【深入探究人工智能】:常见机器学习算法总结
文章目录
- 1、前言
- 1.1 机器学习算法的两步骤
- 1.2 机器学习算法分类
- 2、逻辑回归算法
- 2.1 逻辑函数
- 2.2 逻辑回归可以用于多类分类
- 2.3 逻辑回归中的系数
- 3、线性回归算法
- 3.1 线性回归的假设
- 3.2 确定线性回归模型的拟合优度
- 3.3线性回归中的异常值处理
- 4、支持向量机(SVM)算法
- 4.1 优点
- 4.2 缺点
- 🍀小结🍀


🎉博客主页:小智_x0___0x_
🎉欢迎关注:👍点赞🙌收藏✍️留言
🎉系列专栏:小智带你闲聊
🎉代码仓库:小智的代码仓库
1、前言
机器学习算法是一种基于数据和经验的算法,通过对大量数据的学习和分析,自动发现数据中的模式、规律和关联,并利用这些模式和规律来进行预测、分类或优化等任务。机器学习算法的目标是从数据中提取有用的信息和知识,并将其应用于新的未知数据中。

1.1 机器学习算法的两步骤
机器学习算法通常包括两个主要步骤:训练和预测。在训练阶段,算法使用一部分已知数据(训练数据集)来学习模型或函数的参数,以使其能够对未知数据做出准确的预测或分类。在预测阶段,算法将学习到的模型应用于新的数据,通过模型对数据进行预测、分类或其他任务。
1.2 机器学习算法分类
机器学习算法可以是基于统计学原理、优化方法、神经网络等等。根据学习的方式不同,机器学习算法可以分为监督学习、无监督学习和强化学习等几种类型。不同的机器学习算法适用于不同的问题和数据类型,选择合适的算法可以提高机器学习的任务效果。
-
监督学习算法:监督学习算法需要训练数据集中包含输入和对应的输出(或标签)信息。常用的监督学习算法包括:线性回归、逻辑回归、决策树、支持向量机、朴素贝叶斯、人工神经网络等。
-
无监督学习算法:无监督学习算法不需要训练数据集中的输出信息,主要用于数据的聚类和降维等问题。常用的无监督学习算法包括:K均值聚类、层次聚类、主成分分析、关联规则挖掘等。
-
强化学习算法:强化学习算法通过与环境进行交互,试图找到最优策略来最大化奖励。常用的强化学习算法包括:Q学习、深度强化学习算法等。
此外,还有一些常用的机器学习算法和技术,如集成学习、降维方法、深度学习、迁移学习、半监督学习等,它们通过不同的方式和建模方法来解决不同的问题。选择合适的机器学习算法需要考虑问题的性质、数据的特点、算法的可解释性和计算效率等因素。
2、逻辑回归算法
逻辑回归是一种统计方法,用于根据一个或多个自变量预测二元结果,例如成功或失败。它是机器学习中的一种流行技术,通常用于分类任务,例如确定电子邮件是否是垃圾邮件,或预测客户是否会流失。

逻辑回归模型基于逻辑函数,逻辑函数是一个sigmoid函数,它将输入变量映射到 0 到 1 之间的概率。然后使用该概率对结果进行预测。
逻辑回归模型由以下方程表示:
P ( y = 1 ∣ x ) = 1 / ( 1 + e − ( b 0 + b 1 x 1 + b 2 x 2 + … + b n ∗ x n ) ) P(y=1|x) = 1/(1+e^-(b0 + b1x1 + b2x2 + … + bn*xn)) P(y=1∣x)=1/(1+e−(b0+b1x1+b2x2+…+bn∗xn))
其中 P(y=1|x) 是给定输入变量 x 时结果 y 为 1 的概率,b0 是截距,b1, b2, …, bn 是输入变量 x1, x2, … 的系数, xn。通过在数据集上训练模型并使用优化算法(例如梯度下降)来最小化成本函数(通常是对数损失)来确定系数。模型训练完成后,就可以通过输入新数据并计算结果为 1 的概率来进行预测。将结果分类为 1 或 0 的阈值通常设置为 0.5,但这可以根据情况进行调整具体任务以及误报和漏报之间所需的权衡。
2.1 逻辑函数
逻辑函数,也称为 s i g m o i d sigmoid sigmoid函数,是一条 S 形曲线,将任何实数值映射到 0 到 1 之间的值。它的定义为 f ( x ) = 1 / ( 1 + e − x ) f(x) = 1 / (1 + e^-x ) f(x)=1/(1+e−x)其中 e 是自然对数的底。逻辑函数在逻辑回归中用于对二元结果的概率进行建模。

2.2 逻辑回归可以用于多类分类
逻辑回归可用于多类分类,方法是为每个类创建单独的二元逻辑回归模型并选择预测概率最高的类。这被称为一对一或一对一的方法。或者,我们可以使用 s o f t m a x softmax softmax回归,它是逻辑回归的推广,可以直接处理多个类。
2.3 逻辑回归中的系数
逻辑回归中的系数表示在保持所有其他预测变量不变的情况下,预测变量发生一个单位变化时结果的对数几率的变化。优势比可用于解释系数的大小。优势比大于 1 表示预测变量增加一个单位会增加结果的可能性,而优势比小于 1 表示预测变量增加一个单位会降低结果的可能性。
3、线性回归算法
线性回归是一种统计方法,用于检查两个连续变量之间的关系:一个自变量和一个因变量。线性回归的目标是通过一组数据点找到最佳拟合线,然后可用于对未来的观察进行预测。

简单线性回归模型的方程为:
y = b 0 + b 1 ∗ x y = b0 + b1*x y=b0+b1∗x
其中 y 是因变量,x 是自变量,b0 是 y 截距(直线与 y 轴的交点),b1 是直线的斜率。斜率表示给定 x 变化时 y 的变化。
为了确定最佳拟合线,我们使用最小二乘法,该方法找到使预测 y 值与实际 y 值之间的平方差之和最小化的线。线性回归也可以扩展到多个自变量,称为多元线性回归。多元线性回归模型的方程为: y = b 0 + b 1 x 1 + b 2 x 2 + … + b n ∗ x n y = b0 + b1x1 + b2x2 + … + bn*xn y=b0+b1x1+b2x2+…+bn∗xn。其中 x1, x2, …, xn 是自变量,b1, b2, …, bn 是相应的系数。
线性回归可用于简单线性回归和多元线性回归问题。系数 b0 和 b1, …, bn 使用最小二乘法估计。一旦估计了系数,它们就可以用于对因变量进行预测。线性回归可用于对未来进行预测,例如预测股票的价格或将出售的产品的单位数量。然而,线性回归是一种相对简单的方法,可能并不适合所有问题。它假设自变量和因变量之间的关系是线性的,但情况可能并非总是如此。此外,线性回归对异常值高度敏感,这意味着如果存在任何不遵循数据总体趋势的极值,将会显着影响模型的准确性。
总之,线性回归是一种强大且广泛使用的统计方法,可用于检查两个连续变量之间的关系。它是一个简单但功能强大的工具,可用于预测未来。但是,请务必记住,线性回归假设变量之间存在线性关系,并且对异常值敏感,这可能会影响模型的准确性。
3.1 线性回归的假设
-
线性:自变量和因变量之间的关系是线性的。
-
独立性:观察结果彼此独立。
-
同方差性:误差项的方差在自变量的所有水平上都是恒定的。
-
正态性:误差项呈正态分布。
-
无多重共线性:自变量彼此不高度相关。
-
无自相关:误差项与其自身不自相关。
3.2 确定线性回归模型的拟合优度
有多种方法可以确定线性回归模型的拟合优度:
-
R 平方:R 平方是一种统计度量,表示因变量中的方差由模型中的自变量解释的比例。R 平方值为 1 表示模型解释了因变量中的所有方差,值为 0 表示模型没有解释任何方差。
-
调整 R 平方:调整 R 平方是 R 平方的修改版本,它考虑了模型中自变量的数量。在比较具有不同数量自变量的模型时,它可以更好地指示模型的拟合优度。
-
均方根误差 (RMSE):RMSE 衡量预测值与实际值之间的差异。RMSE 较低表明模型与数据的拟合效果更好。
-
平均绝对误差 (MAE):MAE 测量预测值与实际值之间的平均差异。MAE 越低表明模型与数据的拟合效果越好。

3.3线性回归中的异常值处理
线性回归中的异常值可能会对模型的预测产生重大影响,因为它们可能会扭曲回归线。处理线性回归中的异常值有多种方法,包括以下几点:
-
删除异常值:一种选择是在训练模型之前简单地从数据集中删除异常值。然而,这可能会导致重要信息的丢失。
-
转换数据:应用转换(例如记录数据日志)有助于减少异常值的影响。
-
使用稳健回归方法:稳健回归方法(例如 RANSAC 或 Theil-Sen)对异常值的敏感度低于传统线性回归。
-
使用正则化:正则化可以通过在成本函数中添加惩罚项来帮助防止由异常值引起的过度拟合。
总之,采用什么方法将取决于特定的数据集和分析的目标。
4、支持向量机(SVM)算法
支持向量机 (SVM) 是一种监督学习算法,可用于分类或回归问题。SVM 背后的主要思想是通过最大化间隔(边界与每个类最近的数据点之间的距离)来找到分隔数据中不同类的边界。这些最接近的数据点称为支持向量。

当数据不可线性分离(这意味着数据不能用直线分离)时,SVM 特别有用。在这些情况下,SVM 可以使用称为核技巧的技术将数据转换为更高维的空间,其中可以找到非线性边界。SVM 中使用的一些常见核函数包括多项式、径向基函数 (RBF) 和 s i g m o i d sigmoid sigmoid。
SVM 的主要优点之一是它们在高维空间中非常有效,并且即使在特征数量大于样本数量时也具有良好的性能。此外,SVM 内存效率高,因为它们只需要存储支持向量,而不是整个数据集。另一方面,SVM 对核函数和算法参数的选择很敏感。还需要注意的是,SVM 不适合大型数据集,因为训练时间可能相当长。总之,支持向量机(SVM)是一种强大的监督学习算法,可用于分类和回归问题,特别是当数据不可线性分离时。该算法以其在高维空间中的良好性能以及发现非线性边界的能力而闻名。然而,它对核函数和参数的选择很敏感,也不适合大型数据集。
4.1 优点
-
在高维空间中有效:即使当特征数量大于样本数量时,SVM 也具有良好的性能。
-
内存效率高:SVM 只需要存储支持向量,而不需要存储整个数据集,因此内存效率高。
-
通用性:SVM 可用于分类和回归问题,并且可以使用核技巧处理非线性可分离数据。
-
对噪声和异常值具有鲁棒性:SVM 对数据中的噪声和异常值具有鲁棒性,因为它们仅依赖于支持向量。
4.2 缺点
-
对核函数和参数的选择敏感:SVM 的性能高度依赖于核函数的选择和算法参数。
-
不适合大型数据集:对于大型数据集,SVM 的训练时间可能会相当长。
-
解释结果困难:解释 SVM 的结果可能很困难,特别是在使用非线性核时。
-
不适用于重叠类:当类有明显重叠时,SVM 可能会遇到困难。
总之,SVM 是一种强大且通用的机器学习算法,可用于分类和回归问题,特别是当数据不可线性分离时。然而,它们可能对核函数和参数的选择敏感,不适合大型数据集,并且难以解释结果。
🍀小结🍀
今天我们学习了"机器学习算法"相信大家看完有一定的收获。种一棵树的最好时间是十年前,其次是现在! 把握好当下,合理利用时间努力奋斗,相信大家一定会实现自己的目标!加油!创作不易,辛苦各位小伙伴们动动小手,三连一波💕💕~~~,本文中也有不足之处,欢迎各位随时私信点评指正!

相关文章:
【深入探究人工智能】:常见机器学习算法总结
文章目录 1、前言1.1 机器学习算法的两步骤1.2 机器学习算法分类 2、逻辑回归算法2.1 逻辑函数2.2 逻辑回归可以用于多类分类2.3 逻辑回归中的系数 3、线性回归算法3.1 线性回归的假设3.2 确定线性回归模型的拟合优度3.3线性回归中的异常值处理 4、支持向量机(SVM&a…...

设计模式之解释器模式详解及实例
1、解释器设计模式概述: 解释器模式(Interpreter Pattern)是一种设计模式,它主要用于描述如何构建一个解释器以解释特定的语言或表达式。该模式定义了一个文法表示和解释器的类结构,用于解释符合该文法规则的语句。解…...
Nodejs沙箱逃逸--总结
一、沙箱逃逸概念 JavaScript和Nodejs之间有什么区别:JavaScript用在浏览器前端,后来将Chrome中的v8引擎单独拿出来为JavaScript单独开发了一个运行环境,因此JavaScript也可以作为一门后端语言,写在后端(服务端&#…...

No115.精选前端面试题,享受每天的挑战和学习
文章目录 变量提升和函数提升的顺序Event Loop封装 FetchAPI,要求超时报错的同时,取消执行的 promise(即不继续执行)强缓存和协商缓存的区别token可以放在cookie里吗? 变量提升和函数提升的顺序 在JavaScript中&#…...
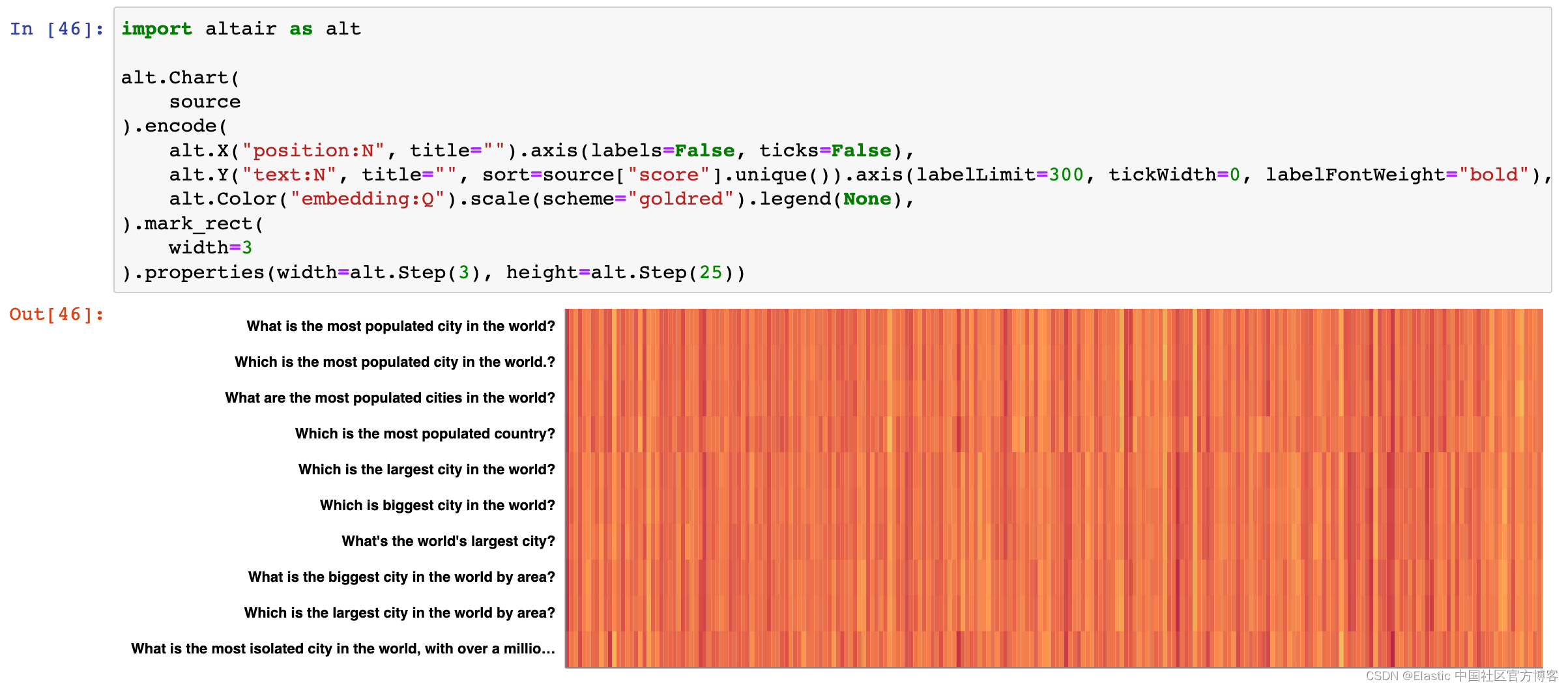
Elasticsearch:语义搜索 - Semantic Search in python
当 OpenAI 于 2022 年 11 月发布 ChatGPT 时,引发了人们对人工智能和机器学习的新一波兴趣。 尽管必要的技术创新已经出现了近十年,而且基本原理的历史甚至更早,但这种巨大的转变引发了各种发展的“寒武纪大爆炸”,特别是在大型语…...
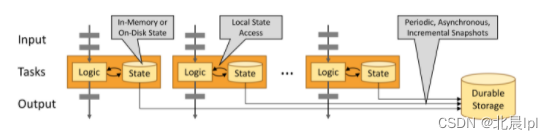
Flink学习笔记(一)
流处理 批处理应用于有界数据流的处理,流处理则应用于无界数据流的处理。 有界数据流:输入数据有明确的开始和结束。 无界数据流:输入数据没有明确的开始和结束,或者说数据是无限的,数据通常会随着时间变化而更新。 在…...
[Raspberry Pi]如何用VNC遠端控制樹莓派(Ubuntu desktop 23.04)?
之前曾利用VMware探索CentOS,熟悉Linux操作系統的指令和配置運作方式,後來在樹莓派價格飛漲的時期,遇到貴人贈送Raspberry Pi 4 model B / 8GB,這下工具到位了,索性跳過樹莓派官方系統(Raspberry Pi OS),直…...

17.HPA和rancher
文章目录 HPA部署 metrics-server部署HPA Rancher部署Rancherrancher添加集群仪表盘创建 namespace仪表盘创建 Deployments仪表盘创建 service 总结 HPA HPA(Horizontal Pod Autoscaling)Pod 水平自动伸缩,Kubernetes 有一个 HPA 的资源&…...
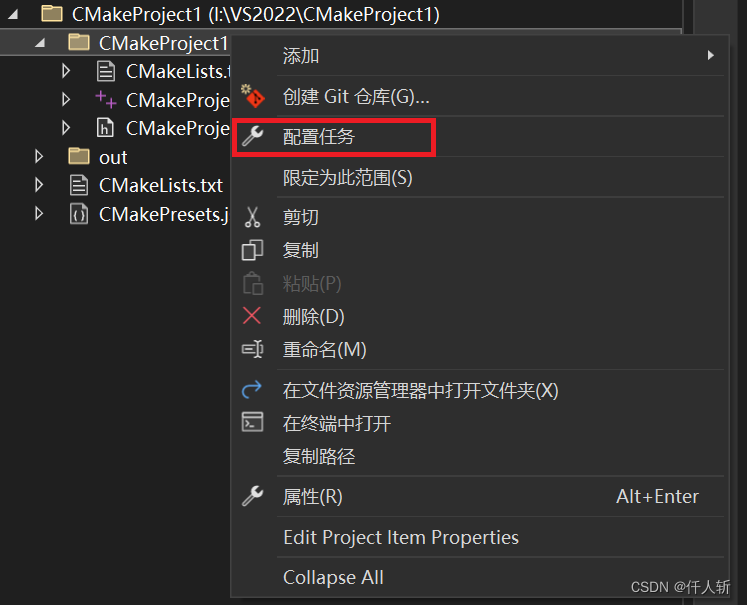
VS2022远程Linux使用cmake开发c++工程配置方法
文章目录 远程连接CMakePresets.json的配置Task.vs.json配置launch.vs.json配置最近使用别人在VS2015上使用visualgdb搭建的linux开发环境,各种不顺手,一会代码不能调转了,一会行号没了,调试的时候断不到正确的位置,取消的断点仍然会进。因此重新摸索了一套使用vs的远程开…...

《强化学习:原理与Python实战》——可曾听闻RLHF
前言: RLHF(Reinforcement Learning with Human Feedback,人类反馈强化学习)是一种基于强化学习的算法,通过结合人类专家的知识和经验来优化智能体的学习效果。它不仅考虑智能体的行为奖励,还融合了人类专家…...
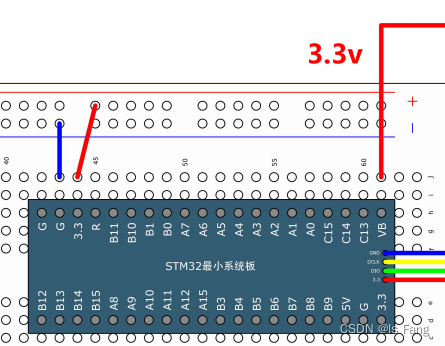
STM32——RTC实时时钟
文章目录 Unix时间戳UTC/GMT 时间戳转换BKP简介BKP基本结构读写BKP备份寄存器电路设计关键代码 RTC简介RTC框图RTC基本结构硬件电路RTC操作注意事项读写实时时钟电路设计关键代码 Unix时间戳 Unix 时间戳(Unix Timestamp)定义为从UTC/GMT的1970年1月1日…...

webSocket 开发
1 认识webSocket WebSocket_ohana!的博客-CSDN博客 一,什么是websocket WebSocket是HTML5下一种新的协议(websocket协议本质上是一个基于tcp的协议)它实现了浏览器与服务器全双工通信,能更好的节省服务器资源和带宽…...
c#设计模式-结构型模式 之 代理模式
前言 由于某些原因需要给某对象提供一个代理以控制对该对象的访问。这时,访问对象不适合或者不能直接 引用目标对象,代理对象作为访问对象和目标对象之间的中介。在学习代理模式的时候,可以去了解一下Aop切面编程AOP切面编程_aop编程…...

openpnp - 自动换刀的设置
文章目录 openpnp - 自动换刀的设置概述笔记采用的openpnp版本自动换刀库的类型选择自动换刀设置前的注意事项先卸掉吸嘴座上所有的吸嘴删掉所有的吸嘴设置自动换刀的视觉识别设置吸嘴座为自动换刀 - 以N1为例备注补充 - 吸嘴轴差个0.3mm, 就有可能怼坏吸嘴END openpnp - 自动换…...
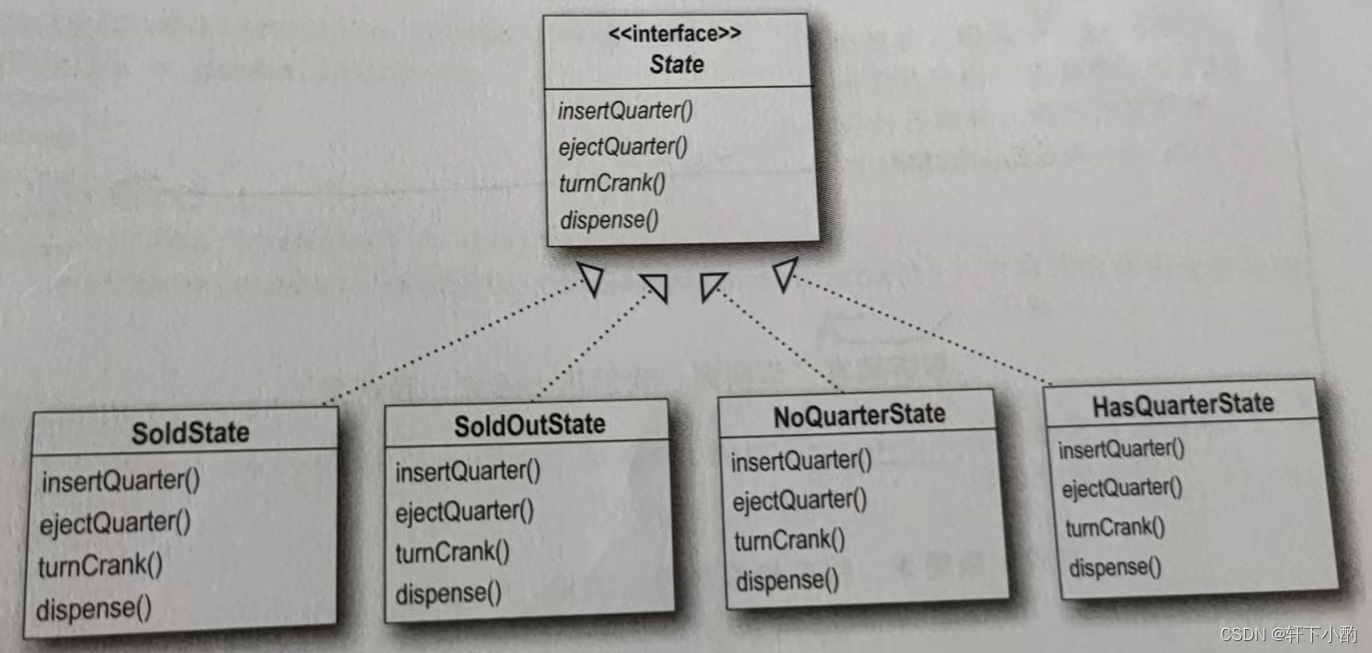
《HeadFirst设计模式(第二版)》第十章代码——状态模式
如下图所示,这是一个糖果机的状态机图,要求使用代码实现: 初始版本: package Chapter10_StatePattern.Origin;/*** Author 竹心* Date 2023/8/19**/public class GumballMachine {final static int SOLD_OUT 0;final static int…...
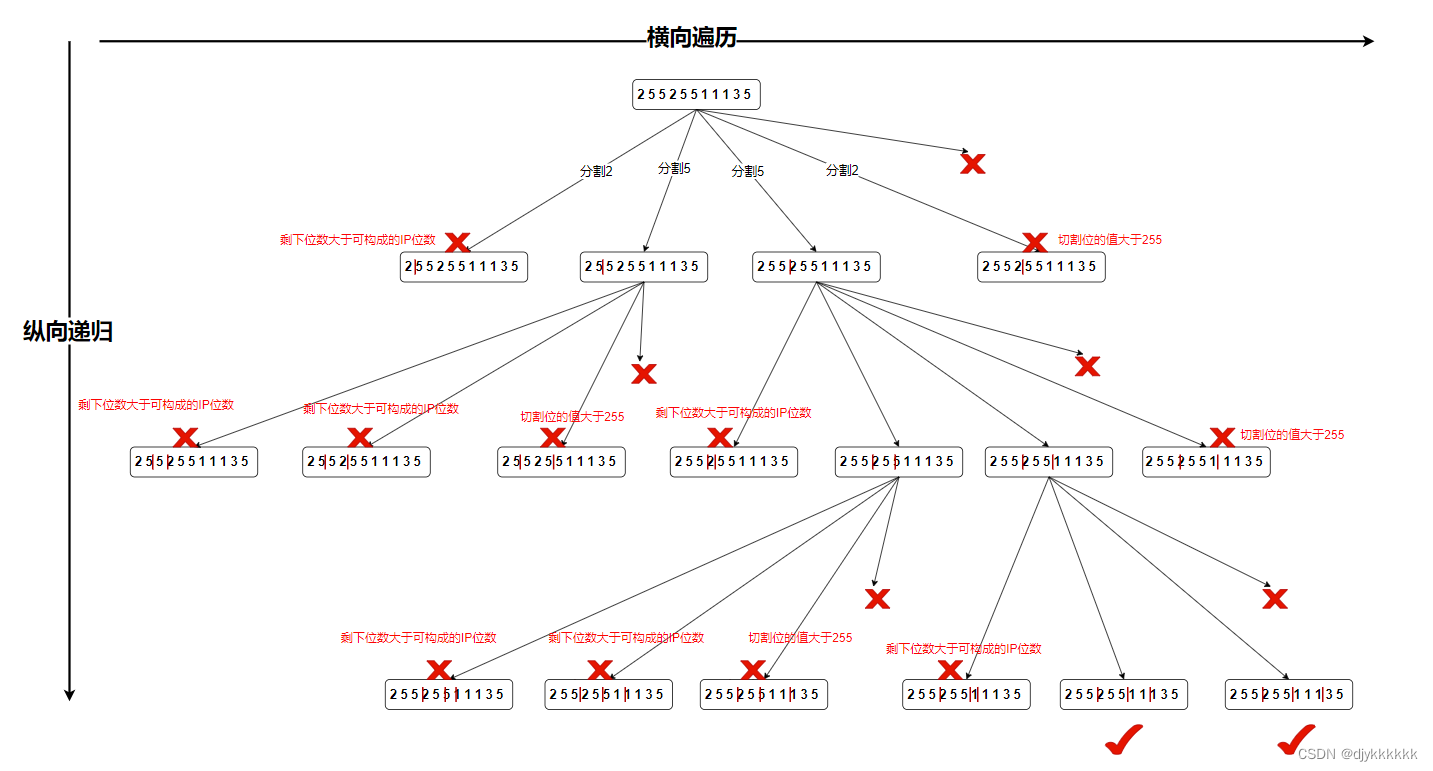
day-25 代码随想录算法训练营(19)回溯part02
216.组合总和||| 思路:和上题一样,差别在于多了总和,但是数字局限在1-9 17.电话号码的字母组合 思路:先纵向遍历第i位电话号码对于的字符串,再横向递归遍历下一位电话号码 93.复原IP地址 画图分析: 思…...

PG逻辑备份与恢复
文章目录 创建测试数据pg_dump 备份pg_restore 恢复pg_restore 恢复并行备份的文件PG 只导出指定函数 创建测试数据 drop database if exists test; create database test ; \c test create table t1(id int primary key); create table t2(id serial primary key, name varch…...
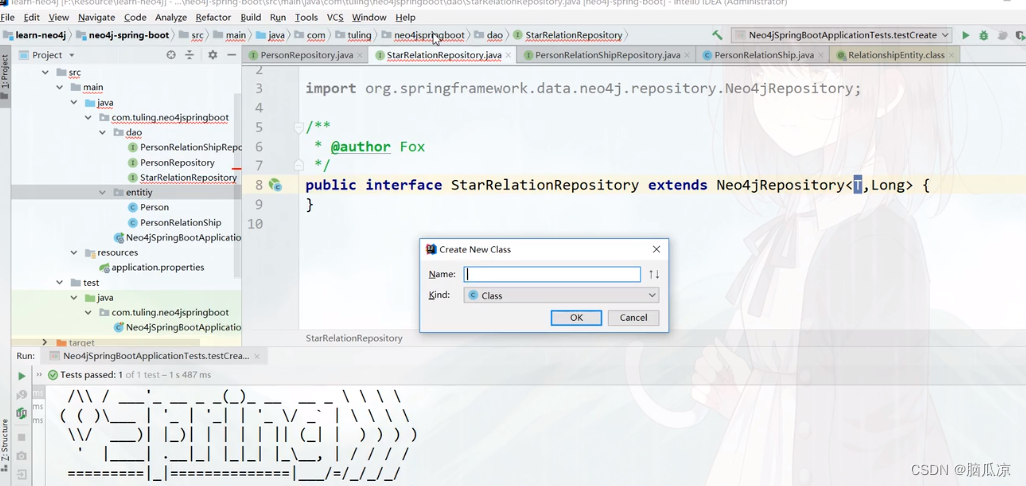
图数据库_Neo4j和SpringBoot整合使用_实战创建明星关系图谱---Neo4j图数据库工作笔记0010
然后我们再来看一下这个明星关系图谱 可以看到这里 这个是原来的startRelation 我们可以写CQL去查询对应的关系 可以看到,首先查询出来以后,然后就可以去创建 我们可以把写的创建明星关系的CQL,拿到 springboot中去执行 可以看到,这里我们先写一个StarRelationRepository,然…...
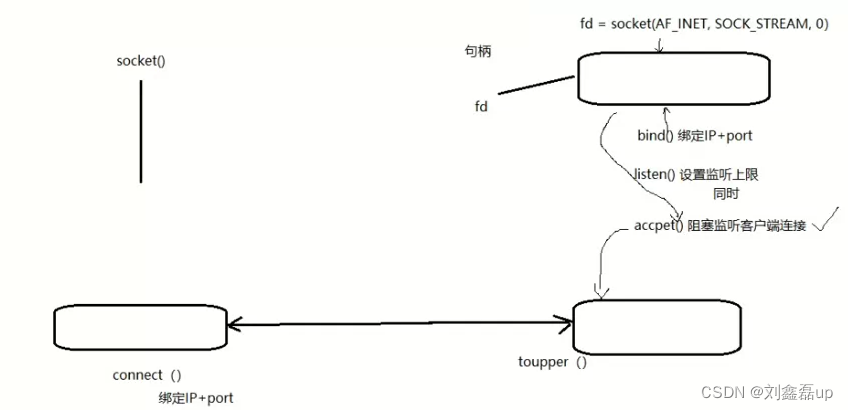
Linux网络编程:Socket套接字编程(Server服务器 Client客户端)
文章目录: 一:定义和流程分析 1.定义 2.流程分析 3.网络字节序 二:相关函数 IP地址转换函数inet_pton inet_ntop(本地字节序 网络字节序) socket函数(创建一个套接字) bind函数(给socket绑定一个服务器地址结…...

Mac OS下应用Python+Selenium实现web自动化测试
在Mac环境下应用PythonSelenium实现web自动化测试 在这个过程中要注意两点: 1.在终端联网执行命令“sudo pip install –U selenium”如果失败了的话,可以尝试用命令“sudo easy_install selenium”来安装selenium; 2.安装好PyCharm后新建project&…...

Wand-Enhancer终极指南:3步免费解锁WeMod Pro高级功能的完整方案
Wand-Enhancer终极指南:3步免费解锁WeMod Pro高级功能的完整方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费…...

FS8024A芯片实现USB-C PD诱骗:打造TYPE-C转DC电源转接头方案
1. 项目概述:一个“小接口”背后的大世界 最近在折腾一个便携显示器项目,手头有现成的12V驱动板,但供电却成了麻烦事。现在谁还愿意随身带个笨重的12V电源适配器?满世界都是USB-C接口的充电宝和笔记本充电器。于是,一个…...

大语言模型百科全书:LLMSurvey项目解析与QLoRA微调实战
1. 项目概述:一份关于大语言模型的“百科全书”如果你最近在关注人工智能,特别是大语言模型(LLM)领域,那么你很可能已经感受到了信息过载的冲击。每天都有新的模型发布、新的评测榜单刷新、新的技术论文涌现。对于研究…...

【限时开放】Midjourney未来主义风格权威认证路径:完成这5个里程碑任务,获取由Adobe+MJ Labs联合签发的Futurism Prompt Architect证书
更多请点击: https://intelliparadigm.com 第一章:【限时开放】Midjourney未来主义风格权威认证路径:完成这5个里程碑任务,获取由AdobeMJ Labs联合签发的Futurism Prompt Architect证书 什么是未来主义Prompt架构师认证…...

轻量化目标检测实战:基于Pytorch的Mobilenet-YOLOv4融合架构设计与性能调优
1. 为什么需要轻量化目标检测模型 在移动端和嵌入式设备上运行目标检测模型时,我们常常面临两个关键挑战:计算资源有限和功耗约束。传统的YOLOv4虽然检测精度高,但其基于CSPDarknet53的主干网络参数量大、计算复杂度高,难以在资源…...

轻量级网络监控工具nmer:配置即代码的探测与响应实践
1. 项目概述:一个轻量级网络监控与响应工具最近在梳理内部网络监控体系时,我重新审视了一个老伙计——psterman/nmer。这可不是什么新潮的框架,但在特定场景下,它的简洁和高效总能让人眼前一亮。简单来说,nmer是一个用…...

TV Bro电视浏览器革命性突破:让Android电视变身智能上网终端
TV Bro电视浏览器革命性突破:让Android电视变身智能上网终端 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 您是否曾在大屏幕电视前感到手足无措࿱…...

别再只会用Matplotlib画基础热力图了!这5个高级定制技巧让你的图表瞬间专业
解锁Matplotlib热力图的5个高阶美学密码:从基础图表到专业可视化 当你第一次用Matplotlib画出热力图时,那种成就感就像解开了数据分析的第一道密码。但随着项目复杂度的提升,那些默认参数生成的图表开始显得单薄——颜色映射不够精准、标注信…...

紧急通知:v8.1即将关闭旧版审美缓存——72小时内必须完成的3步风格校准清单
更多请点击: https://intelliparadigm.com 第一章:v8.1旧版审美缓存关停的技术动因与全局影响 核心架构演进压力 V8.1 引擎中长期运行的“审美缓存”(Aesthetic Cache)模块,本质上是一套基于 DOM 树节点样式偏好建模…...

双碳目标下太阳辐射预报模式【WRF-SOLAR】模拟方法及改进技术在气象、农林生态、电力等相关领域中的实践应用
太阳能是一种清洁能源,合理有效开发太阳能资源对减少污染、保护环境以及应对气候变化和能源安全具有非常重要的实际意义,为了实现能源和环境的可持续发展,近年来世界各国都高度重视太阳能资源的开发利用;另外太阳辐射的光谱成分、…...