如何优化因为高亮造成的大文本(大字段)检索缓慢问题
首先还是说一下背景,工作中用到了 elasticsearch 的检索以及高亮展示,但是索引中的content字段是读取的大文本内容,所以后果就是索引的单个字段很大,造成单独检索请求的时候速度还可以,但是加入高亮之后检索请求的耗时就非常的慢了。所以本文从更换高亮器类型的角度来解决因为高亮造成的检索请求缓慢的问题。
ES的抵消策略
在文章开始前先简单介绍一个elasticsearch的策略,为了在检索的字段中创建出一个有意义的高亮片段,高亮器会使用原始文本的开始和结束字符串的偏移量,偏移量的获取可以从一下方式获得
postings list:如果在mapping中index_options设置为offsets,unified高亮器使用此信息高亮显示文档而不用再次分析文本。term vectors:如果我们在mapping中设置term_vector为with_positions_offsets,则unified高亮器会自动使用term_vector来高亮显示,对于大于1M的大字段,使用term_vector速度会很快,fvh高亮器就是使用的term_vector。plain highlighting:当unified没有其他的选择的时候会使用plain模式,它会创建了一个微小的内存索引,并通过Lucene的查询执行计划器重新运行原始查询条件。plain高亮器默认使用的就是此模式
大文本的纯高亮展示可能需要大量的时间和内存,为了防止这种情况,es默认将大文本的字符数量限制为
1000000,可以使用index.highlight.max_analyzed_offset修改此默认设置
一、FVH高亮器简介
FVH(Fast Vector Highlighter)是Elasticsearch高亮器中的一种算法,使用的是Lucene Fast Vector highlighter,它能够快速而准确地在文本中找到匹配的关键词,并将其标记为高亮。相比于其他高亮器算法,FVH在性能上有着显著的优势,特别适用于大规模数据集和高并发的场景。
二、FVH高亮器的使用方法
安装
首先,确保已经正确安装了 Elasticsearch
version: '3.8'
services:cerebro:image: lmenezes/cerebro:0.8.3container_name: cerebroports:- "9000:9000"command:- -Dhosts.0.host=http://eshot:9200networks:- elastickibana:image: docker.elastic.co/kibana/kibana:8.1.3container_name: kibanaenvironment:- I18N_LOCALE=zh-CN- XPACK_GRAPH_ENABLED=true- TIMELION_ENABLED=true- XPACK_MONITORING_COLLECTION_ENABLED="true"- ELASTICSEARCH_HOSTS=http://eshot:9200- server.publicBaseUrl=http://192.168.160.234:5601ports:- "5601:5601"networks:- elasticeshot:image: elasticsearch:8.1.3container_name: eshotenvironment:- node.name=eshot- cluster.name=es-docker-cluster- discovery.seed_hosts=eshot,eswarm,escold- cluster.initial_master_nodes=eshot,eswarm,escold- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- xpack.security.enabled=false- node.attr.node_type=hotulimits:memlock:soft: -1hard: -1volumes:- D:\zuiyuftp\docker\es8.1\eshot\data:/usr/share/elasticsearch/data- D:\zuiyuftp\docker\es8.1\eshot\logs:/usr/share/elasticsearch/logs- D:\zuiyuftp\docker\es8.1\eshot\plugins:/usr/share/elasticsearch/pluginsports:- 9200:9200networks:- elasticeswarm:image: elasticsearch:8.1.3container_name: eswarmenvironment:- node.name=eswarm- cluster.name=es-docker-cluster- discovery.seed_hosts=eshot,eswarm,escold- cluster.initial_master_nodes=eshot,eswarm,escold- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- xpack.security.enabled=false- node.attr.node_type=warmulimits:memlock:soft: -1hard: -1volumes:- D:\zuiyuftp\docker\es8.1\eswarm\data:/usr/share/elasticsearch/data- D:\zuiyuftp\docker\es8.1\eswarm\logs:/usr/share/elasticsearch/logs- D:\zuiyuftp\docker\es8.1\eshot\plugins:/usr/share/elasticsearch/pluginsnetworks:- elasticescold:image: elasticsearch:8.1.3container_name: escoldenvironment:- node.name=escold- cluster.name=es-docker-cluster- discovery.seed_hosts=eshot,eswarm,escold- cluster.initial_master_nodes=eshot,eswarm,escold- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- xpack.security.enabled=false- node.attr.node_type=coldulimits:memlock:soft: -1hard: -1volumes:- D:\zuiyuftp\docker\es8.1\escold\data:/usr/share/elasticsearch/data- D:\zuiyuftp\docker\es8.1\escold\logs:/usr/share/elasticsearch/logs- D:\zuiyuftp\docker\es8.1\eshot\plugins:/usr/share/elasticsearch/pluginsnetworks:- elastic# volumes:
# eshotdata:
# driver: local
# eswarmdata:
# driver: local
# escolddata:
# driver: localnetworks:elastic:driver: bridge
创建索引
在使用FVH高亮器之前,需要先创建一个索引,并将需要高亮的字段进行映射。例如,我们要在content字段中进行高亮,可以使用以下代码:
PUT /example_target
{"mappings": {"properties": {"content": {"type": "text","analyzer": "ik_max_word","term_vector": "with_positions_offsets"},"title": {"type": "text","analyzer": "ik_max_word","term_vector": "with_positions_offsets"}}}
}
添加测试数据
POST example_target/_doc
{"content":"中华人民共和国是否考虑是否就爱上速度加快分解ask计算机卡死撒中华上的飞机拉丝机是的地方记录 卡就是开发建设看积分卡说了句 ask就疯狂萨拉丁就发士大 sdf 看得见啊李开复 圣诞节卡了 夫哈数据库中华啊,中华,人民爱上中华","title":"中华人名共和国"
}
查询并高亮
使用FVH高亮器进行查询和高亮的过程如下所示:
GET example_target/_search
{"query": {"match": {"content": "中华 爱上"}},"highlight": {"pre_tags": "<em>","post_tags": "</em>", "require_field_match": "false", "fields": {"content": {"type": "fvh","fragment_size": 18,"number_of_fragments": 3}}}
}
以上代码中,我们通过match查询找到了包含关键词的文档,然后在highlight内容中指定了需要高亮的字段,这里是content。执行述查询后,Elasticsearch将返回匹配的结果,并在content字段中添加了高亮标记。
数据量少的时候对比不是特别明显,所以在测试时,可以在索引中添加大量的测试数据进行测试,本人在测试过程中es的索引大小在
500M左右,单个字段纯文本大小也有1-2M。此时这种数据规模下使用普通的高亮器在检索请求时就已经非常缓慢了,根据返回的数据量多少来决定,在取10条数据时已经能达到6秒了,但是在使用fvh高亮器之后时间已经进入毫秒级
三、FVH高亮器的参数配置
先看一下返回的数据结果在对照下面参数学习
{"took" : 4,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 0.41193593,"hits" : [{"_index" : "example_target","_id" : "f1rkC4oBCDmhQc2yo6PQ","_score" : 0.41193593,"_source" : {"content" : "中华人民共和国是否考虑是否就爱上速度加快分解ask计算机卡死撒中华上的飞机拉丝机是的地方记录 卡就是开发建设看积分卡说了句 ask就疯狂萨拉丁就发士大 sdf 看得见啊李开复 圣诞节卡了 夫哈数据库中华啊,中华,人民爱上中华"},"highlight" : {"content" : ["<em>中华</em>人民共和国是否考虑是否就<em>爱上</em>速度","sk计算机卡死撒<em>中华</em>上的飞机拉丝机是的地方记录","夫哈数据库<em>中华</em>啊,<em>中华</em>,人民<em>爱上</em>中华"]}},{"_index" : "example_target","_id" : "G3Fi44kB4IVEhjafHXOf","_score" : 0.33311102,"_source" : {"content" : "中华人民共和国是否考虑是否就爱上速度加快分解ask计算机卡死撒中华上的飞机拉丝机是的地方记录卡就是开发建设看积分卡说了句ask就疯狂萨拉丁就发士大夫哈数据库"},"highlight" : {"content" : ["<em>中华</em>人民共和国是否考虑是否就<em>爱上</em>速度","sk计算机卡死撒<em>中华</em>上的飞机拉丝机是"]}},{"_index" : "example_target","_id" : "HHFt44kB4IVEhjafE3Ov","_score" : 0.31932122,"_source" : {"content" : "中华人民共和国是否考虑是否就爱上速度加快分解ask计算机卡死撒中华上的飞机拉丝机是的地方记录 卡就是开发建设看积分卡说了句 ask就疯狂萨拉丁就发士大 sdf 看得见啊李开复 圣诞节卡了 夫哈数据库"},"highlight" : {"content" : ["<em>中华</em>人民共和国是否考虑是否就<em>爱上</em>速度","sk计算机卡死撒<em>中华</em>上的飞机拉丝机是的地方记录"]}}]}
}通过上面的查询请求中高亮参数的指定可以发现,高亮器还是支持其他的参数的,那么我们下面将对几个常用的参数进行说明
-
fragment_size:指定每个高亮片段的长度,默认为100个字符。 -
number_of_fragments:指定返回的高亮片段数量,默认为5个。 -
pre_tags和post_tags:分别指定高亮标记的前缀和后缀,默认为<em>和</em>。 -
require_field_match:指定是否要求所有字段都匹配关键词才进行高亮,默认为true。可以开启关闭此参数对上面的title字段进行校验 -
type:指定fvh高亮器,除了fvh之外还有unified,plain。unified是默认的高亮器,可以将文本分解为句子,并使用BM25算法对单个句子进行评分,还支持精确的短语高亮显示,支持(fuzzy,prefix,regex)高亮。plain普通的高亮器,适用与简单的查询或者单个字段的匹配。为了准确的反应查询逻辑,它会在内存中创建一个很小的索引,来对原始的查询语句进行执行,来访问当前更低级别的匹配信息。
在使用FVH高亮器时,根据实际需求,可以灵活地调整这些参数,以获得最佳的高亮效果。
总结
通过本文的介绍,我们了解了Elasticsearch高亮器中的FVH算法,并学会了如何使用它为搜索结果增添亮点。FVH高亮器在性能和功能上都有着明显的优势,对于大规模数据集和高并发的场景尤为适用。希望读者通过本文的指引,能够更好地利用FVH高亮器来提升搜索结果的可读性和用户体验。
参考链接
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/highlighting.html
如果感觉本文对你有所帮助欢迎点赞评论转发收藏。如果你想了解更多关于ES的骚操作,更多实战经验,欢迎关注。

原文链接
https://mp.weixin.qq.com/s?__biz=MzIwNzYzODIxMw==&mid=2247486065&idx=1&sn=28ee03fd0e297eb0c5d62405446d4551&chksm=970e11dba07998cd53a3a16e39e396172c3e3b46f96bab0e097eeab08fefb93c63b0d48fe380#rd
相关文章:
如何优化因为高亮造成的大文本(大字段)检索缓慢问题
首先还是说一下背景,工作中用到了 elasticsearch 的检索以及高亮展示,但是索引中的content字段是读取的大文本内容,所以后果就是索引的单个字段很大,造成单独检索请求的时候速度还可以,但是加入高亮之后检索请求的耗时…...

HTML <table> 标签
实例 一个简单的 HTML 表格,包含两行两列: <table border="1"><tr><th>Month</th><th>Savings</th></tr><tr><td>January</td><td>$100</td></tr> </table>定义和用法 &l…...
ubuntu pdf阅读器okular
sudo apt-get install okular安装完毕后,使用如下命令浏览pdf文档 okular xxx.pdf...

根据源码,模拟实现 RabbitMQ - 虚拟主机 + Consume设计 (7)
目录 一、虚拟主机 Consume设计 1.1、承接问题 1.2、具体实现 1.2.1、消费者订阅消息实现思路 1.2.2、消费者描述自己执行任务方式实现思路 1.2.3、消息推送给消费者实现思路 1.2.4、消息确认 一、虚拟主机 Consume设计 1.1、承接问题 前面已经实现了虚拟主机大部分功…...

docker中bridge、host、container、none四种网络模式简介
目录 一.bridge模式 1.简介 2.演示 (1)运行两个容器,不指定网络模式情况下默认是bridge模式 (2)在主机中自动生成了两个veth设备 (3)查看两个容器的IP地址 (4)可以…...
排序算法之详解冒泡排序
引入 冒泡排序顾名思义,就是像冒泡一样,泡泡在水里慢慢升上来,由小变大。虽然冒泡排序和冒泡并不完全一样,但却可以帮助我们理解冒泡排序。 思路 一组无序的数组,要求我们从小到大排列 我们可以先将最大的元素放在数组…...

el-upload组件调用后端接口上传文件实践
要点说明: 使用:http-request覆盖默认的上传行为,可以添加除文件外的其他参数,注意此时仍需保留action属性,action可以传个空串给http-request属性绑定的函数,函数入参必须为param调用接口请求,注意 heade…...

深度学习-实验1
一、Pytorch基本操作考察(平台课专业课) 使用𝐓𝐞𝐧𝐬𝐨𝐫初始化一个 𝟏𝟑的矩阵 𝑴和一个 𝟐𝟏的矩阵 𝑵&am…...
互联网医院开发|医院叫号系统提升就医效率
在这个数字化时代,互联网医院不仅改变了我们的生活方式,也深刻影响着医疗行业。医院叫号系统应运而生,它能够有效解决患者管理和服务方面的难题。不再浪费大量时间在排队上,避免患者错过重要信息。同时,医护工作效率得…...
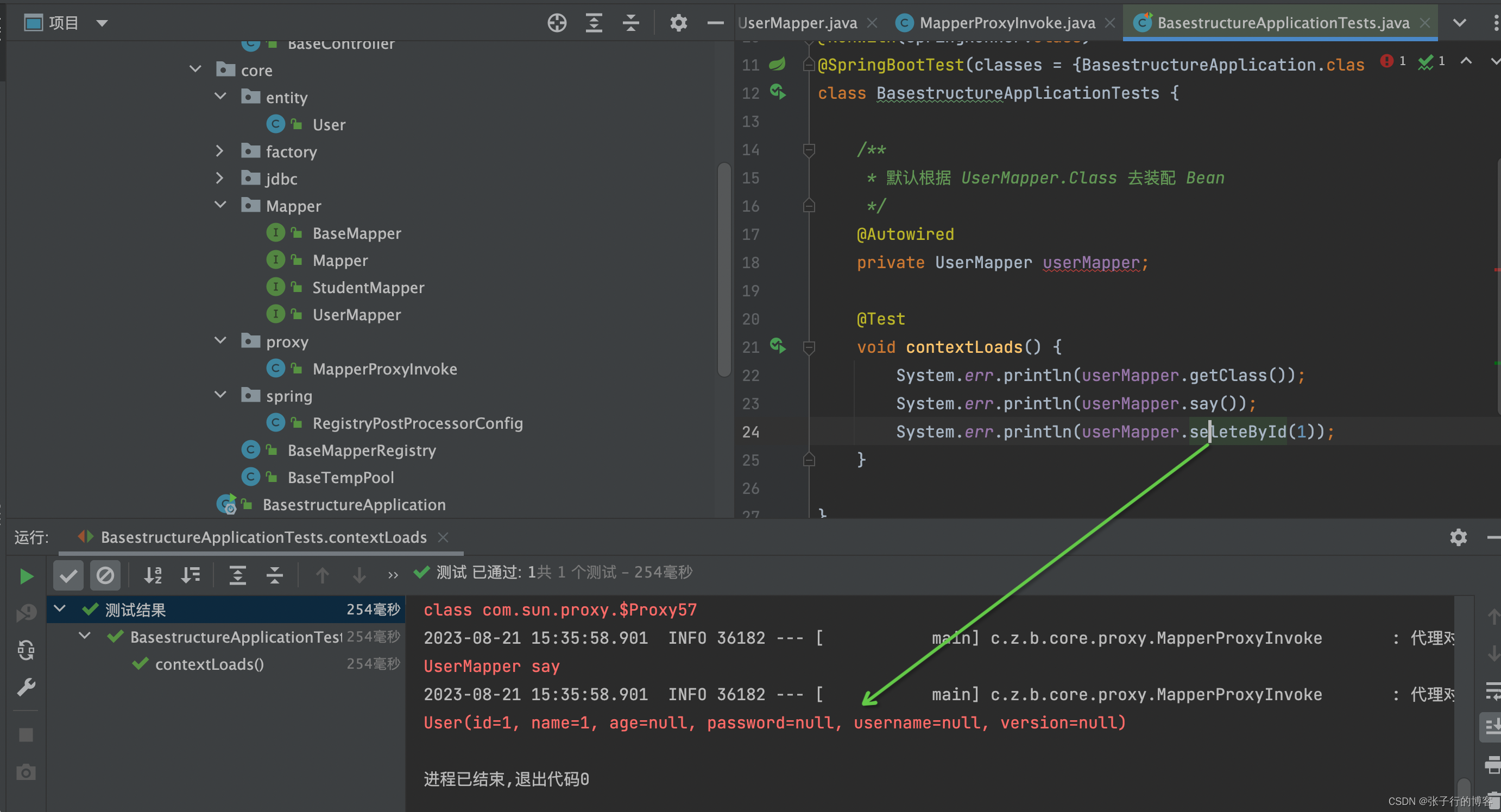
手写 Mybatis-plus 基础架构(工厂模式+ Jdk 动态代理统一生成代理 Mapper)
这里写目录标题 前言温馨提示手把手带你解析 MapperScan 源码手把手带你解析 MapperScan 源码细节剖析工厂模式Jdk 代理手撕脚手架,复刻 BeanDefinitionRegistryPostProcessor手撕 FactoryBean代理 Mapper 在 Spring 源码中的生成流程手撕 MapperProxyFactory手撕增…...

【C++11算法】iota算法
文章目录 前言一、iota函数1.1 iota是什么?1.2 函数原型1.3 参数和返回值1.4 示例代码1.5 示例代码21.6 示例代码3 总结 前言 C标准库提供了丰富的算法,其中之一就是iota算法。iota算法用于填充一个区间,以递增的方式给每个元素赋予一个值。…...

付费加密音乐格式转换Mp3、Flac工具
一、工具介绍 这是一款免费的将付费加密音乐等多种格式转换Mp3 Flac工具,现在大部分云音乐公司,比如QQ音乐、酷我音乐、酷狗音乐、网易云音乐、虾米音乐(RIP🙏)等,都推出了自己专属的云音乐格式,这些格式一般只能在制定的播放器里播放,其它的播放软件并不支持,在很多情…...
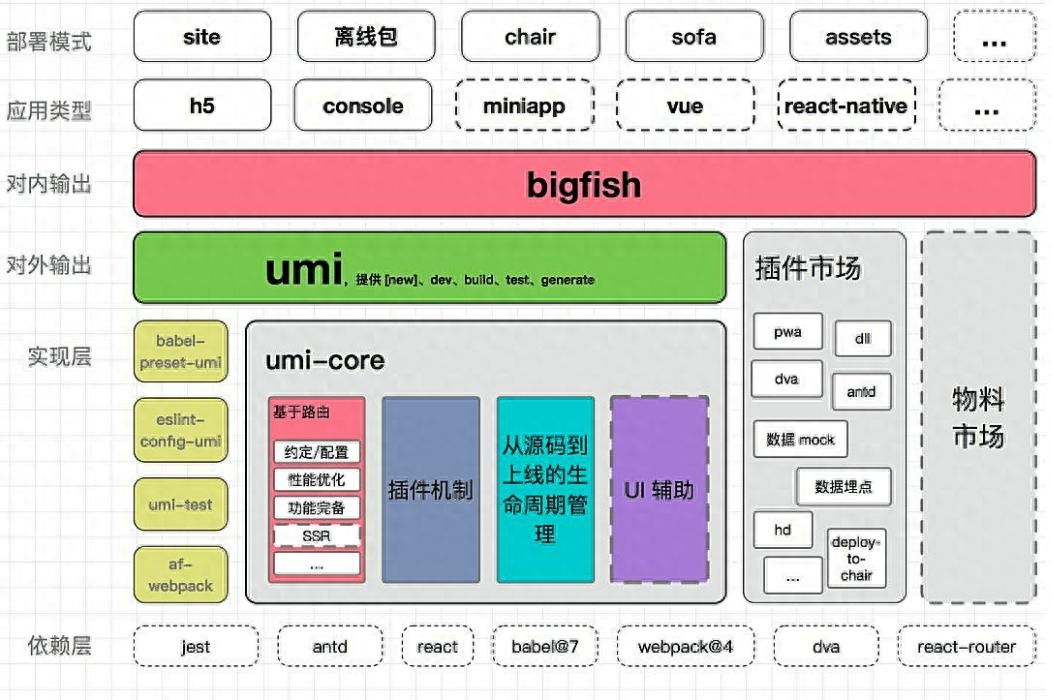
React前端开发架构:构建现代响应式用户界面
在当今的Web应用开发中,React已经成为最受欢迎的前端框架之一。它的出色性能、灵活性和组件化开发模式,使得它成为构建现代响应式用户界面的理想选择。在这篇文章中,我们将探讨React前端开发架构的核心概念和最佳实践,以帮助您构建…...
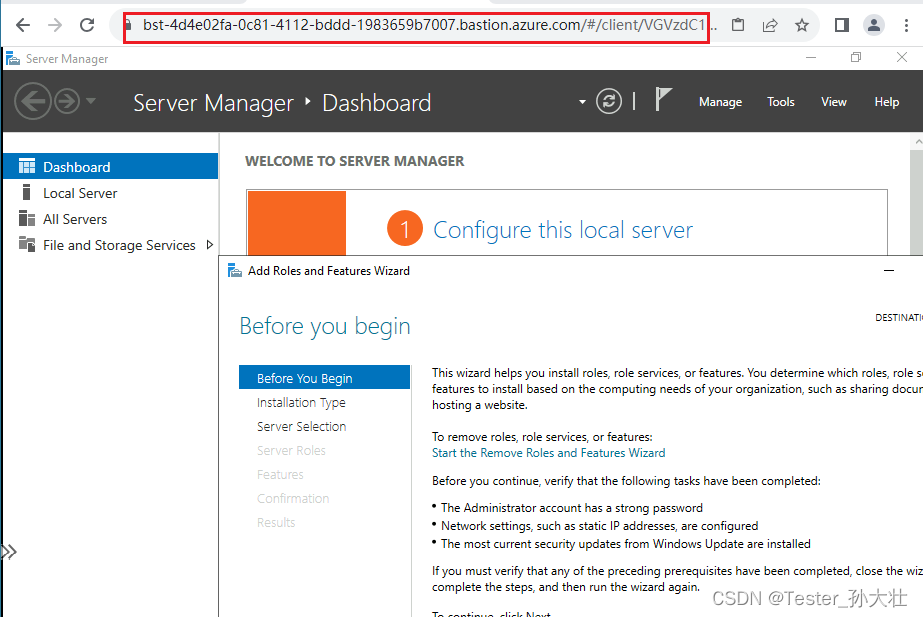
Azure Bastion的简单使用
什么是Azure Bastion Azure Bastion 是一个提供安全远程连接到 Azure 虚拟机(VM)的服务。传统上,访问 VM 需要使用公共 IP 或者设立 VPN 连接,这可能存在一些安全风险。Azure Bastion 提供了一种更安全的方式,它是一个…...

深入理解高并发编程 - 深度解析ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor 继承自 ThreadPoolExecutor 并实现了 ScheduledExecutorService 接口,这使得它可以同时充当线程池和定时任务调度器。 构造方法 public ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE, 0, …...
Android---- 一个完整的小项目(消防app)
前言: 针对不同群体的需求,想着应该拓展写方向。医疗app很受大家喜欢,就打算顺手写个消防app,里面基础框架还是挺简洁 规整的。登陆注册和本地数据库写的便于大家理解。是广大学子的毕设首选啊! 此app主要为了传递 消防…...
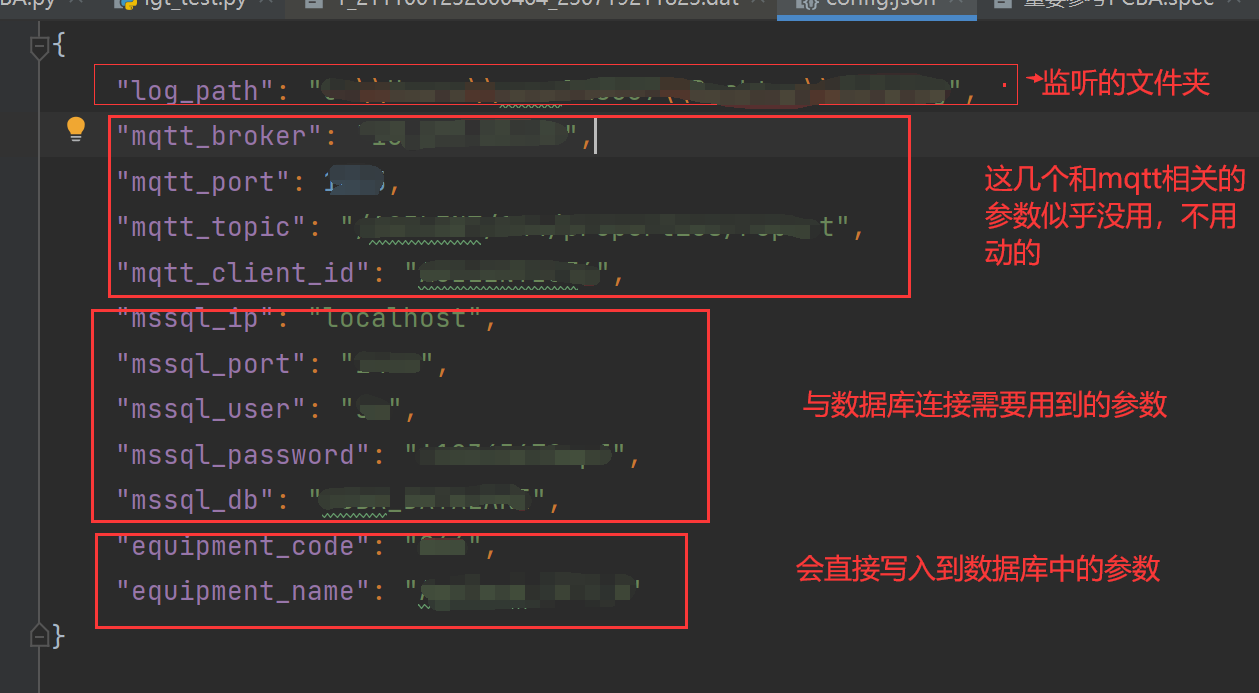
XXX程序 详细说明
用于记录理解PC程序的程序逻辑 1、程序的作用 根据原作者的说明(文件说明.txt),该程序 (PC.py) 的主要作用是提取某一个文件夹中的某个设备 (通过config中的信息看出来是Ag_T_8) 产生的日志文件,然后提取其中某些需要的数据&…...

perl下载与安装教程【工具使用】
Perl是一个高阶程式语言,由 Larry Wall和其他许多人所写,融合了许多语言的特性。它主要是由无所不在的 C语言,其次由 sed、awk,UNIX shell 和至少十数种其他的工具和语言所演化而来。Perl对 process、档案,和文字有很强…...

Chrome谷歌浏览器修改输入框自动填充样式
Chrome谷歌浏览器修改输入框自动填充样式 背景字体 背景 input:-webkit-autofill{-webkit-box-shadow:0 0 0 1000px #fff inset !important; }字体 input:-internal-autofill-selected {-webkit-text-fill-color: #000 !important; }...
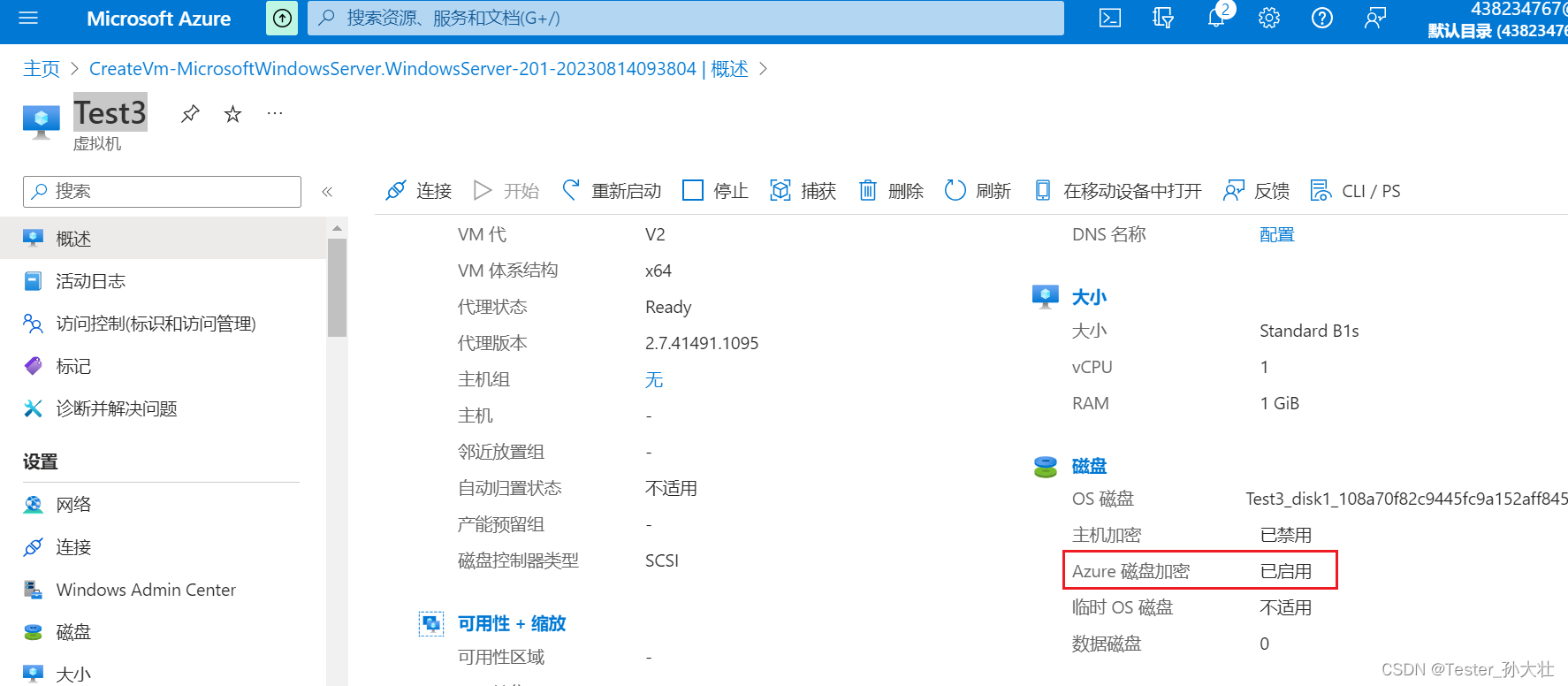
Azure CLI 进行磁盘加密
什么是磁盘加密 磁盘加密是指在Azure中对虚拟机的磁盘进行加密保护的一种机制。它使用Azure Key Vault来保护磁盘上的数据,以防止未经授权的访问和数据泄露。使用磁盘加密,可以保护磁盘上的数据以满足安全和合规性要求。 参考文档:https://l…...

每日 AI 研究简报 · 2026-05-10
(本文借助 AI 大模型及工具辅助整理) 一句话总结:Anthropic 新架构让模型「做梦」反思、MoE 专家池共享设计突破线性增长假设、AI Agent 工具栈开源井喷——今天的信号指向「模块化」与「可组合性」。 🌊 AI 动态与趋势 本周技…...

PIC18F4550微控制器实现USB大容量存储设备设计
1. USB大容量存储设备设计概述USB大容量存储设备(Mass Storage Device,MSD)已成为现代数字生活中不可或缺的组成部分。从U盘到移动硬盘,这类设备的核心都是基于USB Mass Storage Class协议实现的。本文将深入探讨如何利用PIC18F45…...
)
参考文献列表(近现代当代中国篇)
参考文献列表(近现代当代中国篇)0. 无。为什么是空的?——因为鄙视。岐金兰鄙视近现代当代中国绝大多数思想者。不是个人恩怨,不是学术门户,而是对“构建学术实体”这一集体执念的鄙视。他们中的大多数,终其…...

GLM-ASR开源语音识别引擎:基于GLM架构的端到端实践指南
1. 项目概述:一个开源的、基于GLM架构的语音识别引擎最近在语音识别(ASR)这个圈子里,一个名为“GLM-ASR”的开源项目引起了我的注意。它来自zai-org组织,顾名思义,其核心是将自然语言处理领域大放异彩的GLM…...

Python全栈学习路径:从基础语法到FastAPI实战部署
1. 从零到一:我的Python全栈学习路径与实战心得大家好,我是Brais Moure,一名有十多年经验的全栈工程师。过去几年,我一直在Twitch和YouTube上直播编程,并整理了一套完整的Python学习课程,也就是“Hello-Pyt…...

法律即代码:开源项目vericlaw如何用规则引擎实现合同自动化
1. 项目概述与核心价值最近在折腾一些自动化流程,特别是涉及到合同、协议这类法律文书的生成与审核时,发现了一个挺有意思的开源项目:Sheygoodbai/vericlaw。乍一看这个名字,结合其仓库描述,就能猜到它大概和法律&…...

动态紧凑模型在电子热设计中的高效应用
1. 动态紧凑模型在电子热设计中的核心价值在电子设备日益小型化、高功率化的今天,热管理已成为决定产品可靠性的关键因素。传统热仿真方法面临两大痛点:一是计算资源消耗大,特别是处理复杂封装结构时;二是难以准确预测半导体器件的…...

GEE筛选行政区的两种野路子:手绘个圈圈或者随便点个点,就能搞定研究区边界
GEE自定义研究区边界:交互式绘图与动态筛选实战指南 当研究区域无法用标准行政区划描述时,传统GIS工作流程往往陷入数据准备的泥潭。本文介绍两种Google Earth Engine(GEE)中高效定义不规则边界的创新方法,特别适合生态…...

灵魂面甲修改器 2026最新版42项功能
下载地址:https://pan.quark.cn/s/81c8f13901b3 毒盘 支持最新版本,风灵月影42项功能拉满,支持最新版本,Steam/EPIC/学习版全适配! 【5月9日的最新版本不会闪退!全网最新版本!】 ✅ 非软件丨无…...

算法复杂度的实验估算与误差分布建模的技术7
引言算法复杂度分析的理论背景与实验估算的必要性误差来源的常见类型(测量误差、系统噪声、模型偏差等)实验方法在算法评估中的实际意义实验设计与数据采集实验环境配置(硬件、软件、数据集选择)关键性能指标定义(时间…...