FATE框架中pipline基础教程
目录
- 1. 用pipline上传数据
- 2. 用 `Pipeline` 进行 `Hetero SecureBoost` 的训练和预测
- 3. 用 `Pipeline` 构建神经网络模型
- 3.1 Homo-NN Quick Start: A Binary Classification Task
- 3.2 Hetero-NN Quick Start: A Binary Classification Task
- 4. 自定义数据集
- 示例:实现一个简单的图像数据集
- 5. 自定义损失函数
- 6. 自定义模型
- 7. 自定义Trainer控制训练流程
1. 用pipline上传数据
假设我们在127.0.0.1:9380中有一个“FATE流服务”(默认为独立版本)
!pipeline init --ip 127.0.0.1 --port 9380
pipline配置就完成了。
在开始建模任务之前,应该上传要使用的数据。
这通常是包含多个节点的集群。因此,当我们上传这些数据时,数据将被分配给这些节点。
一个pipline的实例应该有:
- initiator: * role: guest* party: 9999- roles:* guest: 9999只有在本地运行才需要party id
pipeline_upload = PipeLine().set_initiator(role='guest', party_id=9999).set_roles(guest=9999)
之后定义数据存储的分区
partition = 4
定义将在FATE作业配置中使用的表名和命名空间
dense_data_guest = {"name": "breast_hetero_guest", "namespace": f"experiment"}
dense_data_host = {"name": "breast_hetero_host", "namespace": f"experiment"}
tag_data = {"name": "breast_hetero_host", "namespace": f"experiment"}
添加要上传的数据
import osdata_base = "/workspace/FATE/"
pipeline_upload.add_upload_data(file=os.path.join(data_base, "examples/data/breast_hetero_guest.csv"),table_name=dense_data_guest["name"], # table namenamespace=dense_data_guest["namespace"], # namespacehead=1, partition=partition) # data infopipeline_upload.add_upload_data(file=os.path.join(data_base, "examples/data/breast_hetero_host.csv"),table_name=dense_data_host["name"],namespace=dense_data_host["namespace"],head=1, partition=partition)pipeline_upload.add_upload_data(file=os.path.join(data_base, "examples/data/breast_hetero_host.csv"),table_name=tag_data["name"],namespace=tag_data["namespace"],head=1, partition=partition)
最后上传数据
pipeline_upload.upload(drop=1)
完整的代码应该为
import os
import argparsefrom pipeline.backend.pipeline import PipeLine# 数据的路径
# 先定义fate 安装的路径
DATA_BASE = "/data/projects/fate"# site-package ver
# import site
# DATA_BASE = site.getsitepackages()[0]def main(data_base=DATA_BASE):# parties configguest = 9999# 定义用于数据存储的分区partition = 4# table name 和 namespacedense_data = {"name": "breast_hetero_guest", "namespace": f"experiment"}tag_data = {"name": "breast_hetero_host", "namespace": f"experiment"}pipeline_upload = PipeLine().set_initiator(role="guest", party_id=guest).set_roles(guest=guest)# 添加上传数据的信息# csv文件路径# 这是单机版的示例,集群版需要上传自己的数据# 每一方分别上传pipeline_upload.add_upload_data(file=os.path.join(data_base, "examples/data/breast_hetero_guest.csv"),table_name=dense_data["name"], # table namenamespace=dense_data["namespace"], # namespacehead=1, partition=partition) # data infopipeline_upload.add_upload_data(file=os.path.join(data_base, "examples/data/breast_hetero_host.csv"),table_name=tag_data["name"],namespace=tag_data["namespace"],head=1, partition=partition)# upload datapipeline_upload.upload(drop=1)if __name__ == "__main__":parser = argparse.ArgumentParser("PIPELINE DEMO")parser.add_argument("--base", "-b", type=str,help="data base, path to directory that contains examples/data")args = parser.parse_args()if args.base is not None:main(args.base)else:main()2. 用 Pipeline 进行 Hetero SecureBoost 的训练和预测
上传完数据之后
Make a `pipeline` instance:- initiator: * role: guest* party: 9999- roles:* guest: 9999* host: 10000
定义如下:
pipeline = PipeLine() \.set_initiator(role='guest', party_id=9999) \.set_roles(guest=9999, host=10000)
定义“reader”加载数据
reader_0 = Reader(name="reader_0")
# 设置 guest 的参数
reader_0.get_party_instance(role='guest', party_id=9999).component_param(table={"name": "breast_hetero_guest", "namespace": "experiment"})
# 设置 host 参数
reader_0.get_party_instance(role='host', party_id=10000).component_param(table={"name": "breast_hetero_host", "namespace": "experiment"})
添加DataTransform组件以将原始数据解析到数据实例中
data_transform_0 = DataTransform(name="data_transform_0")
# 设置 guest 参数
data_transform_0.get_party_instance(role='guest', party_id=9999).component_param(with_label=True)
data_transform_0.get_party_instance(role='host', party_id=[10000]).component_param(with_label=False)
添加一个Intersection组件以执行hetero-scenario的PSI
intersect_0 = Intersection(name="intersect_0")
现在,我们定义“HeteroSecureBoost”组件,为所有相关方设置以下参数。
hetero_secureboost_0 = HeteroSecureBoost(name="hetero_secureboost_0",num_trees=5,bin_num=16,task_type="classification",objective_param={"objective": "cross_entropy"},encrypt_param={"method": "paillier"},tree_param={"max_depth": 3})为了显示评估结果,需要一个Evaluation组件。
evaluation_0 = Evaluation(name="evaluation_0", eval_type="binary")
将组件添加到pipline,按以下执行顺序:
- data_transform_0 comsume reader_0's output data- intersect_0 comsume data_transform_0's output data- hetero_secureboost_0 consume intersect_0's output data- evaluation_0 consume hetero_secureboost_0's prediciton result on training data
然后编译pipline,为提交做好准备。
pipeline.add_component(reader_0)
pipeline.add_component(data_transform_0, data=Data(data=reader_0.output.data))
pipeline.add_component(intersect_0, data=Data(data=data_transform_0.output.data))
pipeline.add_component(hetero_secureboost_0, data=Data(train_data=intersect_0.output.data))
pipeline.add_component(evaluation_0, data=Data(data=hetero_secureboost_0.output.data))
pipeline.compile();
最后,提交pipline
pipeline.fit()
一旦完成了训练,训练后的模型就可以用于预测。(可选项)保存训练过的管道以备将来使用。
pipeline.dump("pipeline_saved.pkl");
首先,部署训练pipline所需组件
pipeline = PipeLine.load_model_from_file('pipeline_saved.pkl')
pipeline.deploy_component([pipeline.data_transform_0, pipeline.intersect_0, pipeline.hetero_secureboost_0]);
定义新的reader组件用于读取预测数据
reader_1 = Reader(name="reader_1")
reader_1.get_party_instance(role="guest", party_id=9999).component_param(table={"name": "breast_hetero_guest", "namespace": "experiment"})
reader_1.get_party_instance(role="host", party_id=10000).component_param(table={"name": "breast_hetero_host", "namespace": "experiment"})
(可选项)定义新的Evaluation 组件。
evaluation_0 = Evaluation(name="evaluation_0", eval_type="binary")
添加组件以按顺序执行用于预测的pipline:
predict_pipeline = PipeLine()
predict_pipeline.add_component(reader_1)\.add_component(pipeline, data=Data(predict_input={pipeline.data_transform_0.input.data: reader_1.output.data}))\.add_component(evaluation_0, data=Data(data=pipeline.hetero_secureboost_0.output.data));最后执行预测作业
predict_pipeline.predict()
3. 用 Pipeline 构建神经网络模型
在FATE-1.10中,整个NN框架被重新设计用于高度可定制的机器学习。
有了这个框架,可以创建自己的模型、数据集、培训器和聚合器来满足特定需求。
在FATE-1.11中,支持使用参数高效方法(Adapters)进行联邦大型语言模型训练。
为了熟悉FATE-NN和管道,可以完成这两个快速入门教程。
- Homo-NN Quick Start: A Binary Classification Task
- Hetero-NN Quick Start: A Binary Classification Task
如果使用的是表格数据,并且不需要任何自定义,则这些教程足以满足需要
3.1 Homo-NN Quick Start: A Binary Classification Task
默认情况下,可以在与其他FATE算法组件相同的过程中使用Homo NN组件:使用FATE附带的读取器和转换器接口输入表数据并转换数据格式,然后将数据输入到算法组件中。然后NN组件将使用自定义的模型、优化器和损失函数进行训练和模型聚合。
在FATE-1.10中,pipline中的Homo NN增加了对pytorch的支持。可以遵循pytorch Sequential的用法,使用pytorch的内置层来定义Sequentious模型并提交模型。同时,可以使用Pytorch附带的损失函数和优化器。
下面是一个基本的二元分类任务 Homo NN任务。有两个客户端的party id分别为10000和9999,10000被指定为服务器端聚合模型。
上传表数据
一开始,我们将数据上传到FATE。可以使用pipline直接上传数据。在这里,我们上传两个文件:guest的文件为bream_homo_guest.csv,host的文件为broam_homo_host.csv。在这里,我们使用的是单机版,如果使用的是集群版本,则需要在每台机器上上传相应的数据。
from pipeline.backend.pipeline import PipeLine # pipeline Class# [9999(guest), 10000(host)] as client
# [10000(arbiter)] as serverguest = 9999
host = 10000
arbiter = 10000
pipeline_upload = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host, arbiter=arbiter)partition = 4# upload a dataset
path_to_fate_project = '../../../../'
guest_data = {"name": "breast_homo_guest", "namespace": "experiment"}
host_data = {"name": "breast_homo_host", "namespace": "experiment"}
pipeline_upload.add_upload_data(file="examples/data/breast_homo_guest.csv", # file in the example/datatable_name=guest_data["name"], # table namenamespace=guest_data["namespace"], # namespacehead=1, partition=partition) # data info
pipeline_upload.add_upload_data(file="examples/data/breast_homo_host.csv", # file in the example/datatable_name=host_data["name"], # table namenamespace=host_data["namespace"], # namespacehead=1, partition=partition) # data infopipeline_upload.upload(drop=1)
编写pipline脚本并执行
上传完成后,我们可以开始编写pipline脚本来提交FATE任务。
先导入相应的组件:
# torch
import torch as t
from torch import nn# pipeline
from pipeline.component.homo_nn import HomoNN, TrainerParam # HomoNN Component, TrainerParam for setting trainer parameter
from pipeline.backend.pipeline import PipeLine # pipeline class
from pipeline.component import Reader, DataTransform, Evaluation # Data I/O and Evaluation
from pipeline.interface import Data # Data Interaces for defining data flow
我们先可以检查Homo NN组件的参数:
print(HomoNN.__doc__)Parameters
----------
name, name of this component
trainer, trainer param
dataset, dataset param
torch_seed, global random seed
loss, loss function from fate_torch
optimizer, optimizer from fate_torch
model, a fate torch sequential defining the model structure
fate_arch_hook
请务必执行fate_arch_hook函数,该函数可以修改torch的某些类,以便pipline可以解析和提交您在脚本中定义的torch层、序列、优化器和损失函数。
from pipeline import fate_torch_hook
t = fate_torch_hook(t)
pipeline
# 创建一个pipeline来提交作业
guest = 9999
host = 10000
arbiter = 10000
pipeline = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host, arbiter=arbiter)# read uploaded dataset
train_data_0 = {"name": "breast_homo_guest", "namespace": "experiment"}
train_data_1 = {"name": "breast_homo_host", "namespace": "experiment"}
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(role='guest', party_id=guest).component_param(table=train_data_0)
reader_0.get_party_instance(role='host', party_id=host).component_param(table=train_data_1)# 转换组件将上传的数据转换为DATE标准格式
data_transform_0 = DataTransform(name='data_transform_0')
data_transform_0.get_party_instance(role='guest', party_id=guest).component_param(with_label=True, output_format="dense")
data_transform_0.get_party_instance(role='host', party_id=host).component_param(with_label=True, output_format="dense")"""
定义 Pytorch model/ optimizer 以及 loss
"""
model = nn.Sequential(nn.Linear(30, 1),nn.Sigmoid()
)
loss = nn.BCELoss()
optimizer = t.optim.Adam(model.parameters(), lr=0.01)"""
创建 Homo-NN 组件
"""
nn_component = HomoNN(name='nn_0',model=model, # set modelloss=loss, # set lossoptimizer=optimizer, # set optimizer# Here we use fedavg trainer# TrainerParam passes parameters to fedavg_trainer, see below for details about Trainertrainer=TrainerParam(trainer_name='fedavg_trainer', epochs=3, batch_size=128, validation_freqs=1),torch_seed=100 # random seed)# define work flow
pipeline.add_component(reader_0)
pipeline.add_component(data_transform_0, data=Data(data=reader_0.output.data))
pipeline.add_component(nn_component, data=Data(train_data=data_transform_0.output.data))
pipeline.add_component(Evaluation(name='eval_0'), data=Data(data=nn_component.output.data))pipeline.compile()
pipeline.fit()
获取组件输出
# get predict scores
pipeline.get_component('nn_0').get_output_data()
# get summary
pipeline.get_component('nn_0').get_summary()
训练器参数和训练器
在这个版本中,Homo NN的训练逻辑和联邦聚合逻辑都在Trainer类中实现。fedavg_trainer是FATE Homo NN的默认trainer,它实现了标准的fedavg算法。TrainerParam的功能是:
-
使用trainer_name=“{module name}”指定要使用的Trainer 。Trainer 位于federatedml.nn.home.trainer目录中,可以自定义Trainer 。
-
剩余的参数将被传递到训练器的__init_()接口
我们可以在FATE中检查fedavg_trainer的参数,这些可用的参数可以填写在TrainerParam中。
导入组件,from federatedml.nn.homo.trainer.fedavg_trainer import FedAVGTrainer
查看FedAVGTrainer的文档以了解可用参数。提交任务时,可以通过TrainerParam传递这些参数
print(FedAVGTrainer.__doc__)
Parameters----------epochs: int >0, epochs to trainbatch_size: int, -1 means full batchsecure_aggregate: bool, default is True, whether to use secure aggregation. if enabled, will add random numbermask to local models. These random number masks will eventually cancel out to get 0.weighted_aggregation: bool, whether add weight to each local model when doing aggregation.if True, According to origin paper, weight of a client is: n_local / n_global, where n_localis the sample number locally and n_global is the sample number of all clients.if False, simply averaging these models.early_stop: None, 'diff' or 'abs'. if None, disable early stop; if 'diff', use the loss difference betweentwo epochs as early stop condition, if differences < tol, stop training ; if 'abs', if loss < tol,stop trainingtol: float, tol value for early stopaggregate_every_n_epoch: None or int. if None, aggregate model on the end of every epoch, if int, aggregateevery n epochs.cuda: bool, use cuda or notpin_memory: bool, for pytorch DataLoadershuffle: bool, for pytorch DataLoaderdata_loader_worker: int, for pytorch DataLoader, number of workers when loading datavalidation_freqs: None or int. if int, validate your model and send validate results to fate-board every n epoch.
...task_type: str, 'auto', 'binary', 'multi', 'regression'this option decides the return format of this trainer, and the evaluation type when running validation.if auto, will automatically infer your task type from labels and predict results.
到目前为止,我们已经对Homo NN有了基本的了解,可以利用它来执行基本的建模任务。此外,Homo NN提供了为更高级的用例定制模型、数据集和训练器的能力。
3.2 Hetero-NN Quick Start: A Binary Classification Task
需要注意的是,Hetero NN也已升级为与Homo NN类似的工作方式,允许使用Pytorch后端对模型和数据集进行高度定制。
此外,Hetero-NN还改进了一些接口,如交互层接口,使其使用逻辑更加清晰。
在本章中,提供一个使用Hetero-NN的基本二分类任务的示例。使用该算法的过程与其他FATE算法一致:使用FATE提供的读取器和转换器接口来输入表数据,然后将数据输入到算法组件中。然后,组件将使用定义好的顶部/底部模型、优化器和损失函数进行训练。此版本的用法与旧版本的FATE的用法基本相同。
上传表数据
首先,将数据上传到FATE。我们可以使用pipline直接上传数据。在这里,我们上传两个文件:guest的文件为bream_hetero_guest.csv,host的文件为broam_hetero_host.csv。在个示例中,我们使用的是单机版,如果使用的是集群版,则需要在每台机器上上传相应的数据。
from pipeline.backend.pipeline import PipeLine # pipeline class# we have two party: guest, whose data with labels
# host, without label
# the dataset is vertically splitdense_data_guest = {"name": "breast_hetero_guest", "namespace": f"experiment"}
dense_data_host = {"name": "breast_hetero_host", "namespace": f"experiment"}guest= 9999
host = 10000pipeline_upload = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host)partition = 4# 上传一份数据
pipeline_upload.add_upload_data(file="./examples/data/breast_hetero_guest.csv",table_name=dense_data_guest["name"], # table namenamespace=dense_data_guest["namespace"], # namespacehead=1, partition=partition) # data infopipeline_upload.add_upload_data(file="./examples/data/breast_hetero_host.csv",table_name=dense_data_host["name"],namespace=dense_data_host["namespace"],head=1, partition=partition) # data infopipeline_upload.upload(drop=1)
breast数据集是一个具有30个特征的二分类数据集,它是垂直分割的:
guest拥有10个特征和标签,而host拥有20个特征
import pandas as pd
df = pd.read_csv('../../../../examples/data/breast_hetero_guest.csv')
df
--------------------------------------------
import pandas as pd
df = pd.read_csv('../../../../examples/data/breast_hetero_host.csv')
df
编写pipline脚本并执行
上传完成后,我们可以开始编写脚本来提交FATE任务。
import torch as t
from torch import nn
from pipeline.backend.pipeline import PipeLine # pipeline Class
from pipeline import fate_torch_hook
from pipeline.component import HeteroNN, Reader, DataTransform, Intersection # Hetero NN Component, Data IO component, PSI component
from pipeline.interface import Data, Model # data, model for defining the work flow
fate_arch_hook
执行fate_arch_hook函数,该函数可以修改torch的某些类,以便pipline可以解析和提交在脚本中定义的torch层、序列、优化器和损失函数。
from pipeline import fate_torch_hook
t = fate_torch_hook(t)
guest = 9999
host = 10000
pipeline = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host)guest_train_data = {"name": "breast_hetero_guest", "namespace": "experiment"}
host_train_data = {"name": "breast_hetero_host", "namespace": "experiment"}pipeline = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host)# read uploaded dataset
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(role='guest', party_id=guest).component_param(table=guest_train_data)
reader_0.get_party_instance(role='host', party_id=host).component_param(table=host_train_data)
# The transform component converts the uploaded data to the DATE standard format
data_transform_0 = DataTransform(name="data_transform_0")
data_transform_0.get_party_instance(role='guest', party_id=guest).component_param(with_label=True)
data_transform_0.get_party_instance(role='host', party_id=host).component_param(with_label=False)
# intersection
intersection_0 = Intersection(name="intersection_0")
Hetero-NN组件
在这里,我们初始化Hetero-NN组件。使用get_party_instance分别获取guest组件和host组件。由于双方的模型体系结构不同,我们必须使用各自的组件为每一方指定模型参数。
hetero_nn_0 = HeteroNN(name="hetero_nn_0", epochs=2,interactive_layer_lr=0.01, batch_size=-1, validation_freqs=1, task_type='classification', seed=114514)
guest_nn_0 = hetero_nn_0.get_party_instance(role='guest', party_id=guest)
host_nn_0 = hetero_nn_0.get_party_instance(role='host', party_id=host)
定义guest和host模型
# Guest Bottom, Top Model
guest_bottom = t.nn.Sequential(nn.Linear(10, 2),nn.ReLU()
)
guest_top = t.nn.Sequential(nn.Linear(2, 1),nn.Sigmoid()
)# Host Bottom Model
host_bottom = t.nn.Sequential(nn.Linear(20, 2),nn.ReLU()
)# After using fate_torch_hook, nn module can use InteractiveLayer, you can view the structure of Interactive layer with print
interactive_layer = t.nn.InteractiveLayer(out_dim=2, guest_dim=2, host_dim=2, host_num=1)
print(interactive_layer)guest_nn_0.add_top_model(guest_top)
guest_nn_0.add_bottom_model(guest_bottom)
host_nn_0.add_bottom_model(host_bottom)optimizer = t.optim.Adam(lr=0.01) # Notice! After fate_torch_hook, the optimizer can be initialized without model parameter
loss = t.nn.BCELoss()hetero_nn_0.set_interactive_layer(interactive_layer)
hetero_nn_0.compile(optimizer=optimizer, loss=loss)----------------------------------------------------------
InteractiveLayer((activation): ReLU()(guest_model): Linear(in_features=2, out_features=2, bias=True)(host_model): ModuleList((0): Linear(in_features=2, out_features=2, bias=True))(act_seq): Sequential((0): ReLU())
pipeline.add_component(reader_0)
pipeline.add_component(data_transform_0, data=Data(data=reader_0.output.data))
pipeline.add_component(intersection_0, data=Data(data=data_transform_0.output.data))
pipeline.add_component(hetero_nn_0, data=Data(train_data=intersection_0.output.data))
pipeline.compile()pipeline.fit()
获取组件输出
# get predict scores
pipeline.get_component('hetero_nn_0').get_output_data()
# get summary
pipeline.get_component('hetero_nn_0').get_summary()
-----------------------------------------------
{'best_iteration': -1,'history_loss': [0.9929580092430115, 0.9658427238464355],'is_converged': False,'validation_metrics': {'train': {'auc': [0.8850615717985308,0.9316368056656624],'ks': [0.6326568363194334, 0.7479123724961683]}}}
到目前为止,我们已经对Hetero-NN有了基本的了解,可以用于执行基本的建模任务。Hetero-NN还支持使用更复杂的模型和数据集。
4. 自定义数据集
FATE主要将表格数据作为其标准数据格式。然而,通过使用NN模块的数据集功能,可以在神经网络中使用非表格数据,如图像、文本、混合数据或关系数据。NN模块中的数据集模块允许自定义数据集,以便在更复杂的数据场景中使用。介绍Homo NN模块中数据集功能的使用,并提供如何自定义数据集的指导。我们将以MNIST手写识别任务为例来说明这些概念。
准备 MNIST Data
从下面的链接下载MNIST数据集,并将其放在项目examples/data文件夹中:
https://webank-ai-1251170195.cos.ap-guangzhou.myqcloud.com/fate/examples/data/mnist.zip
这是MNIST数据集的简化版,共有十个类别,根据标签分为0-9个文件夹,对数据集进行了采样以减少样本数量。
原始数据集为:
http://yann.lecun.com/exdb/mnist/
! ls ../../../../examples/data/mnist
---------------------------------------
0 1 2 3 4 5 6 7 8 9
数据集
在FATE-1.10版本中,FATE为数据集引入了一个新的基类Dataset(./python/federatedml/nn/Dataset/base.py),它基于PyTorch的Dataset类。此类允许用户根据自己的需求创建自定义数据集。其用法与PyTorch的Dataset类类似,增加了在使用FATE-NN进行数据读取和训练时实现两个额外接口的要求:load()和get_sample_ids()。
要在Homo NN中创建自定义数据集,用户需要:
- 开发从dataset类继承的新数据集类
- 实现与PyTorch的数据集用法一致的_len_()和_getitem_()方法,前者应返回数据集的长度,后者应返回指定索引处的相应数据
- 实现load()和get_sample_ids()方法
如果不熟悉PyTorch的Dataset类,可以在PyTorch文档中找到更多信息:Pyttorch Dataset documentation
load()
所需的第一个附加接口是load()。此接口接收文件路径,并允许用户直接从本地文件系统读取数据。提交任务时,可以通过读取器组件指定数据路径。Homo NN将使用用户指定的Dataset类,利用load()接口从指定路径读取数据,并完成数据集的加载以进行训练。更多信息,可以参阅/federatedml/nn/dataset/base.py中的源代码。
get_sample_ids()
第二个附加接口是get_sample_ids()。此接口应返回一个样本ID列表,该列表可以是整数或字符串,并且应具有与数据集相同的长度。实际上,当使用Homo NN时,可以跳过该接口,因为Homo NN组件将自动为样本生成ID。
示例:实现一个简单的图像数据集
为了更好地理解数据集的定制,我们实现了一个简单的图像数据集来读取MNIST图像,然后在横向场景中完成联邦图像分类任务
为了方便起见,我们使用save_to_state的jupyter接口将代码更新为federatedml.nn.dataset,名为mnist_dataset.py,当然也可以手动将代码文件复制到目录中
from pipeline.component.nn import save_to_fate
MNIST数据集
%%save_to_fate dataset mnist_dataset.py
import numpy as np
from federatedml.nn.dataset.base import Dataset
from torchvision.datasets import ImageFolder
from torchvision import transformsclass MNISTDataset(Dataset):def __init__(self, flatten_feature=False): # flatten feature or not super(MNISTDataset, self).__init__()self.image_folder = Noneself.ids = Noneself.flatten_feature = flatten_featuredef load(self, path): # read data from path, and set sample ids# read using ImageFolderself.image_folder = ImageFolder(root=path, transform=transforms.Compose([transforms.ToTensor()]))# filename as the image idids = []for image_name in self.image_folder.imgs:ids.append(image_name[0].split('/')[-1].replace('.jpg', ''))self.ids = idsreturn selfdef get_sample_ids(self): # implement the get sample id interface, simply return idsreturn self.idsdef __len__(self,): # return the length of the datasetreturn len(self.image_folder)def __getitem__(self, idx): # get itemret = self.image_folder[idx]if self.flatten_feature:img = ret[0][0].flatten() # return flatten tensor 784-dimreturn img, ret[1] # return tensor and labelelse:return ret
在实现数据集之后,可以在本地对其进行测试:
from federatedml.nn.dataset.mnist_dataset import MNISTDatasetds = MNISTDataset(flatten_feature=True)
# load MNIST data and check
ds.load('../../../../examples/data/mnist/')
print(len(ds))
print(ds[0])
print(ds.get_sample_ids()[0])
1309
(tensor([0.0118, 0.0000, 0.0000, 0.0118, 0.0275, 0.0118, 0.0000, 0.0118, 0.0000,0.0431, 0.0000, 0.0000, 0.0118, 0.0000, 0.0000, 0.0118, 0.0314, 0.0000,0.0000, 0.0118, 0.0000, 0.0000, 0.0000, 0.0078, 0.0000, 0.0000, 0.0000,0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0039,0.0196, 0.0000, 0.0471, 0.0000, 0.0627, 0.0000, 0.0000, 0.0157, 0.0000,0.0078, 0.0314, 0.0118, 0.0000, 0.0157, 0.0314, 0.0000, 0.0000, 0.0000,0.0000, 0.0000, 0.0000, 0.0000, 0.0078, 0.0000, 0.0000, 0.0000, 0.0039,0.0078, 0.0039, 0.0471, 0.0000, 0.0314, 0.0000, 0.0000, 0.0235, 0.0000,0.0431, 0.0000, 0.0000, 0.0235, 0.0275, 0.0078, 0.0000, 0.0000, 0.0000,0.0000, 0.0000, 0.0000, 0.0000, 0.0039, 0.0118, 0.0000, 0.0000, 0.0078,0.0118, 0.0000, 0.0000, 0.0000, 0.0471, 0.0000, 0.0000, 0.0902, 0.0000,0.0000, 0.0000, 0.0000, 0.0431, 0.0118, 0.0000, 0.0000, 0.0157, 0.0000,0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0039, 0.0039, 0.0000, 0.0000,0.0078, 0.0000, 0.0000, 0.0235, 0.0000, 0.0980, 0.1059, 0.5333, 0.5294,0.7373, 0.3490, 0.3294, 0.0980, 0.0000, 0.0000, 0.0118, 0.0039, 0.0000,0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0157, 0.0000, 0.0000, 0.0000,0.0000, 0.0000, 0.0000, 0.0000, 0.0118, 0.3451, 0.9686, 0.9255, 1.0000,0.9765, 0.9804, 0.8902, 0.9412, 0.5333, 0.1451, 0.0039, 0.0000, 0.0078,0.0078, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0078, 0.0000, 0.0000,0.0118, 0.0000, 0.0000, 0.0157, 0.1059, 0.7569, 0.9843, 0.9922, 1.0000,1.0000, 1.0000, 1.0000, 0.9412, 0.9961, 1.0000, 0.8353, 0.3490, 0.0000,0.0000, 0.0549, 0.0039, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,0.0000, 0.0235, 0.0000, 0.0000, 0.0706, 0.2196, 0.9647, 1.0000, 0.9922,0.9529, 0.9843, 1.0000, 0.9608, 1.0000, 1.0000, 0.9961, 1.0000, 0.9059,
...0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,0.0000]), 0)
测试数据集
在提交任务之前,可以在本地进行测试。 Homo NN Quick Start:A Binary Classification Task中提到的,在Homo NN中,FATE默认使用fedavg_trainer。自定义数据集、模型和训练器可以用于本地调试,以测试程序是否正确运行。
在本地测试期间,将跳过所有联邦进程,并且模型不会执行联邦平均
from federatedml.nn.homo.trainer.fedavg_trainer import FedAVGTrainer
trainer = FedAVGTrainer(epochs=3, batch_size=256, shuffle=True, data_loader_worker=8, pin_memory=False) # set parametertrainer.local_mode() # !! Be sure to enable local_mode to skip the federation process !!import torch as t
from pipeline import fate_torch_hook
fate_torch_hook(t)
# our simple classification model:
model = t.nn.Sequential(t.nn.Linear(784, 32),t.nn.ReLU(),t.nn.Linear(32, 10),t.nn.Softmax(dim=1)
)trainer.set_model(model) # set modeloptimizer = t.optim.Adam(model.parameters(), lr=0.01) # optimizer
loss = t.nn.CrossEntropyLoss() # loss function
trainer.train(train_set=ds, optimizer=optimizer, loss=loss) # use dataset we just developed
在Trainer的train()函数中,数据集将使用Pytorch DataLoader进行迭代。
使用数据集提交任务
导入组件
import torch as t
from torch import nn
from pipeline import fate_torch_hook
from pipeline.component import HomoNN
from pipeline.backend.pipeline import PipeLine
from pipeline.component import Reader, Evaluation, DataTransform
from pipeline.interface import Data, Modelt = fate_torch_hook(t)将数据路径绑定到name和namespace
在这里,我们使用pipline将路径绑定到name和namespace。然后,我们可以使用读取器组件将此路径传递到数据集的“load”接口。
trainer将在train()中获取此数据集,并使用Pytorch Dataloader对其进行迭代我们使用的是单机版,如果使用的是集群版,则需要在每台机器上绑定具有相应name和namespace
import os
# bind data path to name & namespace
fate_project_path = os.path.abspath('../../../../')
host = 10000
guest = 9999
arbiter = 10000
pipeline = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host,arbiter=arbiter)data_0 = {"name": "mnist_guest", "namespace": "experiment"}
data_1 = {"name": "mnist_host", "namespace": "experiment"}data_path_0 = fate_project_path + '/examples/data/mnist'
data_path_1 = fate_project_path + '/examples/data/mnist'
pipeline.bind_table(name=data_0['name'], namespace=data_0['namespace'], path=data_path_0)
pipeline.bind_table(name=data_1['name'], namespace=data_1['namespace'], path=data_path_1)
{‘namespace’: ‘experiment’, ‘table_name’: ‘mnist_host’}
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(role='guest', party_id=guest).component_param(table=data_0)
reader_0.get_party_instance(role='host', party_id=host).component_param(table=data_1)
数据集参数
使用dataset_name指定数据集的模块名称,并在后面填写其参数,这些参数将传递到数据集的接口
数据集参数需要是JSON序列,否则pipline无法解析它们
from pipeline.component.nn import DatasetParamdataset_param = DatasetParam(dataset_name='mnist_dataset', flatten_feature=True) # specify dataset, and its init parametersfrom pipeline.component.homo_nn import TrainerParam # Interface# our simple classification model:
model = t.nn.Sequential(t.nn.Linear(784, 32),t.nn.ReLU(),t.nn.Linear(32, 10),t.nn.Softmax(dim=1)
)nn_component = HomoNN(name='nn_0',model=model, # modelloss=t.nn.CrossEntropyLoss(), # lossoptimizer=t.optim.Adam(model.parameters(), lr=0.01), # optimizerdataset=dataset_param, # datasettrainer=TrainerParam(trainer_name='fedavg_trainer', epochs=2, batch_size=1024, validation_freqs=1),torch_seed=100 # random seed)pipeline.add_component(reader_0)
pipeline.add_component(nn_component, data=Data(train_data=reader_0.output.data))
pipeline.add_component(Evaluation(name='eval_0', eval_type='multi'), data=Data(data=nn_component.output.data))pipeline.compile()
pipeline.fit()pipeline.get_component('nn_0').get_output_data()
pipeline.get_component('nn_0').get_summary()
5. 自定义损失函数
当Pytorch内置的Loss功能无法满足您的使用需求时,您可以使用自定义Loss来训练您的模型
MNIST示例的一个小问题
可能会注意到,在上一个教程的MNIST示例中,分类器输出分数是Softmax函数的结果,我们使用torch内置的CrossEntropyLoss来计算损失。但是,它显示在文档中(Cross EntropyLoss Doc)输入应包含每个类的unnormalized logits,也就是说,在该示例中,我们计算了Softmax两次。
为了解决这个问题,我们可以使用自定义的CrossEntropyLoss。
自定义损失
Customized Loss是一个类,它是torch.nn.Module的子类,并实现正向函数。在FATE训练器中,损失函数将传递两个参数:预测分数和标签(loss_fn(pred,loss)),因此当使用FATE的训练器时,损失函数需要将两个参数作为输入(预测分数和标签)。但是,如果您使用自己的训练器,并定义了自己的训练流程,则不限制如何使用损失函数。
新的交叉熵损失
在这里,实现了新的CrossEntropyLoss,它跳过了softmax计算。可以使用jupyter接口:save_to_state,将代码更新为federatedml.nn.loss,名为ce.py,当然也可以手动将代码文件复制到目录中。
import torch as t
from federatedml.util import consts
from torch.nn.functional import one_hotdef cross_entropy(p2, p1, reduction='mean'):p2 = p2 + consts.FLOAT_ZERO # to avoid nanassert p2.shape == p1.shapeif reduction == 'sum':return -t.sum(p1 * t.log(p2))elif reduction == 'mean':return -t.mean(t.sum(p1 * t.log(p2), dim=1))elif reduction == 'none':return -t.sum(p1 * t.log(p2), dim=1)else:raise ValueError('unknown reduction')class CrossEntropyLoss(t.nn.Module):"""A CrossEntropy Loss that will not compute Softmax"""def __init__(self, reduction='mean'):super(CrossEntropyLoss, self).__init__()self.reduction = reductiondef forward(self, pred, label):one_hot_label = one_hot(label.flatten())loss_ = cross_entropy(pred, one_hot_label, self.reduction)return loss_
用新的损失函数训练
import torch as t
from torch import nn
from pipeline import fate_torch_hook
from pipeline.component import HomoNN
from pipeline.backend.pipeline import PipeLine
from pipeline.component import Reader, Evaluation, DataTransform
from pipeline.interface import Data, Modelt = fate_torch_hook(t)import os
# bind data path to name & namespace
fate_project_path = os.path.abspath('../../../../')
arbiter = 10000
host = 10000
guest = 9999
pipeline = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host,arbiter=arbiter)data_0 = {"name": "mnist_guest", "namespace": "experiment"}
data_1 = {"name": "mnist_host", "namespace": "experiment"}data_path_0 = fate_project_path + '/examples/data/mnist'
data_path_1 = fate_project_path + '/examples/data/mnist'
pipeline.bind_table(name=data_0['name'], namespace=data_0['namespace'], path=data_path_0)
pipeline.bind_table(name=data_1['name'], namespace=data_1['namespace'], path=data_path_1)
在fate_arch_hook之后,我们可以使用t.nn.CustLoss指定自己的损失。在参数中指定模块名称和类名,后面是loss类的初始化参数
初始化参数必须是JSON序列,否则无法提交
from pipeline.component.homo_nn import TrainerParam, DatasetParam # Interface# your loss class
loss = t.nn.CustLoss(loss_module_name='cross_entropy', class_name='CrossEntropyLoss', reduction='mean')# our simple classification model:
model = t.nn.Sequential(t.nn.Linear(784, 32),t.nn.ReLU(),t.nn.Linear(32, 10),t.nn.Softmax(dim=1)
)nn_component = HomoNN(name='nn_0',model=model, # modelloss=loss, # lossoptimizer=t.optim.Adam(model.parameters(), lr=0.01), # optimizerdataset=DatasetParam(dataset_name='mnist_dataset', flatten_feature=True), # datasettrainer=TrainerParam(trainer_name='fedavg_trainer', epochs=2, batch_size=1024, validation_freqs=1),torch_seed=100 # random seed)
pipeline.add_component(reader_0)
pipeline.add_component(nn_component, data=Data(train_data=reader_0.output.data))
pipeline.add_component(Evaluation(name='eval_0', eval_type='multi'), data=Data(data=nn_component.output.data))
pipeline.compile()
pipeline.fit()pipeline.get_component('nn_0').get_output_data()
pipeline.get_component('nn_0').get_summary()
6. 自定义模型
将模型代码命名为image_net.py,可以直接放在federatedml/nn/model_zoo下,也可以使用jupyter笔记本的快捷界面直接保存到federatedml/nn/model_zoo
from pipeline.component.nn import save_to_fate
%%save_to_fate model image_net.py
import torch as t
from torch import nn
from torch.nn import Module# the residual component
class Residual(Module):def __init__(self, ch, kernel_size=3, padding=1):super(Residual, self).__init__()self.convs = t.nn.ModuleList([nn.Conv2d(ch, ch, kernel_size=kernel_size, padding=padding) for i in range(2)])self.act = nn.ReLU()def forward(self, x):x = self.act(self.convs[0](x))x_ = self.convs[1](x)return self.act(x + x_)# we call it image net
class ImgNet(nn.Module):def __init__(self, class_num=10):super(ImgNet, self).__init__()self.seq = t.nn.Sequential(nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5),Residual(12),nn.MaxPool2d(kernel_size=3),nn.Conv2d(in_channels=12, out_channels=12, kernel_size=3),Residual(12),nn.AvgPool2d(kernel_size=3))self.fc = t.nn.Sequential(nn.Linear(48, 32),nn.ReLU(),nn.Linear(32, class_num))self.softmax = nn.Softmax(dim=1)def forward(self, x):x = self.seq(x)x = x.flatten(start_dim=1)x = self.fc(x)if self.training:return xelse:return self.softmax(x)
img_model = ImgNet(10)
img_model
---------------------------
ImgNet((seq): Sequential((0): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))(1): Residual((convs): ModuleList((0): Conv2d(12, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): Conv2d(12, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(act): ReLU())(2): MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, ceil_mode=False)(3): Conv2d(12, 12, kernel_size=(3, 3), stride=(1, 1))(4): Residual((convs): ModuleList((0): Conv2d(12, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): Conv2d(12, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(act): ReLU())(5): AvgPool2d(kernel_size=3, stride=3, padding=0))(fc): Sequential((0): Linear(in_features=48, out_features=32, bias=True)(1): ReLU()(2): Linear(in_features=32, out_features=10, bias=True))(softmax): Softmax(dim=1)
)
from federatedml.nn.dataset.image import ImageDatasetds = ImageDataset()
ds.load('../../../../examples/data/mnist/')
img_model(i[0])
-------------------
tensor([[ 1.3241e-01, 1.3432e-01, 3.6705e-02, 3.9092e-02, -1.2944e-01,5.4261e-02, -1.8467e-01, 1.0478e-01, 1.0396e-03, 4.6396e-02],[ 1.3575e-01, 1.3287e-01, 3.7010e-02, 3.5438e-02, -1.3169e-01,4.9747e-02, -1.8520e-01, 1.0215e-01, 3.3909e-03, 4.6577e-02],[ 1.3680e-01, 1.3542e-01, 3.6674e-02, 3.4830e-02, -1.3046e-01,4.8866e-02, -1.8568e-01, 1.0199e-01, 4.7719e-03, 4.7090e-02],[ 1.3564e-01, 1.3297e-01, 3.6487e-02, 3.5213e-02, -1.3040e-01,5.0300e-02, -1.8406e-01, 1.0286e-01, 3.6997e-03, 4.4414e-02],[ 1.3091e-01, 1.3101e-01, 3.5820e-02, 3.9637e-02, -1.3302e-01,5.2289e-02, -1.8336e-01, 1.0439e-01, 2.8879e-03, 4.4465e-02],[ 1.3206e-01, 1.3344e-01, 3.7300e-02, 3.8817e-02, -1.3155e-01,5.3004e-02, -1.8556e-01, 1.0341e-01, 7.9196e-05, 4.6511e-02],[ 1.3058e-01, 1.3162e-01, 3.5691e-02, 4.0402e-02, -1.3395e-01,5.1268e-02, -1.8198e-01, 1.0670e-01, 3.6078e-03, 4.4348e-02],[ 1.3416e-01, 1.3208e-01, 3.6845e-02, 3.6941e-02, -1.3210e-01,5.2559e-02, -1.8635e-01, 1.0151e-01, 1.1148e-03, 4.7174e-02]],grad_fn=<AddmmBackward0>)
本地测试
我们可以使用我们的数据集、自定义模型和Trainer进行本地调试,以测试程序是否可以运行。
import torch as t
from federatedml.nn.homo.trainer.fedavg_trainer import FedAVGTrainer
trainer = FedAVGTrainer(epochs=3, batch_size=256, shuffle=True, data_loader_worker=8, pin_memory=False)
trainer.set_model(img_model) # set modeltrainer.local_mode() # !! use local mode to skip federation process !!optimizer = t.optim.Adam(img_model.parameters(), lr=0.01)
loss = t.nn.CrossEntropyLoss()
trainer.train(train_set=ds, optimizer=optimizer, loss=loss)
提交一个 Homo-NN 任务并使用 自定义Model
import torch as t
from torch import nn
from pipeline import fate_torch_hook
from pipeline.component import HomoNN
from pipeline.backend.pipeline import PipeLine
from pipeline.component import Reader, Evaluation, DataTransform
from pipeline.interface import Data, Modelt = fate_torch_hook(t)import os
# bind data path to name & namespace
fate_project_path = os.path.abspath('../../../../')
host = 10000
guest = 9999
arbiter = 10000
pipeline = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host,arbiter=arbiter)data_0 = {"name": "mnist_guest", "namespace": "experiment"}
data_1 = {"name": "mnist_host", "namespace": "experiment"}data_path_0 = fate_project_path + '/examples/data/mnist'
data_path_1 = fate_project_path + '/examples/data/mnist'
pipeline.bind_table(name=data_0['name'], namespace=data_0['namespace'], path=data_path_0)
pipeline.bind_table(name=data_1['name'], namespace=data_1['namespace'], path=data_path_1)# 定义reader
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(role='guest', party_id=guest).component_param(table=data_0)
reader_0.get_party_instance(role='host', party_id=host).component_param(table=data_1)
nn.CustModel
在fate_arch_hook之后,我们可以使用t.nn.CustModel来指定模型。在此处指定模块名称和类名。也可以在此处设置模型初始化参数
from pipeline.component.homo_nn import DatasetParam, TrainerParammodel = t.nn.Sequential(# the class_num=10 is the initialzation parameter for your modelt.nn.CustModel(module_name='image_net', class_name='ImgNet', class_num=10)
)nn_component = HomoNN(name='nn_0',model=model, # your cust modelloss=t.nn.CrossEntropyLoss(),optimizer=t.optim.Adam(model.parameters(), lr=0.01),dataset=DatasetParam(dataset_name='image'), # use image datasettrainer=TrainerParam(trainer_name='fedavg_trainer', epochs=3, batch_size=1024, validation_freqs=1),torch_seed=100 # global random seed)pipeline.add_component(reader_0)
pipeline.add_component(nn_component, data=Data(train_data=reader_0.output.data))
pipeline.add_component(Evaluation(name='eval_0', eval_type='multi'), data=Data(data=nn_component.output.data))pipeline.compile()
pipeline.fit()
7. 自定义Trainer控制训练流程
TrainerBase Class是FATE中所有Homo NN Trainer的基础。要创建自定义训练器,需要将federatedml.homo.trainer_base(./python/federatedml/nn/homo/trainer/trainer_base.py)中的TrainerBase类进行子类化。必须实现两个必需的功能:
-
train()函数:此函数接收五个参数:一个训练数据集实例(必须是dataset的子类)、一个验证数据集实例,也是dataset的一个子类、具有初始化训练参数的优化器实例、一个损失函数,以及一个可能包含热启动任务的额外数据的字典。在该函数中,可以定义Homo NN任务的客户端训练和联邦过程。
-
server_aggregate_procedure()函数:此函数接收一个参数,即一个额外的数据字典,该字典可能包含热启动任务的额外数据。它由服务器调用,可以在其中定义聚合过程。
-
还有一个可选的predict()函数,它接收一个参数,即数据集,并允许定义trainer进行预测。如果想使用FATE框架,需要确保返回数据格式正确,以便FATE能够正确显示它。
在Homo NN客户端组件中,set_model()函数用于将初始化的模型设置为训练器。在开发训练器时,可以使用“set_model()”设置模型,然后在训练器中使用“self.model”访问模型。
此处显示这些接口的源代码:
class TrainerBase(object):def __init__(self, **kwargs):...self._model = None......@propertydef model(self):if not hasattr(self, '_model'):raise AttributeError('model variable is not initialized, remember to call'' super(your_class, self).__init__()')if self._model is None:raise AttributeError('model is not set, use set_model() function to set training model')return self._model@model.setterdef model(self, val):self._model = val@abc.abstractmethoddef train(self, train_set, validate_set=None, optimizer=None, loss=None, extra_data={}):"""train_set : A Dataset Instance, must be a instance of subclass of Dataset (federatedml.nn.dataset.base),for example, TableDataset() (from federatedml.nn.dataset.table)validate_set : A Dataset Instance, but optional must be a instance of subclass of Dataset(federatedml.nn.dataset.base), for example, TableDataset() (from federatedml.nn.dataset.table)optimizer : A pytorch optimizer class instance, for example, t.optim.Adam(), t.optim.SGD()loss : A pytorch Loss class, for example, nn.BECLoss(), nn.CrossEntropyLoss()"""pass@abc.abstractmethoddef predict(self, dataset):pass@abc.abstractmethoddef server_aggregate_procedure(self, extra_data={}):pass
Fed模式/本地模式
Trainer的属性“self.fed_mode”在运行联合任务时设置为True。可以使用此变量来确定trainer是在联邦模式下运行还是在本地调试模式下运行。如果想在本地测试训练器,可以使用“local_mode()”函数将“self.fed_mode”设置为False。
示例:开发一个 Toy FedProx
通过演示FedProx算法的实现来提供一个具体的示例https://arxiv.org/abs/1812.06127.在FedProx中,训练过程与标准FedAVG算法略有不同,因为在计算损失时,它需要从当前模型和全局模型计算近端项。
from pipeline.component.nn import save_to_fate
%%save_to_fate trainer fedprox.py
import copy
from federatedml.nn.homo.trainer.trainer_base import TrainerBase
from torch.utils.data import DataLoader
# We need to use aggregator client&server class for federation
from federatedml.framework.homo.aggregator.secure_aggregator import SecureAggregatorClient, SecureAggregatorServer
# We use LOGGER to output logs
from federatedml.util import LOGGERclass ToyFedProxTrainer(TrainerBase):def __init__(self, epochs, batch_size, u):super(ToyFedProxTrainer, self).__init__()# trainer parametersself.epochs = epochsself.batch_size = batch_sizeself.u = u# Given two model, we compute the proximal termdef _proximal_term(self, model_a, model_b):diff_ = 0for p1, p2 in zip(model_a.parameters(), model_b.parameters()):diff_ += ((p1-p2.detach())**2).sum()return diff_# implement the train function, this function will be called by client side# contains the local training process and the federation partdef train(self, train_set, validate_set=None, optimizer=None, loss=None, extra_data={}):sample_num = len(train_set)aggregator = Noneif self.fed_mode:aggregator = SecureAggregatorClient(True, aggregate_weight=sample_num, communicate_match_suffix='fedprox') # initialize aggregator# set dataloaderdl = DataLoader(train_set, batch_size=self.batch_size, num_workers=4)for epoch in range(self.epochs):# the local training processLOGGER.debug('running epoch {}'.format(epoch))global_model = copy.deepcopy(self.model)loss_sum = 0# batch training processfor batch_data, label in dl:optimizer.zero_grad()pred = self.model(batch_data)loss_term_a = loss(pred, label)loss_term_b = self._proximal_term(self.model, global_model)loss_ = loss_term_a + (self.u/2) * loss_term_bloss_.backward()loss_sum += float(loss_.detach().numpy())optimizer.step()# print lossLOGGER.debug('epoch loss is {}'.format(loss_sum))# the aggregation processif aggregator is not None:self.model = aggregator.model_aggregation(self.model)converge_status = aggregator.loss_aggregation(loss_sum)# implement the aggregation function, this function will be called by the sever sidedef server_aggregate_procedure(self, extra_data={}):# initialize aggregatorif self.fed_mode:aggregator = SecureAggregatorServer(communicate_match_suffix='fedprox')# the aggregation process is simple: every epoch the server aggregate model and loss oncefor i in range(self.epochs):aggregator.model_aggregation()merge_loss, _ = aggregator.loss_aggregation()本地测试
我们可以使用local_mode()在本地测试新FedProx训练器。
import torch as t
from federatedml.nn.dataset.table import TableDatasetmodel = t.nn.Sequential(t.nn.Linear(30, 1),t.nn.Sigmoid()
)ds = TableDataset()
ds.load('../../../../examples/data/breast_homo_guest.csv')trainer = ToyFedProxTrainer(10, 128, u=0.1)
trainer.set_model(model)
opt = t.optim.Adam(model.parameters(), lr=0.01)
loss = t.nn.BCELoss()trainer.local_mode()
trainer.train(ds, None, opt, loss)提交任务
# torch
import torch as t
from torch import nn
from pipeline import fate_torch_hook
fate_torch_hook(t)
# pipeline
from pipeline.component.homo_nn import HomoNN, TrainerParam # HomoNN Component, TrainerParam for setting trainer parameter
from pipeline.backend.pipeline import PipeLine # pipeline class
from pipeline.component import Reader, DataTransform, Evaluation # Data I/O and Evaluation
from pipeline.interface import Data # Data Interaces for defining data flow# create a pipeline to submitting the job
guest = 9999
host = 10000
arbiter = 10000
pipeline = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host, arbiter=arbiter)# read uploaded dataset
train_data_0 = {"name": "breast_homo_guest", "namespace": "experiment"}
train_data_1 = {"name": "breast_homo_host", "namespace": "experiment"}
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(role='guest', party_id=guest).component_param(table=train_data_0)
reader_0.get_party_instance(role='host', party_id=host).component_param(table=train_data_1)# The transform component converts the uploaded data to the DATE standard format
data_transform_0 = DataTransform(name='data_transform_0')
data_transform_0.get_party_instance(role='guest', party_id=guest).component_param(with_label=True, output_format="dense")
data_transform_0.get_party_instance(role='host', party_id=host).component_param(with_label=True, output_format="dense")"""
Define Pytorch model/ optimizer and loss
"""
model = nn.Sequential(nn.Linear(30, 1),nn.Sigmoid()
)
loss = nn.BCELoss()
optimizer = t.optim.Adam(model.parameters(), lr=0.01)"""
Create Homo-NN Component
"""
nn_component = HomoNN(name='nn_0',model=model, # set modelloss=loss, # set lossoptimizer=optimizer, # set optimizer# Here we use fedavg trainer# TrainerParam passes parameters to fedavg_trainer, see below for details about Trainertrainer=TrainerParam(trainer_name='fedprox', epochs=3, batch_size=128, u=0.5),torch_seed=100 # random seed)# define work flow
pipeline.add_component(reader_0)
pipeline.add_component(data_transform_0, data=Data(data=reader_0.output.data))
pipeline.add_component(nn_component, data=Data(train_data=data_transform_0.output.data))
pipeline.compile()
pipeline.fit()
相关文章:

FATE框架中pipline基础教程
目录 1. 用pipline上传数据2. 用 Pipeline 进行 Hetero SecureBoost 的训练和预测3. 用 Pipeline 构建神经网络模型3.1 Homo-NN Quick Start: A Binary Classification Task3.2 Hetero-NN Quick Start: A Binary Classification Task 4. 自定义数据集示例:实现一个简…...
Atlas 元数据管理
Atlas 元数据管理 1.Atlas入门 1.1概述 元数据原理和治理功能,用以构建数据资产的目录。对这个资产进行分类和管理,形成数据字典。 提供围绕数据资产的协作功能。 表和表之间的血缘依赖 字段和字段之间的血缘依赖 1.2架构图 导入和导出࿱…...

编程题练习@8-23
分享8月23日两道编程题: 1 开幕式排列 题目描述 导演在组织进行大运会开幕式的排练,其中一个环节是需要参演人员围成一个环形。 演出人员站成了一圈,出于美观度的考虑,导演不希望某一个演员身边的其他人比他低太多或者高太多。 现…...

static相关知识点详解
文章目录 一. 修饰成员变量二. 修饰成员方法三. 修饰代码块四. 修饰类 一. 修饰成员变量 static 修饰的成员变量,称为静态成员变量,该变量不属于某个具体的对象,是所有对象所共享的。 public class Student {private String name;private sta…...

Redisson 分布式锁
Redis是基础客户端库,可用于执行基本操作。 Redisson是基于Redis的Java客户端,提供高级功能如分布式锁、分布式集合和分布式对象。 Redisson提供更友好的API,支持异步和响应式编程,提供内置线程安全和失败重试机制。 实现步骤…...
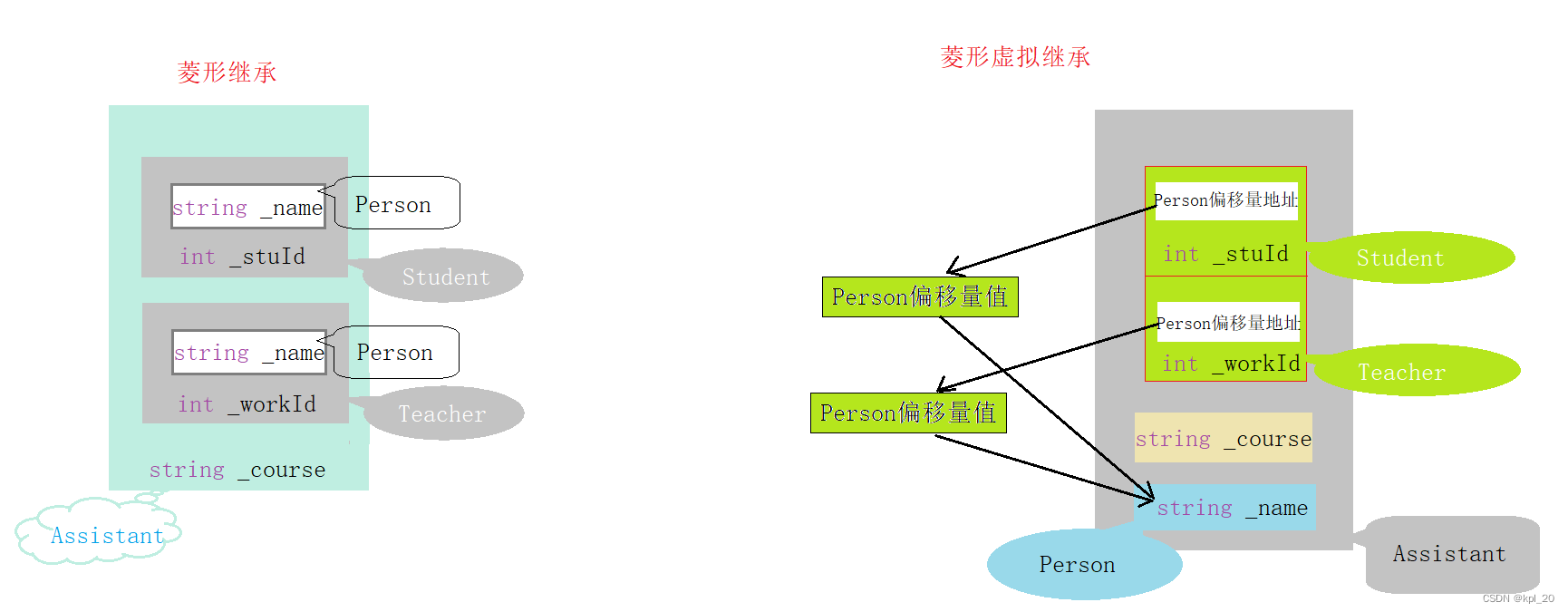
继承(C++)
继承 一、初识继承概念“登场”语法格式 继承方式九种继承方式组合小结(对九种组合解释) 二、继承的特性赋值转换 一一 切片 / 切割作用域 一一 隐藏 / 重定义 三、派生类的默认成员函数派生类的默认成员函数1. 构造函数2. 拷贝构造3. 赋值运算符重载4. …...

文心一言 VS 讯飞星火 VS chatgpt (80)-- 算法导论7.4 5题
五、如果用go语言,当输入数据已经“几乎有序”时,插入排序速度很快。在实际应用中,我们可以利用这一特点来提高快速排序的速度。当对一个长度小于 k 的子数组调用快速排序时,让它不做任何排序就返回。当上层的快速排序调用返回后&…...

SpringCloud 概述
文章目录 SpringCloud 概述一、微服务中的相关概念1、服务注册与发现2、负载均衡3、熔断4、链路追踪5、API网关 二、SpringCloud的介绍三、SpringCloud的架构1、SpringCloud中的核心组件(1)Spring Cloud Netflix组件(2)Spring Clo…...
Apache ShenYu 学习笔记一
1、简介 这是一个异步的,高性能的,跨语言的,响应式的 API 网关。 官网文档:Apache ShenYu 介绍 | Apache ShenYu仓库地址:GitHub - apache/shenyu: Apache ShenYu is a Java native API Gateway for service proxy, pr…...

uniapp 禁止遮罩层下的页面滚动
使用 touchmove.stop.prevent"toMoveHandle" 事件修饰符 若需要禁止蒙版下的页面滚动,可使用 touchmove.stop.prevent"moveHandle",moveHandle 可以用来处理 touchmove 的事件,也可以是一个空函数。将这个方法直接丢到弹…...

postgresql 分组
postgresql 数据汇总 分组汇总聚合函数注意 总结 分组统计总结 高级分组总结 分组汇总 聚合函数 聚合函数(aggregate function)针对一组数据行进行运算,并且返回单个结果。PostgreSQL 支持以下常见的聚合函数: • AVG - 计算一…...
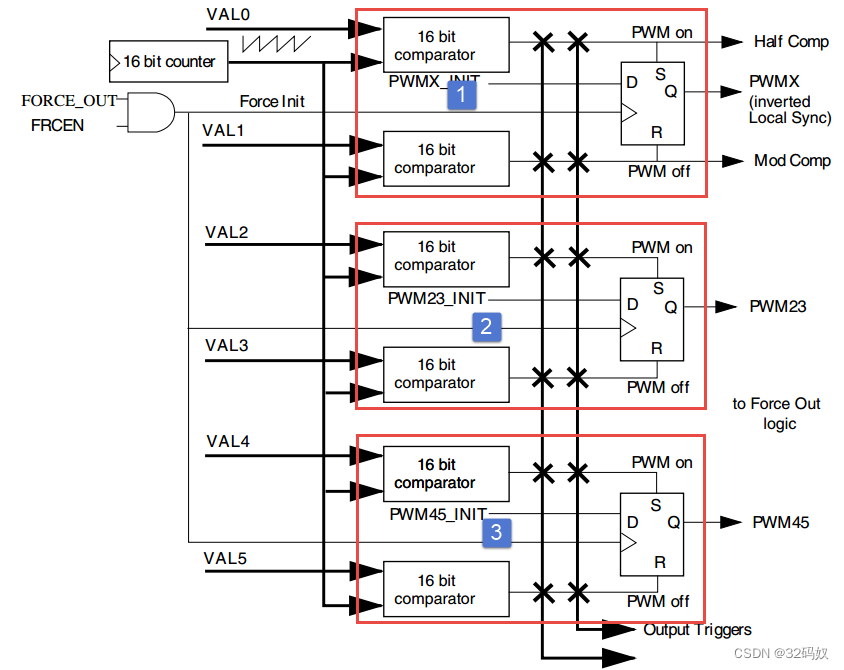
RT1052的EPWM
文章目录 1 EPWM介绍1.1 引脚1.2 时钟1.3 比较寄存器 2 函数 1 EPWM介绍 RT1052 具有 4 个 eFlexPWM(eFlexWM1~eFlex_PWM4)。 每个 eFlexPWM 可以产生四路互补 PWM即产生 8 个 PWM,也可以产生相互独立的 PWM 波。四路分别是模块0-3每个 eFlexPWM 具有各自的故障检…...
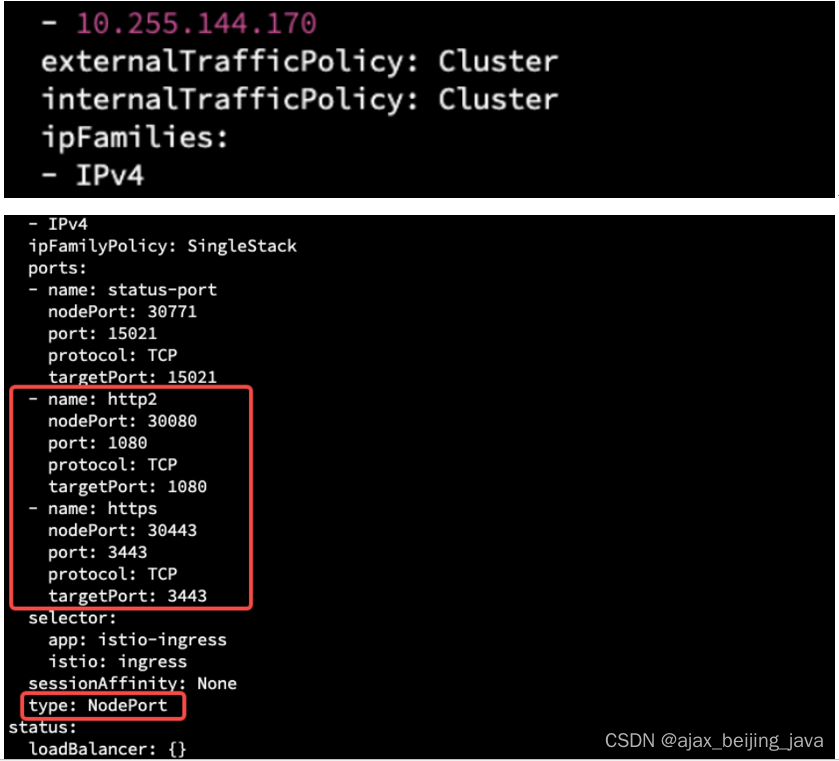
k8s 安装istio (一)
前置条件 已经完成 K8S安装过程十:Kubernetes CNI插件与CoreDNS服务部署 部署 istio 服务网格与 Ingress 服务用到了 helm 与 kubectl 这两个命令行工具,这个命令行工具依赖 ~/.kube/config 这个配置文件,目前只在 kubernetes master 节点中…...

vue 项目在编译时,总是出现系统崩的状态,报错信息中有v7 或者 v8 的样式-项目太大内存溢出
vue 项目在编译时,总是出现系统崩的状态,node 命令框也会报错,如下图:有v7 或者 v8 的样式。 原因分析: 分析:遇到与上面图片相似的问题,我们要首先要想到是否是 有关内存的问题,当然…...

低功耗蓝牙射频指纹识别
射频指纹 射频指纹是什么 射频指纹是一种利用无线电信号的特征来识别设备或用户的技术。射频指纹可以用来做设备身份认证、位置跟踪、安全防护等应用。射频指纹的优点是难以伪造、不依赖于额外的硬件或软件、适用于多种无线通信协议。 射频指纹识别流程 射频指纹识别的一般…...
怎么检测UI卡顿?(线上及线下)
什么是UI卡顿? 在Android系统中,我们知道UI线程负责我们所有视图的布局,渲染工作,UI在更新期间,如果UI线程的执行时间超过16ms,则会产生丢帧的现象,而大量的丢帧就会造成卡顿,影响用…...
Git 常用操作
一、Git 常用操作 1、切换分支 git checkout命令可以用于三种不同的实体:文件,commit,以及分支。checkout的意思就是对于一种实体的不同版本之间进行切换的操作。checkout一个分支,会更新当前的工作空间中的文件,使其…...

前端修改新增操作导致数据删除——js精度丢失
问题描述 笔者在写前端渲染表格的时候,发现无论是修改还是新增,数据都会被删除。检查了前端逻辑并与后端联调均无问题。 然后就开始和后端一起对数据库,结果发现,十几位的id,接收过来的时候,尾数均变为了…...

winform使用usercontrol 构建了一个复杂的列表,列表速度慢该如何优化?
当使用 WinForms 构建复杂的列表时,可能会面临性能问题,特别是在数据量大或 UI 复杂的情况下。以下是一些优化策略,可以帮助您改善列表的性能: 1. **虚拟模式 (Virtual Mode)**:对于大型数据集,考虑使用虚…...
Lnton羚通算法算力云平台如何在OpenCV-Python中使用cvui库创建复选框
CVUI 之 复选框 Python import numpy as np import cv2 import cvuidef checkbox_test():WINDOW_NAME Checkbox-Testchecked [False]# 创建画布frame np.zeros((300, 400, 3), np.uint8)# 初始化窗口cvui.init(WINDOW_NAME)while True:# 画布填色frame[:] (100, 200, 100…...

Atlas框架:机器学习全生命周期的安全审计与验证
1. Atlas框架:机器学习生命周期的安全守护者在机器学习(ML)模型日益渗透到金融、医疗等关键领域的今天,一个令人不安的事实逐渐浮出水面:从数据采集到模型部署的整个生命周期中,每个环节都可能成为攻击者的…...

NanoSVG完整教程:从SVG文件解析到贝塞尔曲线渲染
NanoSVG完整教程:从SVG文件解析到贝塞尔曲线渲染 【免费下载链接】nanosvg Simple stupid SVG parser 项目地址: https://gitcode.com/gh_mirrors/na/nanosvg NanoSVG是一款轻量级的SVG解析库,能够将SVG文件高效转换为贝塞尔曲线数据,…...

5 款实用漏洞扫描工具,网安从业者必备收藏
漏洞扫描是指基于漏洞数据库,通过扫描等手段对指定的远程或者本地计算机系统的安全脆弱性进行检测,发现可利用漏洞的一种安全检测的行为。 在漏洞扫描过程中,我们经常会借助一些漏扫工具,市面上漏扫工具众多,其中有一…...

VSCode写Verilog效率翻倍:除了语法检查,再教你用Python插件自动生成模块例化
VSCode写Verilog效率翻倍:Python插件自动化实战指南 在FPGA开发中,Verilog代码的重复性劳动往往消耗工程师大量时间。我曾在一个图像处理项目中被模块例化折磨得焦头烂额——手动编写30多个相同结构的FIFO例化代码,不仅容易出错,后…...

多重细胞因子检测及其技术综述
一、细胞因子概述细胞因子是一类由免疫细胞(如单核细胞、巨噬细胞、T细胞、B细胞及自然杀伤细胞等)及部分非免疫细胞(如内皮细胞、表皮细胞、成纤维细胞等)在相应刺激诱导下合成并分泌的小分子蛋白质,具有广泛的生物学…...

多品牌技高速存储卡术拆解分析实测:如何同时满足企业级监控与创作两不误?
一、开篇:当监控连续记录与影视创作相遇——存储卡的双重使命在企业级安防监控与专业影像创作的交汇点上,存储卡不再仅仅是数据的载体,而是工作流中不可绕过的风险控制节点。安防监控要求724小时不间断写入,对持续写入稳定性和数据…...

Yaskawa JACP-317800输入输出模块
安川JACP-317800是一款高性能逻辑输入输出模块,隶属于安川CP-317系列PLC系统,专为工业自动化领域的数字信号采集与控制而设计。产品特点:产品类型为逻辑输入输出模块,作为PLC与现场设备之间的信号接口模块重量仅0.3公斤࿰…...

“找档难、找档慢”困扰工作?档案宝智能检索功能,让档案查询秒响应
目录 档案之痛:效率与风险并存 破局之道:智能检索成关键 写在最后 在日常办公中,你是否遇到过这样的场景:需要调取一份重要合同档案,翻遍整个文件柜却找不到;领导紧急要一份历史数据,手动搜索了…...

Go语言安全编码实践:常见漏洞与防护
Go语言安全编码实践:常见漏洞与防护 1. 安全编码原则 安全编码是防止漏洞的根本,包括输入验证、输出编码、最小权限等原则。 2. 安全工具 package securityimport ("regexp""strings" )type Validator struct {emailRegex *regexp.R…...

观察taotoken在ubuntu高峰期调用时的稳定性与自动路由效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 在 Ubuntu 高峰期调用时的稳定性与自动路由效果 1. 背景与测试环境 在日常的开发与调试工作中,我们经常…...