Elasticsearch:如何在 Ubuntu 上安装多个节点的 Elasticsearch 集群 - 8.x

Elasticsearch 是一个强大且可扩展的搜索和分析引擎,可用于索引和搜索大量数据。 Elasticsearch 通常用于集群环境中,以提高性能、提供高可用性并实现数据冗余。 在本文中,我们将讨论如何在 Ubuntu 20.04 上安装和配置具有多节点集群的 Elasticsearch 版本 8。

得益于 Elasticsearch 版本 8 的功能,现在部署 Elasticsearch 集群变得更加容易。 你可以在此处查看有关安装的官方文档。 在本文中,我们将使用 ubuntu deb 安装。 在我之前的文章 “Elasticsearch: 使用 Debian 安装包来安装 Elasticsearch 8.x” 我详述了如何使用 Debian 安装包来安装具有一个节点的集群。在今天的文章中,我来详细介绍如何在 Ubuntu 系统上安装具有三个节点的 Elasticsearch 集群。我的系统配置如下:
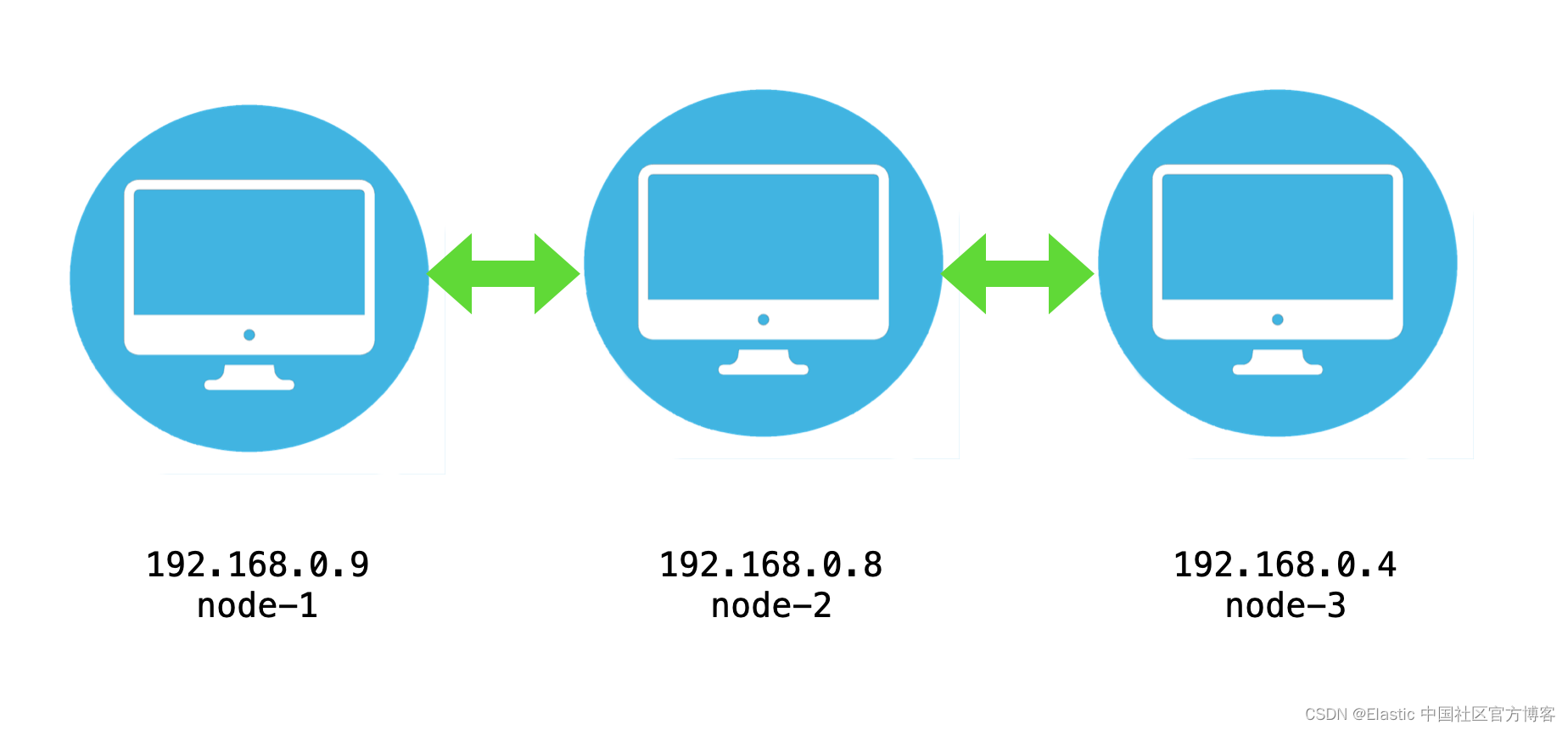
如上所示,我们在 Ubuntu 系统上的 IP 地址如上所示。我们可以使用如下的命令来获得当前的系统的 IP 地址:
ifconfig | grep "inet " | grep -Fv 127.0.0.1 | awk '{print $2}'$ ifconfig | grep "inet " | grep -Fv 127.0.0.1 | awk '{print $2}'
192.168.0.9如果你曾经在自己的电脑上安装过 Elasticsearch,你可以使用如下的命令把之前的安装全部删除:
remove.sh
sudo apt remove elasticsearch
sudo apt purge elasticsearch
sudo rm -rf /var/lib/elasticsearchchmod a+x remove.sh
sudo ./remove.sh一旦之前的 Elasticsearch 都被成功地删除了,那么我们就可开始下面的安装工作了。安装 Elasticsearch 集群的简单步骤如下:
- 在 node-1 上安装 elasticsearch
- 更新 node-1 的 elasticsearch.yml
- 启动 elasticsearch 节点1
- 检查节点健康状况
- 在 node-2 上安装 elasticsearch
- 使用节点 1 中的令牌在节点 2 上运行 “elasticsearch-reconfigure-node --enrollment-token <token-here>” 命令
- 更新 node-2 的 elasticsearch.yml
- 启动 elasticsearch 节点2
- 检查节点数 GET _cat/nodes
- 在相同或不同节点上安装 Kibana
- 为 Kibana 创建注册令牌 elasticsearch-create-enrollment-token -s kibana
- 启动Kibana
安装
安装 node-1
参照官方文档,我们创建如下的安装脚本,以便在各个节点上运行:
install.sh
#!/bin/bashwget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo gpg --dearmor -o /usr/share/keyrings/elasticsearch-keyring.gpgapt-get install apt-transport-httpsecho "deb [signed-by=/usr/share/keyrings/elasticsearch-keyring.gpg] https://artifacts.elastic.co/packages/8.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-8.x.listsudo apt-get update && sudo apt-get install elasticsearch我们使用如下的命令来进行安装:
chmod a+x install.sh
sudo ./install.sh 
在当前的 terminal 下,我们可以看到如下的输出:

安装完成后,你需要创建一个数据目录并将其所有者更改为 Elasticsearch 用户。 接下来,使用以下设置更新 Elasticsearch 配置文件:
/etc/elasticsearch/elasticsearch.yml
cluster.name: elk-logs
node.name: node-1
network.host: 192.168.0.9
discovery.seed_hosts: ["192.168.0.9"]
cluster.initial_master_nodes: ["192.168.0.9"]
重新加载 systemctl 守护进程,启用 Elasticsearch 服务,并通过运行以下命令启动 Elasticsearch 服务:
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearchsystemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch
Created symlink /etc/systemd/system/multi-user.target.wants/elasticsearch.service → /lib/systemd/system/elasticsearch.service.你可以使用以下命令检查 Elasticsearch 服务的状态:
systemctl status elasticsearch
你也可以使用如下的命令来进行查看:
service elasticsearch status如果需要的话,我们可以使用如下的命令来重置内置 elastic 用户的密码,请运行以下命令:
/usr/share/elasticsearch/bin/elasticsearch-reset-password -i -u elastic比你可以使用以下命令检查 Elasticsearch 集群健康状况和节点信息:
curl -k -u elastic:<password> "https://localhost:9200/_cluster/health?pretty"
curl -k -u elastic:<password> "https://localhost:9200/_cat/nodes?v"root@ubuntu2204:~# curl -k -u elastic:password "https://localhost:9200/_cluster/health?pretty"
{"cluster_name" : "elk-logs","status" : "green","timed_out" : false,"number_of_nodes" : 1,"number_of_data_nodes" : 1,"active_primary_shards" : 1,"active_shards" : 1,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}
root@ubuntu2204:~# curl -k -u elastic:password "https://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
127.0.0.1 10 98 7 0.41 0.34 0.26 cdfhilmrstw * ubuntu2204从上面的输出中,我们可以看到有一个节点的集群已经运行起来了。
你需要创建一个注册令牌,以便稍后在其他节点中使用以加入现有的 Elasticsearch 集群。 运行以下命令在 Node-1 上创建注册令牌:
/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node我们可以通过如下的命令来查看 Elasticsearch 的输出日志:
journalctl -u elasticsearch
如果你觉得历史日志太长不便于查看,你可以使用如下的命令来清除之前的日志:
sudo journalctl --rotate
sudo journalctl --vacuum-time=1s安装 node-2
要在 node-2 上安装 Elasticsearch,我们仿照上面的步骤创建 install.sh,并在它们的机器上运行。
sudo ./install.sh不要启动 Elasticsearch。 首先,你需要运行以下命令。 以下命令将修改证书、密钥库和 elasticsearch.yml。

安装后,你可以通过运行以下命令将 Elasticsearch 服务配置为使用你在 node-1 中创建的注册令牌。我们在 node-1 的 terminal 中打入如下的命令:
/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s noderoot@ubuntu2204:~# /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node
eyJ2ZXIiOiI4LjkuMCIsImFkciI6WyIxOTIuMTY4LjAuOTo5MjAwIl0sImZnciI6IjQ5ODRmZDM0ZGJjMTkyNGZjMGI4YmZlZjM4ZTg3NjdjNmUxMzFmNWIxYjAxZGE0MDc4MzI2N2NlODFiMjI5NzQiLCJrZXkiOiI3eGRwLVlrQkhGcVEtMlRPMU1lYTp6dk9rbjEtSFQ1dVEzR3R6MGd4bW5nIn0=我们在 node-2 的 terminal 中打入如下的命令:
/usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token <token-here>root@ubuntu2004:~# /usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token eyJ2ZXIiOiI4LjkuMCIsImFkciI6WyIxOTIuMTY4LjAuOTo5MjAwIl0sImZnciI6IjQ5ODRmZDM0ZGJjMTkyNGZjMGI4YmZlZjM4ZTg3NjdjNmUxMzFmNWIxYjAxZGE0MDc4MzI2N2NlODFiMjI5NzQiLCJrZXkiOiI3eGRwLVlrQkhGcVEtMlRPMU1lYTp6dk9rbjEtSFQ1dVEzR3R6MGd4bW5nIn0=This node will be reconfigured to join an existing cluster, using the enrollment token that you provided.
This operation will overwrite the existing configuration. Specifically: - Security auto configuration will be removed from elasticsearch.yml- The [certs] config directory will be removed- Security auto configuration related secure settings will be removed from the elasticsearch.keystore
Do you want to continue with the reconfiguration process [y/N]y将你在 node-1 上生成的注册令牌粘贴到 上面的命令中, 并运行命令。 该命令将修改 node-2 中的证书和 elasticsearch.yml
我们同时对 elasticsearch.yml 文件进行修改:
cluster.name: elk-logs
node.name: node-2
network.host: 192.168.0.8重新加载 systemctl 守护进程,启用 Elasticsearch 服务,并通过运行以下命令启动 Elasticsearch 服务:
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch我们通过如下的命令来查看 elasticsearch 服务的状态:
service elasticsearch status
同样地,我们使用如下的命令来查看集群的节点:
curl -k -u elastic:<password> "https://localhost:9200/_cat/nodes?v"curl -k -u elastic:-K2s_i2nsG62iphpNOvY "https://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.0.8 20 98 9 0.09 0.16 0.17 cdfhilmrstw - node-2
192.168.0.9 12 98 5 0.10 0.17 0.18 cdfhilmrstw * node-1请注意在上面,我们使用的密码和之前的 node-1 中的不同,这是因为我使用了如下的命令修改了 elastic 超级用户的密码:
oot@ubuntu2004:/etc/elasticsearch# /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic
This tool will reset the password of the [elastic] user to an autogenerated value.
The password will be printed in the console.
Please confirm that you would like to continue [y/N]yPassword for the [elastic] user successfully reset.
New value: -K2s_i2nsG62iphpNOvY从上面的 node 显示结果中,我们可以看出来,已经有两个节点组成了集群。
我们按照上面的步骤,在 node-3 上进行安装。安装完毕后,我们使用同样的命令来进行查看:
root@liuxgu:/etc/elasticsearch# curl -k -u elastic:-K2s_i2nsG62iphpNOvY "https://localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.0.8 17 98 7 0.19 0.21 0.18 cdfhilmrstw - node-2
192.168.0.4 4 99 3 0.50 0.53 0.32 cdfhilmrstw - node-3
192.168.0.9 15 98 5 0.11 0.19 0.18 cdfhilmrstw * node-1从上面的显示中,我们可以看到有三个节点的 Elasticsearch 已经安装完毕。
重新配置各个节点
添加所有节点后,删除 node-1 的 Elasticsearch 配置文件中的 “cluster.initial_master_nodes” 设置。 然后,使用主节点的 IP 或主机名将 “discovery.seed_hosts”设置添加到 node-1 的 Elasticsearch 配置文件中。
比如:
删除节点 1 上的 elasticsearch.yml 文件中的以下设置:
cluster.initial_master_nodes: ["..."]然后,将以下设置添加到 node-1 上的 elasticsearch.yml 文件中:
discovery.seed_hosts: ["192.168.0.9:9300", "192.168.0.8:9300", "192.168.0.4:9300"]请注意,seed_hosts 列表中的 IP 地址和端口号应与集群中符合主节点资格的节点的 IP 地址和端口号相匹配。
首次成功形成集群后,从每个节点的配置中删除 cluster.initial_master_nodes 设置。 重新启动集群或向现有集群添加新节点时不应使用此设置。
接下来,更新所有节点上的 elasticsearch.yml 文件中的 discovery.seed_hosts 设置,以包含集群中所有节点(包括该文件所在节点)的 IP 地址和端口号。
最后,创建一个示例 elasticsearch.yml 文件,其中包含集群所需的配置。 此文件应包含 cluster.name、path.data 和 path.logs 设置,以及任何其他必要的设置,例如安全和传输设置。
cluster.name: elk-logsxpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:enabled: truekeystore.path: certs/http.p12
xpack.security.transport.ssl:enabled: trueverification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12discovery.seed_hosts: ["192.168.0.9:9300", "192.168.0.8:9300", "192.168.0.4:9300"]
http.host: 0.0.0.0
transport.host: 0.0.0.0不要尝试将 elasticsearch.yml 复制并粘贴到此处,因为它不起作用。 证书和密钥库需要在节点之间匹配:)。
检查 Elasticsearch 安装的操作系统级别设置也很重要。 Elasticsearch 文档提供了有关此主题的指导。
如果需要指定 node.role,可以更新 elasticsearch.yml 文件并重新启动 Elasticsearch。 node.roles 设置可用于指定节点的角色,例如数据节点或主节点。 Elasticsearch 文档提供了有关此主题的更多信息。
一旦 Elasticsearch 集群启动并运行,就可以安装并配置 Kibana 以连接到集群。 这涉及使用 elasticsearch-create-enrollment-token 命令在其中一个节点上为 Kibana 创建注册令牌,然后使用注册令牌在 Kibana 服务器上运行 kibana-setup 命令。 最后就可以启动Kibana服务了。
如果安装过程中出现任何问题,可能需要完全删除 Elasticsearch 并从头开始。 Elasticsearch 文档提供了在各种操作系统(包括基于 Debian 的系统)上删除 Elasticsearch 的说明。
安装 Kibana
我们将在 node-1 机器上安装 Kibana。我们运行如下的命令:
sudo apt remove --purge kibana接下来,我们可以运行以下命令来安装 Kibana:
sudo apt install kibana安装后,我们需要在其中一个节点上为 Kibana 创建注册令牌。 为此,请运行以下命令:
sudo /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibanaparallels@ubuntu2204:~$ sudo /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
[sudo] password for parallels:
eyJ2ZXIiOiI4LjkuMCIsImFkciI6WyIxOTIuMTY4LjAuOTo5MjAwIl0sImZnciI6Ijg2NWViYmRmMmQyNDBiMzJjMzI3NDI5MjBmZDBmOGVkMmJlZWZiODlkNzliM2QwODAyYWEwZmNlOGVlZjQ4ZjUiLCJrZXkiOiJmX0MxLVlrQlBZcnJLUkJJMWNPQjpYTzAwN081b1FES1AtWmdNWWkxXzhBIn0=
接下来,我们需要在安装的节点上运行以下命令,以使用注册令牌配置 Kibana:
sudo /usr/share/kibana/bin/kibana-setup --enrollment-token <enrollment-token>parallels@ubuntu2204:~$ sudo /usr/share/kibana/bin/kibana-setup --enrollment-token eyJ2ZXIiOiI4LjkuMCIsImFkciI6WyIxOTIuMTY4LjAuOTo5MjAwIl0sImZnciI6Ijg2NWViYmRmMmQyNDBiMzJjMzI3NDI5MjBmZDBmOGVkMmJlZWZiODlkNzliM2QwODAyYWEwZmNlOGVlZjQ4ZjUiLCJrZXkiOiJmX0MxLVlrQlBZcnJLUkJJMWNPQjpYTzAwN081b1FES1AtWmdNWWkxXzhBIn0=✔ Kibana configured successfully.To start Kibana run:bin/kibana将 <enrollment-token> 替换为上一步中生成的注册令牌。
最后,我们可以使用以下命令在节点上启动 Kibana 服务:
sudo systemctl start kibana这是 kibana.yml 的示例:
server.host: 0.0.0.0
elasticsearch.hosts: ['https://192.168.0.9:9200']
logging.appenders.file.type: file
logging.appenders.file.fileName: /var/log/kibana/kibana.log
logging.appenders.file.layout.type: json
logging.root.appenders: [default, file]
pid.file: /run/kibana/kibana.pid
elasticsearch.serviceAccountToken: long-token
elasticsearch.ssl.certificateAuthorities: [/var/lib/kibana/ca_1692111671076.crt]
xpack.fleet.outputs: [{id: fleet-default-output, name: default, is_default: true, is_default_monitoring: true, type: elasticsearch, hosts: ['https://192.168.0.9:9200'], ca_trusted_fingerprint: 865ebbdf2d240b32c32742920fd0f8ed2beefb89d79b3d0802aa0fce8eef48f5}]我们可以在该集群的浏览器中打开 Kibana:


这样我们的 Kibana 的安装已经完成了。
相关文章:
Elasticsearch:如何在 Ubuntu 上安装多个节点的 Elasticsearch 集群 - 8.x
Elasticsearch 是一个强大且可扩展的搜索和分析引擎,可用于索引和搜索大量数据。 Elasticsearch 通常用于集群环境中,以提高性能、提供高可用性并实现数据冗余。 在本文中,我们将讨论如何在 Ubuntu 20.04 上安装和配置具有多节点集群的 Elast…...
记录win 7旗舰版 “VMware Alias Manager and Ticket Service‘(VGAuhService)启动失败。
记录win 7旗舰版 "VMware Alias Manager and Ticket Service’(VGAuhService)启动失败。 描述如图 https://learn.microsoft.com/zh-CN/cpp/windows/latest-supported-vc-redist?viewmsvc-140#visual-studio-2015-2017-2019-and-2022 安装对应版本的VC 库就可以解决问…...
git 开发环境配置
系统:Mac OS 1、下载git,官网已经推荐使用命令下载。 /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh) 2、验证git是否安装成功 git --version 3、配置本地git全局变量 git config --global user.n…...
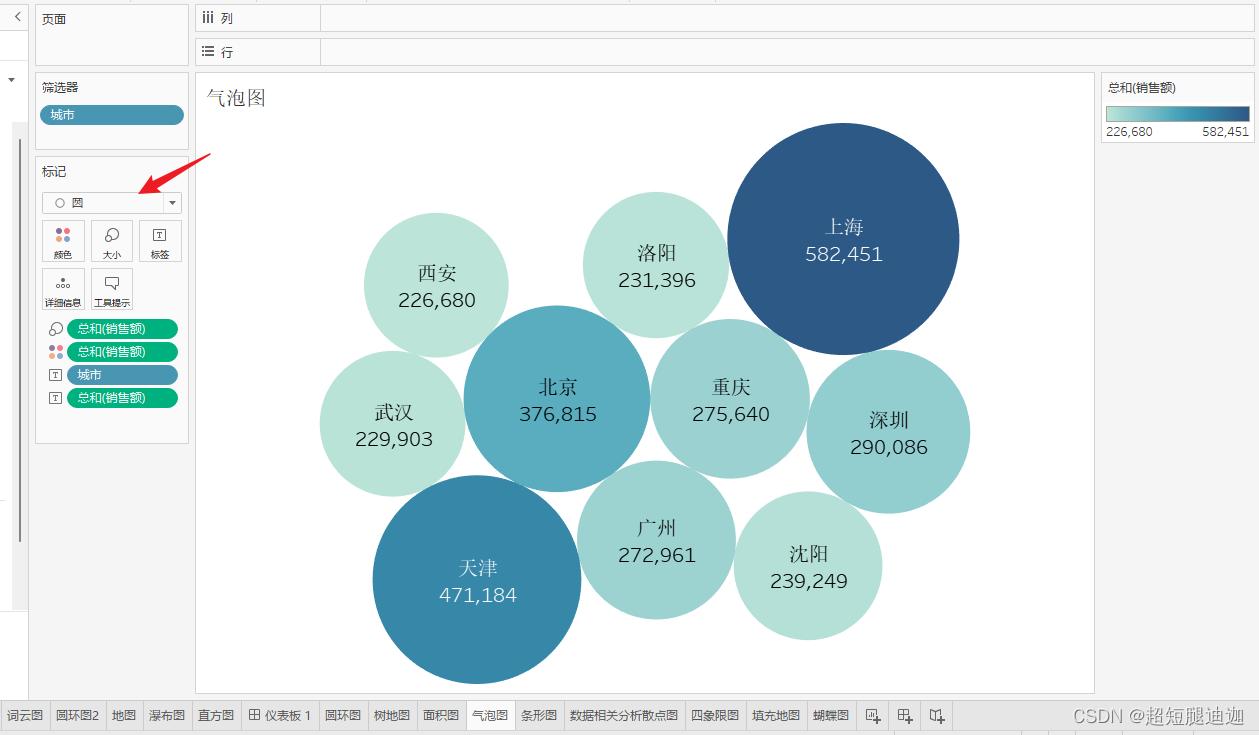
Tableau画图
目录 蝴蝶图 四象图 排序图 盒型图/散点图 圆环图 火柴图 直方图 瀑布图 地理图 面积图 树地图 面积图 条形图 词云图 双轴图 填充地图 tableau2023.2 须知 蝴蝶图 拉好数据之后 创建新字段正负销售额,并拖入第一个颜色标记卡 四象图 智能推荐 散…...
nginx上web服务的基本安全优化、服务性能优化、访问日志优化、目录资源优化和防盗链配置简介
一.基本安全优化 1.隐藏nginx软件版本信息 2.更改源码来隐藏软件名和版本 (1)修改第一个文件(核心头文件),在nginx安装目录下找到这个文件并修改 (2)第二个文件 (3)…...

himall3.0商城源码
目录 1 himall3.0商城源码 1.1 /// 获取待评价订单数量 1.2 /// 保存支付订单信息,生成支付订单 1.3 /// 取最近time分钟内的满足打印的订单数据 himall3.0商城源码 /// <summary>...

【LeetCode75】第二十九题 删除链表的中间节点
目录 题目: 示例; 分析: 代码: 题目: 示例; 分析: 给我们一个链表,让我们把链表中间的节点删了。 那么最直观最基础的办法是遍历两边链表,第一遍拿到链表长度,第二次把链表中间节点删了。 这个暴力做法我没事过…...

Floyd(多源汇最短路)
Floyd求最短路 给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环,边权可能为负数。 再给定 k 个询问,每个询问包含两个整数 x 和 y,表示查询从点 x 到点 y 的最短距离,如果路径不存在,则输出 impo…...
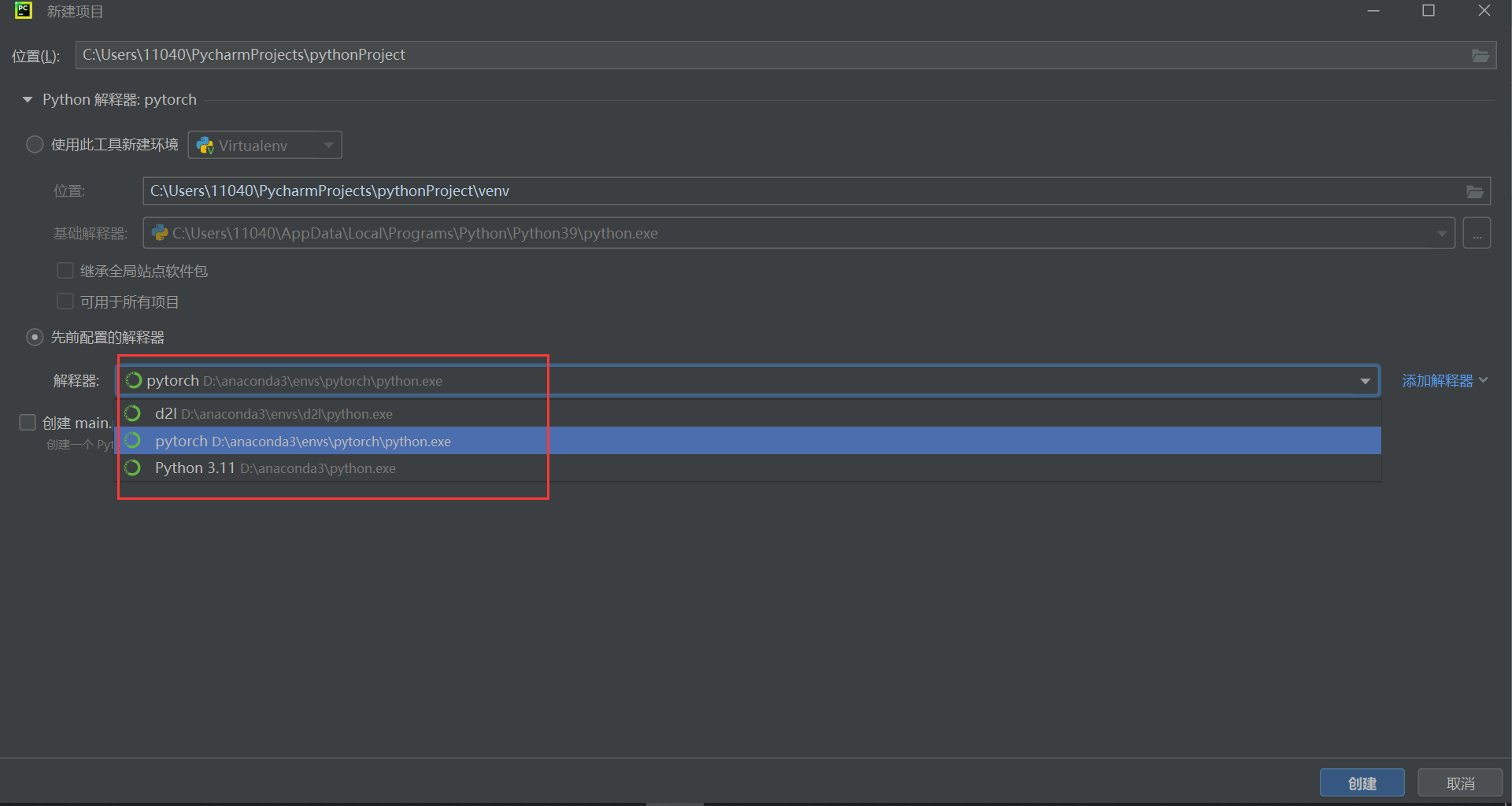
Pycharm找不到Conda可执行文件路径(Pycharm无法导入Anaconda已有环境)
在使用Pycharm时发现无法导入Anaconda创建好的环境,会出现找不到Conda可执行文件路径的问题。 解决 在输入框内输入D:\anaconda3\Scripts\conda.exe,点击加载环境。 注意前面目录是自己Anaconda的安装位置,之后就可以找到Anaconda的现有环…...

国产之光:讯飞星火最新大模型V2.0
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的…...
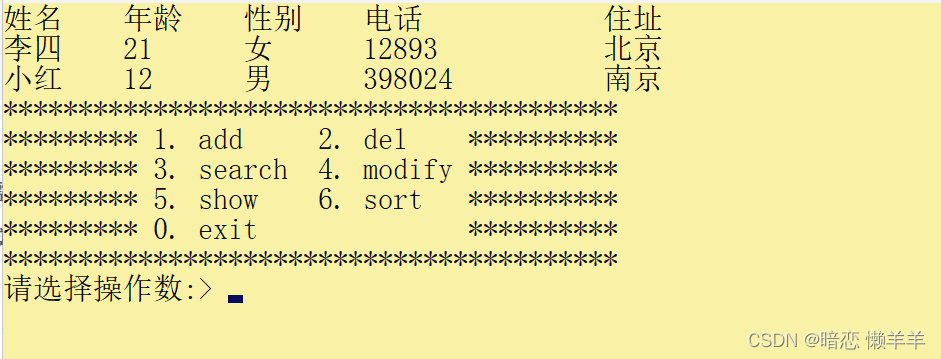
通讯录实现【C语言】
目录 前言 一、整体逻辑分析 二、实现步骤 1、创建菜单和多次操作问题 2、创建通讯录 3、初始化通讯录 4、添加联系人 5、显示联系人 6、删除指定联系人 7、查找指定联系人 8、修改联系人信息 9、排序联系人信息 三、全部源码 前言 我们上期已经详细的介绍了自定…...

pcl欧式聚类
欧式聚类实现方法大致是: 1、找到空间中某点 p 1 p_1 p1,用KD-Tree找到离他最近的n个点,判断这n个点到 p 1 p_1 p1的距离。将距离小于阈值r的点 p 2 、 p 3 、 p 4 p_2、p_3、p_4 p2、p3、p4…放在类Q里 2、在 Q ( p 1 ) Q(p_1…...
macOS Ventura 13.5.1(22G90)发布(附黑/白苹果系统镜像地址)
系统镜像下载:百度:黑果魏叔 系统介绍 黑果魏叔 8 月 18 日消息,苹果今日向 Mac 电脑用户推送了 macOS 13.5.1 更新(内部版本号:22G90),本次更新距离上次发布隔了 24 天。 本次更新重点修复了…...

分布式监控平台——Zabbix
市场上常用的监控软件: 传统运维:zabbix、 Nagios 一、zabbix概述 作为一个运维,需要会使用监控系统查看服务器状态以及网站流量指标,利用监控系统的数据去了解上线发布的结果,和网站的健康状态。 利用一个优秀的监…...
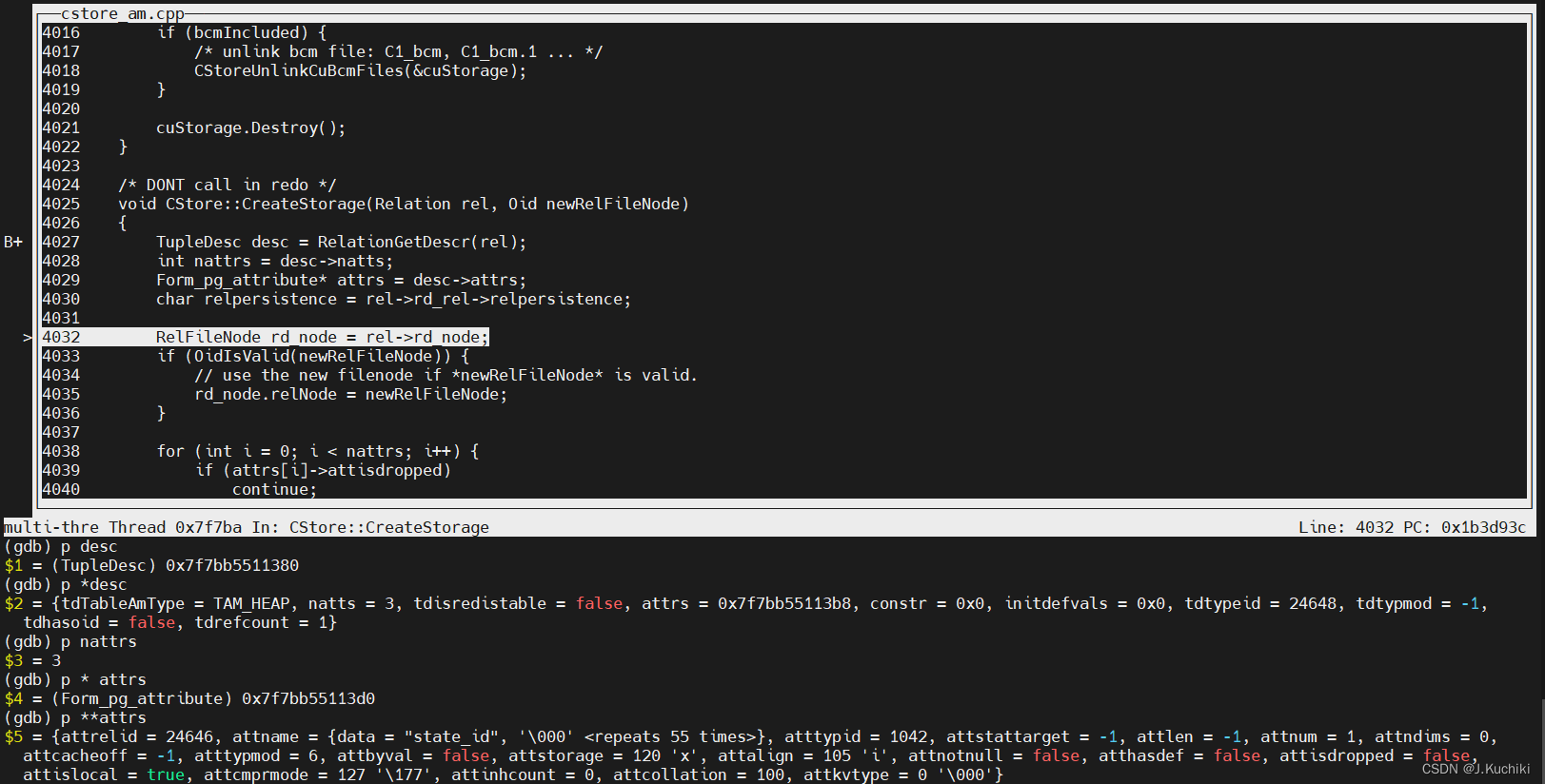
【OpenGauss源码学习 —— 列存储(创建表)】
列存储 什么是列存储?语法实现语法格式参数说明示例源码分析(创建表)语法层(Gram.y)子模块(utility.cpp) 总结 声明:本文的部分内容参考了他人的文章。在编写过程中,我们…...
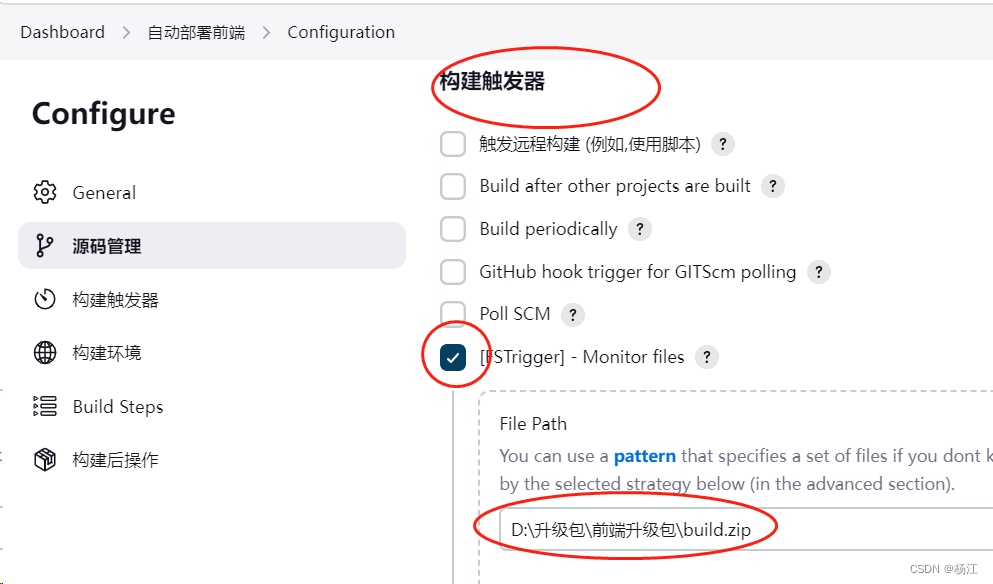
Jenkins 监控dist.zip文件内容发生变化 触发自动部署
为Jenkins添加plugin http://xx:xx/manage 创建一个任务 构建触发器 每3分钟扫描一次,发现指定文件build.zip文件的MD5发生变化后 触发任务...
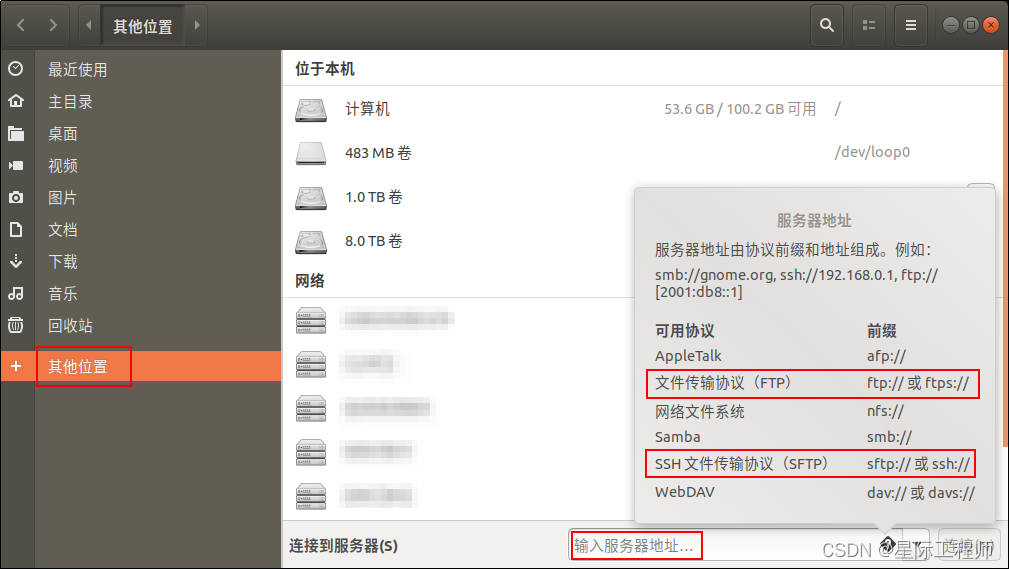
Linux系列讲解 —— FTP协议的应用
简单介绍一下FTP文件传输协议在linux系统中的应用。 目录 0. 基本概念1. FTP Server1.1 安装FTP Server1.2 FTP Server开启和关闭1.3 查看FTP Server是否开启1.4 FTP服务器配置 2. FTP Client2.1 lftp2.2 ftp2.3 sftp2.4 文件资源管理器集成的ftp和sftp 3. ftp常用命令 0. 基本…...

Rancher-RKE-install 部署k8s集群
一、为什么用Rancher-RKE-install 1.CNCF认证的k8s安装程序。 2.有中文文档。 二、安装步骤 1.下载Rancher-Rke的二进制包-下面是项目的地址 GitHub - rancher/rke: Rancher Kubernetes Engine (RKE), an extremely simple, lightning fast Kubernetes distrib…...

PHP8的正则表达式-PHP8知识详解
在网页程序的时候,经常会有查找符合某些复杂规则的字符串的需求。正则表达式就是描述这些规则的工具。 正则表达式是把文本或者字符串按照一定的规范或模型表示的方法,经常用于文本的匹配操作。 例如:我们在填写手机号码的时候,…...
SpringCloud实用篇7——深入elasticsearch
目录 1 数据聚合1.1 聚合的种类1.2 DSL实现聚合1.2.1 Bucket聚合语法1.2.2 聚合结果排序1.2.3 限定聚合范围1.2.4 Metric聚合语法1.2.5.小结 1.3 RestAPI实现聚合1.3.1 API语法1.3.2 业务需求1.3.3 业务实现 2 自动补全2.1 拼音分词器2.2 自定义分词器2.3 自动补全查询2.4 实现…...

AI智能体编排平台:从任务自动化到生态协作的架构与实践
1. 项目概述:一个面向AI编排与技能提升的生态协作平台最近在和一些做AI应用开发的朋友聊天,大家普遍有个痛点:现在AI工具和模型太多了,从大语言模型到图像生成,再到各种自动化脚本,每个都很强大,…...

SimulinkVeriStandLabVIEW协同开发——从模型编译到交互式仪表盘部署
1. 工具链协同开发的核心价值 在电力电子和工业控制领域,快速原型开发往往需要跨越建模、实时测试和人机交互三个关键环节。Simulink、VeriStand和LabVIEW组成的工具链,就像汽车制造的流水线——Simulink是设计图纸的工程师,VeriStand是组装车…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

Shell脚本加固实战:用shellguard提升脚本健壮性与安全性
1. 项目概述:一个为Shell脚本穿上“防弹衣”的守护者 在运维开发、自动化部署乃至日常的系统管理工作中,Shell脚本是我们最忠实、最高效的伙伴。从简单的日志清理到复杂的CI/CD流水线,Shell脚本无处不在。然而,脚本的安全性、健壮…...

基于Claude的AI招聘系统:从简历解析到智能评估全流程实践
1. 项目概述:当Claude成为你的招聘官最近在GitHub上看到一个挺有意思的项目,叫“hire-from-claude”。光看名字,你可能会觉得有点玄乎,难道是要让AI来面试和招聘人类?其实,这个项目的核心思路,是…...
)
从安迪·沃霍尔到AI画布:波普艺术三大视觉基因拆解,手把手复刻金罐头/玛丽莲肖像风格(含可复用prompt模板库)
更多请点击: https://intelliparadigm.com 第一章:从安迪沃霍尔到AI画布:波普艺术的范式迁移 安迪沃霍尔用丝网印刷将可口可乐瓶与玛丽莲梦露转化为大众文化的图腾,其核心并非复制,而是对**重复、去个性化与媒介即内容…...

PowerInfer:基于稀疏激活的LLM推理引擎,消费级GPU运行百亿大模型
1. 项目概述:当大模型推理遇见“热点激活”最近在折腾本地大模型部署的朋友,可能都绕不开一个核心痛点:显存。动辄几十GB的模型,配上动辄几十GB的推理显存需求,让消费级显卡(比如我们常见的24GB显存的RTX 4…...

基于Stellar的智能体经济安全与效率优化框架解析
1. 项目概述:一个面向智能体经济的安全与效率优化框架最近在探索智能体(Agent)应用生态时,我遇到了一个普遍存在的痛点:如何在一个去中心化、多智能体协作的网络中,既保证交互的安全与可信,又能…...

基于SpringBoot的公司固定资产盘点系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot框架的公司固定资产盘点系统以解决传统资产管理方式中存在的效率低下问题。当前企业固定资产管理工作普遍面临数据采集繁琐、…...
)
新手必看!CTFShow文件上传靶场通关保姆级教程(Web151-170全解析)
CTFShow文件上传靶场全解析:从入门到精通的实战指南 初识文件上传漏洞 文件上传功能几乎是每个Web应用都具备的基础模块,但恰恰是这个看似简单的功能,成为了无数安全漏洞的温床。在CTF竞赛中,文件上传类题目因其直观性和实战性&am…...