自监督表征预训练之掩码图像建模
自监督表征预训练之掩码图像建模
前言
目前,在计算机视觉领域,自监督表征预训练有两个主流方向,分别是对比学习(contrastive learning)和掩码图像建模(masked image modeling)。两个方向在近几年都非常火爆,有许多优秀的工作涌现。对比学习方向,有 MoCo 系列、SimCLR 系列、SWaV、SimSiam、DINO 等;掩码图像建模方向,有 BEIT 系列、MAE、CAE 等。本文主要整理几篇掩码图像建模方向的工作。
在自然语言处理领域,BERT 提出的掩码语言建模(masked language modeling)作为一种表征学习预训练方法,已经取得了巨大的成功。那么,在计算机视觉领域,尤其是在 ViT 的提出证明了 Transformer 在 CV 中同样可用之后,掩码建模的预训练方式是否有效呢?
BEiT
前言
ViT 的提出证明了只要经过图像分块和线性映射嵌入, Transformer 同样可以处理图像数据。然而,相较于 CNN,ViT 不存在针对图像数据的归纳偏置,因此通常需要更大的数据来进行训练。为了节省标注的成本,研究者们探索了如何使用自监督的方式对 ViT 进行预训练。对标 BERT 中的掩码语言建模(MLM)训练目标,BEiT(Bidirectional Encoder representation from Image Transformers)提出了掩码图像建模(MIM),使用大量无标注的图像数据,对 ViT 进行自监督表征学习预训练。
要对图像进行掩码,首先想到的就是选择一些像素进行掩码。然而,由于图像中像素信息的冗余性很高,模型通过简单的插值就能大致恢复出被掩码的像素,很难学习到图像的高层语义。那么。是否可以像 BERT 一样,对 token 进行掩码呢?在自然语言中,文本是一种离散的数据形式,所有的单词都存在于一个单词数量有限的词表(vocab)中,而图像中的像素是一种连续的数据形式,可能的像素排列组合数目极其巨大。这使得 MIM 无法直接照搬 MLM 中使用分类头预测被掩码 token 的方式。借鉴 DALL-E 中 dVAE 的做法,BEiT 的解决方案是对图像块进行离散化,需要设计一种方式来构造一种 “视觉词表”。BEiT 的模型结构如图 1 所示。
方法

图像表示
BEiT 中每张图像有两个视角(view):图像块(image patchs)和离散的视觉 token(visual tokens)。在预训练阶段,它们分别作为 BEiT Encoder 模型的输入和输出。
-
图像块
与标准 ViT 的做法一致,BEiT 将原始图像切分为多个规则的图像块。作为 BEiT Encoder 的输入。
-
视觉token
为了将图像数据离散化,BEiT 通过一个 tokenizer 将图像表示为一个离散的 token 序列。
与 DALL-E 一样,BEiT 使用 dVAE 来对 tokenizer 进行训练。训练时, tokenizer qϕ(z∣x)q_\phi(z|x)qϕ(z∣x) 将输入图像 xxx 编码为离散的 token 序列 zzz,decoder pψ(x∣z)p_\psi(x|z)pψ(x∣z)根据 token 序列 zzz 重构出输入图像 xxx。其中,所有可选的 token 序列保存在码本(codebook)中,这里的码本就相当于 NLP 中的词表 vocab。dVAE 的训练过程的目标函数可表示为:Ez∼qϕ(z∣x)[logpψ(x∣z)]\mathbb{E}_{z\sim q_\phi(z|x)}[\log p_\psi(x|z)]Ez∼qϕ(z∣x)[logpψ(x∣z)] 。由于视觉 token 是离散的,整个过程不可导,因此 BEiT 中引入 gumble softmax 来解决这一问题。在 dVAE 训练结束后,开始对 BEiT Encoder 进行预训练时,decoder 将被丢弃,仅使用 tokenizer 来为 BEiT Encoder 的训练生成目标 token。
骨干网络:Image Transformer
BEiT Encoder 是一个标准的 ViT。图像块输入经过线性映射后,每个图像块对应一个特征嵌入 token,然后拼接一个特殊 token [S],并为所有 token 添加位置编码。与标准 ViT 的输入不同的是,BEiT 的对图像块进行掩码,将被掩码图像块的 token 替换为一个共享的、可学习的 token。经过 LLL 层 Transformer Block 提取特征之后,得到图像的特征嵌入。
BEiT 预训练:Masked Image Modeling
经过 BEiT Encoder 图像特征之后,每个被掩码位置的特征经过一个 softmax 分类器,预测该位置的 token。本质上是一个分类任务,候选的类别数即为码本中 token 的个数。整个预训练过程的目标函数可表示为:
max∑x∈DEM[∑i∈MlogpMIM(zi∣xM)]\max\sum_{x\in\mathcal{D}}\mathbb{E}_\mathcal{M}[\sum_{i\in\mathcal{M}}\log p_{\text{MIM}}(z_i|x^\mathcal{M})] maxx∈D∑EM[i∈M∑logpMIM(zi∣xM)]
其中 D\mathcal{D}D 是全部训练数据,M\mathcal{M}M 表示被随机掩码的位置,xMx^{\mathcal{M}}xM 是经过掩码的图像,ziz_izi 是待预测的视觉 token。
微调
BEiT Encoder 经过预训练之后,可以提取图像的特征。这些特征经过不同的 task specific layer 处理之后,可用于处理不同的下游任务,如图像分类、语义分割等。
其他细节
- BEiT 中的掩码策略不是完全随机的,而是按照 block 进行掩码;
- BEiT 中的掩码率为 40%;
- BEiT 直接使用了 DALL-E 通过 dVAE 训练好的 tokenizer;
- 论文中提供了 BEiT 在 VAE 视角下的 ELBO 数学解释;
- 中间微调,BEiT 在自监督预训练结束之后,可以先在规模稍大的中间数据集(原文中为 ImageNet-1K)上微调,然后再在不同的下游任务上微调。
总结
BEiT 是比较早期的 MIM 算法。它通过先训练一个 tokenizer 并构造离散化码本,使得 ViT 能够通过 MIM 目标进行训练。
MAE
前言
MAE(Masked AutoEncoder)的想法非常直接:将图像中的某些图像块掩码掉,然后要求模型重构出掩码掉的像素。如图 2 所示,MAE 整体上是一个编码器-解码器架构。其中,编码器提取可见图像块的特征,解码器根据这些特征重构出原始图像。MAE 有两个需要注意的关键设计:1) 非对称的编码器-解码器架构, 2) 高掩码率。MAE 的编码器-解码器架构是非对称的,编码器的模型尺寸相对较大,仅接收可见的(未被掩码的)图像块,提取其特征,解码器相对轻量,编码后的图像特征 token 和统一且可学习的掩码 token 作为输入。MAE 中掩码的比率非常高,达到 75%。相对的,在 BERT 中,对文本数据的掩码率为 15%。这体现出图像数据的冗余性和文本数据的高度语义性。得益于这两项设计,MAE 可以高效地训练出强大的模型。模型的强大来自于高掩码率带来的任务难度,高效来自于非对称的架构设计,编码器仅需处理可见图像块。
方法

掩码方法
与 ViT 一致,MAE 将原始图像分为规则的、无重叠的图像块。然后,从这些图像块中随机选择一部分保留,另一部分掩码掉。
编码器
MAE 的编码器是一个标准 ViT 模型,但是只接受可见的、未被掩码的图像块作为输入。与标准 ViT 一致,这些可见的图像块经过线性映射,添加位置嵌入,然后经过数个 Transformer Block 提取图像的特征。由于仅需处理可见的图像块, MAE 的编码器计算非常高效,这使得 MAE 编码器的模型尺寸可以非常大。
解码器
MAE 的解码器接收一组完整的 token,包括经过编码器编码的可见图像块的 token,以及 mask token。MAE 中的 mask token 是一个可学习的、共享的向量,表示此位置图像块缺失,需要重构。解码器同样需要给全部 token 添加位置嵌入,然后经过数个 Transformer Block,得到重构结果。注意,解码器仅在预训练时需要,在预训练完成之后,在下游任务上进行微调时,可将解码器丢弃。另外,相较于编码器,解码器模型尺寸较小,MAE 论文中默认解码器对于每个 token 的计算量是编码器的 1/10。
重构目标
BEiT 中,模型的重构目标是 token,不同于此,MAE 是直接重构图像的像素。MAE 中,解码器的最后一层是一个线性层,将每个 token 映射为对应图像块的像素。损失函数为 MSE,只在掩码掉的图像块上计算损失。
另外,MAE 中的关于重构目标的一个小 trick 是对图像块内像素进行标准化(normalization),先计算图像块内所有像素的均值和标准差,然后根据它们对图像块内的所有像素进行标准化。实验显示,进行标准化可以提高表征的质量。
总结
MAE 与 BEiT 不同,它的重构目标是原始像素。MAE 训练高效,表征能力强,它的核心创新点有两个:非对称的编码器-解码器架构和高掩码率。
BEiTv2
前言
当时已有的 MIM 方法的重构目标有三种:原始像素、手工特征和视觉 tokens。这些重构目标都是 low-level 的图像元素,而自监督表征预训练实际更想得到关于高层语义的图像特征。因此,BEiTv2 试图构建语义感知的监督信号,为此,BEiT 有两点主要的创新。首先是提出了向量化知识蒸馏(Vector Quantised Knowledge Distillation,VQ-KD),为 MIM 预训练提供语义层面的监督信号。另外是提出一种块聚合策略(patch aggregation strategy),鼓励模型聚合所有块的信息,提取图像的全局特征,而不是仅关注图像块的重构。
方法
BEiTv2 是在 BEiTv1 的基础上进行改进。前文已经介绍,BEiTv1 分为两个阶段,分别是 tokenizer 的训练和 BEiT Encoder 的预训练。BEiTv2 中两个阶段与 BEiTv1 是一样的,先训练出 tokenizer,为 BEiT Encoder 的预训练提供重构目标。BEiTv2 的两个创新点分别在这两个阶段中。
训练tokenizer
BEiTv1 的 tokenizer 使用 dVAE 进行训练,如此得到的离散 token 高层语义不够丰富。BEiTv2 中提出 VQ-KD 来训练 tokenizer, 训练流程如图 3 所示。BEiTv2 中,同样有 tokenizer 和decoder 两个模型参与训练。tokenizer 又由 encoder 和 quantizer 组成,encoder 将图像映射为一串视觉 token,quantizer 通过最近邻的方式从码本 V\mathcal{V}V 中查找与每个 token 的 L2 距离最接近的 embedding。码本 V∈RK×D\mathcal{V}\in\mathbb{R}^{K\times D}V∈RK×D ,其中包含 KKK 个维度为 DDD 的 embedding。这就是 VQ。在得到量化后的视觉 token 之后,将其送入解码器,解码器的输出目标是教师模型(如 CLIP、DINO 等)给出的语义特征。这个训练过程的目标是最大化解码器的输出与教师模型语义特征的余弦相似度。这就是 KD。通过 VQ-KD 的训练方式,BEiTv2 的 tokenizer 能够为 BEiT encoder 的预训练提供含有高层语义特征的重构目标。tokenizer训练的目标函数为:
max∑x∈D∑i=1Ncos(oi,ti)−∣∣sg[l2(hi)]−l2(vzi)∣∣22−∣∣l2(hi)−sg[l2(vzi)]∣∣22\max\sum_{x\in \mathcal{D}}\sum_{i=1}^N\cos(o_i,t_i)-||\text{sg}[l_2(h_i)]-l_2(v_{z_i})||^2_2-||l_2(h_i)-\text{sg}[l_2(v_{z_i})]||_2^2 maxx∈D∑i=1∑Ncos(oi,ti)−∣∣sg[l2(hi)]−l2(vzi)∣∣22−∣∣l2(hi)−sg[l2(vzi)]∣∣22

预训练 BEiTv2
BEiTv2 的预训练与 BEiTv1 大体一致,将图像进行掩码,并分块送入 Transformer,得到的特征通过 softmax 分类器,预测掩码位置上的 token。BEiTv2 的优化之处是提出了块聚合策略,在图像 token 上拼接了一个 [CLS] token,用来鼓励模型聚合各个图像块,提取图像的全局特征。而不是仅仅关注较为底层的图像块重构。配备有块聚合策略的 MIM 训练流程如图 4 所示。BEiTv2 构建了一个瓶颈层来对 <CLS> token 进行预训练,使其尽可能多地汇聚信息。
[CLS] 的预训练网络如图 4 的右半部分的虚线框所示,是一个两层的 ViT。它的输入是由 BEiTv2 Encoder 的第 lll 层的输出向量和第 LLL 层的[CLS] 向量拼接而成。这两层 ViT 的输出特征也经过 MIM head (与 BEiT Encoder 的 MIM head 共享权重)预测掩码处的 token。在计算整体 MIM 损失时,添加一项 LMIMc\mathcal{L}^c_{MIM}LMIMc 。
为什么说通过对[CLS]的预训练,我们得到的特征 hCLSLh_\text{CLS}Lh_\text{CLS}L 具有图像的全局信息呢?由于在训练 [CLS] token 时,舍弃了图 4 中最左侧的第 l+1l+1l+1 层到第 LLL 层的,却要求两个不同的 MIM 任务共享同一个MIM输出头,这就迫使 <CLS> token 学习更多的全局信息,以弥补被舍弃的图像所有标志的特征的信息。
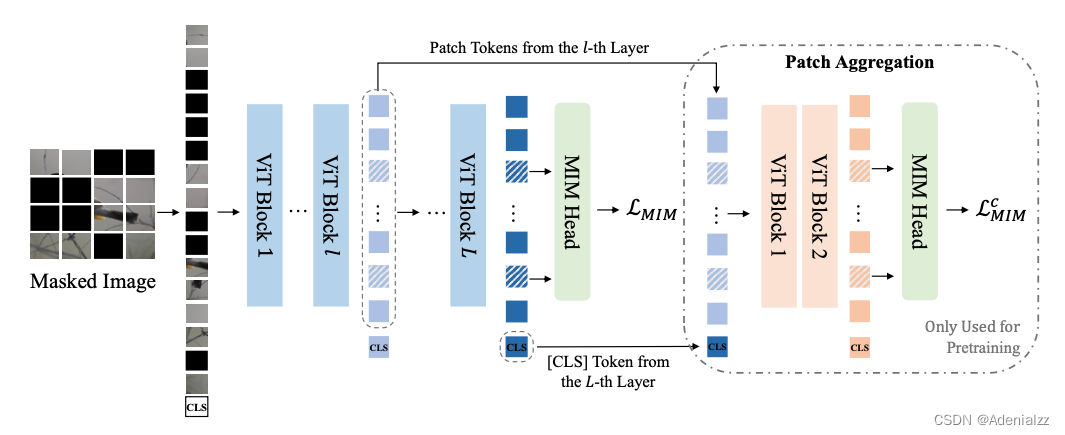
其他细节
- 训练 tokenizer 时,由于中间的最近邻查表操作是不可微的,为了梯度反传,可将 decoder 输入的梯度直接拷贝到 encoder 输出。因为 quantizer 查找的是每个编码器输出的最近邻 embedding,码本 embedding 的梯度可以为编码器指示合理的优化方向;
- 为了稳定码本的训练并提高利用率,避免码本坍塌,导致只有一小部分 embedding 会被使用,tokenizer 的训练采用了一些 trick。其中包括使用标准化 l2 距离、降低 embedding 维度到 32 维、滑动指数平均 (EMA);
- 额外的用于预训练
<CLS>token 的两层 ViT Block 在预训练结束后即被丢弃,不用于下游任务。
总结
BEiTv2 针对 BEiT 等已有 MIM 工作中语义特征缺失的问题,提出了 VQ-KD,对 embedding 进行量化并将 CLIP、DINO 等语义特征提取强的模型作为教师模型,生成重构目标。并提出使用 <CLS> token 来聚合图像块,提取全局特征。
Ref
自监督表征预训练之掩码图像建模:CAE 及其与 MAE、BEiT 的联系
MAE 论文逐段精读【论文精读】
如何看待BEIT V2?是否是比MAE更好的训练方式?
相关文章:
自监督表征预训练之掩码图像建模
自监督表征预训练之掩码图像建模 前言 目前,在计算机视觉领域,自监督表征预训练有两个主流方向,分别是对比学习(contrastive learning)和掩码图像建模(masked image modeling)。两个方向在近几…...
| 代码+思路+重要知识点)
华为OD机试题 - 磁盘容量(JavaScript)| 代码+思路+重要知识点
最近更新的博客 华为OD机试题 - 字符串加密(JavaScript) 华为OD机试题 - 字母消消乐(JavaScript) 华为OD机试题 - 字母计数(JavaScript) 华为OD机试题 - 整数分解(JavaScript) 华为OD机试题 - 单词反转(JavaScript) 使用说明 参加华为od机试,一定要注意不要完全背…...

ChatGPT:“抢走你工作的不会是 AI ,而是先掌握 AI 能力的人”
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! ChatGPT:“抢走你工作的不会是 AI ,而是先掌握 AI 能力的人” ChatGPT:美国OpenAI 研发的聊天机器人程序,人工智能技术…...

数据结构与算法(Java版) | 线性结构和非线性结构
之前,我们说过,数据结构是算法的基础,因此接下来在这一讲我就要来给大家重点介绍一下数据结构了。 首先,大家需要知道的是,数据结构包括两部分,即线性结构和非线性结构。知道这点之后,接下来我…...
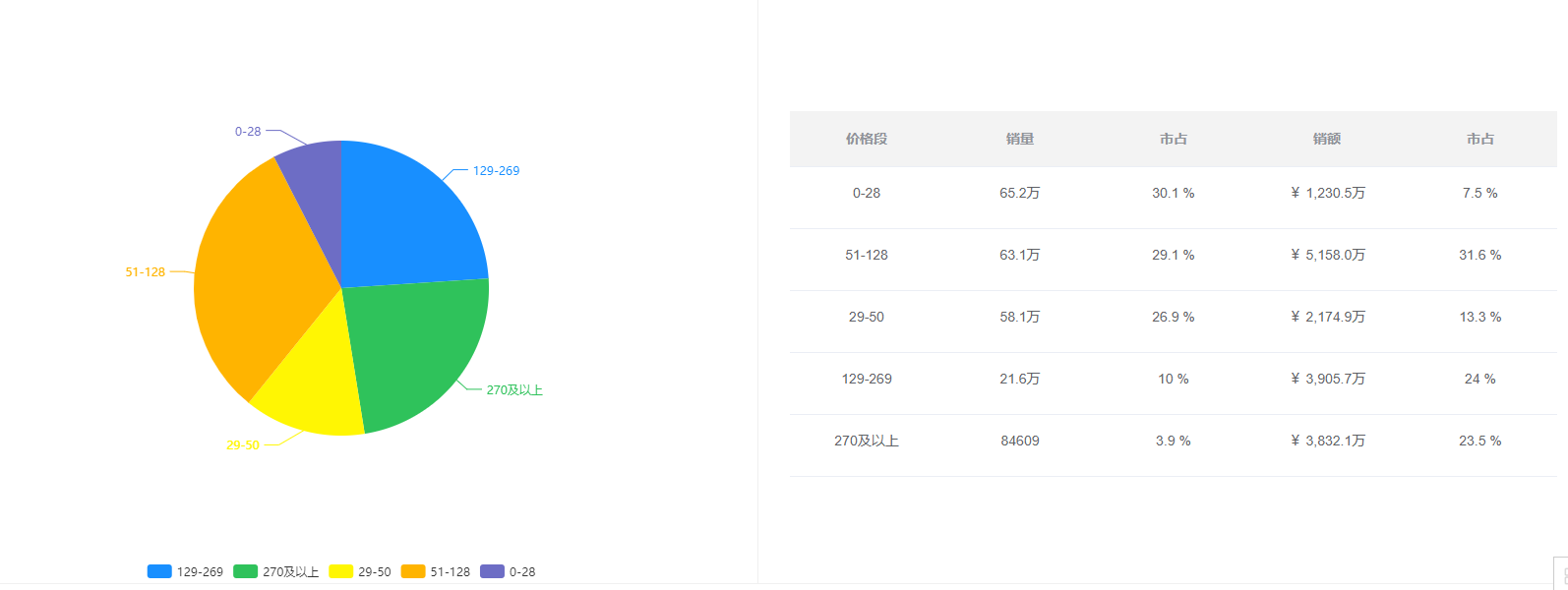
电商数据查询平台:母婴行业妈妈用品全网热销,头部品牌格局初现
以往,奶粉、纸尿裤这类产品基本就代表了整体母婴市场中的消费品。而如今,随着母婴行业的高速发展和消费升级,母婴商品的种类日益丰富,需求也不断深入。 在京东平台,母婴大品类中除了包含婴童相关的食品(奶粉…...
STM32模拟SPI协议获取24位模数转换(24bit ADC)芯片AD7791电压采样数据
STM32模拟SPI协议获取24位模数转换(24bit ADC)芯片AD7791电压采样数据 STM32大部分芯片只有12位的ADC采样性能,如果要实现更高精度的模数转换如24位ADC采样,则需要连接外部ADC实现。AD7791是亚德诺(ADI)半导体一款用于低功耗、24…...
| 代码+思路+重要知识点)
华为OD机试题 - 交换字符(JavaScript)| 代码+思路+重要知识点
最近更新的博客 华为OD机试题 - 字符串加密(JavaScript) 华为OD机试题 - 字母消消乐(JavaScript) 华为OD机试题 - 字母计数(JavaScript) 华为OD机试题 - 整数分解(JavaScript) 华为OD机试题 - 单词反转(JavaScript) 使用说明 参加华为od机试,一定要注意不要完全背…...

最好的工程师像投资者一样思考,而不是建设者
我在大学期间住在图书馆。“我学习的教科书理论越多,我就会成为一名更好的工程师,”我想。然而,当我开始工作时,我注意到业内最优秀的工程师并不一定比应届毕业生了解更多的理论。他们只是带来了不同的心态,即投资者的…...
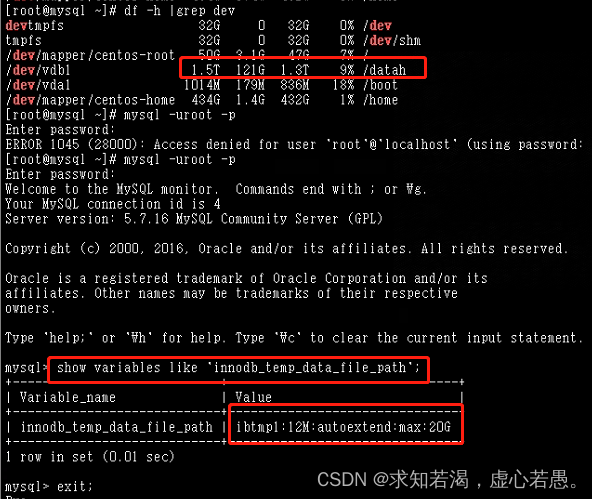
Mysql里的ibtmp1文件太大,导致磁盘空间被占满
目录 一、查看磁盘的时候发现磁盘空间100% 二、 排查的时候:查看是什么文件占用的时候,发现是数据库临时表空间增长的 三、为了避免以后再次出现ibtmp1文件暴涨,限制其大小,需在配置文件加入 四、重启Mysql实例(重启后…...
android kotlin 协程(四) 协程间的通信
android kotlin 协程(四) 协程间的通信 学完本篇你将会了解到: channelproduceactorselect 先来通过上一篇的简单案例回顾一下挂起于恢复: fun main() {val waitTime measureTimeMillis {runBlocking<Unit> {println("main start") // 1 // …...

苹果手机通讯录突然没了怎么恢复?
手机成为生活中的必需品,都会存储着各种数据文件,比如我们使用过的APP、音乐、照片、通讯录等通常都是存在这里面的。但我们的操作难免会有意外,有的是手动不小心删的,有的是误删的,有的是自己孩子删的等,却…...

BI知识全解,值得收藏
2021年度,中国商业软件市场的增长趋势是快速增长的,达到7.8亿美元,同比增长34.9%。商业智能BI在企业应用中具有巨大的价值,并逐渐成为现代企业信息化和数字化转型的基础。所以,全面了解BI,对于企业管理是非…...

【机器学习】GBDT
1.什么是GBDT GBDT(Gradient Boosting Decision Tree),梯度提升树。它是一种基于决策树的集成算法。其中Gradient Boosting 是集成方法boosting中的一种算法,通过梯度下降来对新的学习器进行迭代。它是利用损失函数的负梯度方向在当前模型的值作为残差的…...

C#开发的OpenRA游戏高性能内存访问的方法
C#开发的OpenRA游戏高性能内存访问的方法 一个游戏性能往往是比较关键的, 因为游戏很多时候是比拼的是人的速度和技巧。 比如王者荣耀里,一个大招是否及时地放得出来,就会影响到一场比赛的关键。 而这个大招的释放,又取决于游戏运行在手机上的性能。 如果游戏太耗性能,导致…...
【elasticsearch】elasticsearch es读写原理
一、前言: 今天来学习下 es 的写入原理。 Elasticsearch底层使用Lucene来实现doc的读写操作: Luence 存在的问题: 没有并发设计 lucene只是一个搜索引擎库,并没有涉及到分布式相关的设计,因此要想使用Lucene来处理海量…...

数据在内存中的存储【上篇】
文章目录⚙️1.数据类型的详细介绍🔩1.1.类型的基本归类⚙️2.整型在内存中的存储🔩2.1.原码、反码、补码🔩2.2.大小端的介绍⚙️1.数据类型的详细介绍 🥳基本的内置类型 : 💡char ---------- 字符数据类型…...
慕了没?3年经验,3轮技术面+1轮HR面,拿下字节30k*16薪offer
前段时间有个朋友出去面试,这次他面试目标比较清晰,面的都是业务量大、业务比较核心的部门。前前后后去了不少公司,几家大厂里,他说给他印象最深的是字节3轮技术面1轮HR面,他最终拿到了30k*16薪的offer。第一轮主要考察…...

「可信计算」与软件行为学
可信计算组织(Ttrusted Computing Group,TCG)是一个非盈利的工业标准组织,它的宗旨是加强在相异计算机平台上的计算环境的安全性。TCG于2003年春成立,并采纳了由可信计算平台联盟(the Trusted Computing Platform Alli…...
| 代码+思路+重要知识点)
华为OD机试题 - 找字符(JavaScript)| 代码+思路+重要知识点
最近更新的博客 华为OD机试题 - 字符串加密(JavaScript) 华为OD机试题 - 字母消消乐(JavaScript) 华为OD机试题 - 字母计数(JavaScript) 华为OD机试题 - 整数分解(JavaScript) 华为OD机试题 - 单词反转(JavaScript) 使用说明 参加华为od机试,一定要注意不要完全背…...

Linux 进程启动方法
现实中程序编写的时候,经常会碰到一些这样需求:调用系统命令,完成一些操作,或判定结果 或获取结果作为启动进程,调用第三方进程,并监控进程是否退出加载升级进程,升级进程kill调用者或调用者自行…...

STM32CubeMX配置RT-Thread Nano:从零构建到任务与内存管理实战
1. 环境准备与基础工程搭建 第一次接触STM32CubeMX和RT-Thread Nano时,我完全按照官方文档操作却踩了不少坑。这里分享一个经过实战验证的配置流程,适用于STM32H7系列(其他型号也类似)。你需要准备: STM32CubeMX 6.12.…...

矽力杰 Silergy SY8810 降压稳压器 佰祥电子
突破算力供电瓶颈:SY8810单芯片15A大电流与IC数字调压全景拆解导语:在边缘计算SoC、高速光模块(如QSFP-DD)以及企业级SSD的主板设计中,核心处理器的供电轨正面临着极其苛刻的物理学挑战。随着先进制程工艺不断演进&…...

HoRain云--SeleniumGrid4完全指南:分布式测试实战
🎬 HoRain云小助手:个人主页 🔥 个人专栏: 《Linux 系列教程》《c语言教程》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!…...

数字资产管理问题的创新解法:WeChatMsg的本地化数据主权实现
数字资产管理问题的创新解法:WeChatMsg的本地化数据主权实现 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we…...

如何解决JAVA无人共享无人健身房物联网结合系统防尾随问题
在JAVA无人共享无人健身房物联网结合系统中,防尾随问题可通过AB门防尾随方案结合物联网技术、AI算法和JAVA后端逻辑实现,其核心在于双门互锁机制AI人数检测实时通信控制。以下是具体解决方案:一、系统架构设计硬件层:双门结构&…...

ROS2中nav_msgs/Path消息的实战解析:从数据结构到Rviz可视化
1. 理解nav_msgs/Path消息的核心结构 在ROS2的导航系统中,nav_msgs/Path消息扮演着路径规划与可视化的重要角色。这个消息类型本质上是一条由多个位姿点组成的轨迹,常用于描述机器人需要跟随的全局路径或局部路径。我第一次接触这个数据结构时࿰…...

汇川伺服Modbus通讯踩坑实录:从“通信超时”到“数据错乱”的五个常见故障排查指南
汇川伺服Modbus通讯实战:五大典型故障排查与深度解析 调试现场的温度总是比办公室高几度,尤其是当你面对一台"沉默"的汇川伺服驱动器时。Modbus-RTU协议作为工业自动化领域的"普通话",理论上应该让不同设备间的对话变得…...
)
汽车ECU安全解锁实战:手把手教你用C语言实现AES-CMAC算法(附完整源码)
汽车ECU安全访问实战:AES-CMAC算法深度解析与工程实现 在汽车电子控制单元(ECU)的安全访问机制中,27服务作为常见的诊断协议,其核心安全认证流程往往依赖于AES-CMAC算法。本文将带您深入理解这一算法的工程实现细节&am…...

如何利用payload-dumper-go构建企业级Android OTA安全验证流水线
如何利用payload-dumper-go构建企业级Android OTA安全验证流水线 【免费下载链接】payload-dumper-go an android OTA payload dumper written in Go 项目地址: https://gitcode.com/gh_mirrors/pa/payload-dumper-go 在Android生态系统的持续交付流程中,OTA…...

ai赋能教学:让快马智能体带你通关mysql安装,实时解答所有疑惑
最近在准备MySQL数据库的课程教学资料时,发现很多学生在安装环节就会遇到各种问题。传统的静态教程很难覆盖所有可能的情况,于是尝试用AI技术做了一个智能辅导应用,效果出乎意料的好。这里分享下实现思路和具体功能设计。 智能问答模块 这是最…...