消息中间件相关面试题

👏作者简介:大家好,我是爱发博客的嗯哼,爱好Java的小菜鸟
🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
📝社区论坛:希望大家能加入社区共同进步
🧑💼个人博客:智慧笔记
📕系列专栏:面试宝典
- 本文引自黑马程序员Java面试宝典
文章目录
- 面试官:RabbitMQ-如何保证消息不丢失
- 面试官:RabbitMQ消息的重复消费问题如何解决的
- 面试官:那你还知道其他的解决方案吗?
- 面试官:RabbitMQ中死信交换机 ? (RabbitMQ延迟队列有了解过嘛)
- 面试官:如果有100万消息堆积在MQ , 如何解决 ?
- 面试官:RabbitMQ的高可用机制有了解过嘛
- 面试官:那出现丢数据怎么解决呢?
- 面试官:Kafka是如何保证消息不丢失
- 面试官:Kafka中消息的重复消费问题如何解决的
- 面试官:Kafka是如何保证消费的顺序性
- 面试官:Kafka的高可用机制有了解过嘛
- 面试官:解释一下复制机制中的ISR
- 面试官:Kafka数据清理机制了解过嘛
- 面试官:Kafka中实现高性能的设计有了解过嘛
面试官:RabbitMQ-如何保证消息不丢失
候选人:
嗯!我们当时MYSQL和Redis的数据双写一致性就是采用RabbitMQ实现同步的,这里面就要求了消息的高可用性,我们要保证消息的不丢失。主要从三个层面考虑
第一个是开启生产者确认机制,确保生产者的消息能到达队列,如果报错可以先记录到日志中,再去修复数据
第二个是开启持久化功能,确保消息未消费前在队列中不会丢失,其中的交换机、队列、和消息都要做持久化
第三个是开启消费者确认机制为auto,由spring确认消息处理成功后完成ack,当然也需要设置一定的重试次数,我们当时设置了3次,如果重试3次还没有收到消息,就将失败后的消息投递到异常交换机,交由人工处理
面试官:RabbitMQ消息的重复消费问题如何解决的
候选人:
嗯,这个我们还真遇到过,是这样的,我们当时消费者是设置了自动确认机制,当服务还没来得及给MQ确认的时候,服务宕机了,导致服务重启之后,又消费了一次消息。这样就重复消费了
因为我们当时处理的支付(订单|业务唯一标识),它有一个业务的唯一标识,我们再处理消息时,先到数据库查询一下,这个数据是否存在,如果不存在,说明没有处理过,这个时候就可以正常处理这个消息了。如果已经存在这个数据了,就说明消息重复消费了,我们就不需要再消费了
面试官:那你还知道其他的解决方案吗?
候选人:
嗯,我想想~
其实这个就是典型的幂等的问题,比如,redis分布式锁、数据库的锁都是可以的
面试官:RabbitMQ中死信交换机 ? (RabbitMQ延迟队列有了解过嘛)
候选人:
嗯!了解过!
我们当时的xx项目有一个xx业务,需要用到延迟队列,其中就是使用RabbitMQ来实现的。
延迟队列就是用到了死信交换机和TTL(消息存活时间)实现的。
如果消息超时未消费就会变成死信,在RabbitMQ中如果消息成为死信,队列可以绑定一个死信交换机,在死信交换机上可以绑定其他队列,在我们发消息的时候可以按照需求指定TTL的时间,这样就实现了延迟队列的功能了。
我记得RabbitMQ还有一种方式可以实现延迟队列,在RabbitMQ中安装一个死信插件,这样更方便一些,我们只需要在声明交互机的时候,指定这个就是死信交换机,然后在发送消息的时候直接指定超时时间就行了,相对于死信交换机+TTL要省略了一些步骤
面试官:如果有100万消息堆积在MQ , 如何解决 ?
候选人:
我在实际的开发中,没遇到过这种情况,不过,如果发生了堆积的问题,解决方案也所有很多的
第一:提高消费者的消费能力 ,可以使用多线程消费任务
第二:增加更多消费者,提高消费速度
使用工作队列模式, 设置多个消费者消费消费同一个队列中的消息
第三:扩大队列容积,提高堆积上限
可以使用RabbitMQ惰性队列,惰性队列的好处主要是
①接收到消息后直接存入磁盘而非内存
②消费者要消费消息时才会从磁盘中读取并加载到内存
③支持数百万条的消息存储
面试官:RabbitMQ的高可用机制有了解过嘛
候选人:
嗯,熟悉的~
我们当时项目在生产环境下,使用的集群,当时搭建是镜像模式集群,使用了3台机器。
镜像队列结构是一主多从,所有操作都是主节点完成,然后同步给镜像节点,如果主节点宕机后,镜像节点会替代成新的主节点,不过在主从同步完成前,主节点就已经宕机,可能出现数据丢失
面试官:那出现丢数据怎么解决呢?
候选人:
我们可以采用仲裁队列,与镜像队列一样,都是主从模式,支持主从数据同步,主从同步基于Raft协议,强一致。
并且使用起来也非常简单,不需要额外的配置,在声明队列的时候只要指定这个是仲裁队列即可
面试官:Kafka是如何保证消息不丢失
候选人:
嗯,这个保证机制很多,在发送消息到消费者接收消息,在每个阶段都有可能会丢失消息,所以我们解决的话也是从多个方面考虑
第一个是生产者发送消息的时候,可以使用异步回调发送,如果消息发送失败,我们可以通过回调获取失败后的消息信息,可以考虑重试或记录日志,后边再做补偿都是可以的。同时在生产者这边还可以设置消息重试,有的时候是由于网络抖动的原因导致发送不成功,就可以使用重试机制来解决
第二个在broker中消息有可能会丢失,我们可以通过kafka的复制机制来确保消息不丢失,在生产者发送消息的时候,可以设置一个acks,就是确认机制。我们可以设置参数为all,这样的话,当生产者发送消息到了分区之后,不仅仅只在leader分区保存确认,在follwer分区也会保存确认,只有当所有的副本都保存确认以后才算是成功发送了消息,所以,这样设置就很大程度了保证了消息不会在broker丢失
第三个有可能是在消费者端丢失消息,kafka消费消息都是按照offset进行标记消费的,消费者默认是自动按期提交已经消费的偏移量,默认是每隔5s提交一次,如果出现重平衡的情况,可能会重复消费或丢失数据。我们一般都会禁用掉自动提价偏移量,改为手动提交,当消费成功以后再报告给broker消费的位置,这样就可以避免消息丢失和重复消费了
面试官:Kafka中消息的重复消费问题如何解决的
候选人:
kafka消费消息都是按照offset进行标记消费的,消费者默认是自动按期提交已经消费的偏移量,默认是每隔5s提交一次,如果出现重平衡的情况,可能会重复消费或丢失数据。我们一般都会禁用掉自动提价偏移量,改为手动提交,当消费成功以后再报告给broker消费的位置,这样就可以避免消息丢失和重复消费了
为了消息的幂等,我们也可以设置唯一主键来进行区分,或者是加锁,数据库的锁,或者是redis分布式锁,都能解决幂等的问题
面试官:Kafka是如何保证消费的顺序性
候选人:
kafka默认存储和消费消息,是不能保证顺序性的,因为一个topic数据可能存储在不同的分区中,每个分区都有一个按照顺序的存储的偏移量,如果消费者关联了多个分区不能保证顺序性
如果有这样的需求的话,我们是可以解决的,把消息都存储同一个分区下就行了,有两种方式都可以进行设置,第一个是发送消息时指定分区号,第二个是发送消息时按照相同的业务设置相同的key,因为默认情况下分区也是通过key的hashcode值来选择分区的,hash值如果一样的话,分区肯定也是一样的
面试官:Kafka的高可用机制有了解过嘛
候选人:
嗯,主要是有两个层面,第一个是集群,第二个是提供了复制机制
kafka集群指的是由多个broker实例组成,即使某一台宕机,也不耽误其他broker继续对外提供服务
复制机制是可以保证kafka的高可用的,一个topic有多个分区,每个分区有多个副本,有一个leader,其余的是follower,副本存储在不同的broker中;所有的分区副本的内容是都是相同的,如果leader发生故障时,会自动将其中一个follower提升为leader,保证了系统的容错性、高可用性
面试官:解释一下复制机制中的ISR
候选人:
ISR的意思是in-sync replica,就是需要同步复制保存的follower
其中分区副本有很多的follower,分为了两类,一个是ISR,与leader副本同步保存数据,另外一个普通的副本,是异步同步数据,当leader挂掉之后,会优先从ISR副本列表中选取一个作为leader,因为ISR是同步保存数据,数据更加的完整一些,所以优先选择ISR副本列表
面试官:Kafka数据清理机制了解过嘛
候选人:
嗯,了解过~~
Kafka中topic的数据存储在分区上,分区如果文件过大会分段存储segment
每个分段都在磁盘上以索引(xxxx.index)和日志文件(xxxx.log)的形式存储,这样分段的好处是,第一能够减少单个文件内容的大小,查找数据方便,第二方便kafka进行日志清理。
在kafka中提供了两个日志的清理策略:
第一,根据消息的保留时间,当消息保存的时间超过了指定的时间,就会触发清理,默认是168小时( 7天)
第二是根据topic存储的数据大小,当topic所占的日志文件大小大于一定的阈值,则开始删除最久的消息。这个默认是关闭的
这两个策略都可以通过kafka的broker中的配置文件进行设置
面试官:Kafka中实现高性能的设计有了解过嘛
候选人:
Kafka 高性能,是多方面协同的结果,包括宏观架构、分布式存储、ISR 数据同步、以及高效的利用磁盘、操作系统特性等。主要体现有这么几点:
消息分区:不受单台服务器的限制,可以不受限的处理更多的数据
顺序读写:磁盘顺序读写,提升读写效率
页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
零拷贝:减少上下文切换及数据拷贝
消息压缩:减少磁盘IO和网络IO
分批发送:将消息打包批量发送,减少网络开销
往期文章推荐:
- Java集合相关面试题
- Java集合详解
- 微服务相关面试题
- redis相关面试题
- 图解 Paxos 算法
- Spring相关面试题
- Mysql相关面试题
- 深入浅出WebSocket
相关文章:
消息中间件相关面试题
👏作者简介:大家好,我是爱发博客的嗯哼,爱好Java的小菜鸟 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦 📝社区论坛:希望大家能加入社区共同进步…...
成集云 | 电子签署集成腾讯云企业网盘 | 解决方案
源系统成集云目标系统 方案介绍 电子签署是通过电子方式完成合同、文件或其他文件的签署过程。相较于传统的纸质签署,电子签署具有更高效、更便捷、更安全的优势。 在电子签署过程中,使用电子签名技术来验证签署者的身份并确保签署文件的完整性。电子…...
提升大数据技能,不再颓废!这6家学习网站是你的利器!
随着国家数字化转型,大数据领域对人才的需求越来越多。大数据主要研究计算机科学和大数据处理技术等相关的知识和技能,从大数据应用的三个主要层面(即数据管理、系统开发、海量数据分析与挖掘)出发,对实际问题进行分析…...

uniapp开发小程序-有分类和列表时,进入页面默认选中第一个分类
一、效果: 如下图所示,进入该页面后,默认选中第一个分类,以及第一个分类下的列表数据。 二、代码实现: 关键代码: 进入页面时,默认调用分类的接口,在分类接口里做判断ÿ…...

小程序-uni-app:hbuildx uni-app 安装 uni-icons 及使用
一、官方文档找到uni-icons uni-app官网 二、下载插件 三、点击“打开HBuildX” 四、选择要安装的项目 五、勾选要安装的插件 六、安装后,项目插件目录 根目录uni_modules目录下增加uni-icons、uni-scss 七、引入组件,使用组件 <uni-icons type&qu…...
函数用法详解)
PHP中in_array()函数用法详解
in_array() 函数是PHP中常用的数组函数之一,用于搜索数组中是否存在指定的值。 语法 bool in_array ( mixed $needle , array $haystack [, bool $strict FALSE ] ) 参数描述needle必需。规定要在数组搜索的值。haystack必需。规定要搜索的数组。strict可选。如…...
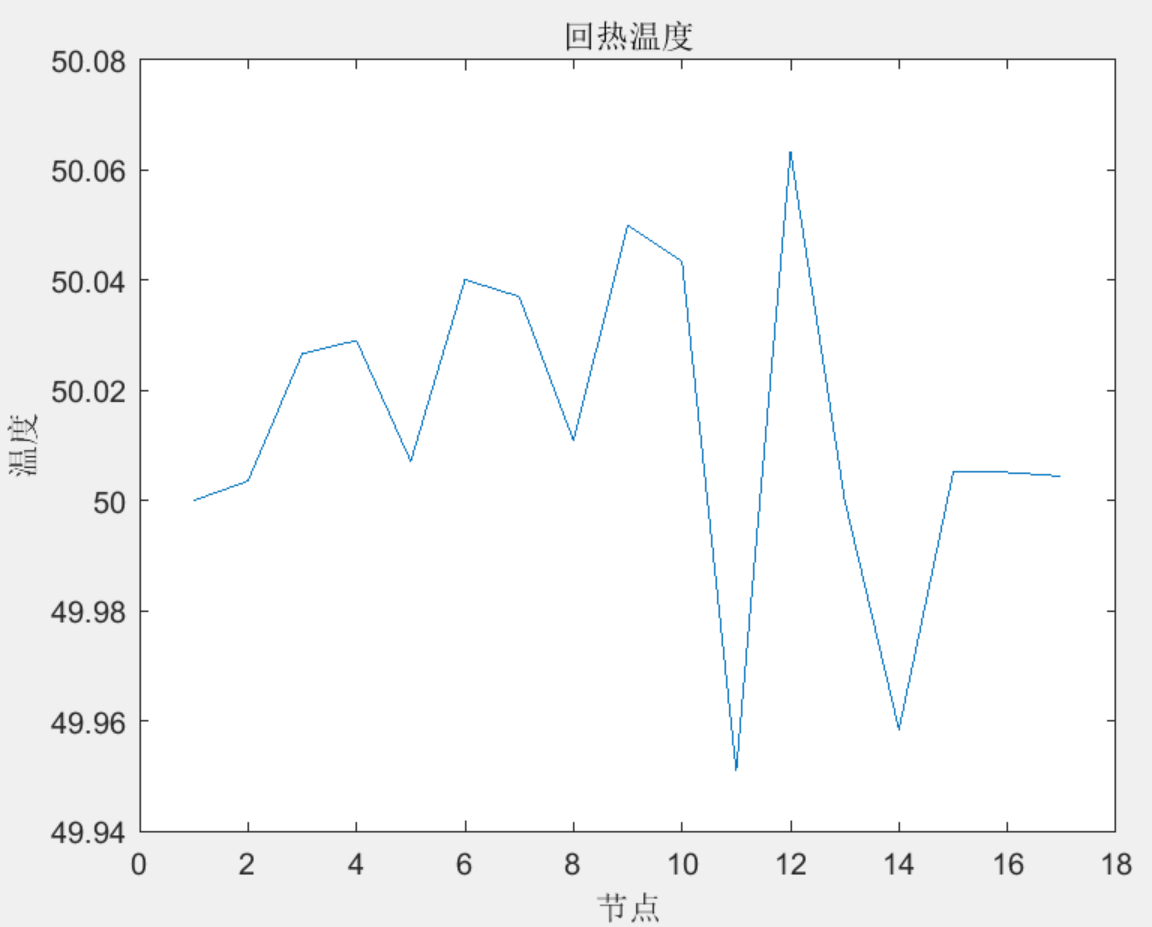
热电联产在综合能源系统中的选址定容研究(matlab代码)
目录 1 主要内容 目标函数 程序模型 2 部分代码 3 程序结果 1 主要内容 该程序参考《热电联产在区域综合能源系统中的定容选址研究》,主要针对电热综合能源系统进行优化,确定热电联产机组的位置和容量,程序以33节点电网和17节点热网为例…...

校园网安全风险分析
⒈物理层的安全风险分析 网络的物理安全风险主要指网络周边环境和物理特性引起的网络设备和线路的不可用 , 而 造成网络系统的不可用。我们在考虑校园网络安全时,首先要考虑物理安全风险,它是整个 网络系统安全的前提。物理安全风险有:设备…...
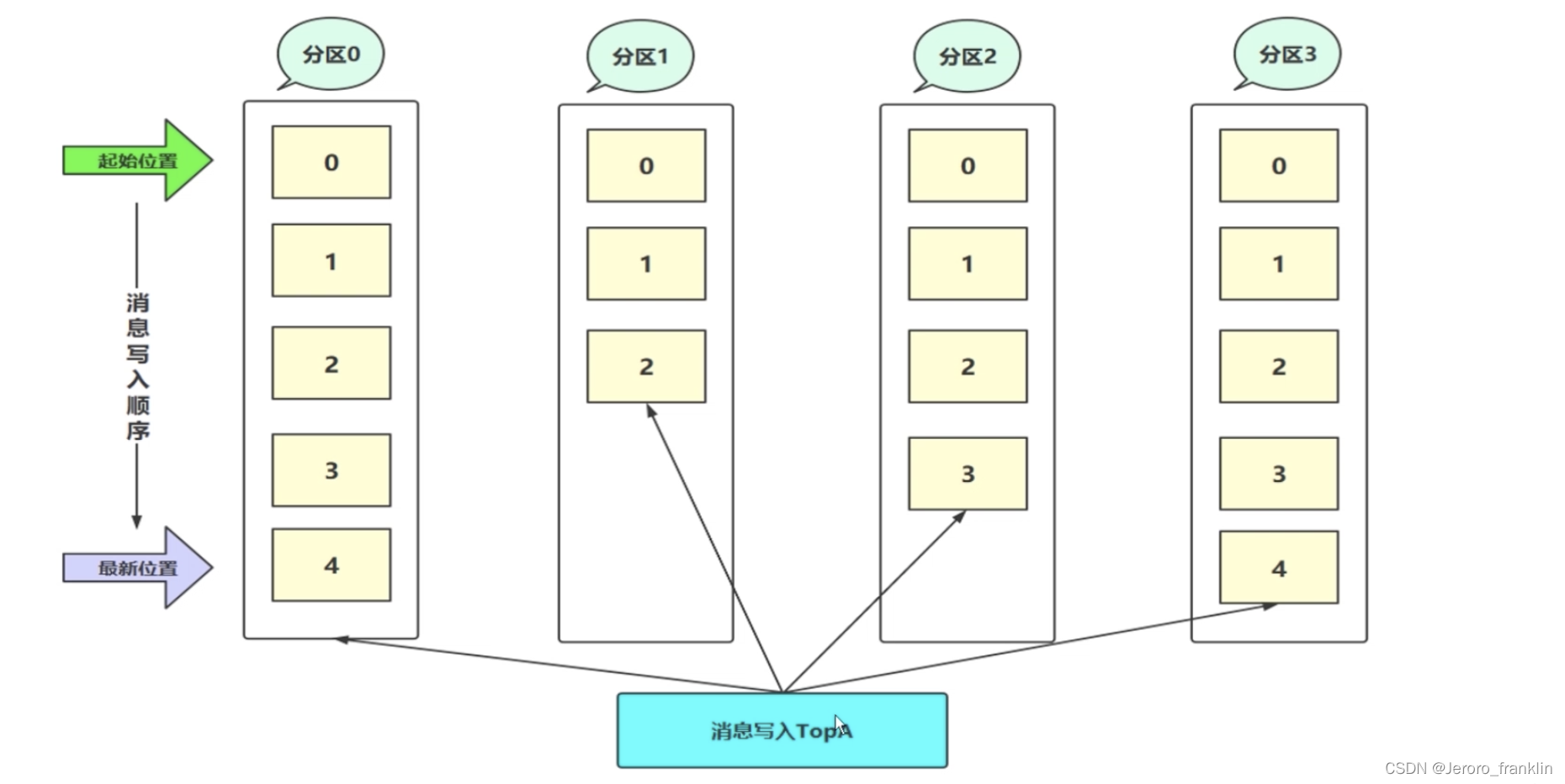
kafka--kafka的基本概念-topic和partition
一、kafka的基本概念-topic和partition 1、topic (主题 ) topic是逻辑概念 以Topic机制来对消息进行分类的,同一类消息属于同一个Topic,你可以将每个topic看成是一个消息队列。 生产者(producer)将消息发…...
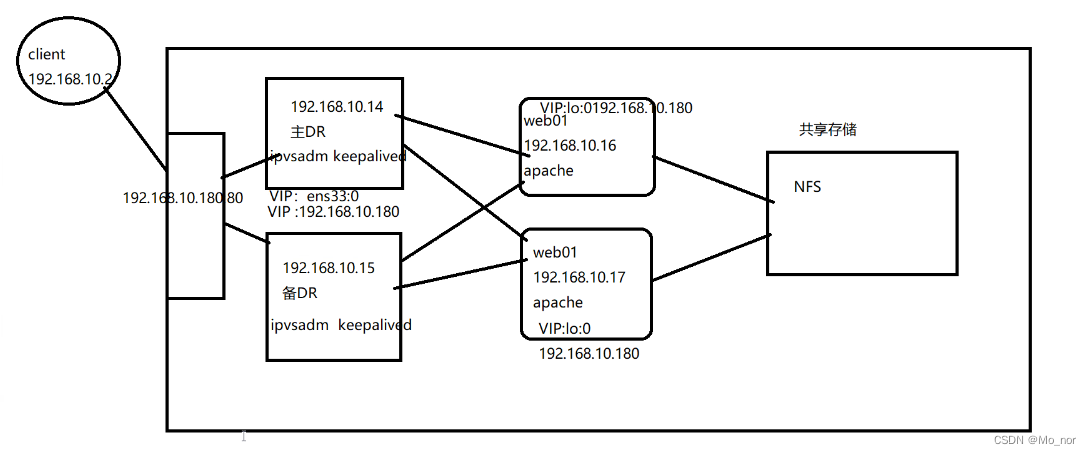
【LVS】3、LVS+Keepalived群集
为什么用它,为了做高可用 服务功能 1.故障自动切换 2.健康检查 3.节点服务器高可用-HA Keepalived的三个模块: core:Keepalived的核心,负责主进程的启动、维护;调用全局配置文件进行加载和解析 vrrp:实…...
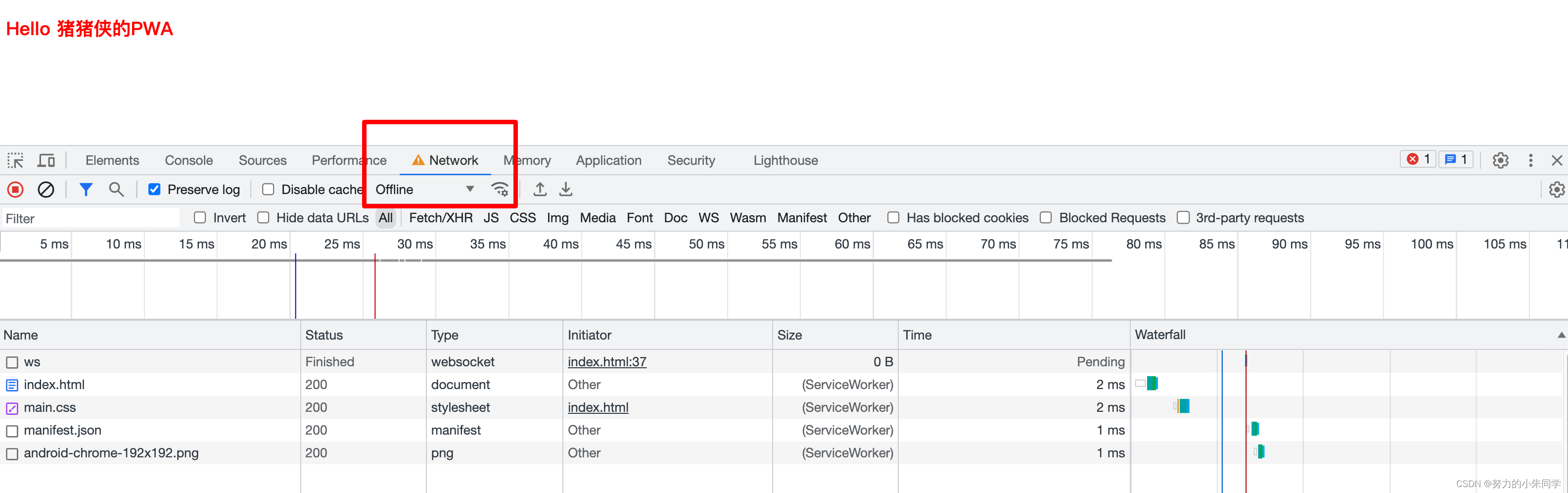
对前端PWA应用的部分理解和基础Demo
一、什么是PWA应用? 1、PWA简介 渐进式Web应用(Progressive Web App),简称PWA,是 Google 在 2015 年提出的一种使用web平台技术构建的应用程序,官方认为其核心在于Reliable(可靠的…...

CSGO饰品价格会一直下跌吗?市场何时止跌回升?
最后一届巴黎major终于落下帷幕,Vitality小蜜蜂2-0战胜GL成功赢下本次Major冠军,也是首次夺得Major冠军!有人欢喜有人忧啊,csgo搬砖的饰品商人们一点也高兴不起来。 4月-5月,csgo皮肤饰品已持续走低快两个月了。手里满…...
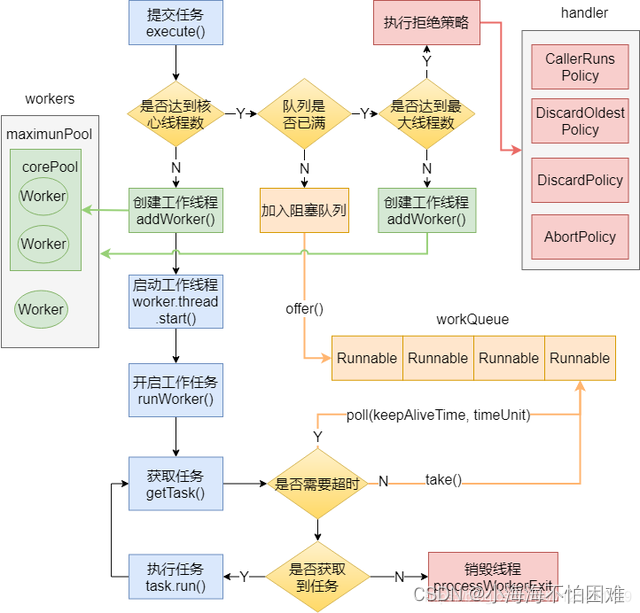
线程池原理
一、线程池的定义 线程池,按照配置参数(核心线程数、最大线程数等)创建并管理若干线程对象,没有任务的时候,这些线程都处于等待空闲状态。如果有新的线程任务,就分配一个空闲线程执行。如果所有线程都处于…...
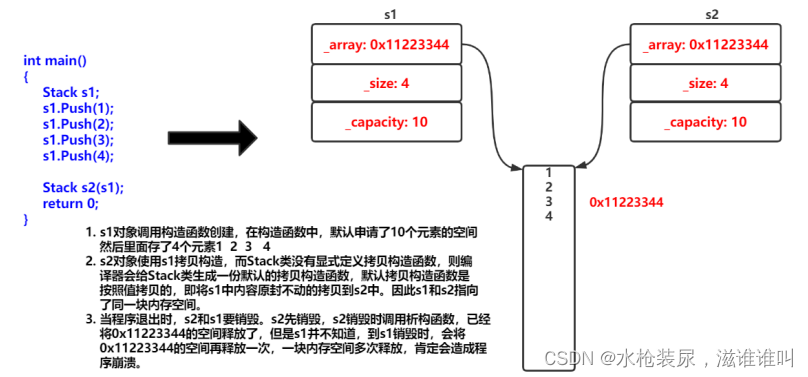
拷贝构造函数
1. 拷贝构造函数是构造函数的一个重载形式。 2. 拷贝构造函数的参数只有一个且必须是类类型对象的引用,使用传值方式编译器直接报错, 因为会引发无穷递归调用。 class Date { public:Date(int year 1900, int month 1, int day 1){_year year;_mont…...

数据库: MySQL安装部署、主从
单机部署 mkdir -p /opt/soft/archive cd /opt/soft/archivewget -i -c https://dev.mysql.com/get/mysql80-community-release-el7-7.noarch.rpm yum install -y mysql80-community-release-el7-7.noarch.rpm yum-config-manager --enable mysql80-community yum install -y …...
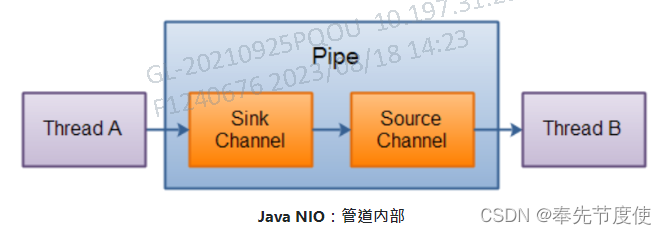
Java IO流(二)IO模型(BIO|NIO|AIO)
概述 Java IO模型同步阻塞IO(BIO)、同步非阻塞IO(NIO)、异步非阻塞IO(AIO/NIO2),Java中的BIO、NIO和AIO理解为是Java语言对操作系统的各种IO模型的封装 IO模型 BIO(Blocking I/O) 概述 BIO是一种同步并阻…...
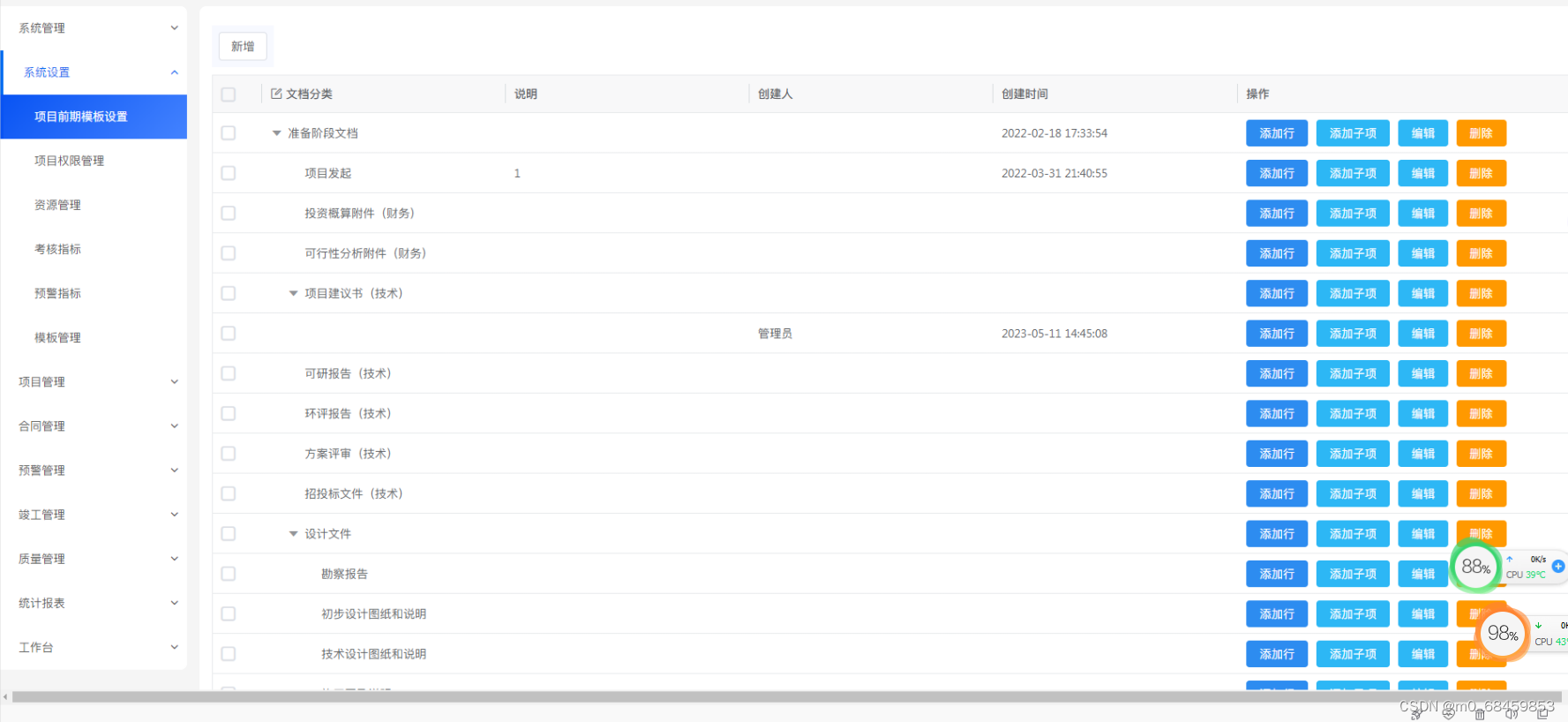
java版本spring cloud 企业工程系统管理 工程项目管理系统源码em
工程项目管理软件(工程项目管理系统)对建设工程项目管理组织建设、项目策划决策、规划设计、施工建设到竣工交付、总结评估、运维运营,全过程、全方位的对项目进行综合管理 工程项目各模块及其功能点清单 一、系统管理 1、数据字典ÿ…...

飞天使-k8s简单搭建
文章目录 k8s概念安装部署-第一版无密钥配置与hosts与关闭swap开启ipv4转发安装前启用脚本开启ip_vs安装指定版本docker 安装kubeadm kubectl kubelet,此部分为基础构建模版 k8s一主一worker节点部署k8s三个master部署,如果负载均衡keepalived 不可用,可以用单节点做…...

java中把一个list转tree的方法
环境 我们有个需求,数据库要存一个无限级联的tree,比如菜单,目录,或者地区等数据,现有两个问题: 问如何设计表。怎么返回给前端一个无线级联的json数据。 思考 第一个问题 在设计表的时候,…...
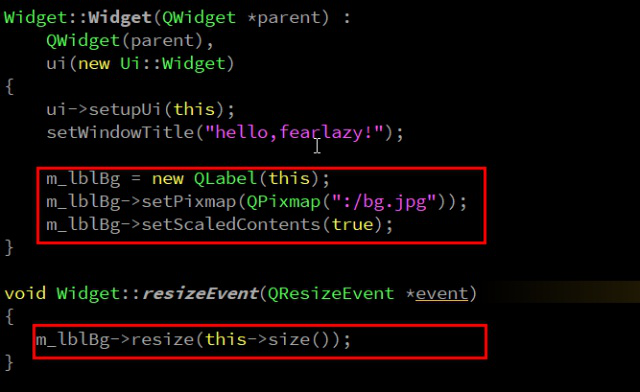
QT设置widget背景图片
首先说方法,在给widget或者frame或者其他任何类型的控件添加背景图时,在样式表中加入如下代码,指定某个控件,设置其背景。 类名 # 控件名 { 填充方式:图片路径 } 例如: QWidget#Widget {border-image: url…...
)
别再踩坑了!emWin6.x窗口管理器定时器WM_CreateTimer的正确打开方式(附RTOS/裸机源码)
深度解析emWin6.x窗口管理器定时器的实战避坑指南 在嵌入式GUI开发中,emWin的窗口管理器定时器功能是构建动态交互界面的核心工具之一。许多开发者在初次接触WM_CreateTimer时,往往会被看似简单的API背后隐藏的细节所困扰——为什么定时器没有触发&#…...

从AwesomeCursorPrompt看提示工程:如何设计高效AI编程指令
1. 项目概述:从“AwesomeCursorPrompt”看提示工程的工程化实践最近在折腾AI编程助手,特别是Cursor这个工具,发现一个挺有意思的现象:很多人觉得它“不够聪明”,或者用起来效果时好时坏。其实,这背后往往不…...

iOS 26.4-26.5终极越狱指南:安全解锁iPhone隐藏功能与高级定制方案
iOS 26.4-26.5终极越狱指南:安全解锁iPhone隐藏功能与高级定制方案 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇…...

AUBO机械臂视觉跟踪避坑指南:手眼标定后,如何让末端稳定跟随移动的ArUco码?
AUBO机械臂视觉跟踪避坑指南:手眼标定后如何实现稳定动态跟随 在工业自动化领域,机械臂的视觉跟踪能力直接决定了柔性制造系统的智能化水平。AUBO i5作为国产协作机械臂的代表性产品,其与视觉系统的集成应用越来越广泛。然而,许多…...

Gitblit服务端在Windows上安装后启动失败?别慌,手把手教你排查‘Failed creating java’这个经典错误
Gitblit服务端Windows启动报错全攻略:从"Failed creating java"到完美解决 当你满怀期待地在Windows服务器上部署Gitblit,准备为团队搭建一个轻量级的Git代码托管平台时,突然在服务启动环节遭遇"Failed creating java"的…...

告别‘鬼影’与模糊:深入解读RangeNet++如何用高效kNN后处理搞定LiDAR语义分割的边界难题
RangeNet:用GPU加速的kNN后处理破解LiDAR语义分割的边界模糊难题 当自动驾驶车辆以每小时60公里的速度行驶时,每100毫秒的决策延迟意味着1.67米的盲区——这恰好是许多交通事故发生的临界距离。在LiDAR语义分割领域,传统方法在点云投影与反投…...

掌握这四大趋势,让你的AI Agent真正“能干活”!CSDN收藏必备指南
本文深入探讨了企业级AI Agent的四大核心趋势:MCP协议实现可扩展集成、GraphRAG提升回答一致性、AgentDevOps确保行为质量与推理链路稳定性、RaaS模式实现结果计费。文章指出,这些趋势共同推动AI Agent从“可用”到“好用”的跨越,并提供了实…...

ClawForgeAI:基于工作流编排的AIGC创意自动化平台解析
1. 项目概述:从“ClawForgeAI/clawforge”看AI驱动的创意工具新范式最近在GitHub上看到一个挺有意思的项目,叫“ClawForgeAI/clawforge”。光看这个名字,你可能会有点摸不着头脑——“ClawForge”听起来像是个游戏模组工具或者某种机械设计软…...

基于TypeScript的MCP服务器开发指南:为AI助手构建安全工具调用能力
1. 项目概述:一个为TypeScript开发者打造的MCP服务器最近在折腾AI应用开发,特别是想给Claude、Cursor这类智能助手扩展更强大的工具调用能力时,不可避免地接触到了Model Context Protocol。如果你也在研究如何让AI助手安全、可控地访问文件系…...

WELearn网课助手:5分钟掌握智能学习,告别熬夜刷课
WELearn网课助手:5分钟掌握智能学习,告别熬夜刷课 【免费下载链接】WELearnHelper 显示WE Learn随行课堂题目答案;支持班级测试;自动答题;刷时长;基于生成式AI(ChatGPT)的答案生成 项目地址: https://git…...