Hadoop小结(下)
HDFS 集群
HDFS 集群是建立在 Hadoop 集群之上的,由于 HDFS 是 Hadoop 最主要的守护进程,所以 HDFS 集群的配置过程是 Hadoop 集群配置过程的代表。
使用 Docker 可以更加方便地、高效地构建出一个集群环境。
每台计算机中的配置
Hadoop 如何配置集群、不同的计算机里又应该有怎样的配置?
HDFS 命名节点对数据节点的远程控制是通过 SSH 来实现的,因此关键的配置项应该在命名节点被配置,非关键的节点配置要在各个数据节点配置。也就是说,数据节点与命名节点的配置可以不同,不同数据节点之间的配置也可以有所不同。
为了方便建立集群,我使用相同的配置文件通过 Docker 镜像的形式同步到所有的集群节点
具体步骤
总体思路是:先用一个包含 Hadoop 的镜像进行配置,配置成集群中所有节点都可以共用的样子,然后再以它为原型生成若干个容器,构成一个集群。
配置原型
首先,使用之前准备的 hadoop_proto 镜像启动为容器:
docker run -d --name=hadoop_temp --privileged hadoop_proto /usr/sbin/init
进入 Hadoop 的配置文件目录:
cd $HADOOP_HOME/etc/hadoop
| 文件 | 作用 |
|---|---|
| workers | 记录所有的数据节点的主机名或 IP 地址 |
| core-site.xml | Hadoop 核心配置 |
| hdfs-site.xml | HDFS 配置项 |
| mapred-site.xml | MapReduce 配置项 |
| yarn-site.xml | YARN 配置项 |
集群的原型配置完毕后,退出容器并上传容器到新镜像 cluster_proto :
docker stop hadoop_temp
docker commit hadoop_temp cluster_proto
部署集群
首先,要为 Hadoop 集群建立专用网络 hnet :
docker network create --subnet=172.20.0.0/16 hnet
接下来创建集群容器:
docker run -d --name=nn --hostname=nn --network=hnet --ip=172.20.1.0 --add-host=dn1:172.20.1.1 --add-host=dn2:172.20.1.2 --privileged cluster_proto /usr/sbin/init
docker run -d --name=dn1 --hostname=dn1 --network=hnet --ip=172.20.1.1 --add-host=nn:172.20.1.0 --add-host=dn2:172.20.1.2 --privileged cluster_proto /usr/sbin/init
docker run -d --name=dn2 --hostname=dn2 --network=hnet --ip=172.20.1.2 --add-host=nn:172.20.1.0 --add-host=dn1:172.20.1.1 --privileged cluster_proto /usr/sbin/init
进入命名节点:
docker exec -it nn su hadoop
格式化 HDFS:
hdfs namenode -format
如果没有出错,那么下一步就可以启动 HDFS:
start-dfs.sh
成功启动之后,jps 命令应该能查到 NameNode 和 SecondaryNameNode 的存在。命名节点不存在 DataNode 进程,因为这个进程在 dn1 和 dn2 中运行。
MapReduce 使用
Word Count 就是"词语统计",这是 MapReduce 工作程序中最经典的一种。它的主要任务是对一个文本文件中的词语作归纳统计,统计出每个出现过的词语一共出现的次数。
Hadoop 中包含了许多经典的 MapReduce 示例程序,其中就包含 Word Count。
注意:这个案例在 HDFS 不运行的状态下依然可以运行,所以我们先在单机模式下测试
首先,启动一个之前制作的 hadoop_proto 镜像的新容器:
docker run -d --name=word_count hadoop_proto
进入容器:
docker exec -it word_count bash
进入 HOME 目录:
cd ~
现在我们准备一份文本文件 input.txt:
I love China
I like China
I love hadoop
I like hadoop
将以上内容用文本编辑器保存。
执行 MapReduce:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount input.txt output
解释一下含义:
hadoop jar从 jar 文件执行 MapReduce 任务,之后跟着的是示例程序包的路径。
wordcount表示执行示例程序包中的 Word Count 程序,之后跟这两个参数,第一个是输入文件,第二个是输出结果的目录名(因为输出结果是多个文件)。
执行之后,应该会输出一个文件夹 output,在这个文件夹里有两个文件:_SUCCESS 和 part-r-00000。
集群模式
现在我们在集群模式下运行 MapReduce。
启动在上一章配置好的集群容器:
docker start nn dn1 dn2
进入 NameNode 容器:
docker exec -it nn su hadoop
进入 HOME:
cd ~
编辑 input.txt:
I love China
I like China
I love hadoop
I like hadoop
启动 HDFS:
start-dfs.sh
创建目录:
hadoop fs -mkdir /wordcount
hadoop fs -mkdir /wordcount/input
上传 input.txt
hadoop fs -put input.txt /wordcount/input/
执行 Word Count:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount /wordcount/input /wordcount/output
查看执行结果:
hadoop fs -cat /wordcount/output/part-r-00000
如果一切正常,将会显示以下结果:
I 4
hadoop 2
like 2
love 2
China 2
MapReduce 编程
在学习了 MapReduce 的使用之后,已经可以处理 Word Count 这类统计和检索任务,但是客观上 MapReduce 可以做的事情还有很多。
MapReduce 主要是依靠开发者通过编程来实现功能的,开发者可以通过实现 Map 和 Reduce 相关的方法来进行数据处理。
为了简单的展示这一过程,我们手工编写一个 Word Count 程序。
注意:MapReduce 依赖 Hadoop 的库,但我使用的 Hadoop 运行环境是 Docker 容器,难以部署开发环境,所以真实的开发工作(包含调试)将需要一个运行 Hadoop 的计算机。
MyWordCount.java 文件代码
/*** 引用声明* 本程序引用自 http://hadoop.apache.org/docs/r1.0.4/cn/mapred_tutorial.html*/
package com.runoob.hadoop;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
/*** 与 `Map` 相关的方法*/
class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(LongWritable key,Text value,OutputCollector<Text, IntWritable> output,Reporter reporter)throws IOException {String line = value.toString();StringTokenizer tokenizer = new StringTokenizer(line);while (tokenizer.hasMoreTokens()) {word.set(tokenizer.nextToken());output.collect(word, one);}}
}
/*** 与 `Reduce` 相关的方法*/
class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {public void reduce(Text key,Iterator<IntWritable> values,OutputCollector<Text, IntWritable> output,Reporter reporter)throws IOException {int sum = 0;while (values.hasNext()) {sum += values.next().get();}output.collect(key, new IntWritable(sum));}
}
public class MyWordCount {public static void main(String[] args) throws Exception {JobConf conf = new JobConf(MyWordCount.class);conf.setJobName("my_word_count");conf.setOutputKeyClass(Text.class);conf.setOutputValueClass(IntWritable.class);conf.setMapperClass(Map.class);conf.setCombinerClass(Reduce.class);conf.setReducerClass(Reduce.class);conf.setInputFormat(TextInputFormat.class);conf.setOutputFormat(TextOutputFormat.class);// 第一个参数表示输入FileInputFormat.setInputPaths(conf, new Path(args[0]));// 第二个输入参数表示输出FileOutputFormat.setOutputPath(conf, new Path(args[1]));JobClient.runJob(conf);}
}
将此 Java 文件的内容保存到 NameNode 容器中去,建议位置:
/home/hadoop/MyWordCount/com/runoob/hadoop/MyWordCount.java
注意:根据当前情况,有的 Docker 环境中安装的 JDK 不支持中文,所以保险起见,请去掉以上代码中的中文注释。
进入目录:
cd /home/hadoop/MyWordCount
编译:
javac -classpath ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.1.4.jar -classpath ${HADOOP_HOME}/share/hadoop/client/hadoop-client-api-3.1.4.jar com/runoob/hadoop/MyWordCount.java
打包:
jar -cf my-word-count.jar com
执行:
hadoop jar my-word-count.jar com.runoob.hadoop.MyWordCount /wordcount/input /wordcount/output2
查看结果:
hadoop fs -cat /wordcount/output2/part-00000
输出:
I 4
hadoop 2
like 2
love 2
China 2
相关文章:
)
Hadoop小结(下)
HDFS 集群 HDFS 集群是建立在 Hadoop 集群之上的,由于 HDFS 是 Hadoop 最主要的守护进程,所以 HDFS 集群的配置过程是 Hadoop 集群配置过程的代表。 使用 Docker 可以更加方便地、高效地构建出一个集群环境。 每台计算机中的配置 Hadoop 如何配置集群…...

使用老北鼻AI免费GPT对话解决gun make安装和解析iso9660的问题
在学习解析ISO9660镜像文件时,使用了GPT来了解相关的库和gun make编译器的相关知识。这个过程可真是一言难尽,每个问题的回答都模棱两可都需要去证实,不能直接复制粘贴,也不能说GPT的回答一点用也没有,至少GPT给出了一…...

shell脚本语句
一、语句 一、条件语句 一、以用户为例演示 一、显示当前登录系统的用户信息 w命令 二、显示有多少个用户 w | wc -l 显示有7个用户 前两个是固定标题,从第三个开始才是登录用户,所以要统计数量需要 命令:echo $[$(w | wc -l) -2] 显示…...

【LeetCode】2235.两整数相加
题目 给你两个整数 num1 和 num2,返回这两个整数的和。 示例 1: 输入:num1 12, num2 5 输出:17 解释:num1 是 12,num2 是 5 ,它们的和是 12 5 17 ,因此返回 17 。示例 2&…...

springboot sl4j2 写入日志到mysql
问题描述 springboot初始化的时候,会先初始化日志然后再加载数据源如果用配置文件进行初始化,那么会出现数据源没有加载成功,导致空指针异常 报错排查如下: 搜索报错信息,OBjects.invoke is Null打断点发现。dataso…...

用 PyTorch 编写分布式应用程序
用 PyTorch 编写分布式应用程序 在这个简短的教程中,我们将介绍 PyTorch 的分布式软件包。 我们将了解如何设置分布式设置,使用不同的交流策略以及如何仔细查看软件包的内部结构。 设定 PyTorch 中包含的分布式软件包(即torch.distributed)…...

空间分析专属 Python 学习资料
空间数据分析能够帮助我们更好地理解地理空间中的模式和关系,从而为决策提供支持。例如,城市规划者可以使用空间数据分析来确定城市发展的最佳方向,环境科学家可以使用空间数据分析来评估污染的影响,而商业分析师可以使用空间数据…...

2. Linux Server 20.04 Qt5.14.2配置Jetson Orin Nano Developer Kit 交叉编译环境
最近公司给了我一块Jetson Orin Nano的板子,先刷了系统(1.Jetson Orin Nano Developer Kit系统刷机)又让我搭建交叉编译环境,所以有了下面的文章 一 :Qt5.14.2交叉编译环境安装 1.准备 1.1设备环境 1.1.1 Server: Ubuntu20.0…...

vue入门
Attribute 绑定 v-bind:取值方式 开发前准备 安装node.js需要高于15.0 创建vue项目 npm init vuelatest安装 npm install 启动 npm run dev模板语法 文本插值 {{ 变量 }} <p> {{ mesg }} </p>这种方式公支持单一表达式,也可以是js代码…...

区块链中slot、epoch、以及在slot和epoch中的出块机制,分叉原理(自己备用)
以太坊2.0中有两个时间概念:时隙槽slot 和 时段(周期)epoch。其中一个slot为12秒,而每个 epoch 由 32 个 slots 组成,所以每个epoch共384秒,也就是 6.4 分钟。 对于每个epoch,使用RANDAO伪随机…...

免费开源的vue+express搭建的后台管理系统
此项目已开源 前端git地址:exp后台管理系统前端: exp后台管理系统前端 后端git地址:express后台管理系统: express后台管理系统 安装运行 npm i yarn i 前端: npm run dev | yarn dev 后端: npm run start | yarn start 主要技术栈 前端后端名称版本名…...
【开发】视频云存储EasyCVR视频汇聚平台AI智能算法定制
安防视频集中存储EasyCVR视频汇聚平台,可支持海量视频的轻量化接入与汇聚管理。平台能提供视频存储磁盘阵列、视频监控直播、视频轮播、视频录像、云存储、回放与检索、智能告警、服务器集群、语音对讲、云台控制、电子地图、平台级联、H.265自动转码等功能。为了便…...
Ribbon:负载均衡及Ribbon
什么是负载均衡? 第一种轮询算法,依次遍历去执行,达到负载均衡 集成Ribbon 导入pom,在消费者服务里的pom文件导入 <!-- Ribbon 集成 --><!-- https://mvnrepository.com/artifact/org.springframework.cloud/spr…...
【声波】声波在硼酸、硫酸镁 (MgSO4) 和纯水中的吸收研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
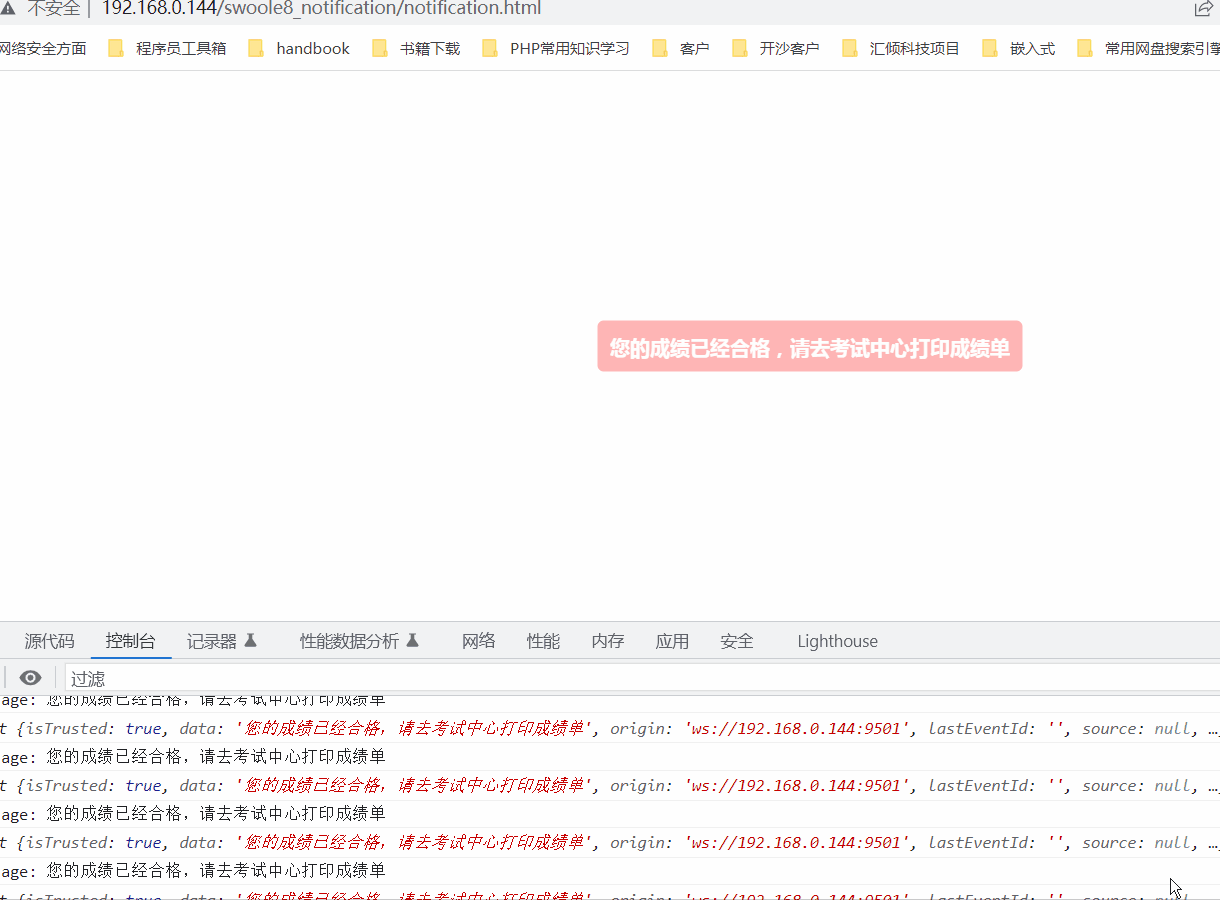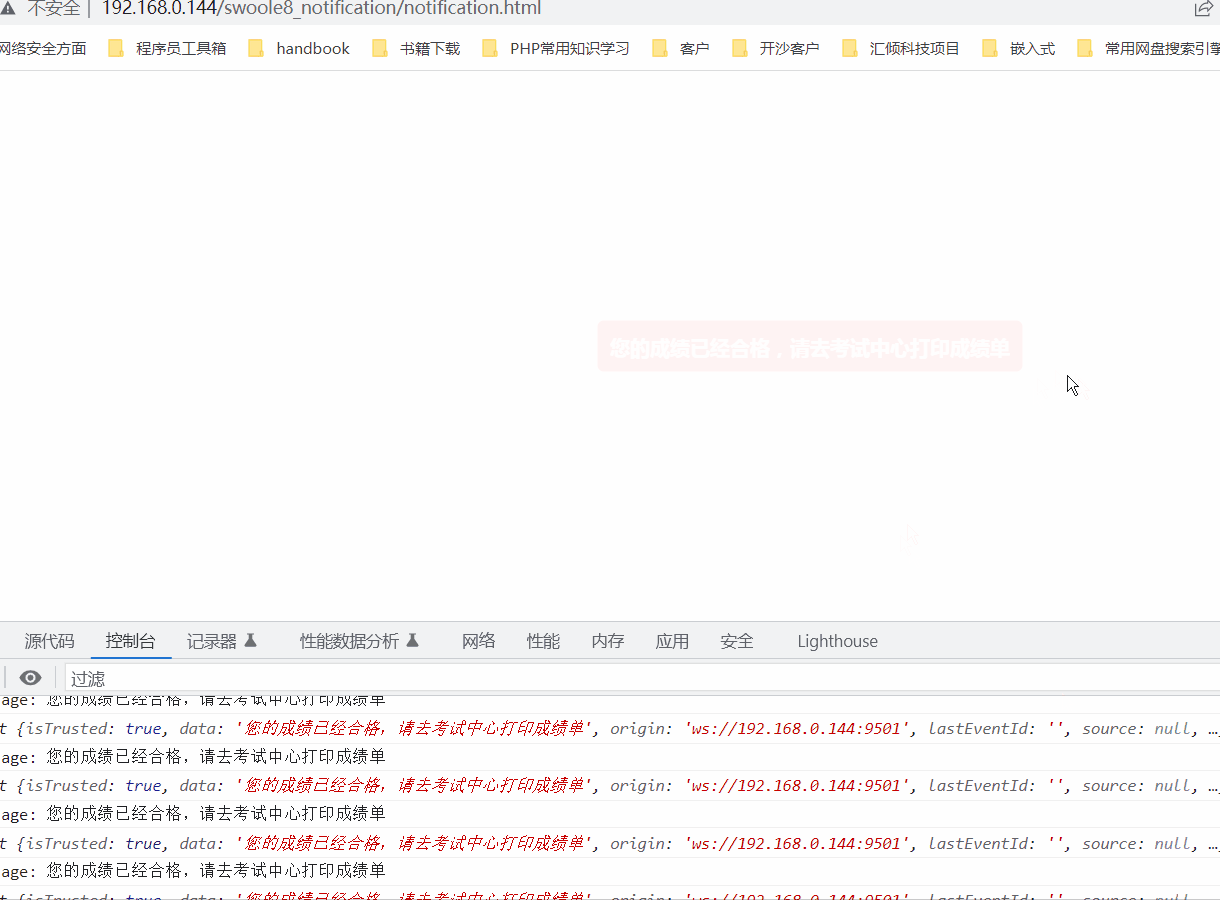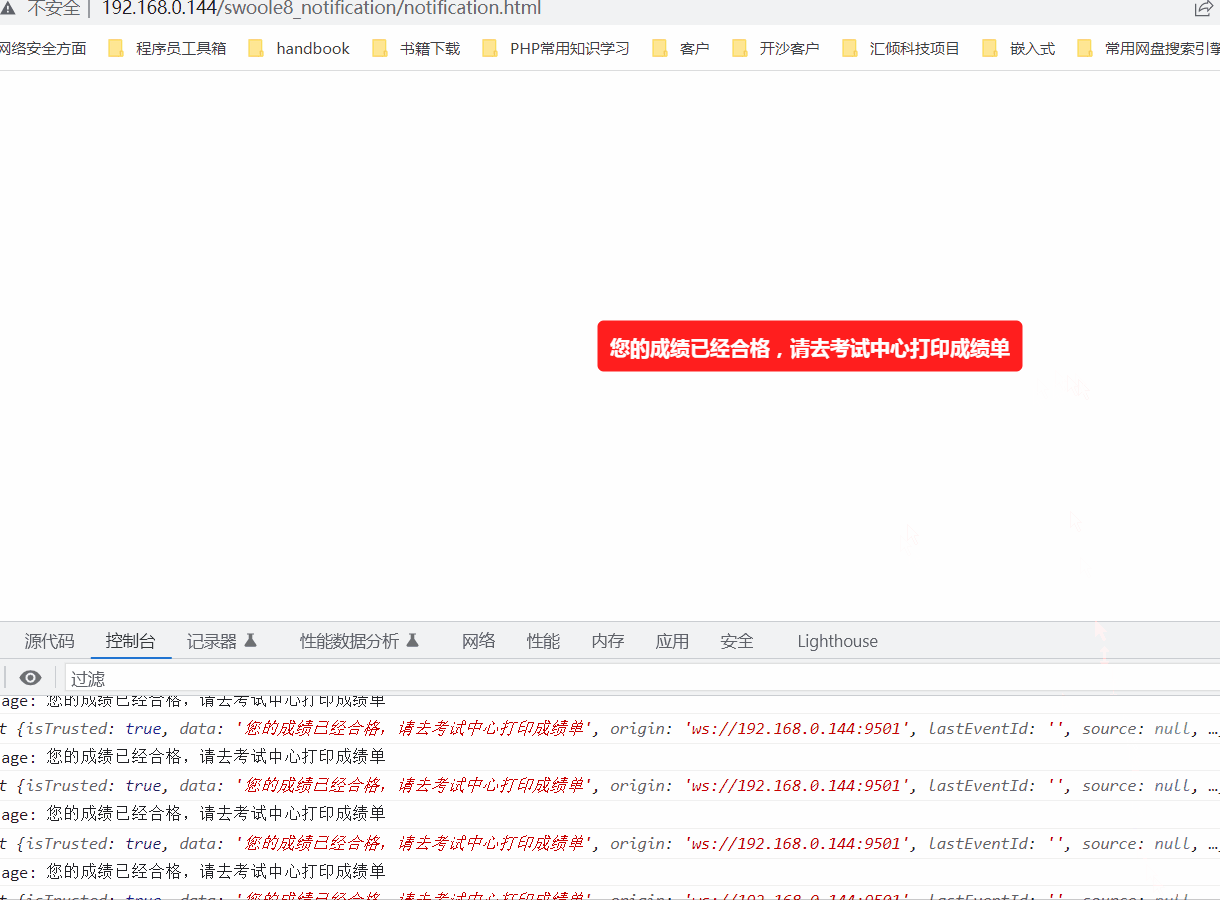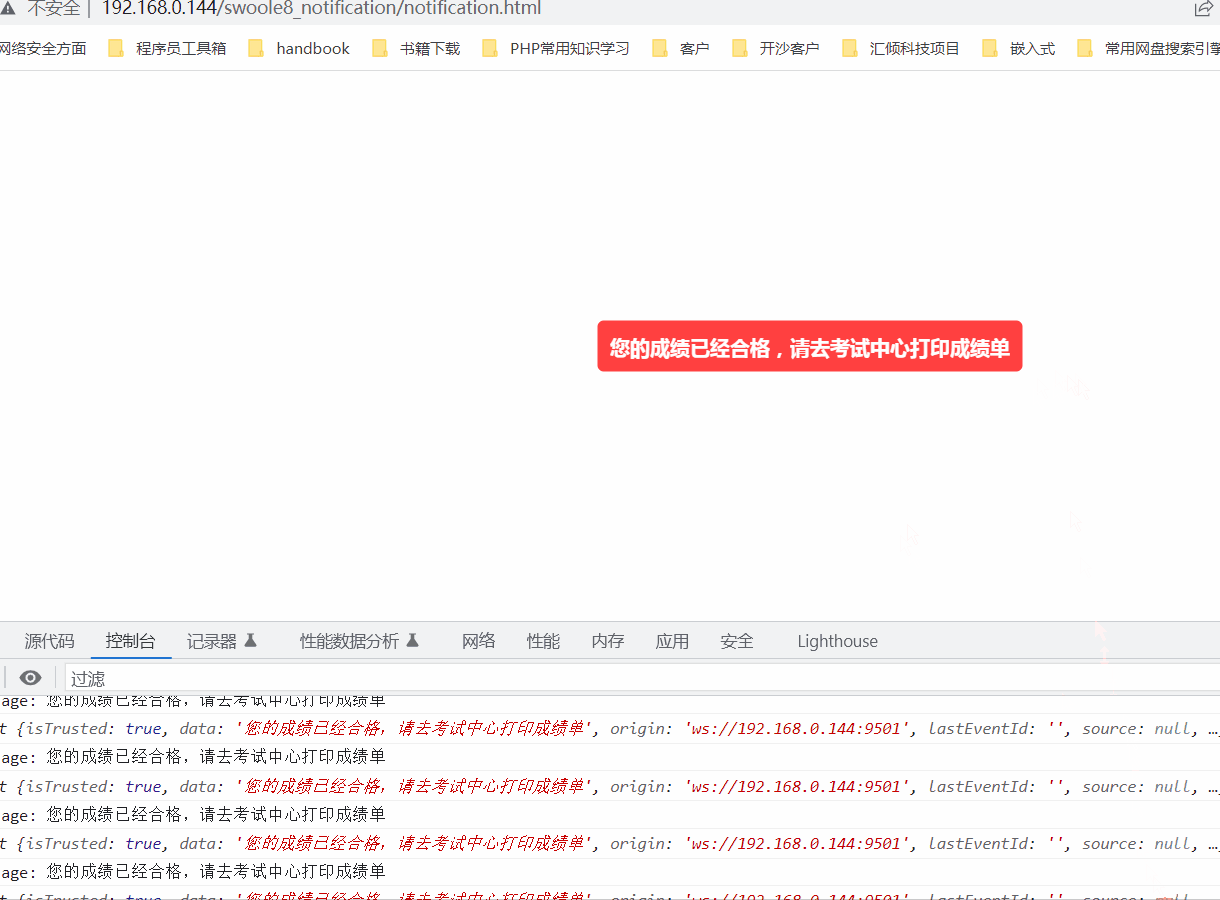
使用swoole实现实时消息推送给客户端
一. 测试服务端 //测试服务端public function testServer(){$server new Server(192.168.0.144, 9501, SWOOLE_BASE, SWOOLE_SOCK_TCP);$server->on(request, function ($request, $response) {$response->header(Content-Type, text/plain);$response->end("He…...

Ordinals 之后,以太坊铭文协议 Ethscriptions 如何再塑 NFT 资产形态
随着加密市场的发展,NFT 赛道逐渐形成了其独有的市场。但在加密熊市的持续影响下,今年 NFT 赛道的发展充满坎坷与挑战。据 NFTGO 数据显示,截至 8 月 7 日,与去年相比,NFT 市值总计约 56.4 亿美元,过去 1 年…...

Python绘制爱心代码(七夕限定版)
写在前面: 又到了一年一度的七夕节啦!你还在发愁送女朋友什么礼物,不知道怎样表达你满满的爱意吗?别担心,我来帮你!今天,我将教你使用Python绘制一个跳动的爱心,用创意和幽默为这个…...

Java两整数相除向上取整
方法一:通过三目运算符 (简单移动) x / y (x % y ! 0 ? 1 : 0);方法二:通过ceil函数(不推荐使用,涉及类型转换) (int)Math.ceil((double)x/y);// 或者(int)Math.ceil(x * 1.0 /y);方法三&…...
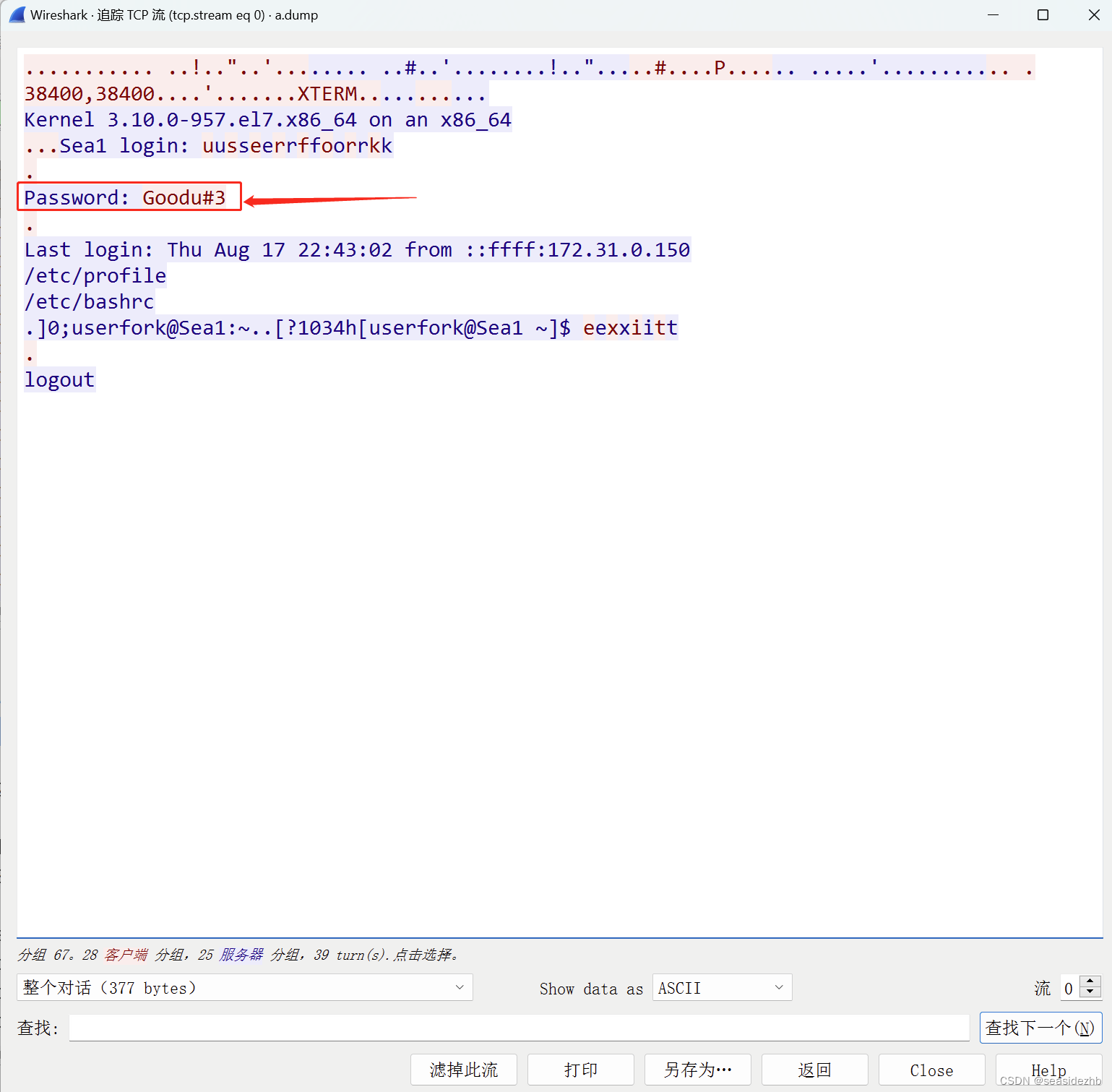
Linux学习之Telnet明文漏洞
yum install telnet telnet-server xinetd -y安装软件。 systemctl start xinetd.service开启xinetd,systemctl start telnet.socket开启telnet。 xinetd来监控端口,然后把数据传给telnet。 ifconfig eth0看一下eth0网卡信息,。 iptable…...
产品经理如何提高用户画像效果?SIKT模型
产品经理做用户画像,最担心被业务方反馈:没效果。这往往是由用户画像与业务场景脱节造成的。那么我们该如何从业务场景出发,让用户画像更有效?一般来说,我们可以采用SIKT模型解决这个问题。 用户画像 1、SIK…...

三维多孔介质催化反应Fluent仿真:从模型构建到关键参数调优的实战解析
1. 三维多孔介质催化反应仿真入门指南 第一次接触Fluent做多孔介质催化反应仿真时,我被复杂的参数设置搞得晕头转向。记得当时为了复现一篇文献结果,整整折腾了两周才摸清门道。这种仿真本质上是通过数值方法模拟流体在多孔催化剂内部的流动、传质和化学…...

AI智能体技能开发实战:从工具调用到安全部署全解析
1. 项目概述:当AI学会“上网”与“思考”最近在折腾AI应用开发的朋友,估计都绕不开一个核心问题:如何让大语言模型(LLM)不只是个“聊天高手”,更能成为一个能独立完成复杂任务的“智能体”。你肯定遇到过&a…...

鲲鹏超节点系统应用创新竞争力
鲲鹏超节点通过灵衢互联,打破传统的服务器边界,实现以数据为中心的全互联架构,为AI infra而生,具备大带宽、低时延、统一编址、内存语义、内存借用、内存共享、对等互联等关键能力,灵衢软件全面开源开放,让…...

STM32多任务处理实战:从裸机调度到FreeRTOS应用详解
1. 项目概述与核心需求解析在嵌入式开发领域,尤其是基于STM32这类资源受限但功能强大的微控制器时,我们常常会遇到一个核心矛盾:硬件只有一个CPU核心,但软件功能却要求它“同时”处理多个任务。比如,一个智能温控器需要…...
)
中标麒麟OS访问Win10共享文件夹,手把手教你搞定SMB连接(附终端挂载命令)
中标麒麟OS与Win10共享文件夹互通实战指南 在国产化办公环境逐步普及的今天,中标麒麟OS作为主流国产操作系统之一,与Windows系统之间的文件共享成为日常办公刚需。本文将针对零基础用户,提供两种高效稳定的SMB共享连接方案:图形化…...

FAST-LIO2后端优化代码逐行解读:从残差计算到地图更新的完整流程
FAST-LIO2后端优化代码逐行解读:从残差计算到地图更新的完整流程 当激光雷达在复杂环境中高速移动时,如何实现精准的实时定位与建图?FAST-LIO2通过创新的迭代误差状态卡尔曼滤波(IEKF)框架,将IMU预积分与激…...

【审计专栏-监督监管】【信息科学与工程学】计算机科学与自动化——第一百五十篇 招投标领域中的应用数学02
编号 033 维度 内容 编号 033 领域 招投标数学分析 类型 餐饮工程“食材价格虚高”与“供应链绑定”式合谋识别 招投标领域 团餐服务、食材集中采购、厨房设备采购 子领域 学校食堂承包、机关单位食堂外包、大型活动供餐、中央厨房建设 招投标的行业 …...

技术解析:基于UMDF的DualShock 3虚拟HID驱动架构与跨协议兼容方案
技术解析:基于UMDF的DualShock 3虚拟HID驱动架构与跨协议兼容方案 【免费下载链接】DsHidMini Virtual HID Mini-user-mode-driver for Sony DualShock 3 Controllers 项目地址: https://gitcode.com/gh_mirrors/ds/DsHidMini 技术问题背景与挑战 在Windows…...
基于CircuitPython与LED Animation库的NeoPixel蓝牙动态灯光系统
1. 项目概述与核心价值如果你玩过微控制器,尤其是像Adafruit的Circuit Playground Bluefruit这类功能丰富的开发板,那你肯定对板载的那一圈NeoPixel RGB LED灯珠印象深刻。它们不只是几个简单的指示灯,而是一个完整的、可编程的彩色光带。但很…...

使用AirLift ESP32与CircuitPython快速实现蓝牙低功耗通信
1. 项目概述与核心价值 如果你正在寻找一种为你的微控制器项目添加蓝牙低功耗(BLE)连接能力的方案,但又不想被复杂的射频电路设计和底层协议栈开发所困扰,那么使用Adafruit AirLift ESP32作为协处理器,配合CircuitPyth…...