《强化学习:原理与Python实战》——可曾听闻RLHF

前言:
RLHF(Reinforcement Learning with Human Feedback,人类反馈强化学习)是一种基于强化学习的算法,通过结合人类专家的知识和经验来优化智能体的学习效果。它不仅考虑智能体的行为奖励,还融合了人类专家的反馈信息,从而使得模型能够更快地学习到有效的策略。相比传统的强化学习算法,RLHF具有加速训练过程、提高模型性能和增强可解释性的优势。通过探索阶段和反馈阶段的循环迭代,RLHF可以逐步优化智能体的行为,并减少训练时间和计算资源的消耗。
《强化学习:原理与Python实战》——解析大模型核心技术RLHF
- 图书活动介绍(参与即有机会免费获得哦)
- 一、RLHF是什么?
- 二、RLHF适用于哪些任务?
- 三、RLHF和其他构建奖励模型的方法相比有何优劣?
- 四、RLHF算法有哪些类别,各有什么优缺点?
- 五、RLHF采用人类反馈会带来哪些局限?
- 六、如何降低人类反馈带来的负面影响?
图书活动介绍(参与即有机会免费获得哦)

活动介绍:本书将抽取评论区三位小伙伴免费送出(为防止小伙伴错过中奖信息,请在文末或博主主页添加博主Vx哦)
参与方式:关注博主、点赞、收藏本文,评论区评论“我真的是你童学呀陈童学!”(一定要点赞+收藏哦,否则无法参与,每个人最多评论三次!)
活动截止时间:2023-8-26 20:00:00
如果想深入了解本书的小伙伴可以继续往下阅读本文的内容哦
一、RLHF是什么?
强化学习利用奖励信号训练智能体。有些任务并没有自带能给出奖励信号的环境,也没有现成的生成奖励信号的方法。为此,可以搭建奖励模型来提供奖励信号。在搭建奖励模型时,可以用数据驱动的机器学习方法来训练奖励模型,并且由人类提供数据。我们把这样的利用人类提供的反馈数据来训练奖励模型以用于强化学习的系统称为人类反馈强化学习,示意图如下。
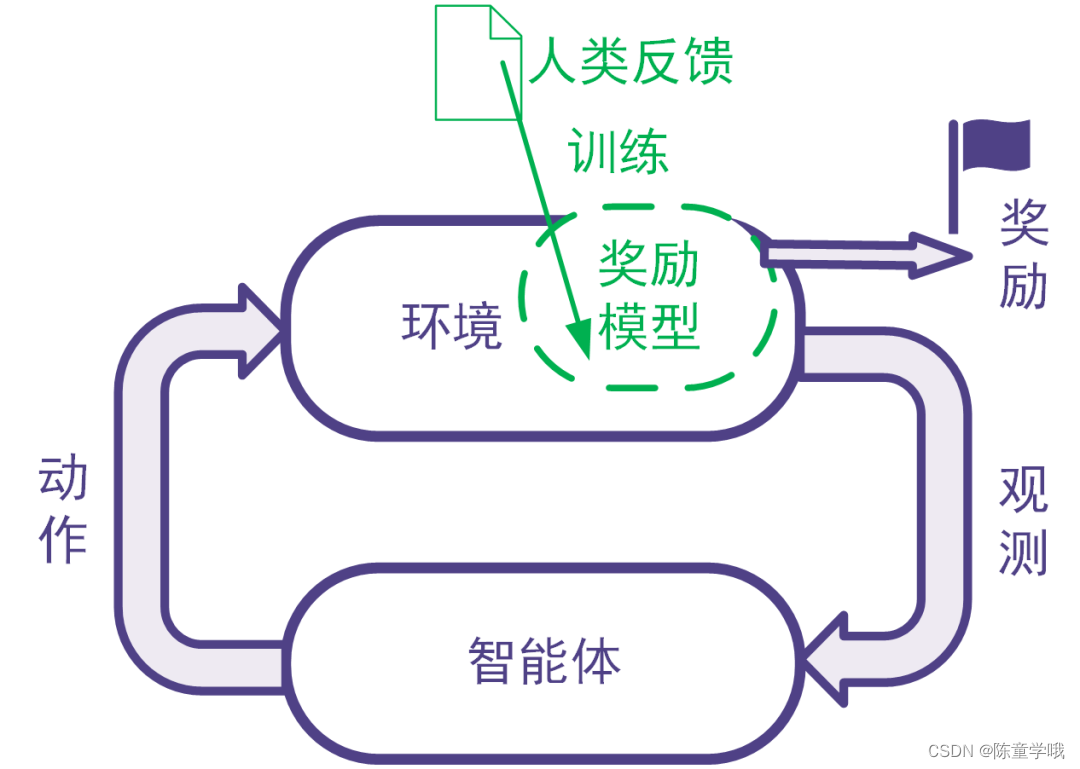
二、RLHF适用于哪些任务?
RLHF适合于同时满足下面所有条件的任务:
-
要解决的任务是一个强化学习任务,但是没有现成的奖励信号并且奖励信号的确定方式事先不知道。为了训练强化学习智能体,考虑构建奖励模型来得到奖励信号。
反例:比如电动游戏有游戏得分,那样的游戏程序能够给奖励信号,那我们直接用游戏程序反馈即可,不需要人类反馈。
反例:某些系统奖励信号的确定方式是已知的,比如交易系统的奖励信号可以由赚到的钱完全确定。这时直接可以用已知的数学表达式确定奖励信号,不需要人工反馈。 -
不采用人类反馈的数据难以构建合适的奖励模型,而且人类的反馈可以帮助得到合适的奖励模型,并且人类来提供反馈可以在合理的代价(包括成本代价、时间代价等)内得到。如果用人类反馈得到数据与其他方法采集得到数据相比不具有优势,那么就没有必要让人类来反馈。
三、RLHF和其他构建奖励模型的方法相比有何优劣?
奖励模型可以人工指定,也可以通过有监督模型、逆强化学习等机器学习方法来学习。RLHF使用机器学习方法学习奖励模型,并且在学习过程中采用人类给出的反馈。
比较人工指定奖励模型与采用机器学习方法学习奖励模型的优劣:这与对一般的机器学习优劣的讨论相同。机器学习方法的优点包括不需要太多领域知识、能够处理非常复杂的问题、能够处理快速大量的高维数据、能够随着数据增大提升精度等等。机器学习算法的缺陷包括其训练和使用需要数据时间空间电力等资源、模型和输出的解释型可能不好、模型可能有缺陷、覆盖范围不够或是被攻击(比如大模型里的提示词注入)。
比较采用人工反馈数据和采用非人工反馈数据的优劣:人工反馈往往更费时费力,并且不同人在不同时候的表现可能不一致,并且人还会有意无意地犯错,或是人类反馈的结果还不如用其他方法生成数据来的有效,等等。我们在后文会详细探讨人工反馈的局限性。采用机器收集数据等非人工反馈数据则对收集的数据类型有局限性。有些数据只能靠人类收集,或是用机器难以收集。这样的数据包括是主观的、人文的数据(比如判断艺术作品的艺术性),或是某些机器还做不了的事情(比如玩一个AI暂时还不如人类的游戏)。
四、RLHF算法有哪些类别,各有什么优缺点?
RLHF算法有以下两大类:
用监督学习的思路训练奖励模型的RLHF、用逆强化学习的思路训练奖励模型的RLHF。
- 1.在用监督学习的思路训练奖励模型的RLHF系统中,人类的反馈是奖励信号或是奖励信号的衍生量(如奖励信号的排序)。
直接反馈奖励信号和反馈奖励信号衍生量各有优缺点。这个优点在于获得奖励参考值后可以直接把它用作有监督学习的标签。缺点在于不同人在不同时候给出的奖励信号可能不一致,甚至矛盾。反馈奖励信号的衍生量,比如奖励模型输入的比较或排序。有些任务给出评价一致的奖励值有困难,但是比较大小容易得多。但是没有密集程度的信息。在大量类似情况导致某部分奖励对应的样本过于密集的情况下,甚至可能不收敛。
一般认为,采用比较类型的反馈可以得到更好的性能中位数,但是并不能得到更好的性能平均值。
- 2.在用逆强化学习的思路训练奖励模型的RLHF系统中,人类的反馈并不是奖励信号,而是使得奖励更大的奖励模型输入即人类给出了较为正确的数量、文本、分类、物理动作等,告诉奖励模型在这时候奖励应该比较大。这其实就是逆强化学习的思想。
这种方法与用监督学习训练奖励模型的RLHF相比,其优点在于,训练奖励模型的样本点不再拘泥于系统给出的需要评判的样本。因为系统给出的需要评估奖励的样本可能具有局限性(因为系统没有找到最优的区间)。
在系统搭建初期,还可以将用户提供的参考答案用于把最初的强化学习问题转化成模仿学习问题。
这类设计还可以根据反馈的类型进一步分类,一类是让人类独立给出专家意见,另一类是在让人类在已有数据的基础上进行改进。让人类提供意见就类似于让人类提供模仿学习里的专家策略(当然可能略有不同,毕竟奖励模型的输入不只有动作)。让用户在已有的参考内容上修改可以减少人类每个标注的成本,但是已有的参考内容可能会干扰到人类的独立判断(这个干扰可能是正面的也可能是负面的)。
五、RLHF采用人类反馈会带来哪些局限?
前面已经提到,人类反馈可能更费时费力,并且不一定能够保证准确性和一致性。除此之外,下面几点会导致奖励模型不完整不正确,导致后续强化学习训练得到的智能体行为不能令人满意。
-
1.提供人类反馈的人群可能有偏见或局限性。
-
2.人的决策可能没有机器决策那么高明。
-
3.没有将提供反馈的人的特征引入到系统。
-
4.人性可能导致数据集不完美。
六、如何降低人类反馈带来的负面影响?
针对人类反馈费时费力且可能导致奖励模型不完整不正确的问题,可以在收集人类反馈数据的同时就训练奖励模型、训练智能体,并全面评估奖励模型和智能体,以便于尽早发现人类反馈的缺陷。发现缺陷后,及时进行调整。
针对人类反馈中出现的反馈质量问题以及错误反馈,可以对人类反馈进行校验和审计,如引入已知奖励的校验样本来校验人类反馈的质量,或为同一样本多次索取反馈并比较多次反馈的结果等。
针对反馈人的选择不当的问题,可以在有效控制人力成本的基础上,采用科学的方法选定提供反馈的人。可以参考数理统计里的抽样方法,如分层抽样、整群抽样等,使得反馈人群更加合理。
对于反馈数据中未包括反馈人特征导致奖励模型不够好的问题,可以收集反馈人的特征,并将这些特征用于奖励模型的训练。比如,在大规模语言模型的训练中可以记录反馈人的职业背景(如律师、医生等),并在训练奖励模型时加以考虑。当用户要求智能体像律师一样工作时,更应该利用由律师提供的数据学成的那部分奖励模型来提供奖励信号;当用户要求智能体像医生一样工作时,更应该利用由医生提供的数据学成的那部分奖励模型来提供奖励信号。
另外,在整个系统的实施过程中,可以征求专业人士意见,以减小其中法律和安全风险。
本文内容摘编自《强化学习:原理与Python实战》,经出版方授权发布。(ISBN:978-7-111-72891-7)
请参与本文赠书活动的小伙伴在正下方添加博主哦!!!!⬇️⬇️⬇️⬇️

相关文章:
《强化学习:原理与Python实战》——可曾听闻RLHF
前言: RLHF(Reinforcement Learning with Human Feedback,人类反馈强化学习)是一种基于强化学习的算法,通过结合人类专家的知识和经验来优化智能体的学习效果。它不仅考虑智能体的行为奖励,还融合了人类专家…...
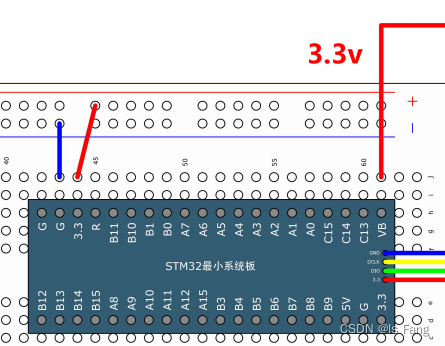
STM32——RTC实时时钟
文章目录 Unix时间戳UTC/GMT 时间戳转换BKP简介BKP基本结构读写BKP备份寄存器电路设计关键代码 RTC简介RTC框图RTC基本结构硬件电路RTC操作注意事项读写实时时钟电路设计关键代码 Unix时间戳 Unix 时间戳(Unix Timestamp)定义为从UTC/GMT的1970年1月1日…...

webSocket 开发
1 认识webSocket WebSocket_ohana!的博客-CSDN博客 一,什么是websocket WebSocket是HTML5下一种新的协议(websocket协议本质上是一个基于tcp的协议)它实现了浏览器与服务器全双工通信,能更好的节省服务器资源和带宽…...
c#设计模式-结构型模式 之 代理模式
前言 由于某些原因需要给某对象提供一个代理以控制对该对象的访问。这时,访问对象不适合或者不能直接 引用目标对象,代理对象作为访问对象和目标对象之间的中介。在学习代理模式的时候,可以去了解一下Aop切面编程AOP切面编程_aop编程…...

openpnp - 自动换刀的设置
文章目录 openpnp - 自动换刀的设置概述笔记采用的openpnp版本自动换刀库的类型选择自动换刀设置前的注意事项先卸掉吸嘴座上所有的吸嘴删掉所有的吸嘴设置自动换刀的视觉识别设置吸嘴座为自动换刀 - 以N1为例备注补充 - 吸嘴轴差个0.3mm, 就有可能怼坏吸嘴END openpnp - 自动换…...
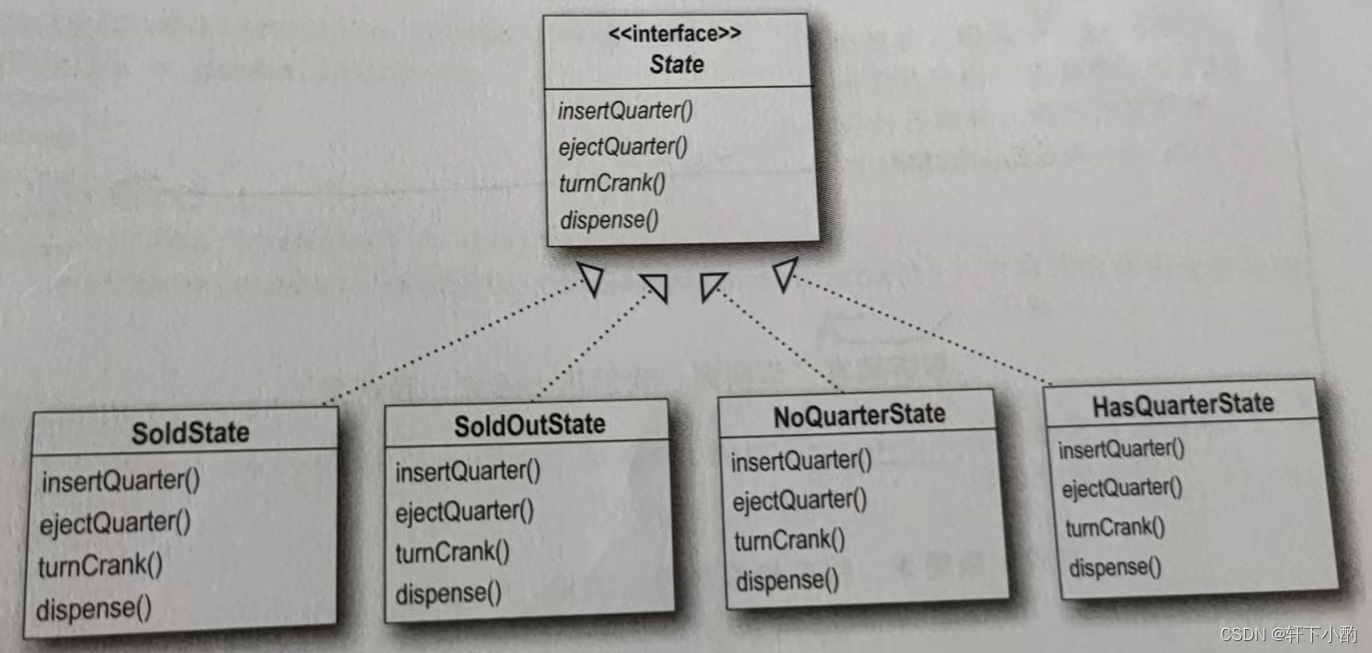
《HeadFirst设计模式(第二版)》第十章代码——状态模式
如下图所示,这是一个糖果机的状态机图,要求使用代码实现: 初始版本: package Chapter10_StatePattern.Origin;/*** Author 竹心* Date 2023/8/19**/public class GumballMachine {final static int SOLD_OUT 0;final static int…...
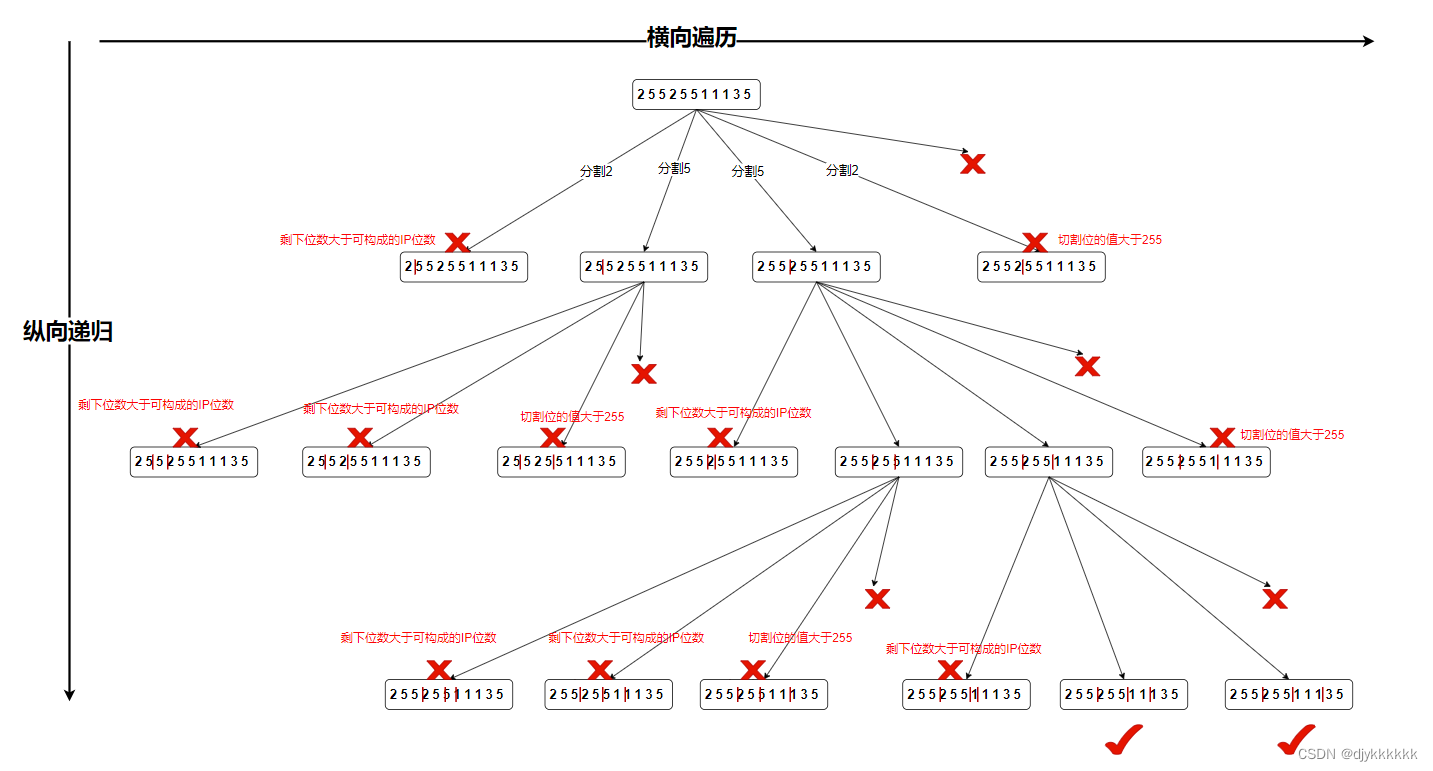
day-25 代码随想录算法训练营(19)回溯part02
216.组合总和||| 思路:和上题一样,差别在于多了总和,但是数字局限在1-9 17.电话号码的字母组合 思路:先纵向遍历第i位电话号码对于的字符串,再横向递归遍历下一位电话号码 93.复原IP地址 画图分析: 思…...

PG逻辑备份与恢复
文章目录 创建测试数据pg_dump 备份pg_restore 恢复pg_restore 恢复并行备份的文件PG 只导出指定函数 创建测试数据 drop database if exists test; create database test ; \c test create table t1(id int primary key); create table t2(id serial primary key, name varch…...
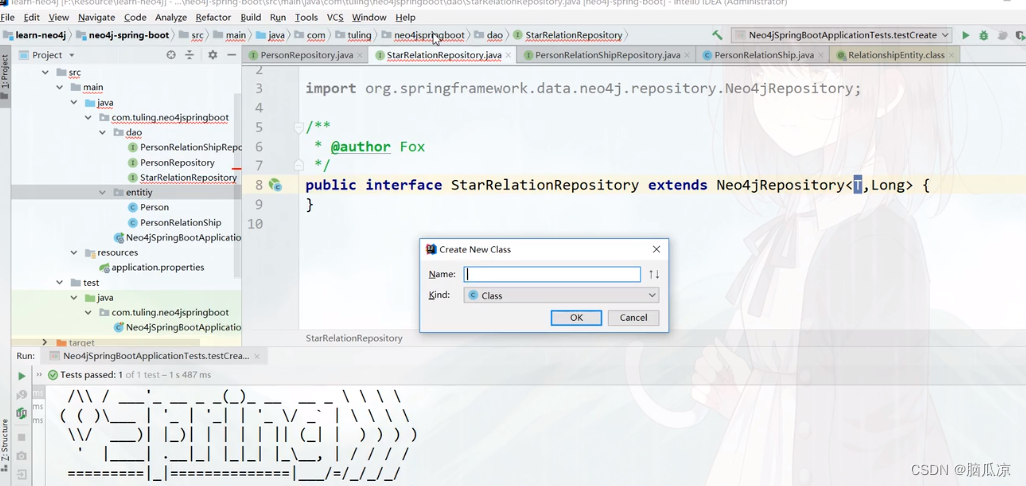
图数据库_Neo4j和SpringBoot整合使用_实战创建明星关系图谱---Neo4j图数据库工作笔记0010
然后我们再来看一下这个明星关系图谱 可以看到这里 这个是原来的startRelation 我们可以写CQL去查询对应的关系 可以看到,首先查询出来以后,然后就可以去创建 我们可以把写的创建明星关系的CQL,拿到 springboot中去执行 可以看到,这里我们先写一个StarRelationRepository,然…...
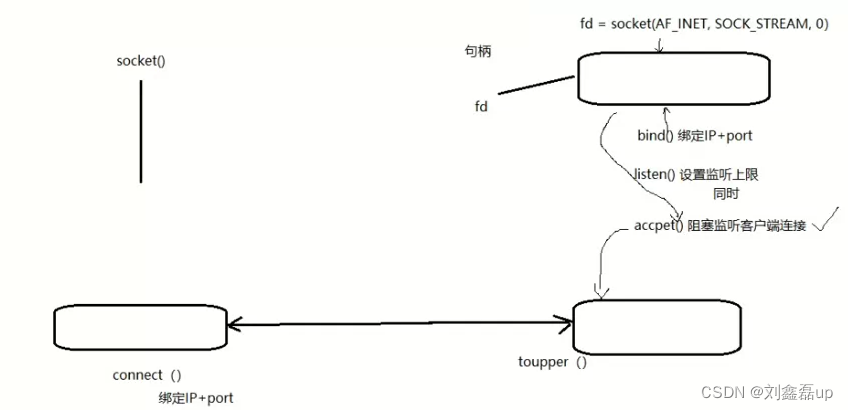
Linux网络编程:Socket套接字编程(Server服务器 Client客户端)
文章目录: 一:定义和流程分析 1.定义 2.流程分析 3.网络字节序 二:相关函数 IP地址转换函数inet_pton inet_ntop(本地字节序 网络字节序) socket函数(创建一个套接字) bind函数(给socket绑定一个服务器地址结…...

Mac OS下应用Python+Selenium实现web自动化测试
在Mac环境下应用PythonSelenium实现web自动化测试 在这个过程中要注意两点: 1.在终端联网执行命令“sudo pip install –U selenium”如果失败了的话,可以尝试用命令“sudo easy_install selenium”来安装selenium; 2.安装好PyCharm后新建project&…...
每天一道leetcode:934. 最短的桥(图论中等广度优先遍历)
今日份题目: 给你一个大小为 n x n 的二元矩阵 grid ,其中 1 表示陆地,0 表示水域。 岛 是由四面相连的 1 形成的一个最大组,即不会与非组内的任何其他 1 相连。grid 中 恰好存在两座岛 。 你可以将任意数量的 0 变为 1 &#…...
【学习日记】【FreeRTOS】FreeRTOS 移植到 STM32F103C8
前言 本文基于野火 FreeRTOS 教程,内容是关于 FreeRTOS 官方代码的移植的注意事项,并将野火例程中 STM32F103RC 代码移植到 STM32F103C8。 一、FreeRTOS V9.0.0 源码的获取 两个下载链接: 官 网 代码托管 二、源码文件夹内容简介 Source…...

Qt 屏幕偶发性失灵
项目场景: 基于NXP i.mx7的Qt应用层项目开发,通过goodix使用触摸屏,走i2c协议。 问题描述 触摸屏使用过程中意外卡死,现场分为多种: i2c总线传输错误,直观表现为触摸屏无效,任何与触摸屏挂接在同一总线上的i2c设备,均受到干扰,并且在传输过程中内核报错以下代码: G…...
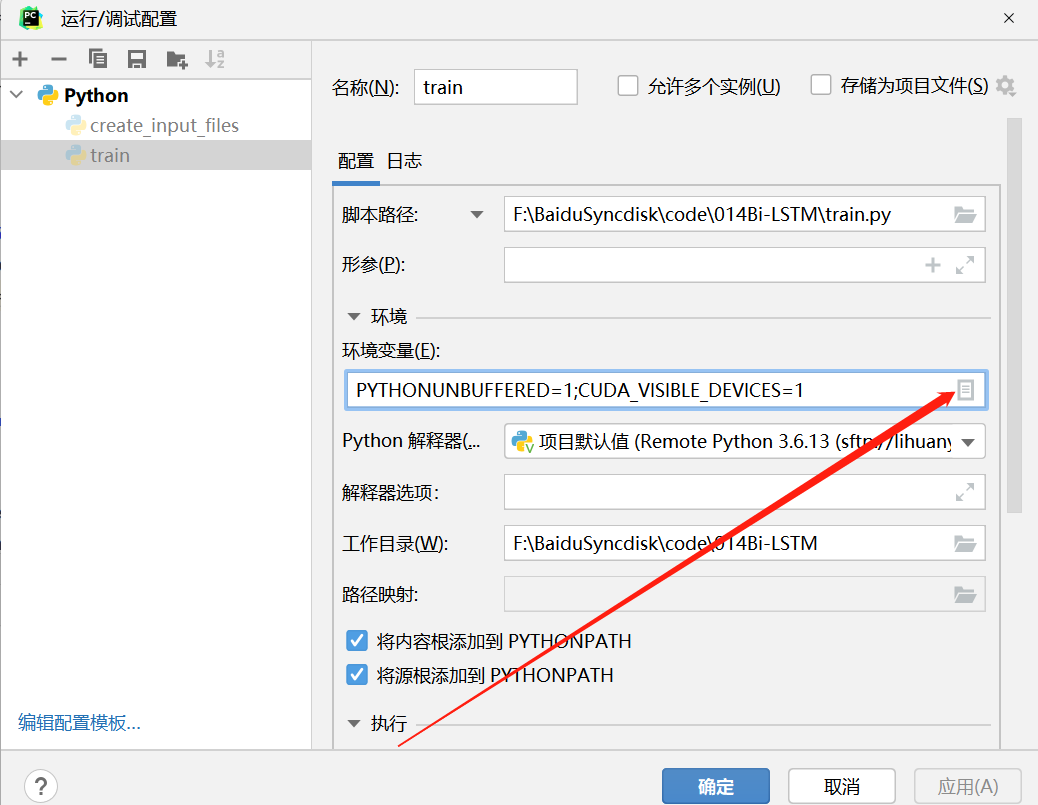
如何在pycharm中指定GPU
如何在pycharm中指定GPU 作者:安静到无声 个人主页 目录 如何在pycharm中指定GPU打开编辑配置点击环境变量添加GPU配置信息推荐专栏在Pycharm运行程序的时候,有时候需要指定GPU,我们可以采用以下方式进行设置: 打开编辑配置 点击环境变量 添加GPU配置信息 添加名称:CU…...

C#判断字符串中有没有字母,正则表达式、IsLetter
要判断字符串中是否包含字母,可以使用正则表达式或者循环遍历字符串的方式。 方法一:使用正则表达式 using System.Text.RegularExpressions;string input "Hello123"; bool containsLetter Regex.IsMatch(input, "[a-zA-Z]");上…...

Jtti:Ubuntu怎么限制指定端口和IP访问
在 Ubuntu 系统中,可以使用防火墙规则来限制特定的端口和IP访问。常用的防火墙管理工具是 iptables,以下是使用 iptables 来限制指定端口和IP访问的步骤: 安装 iptables: 如果系统中没有安装 iptables,可以使用以下命…...

机器学习/深度学习需要掌握的linux基础命令
很多深度学习/机器学习/数据分析等领域(或者说大多数在Python环境下进行操作的领域)的初学者入门时是在Windows上进行学习,也得益于如Anaconda等工具把环境管理做的如此友善 但如果想在该领域继续深耕,一定会与Linux操作系统打交…...

C++11 std::async推荐使用 std::launch::async 模式
async真假多线程 std::launch::async真多线程 std::launch::async | std::launch::deferred可能多线程 std::launch::deferred假多线程 枚举变量说明 枚举定义 enum class launch {async 1, // 0b1deferred 2, // 0b10any async | def…...

没有使用springboot 单独使用spring-boot-starter-logging
如果您不使用Spring Boot框架,但想单独使用Spring Boot Starter Logging,您可以按照以下步骤进行: 1. 添加Maven依赖: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boo…...

2026深度教程:如何用好 Gemini 3.1 Pro 联网搜索?实时信息获取与验证技巧全解析
目前,国内用户想稳定使用顶尖AI模型的联网搜索功能,像聚合了Gemini、ChatGPT、Grok等主流大模型的 KULAAI (m.877ai.cn) 这类镜像站提供了直接可用的方案。本文将深入剖析Gemini 3.1 Pro的联网能力,从原理机制到实操技巧ÿ…...

Raycast扩展vscode-control:用全局启动器遥控VS Code提升开发效率
1. 项目概述:一个为Raycast打造的VS Code遥控器 如果你和我一样,每天大部分时间都泡在代码编辑器里,那么你一定对频繁在编辑器、终端、浏览器和启动器之间切换感到厌烦。尤其是当你需要快速执行一个格式化操作、运行一个NPM脚本,…...

基于大语言模型的自动化股票研报生成系统设计与实现
1. 项目概述:当ChatGPT遇上股票研报最近几年,AI在金融领域的应用已经从简单的数据查询,进化到了能够进行复杂分析和生成专业报告的程度。我关注到一个挺有意思的项目,叫ddobokki/chatgpt_stock_report。光看这个名字,你…...

小米Agent岗二面:你们 RAG 知识库上线之后,文档更新了怎么办?
👔面试官:你们 RAG 知识库上线之后,文档更新了怎么办?总不能每次改个文档就把整个知识库重建一遍吧。 🙋♂️我:可以直接找到变了的那个 chunk,更新它的向量就行了。 👔面试官&a…...

基于多智能体协作的AI开发流程:三人团队模式解析与实践
1. 项目概述与核心痛点如果你和我一样,在日常开发中深度依赖像Claude这样的AI编码助手,那你一定也经历过那种“又爱又恨”的时刻。爱的是它强大的代码生成和理解能力,恨的是它时不时会“放飞自我”——比如你只想让它修改一个函数,…...

如何快速掌握LyricsX:macOS终极歌词同步工具完整指南
如何快速掌握LyricsX:macOS终极歌词同步工具完整指南 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX LyricsX是一款专为macOS设计的终极歌词应用,能够自动同步音乐…...

DeepSeek代码能力实测:3大编程范式通过率对比,92.7%准确率背后的5个隐藏陷阱
更多请点击: https://intelliparadigm.com 第一章:DeepSeek HumanEval测试全景概览 HumanEval 是由 OpenAI 提出的函数级代码生成基准测试集,包含 164 道 Python 编程题,每道题提供函数签名、文档字符串(docstring&am…...

终极代码统计指南:cloc压缩包分析与Git版本对比实战
终极代码统计指南:cloc压缩包分析与Git版本对比实战 【免费下载链接】cloc cloc counts blank lines, comment lines, and physical lines of source code in many programming languages. 项目地址: https://gitcode.com/gh_mirrors/cl/cloc cloc是一款强大…...
那些鲜为人知的“前世今生”)
从多媒体到HPC:聊聊IBM GPFS(Spectrum Scale)那些鲜为人知的“前世今生”
从多媒体到HPC:IBM GPFS的技术进化与商业智慧 1993年,当第一代数字视频编辑系统还在为处理480p分辨率视频而焦头烂额时,IBM实验室里的一组工程师正在解决一个更根本的问题——如何让多个工作站同时高效访问同一组视频素材。这个看似简单的需求…...

Factool:大语言模型事实核查工具包的设计原理与工程实践
1. 项目概述:当AI学会“查证”,我们该如何信任它?最近在折腾大语言模型(LLM)应用落地的朋友,估计都绕不开一个头疼的问题:幻觉(Hallucination)。你让模型写一篇行业报告&…...