[python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度、搜狗、googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨。同时,作者将进一步帮你巩固selenium自动化操作和urllib库等知识。
一. 引入Selenium自动爬取百度图片
下面这部分Selenium代码的主要功能是:
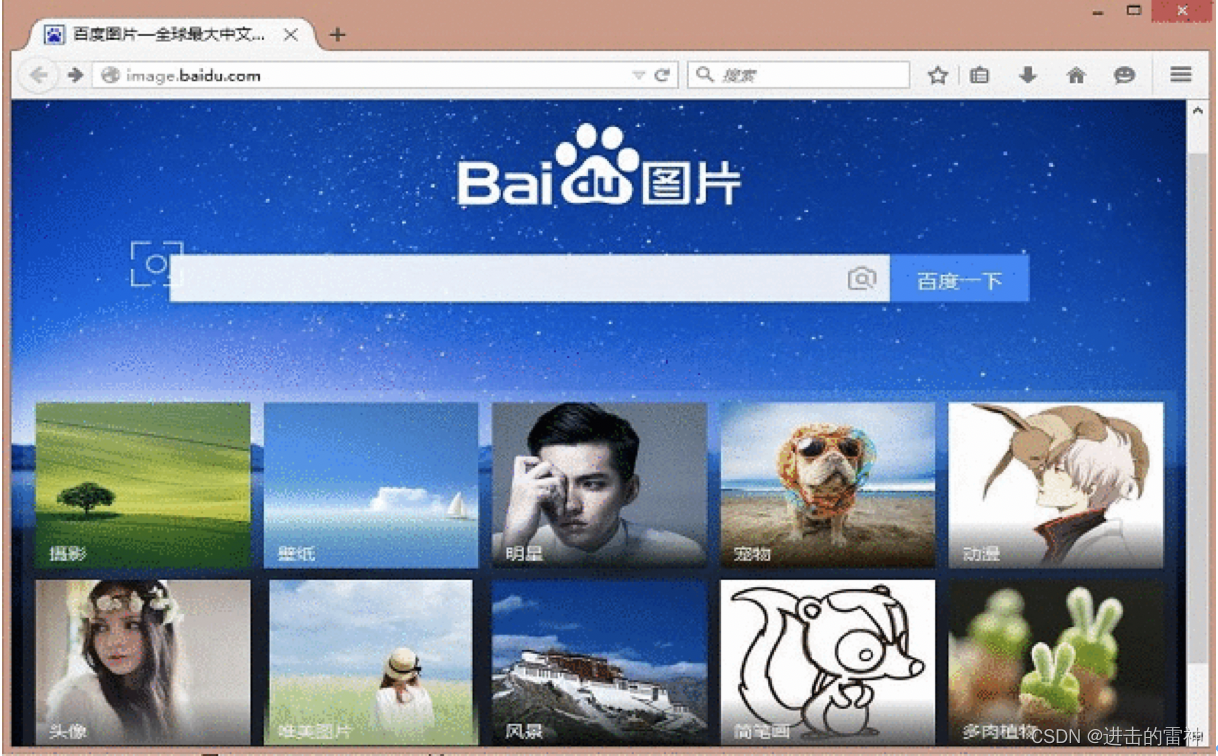
1.先自动运行浏览器,并访问百度图片链接:百度图片-发现多彩世界
2.通过driver.find_element_by_xpath()函数获取输入框的位置;
3.在输入框中自动输入搜索关键词"邓肯",再输入回车搜索"邓肯"相关图片;
4.再通过find_element_by_xpath()获取图片的原图url,这里仅获取一张图片;
5.调用urllib的urlretrieve()函数下载图片。
最后整个动态效果如下图所示,但是图片却无法显示:
代码如下:
# -*- coding: utf-8 -*-
importurllib
importre
importtime
importos
fromselenium import webdriver
fromwebdriver.common.keys importKeys
importwebdriver.support.ui as ui
fromwebdriver.common.action_chains importActionChains #Open PhantomJS
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10) #Search Picture By Baidu
url = "http://image.baidu.com/"
name = u"邓肯"
get(url)
elem_inp = driver.find_element_by_xpath("//form[@id='homeSearchForm']/span[1]/input")
send_keys(name)
send_keys(Keys.RETURN)
sleep(5) #Get the URL of Pictures
#elem_pic = driver.find_element_by_xpath("//div[@class='imgpage']/ul/li/div/a")
elem_pic = driver.find_element_by_xpath("//div[@class='imgpage']/ul/li/div/a/img")
elem_url = elem_pic.get_attribute("src")
printelem_url #Download Pictures
get(elem_url)
urlretrieve(elem_url,"picture.jpg")
print"Download Pictures!!!"二. 简单分析原因及知识巩固
1.urllib.urlretrieve()
通过urlretrieve()函数可设置下载进度发现图片是一下子就加载的。这里给大家巩固这个urlretrieve函数的方法和Python时间命名方式,代码如下:
# -*- coding: utf-8 -*-
importurllib
importtime
importos #显示下载进度
defschedule(a,b,c):
#a:已下载的数据块 b:数据块的大小 c:远程文件的大小
per = 100.0 * a * b / c
ifper > 100 :
per = 100
print'%.2f%%' % per if__name__ == '__main__':
url = "http://img4.imgtn.bdimg.com/it/u=3459898135,859507693&fm=11&gp=0.jpg"
#定义文件名时间命名
t = time.localtime(time.time())
#反斜杠连接多行
filename = str(t.__getattribute__("tm_year")) + "_"+ \
str(t.__getattribute__("tm_mon")) + "_"+ \
str(t.__getattribute__("tm_mday"))
target = "%s.jpg"% filename
printtarget
urlretrieve(url,target,schedule)
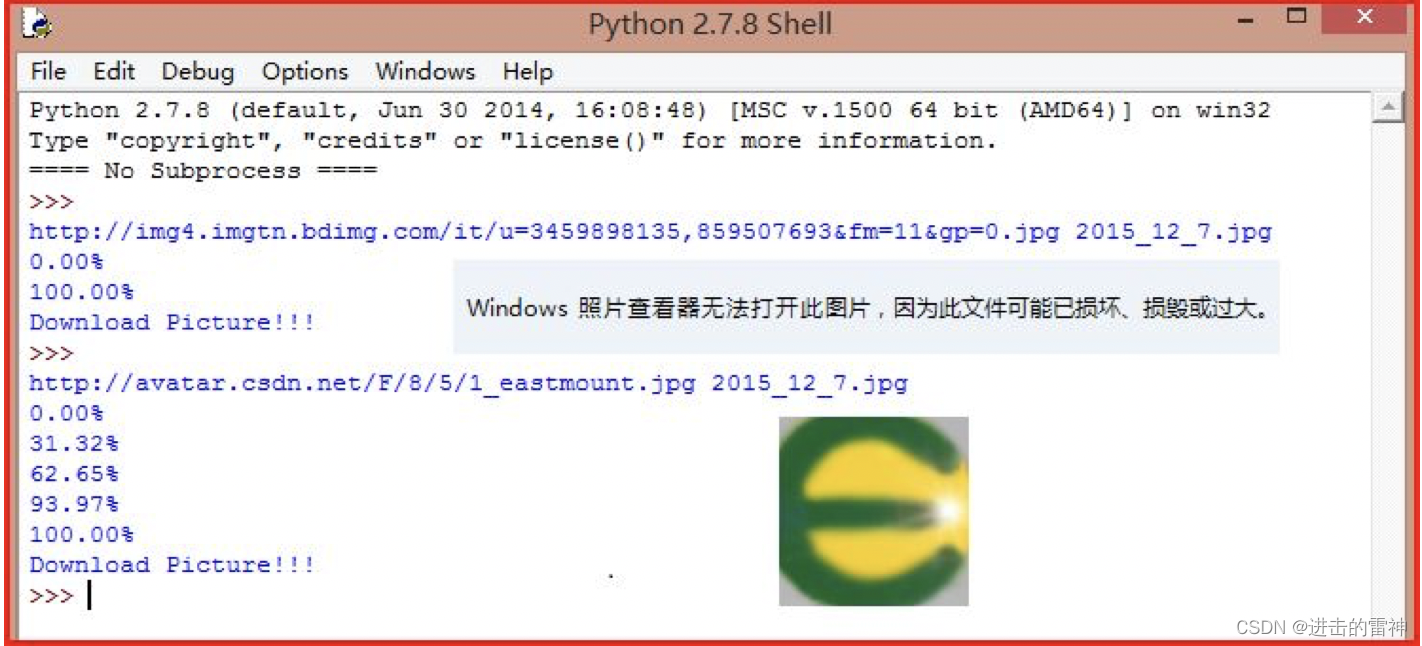
print"Download Picture!!!" 发现该图片的大小仅为168字节,其中输出结果如下图,获取的URL地址如下:
页面不存在_百度搜索
而换张图片是能显示下载进度的,如我的头像。显然我想让程序加个进度就能爬取图片的想法失败。头像地址:https://avatar.csdn.net/F/8/5/1_eastmount.jpg
猜测可能获取的百度URL不是原图地址,或者是个服务器设置了相应的拦截或加密。参考"Python爬虫抓取网页图片",函数相关介绍如下:
>>> help(urllib.urlretrieve)
Help on function urlretrieve inmodule urllib:
urlretrieve(url, filename=None, reporthook=None, data=None) 参数url:
指定的下载路径
参数finename:
指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
参数reporthook:
是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,
我们可以利用这个回调函数来显示当前的下载进度。
参数data:
指post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,
filename 表示保存到本地的路径,header 表示服务器的响应头。 2.urllib2.urlopen()
换个方法urlopen()实现,同时设置消息头试试,并输出信息和图片大小。
# -*- coding: utf-8 -*-
importos
importsys
importurllib
importurllib2 #设置消息头
url = "http://img4.imgtn.bdimg.com/it/u=3459898135,859507693&fm=11&gp=0.jpg"
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/35.0.1916.114 Safari/537.36',
'Cookie': 'AspxAutoDetectCookieSupport=1'
}
request = urllib2.Request(url, None, header)
response = urllib2.urlopen(request)
printheaders['Content-Length'] with open("picture.jpg","wb") as f:
write(response.read())
printgeturl()
printinfo() #返回报文头信息
printurlopen(url).read() 返回内容是”HTTPError: HTTP Error 403: Forbidden“,Selenium打开如下: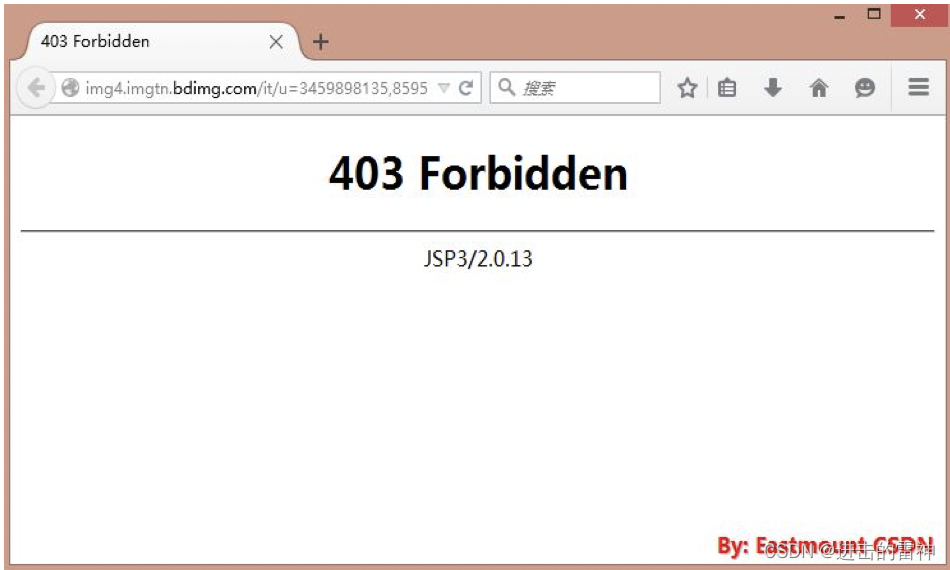
其中403错误介绍如下,服务器拒绝服务:

换成我的博客图像那张图是能下载的,同时设置消息头和代理,推荐一篇文章:
[Python]网络爬虫(五):urllib2的使用细节与抓站技巧
三. 解决方法
主要参考三篇文章和自己的一些想法:
selenium+python 爬取网络图片(2) -- 百度
Python 3 多线程下载百度图片搜索结果
CSDN博客搬家到WordPress - curl设置headers爬取
第一个方法 F12审查元素和SRC的骗局
这是感谢"露为霜"同学提供的方法,如果你通过浏览器点开百度搜索"邓肯"的第一张图片,复制网址后,会发现图片真实的地址为:
http://gb.cri.cn/mmsource/images/2015/11/22/sb2015112200073.jpg
此时你再分析百度搜索页面,你会发现"F12审查元素和获取src元素的行为欺骗了你",正是因为它俩定位到了错误的图片链接。而真实的URL是在"ul/li/"中的"data-objurl"属性中。
代码如下:
# -*- coding: utf-8 -*-
importurllib
importre
importtime
importos
fromselenium import webdriver
fromwebdriver.common.keys importKeys
importwebdriver.support.ui as ui
fromwebdriver.common.action_chains importActionChains #Open PhantomJS
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10) #Search Picture By Baidu
url = "http://image.baidu.com/"
name = u"邓肯"
get(url)
elem_inp = driver.find_element_by_xpath("//form[@id='homeSearchForm']/span[1]/input")
send_keys(name)
send_keys(Keys.RETURN)
sleep(5) #Get the URL of Pictures
num = 1
elem_pic = driver.find_elements_by_xpath("//div[@class='imgpage']/ul/li")
forelem inelem_pic:
elem_url = elem.get_attribute("data-objurl")
printelem_url
#Download Pictures
name = "%03d"% num
urlretrieve(elem_url, str(name) + ".jpg")
num = num + 1
else:
print"Download Pictures!!!" 运行代码成功爬取了9张图片,显然成功了!虽然最后报错:IOError: [Errno socket error] [Errno 10060] ,只爬取了9张图片,但是至少可以正确解决了该问题。运行截图如下所示:
同样的道理,googto的elem.get_attribute("src")改成elem.get_attribute("data-imgurl")即可获取正确的图片地址并正确下载。
PS:百度图片动态加载的功能是非常强大的,当你的鼠标拖动时,它会自动增加新的页面,在<ul>中包括新的一批<li>张图片,这也是不同于其它网页在右下角点击"1、2、3..."翻页的,可能也会成为海量图片爬取的又一难点。
第二个方法 Selenium使用右键另存为
还是使用老的链接,虽然读取是无法显示的,但尝试通过Selenium的鼠标右键另存为功能,看能不能爬取成功。
# -*- coding: utf-8 -*-
importurllib
importre
importtime
importos
fromselenium import webdriver
fromwebdriver.common.keys importKeys
importwebdriver.support.ui as ui
fromwebdriver.common.action_chains importActionChains #Open PhantomJS
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10) #Search Picture By Baidu
url = "http://image.baidu.com/"
name = u"邓肯"
get(url)
elem_inp = driver.find_element_by_xpath("//form[@id='homeSearchForm']/span[1]/input")
send_keys(name)
send_keys(Keys.RETURN)
sleep(5) #Get the URL of Pictures
elem_pic = driver.find_element_by_xpath("//div[@class='imgpage']/ul/li/div/a/img")
elem_url = elem_pic.get_attribute("src")
printelem_url #鼠标移动至图片上右键保存图片
get(elem_url)
printpage_source
elem = driver.find_element_by_xpath("//img")
action = ActionChains(driver).move_to_element(elem)
context_click(elem) #右键#当右键鼠标点击键盘光标向下则移动至右键菜单第一个选项
send_keys(Keys.ARROW_DOWN)
send_keys('v') #另存为
perform()
print"Download Pictures!!!" 运行效果如下图所示。虽然它能实现右键另存为,但是需要手动点击保存,其原因是selenium无法操作操作系统级的对话框,又说"set profile"代码段的设置能解决问题的并不靠谱。通过钩子Hook函数可以实现,以前做过C#的钩子自动点击功能,但是想到下载图片需要弹出并点击无数次对话框就很蛋疼,所以该方法并不好!
钩子函数java版本结合robot可以阅读下面这篇文章:
selenium webdriver 右键另存为下载文件(结合robot and autoIt)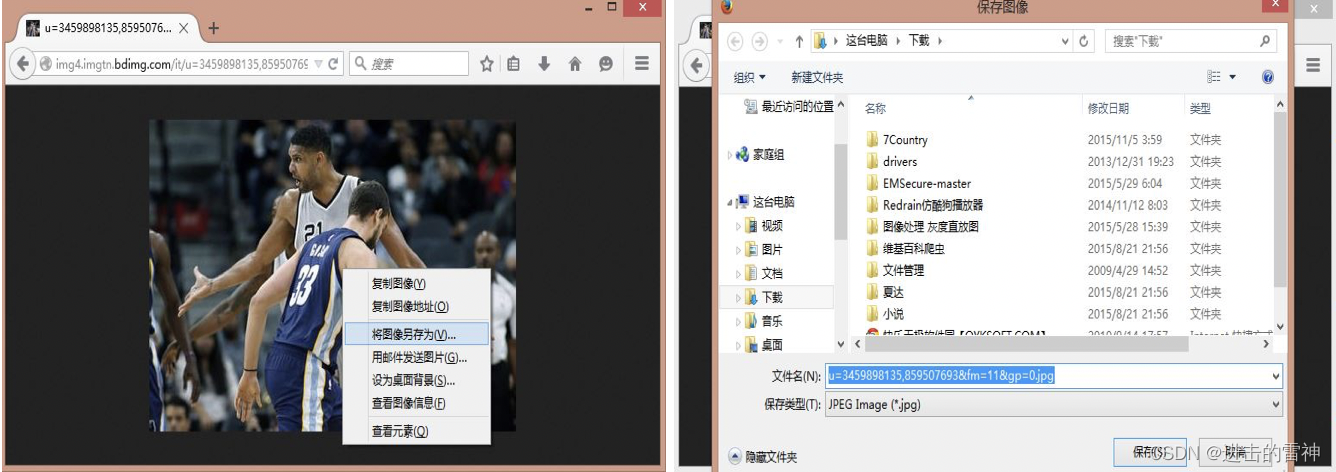
第三个方法 通过Selenium自动点击百度的下载按钮
其实现过程就是通过Selenium找到"下载"按钮,再点击或获取链接即可。
该方法参考文章:selenium+python 爬取网络图片(2) -- 百度
同时,这里需要强调百度动态加载,可以通过Selenium模拟滚动窗口实现,也参考上面文章。其中核心代码为:
driver.maximize_window()pos += i*500 # 每次下滚500js = "document.documentElement.scrollTop=%d" % posdriver.execute_script(js)
第四个方法 百度图片解码下载及线程实现
参考文章:Python 3 多线程下载百度图片搜索结果
相关文章:
[python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度、搜狗、googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨。同时,作者将进一步帮你巩固selenium自动化操作和urllib…...

vue项目预览pdf功能(解决动态文字无法显示的问题)
最近,因为公司项目需要预览pdf的功能,开始的时候找了市面上的一些pdf插件,都能用,但是,后面因为pdf变成了需要根据内容进行变化的,然后,就出现了需要动态生成的文字不显示了。换了好多好多的插件…...

vue3 样式穿透:deep不生效
初学vue3,今天需要修改el-input组件的属性(去掉border和文字居右) 网上搜了一下,大致都是采用:deep 样式穿透来修改el-input的属性 <div class"input-container"><el-input placeholder"请输入111&qu…...
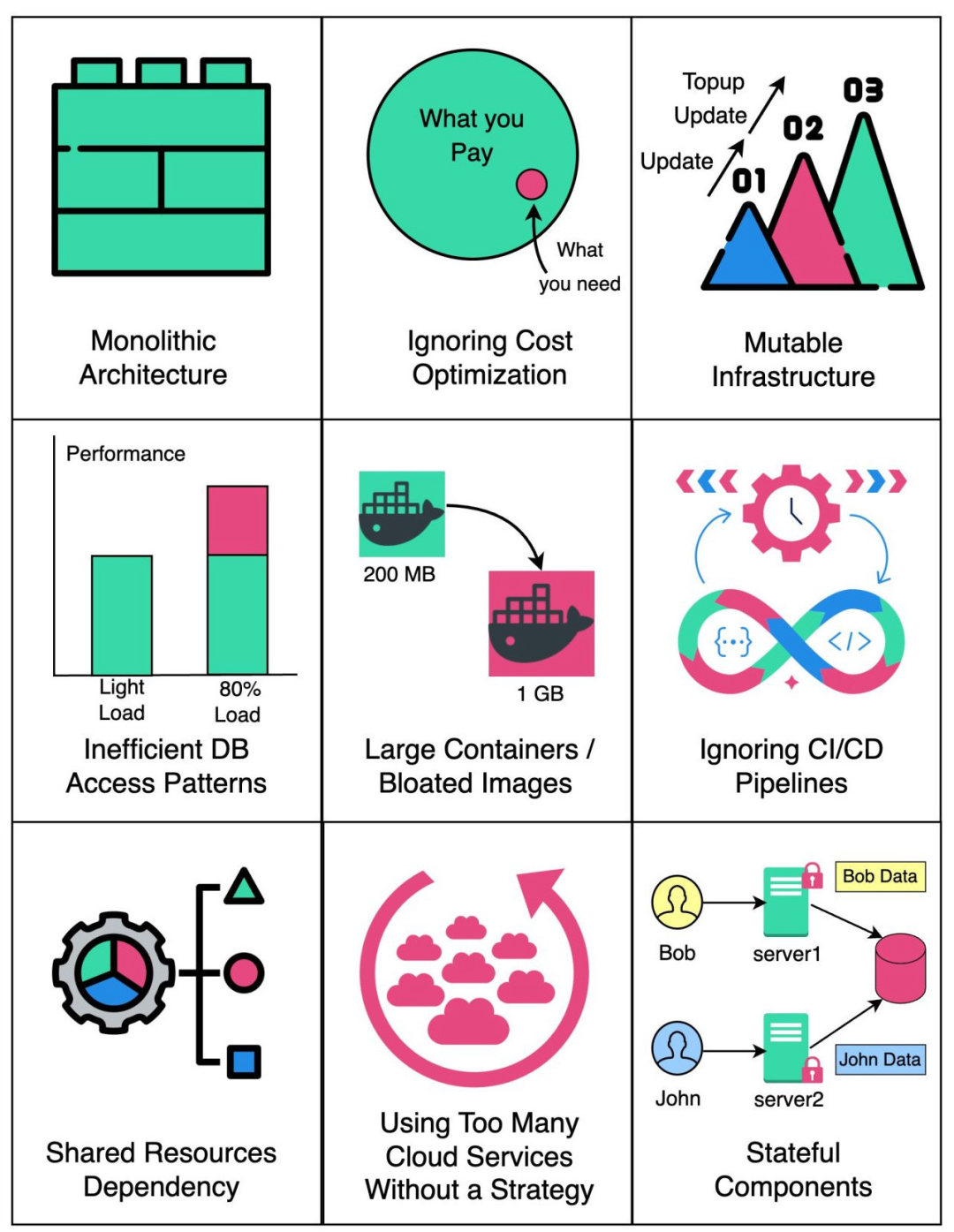
云原生反模式
通过了解这些反模式并遵循云原生最佳实践,您可以设计、构建和运营更加强大、可扩展和成本效益高的云原生应用程序。 1.单体架构:在云上运行一个大而紧密耦合的应用程序,妨碍了可扩展性和敏捷性。2.忽略成本优化:云服务可能昂贵&am…...
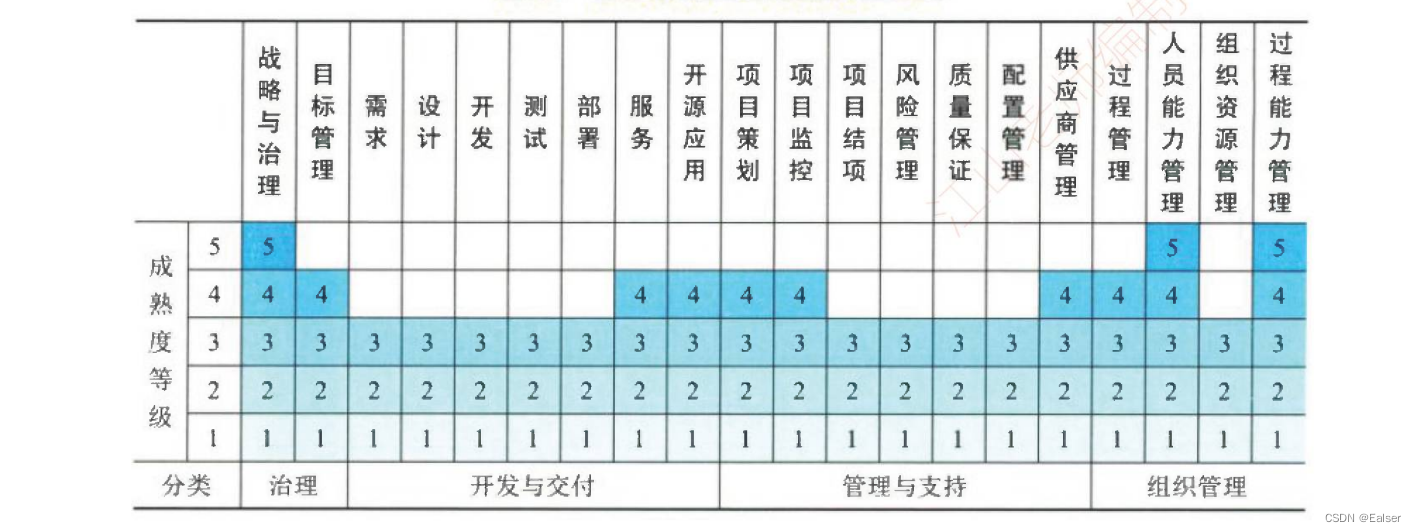
【2023年11月第四版教材】《第5章-信息系统工程(合集篇)》
《第5章-信息系统工程(合集篇)》 章节说明1 软件工程1.1 架构设计1.2 需求分析1.3 软件设计1.4 软件实现[补充第三版教材内容] 1.5 部署交付 2 数据工程2.1 数据建模2.2 数据标准化2.3 数据运维2.4 数据开发利用2.5 数据库安全 3 …...

【qiankun】微前端在项目中的具体使用
1、安装qiankun npm install qiankun --save2、主应用中注册和配置qiankun 在主应用的入口文件main.ts中,引入qiankun的注册方法: import { registerMicroApps, start } from qiankun;创建一个数组,用于配置子应用的相关信息。每个子应用都…...

云安全与多云环境管理:讨论在云计算和多云环境下如何保护数据、应用程序和基础设施的安全
随着云计算和多云环境的广泛应用,企业正面临着数据、应用程序和基础设施安全的新挑战。在这个数字化时代,保护敏感信息和业务运作的连续性变得尤为重要。本文将深入探讨在云计算和多云环境下如何有效地保护数据、应用程序和基础设施的安全。 章节一&…...
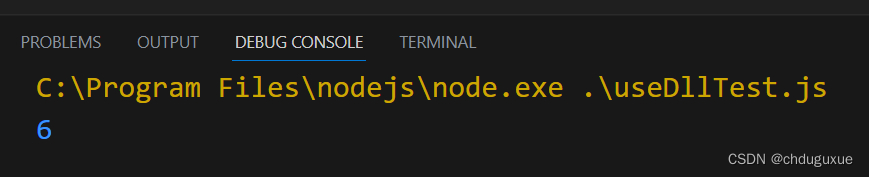
npm install ffi各种失败,换命令npm i ffi-napi成功
网上各种帖子安装ffi,基本上到了windows build tools这里会卡住。 使用命令npm install --global --production windows-build-tools 安装报错信息如下: PS E:\codes\nodejsPath\tcpTest> npm install --global --production windows-build-tools …...

0.flink学习资料
论文: (1)google dataflow model 下载链接:p1792-Akidau.pdf (vldb.org) Akidau T, Bradshaw R, Chambers C, et al. The dataflow model: a practical approach to balancing correctness, latency, and cost in massive-scal…...

C语言:字符函数和字符串函数
往期文章 C语言:初识C语言C语言:分支语句和循环语句C语言:函数C语言:数组C语言:操作符详解C语言:指针详解C语言:结构体C语言:数据的存储 目录 往期文章前言1. 函数介绍1.1 strlen1.…...
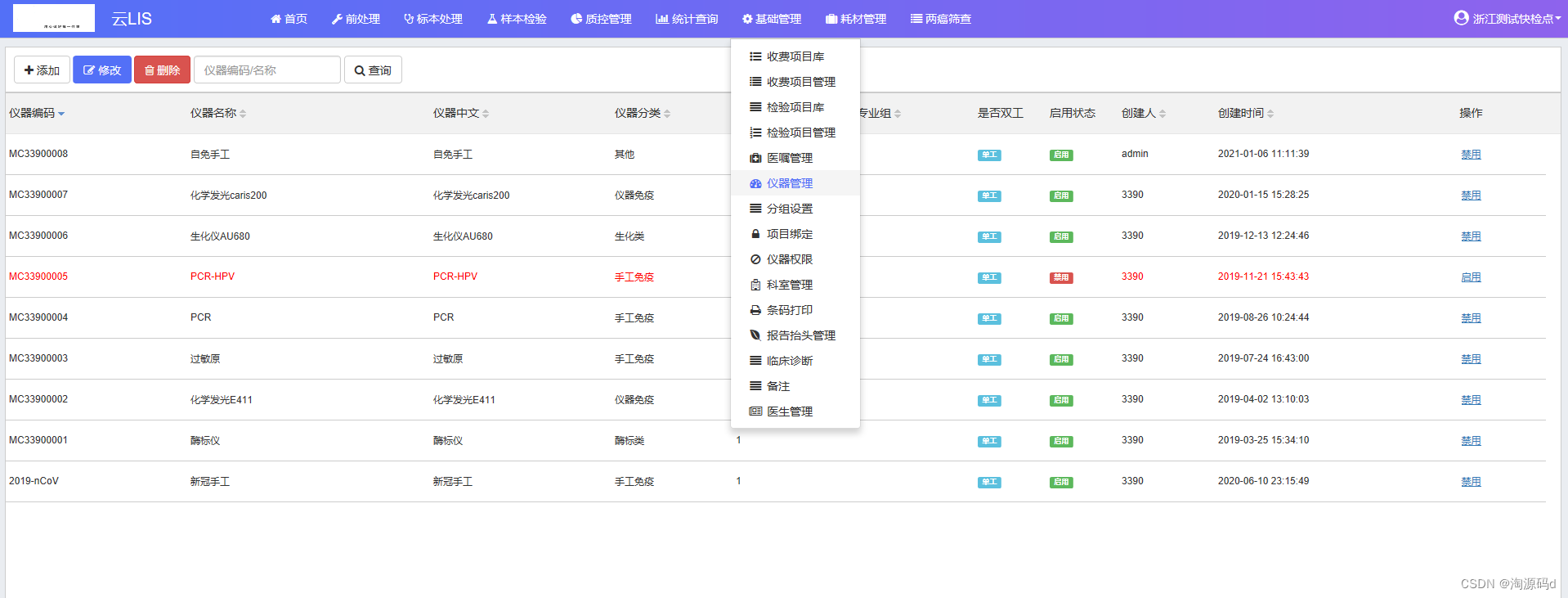
基于.Net Core开发的医疗信息LIS系统源码
SaaS模式.Net Core版云LIS系统源码 医疗信息LIS系统是专为医院检验科设计的一套实验室信息管理系统,能将实验仪器与计算机组成网络,使病人样品登录、实验数据存取、报告审核、打印分发,实验数据统计分析等繁杂的操作过程实现了智能化、自动化…...

部署工业物联网可以选择哪些通信方案?
部署工业物联网有诸多意义,诸如提升生产效率,降低管理成本,保障生产品质稳定,应对长期从业劳动力变化趋势等。针对不同行业、场景,工业物联网需要选择不同的通信方案,以达到成本和效益的最佳平衡。本篇就简…...

flutter-移动端适配
不同屏幕之间的尺寸适配 使用插件 flutter_screenutil flutter_screenutil flutter 屏幕适配方案,用于调整屏幕和字体大小的flutter插件,让你的UI在不同尺寸的屏幕上都能显示合理的布局! 安装 # add flutter_screenutil flutter_screenutil: ^5.8.4 o…...

MySQL 常用函数
一、数学函数 1、ABS(x) 返回绝对值。 mysql> select abs(-4); --------- | abs(-4) | --------- | 4 | --------- 1 row in set (0.00 sec) 2、PI() 返回圆周率,并四舍五入保留五位小数。 mysql> select pi(); ----------…...

动态路由的实现—正则表达式
文章目录 前言一、什么是正则表达式?二、正则表达式在动态路由中的作用三、实现一个简单的路由调度器总结 前言 动态路由有很多种实现方式,支持的规则、性能等有很大的差异。例如开源的路由实现gorouter支持在路由规则中嵌入正则表达式,例如…...

Android实现超出固定行数折叠文字“查看全文“、“收起全文“
先上效果图 分析问题 网上有很多关于这个的代码,实现都过于复杂了,github上甚至还看到一篇文章600多行代码,结果一跑起来全是bug。还是自己写吧!!! 如果我们需要换行的"查看全文"、"收起全…...

Python上楼梯问题:递归解法探究(斐波那契变种)(记忆化递归)
文章目录 上楼梯问题:递归解法探究问题定义解决方案1. 递归2. 记忆化递归关于python memo{}默认参数和字典的语法语法功能版本信息注意事项 结论 上楼梯问题:递归解法探究 在这篇文章中,将对上楼梯问题进行深入探讨。上楼梯问题是一种常见的…...

AI重新定义音视频生产力“新范式”
// 编者按:AIGC无疑是当下的热门话题和场景。面对AI带来的技术变革和算力挑战,该如何应对?LiveVideoStackCon 2023上海站邀请到了网心科技副总裁武磊为我们分享网心在面对AI应用场景和业务需求下的实践经验。 文/武磊 编辑/LiveVideoStack …...

Jmeter生成可视化的HTML测试报告
Jmeter也是可以生成测试报告的。 性能测试工具Jmeter由于其体积小、使用方便、学习成本低等原因,在现在的性能测试过程中,使用率越来越高,但其本身也有一定的缺点,比如提供的测试结果可视化做的很一般。 不过从3.0版本开始&…...

5G技术与其对智能城市、物联网和虚拟现实领域的影响
随着第五代移动通信技术(5G)的到来,我们即将迈向一个全新的数字化世界。5G技术的引入将带来更高的速度、更低的延迟和更大的连接性,推动了智能城市、物联网和虚拟现实等领域的发展。 首先,5G技术将带来超越以往的网络速…...

抖音视频批量下载难题如何解决?douyin-downloader开源工具完整指南
抖音视频批量下载难题如何解决?douyin-downloader开源工具完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fa…...

超自动化巡检:如何应对海量增长的基础设施?
在数字化转型的浪潮中,企业IT基础设施正经历着前所未有的指数级增长。从物理服务器到虚拟机,从容器集群到云原生环境,从传统数据中心到边缘节点,运维对象的数量与种类正在以几何级数膨胀。某大型企业单日告警量可达130万条&#x…...

1 个开发技巧,餐饮小程序加载速度飙升 70%
对于餐饮小程序而言,加载速度直接决定用户留存——据调研,用户打开小程序后,若加载时间超过3秒,流失率会高达80%。很多餐饮门店的小程序,明明功能完善、设计美观,却因为加载缓慢,导致用户刚打开…...
)
攻防世界——echo-server(花指令)
查壳 elf Ubuntu系统写的,用kali运行会报错找到主函数,双击进入loc_80487C1不是很懂,看了大佬的说是花指令常见的花指令机器码 9A,E8,E9,EB 把垃圾数据用nop(0x90h)填充切换到汇编试图将loc_80487C1右键转换成未定义的数据对loc_80487C4进行c…...
)
2026年Java面试高频考点终极整理(纯干货,建议直接背诵)
Java 面试 Java 作为编程语言中的 NO.1,选择入行做 IT 做编程开发的人,基本都把它作为首选语言,进大厂拿高薪也是大多数小伙伴们的梦想。以前 Java 岗位人才的空缺,而需求量又大,所以这种人才供不应求的现状,就是 Java 工程师的薪…...

【AI面试临阵磨枪-56】大模型服务部署:Docker、K8s、GPU 调度、推理加速
一、 面试题目在生产环境中部署大模型服务时,你是如何结合 Docker 和 K8s 实现高效治理的?特别是在 GPU 调度(如共享、切分) 和 推理加速(如 vLLM, TensorRT-LLM) 方面有哪些实战经验?二、 知识…...

Code-Captain:一体化开发工作流自动化工具的设计与实践
1. 项目概述:一个为开发者打造的“全能副驾”最近在 GitHub 上看到一个挺有意思的项目,叫devobsessed/code-captain。光看这个名字,你可能会联想到“代码船长”或者“开发指挥官”之类的形象。没错,这个项目的核心定位,…...

瑞萨e² studio嵌入式IDE深度解析:从图形化配置到多核开发的实战指南
1. 项目概述:为什么我们需要关注e studio?如果你是一位嵌入式开发者,尤其是长期耕耘在瑞萨电子(Renesas)MCU生态中的朋友,那么对e studio这个名字一定不会陌生。它不是一个横空出世的全新IDE,而…...

Ds18b20数字温度传感器
模拟温度传感器: 热敏电阻,, 输出的电压随着温度变化 将变化的电压值,,转化成数字信号,,, 这就是模拟传感器,,比较复杂,,这个数据只是…...

Kraken P2P镜像分发:解决大规模容器化部署的镜像仓库瓶颈
1. 项目概述:一个为容器镜像分发而生的“海妖”如果你在容器化这条路上走得足够远,尤其是在处理大规模、多集群、跨地域的镜像分发时,大概率会遇到一个共同的痛点:镜像仓库成了瓶颈。无论是自建的Harbor、Docker Registry…...