Unrecognized Hadoop major version number: 3.0.0-cdh6.3.2
一.环境描述
spark提交job到yarn报错,业务代码比较简单,通过接口调用获取数据,将数据通过sparksql将数据写入hive中,尝试各种替换hadoop版本,最后拿下
1.hadoop环境
2.项目 pom.xml
spark-submit \
--name GridCorrelationMain \
--master yarn \
--deploy-mode cluster \
--executor-cores 2 \
--executor-memory 4G \
--num-executors 5 \
--driver-memory 2G \
--class cn.zd.maincode.wangge.GridCorrelationMain \
/home/boeadm/zwj/iot/cp-etl-spark-data/target/cp_zhengda_spark_utils-1.0-SNAPSHOT.jareyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE2OTI0MzU5NjgsImlhdCI6MTY5MjM0OTU2Mywic3ViIjo1MjB9.rCmnhF2EhdzH62T7lP3nmxQSxh17PotscxEcZkjL5hk<dependencies><dependency><groupId>org.apache.commons</groupId><artifactId>commons-configuration2</artifactId><version>2.9.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.3.3</version><exclusions><exclusion><artifactId>hadoop-client</artifactId><groupId>org.apache.hadoop</groupId></exclusion><exclusion><artifactId>slf4j-log4j12</artifactId><groupId>org.slf4j</groupId></exclusion></exclusions></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.3.3</version><!--<scope>provided</scope>--><!-- <exclusions><exclusion><groupId>com.google.guava</groupId><artifactId>guava</artifactId></exclusion></exclusions>--></dependency><!--<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>15.0</version></dependency>
--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version><exclusions><exclusion><groupId>commons-codec</groupId><artifactId>commons-codec</artifactId></exclusion><exclusion><groupId>commons-httpclient</groupId><artifactId>commons-httpclient</artifactId></exclusion><!-- <exclusion><groupId>com.google.guava</groupId><artifactId>guava</artifactId></exclusion>--></exclusions><!--<scope>provided</scope>--></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version><exclusions><exclusion><artifactId>hadoop-common</artifactId><groupId>org.apache.hadoop</groupId></exclusion></exclusions></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.11</artifactId><version>2.3.2</version><exclusions><exclusion><artifactId>hive-exec</artifactId><groupId>org.spark-project.hive</groupId></exclusion><exclusion><artifactId>hive-metastore</artifactId><groupId>org.spark-project.hive</groupId></exclusion></exclusions></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><exclusions><exclusion><groupId>org.eclipse.jetty.aggregate</groupId><artifactId>jetty-all</artifactId></exclusion><exclusion><groupId>org.apache.hive</groupId><artifactId>hive-shims</artifactId></exclusion><exclusion><artifactId>hbase-mapreduce</artifactId><groupId>org.apache.hbase</groupId></exclusion><exclusion><artifactId>hbase-server</artifactId><groupId>org.apache.hbase</groupId></exclusion><exclusion><artifactId>log4j-slf4j-impl</artifactId><groupId>org.apache.logging.log4j</groupId></exclusion><exclusion><artifactId>slf4j-log4j12</artifactId><groupId>org.slf4j</groupId></exclusion></exclusions><version>2.1.1</version></dependency><!--服务验证相关依赖--><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.13</version><exclusions><exclusion><groupId>commons-codec</groupId><artifactId>commons-codec</artifactId></exclusion></exclusions><!--<scope>provided</scope>--></dependency><!--本地跑的话 需要这个jar--><dependency><groupId>commons-codec</groupId><artifactId>commons-codec</artifactId><version>1.15</version><!--<scope>provided</scope>--></dependency><dependency><groupId>com.typesafe</groupId><artifactId>config</artifactId><version>1.3.1</version></dependency><!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>${fastjson.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.json/json --><dependency><groupId>org.json</groupId><artifactId>json</artifactId><version>20160810</version></dependency><dependency><groupId>com.github.qlone</groupId><artifactId>retrofit-crawler</artifactId><version>1.0.0</version></dependency><dependency><groupId>com.oracle.database.jdbc</groupId><artifactId>ojdbc8</artifactId><version>12.2.0.1</version></dependency><!--mysql连接--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.40</version></dependency><dependency><groupId>javax.mail</groupId><artifactId>javax.mail-api</artifactId><version>1.5.6</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-email</artifactId><version>1.4</version></dependency></dependencies>3.项目集群提交报错
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.lookupRelation(SessionCatalog.scala:696)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.org$apache$spark$sql$catalyst$analysis$Analyzer$ResolveRelations$$lookupTableFromCatalog(Analyzer.scala:730)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.resolveRelation(Analyzer.scala:685)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$$anonfun$apply$8.applyOrElse(Analyzer.scala:715)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$$anonfun$apply$8.applyOrElse(Analyzer.scala:708)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$apply$1.apply(AnalysisHelper.scala:90)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$apply$1.apply(AnalysisHelper.scala:90)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:89)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:194)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$class.resolveOperatorsUp(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsUp(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$1.apply(AnalysisHelper.scala:87)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$1.apply(AnalysisHelper.scala:87)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:326)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:324)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:87)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:194)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$class.resolveOperatorsUp(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsUp(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$1.apply(AnalysisHelper.scala:87)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$1.apply(AnalysisHelper.scala:87)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:326)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:324)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:87)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:194)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$class.resolveOperatorsUp(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsUp(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.apply(Analyzer.scala:708)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.apply(Analyzer.scala:654)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:87)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:84)
at scala.collection.LinearSeqOptimized$class.foldLeft(LinearSeqOptimized.scala:124)
at scala.collection.immutable.List.foldLeft(List.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:76)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:76)
at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:127)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:121)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:106)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:105)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:201)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:105)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:78)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:651)
at cn.zd.maincode.wangge.GridCorrelationMain$.createDataFrameAndTempView(GridCorrelationMain.scala:264)
at cn.zd.maincode.wangge.GridCorrelationMain$.horecaGridInfo(GridCorrelationMain.scala:148)
at cn.zd.maincode.wangge.GridCorrelationMain$.main(GridCorrelationMain.scala:110)
at cn.zd.maincode.wangge.GridCorrelationMain.main(GridCorrelationMain.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:673)
Caused by: java.lang.ExceptionInInitializerError
at org.apache.hadoop.hive.conf.HiveConf.<clinit>(HiveConf.java:105)
at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:153)
at org.apache.spark.sql.hive.client.HiveClientImpl.<init>(HiveClientImpl.scala:118)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:292)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:395)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:284)
at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:68)
at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:67)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:217)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:217)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:217)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:99)
... 72 more
Caused by: java.lang.IllegalArgumentException: Unrecognized Hadoop major version number: 3.0.0-cdh6.3.2
at org.apache.hadoop.hive.shims.ShimLoader.getMajorVersion(ShimLoader.java:169)
at org.apache.hadoop.hive.shims.ShimLoader.loadShims(ShimLoader.java:134)
at org.apache.hadoop.hive.shims.ShimLoader.getHadoopShims(ShimLoader.java:95)
at org.apache.hadoop.hive.conf.HiveConf$ConfVars.<clinit>(HiveConf.java:354)
... 88 moreEnd of LogType:stderr
4.最终解决方式
将相关依赖不打进包中
<dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><exclusions><exclusion><groupId>org.eclipse.jetty.aggregate</groupId><artifactId>jetty-all</artifactId></exclusion><exclusion><groupId>org.apache.hive</groupId><artifactId>hive-shims</artifactId></exclusion><exclusion><artifactId>hbase-mapreduce</artifactId><groupId>org.apache.hbase</groupId></exclusion><exclusion><artifactId>hbase-server</artifactId><groupId>org.apache.hbase</groupId></exclusion><exclusion><artifactId>log4j-slf4j-impl</artifactId><groupId>org.apache.logging.log4j</groupId></exclusion><exclusion><artifactId>slf4j-log4j12</artifactId><groupId>org.slf4j</groupId></exclusion></exclusions><version>2.1.1</version></dependency><!--服务验证相关依赖--><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.13</version><exclusions><exclusion><groupId>commons-codec</groupId><artifactId>commons-codec</artifactId></exclusion></exclusions><!--<scope>provided</scope>--></dependency><!--本地跑的话 需要这个jar--><dependency><groupId>commons-codec</groupId><artifactId>commons-codec</artifactId><version>1.15</version><!--<scope>provided</scope>--></dependency><dependency><groupId>com.typesafe</groupId><artifactId>config</artifactId><version>1.3.1</version></dependency><!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>${fastjson.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.json/json --><dependency><groupId>org.json</groupId><artifactId>json</artifactId><version>20160810</version></dependency><dependency><groupId>com.github.qlone</groupId><artifactId>retrofit-crawler</artifactId><version>1.0.0</version></dependency><dependency><groupId>com.oracle.database.jdbc</groupId><artifactId>ojdbc8</artifactId><version>12.2.0.1</version></dependency><!--mysql连接--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.40</version></dependency><!--10月31日 新取消-->
<!-- <dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>28.0-jre</version></dependency>--><!-- https://mvnrepository.com/artifact/org.apache.directory.studio/org.apache.commons.codec --><!-- https://mvnrepository.com/artifact/org.apache.commons/org.apache.commons.codec --><!--邮件发送依赖--><dependency><groupId>javax.mail</groupId><artifactId>javax.mail-api</artifactId><version>1.5.6</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-email</artifactId><version>1.4</version></dependency><!--<dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.11.2</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-reflect</artifactId><version>2.11.2</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>2.11.2</version></dependency>--><!-- <dependency>-->
<!-- <groupId>com.starrocks</groupId>-->
<!-- <artifactId>starrocks-spark2_2.11</artifactId>-->
<!-- <version>1.0.1</version>-->
<!-- </dependency>--></dependencies>
相关文章:

Unrecognized Hadoop major version number: 3.0.0-cdh6.3.2
一.环境描述 spark提交job到yarn报错,业务代码比较简单,通过接口调用获取数据,将数据通过sparksql将数据写入hive中,尝试各种替换hadoop版本,最后拿下 1.hadoop环境 2.项目 pom.xml spark-submit \ --name GridCorr…...

机器学习分类,损失函数中为什么要用Log,机器学习的应用
目录 损失函数中为什么要用Log 为什么对数可以将乘法转化为加法? 机器学习(Machine Learning) 机器学习的分类 监督学习 无监督学习 强化学习 机器学习的应用 应用举例:猫狗分类 1. 现实问题抽象为数学问题 2. 数据准备…...
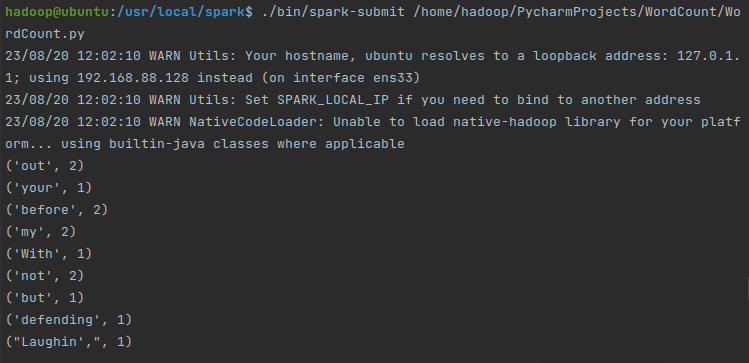
PySpark安装及WordCount实现(基于Ubuntu)
先盘点一下要安装哪些东西: VMwareubuntu 14.04(64位)Java环境(JDK 1.8)Hadoop 2.7.1Spark 2.4.0(Local模式)Pycharm (一)Ubuntu VMware 和 ubuntu 14.04(…...
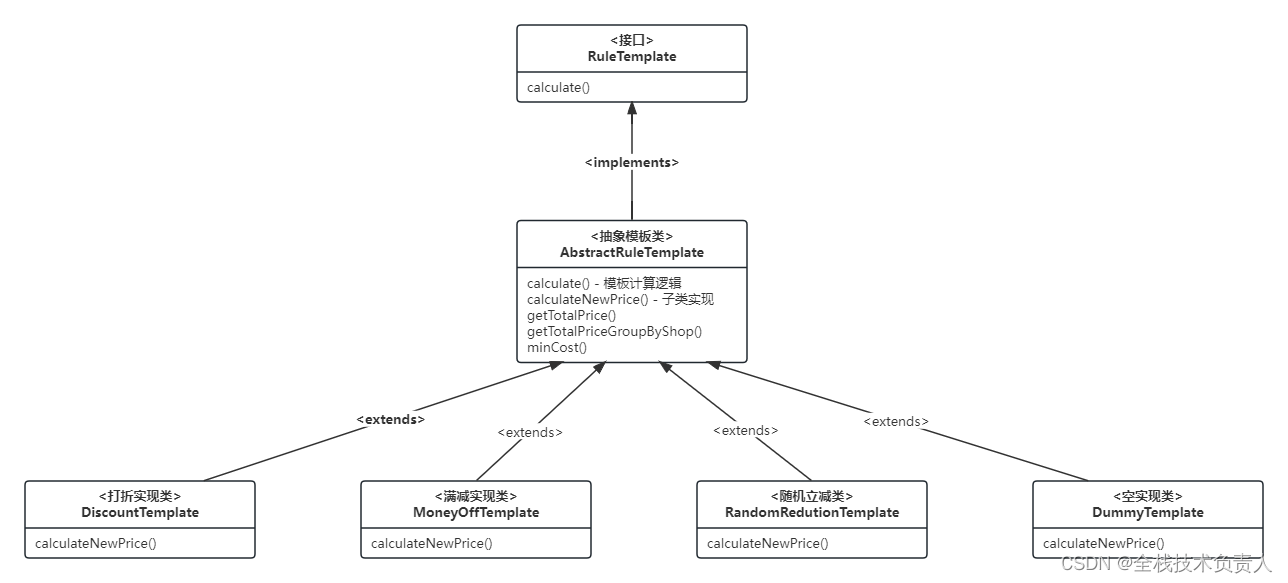
SpringBoot 模板模式实现优惠券逻辑
一、计算逻辑的类结构图 在这张图里,顶层接口 RuleTemplate 定义了 calculate 方法,抽象模板类 AbstractRuleTemplate 将通用的模板计算逻辑在 calculate 方法中实现,同时它还定义了一个抽象方法 calculateNewPrice 作为子类的扩展点。各个具…...
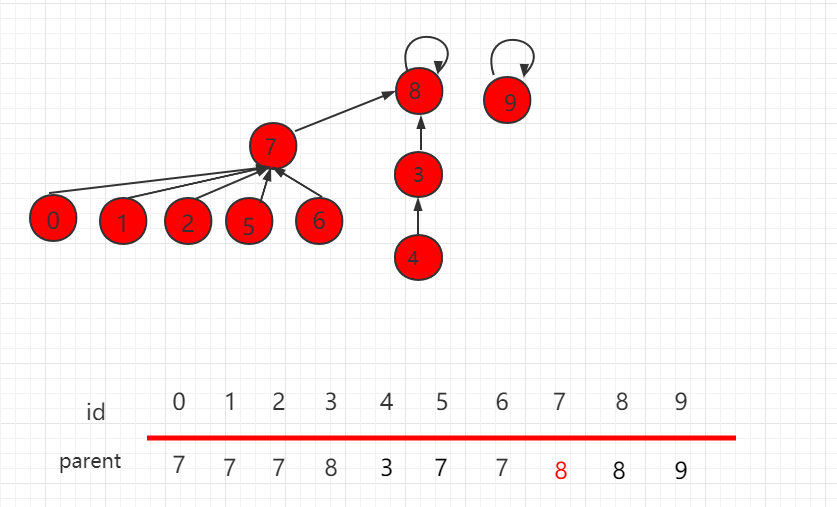
并查集 rank 的优化(Java 实例代码)
目录 并查集 rank 的优化 Java 实例代码 UnionFind3.java 文件代码: 并查集 rank 的优化 上一小节介绍了并查集基于 size 的优化,但是某些场景下,也会存在某些问题,如下图所示,操作 union(4,2)。 根据上一小节&…...

TDA4超级玩家浮出水面,行泊一体功能、成本刷到极致
2023年以来,智能驾驶市场进入L2普及、高阶ADAS功能(NOA)大规模量产的新周期,降本增效,打造极致性价比、提升用户体验等,成为了竞争的焦点。 其中,替换更具性价比的硬件平台、传感器复用、系统优…...

3分钟了解Android中稳定性测试
一、什么是Monkey Monkey在英文里的含义是猴子,在测试行业的学名叫“猴子测试”,指的是没有测试经验的人甚至是根本不懂计算机的人(就像一只猴子),不需要知道程序的任何用户交互方面的知识,给他一个程序&a…...
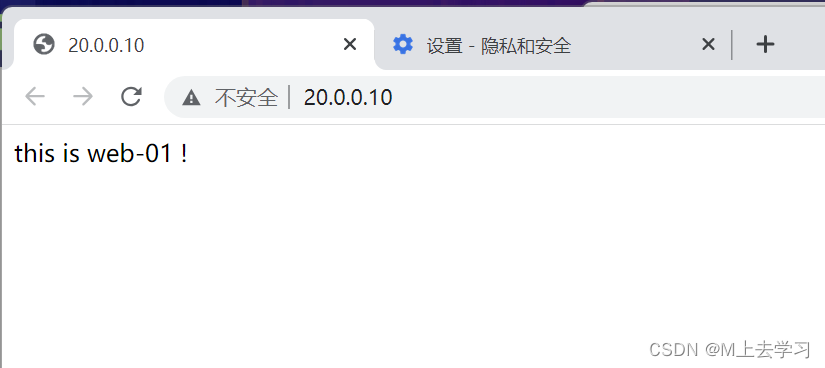
LVS-DR+keepalived实现高可用负载群集
VRRP 通信原理: VRRP就是虚拟路由冗余协议,它的出现就是为了解决静态路由的单点故障。 VRRP是通过一种竞选的一种协议机制,来将路由交给某台VRRP路由。 VRRP用IP多播的方式(多播地址224.0.0.18)来实现高可用的通信&…...

阿里云国际版注册教程
什么是阿里云国际版? 阿里云国际版是阿里云专为海外客户供给的服务器及核算资源,涵盖了云主机、弹性裸金属服务器、容器服务、数据库及安全和监控等一系列云核算解决方案。 与其他云核算服务供给商不同,阿里云国际版在安全性、稳定性、性能方…...

基于百度文心大模型创作的实践与谈论
文心概念 百度文心大模型源于产业、服务于产业,是产业级知识增强大模型。百度通过大模型与国产深度学习框架融合发展,打造了自主创新的AI底座,大幅降低了AI开发和应用的门槛,满足真实场景中的应用需求,真正发挥大模型…...
)
Java基础知识题(五)
系列文章目录 Java基础知识题(一) Java基础知识题(二) Java基础知识题(三) Java基础知识题(四) Java基础知识题(五) 文章目录 系列文章目录 前言 一 Java的数据连接——JDBC 1. 简述什么是JDBC?重点 2. JDBC PreparedStatement比Statement有什么优势&…...

攻防世界-fileinclude
原题 解题思路 题目已经告诉了,flag在flag.php中,先查看网页源代码(快捷键CTRLU)。 通过抓包修改,可以把lan变量赋值flag。在cookie处修改。新打开的网页没有cookie,直接添加“Cookie: languagephp://filte…...
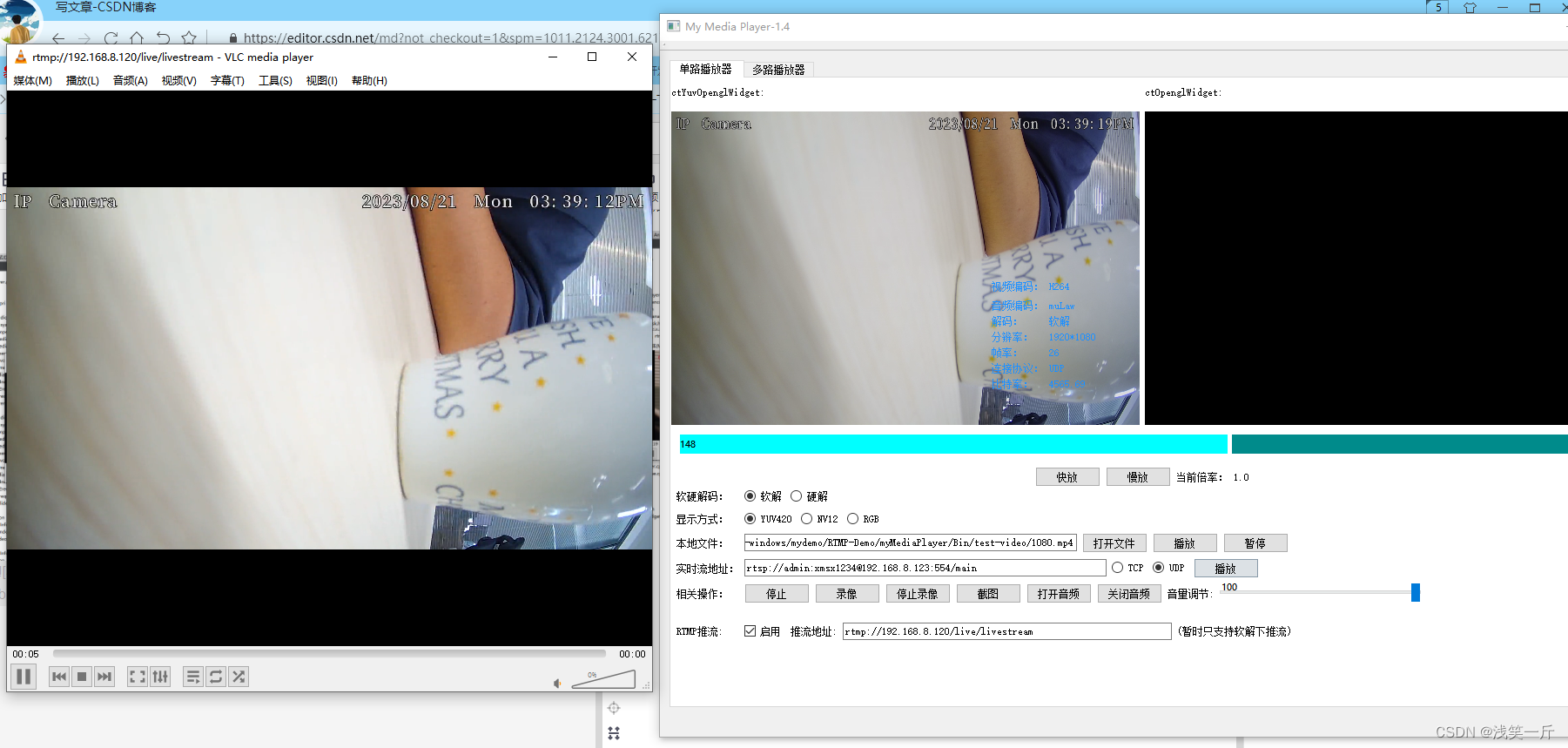
流媒体服务器SRS的搭建及QT下RTMP推流客户端的编写
一、前言 目前市面上有很多开源的流媒体服务器解决方案,常见的有SRS、EasyDarwin、ZLMediaKit和Monibuca。这几种的对比如下: (本图来源:https://www.ngui.cc/zz/1781086.html?actiononClick) 二、SRS的介绍 SRS&am…...
)
Effective C++条款11——在operator=中处理“自我赋值”(构造/析构/赋值运算)
“自我赋值”发生在对象被赋值给自己时: class Widget {}; Widget w; // ... w w; // 赋值给自己 这看起来有点愚蠢,但它合法,所以不要认定客户绝不会那么做。此外赋值动作并不总是那么可被一眼辨识出来,例如: a[i] a[j]; …...
-气泡图(一))
可视化绘图技巧100篇基础篇(八)-气泡图(一)
目录 前言 适用场景 图例 绘图工具及代码实现 EXCEL 1、单轴气泡图...

Elasticsearch查询之Disjunction Max Query
前言 Disjunction Max Query 又称最佳 best_fields 匹配策略,用来优化当查询关键词出现在多个字段中,以单个字段的最大评分作为文档的最终评分,从而使得匹配结果更加合理 写入数据 如下的两条例子数据: docId: 1 title: java …...
Lock wait timeout exceeded; try restarting transaction的错误
文章目录 一、异常发现二、异常定位1、锁表语句确认2、实际场景排查三、解决思路1、本次解决方式2、其他场景解决思路扩展1、【治标方法】innodb_lock_wait_timeout 锁定等待时间改大2、【治标方法】事务信息查询3、【治标方法】如果杀掉线程依然不能解决,可以查找执行线程耗时…...

ShardingSphere01-docker环境安装
使用docker安装数据库是一个非常好的选择,后续的读写分离、数据分片等功能的数据库都是由docker创建。 一、安装准备 1、前提条件 Docker可以运行在Windows、Mac、CentOS、Ubuntu等操作系统上 Docker支持以下的CentOS版本: CentOS 7 (64-bit)CentOS …...
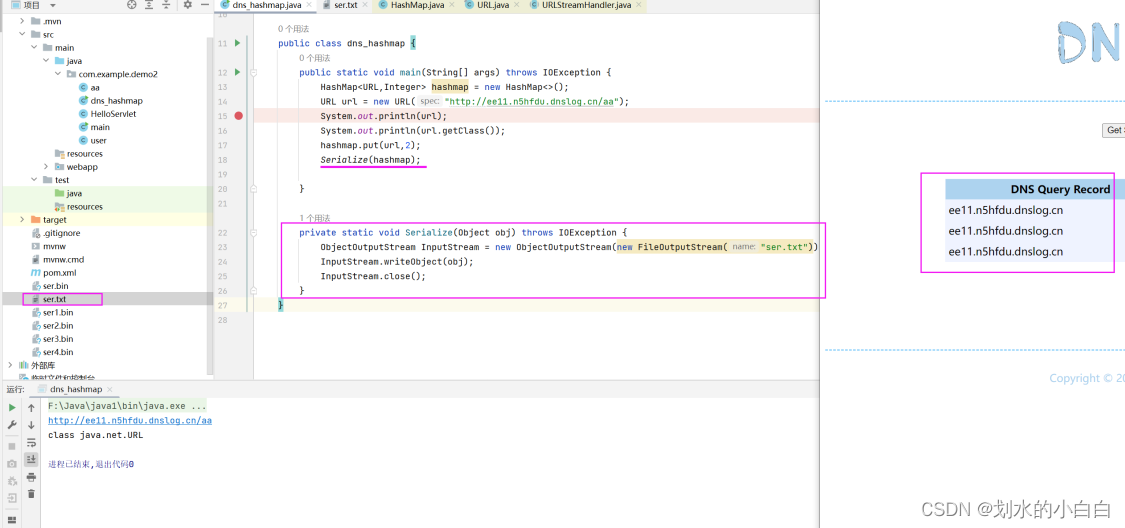
Java代码审计13之URLDNS链
文章目录 1、简介urldns链2、hashmap与url类的分析2.1、Hashmap类readObject方法的跟进2.2、URL类hashcode方法的跟进2.3、InetAddress类的getByName方法 3、整个链路的分析3.1、整理上述的思路3.2、一些疑问的测试3.3、hashmap的put方法分析3.4、反射3.5、整个代码 4、补充说明…...

区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测
区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测 目录 区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测效果一览基本介绍模型描述程序设计参考资料 效果一览 基本介绍 MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列…...

FPGA Multiboot翻车实录:从XDC配置到ICAPE2,我的W25Q128分区血泪史与避坑指南
FPGA Multiboot实战:从配置陷阱到Flash分区优化的全流程解析 第一次在量产产品中实现FPGA远程更新功能时,我盯着实验室里突然变砖的开发板,后背渗出一层冷汗。原本以为按照官方文档配置就能万无一失,没想到Multiboot这个看似简单的…...

电力电子顶刊投稿避坑指南:TIE与TPEL审稿流程、周期及常见误区全解析
电力电子顶刊投稿策略全解析:从TIE到TPEL的实战避坑指南 在电力电子与电机驱动领域,IEEE Transactions on Industrial Electronics (TIE)和IEEE Transactions on Power Electronics (TPEL)无疑是研究者梦寐以求的发表平台。这两本期刊不仅代表着行业内的…...

出海营销决战指南:从“流量过客”到“私域常客”的全局地图
2026 全球出海营销日历:如何在关键节点实现社媒私域流量的指数级增长?2026年,出海战场规则已变。粗放投放的红利耗尽,碎片化的渠道、敏感的风控与难以逾越的文化沟壑,正让每一分营销预算的效能急剧衰减。节点依旧汹涌&…...

医学影像与卫星图的救星?深入聊聊JPEG-LS算法在边缘计算设备上的应用优势
JPEG-LS算法:边缘计算时代的医学影像与卫星图像压缩利器 当一台CT扫描仪每秒产生数百张16位深度的医学影像,或一颗遥感卫星每天传回数TB的高清地表数据时,传统的图像压缩方案往往面临两难选择——要么牺牲宝贵的诊断细节,要么耗尽…...

OpenClaw跨平台部署:nanobot镜像在mac/Windows双系统实测
OpenClaw跨平台部署:nanobot镜像在mac/Windows双系统实测 1. 为什么选择nanobot镜像 第一次听说nanobot这个轻量级OpenClaw镜像时,我正被本地部署大模型的资源消耗问题困扰。作为一个经常在macOS和Windows双系统切换的开发者,我需要一个能在…...

利用快马平台AI能力,十分钟搭建你的Copilot式代码生成原型
今天想和大家分享一个快速验证AI编程助手(Copilot类工具)原型的实践。作为一个经常需要快速验证想法的开发者,我发现用InsCode(快马)平台可以省去很多搭建环境的时间,特别适合做这种概念验证。 明确核心需求 Copilot的核心能力其实…...

手把手教你用LVGL特殊符号打造炫酷UI界面
手把手教你用LVGL特殊符号打造炫酷UI界面 在嵌入式设备开发中,UI设计往往面临资源受限的挑战。LVGL(Light and Versatile Graphics Library)作为一款轻量级开源图形库,通过其丰富的特殊符号系统,让开发者能够在有限资…...

从DVWA存储型XSS看Web安全:开发者常踩的坑与Impossible级别的启示
从DVWA存储型XSS看Web安全:开发者常踩的坑与Impossible级别的启示 在Web应用开发中,安全漏洞就像隐藏在代码中的定时炸弹,而存储型XSS(跨站脚本攻击)无疑是其中最具破坏力的一种。不同于反射型XSS的一次性攻击…...

新手福音:利用快马平台生成你的第一个数学公式编辑器入门项目
最近在自学前端开发,一直想尝试做个数学公式编辑器来练手。作为一个完全的新手,从零开始写这种项目确实有点无从下手。不过我发现用InsCode(快马)平台可以很轻松地生成基础代码框架,再根据自己的需求调整完善,特别适合像我这样的初…...

2026年03月26日全球AI前沿动态
一句话总结全球AI领域密集发布技术、产品、企业动态,覆盖通用/垂直大模型、专项技术、智能体、机器人、硬件基建等全赛道,中国AI在视频、音乐、办公智能体领域领跑,OpenAI关停Sora战略转型,Arm、苹果、腾讯等大厂新品落地…...