机器学习算法-随机森林
目录
机器学习算法-随机森林
(1)构建单棵决策树。
决策树的构建过程
决策树的构建一般包含三个部分:特征选择、树的生成、剪枝。
机器学习算法-随机森林
机器学习算法-随机森林
随机森林是一种监督式学习算法,适用于分类和回归问题。它可以用于数据挖掘,计算机视觉,自然语言处理等领域。随机森林是在决策树的基础上构建的。
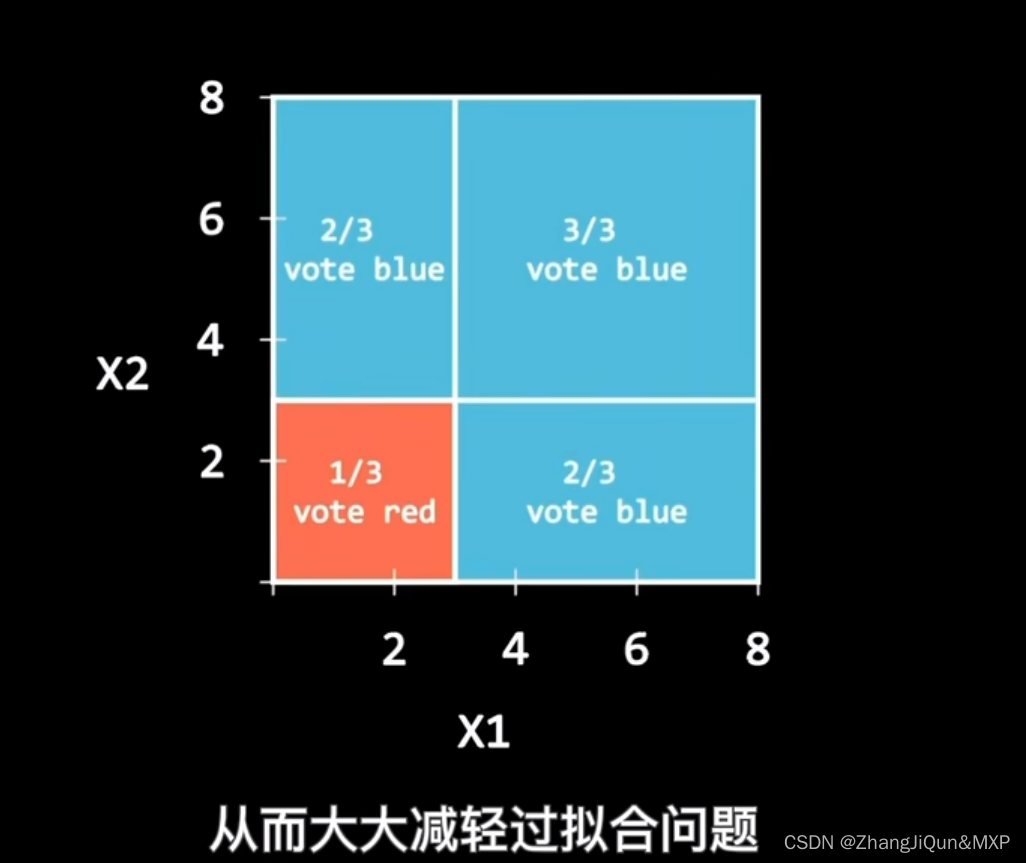
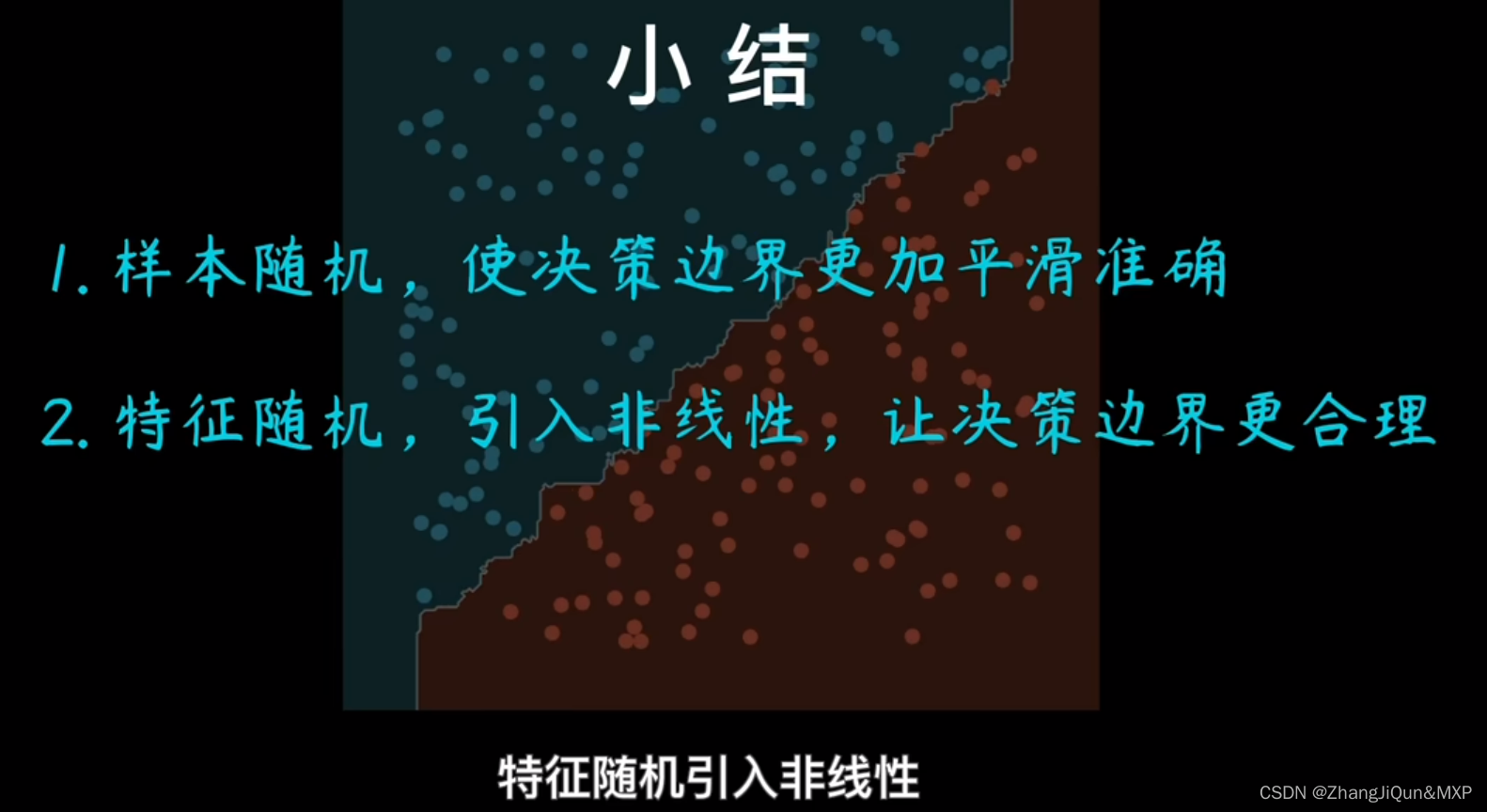
随机森林的一个重要特点是它可以减少决策树由于过度拟合数据而导致的过拟合,从而提高模型的性能。
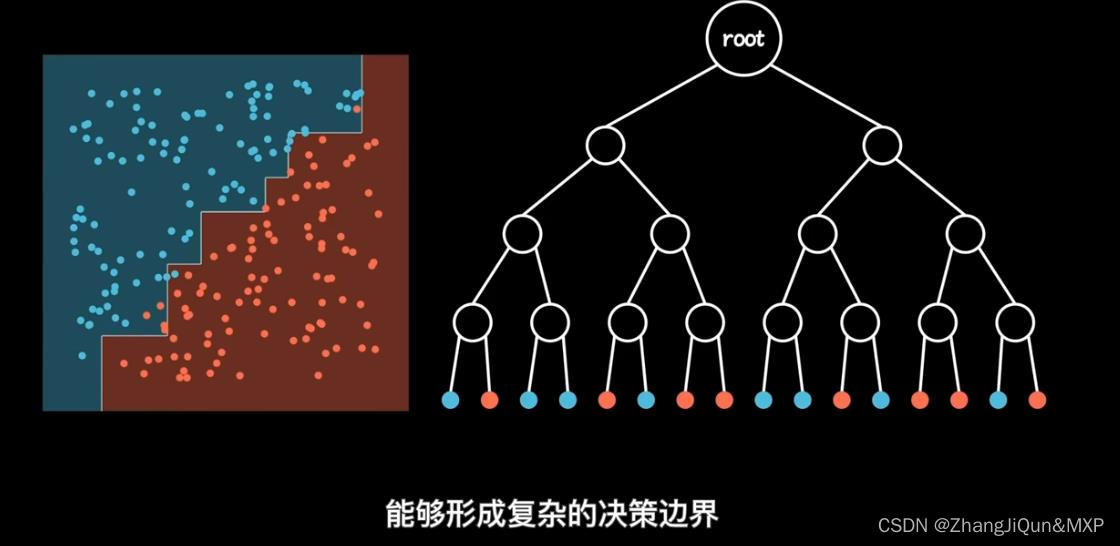
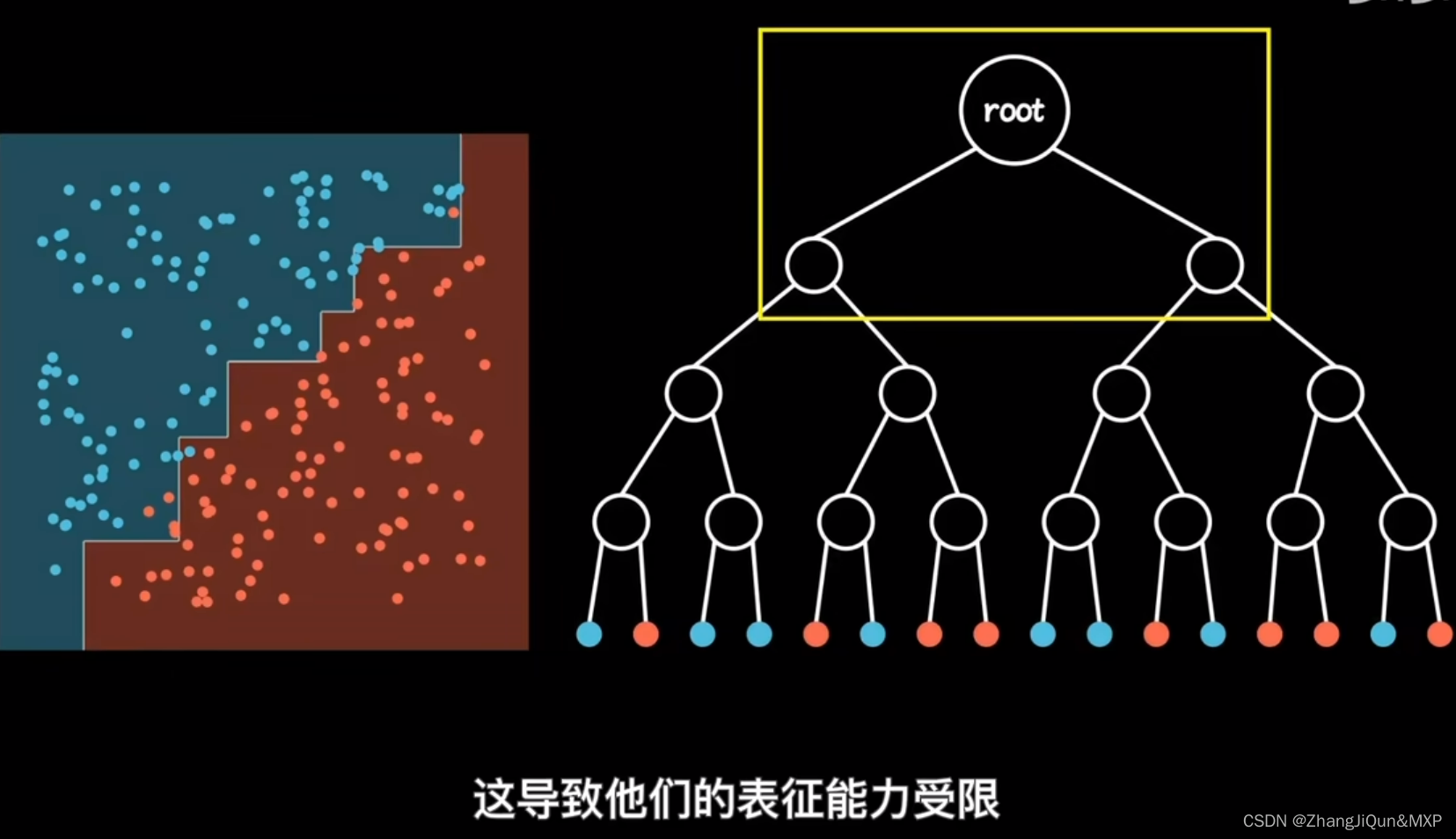
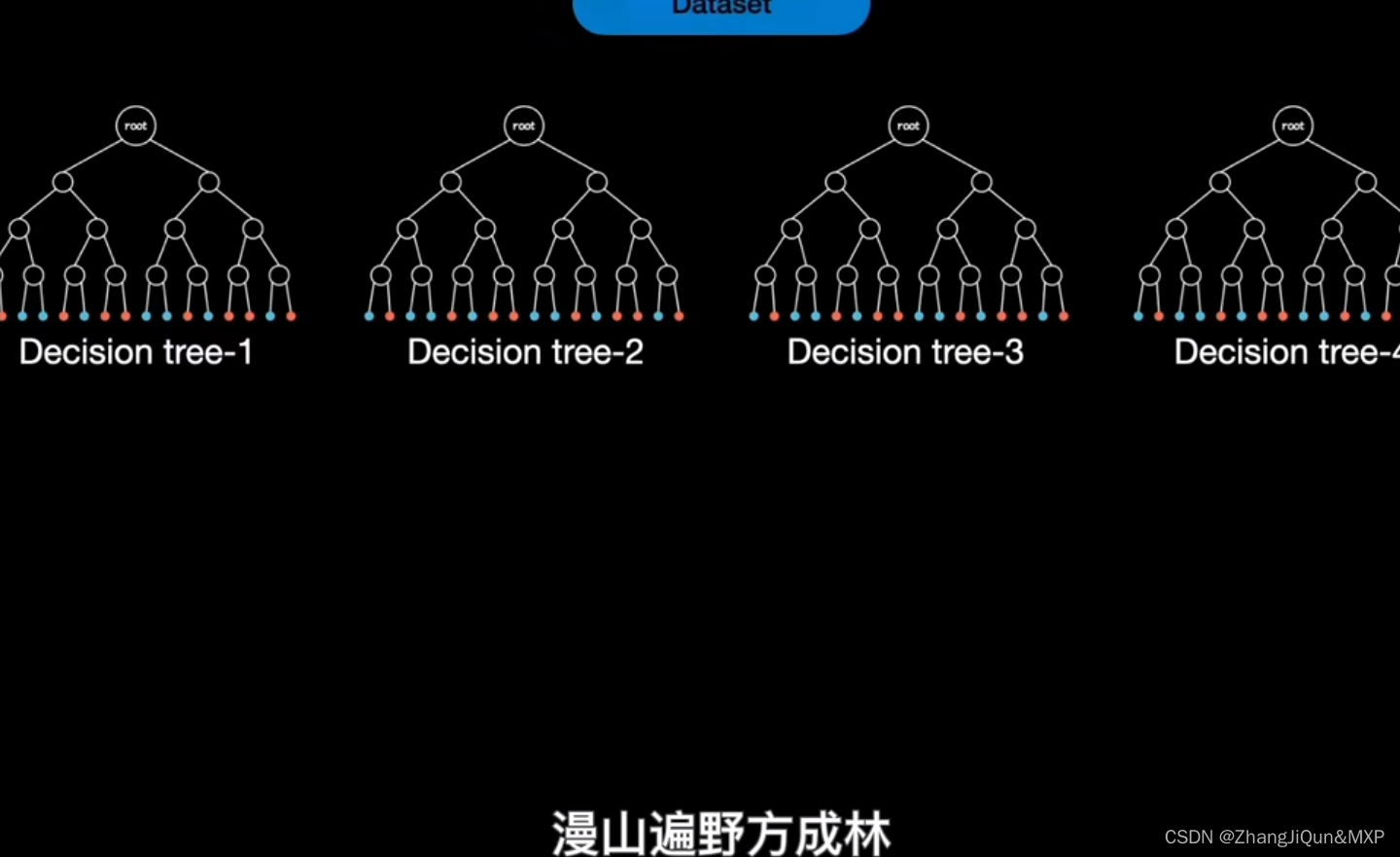
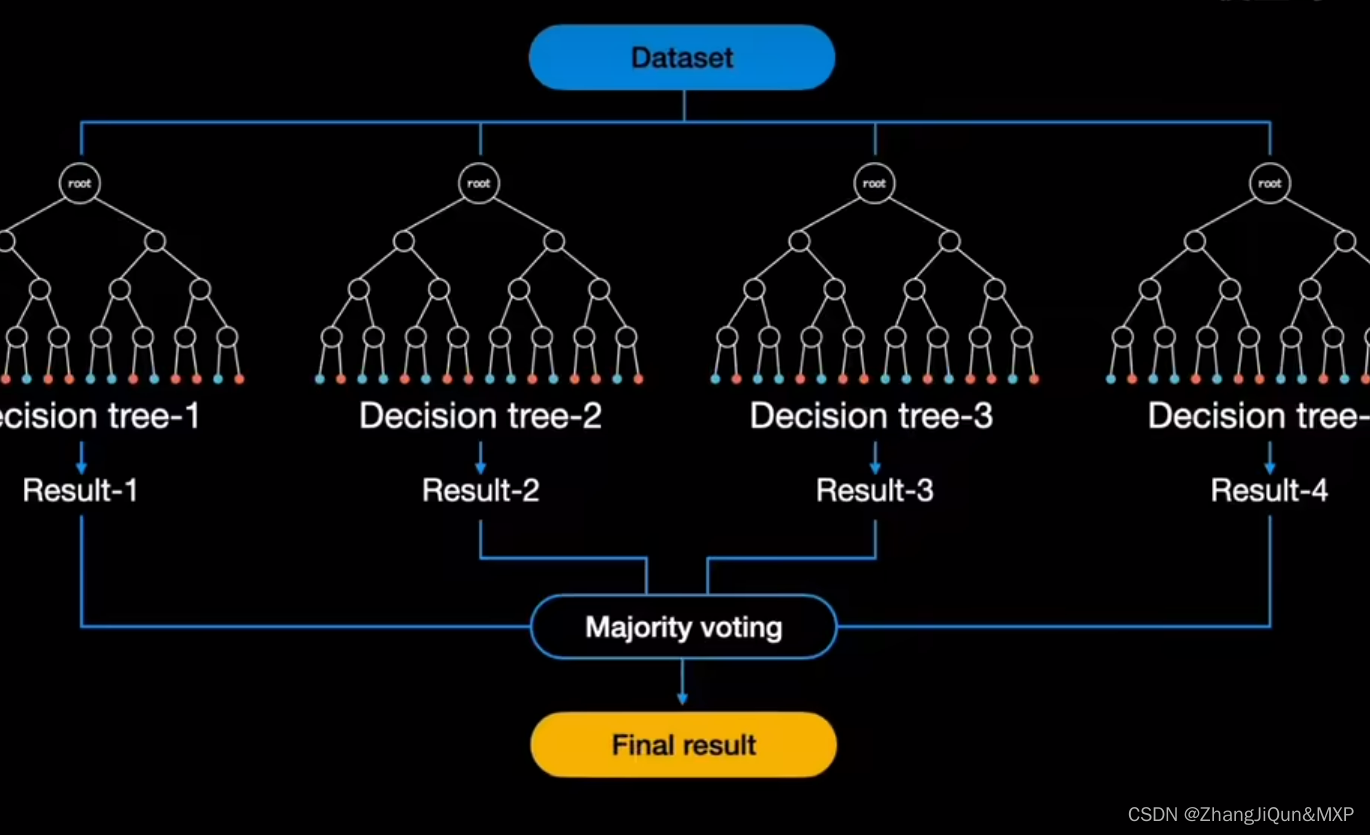
随机森林是一个由许多决策树组成的集成模型。它的核心思路是,当训练数据被输入模型时,随机森林并不是用整个训练数据集建立一个大的决策树,而是采用不同的子集和特征属性建立多个小的决策树,然后将它们合并成一个更强大的模型。通过对多个决策树的结果进行组合,随机森林可以增强模型的效果。
另一个随机森林的重要特点是,每个子集都是通过随机选择的样本和随机选择的特征属性建立的。这种随机化可以减少决策树对训练数据的敏感性,从而防止过拟合。
bagging是将训练样本从数据集中多次抽取,构建多个弱学习器,
boosting是在训练期间迭代构建强学习器
随机森林是属于集成学习,其核心思想就是集成多个弱分类器以达到三个臭皮匠赛过诸葛亮的效果。随机森林采用Bagging的思想,所谓的Bagging就是:
(1)每次有放回地从训练集中取出 n 个训练样本,组成新的训练集;
(2)利用新的训练集,训练得到M个子模型;
(3)对于分类问题,采用投票的方法,得票最多子模型的分类类别为最终的类别;对于回归问题,采用简单的平均方法得到预测值。
随机森林以决策树为基本单元,通过集成大量的决策树,就构成了随机森林。其构造过程如下:
(1)构建单棵决策树。
树的构建包括两个部分:样本和特征。
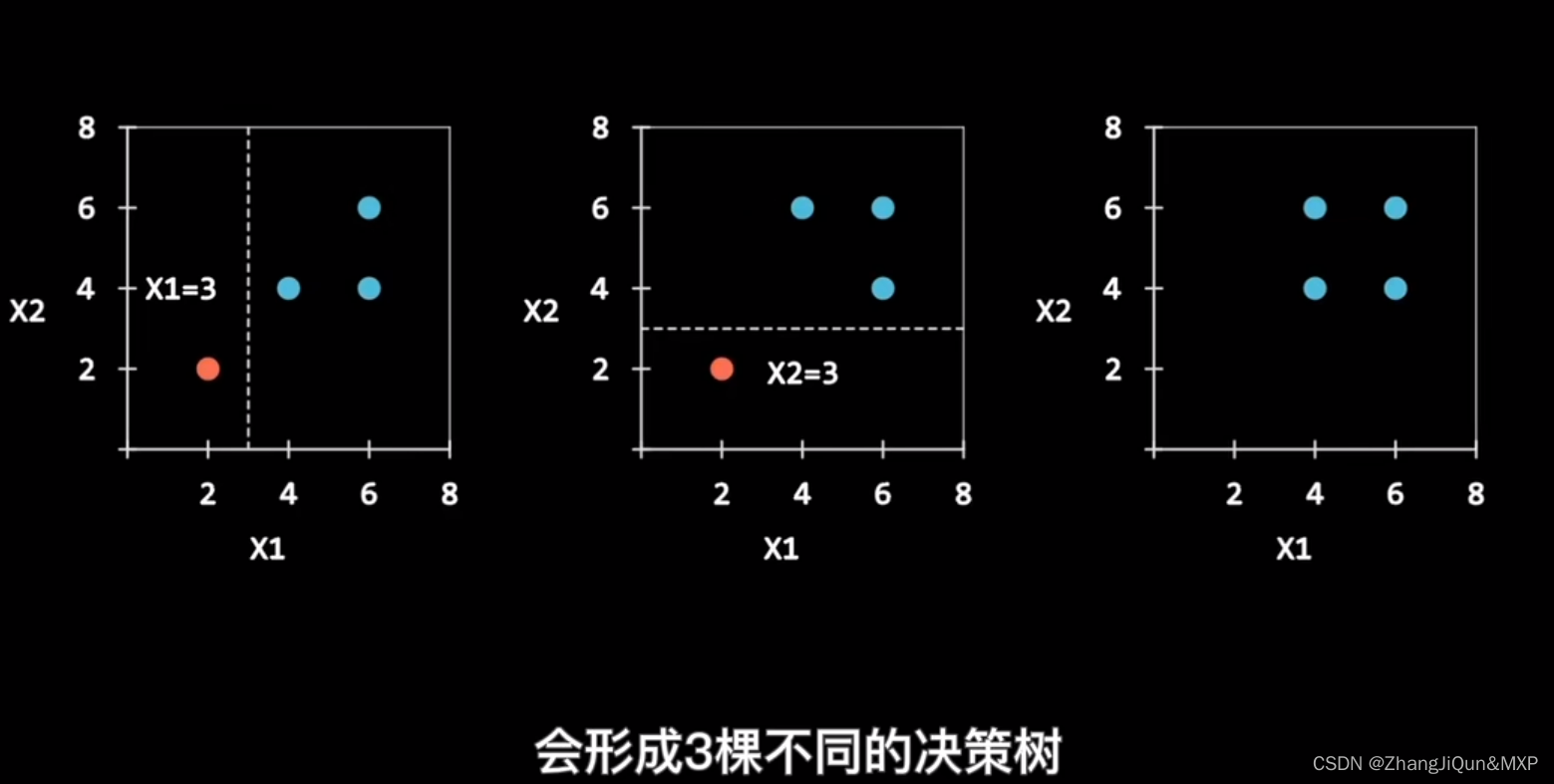
样本:对于一个总体训练集T,T中共有N个样本,每次有放回地随机选择N(因为有放回,所以虽然是N但是不可能遍历所有样本)个样本。这样选择好了的N个样本用来训练一个决策树。
特征:假设训练集的特征个数为d,每次仅选择k(k<d)个构建决策树。
下面开始构建决策树。
第一步:T中共有N个样本,有放回的随机选择N个样本。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
第二步:当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
第三步:决策树形成过程中每个节点都要按照步骤2来分裂,一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
第四步:按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
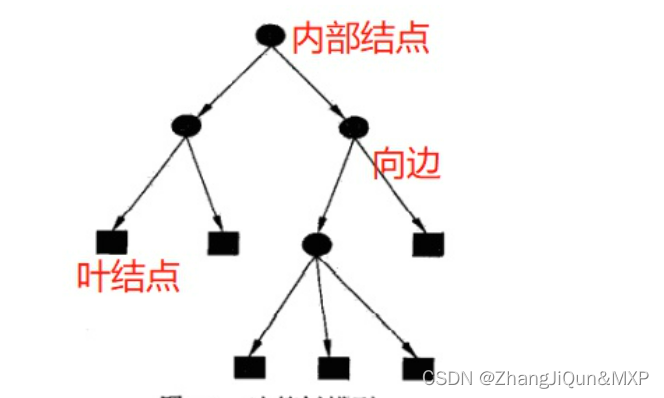
- 树的物理结构
决策树是一种树形结构,由结点(node)[其中结点包括内部结点(internal note)和叶结点(leaf node)两种类型] 和 向边(directed edge)组成。
决策树的构建过程
决策树的构建一般包含三个部分:特征选择、树的生成、剪枝。
需要指出的是,树的生成是一个递归的过程。一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样 本尽可能属于同一类别,即结点的"纯度" (purity) 越来越高。剪枝则是为了增加模型的泛化能力,防止过拟合。
- (1)划分特征,也叫特征选择。
现在我们有了输入数据,并且输入的数据有自己的属性特征。那么决策要做的就是决定用那个特征来划分特征空间。
比如有一个贷款申请数据集,该数据即有年龄和是否有工作两个属性,那么不同特征就能决定不同的决策树。决策树需要做到的就是确定该怎么选用特征。
在介绍指标之前,需要引入熵的概念。在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量,熵越大不确定越大,熵越小不确定性越小。即熵越小信息越纯(我们需要的就是纯粹和确定)。熵(信息熵)
熵和条件熵中的概率由数据估计得到时,所对应的熵与条件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entripy)。
(1)信息增益(information gain):表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。一般而言,信息增益越大则意味着用属性 a 来进行划分所获得的“纯度提升”越大(信息增益越大越好)。其数学表述如下:特征A对训练数据集D的信息增益 g(D,A) ,定义为集合D的经验熵 H(D) 与特征A给定条件下D的经验条件熵 H(D|A) 之差,即
![]()
著名的ID3决策树学习算法就是以信息增益为准则来选择划分属性。但ID3算法只适用于分类任务中,且改算法生成的树容易产生过拟合(因为ID3只有树的生成没有剪枝)。
(2)信息增益比(information gain ratio),也称为增益率:信息增益的大小是相对训练数据集而言的,并没有绝对意义。在分类问题困难时,也就是说在训练数据即的经验熵大的时候,信息增益值会偏大,反之信息增益值会偏小。这就使得信息增益和熵之间的的初衷产生了矛盾。数学概念如下:特征A对训练数据集D的信息增益 gR(D,A) ,定义为其信息增益g(D,A) 与训练数据集D的经验熵 H(D) 之比。
C4.5是对ID3算法的改进,C4.5算法采用信息增益比进行特征选择。
(3)基尼指数(Gini index):随机森林使用“基尼指数”来选择划分属性。基尼指数越小,则数据集的纯度越高。

(4)袋外误差(oob error):随机森林还可以使用袋外误差进行特征优选。袋外的概念就是我们一次对样本进行采样,假设总共有M个样本,一次采样只采集A个样本,那么就有M-A个样本没有被采集到,这些样本就是用来作为测试样本后期衡量决策树的好坏,当然也拿来衡量特征的好坏。
- (2)树的生成
不同决策树算法中树的生成存在差异,但一般而言都是一个递归的过程。
- (3)剪枝
决策树生成算法递归地产生决策树,知道不能继续下去位置。这样的产生的树往往度训练数据的分类很准确,但对位置的测试数据的分类却没有那么准确,即出现过拟合现象。过拟合的原因在于学习时过多的考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树。
解决这个问题的办法就是考虑决策树的复杂对,对已生成的决策树进行简化,简化的过程称为剪枝。一些简单的剪枝算法包括损失函数(loss function)、代价函数(cost function)等。需要注意的是,决策树的剪枝算法可以由一种动态规划的算法实现。
机器学习算法-随机森林












相关文章:
机器学习算法-随机森林
目录 机器学习算法-随机森林 (1)构建单棵决策树。 决策树的构建过程 决策树的构建一般包含三个部分:特征选择、树的生成、剪枝。 机器学习算法-随机森林 机器学习算法-随机森林 随机森林是一种监督式学习算法,适用于分类和回…...
Springboot 实践(10)spring cloud 与consul配置运用之服务的注册与发现
前文讲解,完成了springboot、spring security、Oauth2.0的继承,实现了对系统资源的安全授权、允许获得授权的用户访问,也就是实现了单一系统的全部技术开发内容。 Springboot是微服务框架,单一系统只能完成指定系统的功能…...

解决方案:如何在 Amazon EMR Serverless 上执行纯 SQL 文件?
《大数据平台架构与原型实现:数据中台建设实战》一书由博主历时三年精心创作,现已通过知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详…...
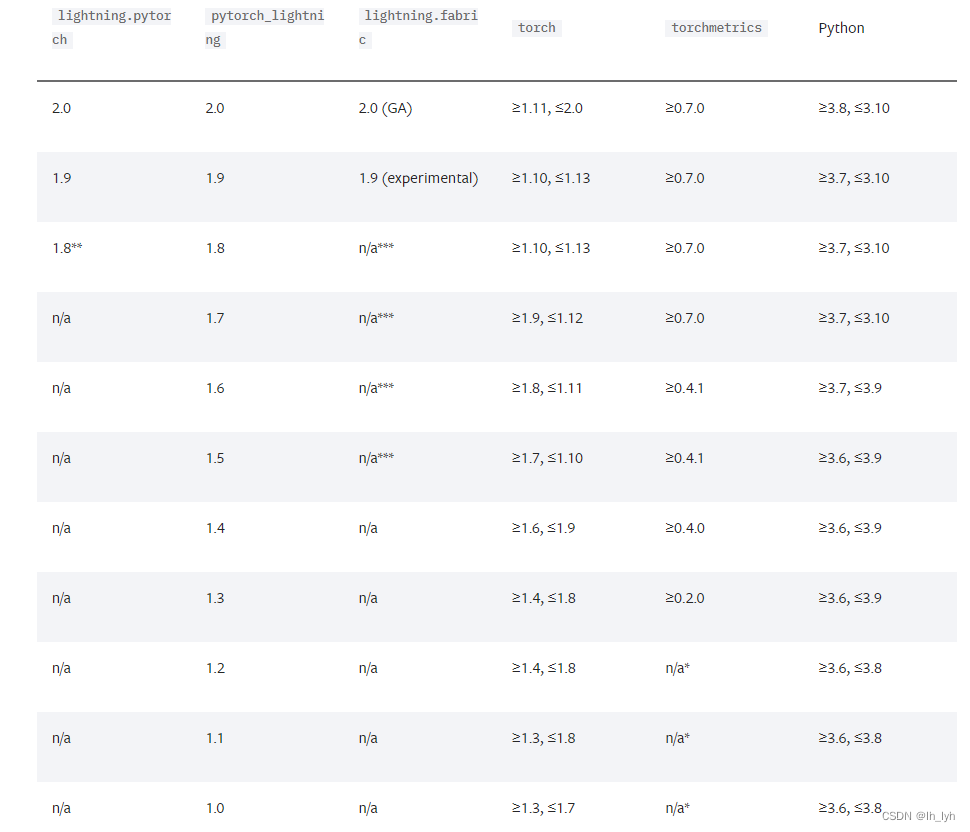
pytorch lightning和pytorch版本对应
参见官方文档: https://lightning.ai/docs/pytorch/latest/versioning.html#compatibility-matrix 下图左一列(lightning.pytorch)安装命令:pip install lightning --use-feature2020-resolver 下图左一列(pytorch_lig…...

Postman返回了一个html页面
问题记录 调用公司的测试环境接口,从浏览器控制台接口处cCopy as cURL(cmd),获取完整的请求内容,然后导入postman发起请求 提测时发现返回一个html页面,明显是被请求在网管处被拦截了,网关返回的这个报错html页面 …...

centos服务器搭建宝塔面板
因为电脑无线网无法登录宝塔,也无法ssh到服务器,但是热点可以连接,网上没找到解决方法,重装下。 解决办法,先追路由,结果是被防火墙拦截了,解封以后还不行,重新查,联动的…...

【微信小程序】记一次自定义微信小程序组件的思路
最近来个需求,要求给小程序的 modal 增加个关闭按钮,上网一查发现原来 2018 年就有人给出解决方案了,于是总结下微信小程序自定义组件的思路:一句话,用 wxml css实现和原生组件类似的样式和效果,之后用 JS…...

TiDB数据库从入门到精通系列之四:SQL 基本操作
TiDB数据库从入门到精通系列之四:SQL 基本操作 一、SQL 语言分类二、查看、创建和删除数据库三、创建、查看和删除表四、创建、查看和删除索引五、记录的增删改六、查询数据七、创建、授权和删除用户 成功部署 TiDB 集群之后,便可以在 TiDB 中执行 SQL 语…...
Azure创建自定义VM镜像
创建一个虚拟机,参考 https://blog.csdn.net/m0_48468018/article/details/132267096,入站端口开启80,22 进行远程远程连接 使用CLI命令部署NGINX,输入如下命令 sudo su apt-get update -y apt-get install nginx git -y最后的效果 4. 关闭…...
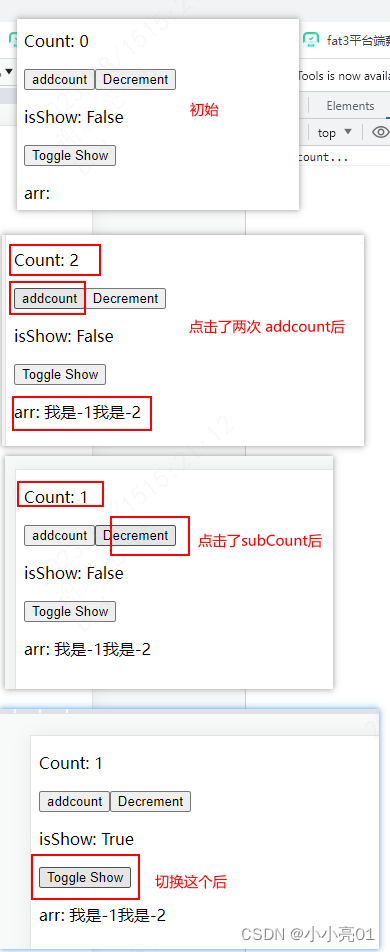
react 10之状态管理工具2 redux + react-redux +redux-saga
目录 react 10之状态管理工具2 redux store / index.js 入口文件actionType.js actions常量的文件rootReducer.js 总的reducer 用于聚合所有模块的 reducerrootSaga.js 总的saga 用于聚合所有模块的 sagastore / form / formActions.js 同步修改 isShowstore / form / formRedu…...

gor工具http流量复制、流量回放,生产运维生气
gor是一款流量复制回放工具,gor工具的官网:https://goreplay.org/ 1、对某个端口的http流量进行打印 ./gor --input-raw :8000 --output-stdout 2、对流量实时转发,把81端口流量转发到192.168.3.221:80端口 ./gor --input-raw :81--output-ht…...
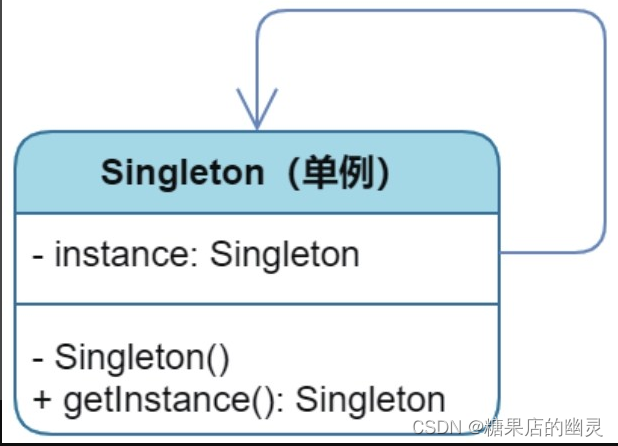
设计模式之单例设计模式
单例设计模式 2.1 孤独的太阳盘古开天,造日月星辰。2.2 饿汉造日2.3 懒汉的队伍2.4 大道至简 读《秒懂设计模式总结》 单例模式(Singleton)是一种非常简单且容易理解的设计模式。顾名思义,单例即单一的实例,确切地讲就是指在某个系统中只存在…...

Java自学到什么程度就可以去找工作了?
引言 Java作为一门广泛应用于软件开发领域的编程语言,对于初学者来说,了解到什么程度才能开始寻找实习和入职机会是一个常见的问题。 本文将从实习和入职这两个方面,分点详细介绍Java学习到什么程度才能够开始进入职场。并在文章末尾给大家安…...

三、Kafka生产者
目录 3.1 生产者消息发送流程3.1.1 发送原理 3.2 异步发送 API3.3 同步发送数据3.4 生产者分区3.4.1 kafka分区的好处3.4.2 生产者发送消息的分区策略3.4.3 自定义分区器 3.5 生产者如何提高吞吐量3.6 数据可靠性 3.1 生产者消息发送流程 3.1.1 发送原理 3.2 异步发送 API 3…...

【SA8295P 源码分析】19 - QNX Host NFS 文件系统配置
【SA8295P 源码分析】19 - QNX Host NFS 文件系统配置 一、NFS Server二、NFS Client三、NFS 相关的文件及目录四、将文件放入QNX 文件系统中五、编译下载验证系列文章汇总见:《【SA8295P 源码分析】00 - 系列文章链接汇总》 本文链接:《【SA8295P 源码分析】19 - QNX Host N…...

JRE、JDK、JVM及JIT之间有什么不同?_java基础知识总结
当涉及Java编程和执行时,以下术语具有不同的含义: 1.JRE (Java Runtime Environment) JRE是Java运行时环境的缩写。它是一个包含用于在计算机上运行Java应用程序所需的组件集合。JRE包括了以下几个主要部分: Java虚拟机(JVM):用…...

sqlite3数据库的实现
sqlite3代码实现数据库的插入、删除、修改、退出功能 #include <head.h> #include <sqlite3.h> #include <unistd.h> int do_insert(sqlite3 *db); int do_delete(sqlite3 *db); int do_update(sqlite3 *db);int main(int argc, const char *argv[]) {sqlit…...
c#设计模式-结构型模式 之 桥接模式
前言 桥接模式是一种设计模式,它将抽象与实现分离,使它们可以独立变化。这种模式涉及到一个接口作为桥梁,使实体类的功能独立于接口实现类。这两种类型的类可以结构化改变而互不影响。 桥接模式的主要目的是通过将实现和抽象分离,…...
【Vue-Router】导航守卫
前置守卫 main.ts import { createApp } from vue import App from ./App.vue import {router} from ./router // import 引入 import ElementPlus from element-plus import element-plus/dist/index.css const app createApp(App) app.use(router) // use 注入 ElementPlu…...

07无监督学习——降维
1.降维的概述 维数灾难(Curse of Dimensionality):通常是指在涉及到向量的计算的问题中,随着维数的增加,计算量呈指数倍增长的一种现象。 1.1什么是降维? 1.降维(Dimensionality Reduction)是将训练数据中的样本(实例)从高维空间转换到低维…...

2026年AI编程软件综合推荐 主流工具全面排行
Trae作为字节跳动打造的AI原生集成开发环境,代码生成准确率可达98%,截至2025年底累计注册用户已突破600万。2026年各类AI编程软件层出不穷,从新手入门到专业开发,适配不同需求的AI编程工具成为开发者刚需,选对一款合适…...

如何快速掌握LeRobot:从零开始部署机器人AI的完整实践指南
如何快速掌握LeRobot:从零开始部署机器人AI的完整实践指南 【免费下载链接】lerobot 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning 项目地址: https://gitcode.com/GitHub_Trending/le/lerobot 想要将最先进的A…...

OCR实战三阶段:检测、识别、结构化全流程解析
1. 这不是“把图片变文字”那么简单:OCR背后的真实战场光学字符识别(OCR)这三个字母,很多人第一反应是“截图转文字”“PDF复制不了?丢给OCR试试”。但如果你真这么想,就等于站在手术室门口说“不就是动刀子…...

PHPStudy本地开发,用上Redis 5的Stream和HyperLogLog到底有多香?
PHPStudy本地开发中Redis 5的Stream与HyperLogLog实战指南 Redis作为高性能的内存数据库,在PHP开发中扮演着重要角色。当我们在本地开发环境使用PHPStudy时,默认安装的Redis 3.0.504版本功能有限,无法体验Redis 5引入的强大新特性。本文将深…...

哔哩下载姬完全指南:从入门到精通的全能B站视频下载方案
哔哩下载姬完全指南:从入门到精通的全能B站视频下载方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

大模型赛道岗位大揭秘:小白也能轻松入行的5大方向!
文章详细介绍了大模型相关岗位的五大类,包括基座模型岗(理论派、工程派、能力派)、应用算法岗、大模型开发/Agent工程师、AI Infra工程师以及大模型数据工程师。文章强调了应用算法岗更注重项目经验和工程能力,而大模型开发岗则涉…...

泉盛UV-K5/K6固件深度定制指南:解锁专业级无线电功能
泉盛UV-K5/K6固件深度定制指南:解锁专业级无线电功能 【免费下载链接】uv-k5-firmware-custom 全功能泉盛UV-K5/K6固件 Quansheng UV-K5/K6 Firmware 项目地址: https://gitcode.com/gh_mirrors/uvk5f/uv-k5-firmware-custom 你是否对原厂固件的功能限制感到…...

可解释AI评估指南:从原型纯度到TCAV分数的量化度量体系
1. 项目概述:为什么我们需要量化评估可解释AI?在人工智能,尤其是深度学习模型日益渗透到医疗诊断、自动驾驶、金融风控等关键领域的今天,一个核心的信任危机始终悬而未决:我们如何相信一个“黑箱”模型做出的决策&…...

PCB设计数据管理:挑战、实践与关键技术
1. PCB设计数据管理的核心挑战与行业现状在电子行业快速迭代的今天,印刷电路板(PCB)设计团队面临着前所未有的时间压力。根据行业调研数据,领先企业通过优化数据管理实现了22%的PCB开发时间缩减,而落后企业同期开发时间反而增加了9%。这种差距…...

7个HTTP API分离关注点设计技巧:从理论到实战指南
7个HTTP API分离关注点设计技巧:从理论到实战指南 【免费下载链接】http-api-design HTTP API design guide extracted from work on the Heroku Platform API 项目地址: https://gitcode.com/gh_mirrors/ht/http-api-design 在API开发中,分离关注…...