【项目实践】基于LSTM的一维数据扩展与预测
基于LSTM的一维数据拟合扩展
一、引(fei)言(hua)
我在做Sri Lanka生态系统服务价值计算时,中间遇到了一点小问题。从世界粮农组织(FAO)上获得Sri Lanka主要农作物产量和价格数据时,其中的主要作物Sorghum仅有2001-2006年的数据,而Millet只有2001-2005,2020-2021这样的间断数据。虽然说可以直接剔除这种过分缺失的数据,但这无疑会对生态因子的计算造成重大影响。所以我想要不要整个函数把他拟合一下,刚好Maize和Rice有2001-2021的完备数据,于是,这个文档就这样诞生了。
二、数据
数据来自FAO,考虑到可能有同学想要跟着尝试一下,这里给出用到的数据。
作物产量
作物价格
2.1 数据探查
我们读取数据,并进行简单的统计量查看。如果要进一步深入研究数据分布及可视化,可以看看我的这篇文章
import pandas as pdpath=r"YourPath"yield_=pd.read_csv(path+r"\yield.csv")
pp_=pd.read_csv(path+r"\Producer Prices.csv")
yield_.head()

需要用到的属性只有Item,Year,Unit,Value
所以我们做这样的处理:
yield_=yield_[["Item","Year","Unit","Value"]]
可以看到有些数据是从1961年开始的,太旧了就不用了,我们从2001年开始。
yield_=yield_[yield_["Year"]>2000]
同样,我们来看看pp_的情况:
pp_.head()

pp_=pp_[["Item","Year","Value","Element"]]
pp_=pp_[pp_["Year"]>2000]
实际上,在这个数据里,产量已经没有问题了。我们只需要做一个简单的处理:
yield_.groupby("Item").mean()["Value"]/10 #转为千克

便可拿到每种作物近二十年的平均产量。
好了现在大问题出现在价值上,我们从下往上看就知道了:
pp_.tail(10)

高粱只有2006年的,那有没有办法利用现成的数据将其扩展呢?
实际上,这类拟合问题有很多种解决方案,但是本问题涉及到时间,之前时间段的因子,以及可能的周期性,都会增加拟合的复杂性。所以,在这里我们采用LSTM来填充数据。
三、模型构建
在本小节,我们将比较传统一维CNN与RNN在结果上的异同。
一般做一维RNN时,可以指定一个时间窗口,比如用2006,2007,2008年的数据,推理2009年的数据,用2007,2008,2009年推理2010年。
我们现在要用之前处理好的pp_c数据中的玉米产量,来预测高粱产量。所以第一步就是将其转化为torch接受的格式。
别忘记导入模块:
import torch
import torch.nn as nn
from torch.nn import functional as F
x=pp_c[pp_c['Item']=="Maize (corn)"]['Value']
x=torch.FloatTensor(x)
之前写数据迭代器的时候,除了可以继承自torch.utils.data.DataLoader,也可以是任意的可迭代对象。这里我们可以简单的设置一个类:
# 设置迭代器
class MyDataSet(object):def __init__(self,seq,ws=6):# ws是滑动窗口大小self.ori=[i for i in seq[:ws]]self.label=[i for i in seq[ws:]]self.reset()self.ws=wsdef set(self,dpi):# 添加数据self.x.append(dpi)def reset(self):# 初始化self.x=self.ori[:]def get(self,idx):return self.x[idx:idx+self.ws],self.label[idx]def __len__(self):return len(self.x)
哦这边提一下,有两种方式,一种是用原始数据做预测,一种是用预测数据做预测,可能有点抽象,下面举个例子。
假设 A = [ a 1 , a 2 , a 3 , a 4 , a 5 , a 6 ] A=[a1,a2,a3,a4,a5,a6] A=[a1,a2,a3,a4,a5,a6],时间窗口大小为3。
用原始数据做预测,那么输入值为: a 1 , a 2 , a 3 a1,a2,a3 a1,a2,a3,得到的结果将与 a 4 a4 a4做比较。下一轮输入为 a 2 , a 3 , a 4 a2,a3,a4 a2,a3,a4,得到的结果将与 a 5 a5 a5做比较。
而用预测的数据做预测,第一轮输入值为 a 1 , a 2 , a 3 a1,a2,a3 a1,a2,a3,得到的结果是 b 4 b4 b4,在与 a 4 a4 a4做比较后,下一轮的输入为 a 2 , a 3 , b 4 a2,a3,b4 a2,a3,b4,会出现如下情况:
输入数据为 b 4 , b 5 , b 6 b4,b5,b6 b4,b5,b6。
我们现在举的例子是用预测的数据做预测。当然,最后也会给出一个用原始数据做预测的版本,那个版本相对简单。
ws=6 # 全局时间窗口
train_data=MyDataSet(x,ws)
网络的架构如下:
class Net3(nn.Module):def __init__(self,in_features=54,n_hidden1=128,n_hidden2=256,n_hidden3=512,out_features=7):super(Net3, self).__init__()self.flatten=nn.Flatten()self.hidden1=nn.Sequential(nn.Linear(in_features,n_hidden1,False),nn.ReLU())self.hidden2=nn.Sequential(nn.Linear(n_hidden1,n_hidden2),nn.ReLU())self.hidden3=nn.Sequential(nn.Linear(n_hidden2,n_hidden3),nn.ReLU())self.out=nn.Sequential(nn.Linear(n_hidden3,out_features))def forward(self,x):x=self.flatten(x)x=self.hidden2(self.hidden1(x))x=self.hidden3(x)return self.out(x)class CNN(nn.Module):def __init__(self, output_dim=1,ws=6):super(CNN, self).__init__()self.relu = nn.ReLU(inplace=True)self.conv1 = nn.Conv1d(ws, 64, 1)self.lr = nn.LeakyReLU(inplace=True)self.conv2 = nn.Conv1d(64, 128, 1)self.bn1, self.bn2 = nn.BatchNorm1d(64), nn.BatchNorm1d(128)self.bn3, self.bn4 = nn.BatchNorm1d(1024), nn.BatchNorm1d(128)self.flatten = nn.Flatten()self.lstm1 = nn.LSTM(128, 1024)self.lstm2 = nn.LSTM(1024, 256)self.lstm3=nn.LSTM(256,512)self.fc = nn.Linear(512, 512)self.fc4=nn.Linear(512,256)self.fc1 = nn.Linear(256, 64)self.fc3 = nn.Linear(64, output_dim)@staticmethoddef reS(x):return x.reshape(-1, x.shape[-1], x.shape[-2])def forward(self, x):x = self.reS(x)x = self.conv1(x) x = self.lr(x)x = self.conv2(x) x = self.lr(x)x = self.flatten(x)# LSTM部分x, h = self.lstm1(x)x, h = self.lstm2(x)x,h=self.lstm3(x)x, _ = hx = self.fc(x.reshape(-1, ))x = self.relu(x)x = self.fc4(x)x = self.relu(x)x = self.fc1(x)x = self.relu(x)x = self.fc3(x)return xNet3主要是一维卷积,CNN加入了LSTM结构。至于名字,是随便取的…跟内容并无关系。
def Train(model,train_data,seed=1):device="cuda" if torch.cuda.is_available() else "cpu"model=model.to(device)Mloss=100000path=r"YourPath\%s.pth"%seed# 设置损失函数,这里使用的是均方误差损失criterion = nn.MSELoss()# 设置优化函数和学习率lroptimizer=torch.optim.Adam(model.parameters(),lr=1e-5,betas=(0.9,0.99),eps=1e-07,weight_decay=0)# 设置训练周期epochs =3000criterion=criterion.to(device)model.train()for epoch in range(epochs):total_loss=0for i in range(len(x)-ws):# 每次更新参数前都梯度归零和初始化seq,y_train=train_data.get(i) # 从我们的数据集中拿出数据seq,y_train=torch.FloatTensor(seq),torch.FloatTensor([y_train])seq=seq.unsqueeze(dim=0)seq,y_train=seq.to(device),y_train.to(device)optimizer.zero_grad()# 注意这里要对样本进行reshape,# 转换成conv1d的input size(batch size, channel, series length)y_pred = model(seq)loss = criterion(y_pred, y_train)loss.backward()train_data.set(y_pred.to("cpu").item()) # 再放入预测数据optimizer.step()total_loss+=losstrain_data.reset()if total_loss.tolist()<Mloss:Mloss=total_loss.tolist()torch.save(model.state_dict(),path)print("Saving")print(f'Epoch: {epoch+1:2} Mean Loss: {total_loss.tolist()/len(train_data):10.8f}')return model
正常训练就OK
d=CNN(ws=ws)
Train(d,train_data,4)

平均损失在10点左右,还有很大优化空间。当然我们这里只是举个非常简单的例子,就是个baseline
checkpoint=torch.load(r"YourPath\4.pth")
d.load_state_dict(checkpoint) # 加载最佳参数
d.to("cpu")
四、结果可视化
我们这里用到Pyechart进行可视化。
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import CurrentConfig
pre,ppre=[i.item() for i in x[:ws]],[]
# pre 是用原始数据做预测
# ppre 用预测数据做预测
for i in range(len(x)-ws+1):ppre.append(d(torch.FloatTensor(x[i:i+ws]).unsqueeze(dim=0)))pre.append(d(torch.FloatTensor(pre[-ws:]).unsqueeze(dim=0)).item())
l=Line()
l.add_xaxis([i for i in range(len(x))])
l.add_yaxis("Original Data",x.tolist())
l.add_yaxis("Pred Data(Using Raw Datas)",x[:ws].tolist()+[i.item() for i in ppre])
l.add_yaxis("Pred Data(Using Pred Datas)",pre)
l.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
l.set_global_opts(title_opts=opts.TitleOpts(title='LSTM CNN'))l.render_notebook()
根据时间窗口的不同,可以得到不同的结果。
ws=4

ws=5

ws=6

从结果上来看,时间窗口越大越好。但是这里我们只能到六了,再大就不礼貌了。(高粱只有六个节点的数据)。
至于验证,我们可以选Rice做验证:
x=torch.FloatTensor(pp_c[pp_c['Item']=="Rice"]['Value'].tolist())
pre,ppre=[i.item() for i in x[:ws]],[]
for i in range(len(x)-ws+1):ppre.append(d(torch.FloatTensor(x[i:i+ws]).unsqueeze(dim=0)))pre.append(d(torch.FloatTensor(pre[-ws:]).unsqueeze(dim=0)).item())
l=Line()
l.add_xaxis([i for i in range(len(x))])
l.add_yaxis("Original Data",x.tolist())
l.add_yaxis("Pred Data(Using Raw Datas)",x[:ws].tolist()+[i.item() for i in ppre])
l.add_yaxis("Pred Data(Using Pred Datas)",pre)
l.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
l.set_global_opts(title_opts=opts.TitleOpts(title='LSTM CNN'))l.render_notebook()

可以发现,用预测做预测的结果,基本上不会差太多,那也就意味着,我们可以对高粱进行预测啦!不过在这之前,我们可以看看用原始数据做训练的结果:

时间窗口一样为6,可以看到在黑线贴合的非常好,但是面对大量缺失的数据,精度就远不如用预测数据做预测的结果了。
此外,这是用CNN做的结果

我们可以发现LSTM的波动要比CNN好,CNN后面死水一潭,应该是梯度消失导致的,前面信息没有了,后面信息又是自个构造的,这就导致了到后面变成了线性情况。
那么最后的最后,就是预测高粱产量了:
pre_data=pp_c[pp_c['Item']=='Sorghum']['Value'].tolist()
l=pre_data[:]
for i in range(len(x)-ws+1):l.append(d(torch.FloatTensor(l[-ws:]).unsqueeze(dim=0)).item())
L=Line()
L.add_xaxis([i for i in range(len(x))])
L.add_yaxis("Pred",l)
L.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
L.set_global_opts(title_opts=opts.TitleOpts(title='sorghum production forecasts'))L.render_notebook()
l.to_csv("path")

相关文章:
【项目实践】基于LSTM的一维数据扩展与预测
基于LSTM的一维数据拟合扩展 一、引(fei)言(hua) 我在做Sri Lanka生态系统服务价值计算时,中间遇到了一点小问题。从世界粮农组织(FAO)上获得Sri Lanka主要农作物产量和价格数据时,其中的主要作物Sorghum仅有2001-2006年的数据,而Millet只有…...

webshell实践,在nginx上实现负载均衡
1、配置多台虚拟机,用作服务器 在不同的虚拟机上安装httpd服务 我采用了三台虚拟机进行服务器设置:192.168.240.11、192.168.240.12、192.168.240.13 [rootnode0-8 /]# yum install httpd -y #使用yum安装httpd服务#开启httpd服务 [rootnode0-8 /]# …...

LVS+Keepalived集群
keepalived Keepalived及其工作原理 Keepalived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以解决静态路由出现的单点故障问题 在一个LVS服务集群中通常有主服务器(MASTER)和备份服务器(BACKUP)两种角色的服务…...

Java的网络编程
网络编程 两台设备之间通过网络实现数据传输,将数据通过网络从一台设备传输到另一台设备 网络 两台或多台设备通过一定物理设备连接起来构成了网络 网络又分为: 局域网:覆盖范围最小,仅仅覆盖一个教室或一个机房城域网:覆盖范围较大,可以…...

kafka配置远程连接
要想实现在本地连接服务器的kafka,则必须在远程kafka配置远程连接 默认的 kafka 配置是无法远程访问的,解决该问题有几个方案。 方案1 advertised.listenersPLAINTEXT://IP:9092 注意必须是 ip,不能是 hostname 方案2 advertised.listene…...

css实现渐变色border
方式1 div {border: 4px solid;border-image: linear-gradient(to right, #8f41e9, #578aef) 1; }/* 或者 */ div {border: 4px solid;border-image-source: linear-gradient(to right, #8f41e9, #578aef);border-image-slice: 1; }作者:MudOnTire 链接:…...

管理 IBM Spectrum LSF
管理 IBM Spectrum LSF 了解如何管理 IBM Spectrum LSF 集群,控制守护程序,更改集群配置以及使用主机和队列。 管理 LSF 作业和作业调度策略。 查看作业信息和控制作业。 了解如何配置资源并将其分配给 LSF 作业。 了解如何在 LSF 集群中提交࿰…...

117页数字化转型与产业互联网发展趋势及机会分析报告PPT
导读:原文《》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。 喜欢文章,您可以点赞评论转发本文,了解更多内容请私信:方…...
【JavaWeb】实训的长篇笔记(上)
JavaWeb的实训是学校的一门课程,老师先讲解一些基础知识,然后让我们自己开发一个比较简单的Web程序。可涉及的知识何其之多,不是实训课的 3 周时间可以讲得完的,只是快速带过。他说:重点是Web开发的流程。 我的实训草草…...

如何使用Docker安装AWVS?
前言 还记得很早的时候使用AWVS,还需要找位置,贴补丁,放文件,现在慢慢掌握Docker后发现,使用Docker去部署一些东西就很方便,当然也包括AWVS。 我们今天带大家通过Docker部署AWVS(有中文哦&…...

vue命名规范
文件和文件夹的命名: 文件夹命名: Vue 项目中通常可以根据功能或页面来划分文件夹。例如,您可以为每个页面创建一个文件夹,并将相关的组件、样式和资源文件放在其中。文件夹的命名最好使用短横线分隔的小写字母(kebab …...
第05天 SpringBoot自动配置原理
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏:每天一个知识点 ✨特色专栏:…...
AlphaZero能否从围棋和国际象棋飞跃到量子计算?
一项新的研究表明,DeepMind惊人的游戏算法AlphaZero可以帮助释放量子计算的力量和潜力。 自两年多前出现以来,AlphaZero一再证明了其快速学习能力,将自己提升到围棋,国际象棋和将棋(日本象棋)的特级大师级别…...

进程切换
进程切换 上下文切换上下文切换的消耗上下文切换与模式切换 对于通常的进程而言,其创建、撤销及要求由系统设备完成的IO操作,都是利用系统调用而进入内核,再由内核中的相应处理程序予以才完成的。进程切换同样是在内核的支持下实现的…...
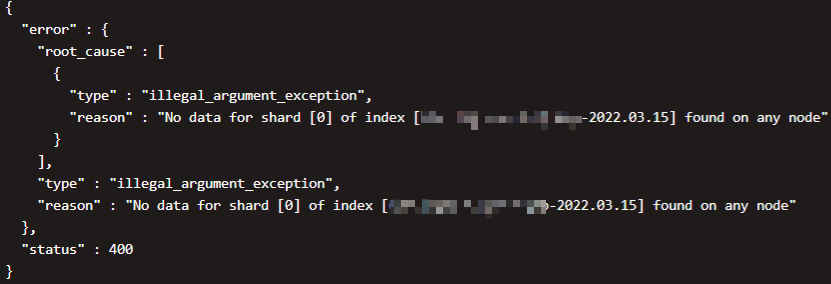
ES踩坑记录之UNASSIGNED分片无法恢复
问题背景 换节点 我们线上有一套ES集群,三台机器,共运行了6个节点。一直在线上跑了几个月也一直没出什么问题。然而好巧不巧,就在昨天,集群中的3号节点磁盘出现故障,导致机器直接瘫痪。本来大家觉得问题不大…...

ubuntu更换国内apt源
ubuntu必备操作 1 更换apt镜像源 备份镜像 cp /etc/apt/sources.list /etc/apt/sources.list.bak查看自己ubuntu版本 # 查看自己的codename #查看自己的ubuntu版本[注意关注:DISTRIB_CODENAME,发行代号] cat /etc/*release# DISTRIB_CODENAMEcosmic …...
OpenCV-Python中的图像处理-视频分析
OpenCV-Python中的图像处理-视频分析 视频分析Meanshift算法Camshift算法光流Lucas-Kanade Optical FlowDense Optical Flow 视频分析 学习使用 Meanshift 和 Camshift 算法在视频中找到并跟踪目标对象: Meanshift算法 Meanshift 算法的基本原理是和很简单的。假设我们有一堆…...
STM32 CubeMX (第四步Freertos内存管理和CPU使用率)
STM32 CubeMX STM32 CubeMX (第四步Freertos内存管理和CPU使用率) STM32 CubeMX一、STM32 CubeMX设置时钟配置HAL时基选择TIM1(不要选择滴答定时器;滴答定时器留给OS系统做时基)使用STM32 CubeMX 库,配置Fr…...

题解 | #1012.Equalize the Array# 2023杭电暑期多校10
1012.Equalize the Array 签到 题目大意 定义一个数组的 m o d e mode mode 是其中出现次数最多的数字(可不唯一) 给定一个数组 a a a ,每次操作可以选定其一个 m o d e mode mode 并使数组中所有与之相等的元素 1 1 1 问任意次操作后…...
)
UE4/5C++多线程插件制作(二十一、使用)
目录 DemoPawn.h DemoPawn.cpp 会出现的bug 插件 相关的插件制作在上一节已经完成了。 具体的使用方式在第0章已经写了,get之后去绑定即可。 而后笔者做了一个接口,具体的绑定方式也就在这个接口里面。 接下来最重要的是进行使用,对此我做了一个与蓝图相关的接口,里…...
)
Vivado工程文件太大?三步教你用Tcl脚本实现源码“瘦身”与备份(附完整命令)
Vivado工程瘦身实战:Tcl脚本驱动的源码管理与协作优化 在FPGA开发领域,Vivado工程文件的体积膨胀问题一直是开发者面临的痛点。一个中等规模的项目经过几次综合与实现后,工程目录轻松突破数百MB并不罕见。这不仅占用宝贵的存储空间ÿ…...

PX4飞控IMU频率上不去?手把手教你用MAVLink命令和SD卡配置文件,稳定提升到200Hz
PX4飞控IMU频率优化实战:从原理到200Hz稳定配置 引言 在无人机开发领域,IMU数据的高频采集对于飞行控制精度至关重要。许多开发者在使用PX4飞控时都遇到过这样的困扰:默认的50Hz IMU频率无法满足高动态飞行需求,而手动调整后要么…...

深入RISC-V链接脚本:从.lds文件看C程序的内存‘出生’与‘搬家’全过程
深入RISC-V链接脚本:从.lds文件看C程序的内存‘出生’与‘搬家’全过程 在嵌入式开发的世界里,一个C程序从源代码到最终在硬件上运行,经历了编译、链接和加载三个关键阶段。这个过程就像一个人的生命历程:编译是"出生"&…...

tabtoy性能优化秘籍:多核并发导出与缓存加速技巧
tabtoy性能优化秘籍:多核并发导出与缓存加速技巧 【免费下载链接】tabtoy 高性能表格数据导出器 项目地址: https://gitcode.com/gh_mirrors/ta/tabtoy 在处理大量表格数据导出时,性能往往是开发者面临的主要挑战。tabtoy作为一款高性能表格数据导…...

VMware macOS解锁神器:Unlocker 3.0终极完整指南
VMware macOS解锁神器:Unlocker 3.0终极完整指南 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 想要在Windows或Linux电脑上体验macOS系统,却苦于VMware默认不支持苹果系统&…...

基于Arduino与IRLib2的万能遥控器DIY:从红外解码到蓝牙HID的嵌入式实践
1. 项目概述与核心价值如果你和我一样,家里电视、机顶盒、音响、空调的遥控器堆满了茶几,每次想用都得翻找半天,或者你正在为一位行动不便的亲友寻找一种更便捷的控制家电的方式,那么这个基于Arduino和IRLib2的万能遥控器DIY项目&…...

对抗测试框架:用字节码增强与混沌工程提升系统韧性
1. 项目概述:一个对抗测试的“剧院”最近在开源社区里,我注意到一个名字挺有意思的项目,叫nanami7777777/anti-test-theater。乍一看,这个标题有点让人摸不着头脑——“反测试剧院”?测试和剧院能扯上什么关系…...
:Offload、Flow、NUMA、IOVA 与性能剖析)
DPDK 教程(四):Offload、Flow、NUMA、IOVA 与性能剖析
DPDK 教程(四):Offload、Flow、NUMA、IOVA 与性能剖析 本文对应学习路径第四步:在已能跑通 多队列转发 后,把系统从“能跑”推到“可解释、可优化”。重点放在:硬件卸载的正确语义、Flow 与 RSS 的分工、NU…...

RAG已死?收藏这篇,小白程序员必看:上下文工程才是大模型未来!
本文探讨了围绕RAG技术的争议,分析了三种不同观点:RAG正进化为更智能的检索系统、RAG已成为核心工程学科、RAG正被长上下文和智能体取代。文章指出,简单的RAG已过时,但提供外部知识的需求依然存在,未来RAG将作为组件之…...
)
数据库角色管理(Role Management)
1.1、角色基础角色是权限的集合,是 Oracle 权限管理的核心机制。12c 增强了角色的安全特性。创建角色:CREATE ROLE app_developer;创建带密码的角色(需激活时提供密码):CREATE ROLE sensitive_role IDENTIFIED BY &quo…...