ElasticSearch基本使用
title: ElasticSearch基本使用
date: 2022-08-29 00:00:00
tags:
- ElasticSearch
- 基本使用
categories: - ElasticSearch
基本概念
随着ES版本的升级,文中有些概念可能已经废弃。
- 索引词(term)
- 一个能够被索引的精确值,区分大小写,可以通过term查询进行准确的搜索。
- 文本(text)
- 一段普通的非结构化文字,文本会被分析成一个个的索引词,存储在es的索引库中,这样才能进行搜索。
- 分析(analysis)
- 将文本转换为索引词的过程,分析的结果依赖于分词器。
- 分析机制用于进行全文文本的分词,以建立供搜索用的反向索引。
- 索引(index)
- 索引类似于关系数据库中的数据库,每个索引有不同字段,可以对应不同的类型;
- 每个索引都可以有一个或者多个主索引片,同时每个索引还可以有零个或者多个副本索引片。
- 文档(document)
- 文档类似于关系数据库中的表中的行记录,每个存储在索引中的一个文档都有一个原始的json文档,被存储在一个叫做_source的字段中。当搜索文档的时候默认返回的是这个字段。
- 一个文档不只有数据,还包含了元数据(metadata)——关于文档的信息:
- _index:文档存储的地方。名字必须是全部小写,不能以下划线开头,不能包含逗号;
- _id:id仅仅是一个字符串,指一个文件的唯一标识 ,它与_index组合时就可以在ES中唯一标识一个文档。
- 创建新文档时,可以自定义id,也可以让ES自动生成id。自动生成的ID有22个字符长,URL-safe, Base64-encoded string universally unique identifiers, 或者叫UUIDs。
- 映射(mapping)
- 映射类似于关系数据库中的表结构,每一个索引都有一个映射,它定义了索引中的每一个字段类型,以及一个索引范围内的设置。一个映射可以事先被定义,或者在第一次存储文档的时候自动识别。
- 映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型(string, number, booleans, date等) 。
- 字段(field)
- 字段类似于关系数据库中表的列,每个字段都对应一个字段类型,例如整数、字符串、对象等,可以指定如何分析该字段的值。
- 重要的是在ES里面:每个文档里的字段都默认会被索引并被查询。也就是说,每个字段专门有一个反向索引用于快速检索。而且与其它数据库不同,它可以在同一个查询中利用所有的这些反向索引,以惊人的速度返回结果。
- 来源字段(sourcefield)
- 默认情况下,原始文档将被存储在_source这个字段中,查询的时候也是返回这个字段。这样可以从搜索结果中访问原始的对象,这个对象返回一个精确的json字符串,这个对象不显示索引分析后的其他任何数据。
- 集群(cluster)
- 由一个或多个共享相同群集名称的节点组成的ES组,它们具有相同的cluster.name,它们协同工作,分享数据和负载。
- ES是一个分布式的文档(document) 存储引擎,它可以实时存储并检索复杂数据结构,序列化的JSON文档。换言说,一旦文档被存储在ES中,它就可以在集群的任一节点上被检索。
- 节点(node)
- 集群中的一个ES服务器,一个节点是一个逻辑上独立的服务,它是集群的一部分,可以存储数据,并参与集群的索引和搜索功能,在启动时,节点将使用广播来发现具有相同群集名称的现有群集,并将尝试加入该群集
- 主节点
- 每个群集有一个单独的主节点,这由程序自动选择,如果当前主节点失败,程序会自动选择其他节点作为主节点。
- 它将临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。主节点不参与文档级别的变更或搜索,这意味着在流量增长的时候,该主节点不会成为集群的瓶颈。
- 路由(routing)
- 操作文档时,选择文档所在分片的过程。一个文档会存储在一个唯一的主分片中,具体存储在哪个分片是通过散列值来进行选择的。
- 默认情况下,这个值是由文档的id生成。
- 如果文档有一个指定的父文档,从父文档ID中生成,该值可以在存储文档的时候进行修改。
- 分片(shard)
- 一个单一的Lucene实例,用来真正存储索引并提供搜索功能。这个是由ES管理的比较底层的功能,ES的索引是指向主分片和副本分片的逻辑空间。
- 对于使用,只需要指定分片的数量,其他不需要做过多的事情。在开发使用的过程中,我们对应的对象都是索引,ES会自动管理集群中所有的分片,当发生故障的时候,ES会把分片移动到不同的节点或者添加新的节点。
- 注意:可以在一个单一的Lucene索引中存储的最大值为2147483519(=integer.max_value - 128)个文档。
- 主分片(primary shard)
- 每个文档都存储在一个分片中,当你存储一个文档的时候,系统会首先存储在主分片中,然后会复制到不同的副本中。默认情况下,一个索引有5个主分片。可以在事先制定分片的数量,当分片一旦建立,分片的数量则不能修改。
- 副本分片(replica shard)
- 副本是主分片的复制,每一个分片有零个或多个副本,这样做有两个目的:
- 增加高可用性:当主分片失败的时候,可以从副本分片中选择一个作为主分片。
- 提高性能:当查询的时候可以到主分片或者副本分片中进行查询。
- 默认情况下,一个主分片有一个副本,但副本的数量可以在后面动态的配置增加。副本必须部署在不同的节点上,不能部署在和主分片相同的节点上。
基本使用
以下示例均在ES 8.3/Kibana 8.3版本上验证通过
怎样与ES交互?
- 有两种方法,一是直接向ES发送HTTP请求,拿创建索引举例:
# 注意默认情况下直接发送情况会失败,需要修改ES配置文件,将xpack.security.enabled设置为false。
# 当然在启用安全认证的情况下,其实也可以通过证书+用户的方式发送请求,我在后续文章中专门介绍。
curl -XPUT 'http://192.168.0.110:9200/mytest?pretty' -d '{"settings": {"index": {"number_of_shards": 5,"number_of_replicas": 2}}
}'
- 另一种方式是使用Kibana Dev Tools页面,使用起来非常便利,这是推荐的交互方式。
PUT /mytest
{"settings": {"index": {"number_of_shards": 5,"number_of_replicas": 2}}
}
- 执行成功后会获得如下响应数据:
{"acknowledged": true,"shards_acknowledged": true,"index": "mytest"
}
- 查看索引,列出所有的索引
GET /_cat/indices,后面跟?v能看到结果的表头。
插入数据
PUT /mytest/_create/p1
{"name": "Mac Book笔记本","price": 12345,"description": "这是一款笔记本","cats": ["3c","computer"]
}
- 请记住_index、_id两者唯一确定一个文档,所以要想保证文档是新加入的,最简单的方式是让ES自动生成唯一_id。
- 如果想使用自定义的_id,必须告诉ES应该在_index、_id两者都不同时才接受请求。
- 第一种方法使用op_type查询参数:PUT /website_blog/123?op_type=create
- 第二种方法是在URL后加/_create做为端点:PUT /website_blog/123/_create
- 如果请求成功的创建了一个新文档,ES将返回正常的元数据且响应状态码是201 Created。另一方面,如果包含相同的_index、_type和_id的文档已经存在,ES将返回409 Conflict响应状态码。
- 当创建文档的时候,如果索引不存在,则会自动创建该索引。
- 自动创建的索引会自动映射每个字段的类型。
- 自动创建索引可以通过配置文件设置action.auto_create_index为false在所有节点的配置文件中禁用。
- 自动映射的字段类型可以通过配置文件设置index.mapper.dynamic为false禁用。自动创建索引可以通过模板设置索引名称,例如:可以设置action.auto_create_index为 +aaa*, -bbb*, +ccc*, -* (+表示准许,-表示禁止) 。
查询数据
GET /mytest/_doc/p1请求将返回文档的全部字段,存储在_source参数中。但是可能你感兴趣的字段只是title。请求个别字段可以使用_source参数。多个字段可以使用逗号分隔:GET /mytest/_doc/p1?_source=cats,name。- 如果你想做的只是检查文档是否存在,对内容完全不感兴趣,使用HEAD方法来代替GET
HEAD /mytest/_doc/p1。 - 你也可以禁掉source,只要设置_source=false即可。
- 如果你只想获取sorce中的一部分内容,还可以用_source_include或者_source_exclude来包含或者过滤其中的某些字段
GET /mytest/_doc/p1?_source_includes=name。
修改数据
PUT /mytest/_doc/p1
{"name": "新款Mac Book笔记本","price": 54321
}
- 文档在ES中是不可变的, 如果需要更新已存在的文档,可以替换掉它。
- 在内部,ES已经标记旧文档为删除并添加了一个完整的新文档。旧版本文档不会立即消失,但你也不能去访问它。ES会在你继续索引更多数据时清理被删除的文档。
删除数据
DELETE /mytest/_doc/p1- 删除一个文档也不会立即从磁盘上移除,它只是被标记成已删除。ES将会在你之后添加更多索引的时候才会在后台进行删除内容的清理。
删除索引
DELETE /mytest- 删除索引后执行
GET /mytest会得到status=404的响应。
简单查询
- 通过url参数进行搜索
GET /mytest/_search?q=price:12345。- q:查询字符串
- df:当查询中没有定义前缀的时候默认使用的字段,例如
?q=123445&df=price。 - analyzer:当分析查询字符串的时候使用的分词器,例如
?q=笔记&df=description&analyzer=ik_max_word。 - lowercase_expanded_terms:搜索的时候忽略大小写标志,默认为true
- analyze_wildcard:通配符或者前缀查询是否被分析,默认false
- default_operator:默认多个条件的关系,AND或者OR,默认OR
- lenient:如果设置为true,字段类型转换失败的时候将被忽略,默认为false
- explain:在每个返回结果中,将包含评分机制的解释
- _source:是否包含元数据,同时支持_source_include和_source_exclude
- fields:只返回索引中指定的列,多个列中间用逗号分开
- sort:排序,例如fieldName:asc或者fieldName:desc
- track_scores:评分轨迹,当排序的时候,设置为true的时候返回评分的信息
- timeout:超时的时间设置
- terminate_after:在每个分片中查询的最大条数,返回结果中会有一个terminated_early字段
- from:开始的记录数
- size:搜索结果中的条数
- search_type:搜索的类型,可以是dfs_query_then_fetch,query_then_fetch,默认query_then_fetch
关于Timeout
- 一般情况下搜索请求不会超时。通常,协调节点会等待接收所有分片的回答。如果有一个节点遇到问题,它会拖慢整个搜索请求。
- Timeout参数告诉协调节点最多等待多久,就可以放弃等待而将已有结果返回。返回部分结果总比什么都没有好。搜索请求的返回将会指出这个搜索是否超时,以及有多少分片成功答复了。
- 你可以定义timeout参数为10或者10ms(10毫秒),或者1s(1秒),例如:
GET /_search?timeout=10ms,ES将返回在请求超时前收集到的结果。 - 注意:超时不是一个断路器,也就是说timeout不会停止执行查询,它仅仅告诉你目前顺利返回结果的节点然后关闭连接。在后台,其他分片可能依旧执行查询,尽管结果已经被发送。
多索引和多类别
- 通过限制搜索的不同索引或类型,可以在集群中跨所有文档搜索。ES转发搜索请求到集群中的主分片或每个分片的复制分片上,收集结果后选择顶部十个返回给我们。
- 可以通过定义URL中的索引或类型来限定搜索的范围,例如:
- /_search:在所有索引中搜索
- /mytest/_search:在索引mytest中搜索
- /mytest,test2/_search:在索引mytest和test2中搜索
- /my*,t*/_search:在以my或t开头的索引的所有类型中搜索
- /_all/_search:在所有索引中搜索
- 当你搜索包含单一索引时,ES转发搜索请求到这个索引的主分片或每个分片的复制分片上,然后聚集每个分片的结果。搜索包含多个索引也是同样的方式——只不过或有更多的分片被关联。
- 注意:搜索一个索引有5个主分片和5个索引各有一个分片事实上是一样的。
分页
- ES接受from和size参数:
- size: 结果数,默认10
- from: 跳过开始的结果数,默认0
- 如果你想每页显示5个结果,页码从1到2,那请求如下:
- GET /_search?size=5
- GET /_search?size=5&from=5
在集群系统中深度分页
- 为什么深度分页是有问题?假设在一个有5个主分片的索引中搜索,当请求结果的第一页(结果1到10)时,每个分片产生自己最顶端10个结果然后返回它们给请求节点,它再排序这所有的50个结果以选出顶端的10个结果。
- 现在假设请求第1000页——结果10001到10010,工作方式都相同,不同的是每个分片都必须产生顶端的10010个结果,然后请求节点排序这50050个结果并丢弃50040个!
- 可以看到在分布式系统中,排序结果的花费随着分页的深入而成倍增长。这也是为什么网络搜索引擎中任何语句不能返回多于1000个结果的原因。
关于routing
- 可以在操作文档的时候,指定用来计算路由的routing值,从而限定操作会落在哪些分片上,如果在新增文档的时候指定了routing,那么后续对这个文档的所有操作,都应该使用同样的routing值,这个技术在设计非常大的搜索系统时非常有用,例如:
- 新增Document ,指定routing:
PUT /mytest/_doc/p12?routing=myrouting{"name": "2022 Mac Book 笔记本","price": 12.59,"description": "这是一款笔记本","cats": ["3c","computer"]}- 查询的时候,也带上相同的routing值
GET /mytest/_doc/p12?routing=myrouting。
关于加减符号
- 搜索中还可以使用加减号,
+前缀表示语句匹配条件必须被满足,类似的-前缀表示条件,必须不被满足。 - 所有条件如果没有
+或-表示是可选的——匹配越多,相关的文档就越多,比如:GET /mytest/_search?q=+price:12.59。
关于API
现在官方推荐大家使用HTTP协议的API,早期也支持TCP协议的API,不过从接口兼容角度考虑后选择废弃了。
多索引参数
- 大多数API支持多索引查询,就是同时可以查询多个索引中的数据,例如,参数test1,test2,test3,表示同时搜索test1,test2,test3三个索引中中的数据,或者用(_all全部索引)。
- 在参数中同时支持通配符的操作,例如test*, 表示查询所有以test开头的索引。同时也支持排除操作,例如+test*, -test3表示查询所有test开头的索引,排除test3。
- 多索引查询还支持以下参数:
- ignore_unavailable:当索引不存在或者关闭的时候,是否忽略这些索引,值为true和false。
- allow_no_indices:当使用通配符查询时,当有索引不存在的时候是否返回查询失败。
- expand_wildcards:控制什么类型的索引被支持,值为open,close,none,all,open表示只支持open类型的索引,close表示只支持关闭状态的索引,none表示不可用,all表示同时支持open和close索引。
- 注意:文档操作API和索引别名API不支持多索引参数。
通用参数
- pretty参数,请求的返回值是经过格式化后的JSON数据,这样阅读起来更加的方便。系统还提供了另一种格式
?format=yaml,YAML格式,这将导致返回的结果具有可读的YAML格式。 - human参数,对于统计数据,系统支持计算机数据,同时也支持适合人类阅读的数据,比如:计算机数据
size_in_bytes: 1024更适合人类阅读的数据:"size": "1kb"。当?human=ture的时候输出更适合人类阅读的数据,但这会消耗更多的资源,默认是false。 - 响应过滤(filter_path)
- 所有的返回值可以通过filter_path来减少返回值的内容,多个值可以用逗号分开。例如:
GET /mytest/_doc/p1?filter_path=found,_source.cats {"found": true,"_source": {"cats": ["3c","computer"]} }- 它也支持通配符
*匹配任何部分字段的名称,例如:
GET /mytest/_doc/p1?filter_path=_source.* {"_source": {"name": "Mac Book笔记本","price": 12345,"description": "这是一款笔记本","cats": ["3c","computer"]} }- 我们可以用两个通配符
**来匹配不确定名称的字段,例如我们可以返回Lucene版本的段信息:GET /_segments?filter_path=indices.**.version。 - 有时直接返回ES的某个字段的原始值,如_source字段。如果你想过滤_source字段,可以结合_source字段和filter_path参数。
- 基于URL的访问控制
- 当多用户通过URL访问ES索引的时候,为了防止用户误删除等操作,可以通过基于URL的访问控制来限制用户对某个具体索引的访问。
- 可以在配置文件中添加参数:rest.action.multi.allow_explicit_index: false。这个参数默认为true。当为false的时候。在请求参数中指定具体索引的请求将会被拒绝。
相关文章:

ElasticSearch基本使用
title: ElasticSearch基本使用 date: 2022-08-29 00:00:00 tags: ElasticSearch基本使用 categories:ElasticSearch 基本概念 随着ES版本的升级,文中有些概念可能已经废弃。 索引词(term) 一个能够被索引的精确值,区分大小写,可以通过term查…...
windows微软商店下载应用失败/下载故障的解决办法;如何在网页上下载微软商店的应用
一、问题背景 设置惠普打印机时,需要安装hp smart,但是官方只提供微软商店这一下载渠道。 点击安装HP Smart,确定进入微软商店下载。 完全加载不出来,可能是因为开了代理。 把代理关了,就能正常打开了。 但是点击“…...
MySQL进阶篇之InnoDB存储引擎
06、InnoDB引擎 6.1、逻辑存储结构 表空间(Tablespace) 表空间在MySQL中最终会生成ibd文件,一个mysql实例可以对应多个表空间,用于存储记录、索引等数据。 段(Segment) 段,分为数据段&#x…...

商标侵权行为的种类有哪些
商标侵权行为的种类有哪些 1、商标侵权行为的种类有以下七种: (1)未经商标注册人的许可,在同一种商品上使用与其注册商标相同的商标的; (2)未经商标注册人的许可,在同一种商品上使用与其注册商标近似的商标,或者在类似商品上使…...
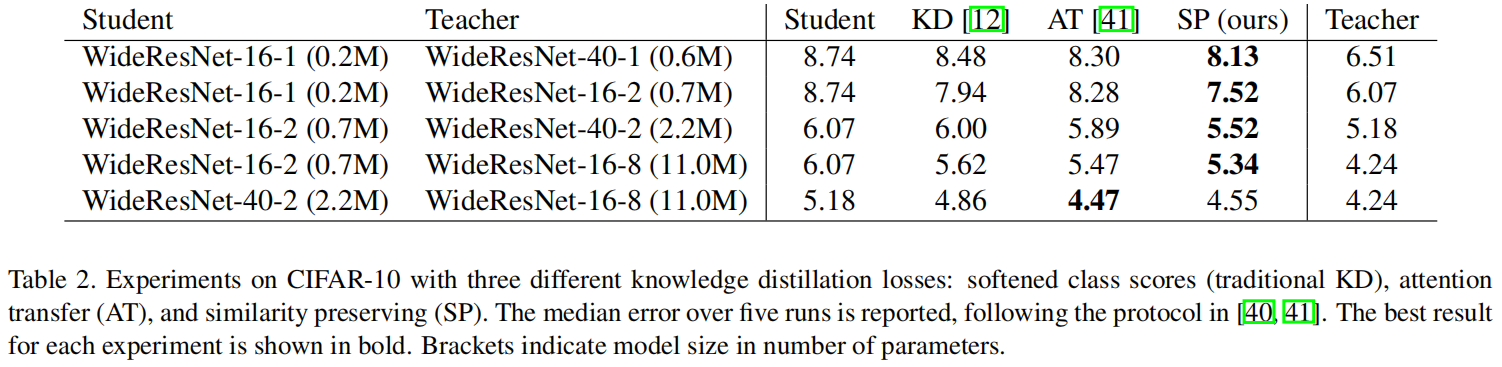
Similarity-Preserving KD(ICCV 2019)原理与代码解析
paper:Similarity-Preserving Knowledge Distillationcode:https://github.com/megvii-research/mdistiller/blob/master/mdistiller/distillers/SP.py背景本文的灵感来源于作者观察到在一个训练好的网络中,语义上相似的输入倾向于引起相似的…...
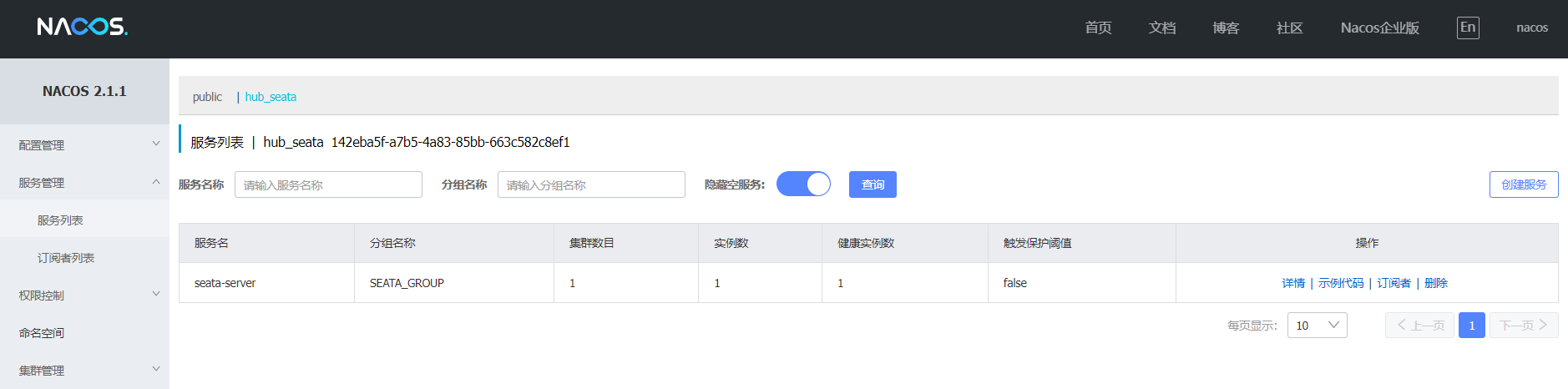
在Linux和Windows上安装seata-1.6.0
记录:381场景:在CentOS 7.9操作系统上,安装seata-1.6.0。在Windows上操作系统上,安装seata-1.6.0。Seata,一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。版本:JDK…...

兼职任务平台收集(二)分享给有需要的朋友们
互联网时代,给人们带来了很大的便利。信息交流、生活缴费、足不出户购物、便捷出行、线上医疗、线上教育等等很多。可以说,网络的时代会一直存在着。很多人也在互联网上赚到了第一桶金,这跟他们的努力和付出是息息相关的。所谓一份耕耘&#…...
目标检测三大数据格式VOC,YOLO,COCO的详细介绍
注:本文仅供学习,未经同意请勿转载 说明:该博客来源于xiaobai_Ry:2020年3月笔记 对应的PDF下载链接在:待上传 目录 目标检测常见数据集总结 V0C数据集(Annotation的格式是xmI) A. 数据集包含种类: B. V0C2007和V0C2012的区别…...
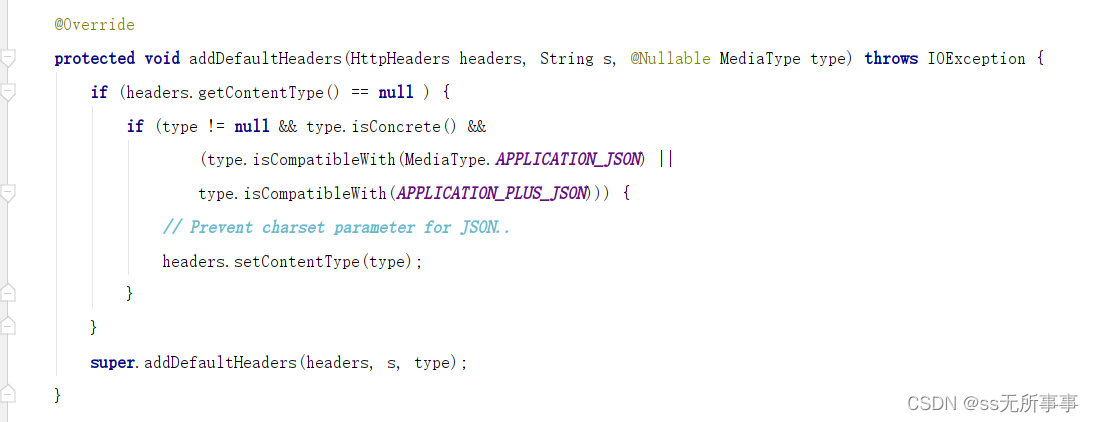
SpringBoot实现统一返回接口(除AOP)
起因 关于使用AOP去实现统一返回接口在之前的博客中我们已经实现了,但我突然突发奇想,SpringBoot中异常类的统一返回好像是通过RestControllerAdvice 这个注解去完成的,那我是否也可以通过这个注解去实现统一返回接口。 正文 这个方法主要…...

ChatGpt - 基于人工智能检索进行论文写作
摘要 ChatGPT 是一款由 OpenAI 训练的大型语言模型,可用于各种自然语言处理任务,包括论文写作。使用 ChatGPT 可以帮助作者提高论文的语言流畅度、增强表达能力和提高文章质量。在写作过程中,作者可以使用 ChatGPT 生成自然语言的段落、句子、单词或者短语,作为启发式的写…...

实例三:MATLAB APP design-多项式函数拟合
一、APP 界面设计展示 注:在左侧点击数据导入,选择自己的数据表,如果数据导入成功,在右侧的空白框就会显示数据导入成功。在多项式项数右侧框中输入项数,例如2、3、4等,点击计算按钮,右侧坐标框就会显示函数图像,在平均相对误差下面的空白框显示平均相对误差。...

springboot多种方式注入bean获取Bean
springboot动态注入bean1、创建Bean(demo)2、动态注入Bean3、通过注解注入Bean4、通过config配置注入Bean5、通过Import注解导入6、使用FactoryBean接口7、实现BeanDefinitionRegistryPostProcessor接口1、创建Bean(demo) Data public class Demo(){private String name;publi…...

Markdown及其语法详细介绍(全面)
文章目录一、基本语法1.标题2.段落和换行3.强调4.列表5.链接6.图片7.引用8.代码9.分割线10表格二、扩展语法1.标题锚点标题 {#anchor}2.脚注3.自动链接4.任务列表5.删除线6.表情符号7.数学公式三、Markdown 应用1.文档编辑2.博客写作3.代码笔记四、常见的工具和平台支持 Markdo…...
在Linux和Windows上安装sentinel-1.8.5
记录:380场景:在CentOS 7.9操作系统上,安装sentinel-1.8.5。在Windows上操作系统上,安装sentinel-1.8.5。Sentinel是面向分布式、多语言异构化服务架构的流量治理组件。版本:JDK 1.8 sentinel-1.8.5 CentOS 7.9官网地址…...
)
面试攻略,Java 基础面试 100 问(十)
StringBuffer、StringBuilder、String区别 线程安全 StringBuffer:线程安全,StringBuilder:线程不安全。 因为 StringBuffer 的所有公开方法都是 synchronized 修饰的,而 StringBuilder 并没有 synchronized 修饰。 StringBuf…...
Zero-shot(零次学习)简介
zero-shot基本概念 首先通过一个例子来引入zero-shot的概念。假设我们已知驴子和马的形态特征,又已知老虎和鬣狗都是又相间条纹的动物,熊猫和企鹅是黑白相间的动物,再次的基础上,我们定义斑马是黑白条纹相间的马科动物。不看任何斑…...

51单片机简易电阻电感电容RLC测量仪仿真设计
51单片机简易电阻电感电容RLC测量仪仿真( proteus仿真程序讲解视频) 仿真图proteus7.8及以上 程序编译器:keil 4/keil 5 编程语言:C语言 设计编号:S0040 51单片机简易电阻电感电容RLC测量仪仿真51单片机最小系统的相关知识复位…...

[软件工程导论(第六版)]第6章 详细设计(课后习题详解)
文章目录1 假设只有SEQUENCE和DO-WHILE两种控制结构,怎样利用它们完成 IF THEN ELSE操作?2 假设只允许使用SEQUENCE和IF-THEN-ELSE两种控制结构,怎样利用它们完成DO WHILE操作?3 画出下列伪码程序的程序流程图和盒图:4…...

【2.19】算法题2:贪心算法、动态规划、分治
题目:给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。子数组 是数组中的一个连续部分。方法一:贪心算法原理:若当前指针所指元素之前的和小…...
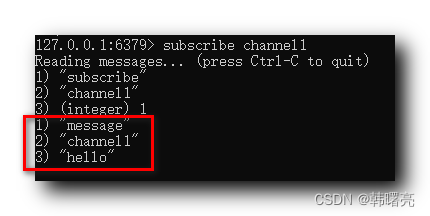
【Redis】Redis 发布订阅通信模式 ( 发布订阅模式 | 订阅频道 | 发布消息 | 接收消息 )
文章目录一、发布订阅模式二、订阅频道三、发布消息四、接收消息一、发布订阅模式 Redis 中 存在一种 发布订阅 消息通信模式 : 消息发布者 : 负责发送消息 , 订阅者需要订阅该发布者频道 ;消息订阅者 : 负责接收消息 ; 订阅者 先 订阅 发布者频道 , 当 发布者 发布消息时 , …...

Czkawka:智能存储管理的5个核心解决方案
Czkawka:智能存储管理的5个核心解决方案 【免费下载链接】czkawka Multi functional app to find duplicates, empty folders, similar images etc. 项目地址: https://gitcode.com/GitHub_Trending/cz/czkawka 1.0 现象剖析:数字存储管理的现实困…...

如何突破思维导图协作瓶颈?云端协同与知识管理新方案
如何突破思维导图协作瓶颈?云端协同与知识管理新方案 【免费下载链接】kityminder 百度脑图 项目地址: https://gitcode.com/gh_mirrors/ki/kityminder 在数字化办公环境中,思维导图作为梳理思路、规划项目的重要工具,其价值已得到广泛…...

LoRA训练助手入门解析:为什么权重排序对LoRA训练效果影响显著
LoRA训练助手入门解析:为什么权重排序对LoRA训练效果影响显著 1. 认识LoRA训练助手 如果你正在尝试训练自己的AI绘画模型,可能会遇到一个常见问题:为什么同样的图片,用不同的标签训练出来的效果差距那么大?这就是我们…...

新手福音:用快马平台将vmware官网概念转化为可交互的虚拟机演示代码
作为一名刚接触虚拟化技术的新手,我最近在VMware官网上看到了关于虚拟机的基础概念介绍。虽然理论知识很全面,但总觉得少了点动手实践的环节。直到发现了InsCode(快马)平台,它让我能够把抽象的概念快速转化为可运行的代码,这种学习…...

避坑指南:微信支付V3 SDK自动更新证书失败的5种常见原因及修复方法
微信支付V3证书自动更新失败排查手册:从原理到实战修复 微信支付的V3版本SDK以其自动证书更新机制著称,但不少开发者在集成过程中都遭遇过AutoUpdateCertificatesVerifier的失败问题。证书更新失败不仅会导致支付功能中断,还可能引发验签错误…...

如何永久保存微信聊天记录:免费工具实现数据可视化与年度报告生成
如何永久保存微信聊天记录:免费工具实现数据可视化与年度报告生成 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trendi…...
20260331-001篇)
网络基础知识整理(精简通用版)20260331-001篇
文章目录 网络基础知识整理(精简通用版) 一、网络基本概念 二、网络拓扑结构 三、OSI 七层模型(核心参考) 四、TCP/IP 模型(实际互联网标准) 五、IP 地址基础 六、传输层协议(TCP vs UDP) TCP(传输控制协议) UDP(用户数据报协议) 七、常见网络协议与端口 八、网络设…...

颠覆原神体验:Snap Hutao智能助手如何重构你的游戏效率
颠覆原神体验:Snap Hutao智能助手如何重构你的游戏效率 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn/Snap.Hu…...

系统架构设计师常见高频考点总结之计算机网络
学习这些网络题目时,可以将网络层次结构想象成高速公路系统:核心层是连接城市的大型立交桥和主干道,追求极速转发;汇聚层是出口闸机,负责检查通行证(安全过滤)和分流;而接入层则是通…...

HUNYUAN-MT 7B翻译终端Typora Markdown写作增强:实时双语文档创作
HUNYUAN-MT 7B翻译终端Typora Markdown写作增强:实时双语文档创作 1. 引言 如果你经常用Typora写技术博客或者项目文档,可能遇到过这样的场景:好不容易写完一篇内容详实的文章,想要分享给国际社区,却卡在了翻译上。手…...