活跃数等。 1、轮询 ① sequences:内部的序列计数器 ② 服务器接口方法权重一样:(sequences1)%服务器的数量(决定调用)哪个服务器的服务。 ③ 服务器…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

基于Groq LPU与React技术栈构建极速AI聊天应用实战
1. 项目概述:当极速推理遇上聊天应用最近在折腾AI应用开发的朋友,估计都绕不开一个词:推理速度。模型能力再强,如果生成一句话要等上十几秒,用户体验就无从谈起。正是在这种背景下,我注意到了unclecode/gro…...

天学网口碑好不好?2026年最新用户实测反馈给你答案
作为深耕教育数字化落地领域5年的从业者,最近后台收到不少公立校电教组老师、学生家长的提问:主打AI英语教学的天学网口碑到底怎么样?刚好我们团队刚做完2026年第一季度的英语教育数字化工具落地效果调研,结合一手实测数据给大家客…...

我给了智能体$100去赚钱,结果...
你看过那些演示。一个自主智能体启动,获得一个目标,然后——跳到两周后的 Twitter 帖子——它不知怎么地就在运营一个 Shopify 店铺、写通讯和炒币了。未来已来。AGI 即将降临。买课吧。 我想找出实际发生了什么。 所以我给了一个智能体 100 美元和一个…...

桌面自动化技能库:基于PyAutoGUI与Selenium的工程化实践
1. 项目概述:一个桌面操作员的技能库最近在GitHub上看到一个挺有意思的项目,叫Marways7/cua_desktop_operator_skill。光看这个名字,可能有点摸不着头脑,但作为一个在自动化运维和桌面支持领域摸爬滚打多年的老手,我立…...

MySQL高可用与扩展-主从复制读写分离分库分表
当单库压力越来越大时,常见演进路线是先做主从复制,再做读写分离;如果数据量和写入压力继续增长,就需要考虑分库分表。 这三者解决的问题不同:方案主要解决什么主从复制数据冗余、读扩展、故障切换基础读写分离缓解读请…...

【c++面向对象编程】第24篇:类型转换运算符:自定义隐式转换与explicit
目录 一、一个自然的想法 二、类型转换运算符的基本语法 写法 使用 三、隐式转换的风险 问题1:意外的不希望发生的转换 问题2:多个转换路径的歧义 问题3:与构造函数隐式转换叠加导致混乱 四、explicit:禁止隐式转换 语法…...

CircuitPython实战:I2S音频播放与asyncio异步编程构建智能温度监测系统
1. 项目概述与核心价值如果你正在寻找一种能让你的嵌入式项目“开口说话”或者“耳听八方”的方案,I2S音频绝对是你绕不开的技术。不同于我们熟悉的模拟音频,I2S是一种纯粹的数字音频传输协议,它通过三根线——时钟、声道选择和数据——就能传…...

在 1688、阿里国际站上,怎么分清哪些是真工厂、哪些是贸易商?一份采购辨别清单
跨境卖家和采购最常踩的坑,就是把贸易商当成了源头工厂。结果是:报价里多了一手差价、打样要等贸易商再转给后面的厂、出了质量问题没人能进车间整改。 平台上的"工厂认证"“源头工厂”"工厂直供"标签,看起来像是替你做了…...

小智聊天机器人的本地化部署。
前天到了,小智机器人ESP32-S2的套件(非焊接版的那一款),找王同学,学了学怎么焊接。昨天,使用面包板搭建电路,安装元器件,服务器端注册设置,刷程序,很快就完成…...