ElasticSearch 数据聚合、自动补全(自定义分词器)、数据同步
文章目录
- 数据聚合
- 一、聚合的种类
- 二、DSL实现聚合
- 1、Bucket(桶)聚合
- 2、Metrics(度量)聚合
- 三、RestAPI实现聚合
- 自动补全
- 一、拼音分词器
- 二、自定义分词器
- 三、自动补全查询
- 四、实现搜索款自动补全(例酒店信息)
- 数据同步
- 双写一致性
数据聚合
一、聚合的种类
官方文档 => 聚合 https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html
聚合:对文档信息的统计、分类、运算。类似mysql sum、avg、count
- 桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组(相当于mysql group by)
- Date Histogram:按照日期阶梯分组,例如一周一组,一月一组
- 度量(metric)聚合:用来计算一些值,最大值、平均值、最小值等。
- Avg:平均值
- Max:最大值
- Min:最小值
- Stats:同时求max、min、avg、sum等
- 管道(pipeline)聚合:以其他聚合结果为基础继续做集合
二、DSL实现聚合
1、Bucket(桶)聚合

_count:默认是按照文档数量的降序排序
GET /hotel/_search
{"size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","size": 20,"order": {"_count": "asc"}}}}
}
上面使用的bucket聚合,会扫描索引库所有的文档进行聚合。可以限制扫描的范围:利用query条件即可。
GET /hotel/_search
{"query": {"range": {"price": {"lt": 200 # 只对价位低于200的聚合}}}, "size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","size": 20,"order": {"_count": "asc"}}}}
}
2、Metrics(度量)聚合

聚合的嵌套,先对外层进行聚合,在对内存进行聚合
注意嵌套查询:写在外层查询括号内,而非并立。
GET /hotel/_search
{"size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","size": 10,"order": {"scoreAgg.avg": "asc"}},"aggs": {"scoreAgg": {"stats": {"field": "score"}}}}}
}三、RestAPI实现聚合

bucket trem聚合(group by),实现品牌、星级、城市聚合的方法
public Map<String, List<String>> filters(RequestParam requestParam) {String[] aggNames = new String[]{"brand","city","starName"};Map<String, List<String>> resultMap = new HashMap<>();SearchRequest searchRequest = new SearchRequest("hotel");// 限定聚合范围BoolQueryBuilder boolQueryBuilder = getBoolQueryBuilder(requestParam);searchRequest.source().query(boolQueryBuilder);// 聚合字段searchRequest.source().size(0);searchRequest.source().aggregation(AggregationBuilders.terms(aggNames[0]).field("brand").size(100));searchRequest.source().aggregation(AggregationBuilders.terms(aggNames[1]).field("city").size(100));searchRequest.source().aggregation(AggregationBuilders.terms(aggNames[2]).field("starName").size(100));try {SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);Aggregations aggregations = searchResponse.getAggregations();for (String aggName : aggNames) {Terms terms = aggregations.get(aggName);List<String> list = new ArrayList<>();for (Terms.Bucket bucket : terms.getBuckets()) {list.add(bucket.getKeyAsString());}resultMap.put(aggName,list);}return resultMap;} catch (IOException e) {e.printStackTrace();return null;}}
自动补全
一、拼音分词器

下载拼音分词器:https://github.com/medcl/elasticsearch-analysis-pinyin/releases/tag/v8.6.0
解压放在plugins目录下(docker挂载的目录),然后重启es

二、自定义分词器


拼音分词器的过滤规则,参照上面下载的链接。
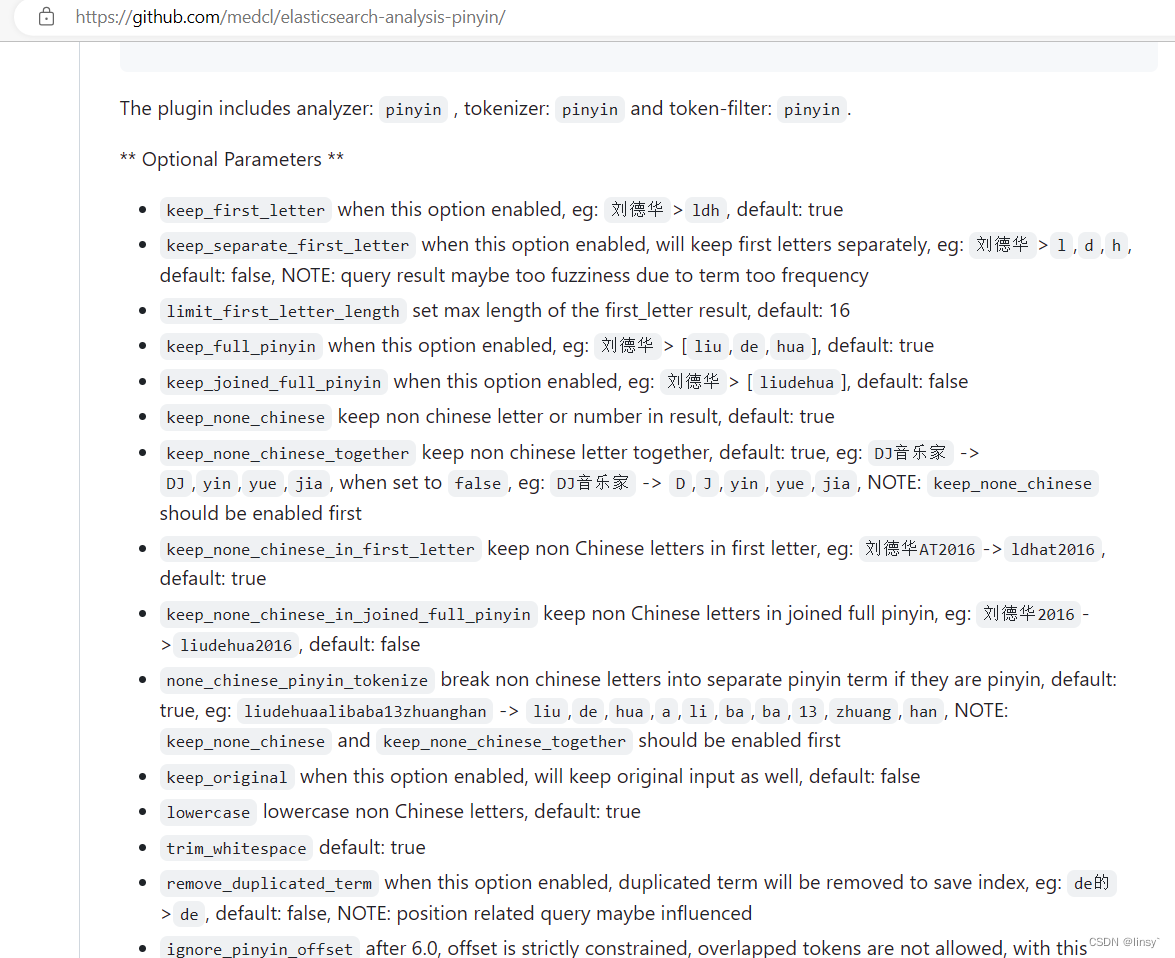
创建一个自定义分词器(text index库),分词器名:my_analyzer
// 自定义拼音分词器 + mapping约束
PUT /test
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}
三、自动补全查询
completion suggester查询:
- 字段类型必须是completion
- 字段值是多词条的数组才有意义

// 自动补全的索引库
PUT test2
{"mappings": {"properties": {"title":{"type": "completion"}}}
}
// 示例数据
POST test2/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{"title": ["Nintendo", "switch"]
}// 自动补全查询
POST /test2/_search
{"suggest": {"title_suggest": {"text": "s", // 关键字"completion": {"field": "title", // 补全字段"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
四、实现搜索款自动补全(例酒店信息)

在这里插入代码片
构建索引库
// 酒店数据索引库
PUT /hotel
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}
查询测试
GET /hotel/_search
{"query": {"match_all": {}}
}GET /hotel/_search
{"suggest": {"YOUR_SUGGESTION": {"text": "s","completion": {"field": "suggestion","skip_duplicates": true // 跳过重复的}}}
}


public List<String> getSuggestion(String prefix) {SearchRequest request = new SearchRequest("hotel");ArrayList<String> list = new ArrayList<>();try {request.source().suggest(new SuggestBuilder().addSuggestion("OneSuggestion",SuggestBuilders.completionSuggestion("suggestion").prefix(prefix).skipDuplicates(true).size(10)));SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);Suggest suggest = response.getSuggest();CompletionSuggestion oneSuggestion = suggest.getSuggestion("OneSuggestion");List<CompletionSuggestion.Entry.Option> options = oneSuggestion.getOptions();for (CompletionSuggestion.Entry.Option option : options) {String text = option.getText().toString();list.add(text);}} catch (IOException e) {e.printStackTrace();}return list;}
数据同步
双写一致性
同步调用数据耦合,业务耦合

异步通知:增加实现难度

监听binlog(记录增删改操作):增加mysql压力,中间价搭建
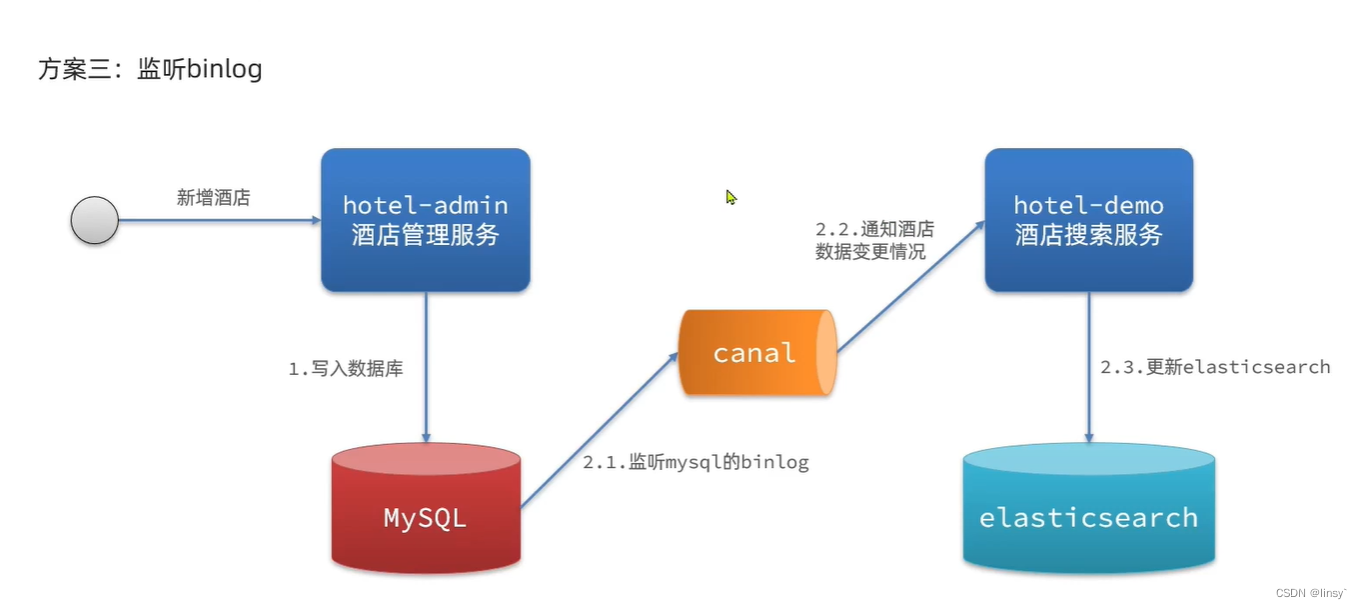
相关文章:
ElasticSearch 数据聚合、自动补全(自定义分词器)、数据同步
文章目录 数据聚合一、聚合的种类二、DSL实现聚合1、Bucket(桶)聚合2、Metrics(度量)聚合 三、RestAPI实现聚合 自动补全一、拼音分词器二、自定义分词器三、自动补全查询四、实现搜索款自动补全(例酒店信息࿰…...

神经网络基础-神经网络补充概念-18-多个样本的向量化
概念 多个样本的向量化通常涉及将一组样本数据组织成矩阵形式,其中每一行代表一个样本,每一列代表样本的特征。这种向量化可以使你更有效地处理和操作多个样本,特别是在机器学习和数据分析中。 代码实现 import numpy as np# 多个样本的数…...

*看门狗1
//while部分是我们在项目中具体需要写的代码,这部分的程序可以用独立看门狗来监控 //如果我们知道这部分代码的执行时间,比如是500ms,那么我们可以设置独立看门狗的 //溢出时间是600ms,比500ms多一点,如果要被监控的程…...
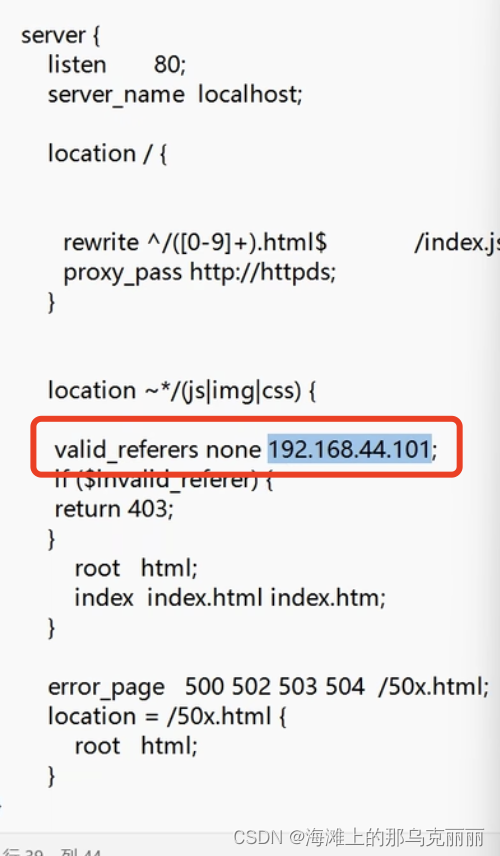
nginx防盗链
防盗链介绍 通过二次访问,请求头中带有referer,的方式不允许访问静态资源。 我们只希望用户通过反向代理服务器才可以拿到我们的静态资源,不希望别的服务器通过二次请求拿到我们的静态资源。 盗链是指在自己的页面上展示一些并不在自己服务…...
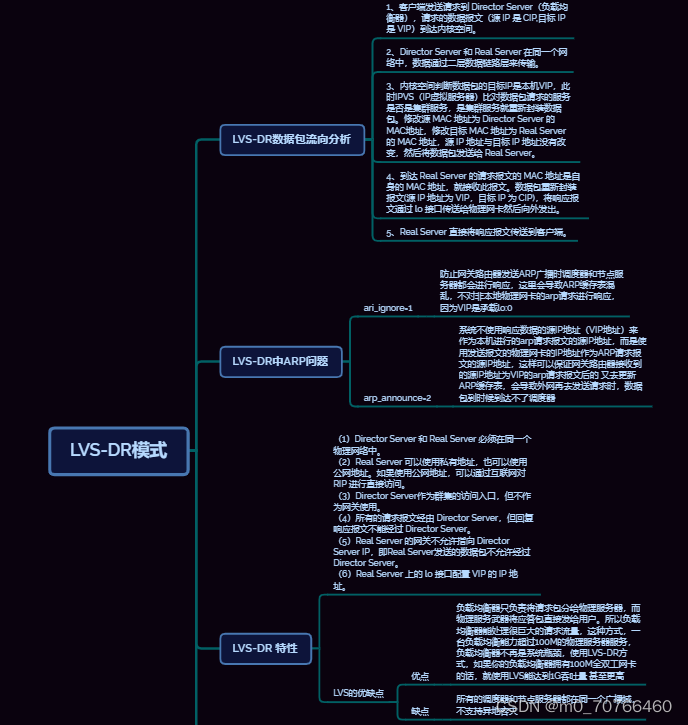
8月16日上课内容 第二章 部署LVS-DR群集
本章结构: 数据包流向分析: 数据包流向分析: (1)客户端发送请求到 Director Server(负载均衡器),请求的数据报文(源 IP 是 CIP,目标 IP 是 VIP)到达内核空间。 …...
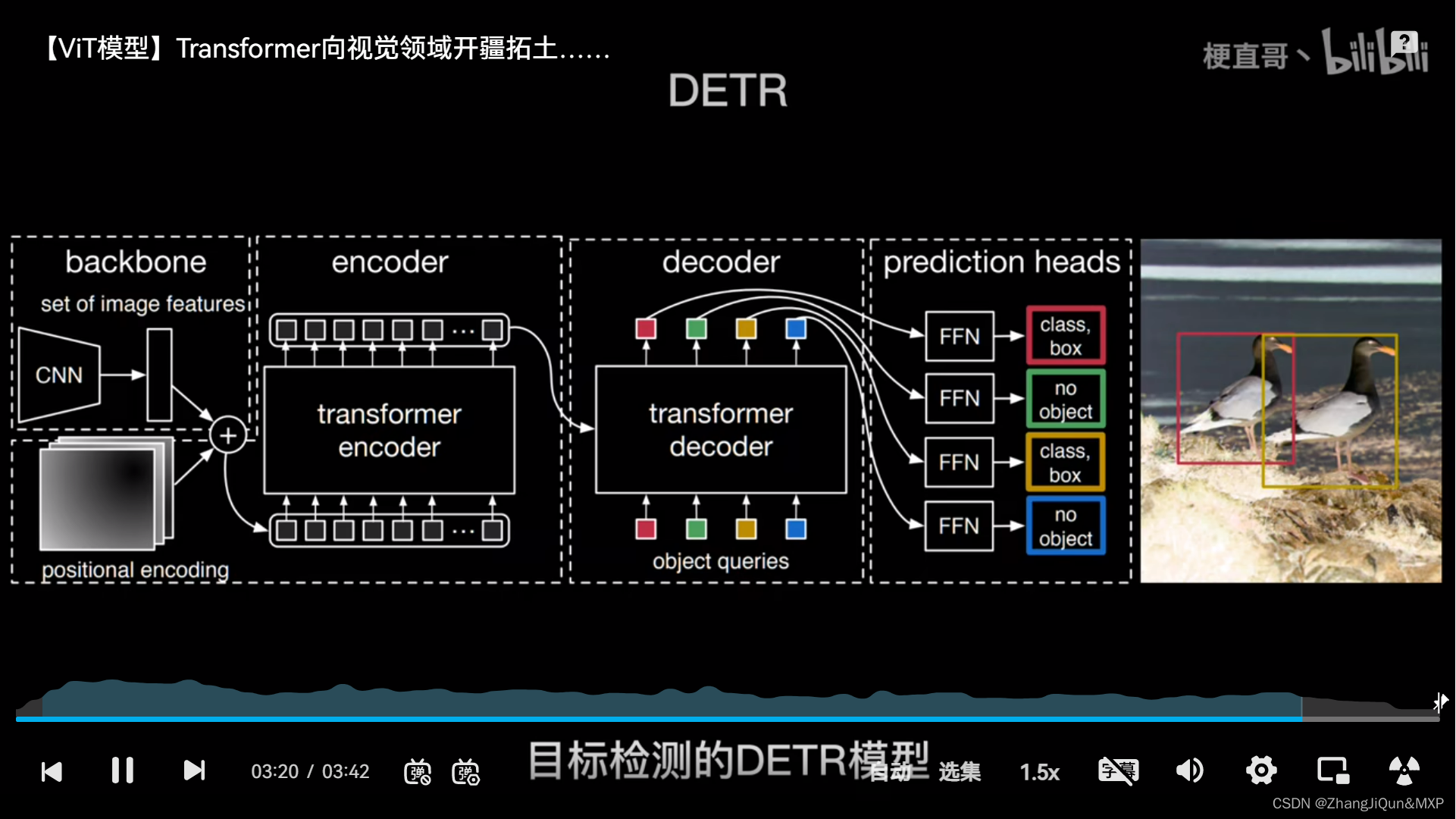
ViT模型架构和CNN区别
目录 Vision Transformer如何工作 ViT模型架构 ViT工作原理解析 步骤1:将图片转换成patches序列 步骤2:将patches铺平 步骤3:添加Position embedding 步骤4:添加class token 步骤5:输入Transformer Encoder 步…...
发布python模仿2023年全国职业的移动应用开发赛项样式开发的开源的新闻api,以及安卓接入案例代码
python模仿2023年全国职业的移动应用开发赛项样式开发的开源的新闻api,以及原生安卓接入案例代码案例 源码地址:keyxh/newsapi: python模仿2023年全国职业的移动应用开发赛项样式开发的开源的新闻api,以及安卓接入案例代码 (github.com) 目录 1.环境配…...

adb command
查看屏幕分辨率 adb shell wm size 查看dpi adb shell dumpsys window | grep ‘dpi’ WIFI调试: adb tcpip 5555adb connect 设备ip 注意,USB拔插会断掉,所以插上USB后再 adb connect 设备ip。【注意】华为手机自建热点的ip一般是192.1…...
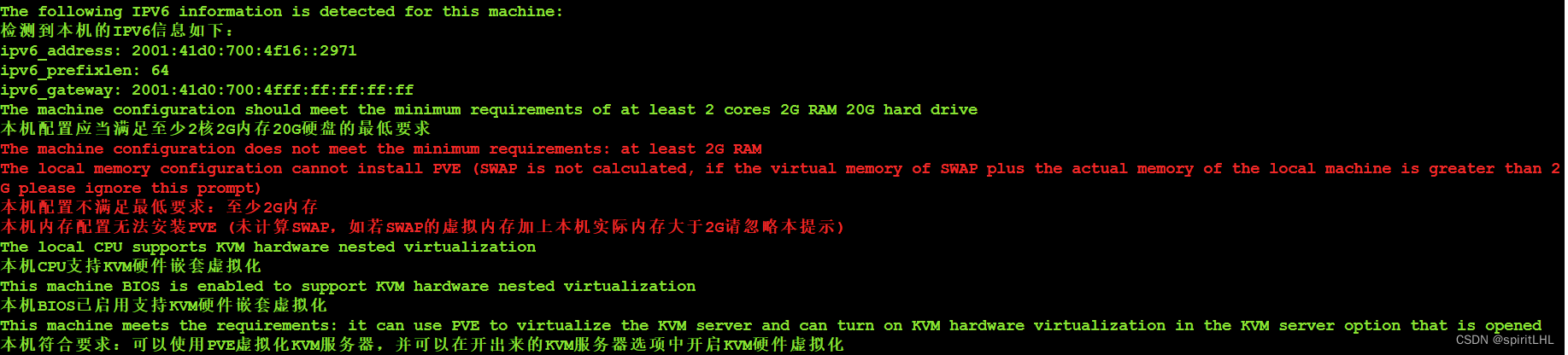
在ARM服务器上一键安装Proxmox VE(以在Oracle Cloud VPS上为例)(甲骨文)
前言 如题,具体用到的说明文档如下 virt.spiritlhl.net 具体流程 首先是按照说明,先得看看自己的服务器符不符合安装 Proxmox VE的条件 https://virt.spiritlhl.net/guide/pve_precheck.html#%E5%90%84%E7%A7%8D%E8%A6%81%E6%B1%82 有提到硬件和软…...
)
KMP算法(JS)
KMP算法 什么时KMP算法 KMP算法是一种改进的字符串匹配算法 由D.E.Knuth,J.H.Morris和 V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。 KMP的主要思想是当出现字符串不匹配时,可以知道…...
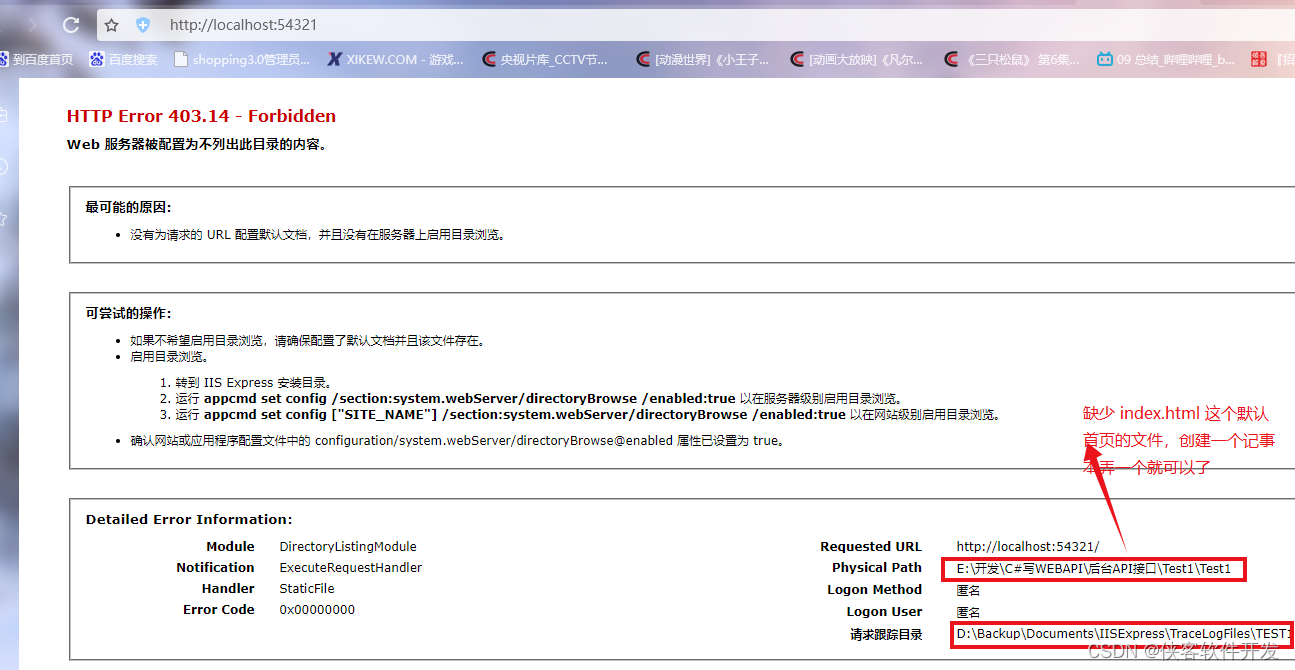
恢复NuGet包_解决:System.BadImageFormatException:无法加载文件或程序集
C#工程 主要是开发了一个 web api接口,这个工程源码去年还可以的,今年换了一个电脑打开工程就报错。 错误提示如下: 在 Microsoft.CodeAnalysis.CSharp.CommandLine.Program.Main(String[] args) Test1 System.BadImageFormatEx…...
Django学习笔记(2)
创建app 属于自动执行了python manage.py 直接在里面运行startapp app01就可以创建app01的项目了 之后在setting.py中注册app01 INSTALLED_APPS ["django.contrib.admin","django.contrib.auth","django.contrib.contenttypes","django.c…...

高德地图开发者平台Python应用实践:快速入门周边商业环境信息查询
高德地图开发平台提供了丰富的API接口,可以方便地进行地图数据的开发和分析。在商业分析数据采集中,使用高德地图开发平台的周边查询功能可以快速获取周边商圈、小区等信息,为商业决策提供数据支持。 针对您的需求,我建议采用以下…...

【ES6】—let 声明方式
一、不属于顶层对象window let 关键字声明的变量,不会挂载到window的属性 var a 5 console.log(a) console.log(window.a) // 5 // 5 // 变量a 被挂载到window属性上了 , a window.alet b 6 console.log(b) console.log(window.b) // 6 // undefin…...

【数据分析入门】Jupyter Notebook
目录 一、保存/加载二、适用多种编程语言三、编写代码与文本3.1 编辑单元格3.2 插入单元格3.3 运行单元格3.4 查看单元格 四、Widgets五、帮助 Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。 …...

反射知识总结
1、反射概述 反射是指对于任何一个Class类,在"运行的时候"都可以直接得到这个类全部成分。在运行时,可以直接得到这个类的构造器对象:Constructor在运行时。可以直接得到这个类的成员变量对象:Field在运行时,…...
MongoDB 安装 linux
本文介绍一下MongoDB的安装教程。 系统环境:CentOS7.4 可以用 cat /etc/redhat-release 查看本机的系统版本号 一、MongoDB版本选择 当前最新的版本为7.0,但是由于7.0版本安装需要升级glibc2.25以上,所以这里我暂时不安装该版本。我们选择的是6.0.9版本…...
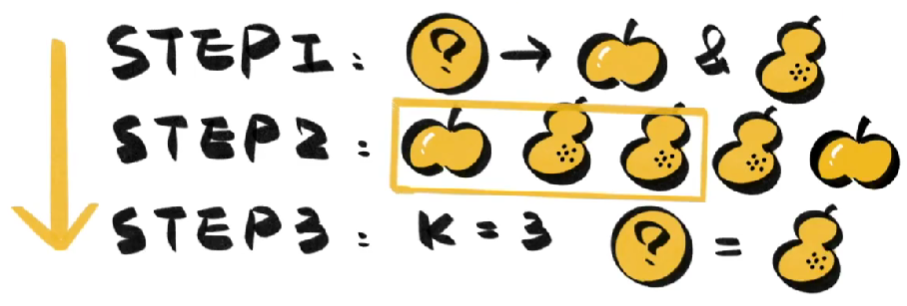
什么是KNN( K近邻算法)
什么是KNN( K近邻算法) 虽然名字中有NN,KNN并不是哪种神经网络,它全名K-Nearest-Neighbors:K近邻算法,是机器学习中常用的分类算法。 物以类聚,人以群分。KNN的基础思想很简单,要判断一个新数据的类别&…...

Linux查看命令总结
1.动态实时查找命令 使用以下命令的前提是需要在找到日志位置 tail -f server.log 实时展示日志末尾内容,默认最后10行,相当于增加参数 -n 10 tail -n filename; tail命令扩展 查看日志最后20行内容并实时更新日志 tail -f -n 20 server.log或者 tail -fn 20 ser…...

npm报错 Cannot find module ‘@vuepress\core\node_m
通常是由于缺少依赖包或者依赖包版本不兼容引起的。可以尝试以下步骤来解决这个问题: 确保您的项目的依赖包是最新的,可以运行 npm update 命令来更新依赖包。 如果更新依赖包后仍然有问题,可以尝试删除 node_modules 文件夹,并重…...

终极CFP管理指南:developers.events如何帮助您提交演讲申请
终极CFP管理指南:developers.events如何帮助您提交演讲申请 【免费下载链接】developers-conferences-agenda developers.events is a community-driven platform listing developer/tech conferences and Calls for Papers (CFPs) worldwide with a list, a calend…...

终极指南:如何用Chromatic快速掌握Chromium/V8通用修改器
终极指南:如何用Chromatic快速掌握Chromium/V8通用修改器 【免费下载链接】chromatic Universal modifier for Chromium/V8 | 广谱注入 Chromium/V8 的通用修改器 项目地址: https://gitcode.com/gh_mirrors/be/chromatic 想象一下,你正在开发一个…...

基于Kubernetes Operator的企业级区块链网络自动化部署实践
1. 项目概述:企业级区块链的云原生部署方案如果你正在寻找一个能够将企业级区块链网络快速、稳定地部署到Kubernetes集群上的成熟方案,那么ConsenSys开源的quorum-kubernetes项目绝对值得你花时间深入研究。这个项目不是一个简单的概念验证,而…...

2026届最火的十大AI辅助写作平台解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下这个学术环境当中,AI辅助论文的写作已然变成了一种具备高效性的工具。借助…...
)
给IPC相机调图像,别再瞎调了!一份保姆级的ISP线性模式调试顺序图(附避坑要点)
IPC相机图像调试实战指南:从线性模式到专业级画质优化 刚接触IPC相机图像调试的工程师们,常常会陷入参数迷宫——面对AE、AWB、Gamma、3DNR等数十个模块,该从何处入手?调试顺序的错误可能导致反复返工,甚至影响最终成像…...

Ctool架构深度解析:模块化开发工具集的高效实现方案
Ctool架构深度解析:模块化开发工具集的高效实现方案 【免费下载链接】Ctool 程序开发常用工具 chrome / edge / firefox / utools / windows / linux / mac 项目地址: https://gitcode.com/gh_mirrors/ct/Ctool 在程序开发过程中,开发者经常需要在…...
:核心抽象层 —— 块 、分区 、inode 从原理到实操)
【Linux 指南】文件系统系列(二):核心抽象层 —— 块 、分区 、inode 从原理到实操
上一篇我们吃透了磁盘的底层原理,搞懂了磁盘通过 CHS/LBA 寻址定位扇区,也知道扇区是磁盘硬件的最小读写单位(512 字节)。但随之而来的两个核心问题摆在眼前:一是逐个扇区读写磁盘效率极低,磁头的寻道和旋转…...
)
Chlorophyll印相稀缺资源包泄露!含19世纪银盐配方数字化映射表、327张原生植物扫描底片及MJ v6.2专用--style raw参数集(限今日领取)
更多请点击: https://intelliparadigm.com 第一章:Chlorophyll印相的技术起源与美学范式 Chlorophyll印相(叶绿素印相)并非传统摄影术的延伸,而是一种融合植物生物化学、光敏反应与数字图像处理的跨媒介实践。其技术雏…...

MyBatis如何实现动态数据源切换?
MyBatis如何实现动态数据源切换 在现代应用中,特别是微服务架构中,使用多个数据库的情况越来越常见。MyBatis是一个流行的Java持久层框架,它允许我们方便地与多种数据库进行交互。在某些情况下,我们可能需要动态切换数据源&#x…...
)
别再死记公式了!用Python+LTspice快速搞定LC滤波器设计(附仿真文件)
用PythonLTspice实现LC滤波器设计的工程化实践 在传统电子工程教学中,LC滤波器设计往往陷入繁琐的公式推导和手工计算泥潭。当学生终于理解完所有理论公式,准备动手实践时,却发现自己被复杂的参数计算和反复的电路调试所困扰。这种理论与实践…...