爬虫百度返回“百度安全验证”终极解决方案
这篇文章也可以在我的博客查看
爬不了啊!!
最近一哥们跟我说百度爬虫爬不了
弹出:“百度安全验证”,“网络不给力,请稍后重试”
说到爬虫,这里指的是Python中最常用的requests库
我说怎么爬不了了?
user-agent加了吗?cookie加了吗?
他说都加了
我不信邪,试了一下,超,真的返回百度安全认证:
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="utf-8"><title>百度安全验证</title><!-- 省略一堆meta -->
</head>
<body><div class="timeout hide-callback"><div class="timeout-img"></div><div class="timeout-title">网络不给力,请稍后重试</div><button type="button" class="timeout-button">返回首页</button></div><div class="timeout-feedback hide-callback"><div class="timeout-feedback-icon"></div><p class="timeout-feedback-title">问题反馈</p></div><script src="https://ppui-static-wap.cdn.bcebos.com/static/touch/js/mkdjump_v2_21d1ae1.js"></script>
</body>
</html>
网络有说加Accept header的,我试了,也不行。
我的代码是这样的:
import requestsheaders={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
'Accept-Encoding': 'gzip, deflate, br',
'Cookie': '[yummy cookies ^_^]',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7'
}
response = requests.get('https://baidu.com/s', headers=headers)
response.encoding = 'utf-8'
print(response.text)
我纳闷了,怎么回事呢?
考虑到爬虫其实也是访问网站的过程
此时应该使用fiddler的Composer对需要爬取的报文进行调试
通过不断地增加、减少header项,最终得出必要的headers
到最后,发现请求百度所必须的数据其实只有:
以下是Fiddler Composer的raw输入
GET https://xueshu.baidu.com/s?wd=%E5%9B%BE%E5%83%8F%E9%87%8D%E5%BB%BA%E3%80%81%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0 HTTP/1.1
Host: xueshu.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36
Accept-Encoding: gzip, deflate, br
Cookie: [yummy cookies ^_^]
也就是:
User-AgentCookieAccept-Encoding
但是……我之前的代码已经包含这些了啊?还赠送了一个Accept呢?
分析真正问题
这是我突然意识到一个事儿……
说到底,Fiddler不也是机器人吗?
为啥Fiddler能发出去,但Python的requests发不出去啊
难道是requests被抓到小鸡脚了吗?
一波考虑之后 感觉有可能
Fiddler虽然也是机器人,但它作为一个流量转发工具,它很完善,行为更像浏览器
而requests相反,它本来就不是用作浏览器访问,而是以最轻便方式执行http请求
其中可能某些浏览器应有的行为,被requests阉割掉了,然后被百度识别出来了
爆破
好吧,但不管怎样,你百度还是需要提供服务的
requests虽然因为不是浏览器被你识别出来了,那我用浏览器访问你,你又该如何应对?
因此祭出爬虫的宇宙终极答案:无头浏览器
Selenium
Selenium是一个用于自动化浏览器操作的工具,常用于测试网页应用程序和执行Web任务
它提供了多种编程语言的客户端库,如Python、Java、C#等,用于控制浏览器的行为
通过编写代码,可以模拟用户在浏览器中的操作,比如点击链接、填写表单、提交数据等
OK很好,我们就用Selenium进行爬虫
安装环境
Selenium
我们需要下载python的Selenium库,执行:
pip install -U selenium
浏览器
你需要一个真的浏览器以进行网上冲浪,希望你有一个_
Linux shell玩家也可以安装浏览器
不过就不在此展开了
浏览器驱动
需要安装与你浏览器对应的浏览器驱动(Browse Driver)以供Selenium调用
这里也不详细展开,但大致分两种做法:
手动安装
注意下的是Driver,别下成浏览器本身了
无非就是到官网下,比如:
- Chrome的最新版
- Chrome 114以前
自动安装
可以使用webdriver-manager Python库实现自动化安装管理
pip install webdriver-manager
调用就自动安装,比如Chrome:
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManagerdriver = webdriver.Chrome(ChromeDriverManager().install())
爬就爬,我最会爬了
那就给大伙用Selenium爬一个
编写以下代码,唯一需要注意的就是Driver的路径需要更改(我放到项目根目录了,所以直接写文件名):
from selenium import webdriver
from selenium.webdriver.chrome.options import Options# 我们并不需要浏览器弹出
options = Options()
options.headless = True# 启动浏览器的无头模式,访问
driver = webdriver.Chrome('chromedriver.exe', options=options)
driver.get("https://xueshu.baidu.com/s?wd=图像重建、深度学习")# 获取页面的源代码
page_source = driver.page_source
# 输出页面源代码
print(page_source)driver.quit()
无头浏览器将会为你操办一切,直接访问到页面
不仅不需要cookie(在非登录的情况下),甚至连header都不需要
问题
你可能会感觉得到,这东西运行起来比requests慢
我只能说确实,因为它是真浏览器
但是……你真的需要快吗?
- 爬虫太快也是会被封IP的
- 如果你配置了IP池、多线程一系列框架,还需要在乎这点速度差距吗?
慢还有一个好处,它更像人工行为了,它能难被检测出了,嘻嘻
那今天的爬虫就到这了,该睡觉了
相关文章:

爬虫百度返回“百度安全验证”终极解决方案
这篇文章也可以在我的博客查看 爬不了啊!! 最近一哥们跟我说百度爬虫爬不了 弹出:“百度安全验证”,“网络不给力,请稍后重试” 说到爬虫,这里指的是Python中最常用的requests库 我说怎么爬不了了&#x…...
visual studio 2022配置
前提:我linux c 开发 一直在使用vscode 更新了个版本突然代码中的查找所用引用和变量修改名称不能用了,尝试了重新配置clang vc都不行,估计是插件问题,一怒之下改用visual studio 2022 为了同步2个IDE之间的差别,目前…...
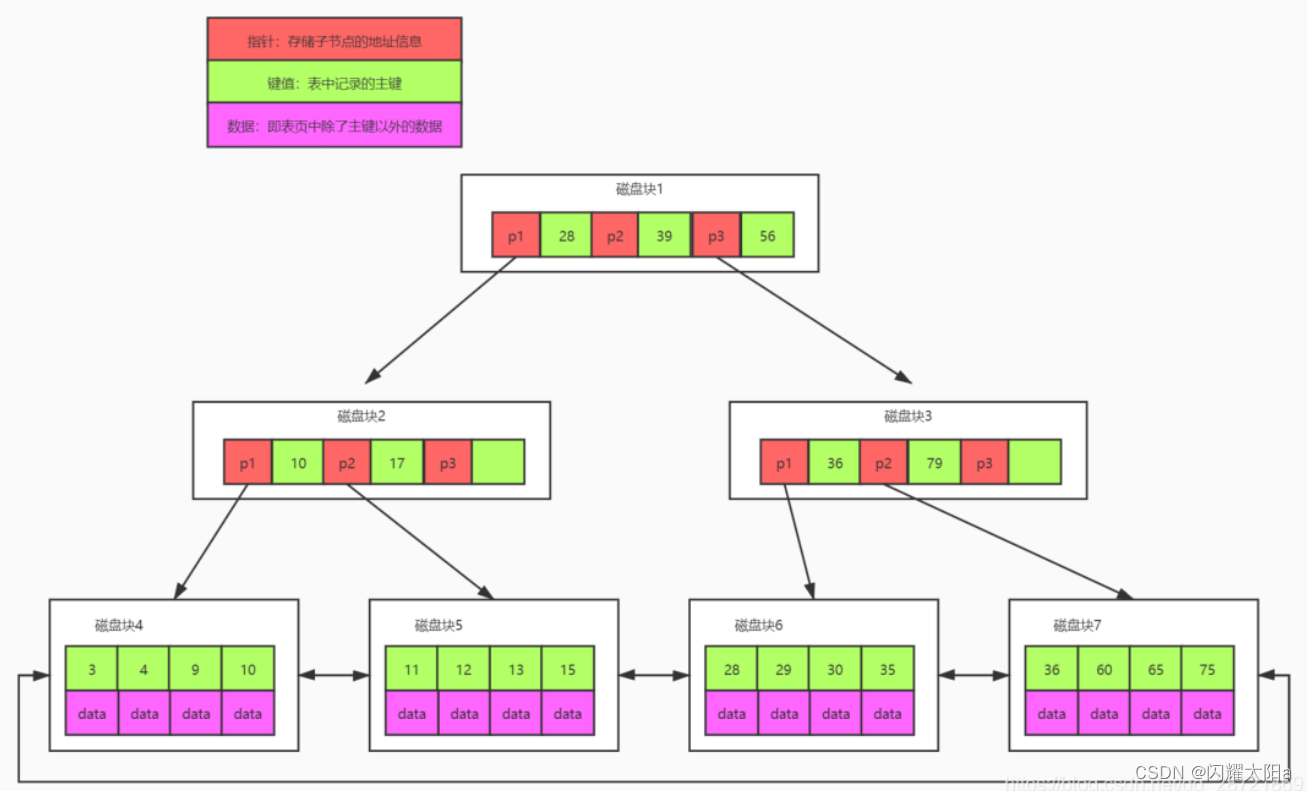
B-树和B+树的区别
B-树和B树的区别 一、B-tree数据存储 在下图中 P 代表的是指针,指向的是下一个磁盘块。在第一个节点中的 16、24 就是代表我们的 key 值是什么。date 就是这个 key 值对应的这一行记录是什么。 假设寻找 key 为 33 的这条记录,33 在 16 和 34 中间&am…...

c注册cpp回调函数
在C语言中注册回调函数,函数需要使用静态函数,可使用bind和function来转换 案例一: #include <iostream> #include <functional> #include <string.h> #include "http_server.h" #include "ret_err_code.…...

批量将excel中字段为“八百”替换成“九百”
要批量将Excel中字段为"八百"的内容替换为"九百",您可以使用Python的openpyxl库来实现。以下是一个示例代码演示如何读取Excel文件并进行替换操作: from openpyxl import load_workbook # 打开Excel文件 wb load_workbook(your_ex…...

关于docker-compose up -d在文件下无法运行的原因以及解决方法
一、确认文件下有docker-compose.yml文件 二、解决方法 检查 Docker 服务是否运行: 使用以下命令检查 Docker 服务是否正在运行: systemctl status docker 如果 Docker 未运行,可以使用以下命令启动它: systemctl start docker …...
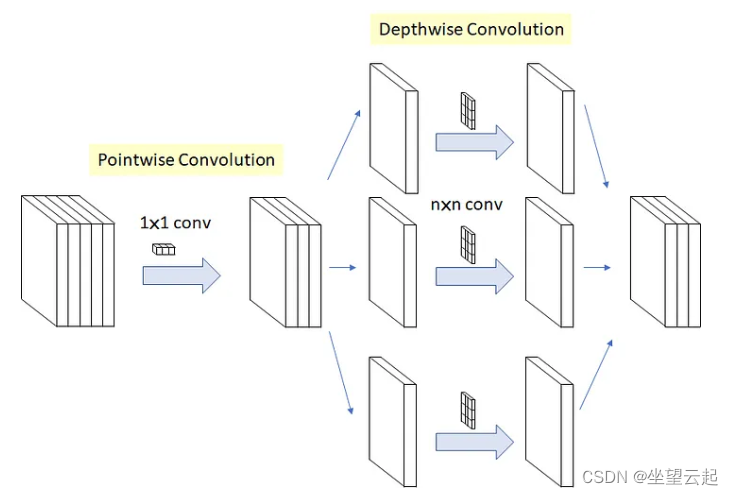
机器学习笔记 - 基于keras + 小型Xception网络进行图像分类
一、简述 Xception 是深度为 71 层的卷积神经网络,仅依赖于深度可分离的卷积层。 论文中将卷积神经网络中的 Inception 模块解释为常规卷积和深度可分离卷积运算(深度卷积后跟点卷积)之间的中间步骤。从这个角度来看,深度可分离卷积可以理解为具有最大数量塔的 Inception 模…...

【Unity每日一记】SceneManager场景资源动态加载
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:uni…...

自动驾驶数据回传需求
1、需求分析 用户 用户需求 实时性要求 需回传数据 数据类型 采样周期 数据量 大小 数据回传通道 研发工程师 分析评估系统性能表现,例如智驾里程统计、接管率表现、油耗表现、AEB报警次数等 当天 车身底盘数据、自动驾驶系统状态数据等 结构化数据 10…...
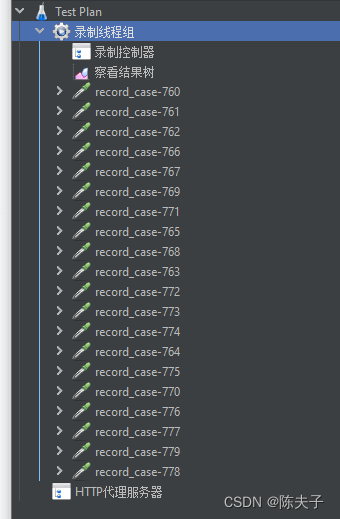
使用Jmeter自带recorder代理服务器录制接口脚本
脚本录制 配置线程组 添加代理服务器 端口 和 录制脚本放置位置可根据需要设置 启动录制 点击启动后 弹出创建证书提示,点击OK 这个证书后续需要使用到 然后可见 一个弹窗。 Recorder . 本质是代理服务录制交易控制 可设置对应数据 方便录制脚本的查看 证书配置…...
我和 TiDB 的故事 | 远近高低各不同
作者: ShawnYan 原文来源: https://tidb.net/blog/b41a02e6 Hi, TiDB, Again! 书接上回, 《我和 TiDB 的故事 | 横看成岭侧成峰》 ,一年时光如白驹过隙,这一年我好似在 TiDB 上投入的时间总量不是很多࿰…...

深入浅出Pytorch函数——torch.nn.init.zeros_
分类目录:《深入浅出Pytorch函数》总目录 相关文章: 深入浅出Pytorch函数——torch.nn.init.calculate_gain 深入浅出Pytorch函数——torch.nn.init.uniform_ 深入浅出Pytorch函数——torch.nn.init.normal_ 深入浅出Pytorch函数——torch.nn.init.c…...

Jenkins-发送邮件配置
在Jenkins构建执行完毕后,需要及时通知相关人员。因此在jenkins中是可以通过邮件通知的。 一、Jenkins自带的邮件通知功能 找到manage Jenkins->Configure System,进行邮件配置: 2. 配置Jenkins自带的邮箱信息 完成上面的配置后…...
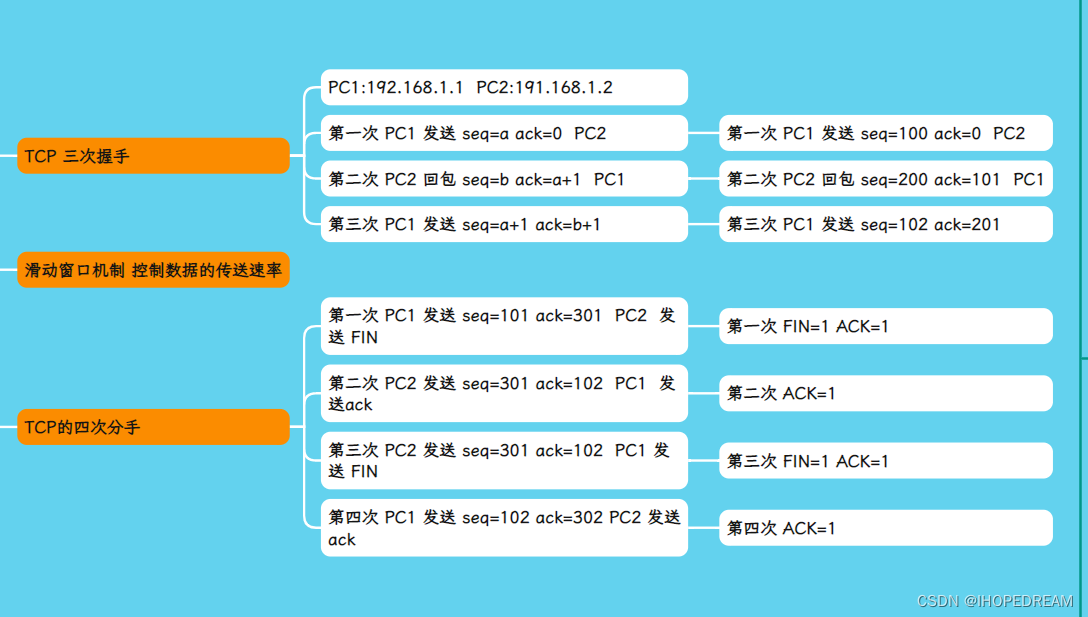
网络通信原理传输层TCP三次建立连接(第四十八课)
ACK :确认号 。 是期望收到对方的下一个报文段的数据的第1个字节的序号,即上次已成功接收到的数据字节序号加1。只有ACK标识为1,此字段有效。确认号X+1SEQ:序号字段。 TCP链接中传输的数据流中每个字节都编上一个序号。序号字段的值指的是本报文段所发送的数据的第一个字节的…...

【Python机器学习】实验14 手写体卷积神经网络(PyTorch实现)
文章目录 LeNet-5网络结构(1)卷积层C1(2)池化层S1(3)卷积层C2(4)池化层S2(5)卷积层C3(6)线性层F1(7)线性层F2 …...
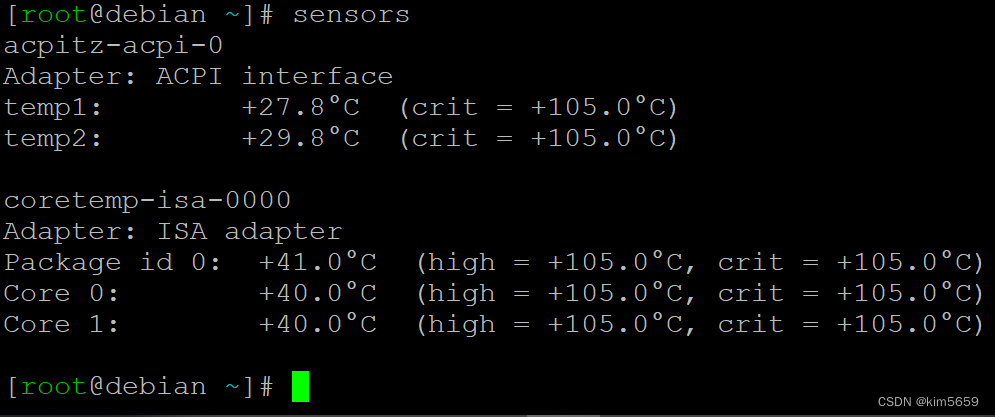
Debian查询硬件状态
很早以前写过一个查询树霉派硬件状态的文章,用是Python写的一个小程序。里面用到了vcgencmd这个测温度的内部命令,但这个命令在debian里面没有,debian里只有lm_sensors的外部命令,需要安装:apt-get install lm_sensors…...
)
除自身以外数组的乘积(c语言详解)
题目:除自身外数组的乘积 给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据保证数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请不要使用除…...

ONES × 鲁邦通|打造研发一体化平台,落地组织级流程规范
近日,ONES 签约工业互联网行业领先的解决方案提供商——鲁邦通,助力鲁邦通优化组织级流程规范,落地从需求到交付的全生命周期线上化管理。 依托于 ONES 一站式研发管理平台,鲁邦通在软硬件设计开发、项目管理和精益生产等方面的数…...
【GaussDB】 SQL 篇
建表语句 表的分类 普通的建表语句 复制表内容 只复制表结构 create table 新表名(like 源表名 including all); 如果希望注释被复制的话要指定including comments 复制索引、主键约束和唯一约束,那么需要指定including indexes including constraints …...
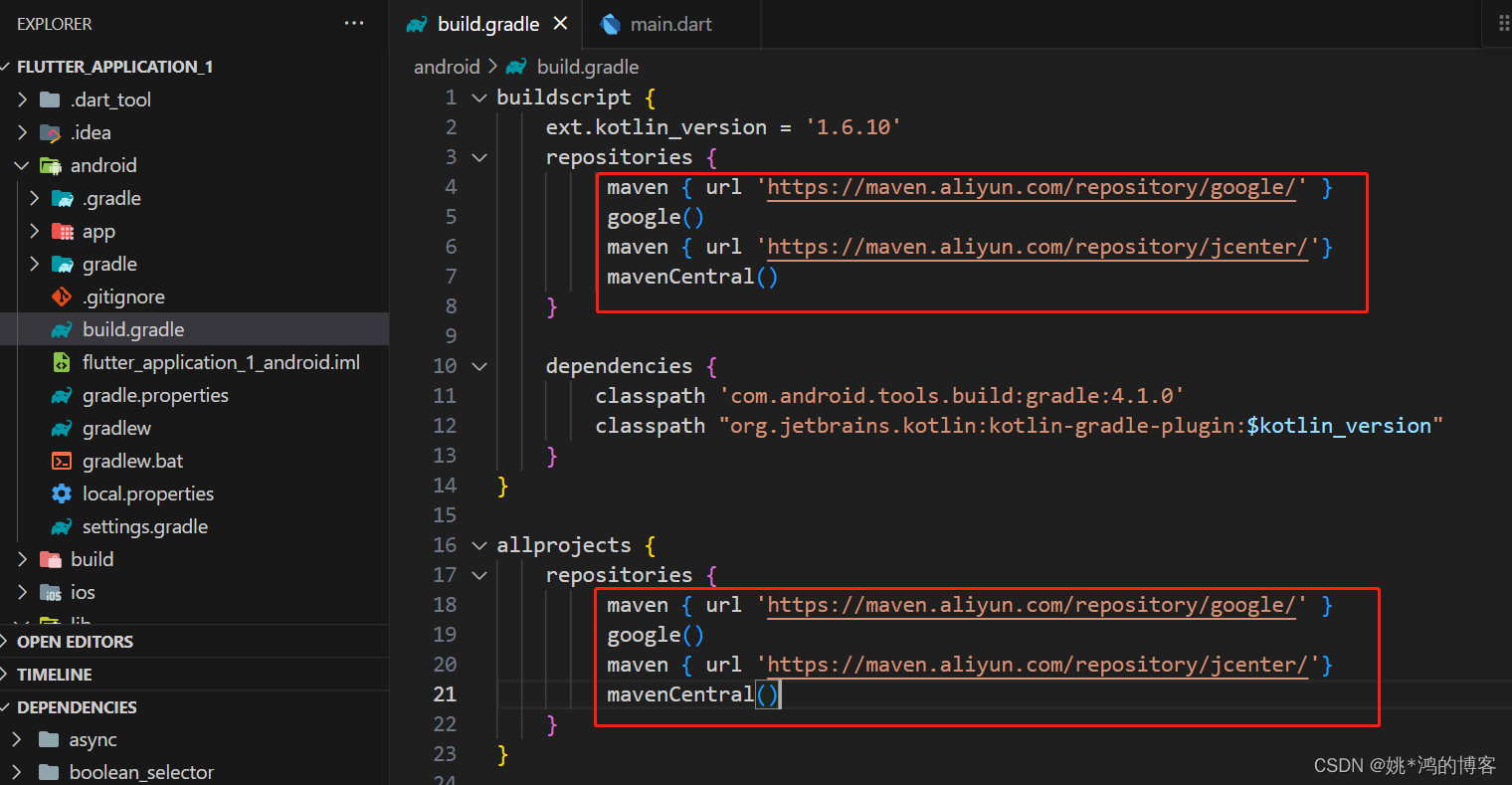
rn和flutter出现“Running Gradle task ‘assembleDebug
在第一次运行rn和flutter时,会卡在Running Gradle task assembleDebug,可以使用阿里的镜像,如下图: maven { url https://maven.aliyun.com/repository/google/ } google() maven { url https://maven.aliyun.com/repository/jcen…...

AI Native Web 开发实战:从零构建智能应用
AI Native Web 产品实战指南:从概念到落地的完整路线做了大半年 AI 应用开发之后,我发现一个现象:很多人知道 “AI Native” 这个词,但真要动手做一个 AI Native 的 Web 产品,脑子里是一团浆糊的。这篇文章就是想把这块…...
)
【限时技术白皮书】ElevenLabs尼泊尔文语音质量评估体系(含MOS打分标准、基线数据集、及与Google Cloud Text-to-Speech Nepali v1.3对比)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs尼泊尔文语音质量评估体系概述 ElevenLabs 对尼泊尔文(नेपाली)语音合成的支持虽属新兴能力,但其质量评估需兼顾语言学特性、声学保真度与文化适配性…...

解密工业通信调试:Wu.CommTool深度解析与实战指南
解密工业通信调试:Wu.CommTool深度解析与实战指南 【免费下载链接】Wu.CommTool 基于C#、WPF、Prism、MaterialDesign、HandyControl开发的通讯调试工具。支持Modbus Rtu调试、Mqtt调试、TCP调试、串口调试、UDP调试 项目地址: https://gitcode.com/gh_mirrors/wu…...

C++ mutable关键字深度解析:从const正确性到线程安全实践
1. 从一次线上调试的“诡异”现象说起 那天下午,我正盯着一个线上服务的监控面板,一个看似无关紧要的日志打印频率异常引起了我的注意。这是一个用C编写的多线程数据处理模块,其中有一个用于统计处理次数的成员变量,被声明为 con…...

个人开发者如何借助 Taotoken 低成本体验顶级大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 个人开发者如何借助 Taotoken 低成本体验顶级大模型 对于个人开发者或学生而言,直接接入和使用各家顶尖大模型 API 往往…...

如何5分钟实现Windows系统自动化软件部署:winget-install完整指南
如何5分钟实现Windows系统自动化软件部署:winget-install完整指南 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.com/gh_…...

Verilog行为级建模:从initial/always到阻塞非阻塞赋值的核心语法解析
1. 项目概述:从“连线”到“行为”的思维跃迁刚接触数字电路设计的朋友,可能都是从画原理图、连逻辑门开始的。但当你面对一个需要处理复杂时序、包含状态机或者有算法逻辑的模块时,光靠门级网表来描述,那工程量简直让人头皮发麻。…...

模型哈密顿量构建:从第一性原理到可计算有效模型的实践指南
1. 项目概述:从“黑箱”到“白箱”的化学计算桥梁 在计算化学和材料科学领域,我们常常面临一个核心矛盾:一方面,我们希望模型足够精确,能够捕捉到电子结构最细微的相互作用,比如使用密度泛函理论࿰…...

如何在华硕路由器上3分钟安装AdGuardHome实现全网广告拦截
如何在华硕路由器上3分钟安装AdGuardHome实现全网广告拦截 【免费下载链接】Asuswrt-Merlin-AdGuardHome-Installer The Official Installer of AdGuardHome for Asuswrt-Merlin 项目地址: https://gitcode.com/gh_mirrors/as/Asuswrt-Merlin-AdGuardHome-Installer 厌倦…...

科技中介机构如何提升服务能力与客户转化率?
观点作者:科易网-国家科技成果转化(厦门)示范基地 一、现状概述:科技成果转化中的“最后一公里”困境 近年来,我国科技创新投入持续增长,技术产出规模不断扩大。然而,科技成果从实验室走向市场、…...