8.2.tensorRT高级(3)封装系列-内存管理的封装,内存的复用
目录
- 前言
- 1. 内存管理封装
- 2. 补充知识
- 总结
前言
杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。
本次课程学习 tensorRT 高级-内存管理的封装,内存的复用
课程大纲可看下面的思维导图

1. 内存管理封装
这节课程我们学习 memory 的封装,使得内存分配复制自动管理,避免手动管理的繁琐
我们可以回顾下之前的分类器、检测器案例代码,假设我们为输入分配了一个 input_data_host 的空间,对应的往往我们也会在 input_data_device 上分配一块同样大小的内存空间;对于 output 也是类似,因此引发我们的思考,我们完全可以将这两个对应的内存打包在一起,方便我们的管理
我们来看代码,
mix-memory.hpp
#ifndef MEMORY_HPP
#define MEMORY_HPP#include <stddef.h>#define CURRENT_DEVICE_ID -1class MixMemory {
public:MixMemory(int device_id = CURRENT_DEVICE_ID);MixMemory(void* cpu, size_t cpu_size, void* gpu, size_t gpu_size, int device_id = CURRENT_DEVICE_ID);virtual ~MixMemory();void* gpu(size_t size);void* cpu(size_t size);template<typename _T>_T* gpu(size_t size){ return (_T*)gpu(size * sizeof(_T)); }template<typename _T>_T* cpu(size_t size){ return (_T*)cpu(size * sizeof(_T)); };void release_gpu();void release_cpu();void release_all();// 是否属于我自己分配的gpu/cpuinline bool owner_gpu() const{return owner_gpu_;}inline bool owner_cpu() const{return owner_cpu_;}inline size_t cpu_size() const{return cpu_size_;}inline size_t gpu_size() const{return gpu_size_;}inline int device_id() const{return device_id_;}inline void* gpu() const { return gpu_; }// Pinned Memoryinline void* cpu() const { return cpu_; }template<typename _T>inline _T* gpu() const { return (_T*)gpu_; }// Pinned Memorytemplate<typename _T>inline _T* cpu() const { return (_T*)cpu_; }void reference_data(void* cpu, size_t cpu_size, void* gpu, size_t gpu_size, int device_id = CURRENT_DEVICE_ID);private:void* cpu_ = nullptr;size_t cpu_size_ = 0;bool owner_cpu_ = true;int device_id_ = 0;void* gpu_ = nullptr;size_t gpu_size_ = 0;bool owner_gpu_ = true;
};#endif // MEMORY_HPP
mix-memory.cpp
#include "mix-memory.hpp"
#include "cuda-tools.hpp"
#include <string.h>
#include <assert.h>inline static int check_and_trans_device_id(int device_id){if(device_id != CURRENT_DEVICE_ID){CUDATools::check_device_id(device_id);return device_id;}checkRuntime(cudaGetDevice(&device_id));return device_id;
}MixMemory::MixMemory(int device_id){device_id_ = check_and_trans_device_id(device_id);
}MixMemory::MixMemory(void* cpu, size_t cpu_size, void* gpu, size_t gpu_size, int device_id){reference_data(cpu, cpu_size, gpu, gpu_size, device_id);
}void MixMemory::reference_data(void* cpu, size_t cpu_size, void* gpu, size_t gpu_size, int device_id){release_all();if(cpu == nullptr || cpu_size == 0){cpu = nullptr;cpu_size = 0;}if(gpu == nullptr || gpu_size == 0){gpu = nullptr;gpu_size = 0;}this->cpu_ = cpu;this->cpu_size_ = cpu_size;this->gpu_ = gpu;this->gpu_size_ = gpu_size;this->owner_cpu_ = !(cpu && cpu_size > 0);this->owner_gpu_ = !(gpu && gpu_size > 0);device_id_ = check_and_trans_device_id(device_id);
}MixMemory::~MixMemory() {release_all();
}void* MixMemory::gpu(size_t size) {if (gpu_size_ < size) {release_gpu();gpu_size_ = size;CUDATools::AutoDevice auto_device_exchange(device_id_);checkRuntime(cudaMalloc(&gpu_, size));checkRuntime(cudaMemset(gpu_, 0, size));}return gpu_;
}void* MixMemory::cpu(size_t size) {if (cpu_size_ < size) {release_cpu();cpu_size_ = size;CUDATools::AutoDevice auto_device_exchange(device_id_);checkRuntime(cudaMallocHost(&cpu_, size));assert(cpu_ != nullptr);memset(cpu_, 0, size);}return cpu_;
}void MixMemory::release_cpu() {if (cpu_) {if(owner_cpu_){CUDATools::AutoDevice auto_device_exchange(device_id_);checkRuntime(cudaFreeHost(cpu_));}cpu_ = nullptr;}cpu_size_ = 0;
}void MixMemory::release_gpu() {if (gpu_) {if(owner_gpu_){CUDATools::AutoDevice auto_device_exchange(device_id_);checkRuntime(cudaFree(gpu_));}gpu_ = nullptr;}gpu_size_ = 0;
}void MixMemory::release_all() {release_cpu();release_gpu();
}
在头文件中我们定义了一个 MixMemory 的类,专门用于混合内存(即CPU和GPU内存)的管理。类中提供了构造函数,允许已经分配的 CPU 和 GPU 内存定义为 MixMemory,提供了一些模板函数,用于返回特定类型的 GPU 和 CPU 内存指针,提供了用于分配和释放 GPU 和 CPU 内存的方法,还提供了一些内联函数,用于获取当前对象的属性,如 owner_gpu()、gpu_size()、device_id()、gpu() 等,核心函数是 void gpu(size_t size)*
在 gpu 分配方法中,如果申请的大小大于当前的 GPU 内存大小,则释放现有的 GPU 内存,并为新的大小分配内存,它通过 cudaMalloc 和 cudaMemset 来分配和初始化内存。而如果申请的内存大小小于或等于当前的 GPU 内存大小,它将直接返回现有的 GPU 内存。
如果我之前在 GPU 上分配了一块 100 字节的空间,现在需要分配 10 个字节的空间,我会直接拿之前分配的 100 个字节的空间给你,而不用再分配,如果我现在需要分配 1000 个字节的空间,那么我会释放掉之前的 100 个字节,然后重新分配个 1000 字节的空间,以后但凡需要小于 1000 字节的内存空间,我都不会发生分配操作,性能上来讲更友好,对于使用者来讲更简单一些
对于使用者来说只需要给我大小,不用考虑中间是分配还是释放还是重新分配,给大小拿地址,非常友好,这是 MixMemory 提高性能的核心点,就是让同一块内存尽可能地重复的去使用它,而不是每次都去分配一块新内存
这种方法是一个常见的内存管理策略,称为 lazy allocation 或 lazy resizing。其背后的思路是,如果已经分配了足够的内存来满足当前的请求,那么就没有必要重新分配。这样可以避免频繁的内存分配和释放操作,从而提高性能。
MixMemory 类为 CPU 和 GPU 内存分配和管理提供了一个封装。它有助于确保在分配新内存之前释放现有的内存,并通过 AutoDevice 来完成指定 device 上的内存分配,它简化了 CUDA 内存管理,通过内部跟踪和自动释放来实现内存的复用。
在 main.cpp 中,我们分配 host 和 device 内存时,就可以直接使用 MixMemory 了,部分代码如下:
MixMemory input_data;
float* input_data_host = input_data.cpu<float>(input_numel);
float* input_data_device = input_data.gpu<float>(input_numel);MixMemory output_data;
float* output_data_host = output_data.cpu<float>(num_classes);
float* output_data_device = output_data.gpu<float>(num_classes);
使用 MixMemory 相对来说轻松多了,不用去 cudaMallocHost、cudaMalloc 手动分配内存以及 cudaFreeHost、cudaFree 手动释放内存了,并且还可以解决内存复用的问题,
2. 补充知识
关于 MixMemory 的封装,你需要知道:(form 杜老师)
1. MixMemory 的存在,是为了避免每次内存都要分配和释放,对内存做重复使用提升性能
- 如果第二次执行 gpu 获取 gpu 内存,会检查当前已经分配是否够用,如果不够则重新分配,够就直接返回
2. MixMemory 的封装,考虑到分配时当前设备 ID 如果不同该怎么办,释放时,当前设备 ID 不同怎么办
3. 对 cuda 的基本操作做了封装,对于这类常用的功能进行封装,便于使用
4. AutoDevice,对于当前设备 ID old 和准备分配内存所操作的设备 ID target 不用时,解决如下问题:
- 获取当前设备 ID old
- 设置当前设备 ID 为 target
- 进行内存分配,分配结果在目的 ID target 上
- 设置当前设备 ID 为 old ID
总结
本次课程学习了对 memory 的封装,我们每次都要去 cudaMalloc、cudaMallocHost 分配 device 和 host 内存,然后去 cudaFree、cudaFreeHost 去释放内存,非常麻烦,我们对混合内存进行了封装,通过 MixMemory 实现的内存的分配和释放以及内存的复用,其中复用思想在于申请分配的内存大于之前已经分配的内存才去释放并重新分配,否则直接返回之前已经分配好的内存,这样可以避免频繁的内存分配和释放操作,从而提高性能。
相关文章:
8.2.tensorRT高级(3)封装系列-内存管理的封装,内存的复用
目录 前言1. 内存管理封装2. 补充知识总结 前言 杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。 本次课程学习 tensorRT 高级-内存管理的封装&…...

Keepalived入门指南:实现故障转移和负载均衡
文章目录 一、简介1. Keepalived概述2. 高可用性和负载均衡的重要性 二、故障转移1. 什么是故障转移2. Keepalived的故障转移原理a) VRRP协议b) 虚拟路由器ID和优先级 3. 配置Keepalived实现故障转移a) 主备服务器的设置b) 监控网络接口c) 虚拟IP的配置d) 备份服务器接管流程 三…...

cuOSD(CUDA On-Screen Display Library)库的学习
目录 前言1. cuOSD1.1 Description1.2 Getting started1.3 For Python Interface1.4 Demo1.5 Performance Table 2. cuOSD案例2.1 环境配置2.2 simple案例2.3 segment案例2.4 segment2案例2.5 polyline案例2.6 comp案例2.7 perf案例 3. cuOSD浅析3.1 simple_draw函数 4. 补充知…...

c++函数指针基本用法
将函数像变量一样传递,实际上拿到的是函数的地址,由于函数类型的多样,可以使用auto关键字,可以使用 void(*function2)() ,不过它太繁琐,因此使用typedef 起个名字 typedef void(*HelloWorldFunction)(); 叫…...

Java创建对象的几种方式
在Java中,对象是程序中的一种基本元素,它通过类定义和创建。本篇教程旨在介绍Java中创建对象的几种方式,包括使用new关键字、反射、clone、反序列化等方式。 使用new关键字创建对象 在Java中,最常用的创建对象方式是使用new关键…...

Docker实战专栏简介
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
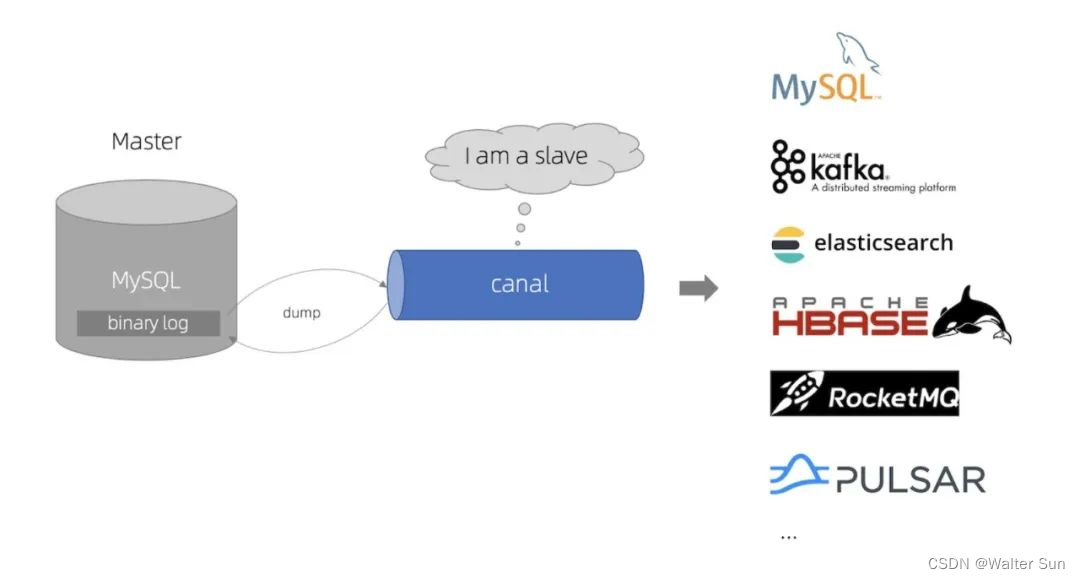
解放数据库,实时数据同步利器:Alibaba Canal
文章首发地址 Canal是一个开源的数据库增量订阅&消费组件,主要用于实时数据同步和数据订阅的场景,特别适用于构建分布式系统、数据仓库、缓存更新等应用。它支持MySQL、阿里云RDS等主流数据库,能够实时捕获数据库的增删改操作ÿ…...

机器学习基础之《分类算法(3)—模型选择与调优》
作用是如何选择出最好的K值 一、什么是交叉验证(cross validation) 1、定义 交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试&#x…...
Datawhale Django后端开发入门 TASK03 QuerySet和Instance、APIVIew
一、QuerySet QuerySet 是 Django 中的一个查询集合,它是由 Model.objects 方法返回的,并且可以用于生成数据库中所有满足一定条件的对象的列表。 QuerySet 在 Django 中表示从数据库中获取的对象集合,它是一个可迭代的、类似列表的对象集合。主要特点…...

Python 网页解析中级篇:深入理解BeautifulSoup库
在Python的网络爬虫中,BeautifulSoup库是一个重要的网页解析工具。在初级教程中,我们已经了解了BeautifulSoup库的基本使用方法。在本篇文章中,我们将深入学习BeautifulSoup库的进阶使用。 一、复杂的查找条件 在使用find和find_all方法查找…...
IDEA 如何制作代码补丁?IDEA 生成 patch 和使用 patch
什么是升级补丁? 比如你本地修复的 bug,需要把增量文件发给客户,很多场景下大家都需要手工整理修改的文件,并整理好目录,这个很麻烦。那有没有简单的技巧呢?看看 IDEA 生成 patch 和使用 patch 的使用。 介…...
Redis专题-秒杀
Redis专题-并发/秒杀 开局一张图,内容全靠“编”。 昨天晚上在群友里看到有人在讨论库存并发的问题,看到这里我就决定写一篇关于redis秒杀的文章。 1、理论部分 我们看看一般我们库存是怎么出问题的 其实redis提供了两种解决方案:加锁和原子操…...
C++笔记之std::move和右值引用的关系、以及移动语义
C笔记之std::move和右值引用的关系、以及移动语义 code review! 文章目录 C笔记之std::move和右值引用的关系、以及移动语义1.一个使用std::move的最简单C例子2.std::move 和 T&& reference_name expression;对比3.右值引用和常规引用的经典对比——移动语义和拷贝语…...

ES6自用笔记
目录 原型链 引用类型:__proto__(隐式原型)属性,属性值是对象函数:prototype(原型)属性,属性值是对象 相关方法 person.prototype.isPrototypeOf(stu) Object.getPrototypeOf(Object)替换已不推荐的Object._ _ proto _ _ Ob…...

【BASH】回顾与知识点梳理(二十九)
【BASH】回顾与知识点梳理 二十九 二十九. 进程和工作管理29.1 什么是进程 (process)进程与程序 (process & program)子进程与父进程:fork and exec:进程呼叫的流程系统或网络服务:常驻在内存的进程 29.2 Linux 的多人多任务环境多人环境…...

Docker的Cgroup资源限制
Docker通过Cgroup来控制容器使用的资源配额,包括 CPU、内存、磁盘三大方面,基本覆盖了常见的资源配颡和使用量控制。 Cgoup 是CotrolGroups 的缩写,是Linux 内核提供的一种可以限制、记录、隔高进程组所使用的物理资源(如CPU、内存…...

AI智能语音机器人的基本业务流程
先画个图,了解下AI语音机器人的基本业务流程。 上图是一个AI语音机器人的业务流程,简单来说就是首先要配置话术,就是告诉机器人在遇到问题该怎么回答,这个不同公司不同行业的差别比较大,所以一般每个客户都会配置其个性…...
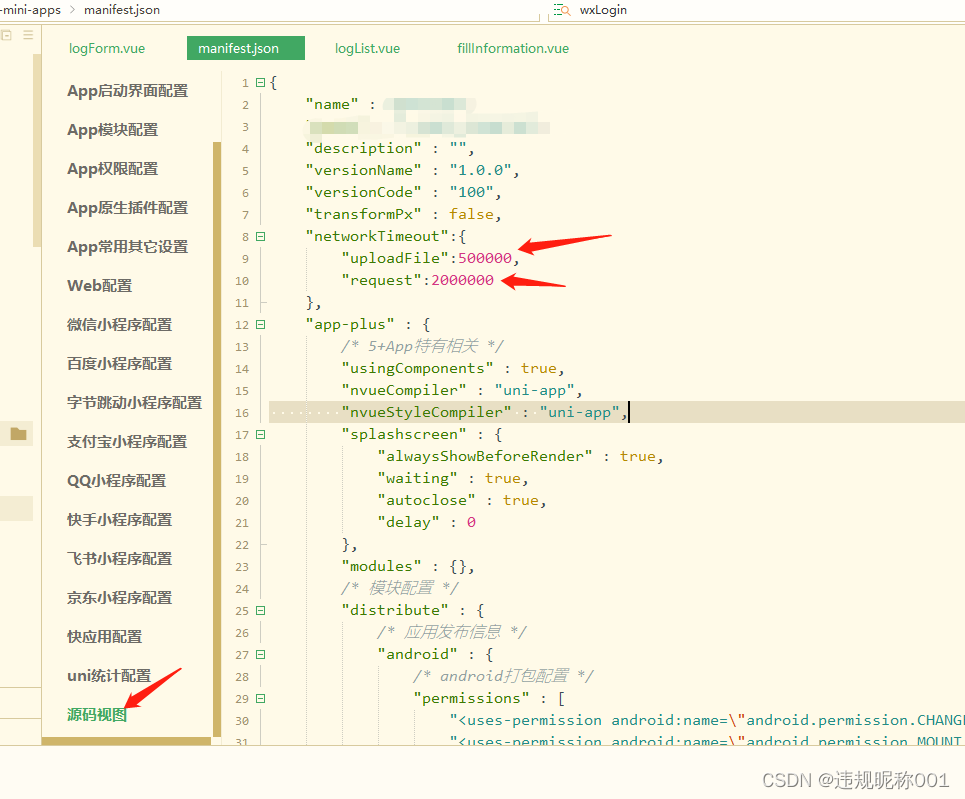
uniapp 上传比较大的视频文件就超时
uni.uploadFile,上传超过10兆左右的文件就报错err:uploadFile:fail timeout,超时 解决: 在manifest.json文件中做超时配置 uni.uploadFile({url: this.action,method: "POST",header: {Authorization: uni.getStorage…...
CSS简介
目录 CSS CSS概念 核心概念 为什么需要CSS 语法 CSS的引入方式 内联样式(行内样式) 内部样式 外部样式(推荐) CSS CSS概念 CSS(Cascading Style Sheets)层叠样式表,又叫级联样式表&am…...
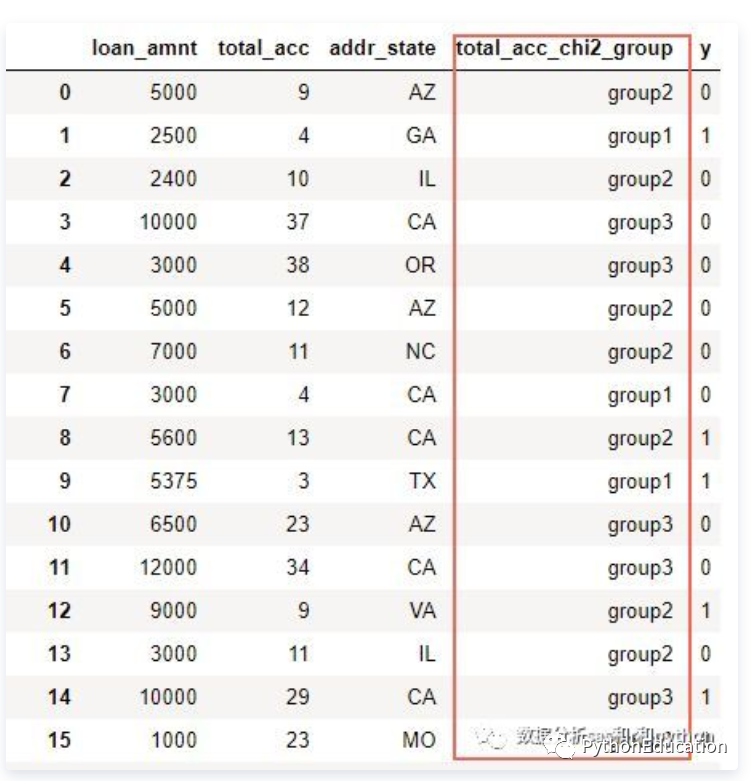
卡方分箱(chi-square)
统计学,风控建模经常遇到卡方分箱算法ChiMerge。卡方分箱在金融信贷风控领域是逻辑回归评分卡的核心,让分箱具有统计学意义(单调性)。卡方分箱在生物医药领域可以比较两种药物或两组病人是否具有显著区别。但很多建模人员搞不清楚…...

曲轴基于灵敏度的拓扑优化-CAE操作过程
前言 本示例展示了曲轴基于灵敏度的拓扑优化的基本工作流程。 该模型为简化曲轴模型,设计区域采用壳单元建模,轴体部分采用梁单元建模,壳单元与梁单元之间通过 RBE2 多点约束单元 进行耦合连接。 本次优化的目标是通过体积最小化实现曲轴的轻…...

从零构建高频无线传输系统:调幅技术实战解析
1. 调幅无线传输系统入门指南 第一次接触调幅无线传输系统时,我也被各种专业术语搞得一头雾水。简单来说,调幅(AM)就是通过改变载波信号的幅度来传递信息的技术。想象一下快递员送包裹:载波就像快递车,而我们要发送的信息就是包裹…...

有桥BOOST PFC变换器原理、工作模式和控制模式的优缺点
前言在现代电力电子设备中,功率因数校正(PFC)技术已经成为不可或缺的核心环节。随着全球各国对电网谐波污染的管控日益严格(如 IEC 61000-3-2 标准,对各类用电设备的谐波电流发射施加严格限值;例如对于功率…...

为AI编码助手集成aislop-skill:实时代码质量检测与修复
1. 项目概述:为AI编码助手装上“质检员”如果你和我一样,日常重度依赖Cursor、Windsurf这类AI驱动的IDE,或者频繁使用Claude Code、Gemini CLI等代码生成工具,那你一定遇到过这样的场景:AI助手生成的代码,功…...
)
从网页地图卡顿说起:深入理解瓦片加载与前端性能优化(Leaflet/Mapbox实战)
从网页地图卡顿说起:深入理解瓦片加载与前端性能优化(Leaflet/Mapbox实战) 当用户在地图应用中频繁缩放拖拽却遭遇卡顿、白屏时,体验会瞬间崩塌。作为前端开发者,我们该如何从底层机制入手解决这些问题?本文…...

德国工业4.0:从顶层设计到车间实践的制造业数字化转型
1. 工业4.0浪潮下的欧洲:一场由德国引领的深度变革提到德国制造,很多人脑海里蹦出来的词是“严谨”、“保守”甚至“刻板”。没错,德国人对于工业流程、制造工艺和质量标准的执着,有时近乎偏执。但正是这种对“传统”的极致坚守&a…...

脉冲神经网络SAST训练方法:解决代理-硬件转换差距
1. 脉冲神经网络与传感器计算的挑战脉冲神经网络(SNNs)作为第三代神经网络模型,其核心特征是采用离散的脉冲信号进行信息传递和处理。这种事件驱动的计算方式与传统的连续激活神经网络(ANNs)有着本质区别。在传感器端计…...

本地化AI编码助手codex-assistant:部署、实战与安全指南
1. 项目概述:一个本地化的AI编码助手最近在折腾一个挺有意思的开源项目,叫codex-assistant。简单来说,它就是一个能让你用自然语言直接驱动本地代码任务的工具。想象一下,你对着一个命令行窗口说“给我写个Python函数,…...

Android本地AI智能家居框架:ZeroClaw架构设计与工程实践
1. 项目缘起与核心愿景几年前,我还在为一个智能家居项目焦头烂额,试图让家里的灯光、空调和音箱能听懂人话,而不是只会执行预设的“回家模式”或“睡眠模式”。当时市面上主流的方案,要么是依赖某个封闭的云平台,所有指…...

【波导仿真】基于矢量有限元法分析均匀波导附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &#x…...