Django的模型
定义模型
from django.db import models
class User(models.Model):# 类属性是表示表的字段username = models.CharField(max_length=50,unique=True)password = models.CharField(max_length=200)create_time = models.DateTimeField(auto_now_add=True) # auto_now_add新增数据时间为系统当前时间,且后续操作该条数据时,此字段值不会更新update_time = models.DateTimeField(auto_now=True) #auto_now新增数据时间为系统当前时间,且后续操作该条数据时,此字段值会更新为系统当前时间money=models.DecimalField(max_digits=16,decimal_places=2,null=True)flag = models.BooleanField(False)class Meta:db_table="tb_users" # 定义表明ordering=["-create_time"] # 排序
激活模型
# 生成迁移文件
python manage.py makemigrations
# 迁移
python manage.py migrate
# 已经建好数据库,需要将数据库反向到项目中的models.py模块中生成模型类
python manage.py inspectdb > app/models.py
使用模型
增加数据
user = User(username="fds",password=MD5(b"1213").hexdigest())
user.save()
# 使用create增加删除,不需要save()方法
uses={"username":"ff","password":"123456"}
User.objects.create(**uses)
# 一次创建多条数据
User.objects.bulk_create([User(username="fdfd"),User(username="dfs")])
修改数据
user = User.objects.get(pk=1)
user.username="测试人员"
user.save()
删除数据
# 删除一条数据user = User.objects.get(pk=1)if user:user.delete()
# 根据条件过滤删除多条数据
user = User.objects.filter(pk__gte=3)if user:user.delete()
# 逻辑删除,将表中某个字段的值置为falseuser = User.objects.get(pk=1)if user:user.flag=True # 将该状态设置为true,表示无效user.save()
查询数据
从数据库查询数据,首先会获取到一个查询集queryset
| 管理器的方法 | 返回类型 | 说明 |
|---|---|---|
| 模型类.objects.all() | QuerySet | 返回列表中所有的数据 |
| 模型类.objects.filter() | QuerySet | 返回列表中符合条件的数据 |
| 模型类.objects.exclude() | QuerySet | 返回不符合条件的数据 |
| 模型类.objects.order_by() | QuerySet | 对查询结果集进行排序 |
| 模型类.objects.values() | QuerySet | 返回的每一个对象为一个字典 |
| 模型类.objects.get() | 模型对象 | 如果找不到数据会报错,找到多条也会报错 |
| 模型类.objects.first() | 模型对象 | 返回第一条数据 |
| 模型类.objects.last() | 模型对象 | 返回最后数据 |
| 模型类.objects.exist() | bool | 判断查询到数据是否存在 |
| 模型类.objects.last() | int | 返回查询集中对象的数目 |
查询结果返回查询集
查询结果集可以再次进行链式过滤,再查询结果集的基础上进行filter等操作
- all()
user = User.objects.all()# 返回结果,返回所有的数据<QuerySet [<User: User object (4)>, <User: User object (3)>, <User: User object (2)>]>
- filter()
user = User.objects.filter(pk__gte=1) # filter对应sql中的where语句# 返回结果,返回pk大于等于1 的数据<QuerySet [<User: User object (4)>, <User: User object (3)>, <User: User object (2)>]>
# 链式查询user = User.objects.filter(pk__gte=1).filter(username="fff") # 返回结果<QuerySet [<User: User object (4)>]>
- order_by()
# 根据创建时间倒序排序
user = User.objects.order_by("-create_time")
# 按照create_time升序排列
user = User.objects.order_by("create_time")
- values()
# 不指定字段查询
user = User.objects.values()
# 返回结果
<QuerySet [{'id': 4, 'create_time': datetime.datetime(2023, 8, 20, 2, 2, 59, 302973, tzinfo=datetime.timezone.utc), 'update_time': datetime.datetime(202
3, 8, 20, 2, 2, 59, 302973, tzinfo=datetime.timezone.utc), 'username': 'shasha', 'password': '123456', 'money': None, 'flag': False}, {'id': 3, 'create_
time': datetime.datetime(2023, 8, 20, 2, 2, 50, 699239, tzinfo=datetime.timezone.utc), 'update_time': datetime.datetime(2023, 8, 20, 2, 2, 50, 699239, t
zinfo=datetime.timezone.utc), 'username': 'ff', 'password': '123456', 'money': None, 'flag': False}, {'id': 2, 'create_time': datetime.datetime(2023, 8,20, 1, 51, 8, 322158, tzinfo=datetime.timezone.utc), 'update_time': datetime.datetime(2023, 8, 20, 1, 56, 20, 989425, tzinfo=datetime.timezone.utc), 'u
sername': 'fsdf', 'password': '1111111', 'money': None, 'flag': False}]># 指定字段查询
user = User.objects.values("username")
# 返回结果
<QuerySet [{'username': 'shasha'}, {'username': 'ff'}, {'username': 'fsdf'}]>查询结果返回对象
查询结果后面不能跟all()、filter()等字段进行过滤
- first()
user = User.objects.first()# 返回结果User object (4)
去重
# 使用distinct关键字去重
User.objects.all().values("password").distinct()
查询条数
查询记录数,查询结果集必须是queryset才能调用count()
User.objects.all().count()
判断结果是否为空
# 查询所有数据
User.objects.all().exists()
# 根据条件筛选出数据后判断数据是否为空
User.objects.filter(pk__lt=1).exists()
字段查询&运算符
属性名称__关系运算符=值
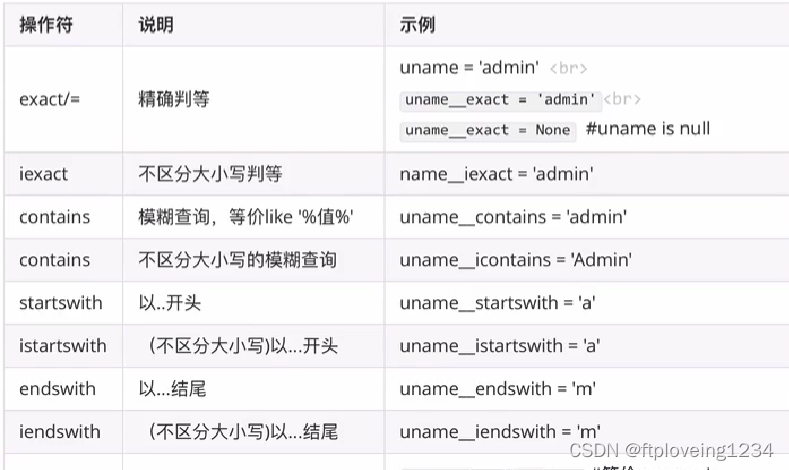
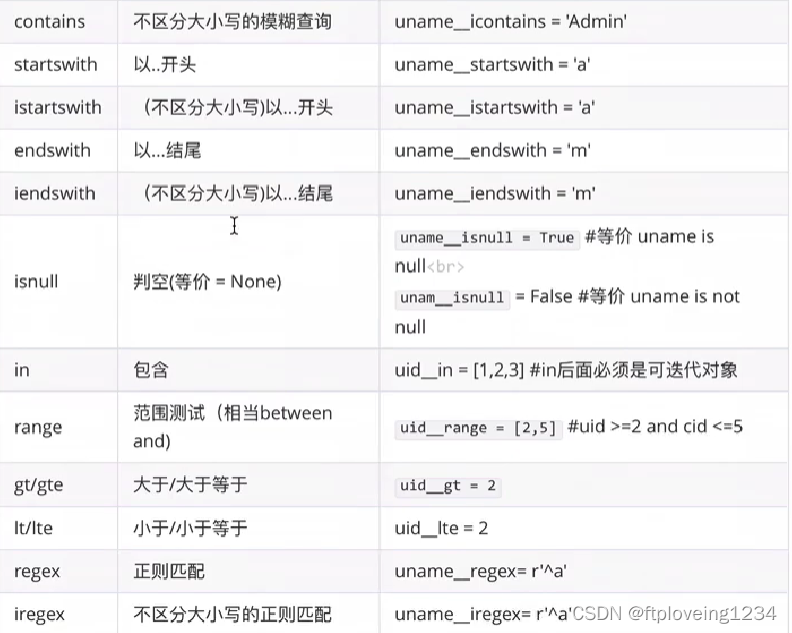
判断某个字段的值是否为空
# 查询money为空的结果
User.objects.filter(money__isnull=True)
# 返回结果
<QuerySet [<User: User object (4)>]>
精确判等
User.objects.filter(money__exact="100")
模糊查询
User.objects.filter(username__contains="h")
查询在区间范围内的数据
User.objects.filter(money_range=[90,200])
日期查询
# 查询年份
User.objects.filter(create_time__year=2023)
统计查询
使用aggregate方法进行聚合查询,不分组统计查询数据
- Max
# 查询到id的最大值
User.objects.aggregate(Max('pk'))
使用annotate方法进行分组统计查询数据
原生sql
User.objects.raw("select * from tb_users ")
# 返回结果
<RawQuerySet: select * from tb_users >
模型关系
一对一
外键设置在哪一方都可以,通过OneToOneField关键字设置关联关系
一对多
一般是将主表中的主键放到从表中做外键,外键一般是一对多中多的一方设置,通过ForeignKey关键字设置
class BookModel(models.Model):# 主表name =models.CharField(max_length=50,verbose_name="书名")price=models.IntegerField(verbose_name="价格")pub_date = models.DateField(verbose_name="时间")# 从主表查询从表的名字是通过related_name取的pub=models.ForeignKey('Publish',on_delete=models.CASCADE,related_name="books",null=True)
class Publish(models.Model):# 从表name=models.CharField(max_length=100)
从表操作主表,是通过在从表定义的外键进行操作的,对主表进行增删改查
# 修改从表中外键的值book = BookModel.objects.get(pk=2)pub1 = Publish.objects.get(pk=1)book.pub=pub1 # 修改从表中外键的值,且外键的值pub1必须是一个对象book.save()
通过主表操作从表,利用在从表中定义的related_name的值操作从表,对从表进行增删改查
# 通过主表操作从表,给从表新增数据# 通过出版社操作图书pub = Publish.objects.get(pk=2)# 给pk=2增加几本书pub.books.create(name="fds11",price=22,pub_date='2023-09-01')
# 通过主表操作从表,更新从表中的数据# 通过出版社操作图书pub = Publish.objects.get(pk=2)# 给pk=2增加几本书pub.books.update(name="娃哈哈",price=22,pub_date='2023-09-01')
book = BookModel.objects.get(pk=2)print(book.pub) # Publish object (1)# book.pub是Publish的对象
# 通过主表查询从表pub = Publish.objects.get(pk=2)# pub-books是一个查询管理器对象book = pub.books.all()
# 以从表字段作为过滤条件,查询主表中的数据
pub = Publish.objects.filter(books__name="娃哈哈")
# 返回查询结果
<QuerySet [<Publish: Publish object (2)>, <Publish: Publish object (2)>]>
多对多
通过ManyToManyField关键字设置多对多关系(商品和客户间的关系是多对多的关系)
注:一般要手动创建第三张表用来关联多对多的两张表
class Buyer(models.Model):name = models.CharField(max_length=50)leve = models.IntegerField(default=1)class Meta:db_table = "tb_buyer"class Goods():name = models.CharField(max_length=50, verbose_name="名")price = models.IntegerField(verbose_name="价格")class Meta:db_table = "tb_goods"# 多对多的关联的第三张表
class Order():buyer = models.ForeignKey("Buyer",on_delete=models.CASCADE)goods = models.ForeignKey("Goods", on_delete=models.CASCADE)num = models.IntegerField(default=1)class Meta:db_table="tb_order"
相关文章:
Django的模型
定义模型 from django.db import models class User(models.Model):# 类属性是表示表的字段username models.CharField(max_length50,uniqueTrue)password models.CharField(max_length200)create_time models.DateTimeField(auto_now_addTrue) # auto_now_add新增数据时间…...

非计算机科班如何丝滑转码
近年来,很多人想要从其他行业跳槽转入计算机领域。非计算机科班如何丝滑转码? 方向一:如何规划才能实现转码? 对于非计算机科班的人来说,想要在计算机领域实现顺利的转码并不是一件容易的事情,但也并非不…...

PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(12)——数据增强 0. 前言1. 图像增强1.1 仿射变换1.2 亮度修改1.3 添加噪音1.4 联合使用多个增强方法 2. 对批图像执行图像增强3. 利用数据增强训练模型小结系列链接 0. 前言 数据增强是指通过对原始数据进行一系列变换和处理&…...
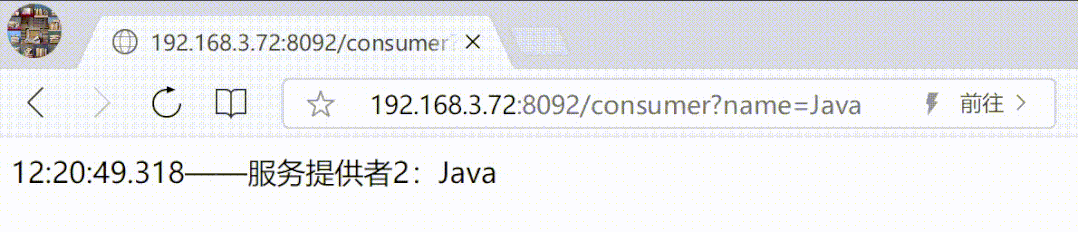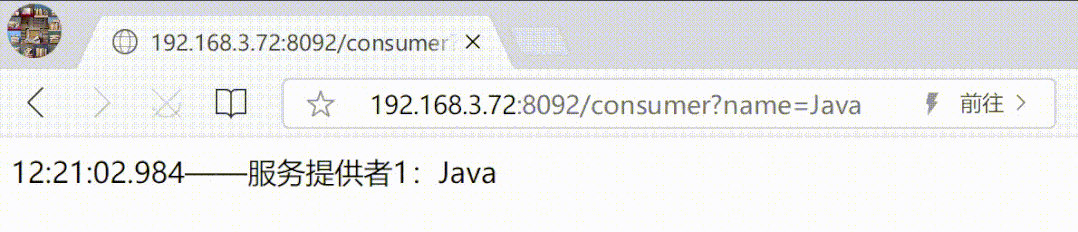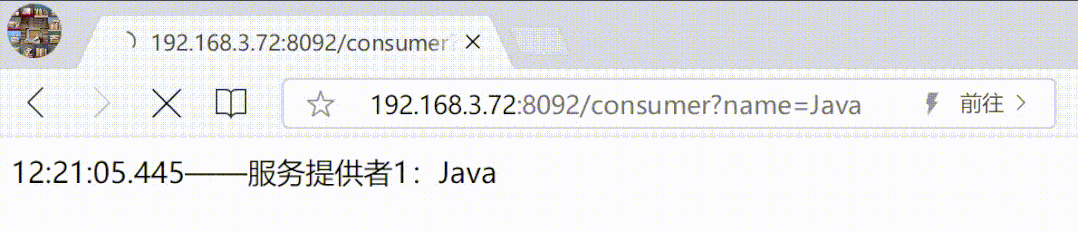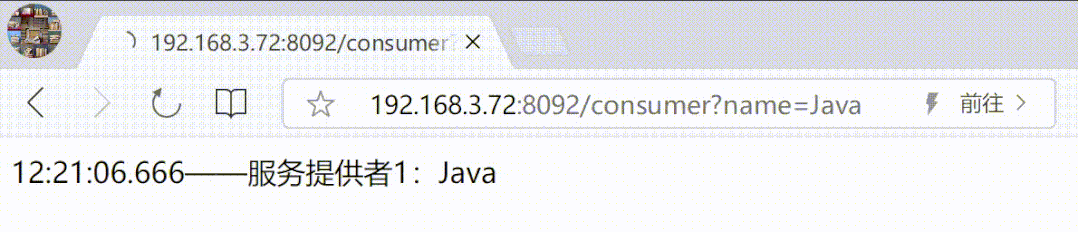
SpringCloud Ribbon中的7种负载均衡策略
SpringCloud Ribbon中的7种负载均衡策略 Ribbon 介绍负载均衡设置7种负载均衡策略1.轮询策略2.权重策略3.随机策略4.最小连接数策略5.重试策略6.可用性敏感策略7.区域敏感策略 总结 负载均衡通器常有两种实现手段,一种是服务端负载均衡器,另一种是客户端…...
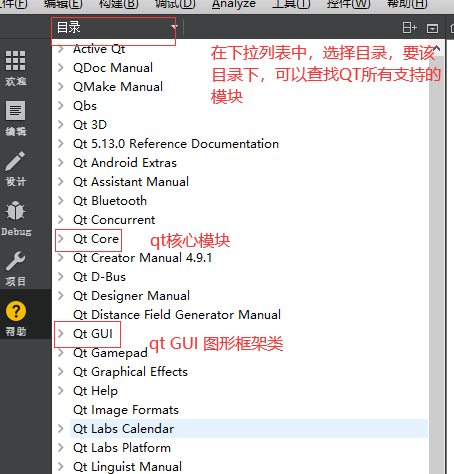
04 qt功能类、对话框类和文件操作
一 QT中时间和日期 时间 ---- QTime日期 ---- QDate对于Qt而言,在实际的开发过程中, 1)开发者可能知道所要使用的类 ---- >帮助手册 —>索引 -->直接输入类名进行查找 2)开发者可能不知道所要使用的类,只知道开发需求文档 ----> 帮助 手册,按下图操作: 1 …...
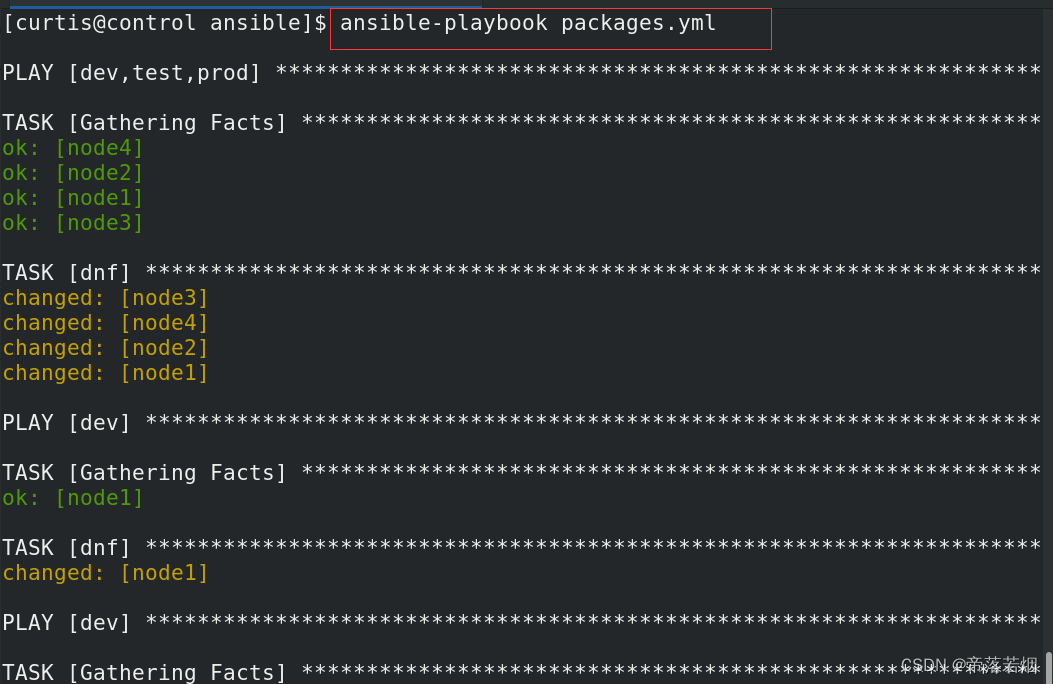
安装软件包
安装软件包 创建一个名为 /home/curtis/ansible/packages.yml 的 playbook : 将 php 和 mariadb 软件包安装到 dev、test 和 prod 主机组中的主机上 将 RPM Development Tools 软件包组安装到 dev 主机组中的主机上 将 dev 主机组中主机上的所有软件包更新为最新版本 vim packa…...

玩转单元测试之gmock
引言 前文我们学习了gtest相关的使用,单靠gtest,有些场景仍然无法进行测试,因此就诞生了gmock。 gmock快速入门 在引入gtest时,gmock也同样引入了,因此只需要在编译时加上合适的编译选项即可,注意不同版…...

POI与EasyExcel--写Excel
简单写入 03和07版的简单写入注意事项: 1. 对象不同:03对应HSSFWorkbook,07对应XSSFWorkbook 2. 文件后缀不同:03对应xls,07对应xlsx package com.zrf;import org.apache.poi.hssf.usermodel.HSSFWorkbook; import …...
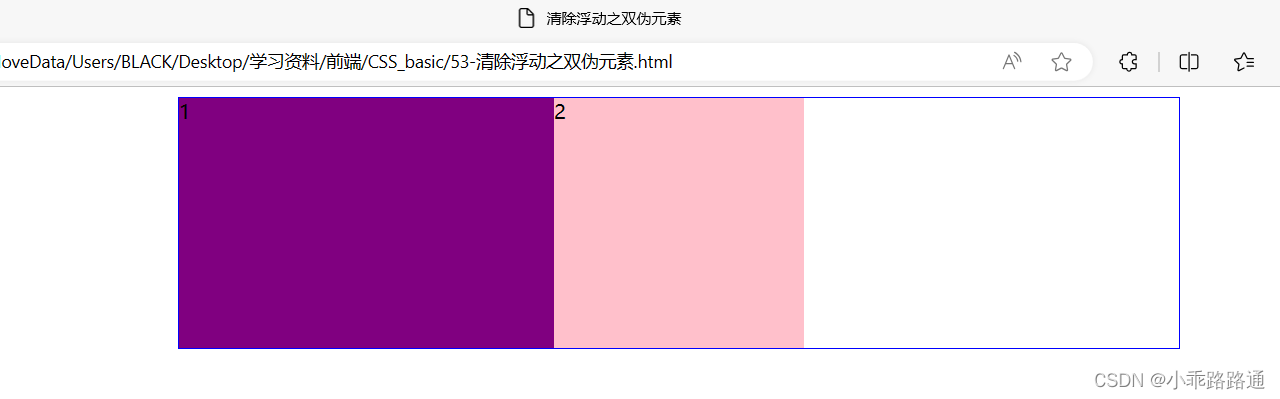
7. CSS(四)
目录 一、浮动 (一)传统网页布局的三种方式 (二)标准流(普通流/文档流) (三)为什么需要浮动? (四)什么是浮动 (五)浮…...

uni-app 集成推送
研究了几天,终于是打通了uni-app的推送,本文主要针对的是App端的推送开发过程,分为在线推送和离线推送。我们使用uni-app官方推荐的uni-push2.0。官方文档 准备工作:开通uni-push功能 勾选uniPush2.0点击"配置"填写表单…...

Spring Boot+Redis 实现消息队列实践示例
Spring BootRedis 实现一个轻量级的消息队列 文章目录 Spring BootRedis 实现一个轻量级的消息队列0.前言1.基础介绍2.步骤2.1. 引入依赖2.2. 配置文件2.3. 核心源码 4.总结答疑 5.参考文档6. Redis从入门到精通系列文章 0.前言 本文将介绍如何利用Spring Boot与Redis结合实现…...
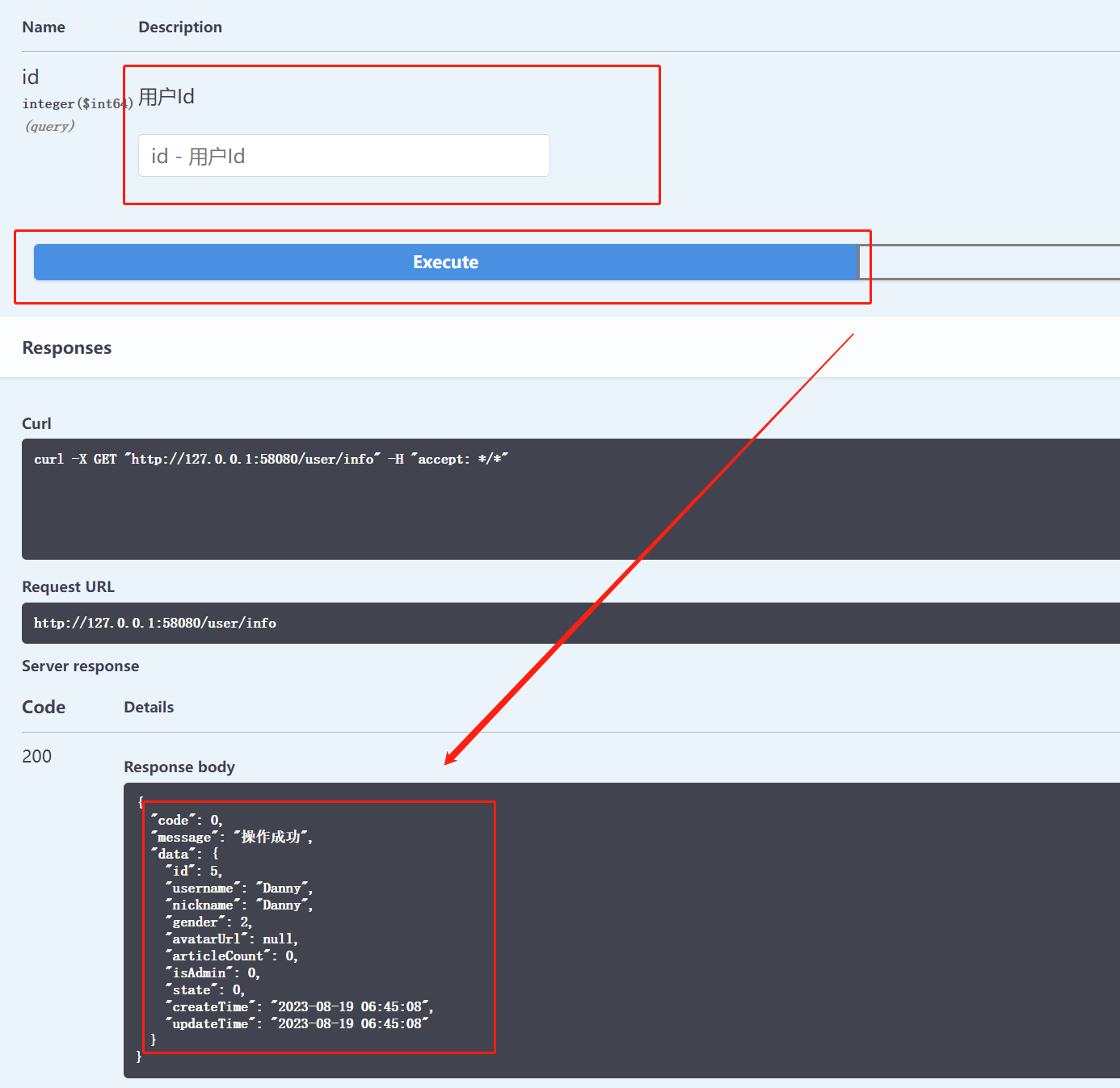
11. 实现业务功能--获取用户信息
目录 1. 实现 Controller 2. 单体测试 3. 修复返回值存在的缺陷 3.1 用户的隐私数据:密码的密文和盐不能显示 3.2 将值为 null 的字段可以进行过滤 3.3 时间的格式需要进行处理,如 yyyy-mmmm-ddd HH:mm:ss 3.4 data 属性没有返回 4. 实现前端页…...
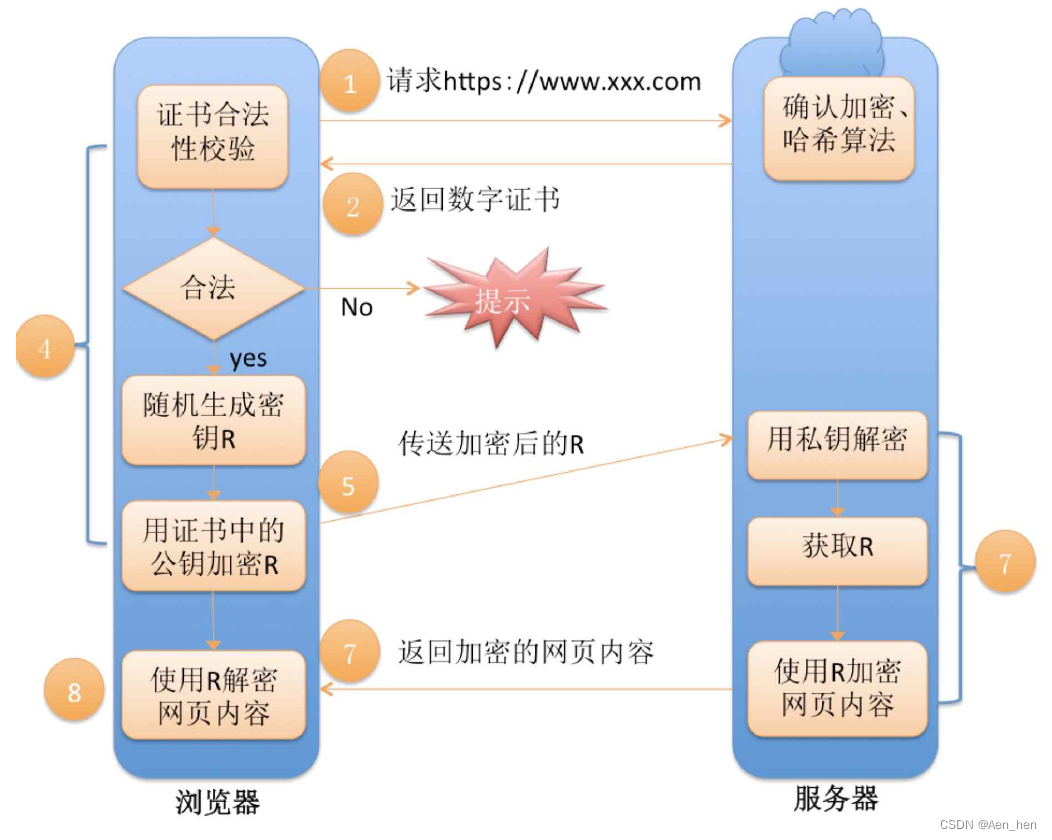
HTTPS
HTTPS是什么 HTTPS 属于应用层协议,其原理是通过SSL/TLS协议在HTTP和TCP之间插入一层安全机制。通过SSL/TLS握手过程,客户端和服务器协商出一个对称密钥,用于后续的数据加密和解密,从而保证数据的机密性和完整性。 为什么会需要…...

spring详解
spring是于2003年兴起的一款轻量级的,非侵入式的IOC和AOP的一站式的java开发框架,为简化企业级应用开发而生。 轻量级的:指的是spring核心功能的jar包不大。 非侵入式的:业务代码不需要继承或实现spring中任何的类或接口 IOC&…...

香港服务器备案会通过吗?
对于企业或个人来说,合规备案是网络运营的基本要求,也是保护自身权益的重要举措。以下内容围绕备案展开话题,希望为您解开疑惑。 香港服务器备案会通过吗? 目前,香港服务器无法备案,这是由于国内管理规定的限制…...

乐鑫推出 ESP ZeroCode 控制台
乐鑫科技 ESP ZeroCode 控制台是一个网页应用,用户只需点击鼠标,描述想要创建的产品类型、功能及其硬件配置,即可按照自身需求,快速生成符合 Matter 认证的固件,并在硬件上进行试用。试用过程中,如有任何不…...

从NLP到聊天机器人
一、说明 今天,当打电话给银行或其他公司时,听到电话另一端的机器人向你打招呼是很常见的:“你好,我是你的数字助理。请问你的问题。是的,机器人现在不仅可以说人类语言,还可以用人类语言与用户互动。这是由…...
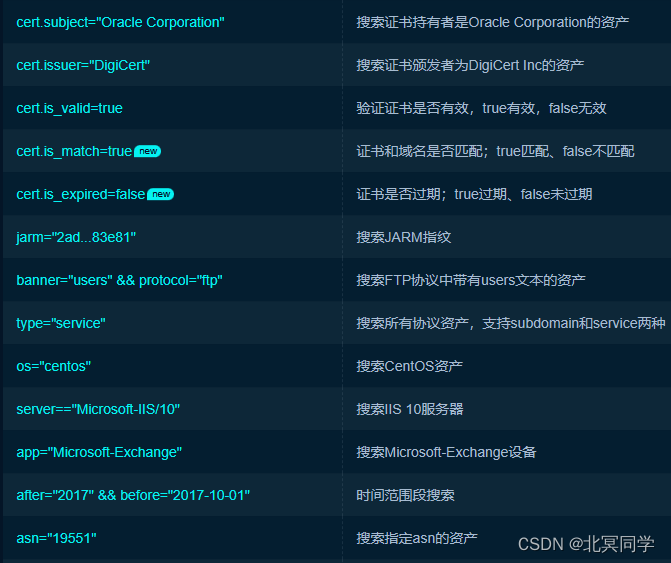
相关搜索引擎常用搜索语法(Google hacking语法和FOFA语法)
一:Google Hack语法 Google Hacking原指利用Google搜索引擎搜索信息来进行入侵的技术和行为,现指利用各种搜索引擎并使用一些高级的搜索语法来搜索信息。既利用搜索引擎强大的搜索功能,在在浩瀚的互联网中搜索到我们需要的信息。 ࿰…...

Mysql查询
第三章:select 语句 SELECT employees.employee_id,employees.department_id FROM employees WHERE employees.employee_id176; DESC departments;SELECT * FROM departments;第四章:运算符使用 SELECT employees.last_name,employees.salary FROM em…...

解决http下navigator.clipboard为undefined问题
开发环境下使用navigator.clipboard进行复制操作,打包部署到服务器上后,发现该功能显示为undefined;查相关资料后,发现clipboard只有在安全域名下才可以访问(https、localhost),在http域名下只能得到undefined…...

TigerVNC终极指南:快速掌握跨平台远程桌面控制
TigerVNC终极指南:快速掌握跨平台远程桌面控制 【免费下载链接】tigervnc High performance, multi-platform VNC client and server 项目地址: https://gitcode.com/gh_mirrors/ti/tigervnc TigerVNC是一款高性能、跨平台的VNC客户端和服务器软件࿰…...

通过Taotoken模型广场为不同视频类型选择合适的生成模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken模型广场为不同视频类型选择合适的生成模型 为视频内容生成高质量的文本描述、脚本或字幕,是许多创作者和…...

在新磁盘挂载点/data安装codex
实例是 Oracle Cloud Always Free VM.Standard.E2.1.Micro Linux, /data 目录。 Codex CLI 官方支持用 npm 安装:npm i -g openai/codex,首次运行需要登录 ChatGPT 或配置 API key; 建议:Codex 安装到 /data;bubblewr…...

OpenClaw 如何实现任务恢复与失败重试?
网罗开发(小红书、快手、视频号同名)大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等方…...

为ae做片段视频项目配置专属AI模型并控制成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为AE做片段视频项目配置专属AI模型并控制成本 对于小型视频工作室或独立制作人而言,在After Effects等工具中处理大量视…...

云雾栖茶山,在云顶山读懂一片茶叶的蜕变旅程
位于福建省安溪县西坪镇的云顶山茶园,是一处融合了茶叶种植与传统制茶工艺的生态旅游区。该区域海拔约800米,常年云雾缭绕,土壤富含矿物质,为茶树生长提供了适宜的自然条件。景区以乌龙茶种植为核心,围绕“从叶片到茶杯…...

STM32F103C8T6与DHT11单总线通信:从时序解析到数据校验的实战指南
1. 认识STM32F103C8T6与DHT11这对黄金搭档 第一次接触嵌入式开发的朋友可能会觉得,让单片机读取温湿度数据是个复杂的事情。但当你用STM32F103C8T6这颗性价比超高的Cortex-M3内核芯片,搭配DHT11这个经典温湿度传感器时,事情就变得简单多了。…...

3个步骤解决Mac Boot Camp驱动部署难题:Brigadier自动化方案详解
3个步骤解决Mac Boot Camp驱动部署难题:Brigadier自动化方案详解 【免费下载链接】brigadier Fetch and install Boot Camp ESDs with ease. 项目地址: https://gitcode.com/gh_mirrors/bri/brigadier 还在为Mac电脑安装Windows系统后的驱动问题而烦恼吗&…...

智能产品系统架构分析 - 智能办公系统架构分层
方向:方案分析、架构设计、模块分解 智能产品系统架构分析:智能办公系统架构分层。 对智能办公系统进行架构分层分析,给出实例、UML建模、项目结构等。 “智能产品系统架构分析:智能办公系统架构分层”。 包含设备控制、预约管…...

现代差旅电力管理实战:从充电安全到设备续航全攻略
1. 一次久违的飞行:无处不在的电力焦虑与科技依赖距离上一次飞行已经过去了整整十七个月。当我上周踏入纽约拉瓜迪亚机场,准备开启后疫情时代的首次旅程时,感觉像是进入了另一个维度。在我缺席的这段时间里,LGA完成了一场彻底的蜕…...