Python搭建自己[IP代理池]
IP代理是什么:
ip就是访问网页数据服务器位置信息,每一个主机或者网络都有一个自己IP信息
为什么要使用代理ip:
因为在向互联网发送请求中,网页端会识别客户端是真实用户还是爬虫程序,在今天以互联网为主导的世界中,数据一种资源,谁能得到更多有效的数据,谁就能在今天互联网世界斗争中获得先机,所以网页是不愿意把数据作为开源分享给其他互联网运营公司的,它会创造出许许多多的反制措施来避免自己的数据被其他竞争对手(或利益相关的其他服务商),但又不得不为了创造更高的经济价值,来以非常有限的隧道中让正常真实用户访问它的网页,所以IP作为访问者的唯一标识,自然而然成为互联网公司鉴别真实非爬虫用户的一种手段。
如果你设置的程序访问时间过快(行为异常)超过了正常人访问的时间(行为),被访问的网页就会判定你是一个爬虫程序,对你的IP进行封禁(一般为5-15分钟,不会超过12小时)。
所以作为爬虫工作者为了获取互联网中的数据,通过以更换ip的方式来再一次访问该网页。
因此由于市场需求,网络上出现许多以”为爬虫工作者提供ip地址“的互联网公司。
这类互联网公司为爬虫职业学习者,提供了一些免费IP信息以供学习,在真实项目获取免费IP信息的方式是不被建议的,作者期望你能通过付费的方式来获取更多高质量的IP资源。
作者作为python爬虫初学者赖给大家讲述一下,如何搭建自己IP代理池,IP代理池听名闻义,其实就是装载了许许多多的高质量IP资源,以供学习者和工作人员及时的更换IP避免对项目产生不可挽回的损失。
作为爬虫学习者,我们应该较其他行业人员应具有爬虫技术,通过爬虫来获取更多IP数据。
对IP代理提供商发起访问请求:(本次IP资源的提供商为:”云代理“)
import time
import requests
import parsel
#新建一个列表用来存储完整ip数据
proxies_list = []
for page in range(1,8):print(f"===========正在爬取第{page}====================")time.sleep(1)url = 'http://www.ip3366.net/free/?stype=1&page={page_turn}'.format(page_turn=page) #服务器获取数据
#浏览器的身份标识headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}response = requests.get(url=url,headers=headers)#指定一个编码 = 获取一个编码response.encoding = response.apparent_encodinghtml_data = response.text将web服务器返回页面数据进行解析:本次采用xpath解析
#3.数据解析 使用xpath 方法,xpath专门用于解析html页面selector = parsel.Selector(html_data) #转换数据类型# print(selector)trs = selector.xpath('//table/tbody/tr')# print(trs)#将拼接好的完整地址保存在一个名为proxies_list的列表中#遍历每一个tr标签for tr in trs:ip = tr.xpath('./td[1]/text()').get()adr = tr.xpath('./td[2]/text()').get()# print(ip,adr)将获取的数据拼接起来:因为完整ip地址需要加上 http:// 或者 https://
proxies_dict = {#字符串的拼接"http":"http://"+ip+":"+adr,"https":"https://"+ip+":"+adr,}将获取的完整的IP信息存储起来
proxies_list.append(proxies_dict)第二大部分:将获取到IP数据检测一下是否可用,避免在爬虫项目中项目浪费太多的时间,来检测ip的可用性。
免费IP几乎百分之九十不可用,所以作为爬虫工作者建议你购买付费数据
定义一个函数用来检测数据是否可用:
def check_ip(proxies_list):""" 代理检测"""#将高质量可用代理存储起来can_user= []for proxie in proxies_list:#发送一个请求以便得到该代理的状态码try:response = proxie.get(url='https://www.baidu.com',proxies=proxie,timeout=2)if response.status_code == 200: #如果该IP访问百度后,返回的状态码为200时,说明该地阿里可以使用#将该代理保存起来can_user.append(proxie)except:print('当前代理:',proxie,'请求时间过长不可用')#如果代理可用则执行else中的语句else:print('当前代理:', proxie, '可以使用')return can_user这里我要说的重点是:
response.status_code == 200通过向特定的网页发起get请求,以返回状态码来检测该IP数据是否正常可用,如果在有限的时间中它返回的状态码为200说明该IP数据是正常可用的。
通过方法的调用来让该检测代码段运行起来:
can_user = check_ip(proxies_list)
print('可以使用的代理:',can_user)
print('可以使用的代理数量为:',len(can_user))这里我要说的是:通过check_ip()方法调用并且向该方法传递一个参数”proxies_list“,该参数是我们定义的用来存储在ip提供商那里爬取全部IP数据,通过调用该方法,并且将未进行识别的ip数据传入。让检测程序代码段运行起来,获取可供使用IP数据
文章的最后,我要说的是,希望大家能感激每一位资源的提供者,只有消费才会产生价值,带动市场,我们应该尊重劳动者的辛苦劳作。
完整代码段:
#建立步骤:
'''
爬取提供免费代理的网站数据(ip地址 端口号,地址信息)1.寻找数据地址2.发送请求3.需要的数据(页面解析保存下来),或者不需要的数据(剔除)4.需要的数据保存(IP地址,端口,拼接https://)'''
import time
import requests
# 安装parsel时报错,经过排查应该是镜像源的问题(网络上说是尽量使用国内镜像源,国外网速不行,我使用的就是阿里云的镜像)应该是阿里云的镜像不行,我换了一个豆瓣的镜像源
#具体使用办法在安装包的后面添加上,通过那个镜像源:pip install parsel -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com 把”库包名“换成你要安装的包的名称即可;
import parsel
#使用代理:
#定义一个函数:
def check_ip(proxies_list):""" 代理检测"""#将高质量可用代理存储起来can_user= []for proxie in proxies_list:#发送一个请求以便得到该代理的状态码try:response = proxie.get(url='https://www.baidu.com',proxies=proxie,timeout=2)if response.status_code == 200: #如果该IP访问百度后,返回的状态码为200时,说明该地阿里可以使用#将该代理保存起来can_user.append(proxie)except:print('当前代理:',proxie,'请求时间过长不可用')#如果代理可用则执行else中的语句else:print('当前代理:', proxie, '可以使用')return can_user#1.寻找数据的地址
proxies_list = []
for page in range(1,8):print(f"===========正在爬取第{page}====================")time.sleep(1)url = 'http://www.ip3366.net/free/?stype=1&page={page_turn}'.format(page_turn=page) #服务器获取数据
#浏览器的身份标识headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}response = requests.get(url=url,headers=headers)#指定一个编码 = 获取一个编码response.encoding = response.apparent_encodinghtml_data = response.text#3.数据解析 使用xpath 方法,xpath专门用于解析html页面selector = parsel.Selector(html_data) #转换数据类型# print(selector)trs = selector.xpath('//table/tbody/tr')# print(trs)#将拼接好的完整地址保存在一个名为proxies_list的列表中#遍历每一个tr标签for tr in trs:ip = tr.xpath('./td[1]/text()').get()adr = tr.xpath('./td[2]/text()').get()# print(ip,adr)proxies_dict = {#字符串的拼接"http":"http://"+ip+":"+adr,"https":"https://"+ip+":"+adr,}proxies_list.append(proxies_dict)print('获取成功',proxies_dict)#break 次break是为了检测第一页数据返回是否正常,其实我获取的所有免费代理
print(proxies_list)
print('获取的代理数据为:',len(proxies_list))# proxies_list.append(proxies_dict)
print('==========================正在检测代理======================')
can_user = check_ip(proxies_list)
print('可以使用的代理:',can_user)
print('可以使用的代理数量为:',len(can_user))相关文章:

Python搭建自己[IP代理池]
IP代理是什么:ip就是访问网页数据服务器位置信息,每一个主机或者网络都有一个自己IP信息为什么要使用代理ip:因为在向互联网发送请求中,网页端会识别客户端是真实用户还是爬虫程序,在今天以互联网为主导的世界中&#…...
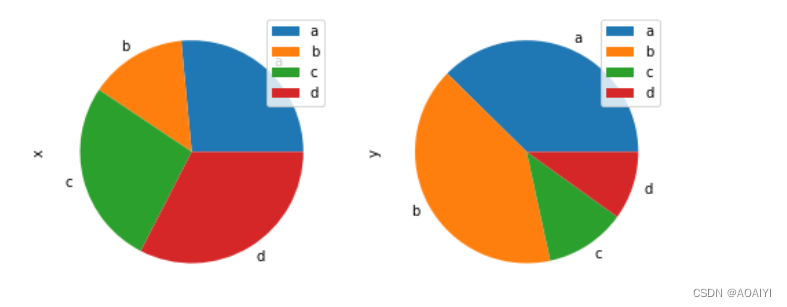
pandas——plot()方法可视化
pandas——plot()方法可视化 作者:AOAIYI 创作不易,如果觉得文章不错或能帮助到你学习,记得点赞收藏评论哦 在此,感谢你的阅读 文章目录pandas——plot()方法可视化一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤…...
)
【Three.js基础】坐标轴辅助器、requestAnimationFrame处理动画、Clock时钟、resize页面尺寸(二)
🐱 个人主页:不叫猫先生 🙋♂️ 作者简介:前端领域新星创作者、阿里云专家博主,专注于前端各领域技术,共同学习共同进步,一起加油呀! 💫系列专栏:vue3从入门…...
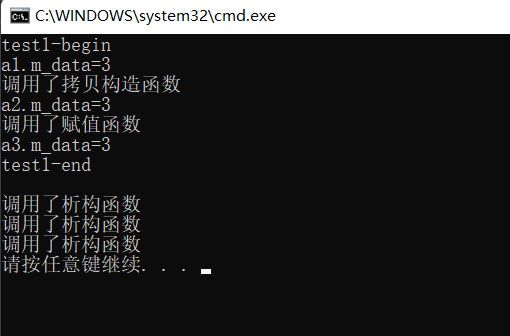
C++之完美转发、移动语义(forward、move函数)
完美转发1. 在函数模板中,可以将自己的参数“完美”地转发给其它函数。所谓完美,即不仅能准确地转发参数的值,还能保证被转发参数的左、右值属性不变。2. C11标准引入了右值引用和移动语义,所以,能否实现完美转发&…...
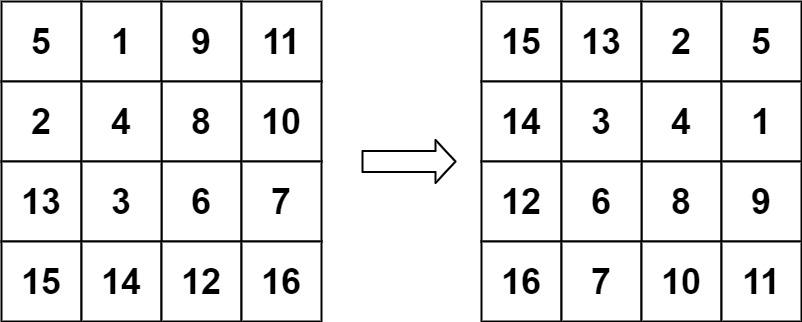
LeetCode刷题系列 -- 48. 旋转图像
给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。示例 1:输入:matrix [[1,2,3],[4,5,6],[7,8,9]]输出&#…...

在多线程环境下使用哈希表
一.HashTable和HashMapHashTable是JDK1.0时创建的,其在创建时考虑到了多线程情况下存在的线程安全问题,但是其解决线程安全问题的思路也相对简单:在其众多实现方法上加上synchronized关键字(效率较低),保证…...
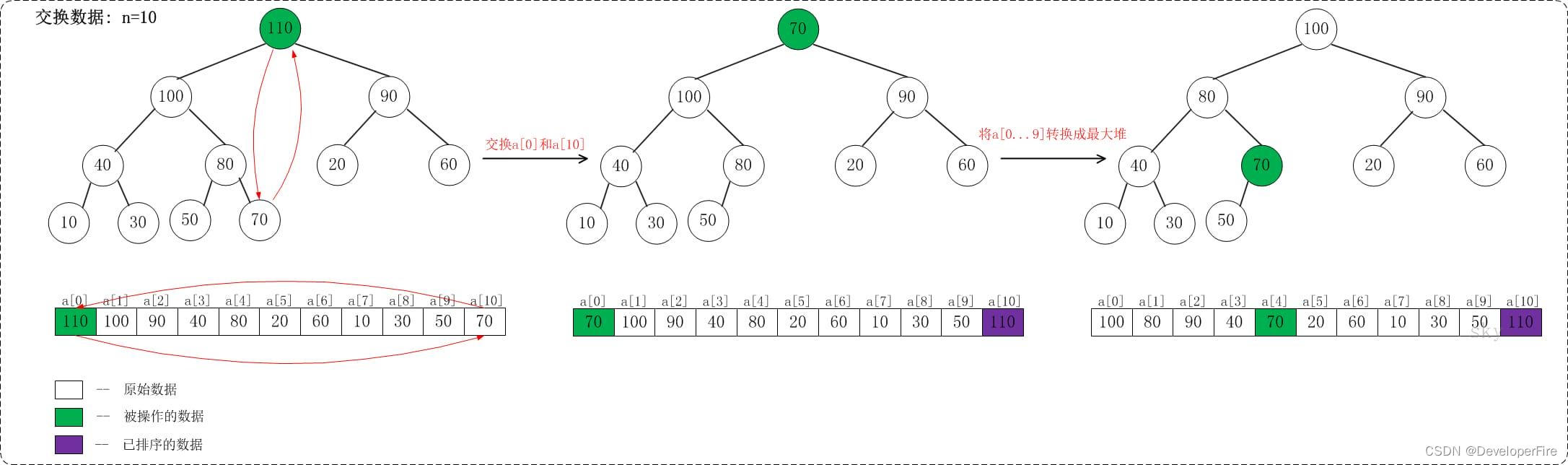
【排序算法】堆排序(Heap Sort)
堆排序是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序介绍学习堆排序之前,有必要了解堆!若…...
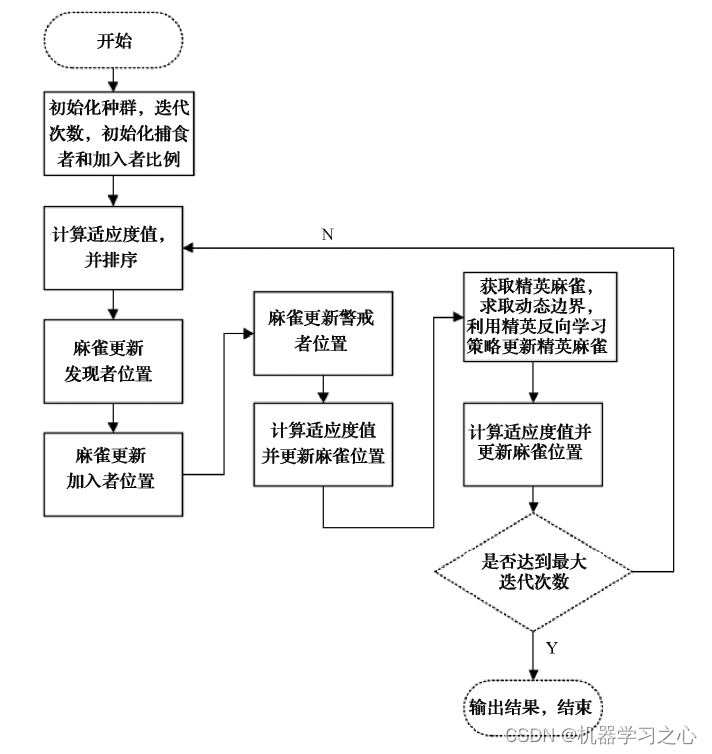
分类预测 | Matlab实现SSA-RF和RF麻雀算法优化随机森林和随机森林多特征分类预测
分类预测 |Matlab实现SSA-RF和RF麻雀算法优化随机森林和随机森林多特征分类预测 目录分类预测 |Matlab实现SSA-RF和RF麻雀算法优化随机森林和随机森林多特征分类预测分类效果基本介绍模型描述程序设计参考资料分类效果 基本介绍 Matlab实现SSA-RF和RF麻雀算法优化随机森林和随机…...
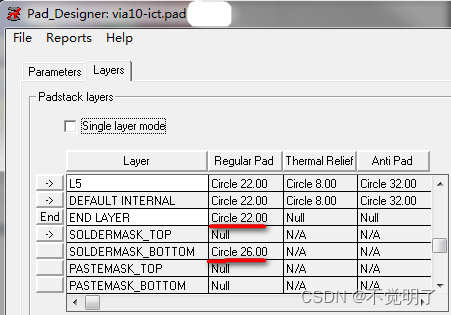
Allegro如何添加ICT操作指导
Allegro如何添加ICT操作指导 当PCB板需要做飞针测试的时候,通常需要在PCB设计的时候给需要测试的网络添加上ICT。 如图: Allegro支持给网络添加ICT,具体操作如下 首先在库中创建一个阻焊开窗的过孔,比如via10-ict一般阻焊开窗的尺寸比盘单边大2mil 在PCB中选择Manufacture…...

软件架构设计(二)——领域架构、基于架构的软件开发方法
目录 一、架构描述语言 ADL 二、特定领域软件架构 DSSA 三、DSSA的三层次架构模型 . 四、基于架构的软件开发方法 (1)基于架构的软件设计(ABSD) (2)开发过程 一、架构描述语言 ADL ADL是一种形式化语言,它在底层语义模型的支持下,为软件系统概念体…...
---数组遍历方法)
数组常用方法(2)---数组遍历方法
1. forEach(cb) 回调函数中有三个参数,第一个是当前遍历项(必须),第二个是索引,第三个是遍历的数组本身。forEach() 对于空数组不会执行回调函数。forEach()不会使用回调函数的返回值,返回值为undefined。…...
卸载Node.js
0 写在前面 无论您是因为什么原因要卸载Node.js都必须要卸载干净。 请阅读: 1 卸载步骤 1.1通过控制面板卸载node.js winR—>control.exe—>卸载程序—>卸载Node.js 等待—>卸载成功 1.2 删除安装时的nodejs文件夹 通过记忆或者Everthing搜索找…...

发表计算机SCI论文,会经历哪些过程? - 易智编译EaseEditing
一、选期刊。 一定要先选期刊。每本期刊都有自己的特色和方向,如果你的稿子已经成型,再去考虑期刊选择的问题,恐怕后期不是退稿就是要大面积修改稿子。 选期刊的标准没有一定的,主要是各单位都有自己的要求,当然小编…...

python中lambda的用法
1. lambada简单介绍 lambda 在Python编程中使用的频率非常高,我们通常提及的lambda表达式其实是python中的一类特殊的定义函数的形式,使用它可以定义一个匿名函数。即当你需要一个函数,但又不想费神去命名一个函数,这时候…...
网络安全协议(3)
作者简介:一名在校云计算网络运维学生、每天分享网络运维的学习经验、和学习笔记。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 目录 前言 一.当前流行操作系统的安全等级 1.Windows的安全等级 什么是EAL…...

102.第十九章 MySQL数据库 -- MySQL的备份和恢复(十二)
5.备份和恢复 5.1 备份恢复概述 5.1.1 为什么要备份 灾难恢复:硬件故障、软件故障、自然灾害、黑客攻击、误操作测试等数据丢失场景 参考链接: https://www.toutiao.com/a6939518201961251359/ 5.1.2 备份类型 完全备份,部分备份 完全备份:整个数据集 部分备份:只备份数…...
【C++】C++入门 类与对象(一)
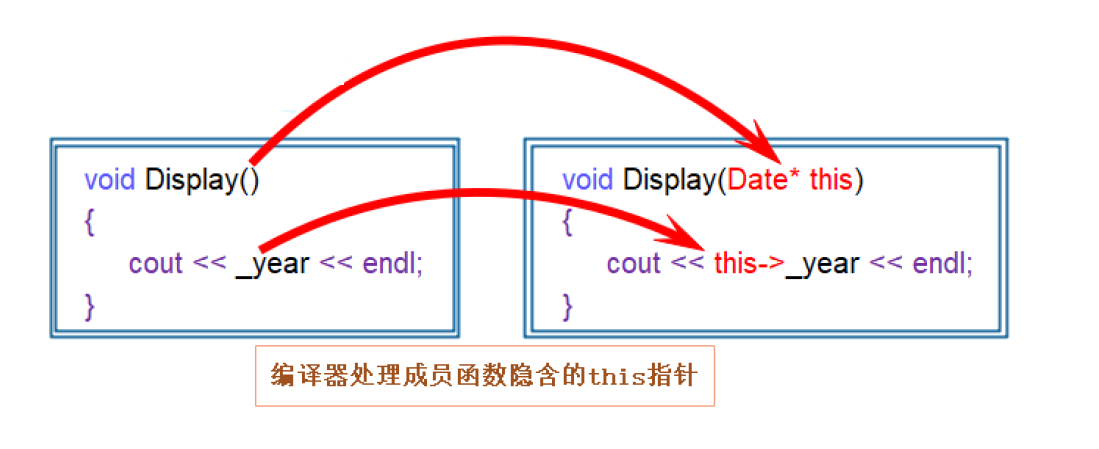
类与对象(一)一、类的引入二、类的定义1、类的两种定义方式:2、成员变量命名规则的建议:三、类的访问限定符及封装1、访问限定符2、封装四、类的实例化1、类的实例化概念2、类对象的大小的计算五、this指针this指针的特性一、类的…...

笔记_js运算符
目录二进制相关运算符移位运算符<<>>|(位或运算)参考文档二进制相关运算符 移位运算符 移位运算就是对二进制进行有规律的移位。 tips:进制转换文档链接 << “<<”运算符执行左移位运算。在移位运算过程中,符号位始终保持不变…...
java面试题(十九) Mybatis
4.1 谈谈MyBatis和JPA的区别 参考答案 ORM映射不同: MyBatis是半自动的ORM框架,提供数据库与结果集的映射; JPA(默认采用Hibernate实现)是全自动的ORM框架,提供对象与数据库的映射。 可移植性不同&…...

Linux系统位运算函数以及相应CPU ISA实现收录
以32位数据的二进制表示为例,习惯的写法是LSB在左,MSB在右,注意BIT序和大小端的字节序没有关系。Linux和BIT操作有关的接口在定义在头文件bitops.h中,bitops.h定义有两层,通用层和架构层,对应两个bitops.h&…...

从零基础到AI大模型高手,自学AI大模型学习路线推荐,不走弯路!
本文提供了一条详尽的AI大模型自学路线,旨在帮助新手小白系统学习。路线涵盖数学与编程基础、机器学习入门、深度学习深入、大模型探索、进阶与应用以及社区与资源等多个方面。内容详细列出了各阶段的学习资源,包括经典书籍、在线课程、实践项目等&#…...

D26: 向下负责——保护团队免受 AI 焦虑影响
文章目录 D26: 向下负责——保护团队免受 AI 焦虑影响 🎯 为什么这个话题重要? 现实痛点:团队 AI 焦虑的三种表现 一个真实场景 一、理解 AI 焦虑的本质 1.1 焦虑从何而来? 1.2 焦虑的恶性循环 1.3 一个心理学视角 二、建立团队心理安全网 2.1 心理安全:团队韧性的基石 2…...

Python 爬虫高级实战:爬虫接口限流自适应调节
前言 网络目标站点普遍具备严格的接口访问限流、频率校验、IP 频次风控、接口令牌校验等防护机制,常规固定延时、固定并发的爬虫模式极易触发封禁、接口 429 限流、会话失效、IP 拉黑等问题。人工配置延时、手动调整并发阈值的传统方式,无法适配站点动态…...

上午题_程序设计语言
编译程序和解释程序...

2025届学术党必备的五大降重复率方案横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下知网已然上线了AI检测功能,会针对论文里疑似人工智能生成的内容展开识别。为…...

IO:为专业开发者打造的AI编程助手架构解析与实战指南
1. 项目概述:IO,一个为专业开发者打造的AI编程助手如果你和我一样,每天大部分时间都在和代码、终端、以及各种开发工具打交道,那你一定理解那种对“流畅感”的渴望。我们需要的不是一个只会回答问题的聊天机器人,而是一…...

Windows内核级虚拟串口驱动com0com:构建无限虚拟COM端口对的终极解决方案
Windows内核级虚拟串口驱动com0com:构建无限虚拟COM端口对的终极解决方案 【免费下载链接】com0com Null-modem emulator - The virtual serial port driver for Windows. Brought to you by: vfrolov [Vyacheslav Frolov](http://sourceforge.net/u/vfrolov/profil…...
 深度诊断与流量整形方案)
lsyncd rsyncssh同步中断:Broken pipe (32) 深度诊断与流量整形方案
1. 问题现象与初步诊断 最近在帮客户部署lsyncdrsyncssh方案时,遇到了一个典型问题:同步25GB目录时,总是在传输4GB左右中断。日志里反复出现"Broken pipe (32)"错误,就像下面这样: packet_write_wait: Conne…...

从零到一:基于C#与ArcGIS二次开发构建迎风面指数计算插件实战
1. 环境准备与工具搭建 第一次接触ArcGIS二次开发时,我被官方文档里密密麻麻的API吓得不轻。后来发现只要配好环境,开发插件比想象中简单得多。你需要准备三样东西:Visual Studio(建议2019或2022社区版)、ArcGIS Desk…...

Foundation Sites响应式设计原理:5个核心断点系统详解,打造完美移动优先体验
Foundation Sites响应式设计原理:5个核心断点系统详解,打造完美移动优先体验 【免费下载链接】foundation-sites The most advanced responsive front-end framework in the world. Quickly create prototypes and production code for sites that work …...