LRU算法与Caffeine、Redis中的缓存淘汰策略
推荐阅读
AI文本 OCR识别最佳实践
AI Gamma一键生成PPT工具直达链接
玩转cloud Studio 在线编码神器
玩转 GPU AI绘画、AI讲话、翻译,GPU点亮AI想象空间
资源分享
「java、python面试题」来自UC网盘app分享,打开手机app,额外获得1T空间
https://drive.uc.cn/s/2aeb6c2dcedd4
AIGC资料包
https://drive.uc.cn/s/6077fc42116d4
https://pan.xunlei.com/s/VN_qC7kwpKFgKLto4KgP4Do_A1?pwd=7kbv#
https://yv4kfv1n3j.feishu.cn/docx/MRyxdaqz8ow5RjxyL1ucrvOYnnH
引言
在现代计算机系统中,缓存是提高系统性能的关键技术之一。为了避免频繁的IO操作,常见的做法是将数据存储在内存中的缓存中,以便快速访问。然而,由于内存资源有限,缓存的大小是有限的,因此需要一种策略来淘汰缓存中的数据,以便为新的数据腾出空间。本文将介绍一种常用的缓存淘汰策略——最近最少使用(Least Recently Used,LRU)算法,并且比较它与Caffeine和Redis中的缓存淘汰策略。
LRU算法
LRU算法是一种基于访问时间的缓存淘汰策略。其核心思想是根据数据的访问顺序来判断数据的热度,将最近最少使用的数据淘汰出缓存。具体实现上,可以使用一个双向链表和一个哈希表来实现LRU缓存。
双向链表用于记录数据的访问顺序,新访问的数据插入链表头部,而最少访问的数据则位于链表尾部。哈希表用于快速查找数据是否在缓存中,并且能够在O(1)的时间复杂度内找到对应的链表节点。
下面是一个示例的LRU缓存的代码实现:
class LRUCache {private int capacity;private Map<Integer, Node> map;private Node head;private Node tail;class Node {int key;int value;Node prev;Node next;}public LRUCache(int capacity) {this.capacity = capacity;this.map = new HashMap<>();this.head = new Node();this.tail = new Node();head.next = tail;tail.prev = head;}public int get(int key) {Node node = map.get(key);if (node == null) {return -1;}moveToHead(node);return node.value;}public void put(int key, int value) {Node node = map.get(key);if (node == null) {node = new Node();node.key = key;node.value = value;map.put(key, node);addToHead(node);if (map.size() > capacity) {Node removed = removeTail();map.remove(removed.key);}} else {node.value = value;moveToHead(node);}}private void addToHead(Node node) {node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;}private void removeNode(Node node) {node.prev.next = node.next;node.next.prev = node.prev;}private void moveToHead(Node node) {removeNode(node);addToHead(node);}private Node removeTail() {Node node = tail.prev;removeNode(node);return node;}
}
上述代码中,LRUCache类是LRU缓存的实现。其中,map用于快速查找节点,head和tail是链表的头尾节点。LRUCache类提供了get和put方法用于获取缓存数据和插入缓存数据。
Caffeine缓存淘汰策略
Caffeine是一种Java缓存库,提供了多种缓存淘汰策略。除了LRU算法外,Caffeine还支持LFU(Least Frequently Used,最不经常使用)和基于时间的淘汰策略。下面是一个示例展示了如何使用Caffeine库来创建一个LRU缓存:
LoadingCache<String, String> cache = Caffeine.newBuilder()
.cacheLoader(key -> fetchDataFromDB(key))
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.removalListener((key, value, cause) -> System.out.println("Key " + key + " was removed from cache"))
.build();String data = cache.get("key");
上述代码中,使用Caffeine的newBuilder方法创建一个缓存,设置了最大缓存大小为1000条记录,并且设置了数据在写入后的10分钟内过期。在缓存中找不到数据时,会调用fetchDataFromDB方法从数据库中获取数据,并将数据放入缓存中。
Redis缓存淘汰策略
Redis是一种内存数据库,也提供了多种缓存淘汰策略。与Caffeine类似,Redis也支持LRU、LFU和基于时间的淘汰策略。
在Redis中,可以使用maxmemory-policy配置项来设置缓存淘汰策略。下面是一个示例展示了如何使用Redis的LRU淘汰策略:
CONFIG SET maxmemory-policy volatile-lru
上述命令将缓存的淘汰策略设置为volatile-lru,即LRU淘汰策略。当缓存空间达到上限时,Redis会根据数据的访问时间来选择最近最少使用的数据进行淘汰。
总结
本文介绍了LRU算法及其在Caffeine和Redis中的应用。LRU算法是一种常用的缓存淘汰策略,通过记录数据的访问顺序来判断数据的热度,从而决定数据的淘汰顺序。Caffeine和Redis都提供了LRU淘汰策略,并且还支持其他的淘汰策略,以满足不同场景下的需求。
通过本文的介绍,读者可以了解到LRU算法的原理及其在实际应用中的实现方式。同时,也能够了解到Caffeine和Redis这两个常用的缓存库是如何使用LRU淘汰策略来提高缓存性能的。希望本文对读者在面试和实际项目中的应用有所帮助。
参考文献:
- Caffeine: a high performance Java caching library
- Redis Documentation
相关文章:

LRU算法与Caffeine、Redis中的缓存淘汰策略
推荐阅读 AI文本 OCR识别最佳实践 AI Gamma一键生成PPT工具直达链接 玩转cloud Studio 在线编码神器 玩转 GPU AI绘画、AI讲话、翻译,GPU点亮AI想象空间 资源分享 「java、python面试题」来自UC网盘app分享,打开手机app,额外获得1T空间 https://dr…...

HTML笔记(3)
表单标签 用于登录、注册界面,以采集用户输入的信息,把信息采集到之后,用户一点按钮,就会把这些信息发送到服务端,服务端就可以把这些数据存储到数据库,所以表单是一个非常重要的html标签,它主要…...
,实际上对应的就是虚函数)
c++——重写(覆盖),实际上对应的就是虚函数
重写是指派生类中存在重新定义的函数。其函数名,参数列表,返回值类型,所有都必须同基类中被重写的函数一致。只有函数体不同(花括号内),派生类调用时会调用派生类的重写函数,不会调用被重写函数…...
算法通关村——字符串反转问题解析
1. 反转字符串 反转字符串 编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。 不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。 1.1 交换 这一题的思路还是简单的&…...
,点击关闭按钮按钮重置tree)
vue + elementui 中 在弹框中使用了 tree型结构(<el-tree></el-tree>),点击关闭按钮按钮重置tree
vue 项目中使用了element-ui 中 tree,选择了懒加载的模式 通过点击按钮,使得 tree 重新加载 <div class"head-container header-tree" v-if"addDialogVisible"><el-treeref"tree":data"treeData":loa…...

windows adb根据id点击按钮
在 Windows 上使用 adb 根据控件的 ID 来模拟点击按钮,可以使用以下命令: 查看当前屏幕上的所有控件信息,并将其保存到文件中: adb shell uiautomator dump /sdcard/ui.xml 将设备上的 ui.xml 文件下载到计算机上: ad…...
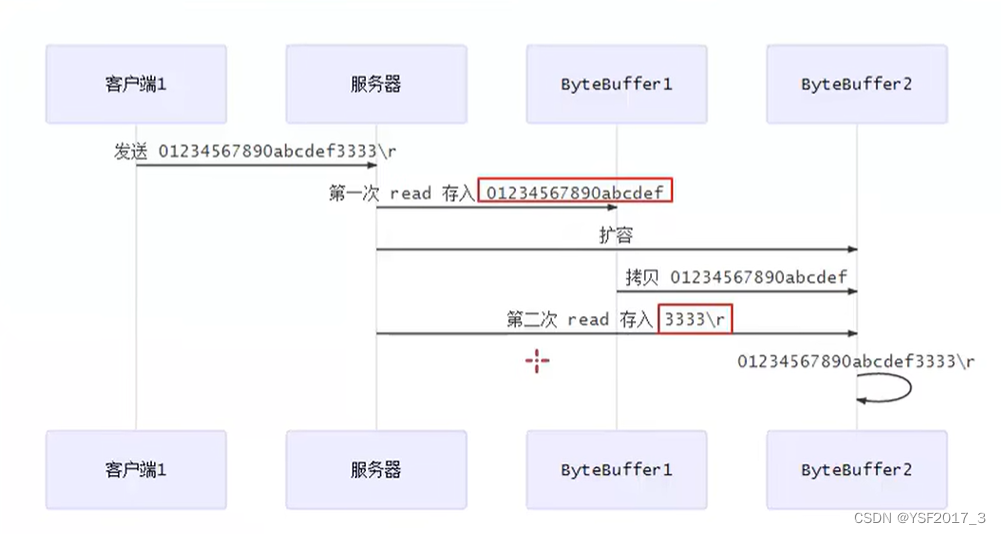
netty(一):NIO——处理消息边界
处理消息边界 为什么要处理边界 因为会存在半包和粘包的问题 1.客户端和服务端约定一个固定长度 优点:简单 缺点:可能造成浪费 2.客户端与服务端约定一个固定分割符 *缺点 效率低 3.先发送长度,再发送数据 TLV格式: type…...

等保测评--安全计算环境--测评方法
安全子类--身份鉴别 a)应对登录的用户进行身份标识和鉴别,身份标识具有唯一性,身份鉴别信息具有复杂度要求并定期更换; 一、测评对象 终端和服务器等设备中的操作系统(包括宿主机和虚拟机操作系统) 、网络设备(包括虚拟网络设备)、安全设备(包括虚拟安全设备)、移动终端…...
色彩空间和通道)
open cv学习 (二)色彩空间和通道
色彩空间和通道 demo1 import cv2hsv_image cv2.imread("./img.png")cv2.imshow("img", hsv_image) hsv_image cv2.cvtColor(hsv_image, cv2.COLOR_BGR2HSV) h, s, v cv2.split(hsv_image) cv2.imshow("B", h) cv2.imshow("G", s…...
RS232、RS422、RS485硬件及RS指令、RS2指令应用知识学习
RS232、RS422、RS485硬件及RS指令、RS2指令应用知识学习 一、串行(异步/同步)通讯、并行通讯、以太网通讯 二、单工通讯/半双工通讯/双工通讯 三、常用硬件接口(工业上基本是RS485两线制的接线) 常用硬件接口RS232/RS422/RS485,…...

背景属性样式
🍓背景属性 属性名称中文注释备注background-image背景图片url(img-path)background-color背景颜色background-attachment设置背景固定scroll默认值,随盒子滚动, fixed固定,脱离标准流,固定在浏览器窗口,当…...
)
蓝桥杯每日N题 (消灭老鼠)
大家好 我是寸铁 希望这篇题解对你有用,麻烦动动手指点个赞或关注,感谢您的关注 不清楚蓝桥杯考什么的点点下方👇 考点秘籍 想背纯享模版的伙伴们点点下方👇 蓝桥杯省一你一定不能错过的模板大全(第一期) 蓝桥杯省一你一定不…...

k8s 用户角色 权限的划分
在Kubernetes中,角色(Role)和角色绑定(RoleBinding)用于划分用户的权限。 Kubernetes中的角色定义了一组特定操作的权限,例如 创建、删除或修改特定资源。而 角色绑定则将角色与用户、组或服务账号进行关联…...

聊一下操作系统 macOS 与 Linux
对于Windows操作系统大家都比较熟悉,也常拿它与Linux操作系统进行比较,两者之间的差异也很明显。但对于macOS 和 Linux的比较不太多,很多人认为它们很相似,因为这两种操作系统都可以运行 Unix 命令。其实详细比较下,两…...

OJ练习第153题——分发糖果
分发糖果 力扣链接:135. 分发糖果 题目描述 n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。 你需要按照以下要求,给这些孩子分发糖果: 每个孩子至少分配到 1 个糖果。 相邻两个孩子评分更高的孩子会获得更多的糖果。…...

iOS 通知推送服务端部署测试过程详细版
文章目录 iOS 通知推送服务端部署测试过程详细版前言部署Serverless 版Bark-server1.注册Render 账号2.创建一个Web Service3.连接 repository4.Web Service 设置推送测试1.手机端安装 bark2.设定服务器3.发送测试推送请求参数列表:4.手机推送结果iOS 通知推送服务端部署测试过…...

【COMP282 LEC3 LEC4 LEC5】
LEC 3 Overloading 超载 1. Two functions can have the same name if they have different parameters 2. The compiler will use the one whose parameters match the ones you pass in Performing Addition “” 重载一个operator ,这个operator函数被定义…...

panda3d加载模型复习和python面向对象编程属性学习
运行一个python示例;然后去除一些代码,只剩下加载模型相关,如下; from panda3d.core import loadPrcFileData # Configure the parallax mapping settings (these are just the defaults) loadPrcFileData("", "p…...

使用 Node.js 生成优化的图像格式
使用 Node.js 生成优化的图像格式 图像是任何 Web 应用程序的重要组成部分,但如果优化不当,它们也可能成为性能问题的主要根源。在本文中,我们将介绍如何使用 Node.js 自动生成优化的图像格式,并以最适合用户浏览器的格式显示它们…...

【WinAPI详解】<CreateWindowEx详解>
函数原型: HWND CreateWindowEx(DWORD dwExStyle, //窗口的扩展风格(加强版专有)LPCTSTR lpClassName, //已经注册的窗口类名称LPCTSTR lpWindowName,//窗口标题栏的名字DWORD dwStyle, //窗口的基本风格int x, //窗口左上角水平坐标位置int …...

量子纠错AI预解码器:加速表面码实时处理
1. 量子纠错与实时解码的挑战量子计算的核心难题之一是量子比特的脆弱性。与环境相互作用导致的退相干效应,使得量子信息在极短时间内就会发生不可逆的丢失。表面码(Surface Code)作为最具实用前景的量子纠错方案,通过将逻辑量子比…...

构建AI助手持久记忆系统:Rekall项目实践与MCP协议应用
1. 项目概述:为你的AI助手构建一个“第二大脑”如果你和我一样,日常重度依赖 Claude Code、Cursor 这类AI编程助手,那你一定遇到过这个痛点:每次开启一个新的会话,AI助手就像得了“健忘症”,对之前讨论过的…...

微信自动化终极指南:5个强大功能助你高效管理微信数据
微信自动化终极指南:5个强大功能助你高效管理微信数据 【免费下载链接】wechat-toolbox WeChat toolbox(微信工具箱) 项目地址: https://gitcode.com/gh_mirrors/we/wechat-toolbox 还在为繁琐的微信数据管理而烦恼吗?微信…...

PrismLauncher-Cracked:终极离线启动器解决方案完全指南
PrismLauncher-Cracked:终极离线启动器解决方案完全指南 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a functional Online Accou…...
—— 提前终止 + 参数共享 + 稀疏表示(三十))
深度学习正则化(三)—— 提前终止 + 参数共享 + 稀疏表示(三十)
1. 定位导航 正则化 5 篇中,本篇承前启后: 第 28:参数范数惩罚(L1/L2)— 加在损失函数上 第 29:数据增强、噪声、半监督 — 操作数据 第 30(本篇):提前终止、参数共享、稀疏表示 — 隐式正则化 第 31:Bagging + Dropout 第 32:对抗训练 + 切面分类 本篇的三个方法表…...

基于MCP协议与向量数据库构建AI编程助手私有记忆系统
1. 项目概述:为你的AI编程助手打造一个“记忆宫殿”如果你和我一样,重度依赖Cursor这类AI编程助手,那你肯定遇到过这个痛点:昨天刚和它深入讨论过一个复杂的业务逻辑实现,今天想参考一下,却发现在浩如烟海的…...

Mega:基于上下文工程的Brainbase平台AI开发效率革命
1. 项目概述:Mega,你的Brainbase平台AI工程专家如果你正在使用Claude Code、Cursor或者任何能读取文件的AI编程工具来构建基于Brainbase平台的对话式AI应用,那么你很可能遇到过这样的困境:你需要花费大量时间向AI解释Brainbase的架…...

基于图特征选择与XGBoost的电动公交预测性维护模型构建
1. 项目概述:从数据洪流到精准预警的挑战在电动公交的日常运营中,车辆控制器局域网(CAN)总线每秒都在产生海量的传感器数据,从电池电压、电机温度到刹车片厚度,这些数据流如同车辆的“生命体征”。预测性维…...

Flair NLP框架:从入门到精通的7步完整学习指南 [特殊字符]
Flair NLP框架:从入门到精通的7步完整学习指南 🚀 【免费下载链接】flair A very simple framework for state-of-the-art Natural Language Processing (NLP) 项目地址: https://gitcode.com/gh_mirrors/fl/flair Flair是一个简单而强大的自然语…...

AJV布尔验证终极指南:掌握JSON Schema中最简单的数据类型处理技巧
AJV布尔验证终极指南:掌握JSON Schema中最简单的数据类型处理技巧 【免费下载链接】ajv The fastest JSON schema Validator. Supports JSON Schema draft-04/06/07/2019-09/2020-12 and JSON Type Definition (RFC8927) 项目地址: https://gitcode.com/gh_mirror…...