opencv进阶07-支持向量机cv2.ml.SVM_create()简介及示例
支持向量机(Support Vector Machine,SVM)是一种二分类模型,目标是寻找一个标准(称为超平面)对样本数据进行分割,分割的原则是确保分类最优化(类别之间的间隔最大)。当数据集较小时,使用支持向量机进行分类非常有效。支持向量机是最好的现成分类器之一,这里所谓的“现成”是指分类器不加修改即可直接使用。
在对原始数据分类的过程中,可能无法使用线性方法实现分割。支持向量机在分类时,把无法线性分割的数据映射到高维空间,然后在高维空间找到分类最优的线性分类器。
Python 提供了不同的实现支持向量机的库(例如 sk-learn 库、LIBSVM 库等),OpenCV 也提供了对支持向量机的支持,对于上述库,基本都可以直接使用,无须深入了解支持向量机的原理。
理论基础
- 分类
某 IT 企业在 2017 年通过笔试、面试的形式招聘了一批员工。2018 年,企业针对这批员工在过去一年的实际表现进行了测评,将他们的实际表现分别确定为 A 级(优秀)和 B 级(良好)。这批员工的笔试成绩、面试成绩和等级如图 21-1 所示,图中横坐标是笔试成绩,纵坐标
是面试成绩,位于右上角的圆点表示测评成绩是 A 级,位于左下角的小方块表示测评成绩是 B级。
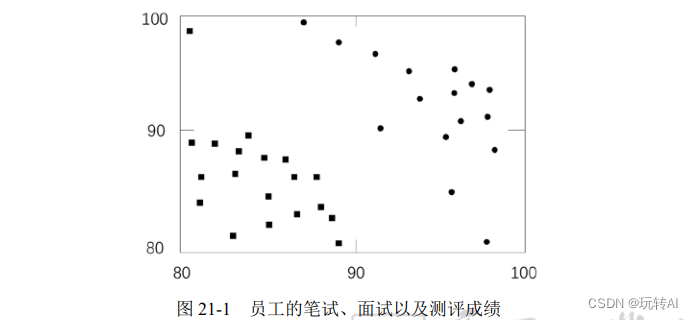
当然,公司肯定希望招聘到的员工都是 A 类(表现为 A 级)的。关键是如何根据笔试和面试成绩确定哪些员工可能是未来的 A 类员工呢?或者说,如何根据笔试和面试成绩确保招聘的员工是潜在的优秀员工?偷懒的做法是将笔试和面试的成绩标准都定得较高,但这样做可能会漏掉某些优秀的员工。
所以,要合理地确定笔试和面试的成绩标准,确保能够准确高效地招到 A 类员工。例如,在图 21-2 中,分别使用直线对笔试和面试成绩进行了 3 种不同形式的划分,将成绩位于直线左下方的员工划分为 B 类,将成绩位于右上方的员工划分为 A 类。
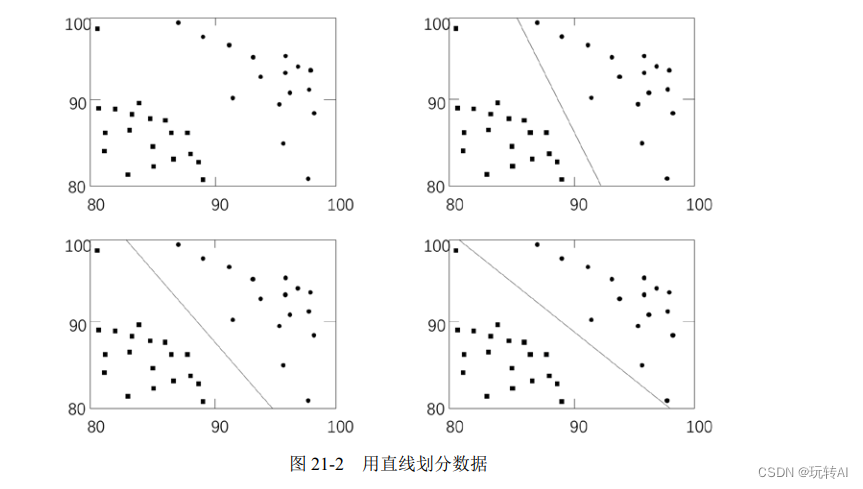
2. 分类器
在图 21-2 中用于划分不同类别的直线,就是分类器。在构造分类器时,非常重要的一项工作就是找到最优分类器。
那么,图 21-2 中的三个分类器,哪一个更好呢?从直观上,我们可以发现图 21-2 中右上角的分类器和右下角的分类器都偏向了某一个分类(即与其中一个分类的间距更小),而左下角的分类器实现了“均分”。而左下角的分类器,尽量让两个分类离自己一样远,这样就为每个分类都预留了等量的扩展空间,即使有新的靠近边界的点进来,也能够按照位置划分到对应的分类内。
以上述划分为例,说明如何找到支持向量机:在已有数据中,找到离分类器最近的点,确保它们离分类器尽可能地远。这里,离分类器最近的点到分类器的距离称为间隔(margin)。我们希望间隔尽可能地大,这样分类器在处理数据时,就会更准确。
例如,在图 21-3 中,左下角分类器的间隔最大。离分类器最近的那些点叫作支持向量(support vector)。正是这些支持向量,决定了分类器所在的位置。
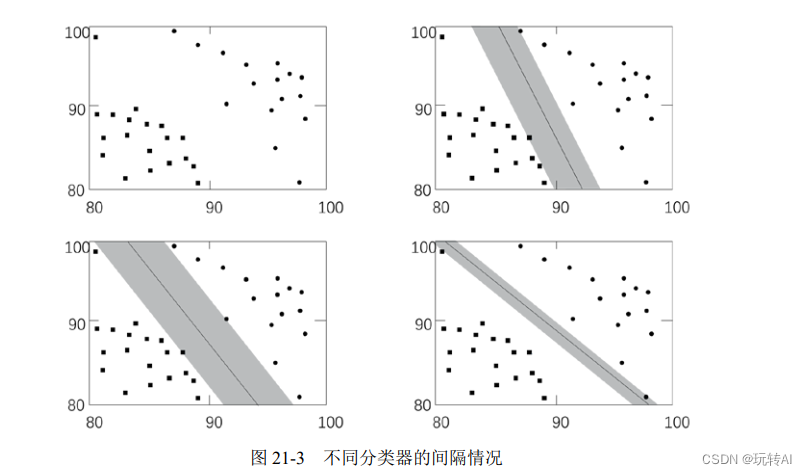
3. 将不可分变为可分
上例的数据非常简单,我们可以使用一条直线(线性分类器)轻易地对其进行划分。而现实中的大多数问题,往往是非常复杂的,不可能像上例一样简单地完成划分。
通常情况下,支持向量机会将不那么容易分类的数据通过函数映射变为可分类的。
举个例子,假设我们不小心将豌豆和小米混在了一起。豌豆的个头很大,直径在 10 mm 左右;小米个头小,直径在 1mm 左右。如果想把它们分开,直接使用直线是不行的。此时,我们可以使用直径为 3 mm 的筛子,将豌豆和小米区分开。在某种意义上,这个筛子就是映射操作,它将豌豆和小米有效地分开了。
支持向量机在处理数据时,如果在低维空间内无法完成分类,就会自动将数据映射到高维空间,使其变为(线性)可分的。简单地讲,就是对当前数据进行函数映射操作。
如图 21-4 所示,在分类时,通过函数 f 的映射,让左图中本来不能用线性分类器分类的数据变为右图中线性可分的数据。当然,在实际操作中,也可能将数据由低维空间向高维空间转换。

大家也许会担心,数据由低维空间转换到高维空间后运算量会呈几何级增加,但实际上,支持向量机能够通过核函数有效地降低计算复杂度。
4. 概念总结
尽管上面分析的是二维数据,但实际上支持向量机可以处理任何维度的数据。在不同的维度下,支持向量机都会尽可能寻找类似于二维空间中的直线的线性分类器。
例如,在二维空间,支持向量机会寻找一条能够划分当前数据的直线;在三维空间,支持向量机会寻找一个能够划分当前数据的平面(plane);在更高维的空间,支持向量机会尝试寻找一个能够划分当前数据的超平面(hyperplane)。
一般情况下,把能够可以被一条直线(更一般的情况,即一个超平面)分割的数据称为线性可分的数据,所以超平面是线性分类器。
“支持向量机”是由“支持向量”和“机器”构成的。
-
“支持向量”是离分类器最近的那些点,这些点位于最大“间隔”上。通常情况下,分类仅依靠这些点完成,而与其他点无关。
-
“机器”指的是分类器。
综上所述,支持向量机是一种基于关键点的分类算法。
SVM 案例介绍
在使用支持向量机模块时,需要先使用函数 cv2.ml.SVM_create()生成用于后续训练的空分类器模型。该函数的语法格式为:
svm = cv2.ml.SVM_create( )
获取了空分类器 svm 后,针对该模型使用 svm.train()函数对训练数据进行训练,其语法格式为:
训练结果= svm.train(训练数据,训练数据排列格式,训练数据的标签)
式中参数的含义如下:
- 训练数据:表示原始数据,用来训练分类器。例如,前面讲的招聘的例子中,员工的笔试成绩、面试成绩都是原始的训练数据,可以用来训练支持向量机。
- 训练数据排列格式:原始数据的排列形式
有按行排列(cv2.ml.ROW_SAMPLE,每一条训练数据占一行)和按列排列(cv2.ml.COL_SAMPLE,每一条训练数据占一列)两种形式,根据数据的实际排列情况选择对应的参数即可。 - 训练数据的标签:原始数据的标签。
- 训练结果:训练结果的返回值。
例如,用于训练的数据为 data,其对应的标签为 label,每一条数据按行排列,对分类器模型 svm 进行训练,所使用的语句为:
返回值 = svm.train(data,cv2.ml.ROW_SAMPLE,label)
完成对分类器的训练后,使用 svm.predict()函数即可使用训练好的分类器模型对测试数据进行分类,其语法格式为:
(返回值,返回结果) = svm.predict(测试数据)
以上是支持向量机模块的基本使用方法。在实际使用中,可能会根据需要对其中的参数进行调整。OpenCV 支持对多个参数的自定义,例如:可以通过 setType()函数设置类别,通过setKernel()函数设置核类型,通过 setC()函数设置支持向量机的参数 C(惩罚系数,即对误差的宽容度,默认值为 0)。
示例:已知老员工的笔试成绩、面试成绩及对应的等级表现,根据新入职员工的笔试成绩、面试成绩预测其可能的表现。
根据题目要求,首先构造一组随机数,并将其划分为两类,然后使用 OpenCV 自带的支持向量机模块完成训练和分类工作,最后将运算结果显示出来。具体步骤如下。
- 生成模拟数据
首先,模拟生成入职一年后表现为 A 级的员工入职时的笔试和面试成绩。构造 20 组笔试和面试成绩都分布在[95, 100)区间的数据对:
a = np.random.randint(95,100, (20, 2)).astype(np.float32)
上述模拟成绩,在一年后对应的工作表现为 A 级。
接下来,模拟生成入职一年后表现为 B 级的员工入职时的笔试和面试成绩。构造 20 组笔试和面试成绩都分布在[90, 95)区间的数据对:
b = np.random.randint(90,95, (20, 2)).astype(np.float32)
上述模拟成绩,在一年后对应的工作表现为 B 级。
最后,将两组数据合并,并使用 numpy.array 对其进行类型转换:
data = np.vstack((a,b))
data = np.array(data,dtype='float32')
- 构造分组标签
首先,为对应表现为 A 级的分布在[95, 100)区间的数据,构造标签“0”:
aLabel=np.zeros((20,1))
接下来,为对应表现为 B 级的分布在[90, 95)区间的数据,构造标签“1”:
bLabel=np.ones((20,1))
最后,将上述标签合并,并使用 numpy.array 对其进行类型转换:
label = np.vstack((aLabel, bLabel))
label = np.array(label,dtype='int32')
- 训练
用支持向量机模块对已知的数据和其对应的标签进行训练:
svm = cv2.ml.SVM_create()
result = svm.train(data,cv2.ml.ROW_SAMPLE,label)
- 分类
生成两个随机的数据对(笔试成绩,面试成绩)用于测试。可以用随机数,也可以直接指定两个数字。
这里,我们想观察一下笔试和面试成绩差别较大的数据如何分类。用如下语句生成成绩:
test = np.vstack([[98,90],[90,99]])
test = np.array(test,dtype='float32')
然后,使用函数 svm.predict()对随机成绩分类:
(p1,p2) = svm.predict(test)
- 显示分类结果
将基础数据(训练数据)、用于测试的数据(测试数据)在图像上显示出来:
plt.scatter(a[:,0], a[:,1], 80, 'g', 'o')
plt.scatter(b[:,0], b[:,1], 80, 'b', 's')
plt.scatter(test[:,0], test[:,1], 80, 'r', '*')
plt.show()
将测试数据及预测分类结果显示出来:
print(test)
print(p2)
整体代码如下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 第 1 步 准备数据
# 表现为 A 级的员工的笔试、面试成绩
a = np.random.randint(95,100, (20, 2)).astype(np.float32)
# 表现为 B 级的员工的笔试、面试成绩
b = np.random.randint(90,95, (20, 2)).astype(np.float32)
# 合并数据
data = np.vstack((a,b))
data = np.array(data,dtype='float32')
# 第 2 步 建立分组标签,0 代表 A 级,1 代表 B 级
#aLabel 对应着 a 的标签,为类型 0-等级 A
aLabel=np.zeros((20,1))
#bLabel 对应着 b 的标签,为类型 1-等级 B
bLabel=np.ones((20,1))
# 合并标签
label = np.vstack((aLabel, bLabel))
label = np.array(label,dtype='int32')
# 第 3 步 训练
# 用 ml 机器学习模块 SVM_create() 创建 svm
svm = cv2.ml.SVM_create()
# 属性设置,直接采用默认值即可
#svm.setType(cv2.ml.SVM_C_SVC) # svm type
#svm.setKernel(cv2.ml.SVM_LINEAR) # line
#svm.setC(0.01)
# 训练
result = svm.train(data,cv2.ml.ROW_SAMPLE,label)
# 第 4 步 预测
# 生成两个随机的笔试成绩和面试成绩数据对
test = np.vstack([[98,90],[90,99]])
test = np.array(test,dtype='float32')
# 预测
(p1,p2) = svm.predict(test)
# 第 5 步 观察结果
# 可视化
plt.scatter(a[:,0], a[:,1], 80, 'g', 'o')
plt.scatter(b[:,0], b[:,1], 80, 'b', 's')
plt.scatter(test[:,0], test[:,1], 80, 'r', '*')
plt.show()
# 打印原始测试数据 test,预测结果
print(test)
print(p2)
同时,程序会在控制台输出如下运行结果:
[[98. 90.]
[90. 99.]]
[[1.]
[1.]]
运行结果表明:
-
笔试成绩为 98 分,面试成绩为 90 分,对应的分类为 1,即该员工一年后的测评可能为B 级(表现良好)。
-
笔试成绩为 90 分,面试成绩为 99 分,对应的分类为 1,即该员工一年后的测评可能为B 级(表现良好)。
因为我们采用随机方式生成数据,所以每次运行时所生成的数据会有所不同,运行结果也就会有所差异。
相关文章:
opencv进阶07-支持向量机cv2.ml.SVM_create()简介及示例
支持向量机(Support Vector Machine,SVM)是一种二分类模型,目标是寻找一个标准(称为超平面)对样本数据进行分割,分割的原则是确保分类最优化(类别之间的间隔最大)。当数据…...

LA@n维向量@解析几何向量和线性代数向量
文章目录 概念n维向量向量类型实向量和复向量行向量和列向量行列向量的转换特殊向量向量运算 矩阵的向量分块👺 解析几何向量和线性代数向量👺向量空间 n n n维向量空间 n n n维空间的 n − 1 n-1 n−1维超平面 概念 n维向量 由 n n n个有次序的数 a …...
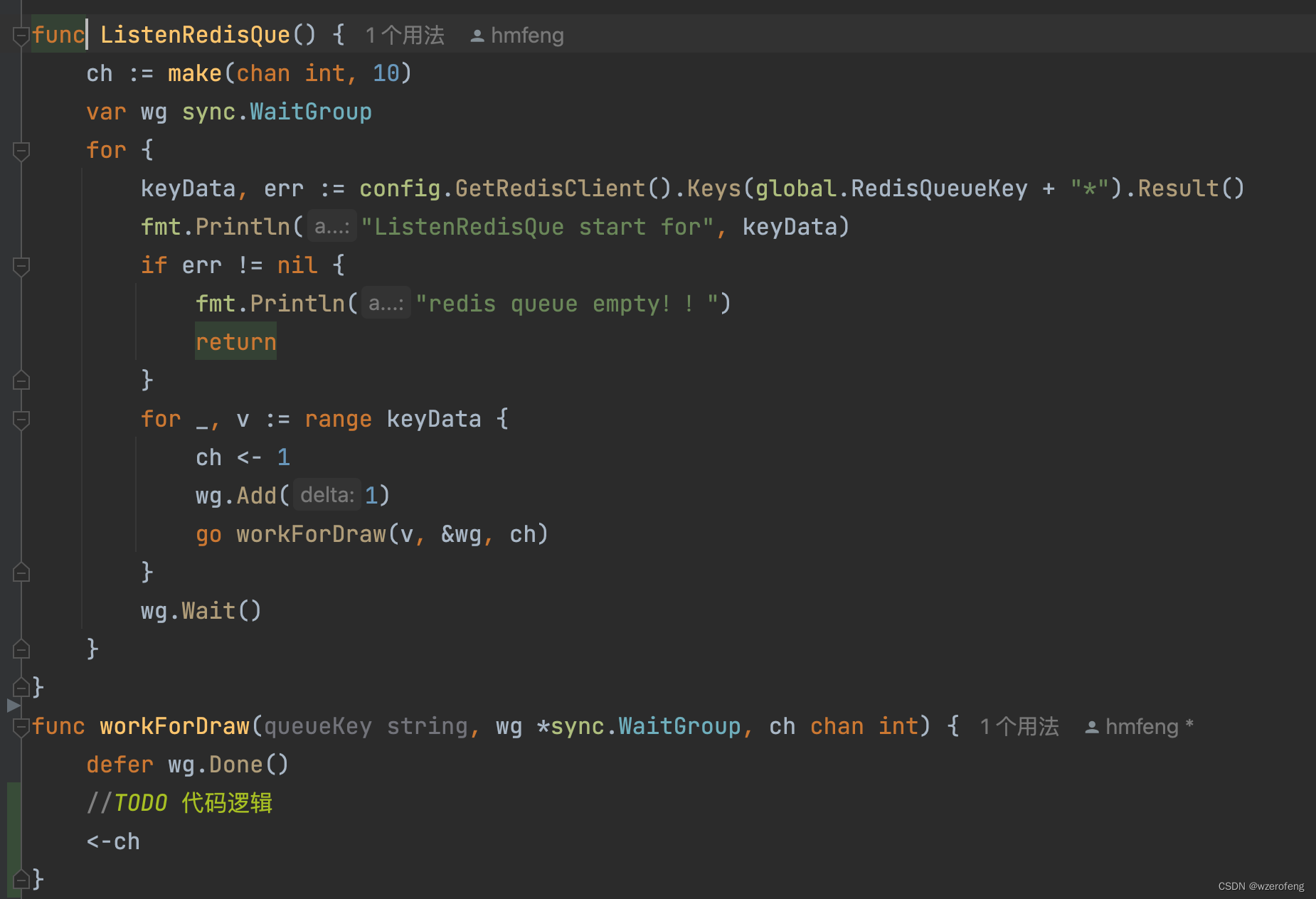
go 协程并发数控制
错误的写法: 这里的<-ch 是为了从channel 中读取 数据,为了不使channel通道被写满,阻塞 go 协程数的创建。但是请注意,go workForDraw(v, &wg) 是不阻塞后续的<-ch 执行的,所以就一直go workForDraw(v, &…...
MySQL的安装以及卸载
下载官网 https://www.mysql.com/ 切到下载tab页 找到 MySQL Community Server 或者 MySQL Community (GPL) Downloads --> MySQL Community Server 点击download按钮: 点击download进入下载页面选择No thanks, just start my download就可以开始下载了。 下…...

LRU算法与Caffeine、Redis中的缓存淘汰策略
推荐阅读 AI文本 OCR识别最佳实践 AI Gamma一键生成PPT工具直达链接 玩转cloud Studio 在线编码神器 玩转 GPU AI绘画、AI讲话、翻译,GPU点亮AI想象空间 资源分享 「java、python面试题」来自UC网盘app分享,打开手机app,额外获得1T空间 https://dr…...

HTML笔记(3)
表单标签 用于登录、注册界面,以采集用户输入的信息,把信息采集到之后,用户一点按钮,就会把这些信息发送到服务端,服务端就可以把这些数据存储到数据库,所以表单是一个非常重要的html标签,它主要…...
,实际上对应的就是虚函数)
c++——重写(覆盖),实际上对应的就是虚函数
重写是指派生类中存在重新定义的函数。其函数名,参数列表,返回值类型,所有都必须同基类中被重写的函数一致。只有函数体不同(花括号内),派生类调用时会调用派生类的重写函数,不会调用被重写函数…...
算法通关村——字符串反转问题解析
1. 反转字符串 反转字符串 编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。 不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。 1.1 交换 这一题的思路还是简单的&…...
,点击关闭按钮按钮重置tree)
vue + elementui 中 在弹框中使用了 tree型结构(<el-tree></el-tree>),点击关闭按钮按钮重置tree
vue 项目中使用了element-ui 中 tree,选择了懒加载的模式 通过点击按钮,使得 tree 重新加载 <div class"head-container header-tree" v-if"addDialogVisible"><el-treeref"tree":data"treeData":loa…...

windows adb根据id点击按钮
在 Windows 上使用 adb 根据控件的 ID 来模拟点击按钮,可以使用以下命令: 查看当前屏幕上的所有控件信息,并将其保存到文件中: adb shell uiautomator dump /sdcard/ui.xml 将设备上的 ui.xml 文件下载到计算机上: ad…...
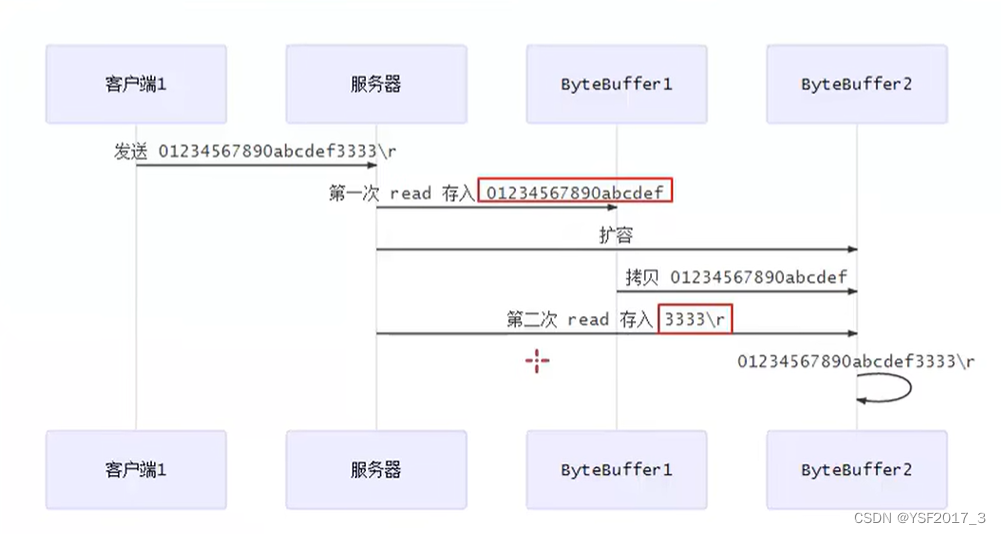
netty(一):NIO——处理消息边界
处理消息边界 为什么要处理边界 因为会存在半包和粘包的问题 1.客户端和服务端约定一个固定长度 优点:简单 缺点:可能造成浪费 2.客户端与服务端约定一个固定分割符 *缺点 效率低 3.先发送长度,再发送数据 TLV格式: type…...

等保测评--安全计算环境--测评方法
安全子类--身份鉴别 a)应对登录的用户进行身份标识和鉴别,身份标识具有唯一性,身份鉴别信息具有复杂度要求并定期更换; 一、测评对象 终端和服务器等设备中的操作系统(包括宿主机和虚拟机操作系统) 、网络设备(包括虚拟网络设备)、安全设备(包括虚拟安全设备)、移动终端…...
色彩空间和通道)
open cv学习 (二)色彩空间和通道
色彩空间和通道 demo1 import cv2hsv_image cv2.imread("./img.png")cv2.imshow("img", hsv_image) hsv_image cv2.cvtColor(hsv_image, cv2.COLOR_BGR2HSV) h, s, v cv2.split(hsv_image) cv2.imshow("B", h) cv2.imshow("G", s…...
RS232、RS422、RS485硬件及RS指令、RS2指令应用知识学习
RS232、RS422、RS485硬件及RS指令、RS2指令应用知识学习 一、串行(异步/同步)通讯、并行通讯、以太网通讯 二、单工通讯/半双工通讯/双工通讯 三、常用硬件接口(工业上基本是RS485两线制的接线) 常用硬件接口RS232/RS422/RS485,…...

背景属性样式
🍓背景属性 属性名称中文注释备注background-image背景图片url(img-path)background-color背景颜色background-attachment设置背景固定scroll默认值,随盒子滚动, fixed固定,脱离标准流,固定在浏览器窗口,当…...
)
蓝桥杯每日N题 (消灭老鼠)
大家好 我是寸铁 希望这篇题解对你有用,麻烦动动手指点个赞或关注,感谢您的关注 不清楚蓝桥杯考什么的点点下方👇 考点秘籍 想背纯享模版的伙伴们点点下方👇 蓝桥杯省一你一定不能错过的模板大全(第一期) 蓝桥杯省一你一定不…...

k8s 用户角色 权限的划分
在Kubernetes中,角色(Role)和角色绑定(RoleBinding)用于划分用户的权限。 Kubernetes中的角色定义了一组特定操作的权限,例如 创建、删除或修改特定资源。而 角色绑定则将角色与用户、组或服务账号进行关联…...

聊一下操作系统 macOS 与 Linux
对于Windows操作系统大家都比较熟悉,也常拿它与Linux操作系统进行比较,两者之间的差异也很明显。但对于macOS 和 Linux的比较不太多,很多人认为它们很相似,因为这两种操作系统都可以运行 Unix 命令。其实详细比较下,两…...

OJ练习第153题——分发糖果
分发糖果 力扣链接:135. 分发糖果 题目描述 n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。 你需要按照以下要求,给这些孩子分发糖果: 每个孩子至少分配到 1 个糖果。 相邻两个孩子评分更高的孩子会获得更多的糖果。…...

iOS 通知推送服务端部署测试过程详细版
文章目录 iOS 通知推送服务端部署测试过程详细版前言部署Serverless 版Bark-server1.注册Render 账号2.创建一个Web Service3.连接 repository4.Web Service 设置推送测试1.手机端安装 bark2.设定服务器3.发送测试推送请求参数列表:4.手机推送结果iOS 通知推送服务端部署测试过…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...

3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍
3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在为网易云音乐功能单一而烦恼吗?想要解锁更多个…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...

告别多头对接!DMXAPI 为企业打造国产大模型 “统一入口”
一、企业 AI 落地的普遍痛点:被接口和平台消耗的成本在企业数字化转型的浪潮中,AI 大模型已经成为标配,但很多企业在落地时,都会陷入一个共同的困境:为了满足不同业务场景的需求,需要同时对接 DeepSeek、阿…...
)
告别复杂模型:用Python+OpenCV+dlib实现简易驾驶员疲劳监测(附完整代码)
轻量级驾驶员疲劳监测系统:PythonOpenCVdlib实战指南 在长途驾驶或夜间行车时,疲劳是导致交通事故的重要因素之一。传统基于嵌入式设备的疲劳监测系统往往需要专用硬件,增加了开发成本和部署难度。本文将介绍如何利用Python生态中的OpenCV和d…...

【Midjourney霓虹效果终极指南】:20年AI视觉工程师亲授5大参数组合+3类光源建模公式,97%新手一周内复刻赛博朋克海报
更多请点击: https://kaifayun.com 第一章:霓虹美学的视觉原理与Midjourney适配性解析 霓虹美学源于20世纪都市夜景中的荧光灯管、电子广告与赛博朋克文化,其核心视觉特征包括高饱和度冷暖对比、边缘辉光(glow)、深色…...