PyTorch训练深度卷积生成对抗网络DCGAN
文章目录
- DCGAN介绍
- 代码
- 结果
- 参考
DCGAN介绍
将CNN和GAN结合起来,把监督学习和无监督学习结合起来。具体解释可以参见 深度卷积对抗生成网络(DCGAN)
DCGAN的生成器结构:

图片来源:https://arxiv.org/abs/1511.06434
代码
model.py
import torch
import torch.nn as nnclass Discriminator(nn.Module):def __init__(self, channels_img, features_d):super(Discriminator, self).__init__()self.disc = nn.Sequential(# Input: N x channels_img x 64 x 64nn.Conv2d(channels_img, features_d, kernel_size=4, stride=2, padding=1), # 32 x 32nn.LeakyReLU(0.2),self._block(features_d, features_d*2, 4, 2, 1), # 16 x 16self._block(features_d*2, features_d*4, 4, 2, 1), # 8 x 8self._block(features_d*4, features_d*8, 4, 2, 1), # 4 x 4nn.Conv2d(features_d*8, 1, kernel_size=4, stride=2, padding=0), # 1 x 1nn.Sigmoid(),)def _block(self, in_channels, out_channels, kernel_size, stride, padding):return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False),nn.BatchNorm2d(out_channels),nn.LeakyReLU(0.2),)def forward(self, x):return self.disc(x)class Generator(nn.Module):def __init__(self, z_dim, channels_img, features_g):super(Generator, self).__init__()self.gen = nn.Sequential(# Input: N x z_dim x 1 x 1self._block(z_dim, features_g*16, 4, 1, 0), # N x f_g*16 x 4 x 4self._block(features_g*16, features_g*8, 4, 2, 1), # 8x8self._block(features_g*8, features_g*4, 4, 2, 1), # 16x16self._block(features_g*4, features_g*2, 4, 2, 1), # 32x32nn.ConvTranspose2d(features_g*2, channels_img, kernel_size=4, stride=2, padding=1,),nn.Tanh(),)def _block(self, in_channels, out_channels, kernel_size, stride, padding):return nn.Sequential(nn.ConvTranspose2d(in_channels,out_channels,kernel_size,stride,padding,bias=False,),nn.BatchNorm2d(out_channels),nn.ReLU(),)def forward(self, x):return self.gen(x)def initialize_weights(model):for m in model.modules():if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)):nn.init.normal_(m.weight.data, 0.0, 0.02)def test():N, in_channels, H, W = 8, 3, 64, 64z_dim = 100x = torch.randn((N, in_channels, H, W))disc = Discriminator(in_channels, 8)initialize_weights(disc)assert disc(x).shape == (N, 1, 1, 1)gen = Generator(z_dim, in_channels, 8)initialize_weights(gen)z = torch.randn((N, z_dim, 1, 1))assert gen(z).shape == (N, in_channels, H, W)print("success")if __name__ == "__main__":test()训练使用的数据集:CelebA dataset (Images Only) 总共1.3GB的图片,使用方法,将其解压到当前目录
图片如下图所示:

train.py
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import Discriminator, Generator, initialize_weights# Hyperparameters etc.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
LEARNING_RATE = 2e-4 # could also use two lrs, one for gen and one for disc
BATCH_SIZE = 128
IMAGE_SIZE = 64
CHANNELS_IMG = 3 # 1 if MNIST dataset; 3 if celeb dataset
NOISE_DIM = 100
NUM_EPOCHS = 5
FEATURES_DISC = 64
FEATURES_GEN = 64transforms = transforms.Compose([transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),transforms.ToTensor(),transforms.Normalize([0.5 for _ in range(CHANNELS_IMG)], [0.5 for _ in range(CHANNELS_IMG)]),]
)# If you train on MNIST, remember to set channels_img to 1
# dataset = datasets.MNIST(
# root="dataset/", train=True, transform=transforms, download=True
# )# comment mnist above and uncomment below if train on CelebA# If you train on celeb dataset, remember to set channels_img to 3
dataset = datasets.ImageFolder(root="celeb_dataset", transform=transforms)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
gen = Generator(NOISE_DIM, CHANNELS_IMG, FEATURES_GEN).to(device)
disc = Discriminator(CHANNELS_IMG, FEATURES_DISC).to(device)
initialize_weights(gen)
initialize_weights(disc)opt_gen = optim.Adam(gen.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
opt_disc = optim.Adam(disc.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
criterion = nn.BCELoss()fixed_noise = torch.randn(32, NOISE_DIM, 1, 1).to(device)
writer_real = SummaryWriter(f"logs/real")
writer_fake = SummaryWriter(f"logs/fake")
step = 0gen.train()
disc.train()for epoch in range(NUM_EPOCHS):# Target labels not needed! <3 unsupervisedfor batch_idx, (real, _) in enumerate(dataloader):real = real.to(device)noise = torch.randn(BATCH_SIZE, NOISE_DIM, 1, 1).to(device)fake = gen(noise)### Train Discriminator: max log(D(x)) + log(1 - D(G(z)))disc_real = disc(real).reshape(-1)loss_disc_real = criterion(disc_real, torch.ones_like(disc_real))disc_fake = disc(fake.detach()).reshape(-1)loss_disc_fake = criterion(disc_fake, torch.zeros_like(disc_fake))loss_disc = (loss_disc_real + loss_disc_fake) / 2disc.zero_grad()loss_disc.backward()opt_disc.step()### Train Generator: min log(1 - D(G(z))) <-> max log(D(G(z))output = disc(fake).reshape(-1)loss_gen = criterion(output, torch.ones_like(output))gen.zero_grad()loss_gen.backward()opt_gen.step()# Print losses occasionally and print to tensorboardif batch_idx % 100 == 0:print(f"Epoch [{epoch}/{NUM_EPOCHS}] Batch {batch_idx}/{len(dataloader)} \Loss D: {loss_disc:.4f}, loss G: {loss_gen:.4f}")with torch.no_grad():fake = gen(fixed_noise)# take out (up to) 32 examplesimg_grid_real = torchvision.utils.make_grid(real[:32], normalize=True)img_grid_fake = torchvision.utils.make_grid(fake[:32], normalize=True)writer_real.add_image("Real", img_grid_real, global_step=step)writer_fake.add_image("Fake", img_grid_fake, global_step=step)step += 1
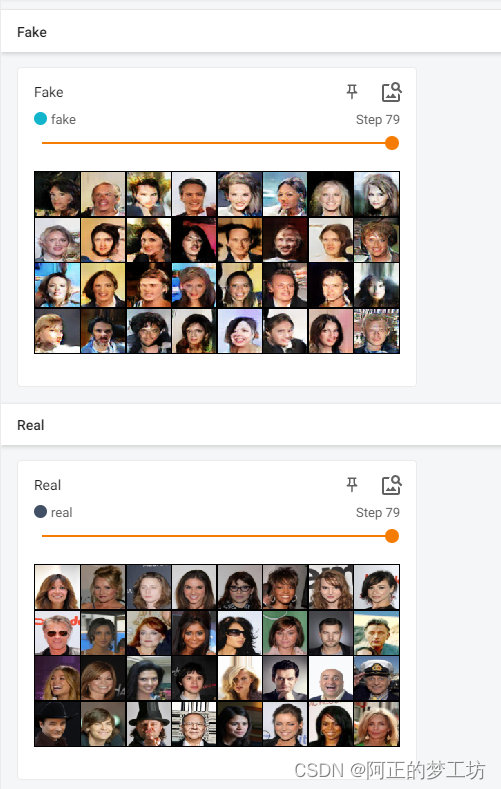
结果
训练5个epoch,部分结果如下:
Epoch [3/5] Batch 1500/1583 Loss D: 0.4996, loss G: 1.1738
Epoch [4/5] Batch 0/1583 Loss D: 0.4268, loss G: 1.6633
Epoch [4/5] Batch 100/1583 Loss D: 0.4841, loss G: 1.7475
Epoch [4/5] Batch 200/1583 Loss D: 0.5094, loss G: 1.2376
Epoch [4/5] Batch 300/1583 Loss D: 0.4376, loss G: 2.1271
Epoch [4/5] Batch 400/1583 Loss D: 0.4173, loss G: 1.4380
Epoch [4/5] Batch 500/1583 Loss D: 0.5213, loss G: 2.1665
Epoch [4/5] Batch 600/1583 Loss D: 0.5036, loss G: 2.1079
Epoch [4/5] Batch 700/1583 Loss D: 0.5158, loss G: 1.0579
Epoch [4/5] Batch 800/1583 Loss D: 0.5426, loss G: 1.9427
Epoch [4/5] Batch 900/1583 Loss D: 0.4721, loss G: 1.2659
Epoch [4/5] Batch 1000/1583 Loss D: 0.5662, loss G: 2.4537
Epoch [4/5] Batch 1100/1583 Loss D: 0.5604, loss G: 0.8978
Epoch [4/5] Batch 1200/1583 Loss D: 0.4085, loss G: 2.0747
Epoch [4/5] Batch 1300/1583 Loss D: 1.1894, loss G: 0.1825
Epoch [4/5] Batch 1400/1583 Loss D: 0.4518, loss G: 2.1509
Epoch [4/5] Batch 1500/1583 Loss D: 0.3814, loss G: 1.9391
使用
tensorboard --logdir=logs
打开tensorboard
参考
[1] DCGAN implementation from scratch
[2] https://arxiv.org/abs/1511.06434
相关文章:
PyTorch训练深度卷积生成对抗网络DCGAN
文章目录 DCGAN介绍代码结果参考 DCGAN介绍 将CNN和GAN结合起来,把监督学习和无监督学习结合起来。具体解释可以参见 深度卷积对抗生成网络(DCGAN) DCGAN的生成器结构: 图片来源:https://arxiv.org/abs/1511.06434 代码 model.py impor…...

Spring-4-掌握Spring事务传播机制
今日目标 能够掌握Spring事务配置 Spring事务管理 1 Spring事务简介【重点】 1.1 Spring事务作用 事务作用:在数据层保障一系列的数据库操作同成功同失败 Spring事务作用:在数据层或业务层保障一系列的数据库操作同成功同失败 1.2 案例分析Spring…...
[PyTorch][chapter 49][创建自己的数据集 1]
前言: 后面几章主要利用DataSet 创建自己的数据集,实现建模, 训练,迁移等功能。 目录: pokemon 数据集深度学习工程步骤 一 pokemon 数据集介绍 1.1 pokemon: 数据集地址: 百度网盘路径: https://pan.baidu.com/s/1…...
中间件(二)dubbo负载均衡介绍
一、负载均衡概述 支持轮询、随机、一致性hash和最小活跃数等。 1、轮询 ① sequences:内部的序列计数器 ② 服务器接口方法权重一样:(sequences1)%服务器的数量(决定调用)哪个服务器的服务。 ③ 服务器…...
springboot异步文件上传获取输入流提示找不到文件java.io.FileNotFoundException
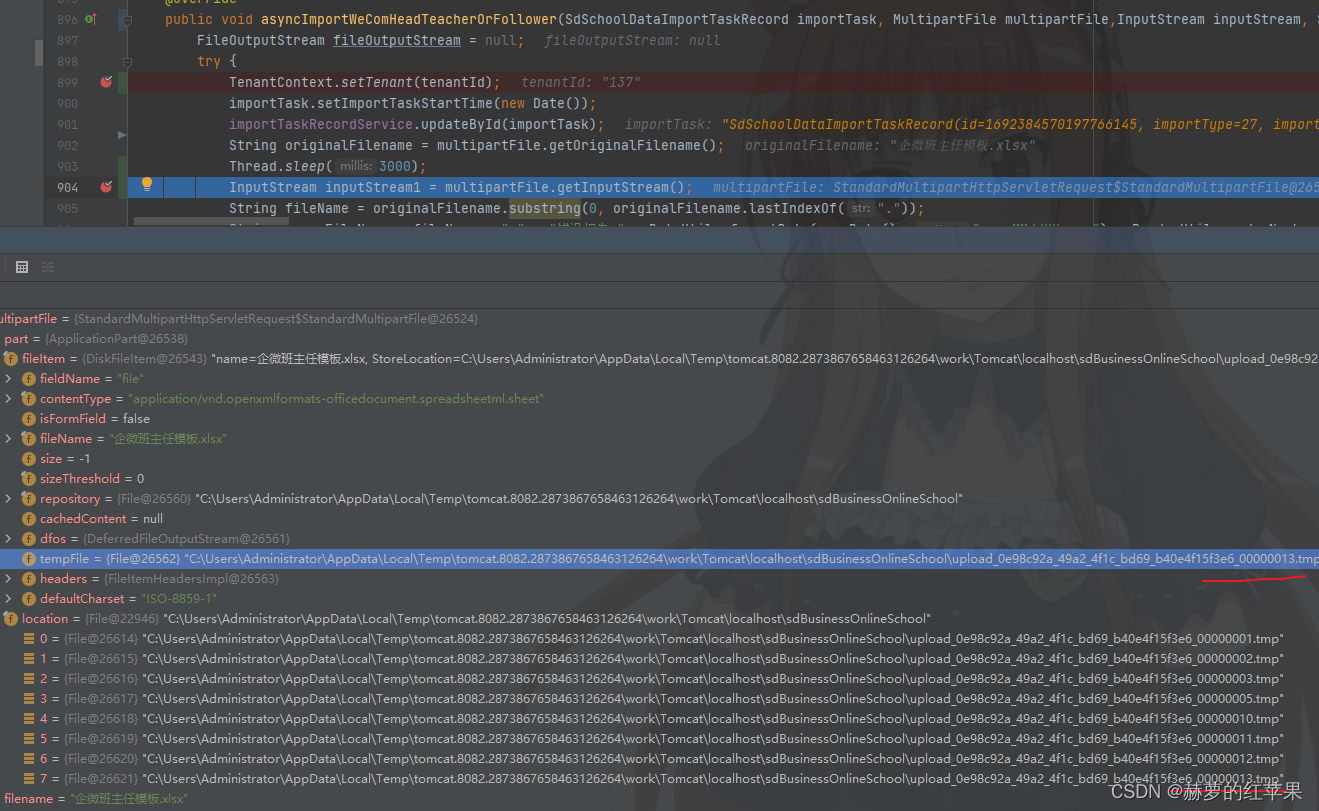
springboot上传文件,使用异步操作处理上传的文件数据,出现异常如下: 这个是在异步之后使用传过来的MultipartFile对象尝试调用getInputStream方法发生的异常。 java.io.FileNotFoundException: C:\Users\Administrator\AppData\Local\Temp\to…...

安装jenkins-cli
1、要在 Linux 操作系统上安装 jcli curl -L https://github.com/jenkins-zh/jenkins-cli/releases/latest/download/jcli-linux-amd64.tar.gz|tar xzv sudo mv jcli /usr/local/bin/ 在用户根目录下,增加 jcli 的配置文件: jcli config gen -ifalse …...

linux通过NC工具启动临时端口监听
1.安装nc工具 yum install nc -y2. 启动监听指定端口 #例如监听8080端口 nc -lk 8080#后台监听 nc -lk 8080 &3. 验证 #通过另外一台网络能通的机器,telnet 该机器ip 监听端口能通,并且能接手数据 telnet 192.xxx.xxx.xx 8080...

开源语音聊天软件Mumble
网友 大气 告诉我,Openblocks在国内还有个版本叫 码匠,更贴合国内软件开发的需求,如接入了国内常用的身份认证,接入了国内的数据库和云服务,也对小程序、企微 sdk 等场景做了适配。 在 https://majiang.co/docs/docke…...

JDK 1.6与JDK 1.8的区别
ArrayList使用默认的构造方式实例 jdk1.6默认初始值为10jdk1.8为0,第一次放入值才初始化,属于懒加载 Hashmap底层 jdk1.6与jdk1.8都是数组链表 jdk1.8是链表超过8时,自动转为红黑树 静态方式不同 jdk1.6是先初始化static后执行main方法。 jdk1.8是懒加…...

单片机实训报告
这周我们进行了单片机实训,一周中我们通过七个项目1:P1 口输入/输出 2:继电器控制 3 音频控制 4:子程序设计 5:字符碰头程序设计 6:外部中断 7: 急救车与交通信号灯,练习编写了子程…...

【编织时空四:探究顺序表与链表的数据之旅】
本章重点 链表的分类 带头双向循环链表接口实现 顺序表和链表的区别 缓存利用率参考存储体系结构 以及 局部原理性。 一、链表的分类 实际中链表的结构非常多样,以下情况组合起来就有8种链表结构: 1. 单向或者双向 2. 带头或者不带头 3. 循环或者非…...

PHP8的字符串操作1-PHP8知识详解
字符串是php中最重要的数据之一,字符串的操作在PHP编程占有重要的地位。在使用PHP语言开发web项目的过程中,为了实现某些功能,经常需要对某些字符串进行特殊的处理,比如字符串的格式化、字符串的连接与分割、字符串的比较、查找等…...
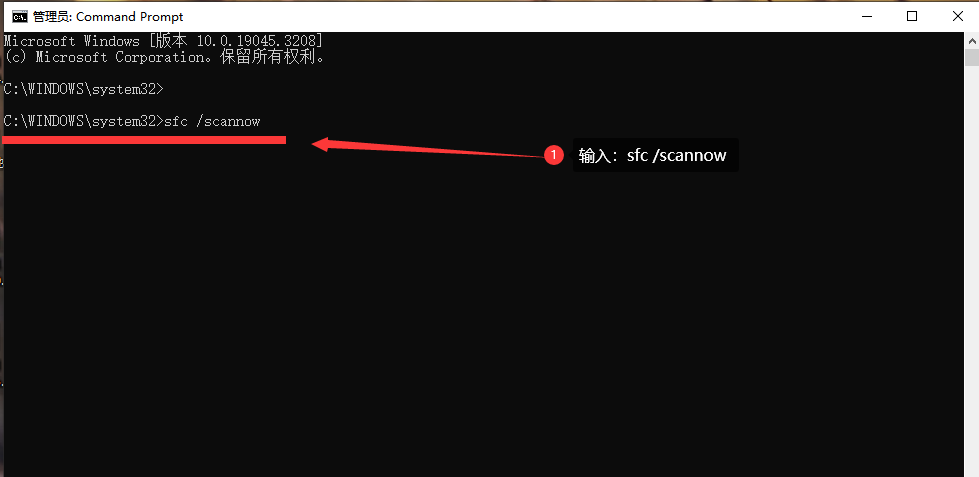
电脑提示msvcp140.dll丢失的解决方法,dll组件怎么处理
Windows系统有时在打开游戏或者软件时, 系统会弹窗提示缺少“msvcp140.dll.dll”文件 或者类似错误提示怎么办? 错误背景: msvcp140.dll是Microsoft Visual C Redistributable Package中的一个动态链接库文件,它在运行软件时提…...

stable diffusion基础
整合包下载:秋叶大佬 【AI绘画8月最新】Stable Diffusion整合包v4.2发布! 参照:基础04】目前全网最贴心的Lora基础知识教程! VAE 作用:滤镜微调 VAE下载地址:C站(https://civitai.com/models…...

Greiner–Hormann裁剪算法深度探索:C++实现与应用案例
介绍 在计算几何中,裁剪是一个核心的主题。特别是,多边形裁剪已经被广泛地应用于计算机图形学,地理信息系统和许多其他领域。Greiner-Hormann裁剪算法是其中之一,提供了一个高效的方式来计算两个多边形的交集、并集等。在本文中&…...

Automatically Correcting Large Language Models
本文是大模型相关领域的系列文章,针对《Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies》的翻译。 自动更正大型语言模型:综述各种自我更正策略的前景 摘要1 引言2 自动反馈校正LLM的…...
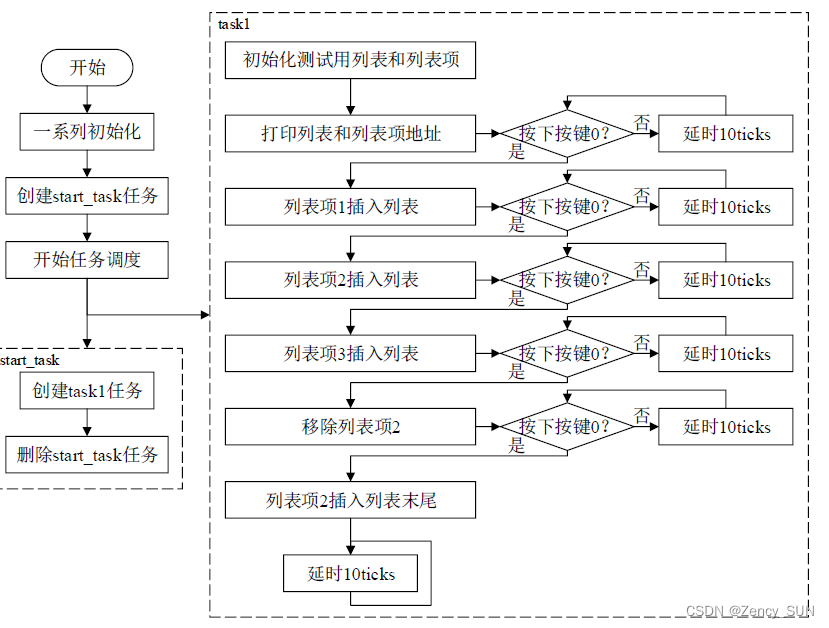
【学习FreeRTOS】第8章——FreeRTOS列表和列表项
1.列表和列表项的简介 列表是 FreeRTOS 中的一个数据结构,概念上和链表有点类似,列表被用来跟踪 FreeRTOS中的任务。列表项就是存放在列表中的项目。 列表相当于链表,列表项相当于节点,FreeRTOS 中的列表是一个双向环形链表列表的…...

分布式图数据库 NebulaGraph v3.6.0 正式发布,强化全文索引能力
本次 v3.6.0 版本,主要强化全文索引能力,以及优化部分场景下的 MATCH 性能。 强化 强化增强全文索引功能,具体 pr 参见:#5567、#5575、#5577、#5580、#5584、#5587 优化 支持使用 MATCH 子句检索 VID 或属性索引时使用变量&am…...
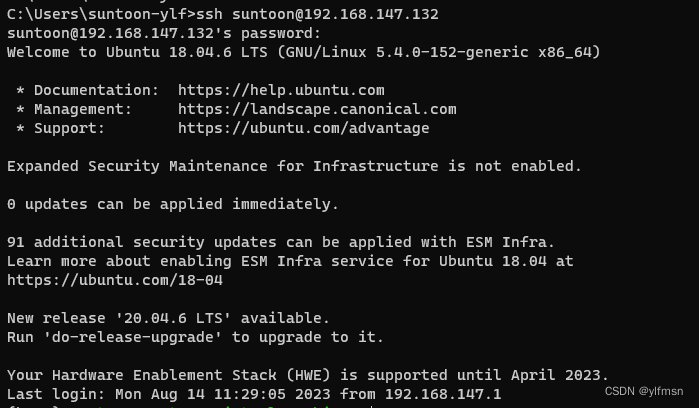
在 ubuntu 18.04 上使用源码升级 OpenSSH_7.6p1到 OpenSSH_9.3p1
1、检查系统已安装的当前 SSH 版本 使用命令 ssh -V 查看当前 ssh 版本,输出如下: OpenSSH_7.6p1 Ubuntu-4ubuntu0.7, OpenSSL 1.0.2n 7 Dec 20172、安装依赖,依次执行以下命令 sudo apt update sudo apt install build-essential zlib1g…...

python中可以处理word文档的模块:docx模块
前言 大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 话不多说,直接开搞,如果有什么疑惑/资料需要的可以点击文章末尾名片领取源码 一.docx模块 Python可以利用python-docx模块处理word文档,处理方式是面向对象的。 也就是说python-docx模块…...

我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案 作为一名频繁使用Claude Code进行代码生成和审查的个人…...

无线渗透测试框架Airecon:自动化工具链整合与实战应用
1. 项目概述与核心价值最近在整理自己的渗透测试工具箱时,又翻出了pikpikcu/airecon这个老伙计。说实话,在无线安全评估这个细分领域里,它可能不是名气最响的那个,但绝对是我个人在内部网络渗透和红队演练中最顺手、最高效的“组合…...

深度集成AI的VSCode扩展:从代码生成到调试的全流程实战指南
1. 项目概述:一个为VSCode注入AI灵魂的扩展如果你和我一样,每天有超过8小时的时间是在Visual Studio Code(VSCode)里度过的,那么你一定对提升编码效率有着近乎偏执的追求。从代码补全、语法高亮到调试、版本控制&#…...
)
用51单片机和HC-SR04超声波模块DIY一个倒车雷达(附完整代码和立创EDA原理图)
51单片机与HC-SR04超声波模块实战:打造高精度倒车雷达系统 在汽车电子和智能硬件领域,倒车雷达作为基础安全装置,其DIY实现不仅能帮助理解超声波测距原理,更是掌握嵌入式系统开发的绝佳实践。本文将手把手教你使用经典的STC89C52单…...

蜘蛛池技术解析:网站收录提速的关键工具与运营策略
在搜索引擎优化领域,蜘蛛池是助力网站收录提速的重要辅助工具,尤其适配新站、低权重站或海量内容站,能有效破解收录慢、收录少、深层页面难抓取等痛点。本文从技术原理、核心价值、搭建要点及合规运营策略四方面,全面解析蜘蛛池的…...

量子误差缓解:Bhattacharyya距离与保形预测的应用
1. 量子噪声与误差缓解的核心挑战在当前的NISQ(Noisy Intermediate-Scale Quantum)时代,量子计算机面临的最大障碍就是噪声和误差问题。这些噪声主要来源于量子比特与环境之间的相互作用、门操作的不完美性以及测量误差等。以一个典型的超导量…...

MCP2221+Blinka+Jupyter:桌面Python直连I2C传感器实时可视化
1. 项目概述:当桌面电脑“学会”与传感器对话作为一名在嵌入式开发和数据可视化领域摸爬滚打了十多年的老手,我见过太多为了读取一个温度传感器的数据,而不得不先折腾Arduino固件、再折腾串口通信、最后还要自己写个上位机软件的复杂流程。整…...

影刀RPA跨境店群运营架构:基于Python的高并发环境隔离与自动化调度系统设计实战
关于我一个曾经死磕底层算法、痴迷于压榨软硬件性能的资深架构师,最后跑去给跨境工作室写店群底层自动化调度系统这件事。 很多以前在技术圈里混的同行,或者是看着我一路从后端重构做到 ImageTransPro 图像处理软件 5.0.3 这种复杂版本迭代的极客朋友们…...

RML2016.10a数据集读取避坑指南:用Python pickle解决‘latin-1’编码报错
RML2016.10a数据集读取避坑指南:用Python pickle解决‘latin-1’编码报错 当你第一次拿到RML2016.10a数据集,满心欢喜准备开始实验时,一个简单的.pkl文件读取操作却可能让你陷入编码错误的泥潭。UnicodeDecodeError: utf-8 codec cant decode…...

基于CCS811与CircuitPython的可穿戴呼吸监测面具制作全解析
1. 项目概述与核心价值 几年前,当我第一次接触到可穿戴健康设备时,就被其潜力深深吸引。但市面上的产品要么是封闭的“黑盒”,数据不透明;要么价格高昂,难以进行个性化定制。我一直想,能不能自己动手做一个…...