【Hibench 】完成 HDP-Spark 性能测试

🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁
🦄 个人主页——🎐开着拖拉机回家_Linux,Java基础学习,大数据运维-CSDN博客 🎐✨🍁
🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
目录
🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁
一、HiBench简介
二、版本和依赖
三、下载和编译
3.1 下载安装包
3.2 HiBench编译
3.3 Hibench目录说明
四、修改配置文件
4.1 hibench.conf
4.2 hadoop.conf
4.3 spark.conf
五、运行测试
5.1 准备数据
5.2 运行测试
5.3 report结果查询
六、遇到的问题
一、HiBench简介
HiBench是Intel推出的一个大数据基准测试工具,可以帮助评估不同的大数据框架在速度、吞吐量和系统资源利用方面评估不同的大数据框架的性能表现。它包含一组Hadoop、Spark和流式WorkLoads,包括Sort、WordCount、TeraSort、Repartition、Sleep、SQL、PageRank、Nutch索引、Bayes、Kmeans、NWeight和增强型DFSIO等。它还包含几个用于Spark Streaming、Flink、Storm和Gearpump的流式WorkLoads。
项目GitHub地址:GitHub - Intel-bigdata/HiBench: HiBench is a big data benchmark suite.
二、版本和依赖
| 软件 | 版本 |
| hadoop | 2.10(官方要求Apache Hadoop 3.0.x, 3.1.x, 3.2.x, 2.x, CDH5, HDP) |
| maven | 3.8.5 |
| java | 8 |
| python | 2.7.5 |
HDP 集群版本信息
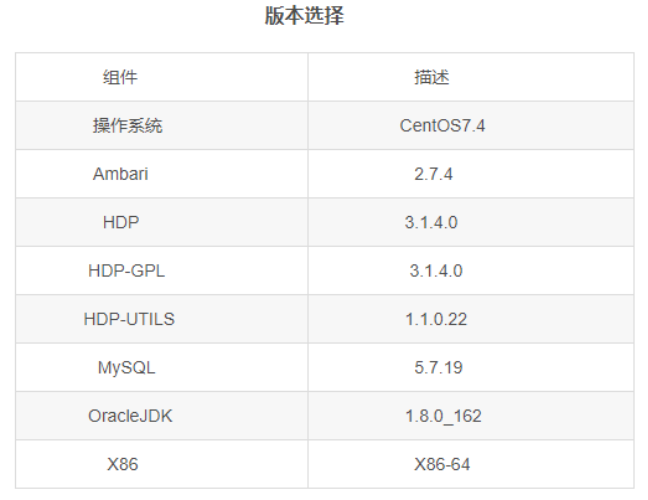
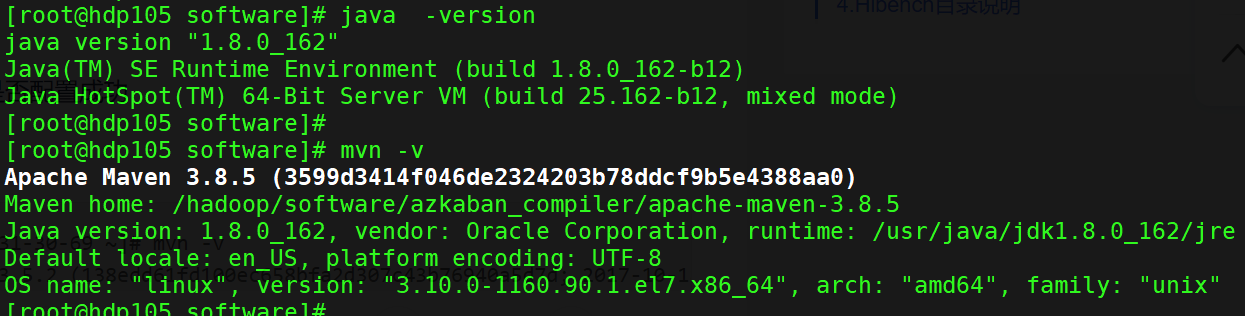
Java 和Maven 环境配置
三、下载和编译
3.1 下载安装包
cd /opt
下载并解压wget https://github.com/Intel-bigdata/HiBench/archive/v7.1.1.tar.gz
tar -zxvf v7.1.1.tar.gz
cd HiBench-7.1.1/
3.2 HiBench编译
HiBench编译支持如下几种方式:
- Build All
- Build a specific framework benchmark
- Build a single module
- Build Structured Streaming
在进行Hibench的时候可以指定Spark和Scala的版本,通过如下参数指定
具体参考官网: https://github.com/Intel-bigdata/HiBench/blob/master/docs/build-hibench.md
# 执行全部编译 编译所有框架及模块
./bin/build_all.sh
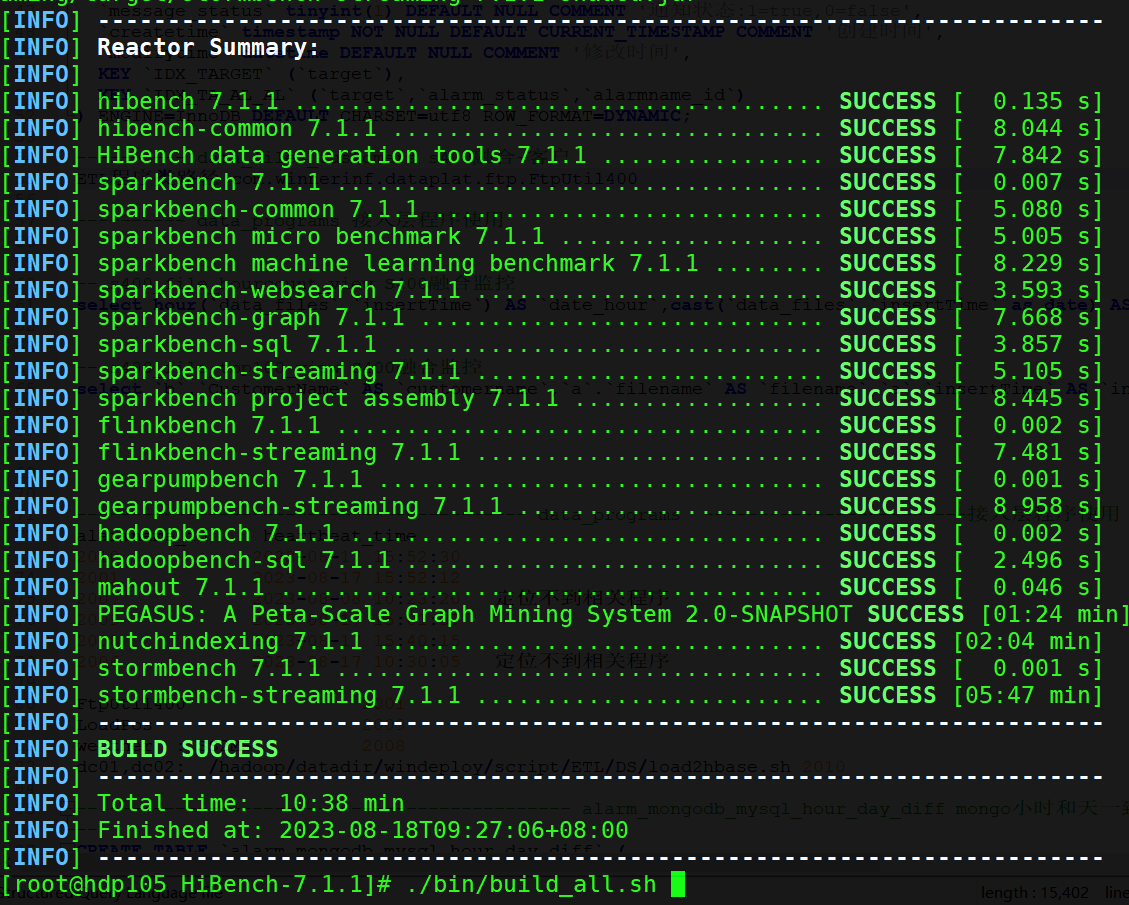
3.3 Hibench目录说明
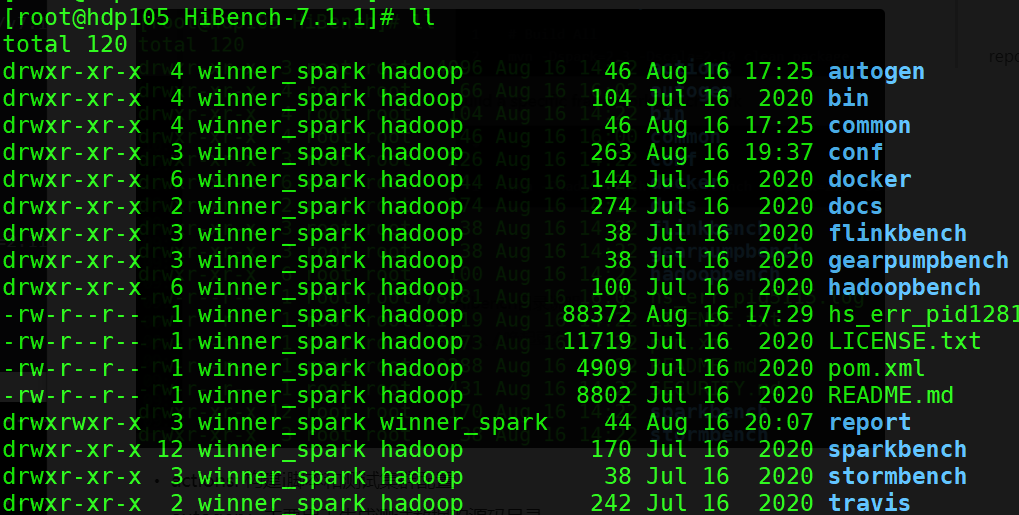
- autogen:主要用于生成测试数据的源码目录
- bin:测试脚本放置目录
- common:公共依赖源码目录
- conf:配置文件目录(Hibench/Hadoop/Spark等配置文件存放目录)
- docker:docker 方式部署
- flinkbench:Flink框架源码目录
- gearpumpbench:gearpumpbench框架源码目录
- hadoopbench:hadoop框架源码目录
- sparkbench:spark框架的源码目录
- stormbench:storm框架的源码目录
四、修改配置文件
4.1 hibench.conf
hibench.conf 配置数据集大小和并行度
hibench.scale.profile tiny
# Mapper number in hadoop, partition number in Spark
hibench.default.map.parallelism 8# Reducer nubmer in hadoop, shuffle partition number in Spark
hibench.default.shuffle.parallelism 8- hibench.scale.profile:主要配置HiBench测试的数据规模,可自定义配置;
- hibench.default.map.parallelism:主要配置MapReduce的Mapper数量;
- hibench.default.shuffle.parallelism:配置Reduce数量;
HiBench的默认数据规模有:tiny, small, large, huge, gigantic andbigdata,在这几种数据规模之外还可以自己指定数据量。
4.2 hadoop.conf
hadoop.conf,配置hadoop集群的相关信息(如下为HDP集群配置)
cp conf/hadoop.conf.template conf/hadoop.confvim conf/hadoop.conf
# Hadoop home
hibench.hadoop.home /usr/hdp/3.1.4.0-315/hadoop# The path of hadoop executable
hibench.hadoop.executable ${hibench.hadoop.home}/bin/hadoop# Hadoop configraution directory
hibench.hadoop.configure.dir ${hibench.hadoop.home}/etc/hadoop# The root HDFS path to store HiBench data
hibench.hdfs.master hdfs://winner# Hadoop release provider. Supported value: apache, cdh5, hdp
hibench.hadoop.release hdphibench.hdfs.master 可以在 core-site.xml中的 fs.defaultFS 找到,开启了NameNode高可用 。
4.3 spark.conf
spark.conf,配置hadoop集群的相关信息
cp conf/spark.conf.template conf/spark.conf
vim conf/spark.conf# Spark home
hibench.spark.home /usr/hdp/3.1.4.0-315/spark2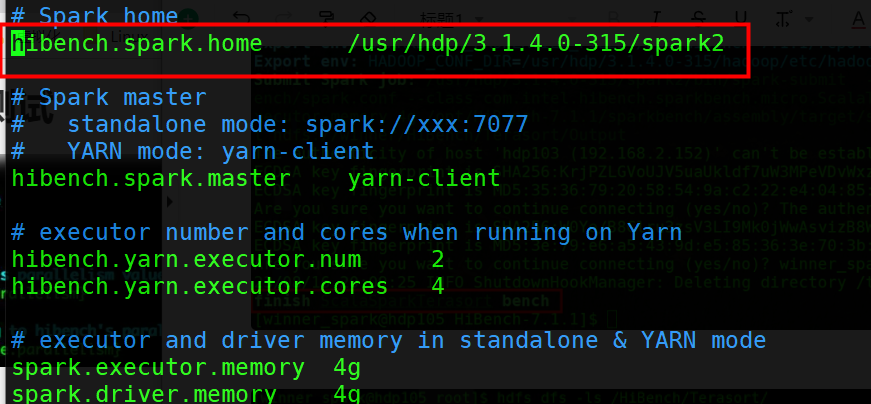
可自定义数据规模
conf/workloads/micro/terasort.conf
#datagen
hibench.terasort.tiny.datasize 32000
hibench.terasort.small.datasize 3200000
hibench.terasort.large.datasize 32000000
hibench.terasort.huge.datasize 320000000
hibench.terasort.gigantic.datasize 3200000000
hibench.terasort.bigdata.datasize 6000000000hibench.workload.datasize ${hibench.terasort.${hibench.scale.profile}.datasize}
## 增加自定义的数据量
#hibench.terasort.myscale.datasize 5242880
#hibench.workload.datasize ${hibench.terasort.${hibench.scale.profile}.datasize}# export for shell script
hibench.workload.input ${hibench.hdfs.data.dir}/Terasort/Input
hibench.workload.output ${hibench.hdfs.data.dir}/Terasort/Output在 hibench.conf 中 设置 hibench.scale.profile 为 myscale ,默认为 tiny
五、运行测试
5.1 准备数据
HDP 集群开启了 kerberos , 运行脚本使用了 kerberos 用户。如下生成一个WordCount测试数据集。
bin/workloads/micro/wordcount/prepare/prepare.sh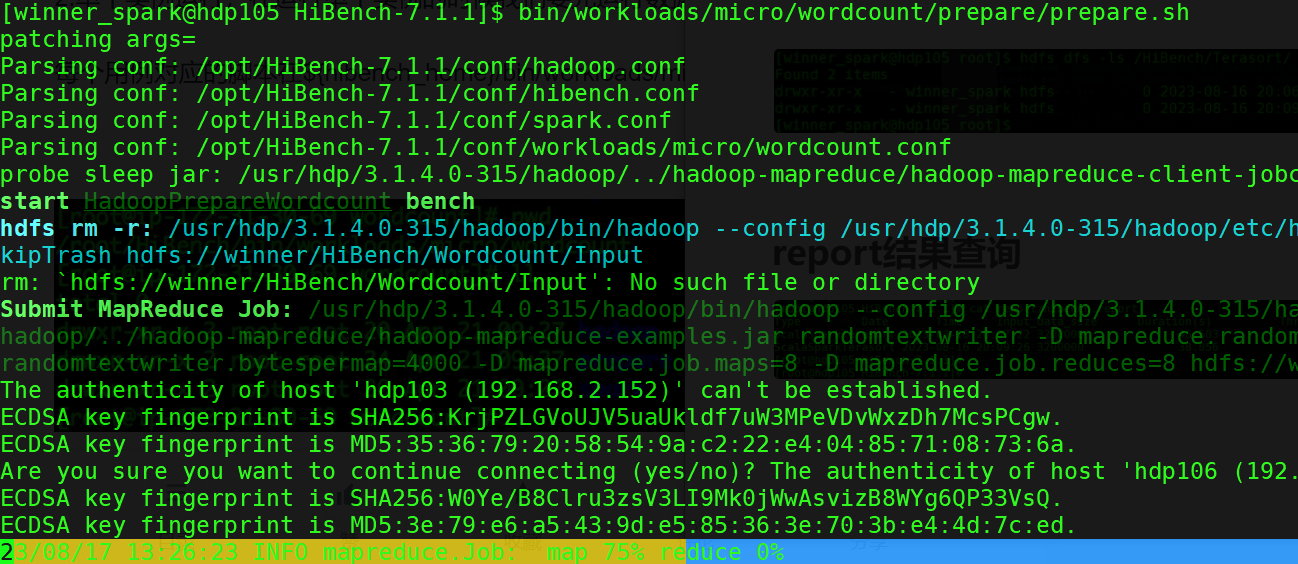
5.2 运行测试
将WordCount基准测试数据集生成后,就可以执行基准测试了,对于WordCount基准测试选择了Spark 运行以下命令即可:
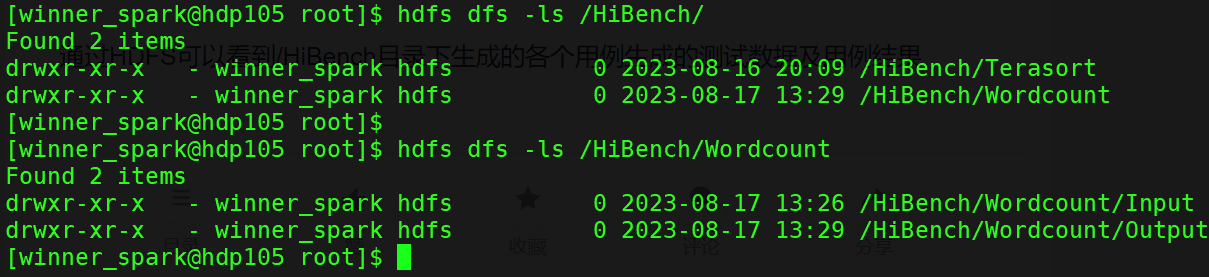
bin/workloads/micro/terasort/spark/run.sh通过HDFS可以看到/HiBench目录下生成的各个用例生成的测试数据及用例结果
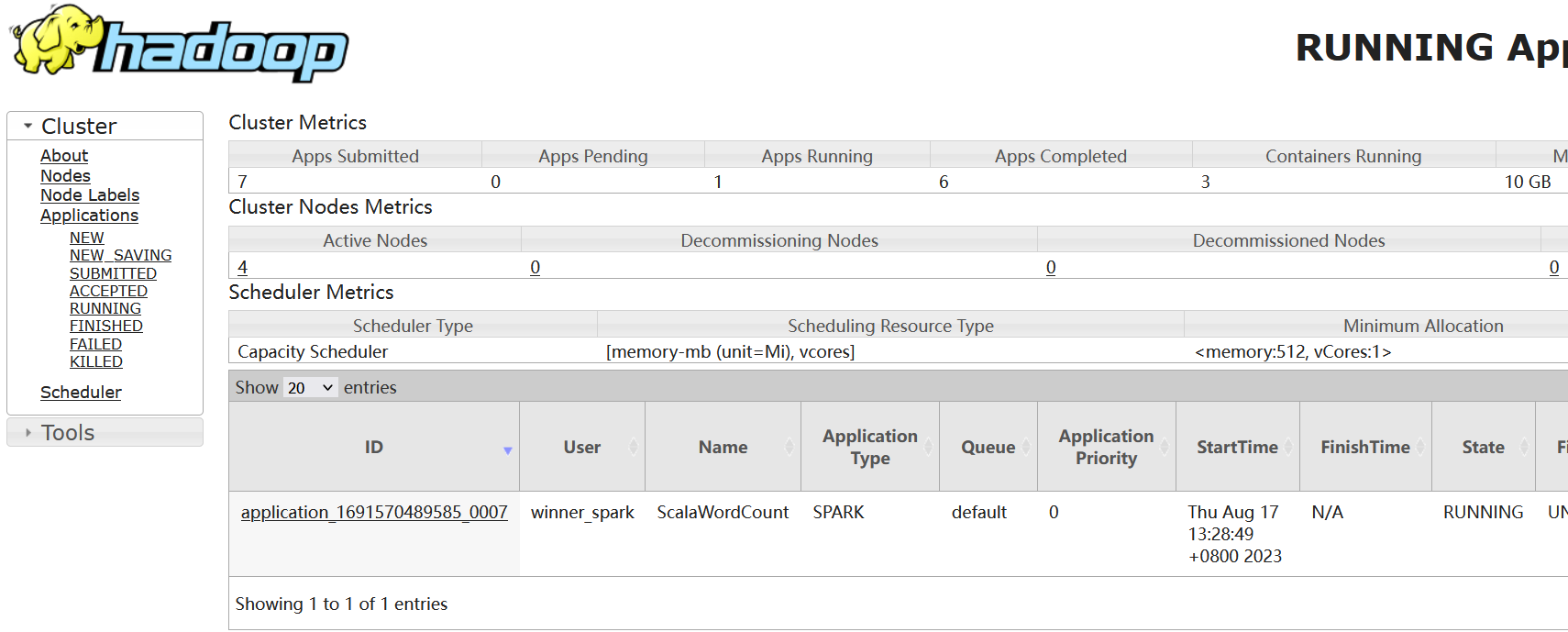
YARN 可以到 任务 ScalaWordCount
5.3 report结果查询
[root@hdp105 HiBench-7.1.1]# cat report/hibench.report
Type Date Time Input_data_size Duration(s) Throughput(bytes/s) Throughput/node
ScalaSparkTerasort 2023-08-16 20:07:22 3200000 46.503 68812 17203
ScalaSparkTerasort 2023-08-16 20:09:26 3200000 38.856 82355 20588
ScalaSparkWordcount 2023-08-17 13:29:46 37181 66.082 562 140 ScalaSparkWordcount 数据大小37181 ,运行时间66.082 ·。 每个用例的测试数据量、运行耗时及吞吐量。如下是生成的日志和统计的指标文件:

即将 wordCount 使用Spark 运行后的 monitor.html 下载到本地 拖到浏览器
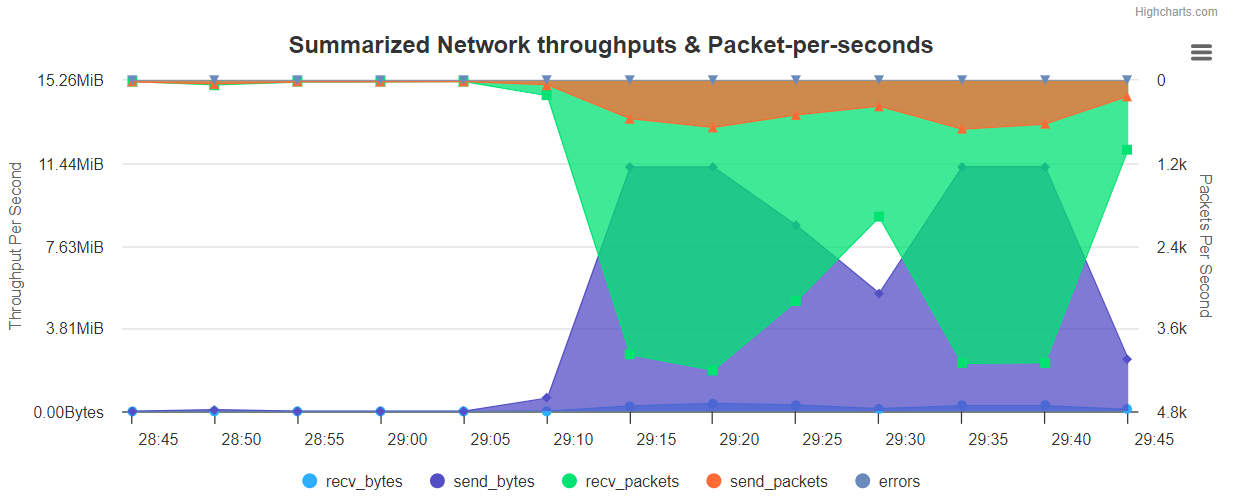
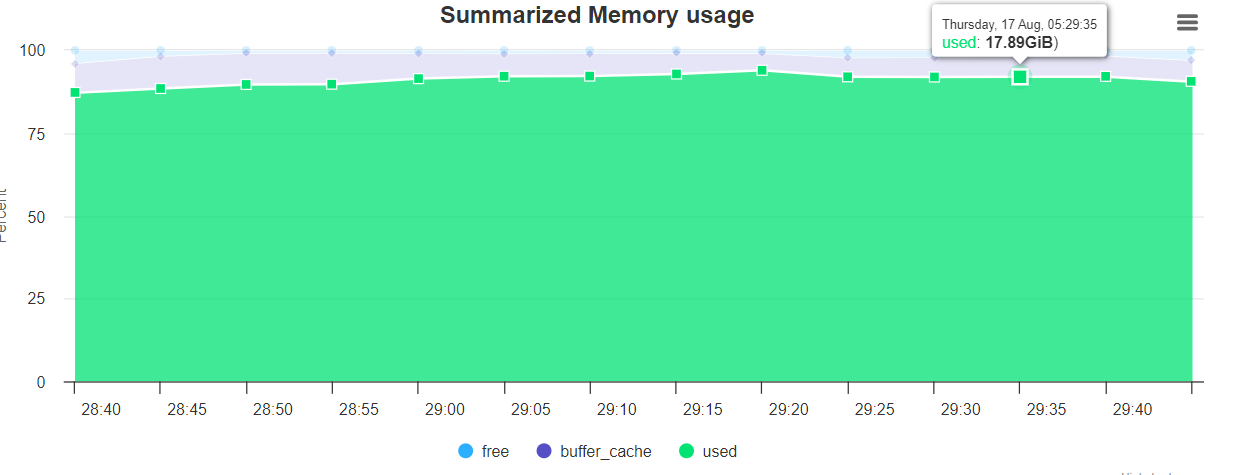
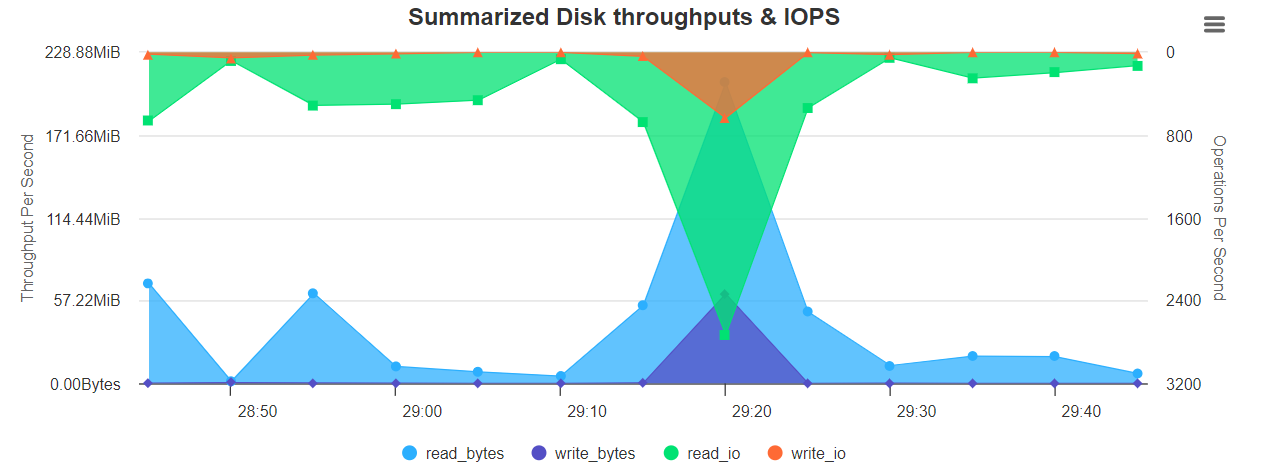
/opt/HiBench-7.1.1/report/wordcount/spark/monitor.html图表展示如下:
Summarized Network throughputs & Packer-per-sedonds
Summarized Memory usage
Summarized Disk throughput & IOPS
六、遇到的问题
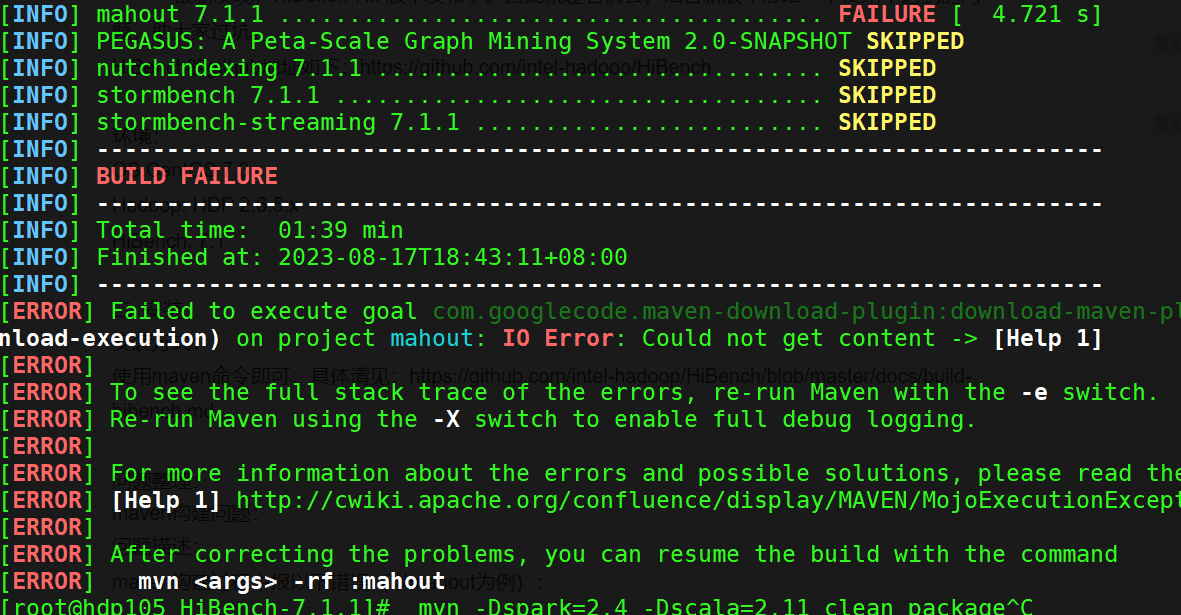
build 的时候遇到了 插件下载不了的问题 ,问题如下:
[INFO] mahout 7.1.1 ....................................... FAILURE [ 7.767 s]
[INFO] PEGASUS: A Peta-Scale Graph Mining System 2.0-SNAPSHOT SKIPPED
[INFO] nutchindexing 7.1.1 ................................ SKIPPED
[INFO] stormbench 7.1.1 ................................... SKIPPED
[INFO] stormbench-streaming 7.1.1 ......................... SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 03:07 min
[INFO] Finished at: 2023-08-17T18:56:25+08:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal com.googlecode.maven-download-plugin:download-maven-plugin:1.2.0:wget (extra-download-execution) on project mahout: IO Error: Could not get content -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <args> -rf :mahout
报错截图如下:
修改pom文件
hadoopbench/mahout/pom.xml 解决方式: 就是 把插件下载build 部分删除 ,我不用你就行了, 无非构建 慢点。
参考链接:HiBench 7.x 使用问题整理
HiBench大数据基准测试使用 - 知乎
如何使用HiBench进行基准测试_51CTO博客_基准测试
相关文章:
【Hibench 】完成 HDP-Spark 性能测试
🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁 🦄 个人主页——🎐开着拖拉机回家_Linux,Java基础学习,大数据运维-CSDN博客 🎐✨🍁 🪁🍁 希望本文能够给您带来一定的…...
【C++奇遇记】内存模型
🎬 博客主页:博主链接 🎥 本文由 M malloc 原创,首发于 CSDN🙉 🎄 学习专栏推荐:LeetCode刷题集 数据库专栏 初阶数据结构 🏅 欢迎点赞 👍 收藏 ⭐留言 📝 如…...

Debootstrap 教程
文章目录 Debootstrap 教程安装 debootstrap使用 debootstrap运行 debootstrap进入新的系统结束语 Debootstrap 教程 debootstrap 是一个用于在 Debian-based 系统上创建一个基本的 Debian 系统的工具。它可以用于创建 chroot 环境、容器或者为新的系统安装做准备。 安装 deb…...
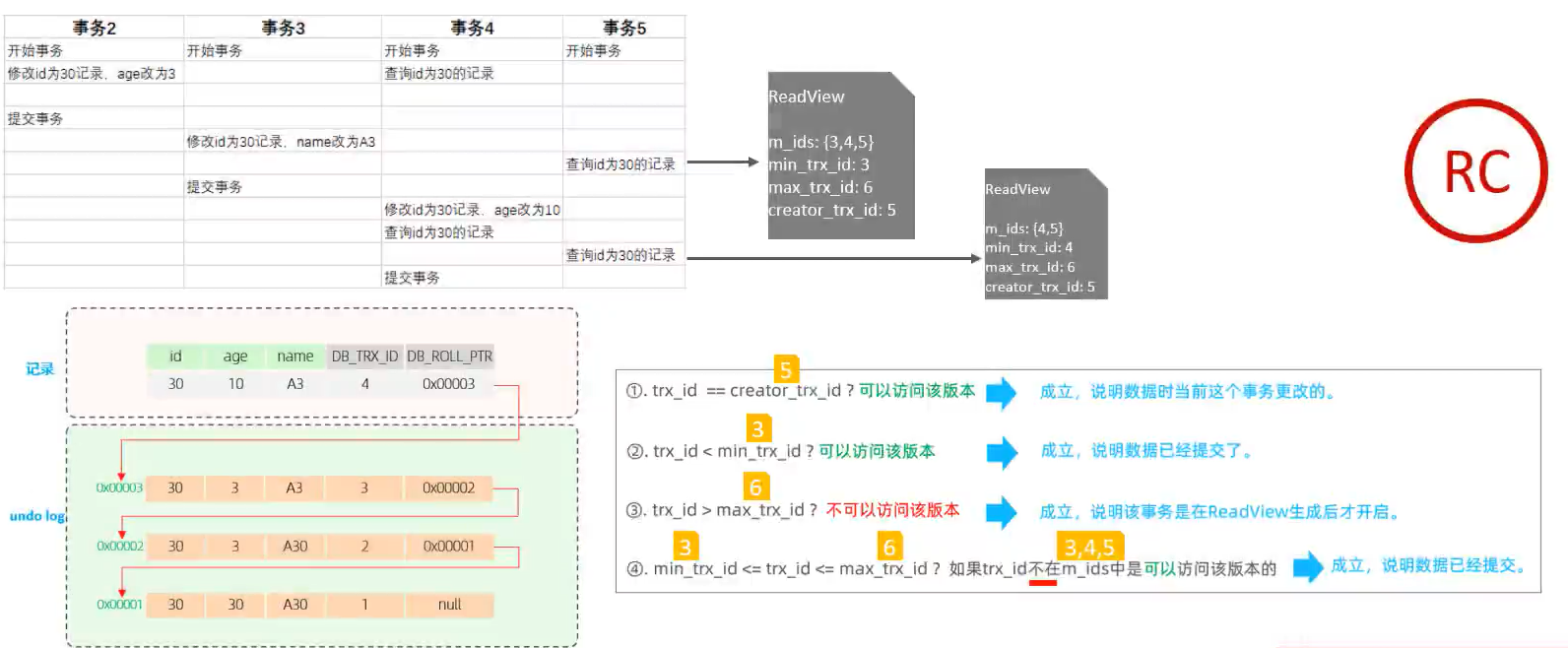
MySQL之InnoDB引擎
MySQL之InnoDB引擎 简介逻辑存储结构InnoDB架构内存架构缓冲池LRU List、Free List和Flush List更改缓冲区(在5.x版本之前叫做插入缓冲区)自适应hash日志缓冲区 磁盘架构System TablespaceFile Per Table TabspaceGeneral TablespceUndo TablespaceTemp …...

API自动化管理: 从繁琐到轻松
在数字化时代,API(应用程序编程接口)在软件开发中扮演着至关重要的角色。然而,API管理可能会变得十分繁琐,耗费大量时间和资源。那么,如何实现API自动化管理,从而节省时间、提高效率,…...
Databend 开源周报第 107 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 理解连接参数 …...

计算机网络参考模型
目录 编辑 简介 1.分层模型 1.1 分层的思想 1.2 OSI参考模型与TCP/IP协议簇 1.OSI 参考模型 2.TCP/IP 参考模型 简介 本章大家将学习网络参考模型的概念,对干参考模型的讲解将会贯穿网络课程的始终,因为它是理解网络这个全新世界的关键所在&…...
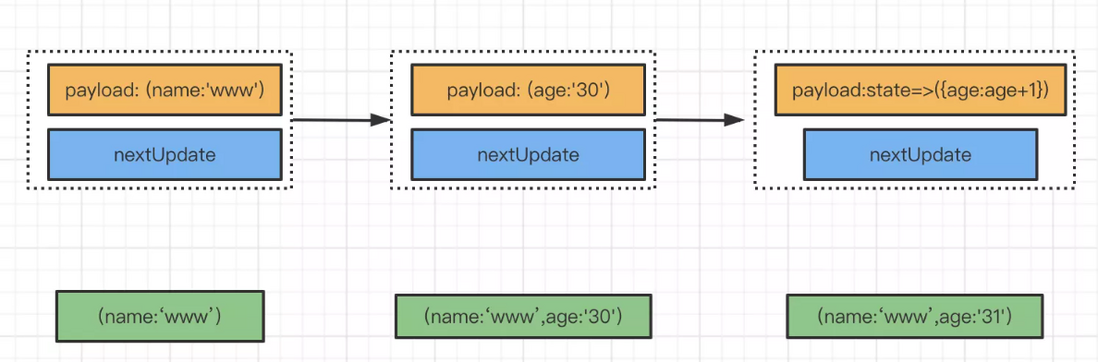
【React基础全篇】
文章目录 一、关于 React二、脚手架2.1 create-react-app 脚手架的使用2.2 项目目录解析2.3 抽离配置文件2.4 webpack 二次封装2.4.1 集成 css 预处理器2.4.2 配置解析别名 2.5 setupProxy 代理 三、JSX3.1 jsx 语法详解3.2 React.createElement 四、组件定义4.1 类组件4.2 函数…...

如何使用 Vue.js 侦听嵌套数据?
new Vue({el: "#app",data: {target: {list: [],},},watch: {"target.list": {handler(newVal, oldVal) {},deep: true,},} }); 给target的list属性增加侦听器,需要在watch中使用字符串的写法 "target.list" 来标记侦听的内容 han…...

Spring AOP详解
Spring AOP是Spring框架中的一个模块,它允许开发人员使用面向切面编程(AOP)的思想来解耦系统的不同层次。 Spring AOP的核心概念是切面(aspect)、连接点(join point)、通知(advice)、切点(pointcut)和引入(introduction)。 切面(aspect):切面是一个类, 它…...
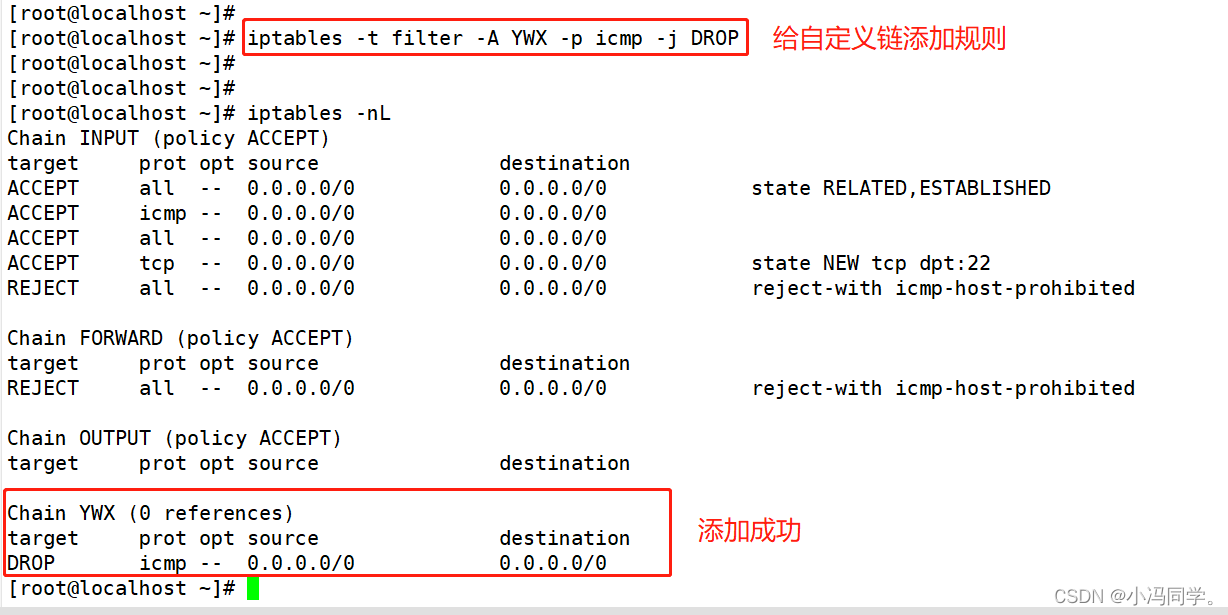
linux iptables安全技术与防火墙
linux iptables安全技术与防火墙 1、iptables防火墙基本介绍1.1netfilter/iptables关系1.2iptables防火墙默认规则表、链结构 2、iptables的四表五链2.1四表2.2五链2.3四表五链总结2.3.1 规则链之间的匹配顺序2.3.2 规则链内的匹配顺序 3、iptables的配置3.1iptables的安装3.2i…...
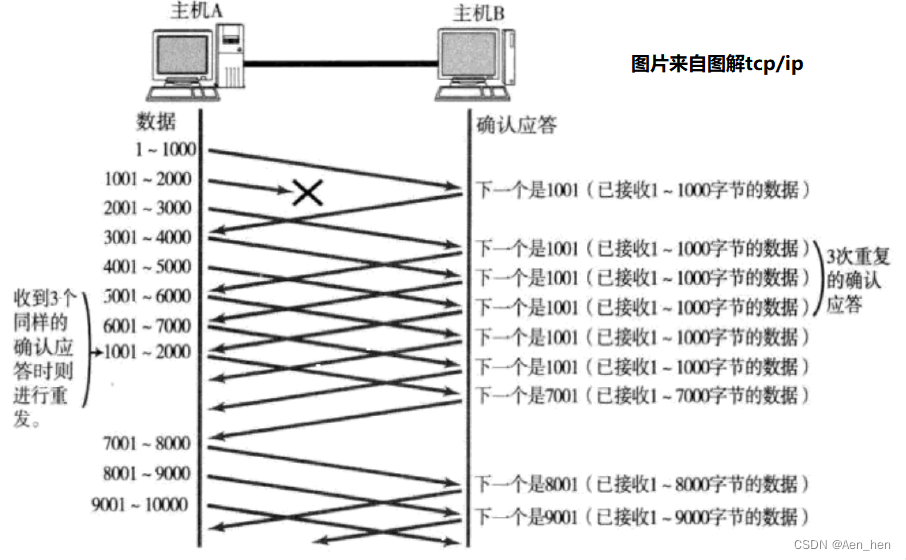
TCP性能机制
延迟应答 为什么有延迟应答 发送方如果长时间没有收到ACK应答,则会触发超时重传机制,重新发送数据包。但如果接收数据的主机立刻返回ACK应答, 这时候返回的窗口可能比较小,发送方一次只能发少量数据,效率较低。 举个例子理解一…...

qt信号槽同步问题
目录 信号槽: 注意事项: 具体例子: 线程安全问题的例子: 信号槽: 在Qt编程中,信号(Signal)和槽(Slot)是一种用于在对象之间进行通信的机制。信号用于发出…...
七夕特惠-8折抢购,从速
在七夕这个特殊的日子,我们推出了8折优惠活动,具体如下: 不管是充值会员,还是购买套路文章,一律享受8折优惠,活动截止时间为2023年8月24日12时。 甚至还有免费抽奖活动 兑奖方式,复制兑奖码…...
[NLP]LLM--transformer模型的参数量
1. 前言 最近,OpenAI推出的ChatGPT展现出了卓越的性能,引发了大规模语言模型(Large Language Model, LLM)的研究热潮。大规模语言模型的“大”体现在两个方面:模型参数规模大,训练数据规模大。以GPT3为例,GPT3的参数量…...

5 Python的面向对象编程
概述 在上一节,我们介绍了Python的函数,包括:函数的定义、函数的调用、参数的传递、lambda函数等内容。在本节中,我们将介绍Python的面向对象编程。面向对象编程(Object-Oriented Programming, 即OOP)是一种…...

卷积神经网络——上篇【深度学习】【PyTorch】【d2l】
文章目录 5、卷积神经网络5.1、卷积5.1.1、理论部分5.1.2、代码实现5.1.3、边缘检测 5.2、填充和步幅5.2.1、理论部分5.2.2、代码实现 5.3、多输入多输出通道5.3.1、理论部分5.3.2、代码实现 5.4、池化层 | 汇聚层5.4.1、理论部分5.4.2、代码实现 5、卷积神经网络 5.1、卷积 …...

【从零学习python 】54. 内存中写入数据
文章目录 内存中写入数据StringIOBytesIO进阶案例 内存中写入数据 除了将数据写入到一个文件以外,我们还可以使用代码,将数据暂时写入到内存里,可以理解为数据缓冲区。Python中提供了StringIO和BytesIO这两个类将字符串数据和二进制数据写入…...
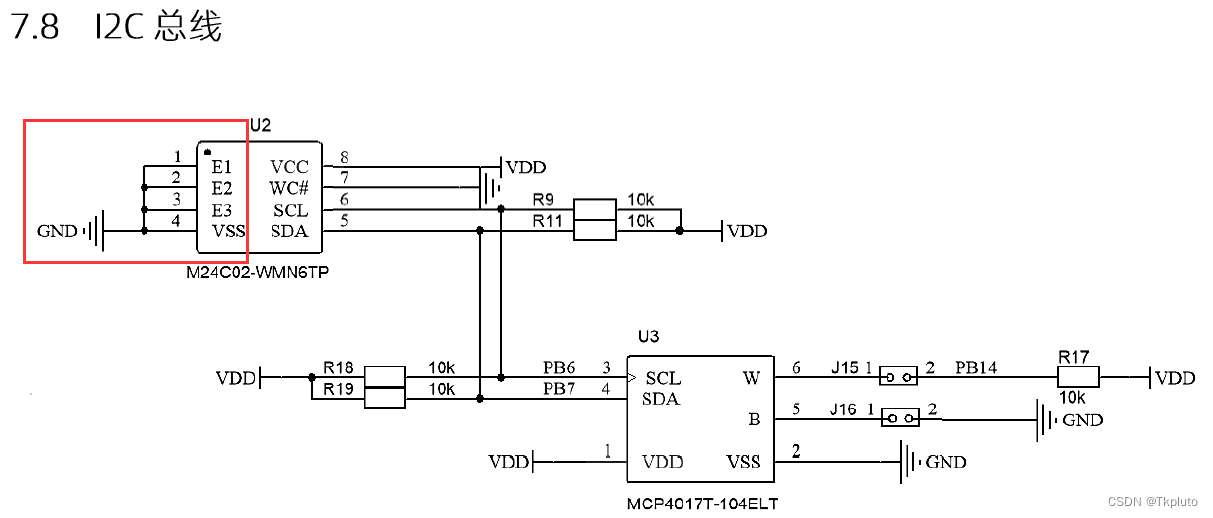
速通蓝桥杯嵌入式省一教程:(九)AT24C02芯片(E2PROM存储器)读写操作与I2C协议
AT24C02芯片(又叫E2PROM存储器、EEPROM存储器),是一种通过I2C(IIC)协议通信的掉电保存存储器芯片,其内部含有256个8位字节。在介绍这款芯片之前,我们先来粗略了解一下I2C协议。 I2C总线是一种双向二线制的同步串行总线…...

负载均衡:优化性能与可靠性的关键
在现代互联网时代,数以万计的用户访问着各种在线服务,从即时通讯、社交媒体到电子商务和媒体流媒体,无不需要应对海量的请求和数据传输。在这个高并发的环境下,负载均衡成为了关键的技术,它旨在分散工作负载࿰…...
)
MATLAB roots函数实战:5分钟搞定高阶系统稳定性判断(附完整代码)
MATLAB roots函数实战:高阶系统稳定性分析的黄金法则 在控制工程和自动化领域,系统稳定性分析是每个工程师的必修课。面对复杂的高阶系统特征方程,传统的手工计算方法不仅耗时耗力,还容易出错。而MATLAB的roots函数配合简单的可视…...

Deep SORT:如何用深度关联度量实现95%+准确率的实时多目标追踪?
Deep SORT:如何用深度关联度量实现95%准确率的实时多目标追踪? 【免费下载链接】deep_sort Simple Online Realtime Tracking with a Deep Association Metric 项目地址: https://gitcode.com/gh_mirrors/de/deep_sort 在计算机视觉领域ÿ…...

单片机软件架构师使用Taotoken多模型对比分析内存分配策略
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 单片机软件架构师使用Taotoken多模型对比分析内存分配策略 在嵌入式软件开发中,内存分配策略的选择直接影响着系统的实…...

VESC驱动无刷电机入门避坑:从看不懂ChibiOS源码到5分钟搞定CAN通讯
VESC驱动无刷电机入门避坑:从看不懂ChibiOS源码到5分钟搞定CAN通讯 第一次接触VESC驱动无刷电机时,面对满屏的ChibiOS源码和复杂的CAN通讯协议,很多嵌入式新手都会感到无从下手。特别是当你已经能用VESC Tool让电机转起来,但想通过…...

三步实现iOS虚拟定位:无需越狱的终极免费方案
三步实现iOS虚拟定位:无需越狱的终极免费方案 【免费下载链接】iFakeLocation Simulate locations on iOS devices on Windows, Mac and Ubuntu. 项目地址: https://gitcode.com/gh_mirrors/if/iFakeLocation iFakeLocation是一个专业级的iOS虚拟定位工具&am…...

虞城装修公司选哪家专业?业主正确对比装修公司的方法,看完不踩坑
在虞城准备装修的业主,大多都会纠结一个问题:虞城装修公司这么多,到底哪家更专业? 很多人都是第一次装修,不懂行、不会分辨,只会看价格、看广告,很容易被低价套路、中途增项、工艺偷工减料坑到崩…...

Tessera:内核级异构GPU分解技术解析与应用
1. Tessera:内核级异构GPU分解技术解析现代GPU数据中心正变得越来越异构化,不同型号的GPU在计算能力、内存带宽和成本效率上存在显著差异。这种异构性源于GPU发布周期与退役时间表的不匹配,以及高昂的成本和有限的供应。例如,Goog…...

Flutter for OpenHarmony学习资料搜索与PDF阅读器技术文章
Flutter for OpenHarmony学习资料搜索与PDF阅读器技术文章 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 🚀 Flutter for OpenHarmony 学习资料搜索与 PDF 阅读器开发实战 大家好!今天带大家从零开始打造一款专…...

Ctool架构深度解析:模块化开发工具集的高效实现方案
Ctool架构深度解析:模块化开发工具集的高效实现方案 【免费下载链接】Ctool 程序开发常用工具 chrome / edge / firefox / utools / windows / linux / mac 项目地址: https://gitcode.com/gh_mirrors/ct/Ctool 在程序开发过程中,开发者经常需要在…...

Unlock Music:3种创新用法让你重新掌控被加密的音乐收藏
Unlock Music:3种创新用法让你重新掌控被加密的音乐收藏 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: htt…...