Hadoop学习:深入解析MapReduce的大数据魔力之数据压缩(四)
Hadoop学习:深入解析MapReduce的大数据魔力之数据压缩(四)
- 4.1 概述
- 1)压缩的好处和坏处
- 2)压缩原则
- 4.2 MR 支持的压缩编码
- 4.3 压缩方式选择
- 4.3.1 Gzip 压缩
- 4.3.2 Bzip2 压缩
- 4.3.3 Lzo 压缩
- 4.3.4 Snappy 压缩
- 4.3.5 压缩位置选择
- 4.4 压缩参数配置
- 4.5 压缩实操案例
- 4.5.1 Map输出端采用压缩
- 4.5.2 Reduce输出端采用压缩
- 常见错误及解决方案
4.1 概述
1)压缩的好处和坏处
压缩的优点:以减少磁盘IO、减少磁盘存储空间。
压缩的缺点:增加CPU开销。
2)压缩原则
(1)运算密集型的Job,少用压缩
(2)IO密集型的Job,多用压缩
4.2 MR 支持的压缩编码
1)压缩算法对比介绍


2)压缩性能的比较

4.3 压缩方式选择
压缩方式选择时重点考虑:压缩/解压缩速度、压缩率(压缩后存储大小)、压缩后是否
可以支持切片。
4.3.1 Gzip 压缩
优点:压缩率比较高;
缺点:不支持Split;压缩/解压速度一般;
4.3.2 Bzip2 压缩
优点:压缩率高;支持Split;
缺点:压缩/解压速度慢。
4.3.3 Lzo 压缩
优点:压缩/解压速度比较快;支持Split;
缺点:压缩率一般;想支持切片需要额外创建索引。
4.3.4 Snappy 压缩
优点:压缩和解压缩速度快;
缺点:不支持Split;压缩率一般;
4.3.5 压缩位置选择
压缩可以在MapReduce作用的任意阶段启用。

4.4 压缩参数配置
1)为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器

2)要在Hadoop中启用压缩,可以配置如下参数


4.5 压缩实操案例
4.5.1 Map输出端采用压缩
即使你的MapReduce的输入输出文件都是未压缩的文件,你仍然可以对Map任务的中
间结果输出做压缩,因为它要写在硬盘并且通过网络传输到Reduce节点,对其压缩可以提
高很多性能,这些工作只要设置两个属性即可,我们来看下代码怎么设置。
1)给大家提供的Hadoop源码支持的压缩格式有:==BZip2Codec、DefaultCodec ==
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountDriver { public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); // 开启map端输出压缩 conf.setBoolean("mapreduce.map.output.compress", true); // 设置map端输出压缩方式 conf.setClass("mapreduce.map.output.compress.codec",
BZip2Codec.class,CompressionCodec.class);Job job = Job.getInstance(conf); job.setJarByClass(WordCountDriver.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); }
}
2)Mapper保持不变
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text,
IntWritable>{ Text k = new Text(); IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context
context)throws IOException, InterruptedException { // 1 获取一行 String line = value.toString(); // 2 切割 String[] words = line.split(" "); // 3 循环写出 for(String word:words){ k.set(word); context.write(k, v); } }
}
3)Reducer保持不变
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text, IntWritable, Text,
IntWritable>{ IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; // 1 汇总 for(IntWritable value:values){ sum += value.get(); } v.set(sum); // 2 输出 context.write(key, v); }
}
4.5.2 Reduce输出端采用压缩
基于WordCount案例处理。
1)修改驱动
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.io.compress.Lz4Codec;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountDriver { public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(WordCountDriver.class); job.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置reduce端输出压缩开启
FileOutputFormat.setCompressOutput(job, true);
// 设置压缩的方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
//
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
//
FileOutputFormat.setOutputCompressorClass(job,
DefaultCodec.class);
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
2)Mapper和Reducer保持不变(详见4.5.1)
常见错误及解决方案
1)导包容易出错。尤其Text和CombineTextInputFormat。
2)Mapper 中第一个输入的参数必须是LongWritable或者NullWritable,不可以是IntWritable. 报的错误是类型转换异常。
3)java.lang.Exception: java.io.IOException: Illegal partition for 13926435656 (4),说明 Partition
和ReduceTask 个数没对上,调整ReduceTask个数。
4)如果分区数不是1,但是reducetask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1 肯定不执行。
5)在Windows环境编译的jar包导入到Linux环境中运行,
hadoop
jar
wc.jar
/user/atguigu/output
报如下错误:
Exception
in
com.atguigu.mapreduce.wordcount.WordCountDriver
thread
“main”
/user/atguigu/
java.lang.UnsupportedClassVersionError:
com/atguigu/mapreduce/wordcount/WordCountDriver : Unsupported major.minor version 52.0
原因是Windows环境用的jdk1.7,Linux环境用的jdk1.8。
解决方案:统一jdk版本。
6)缓存pd.txt小文件案例中,报找不到pd.txt文件
原因:大部分为路径书写错误。还有就是要检查pd.txt.txt的问题。还有个别电脑写相对路径
找不到pd.txt,可以修改为绝对路径。
7)报类型转换异常。
通常都是在驱动函数中设置Map输出和最终输出时编写错误。
Map 输出的key如果没有排序,也会报类型转换异常。
8)集群中运行wc.jar时出现了无法获得输入文件。
原因:WordCount案例的输入文件不能放用HDFS集群的根目录。
9)出现了如下相关异常
Exception
in
thread
“main”
java.lang.UnsatisfiedLinkError:
org.apache.hadoop.io.nativeio.NativeIO W i n d o w s . a c c e s s 0 ( L j a v a / l a n g / S t r i n g ; I ) Z a t o r g . a p a c h e . h a d o o p . i o . n a t i v e i o . N a t i v e I O Windows.access0(Ljava/lang/String;I)Z at org.apache.hadoop.io.nativeio.NativeIO Windows.access0(Ljava/lang/String;I)Zatorg.apache.hadoop.io.nativeio.NativeIOWindows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:609)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977)
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:356)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:371)
at org.apache.hadoop.util.Shell.(Shell.java:364)
解决方案:拷贝hadoop.dll文件到Windows目录C:\Windows\System32。个别同学电脑
还需要修改Hadoop源码。
方案二:创建如下包名,并将NativeIO.java拷贝到该包名下

10)自定义Outputformat 时,注意在RecordWirter 中的 close 方法必须关闭流资源。否则输出的文件内容中数据为空。
@Override
public
void
close(TaskAttemptContext context) throws IOException,
InterruptedException {
if (atguigufos != null) {
atguigufos.close();
}
if (otherfos != null) {
otherfos.close();
}
}
相关文章:
Hadoop学习:深入解析MapReduce的大数据魔力之数据压缩(四)
Hadoop学习:深入解析MapReduce的大数据魔力之数据压缩(四) 4.1 概述1)压缩的好处和坏处2)压缩原则 4.2 MR 支持的压缩编码4.3 压缩方式选择4.3.1 Gzip 压缩4.3.2 Bzip2 压缩4.3.3 Lzo 压缩4.3.4 Snappy 压缩4.3.5 压缩…...
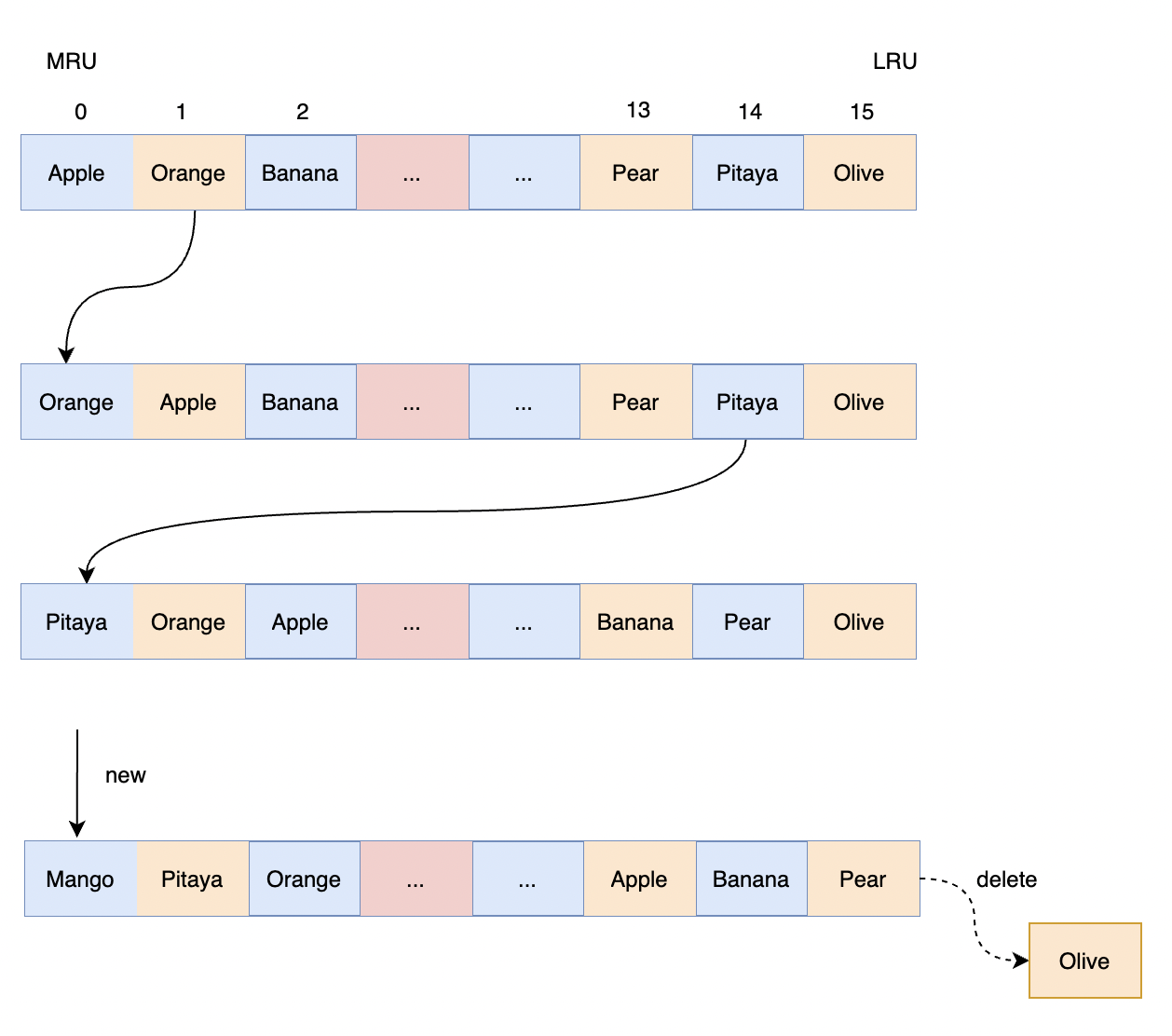
LRU淘汰策略执行过程
1 介绍 Redis无论是惰性删除还是定期删除,都可能存在删除不尽的情况,无法删除完全,比如每次删除完过期的 key 还是超过 25%,且这些 key 再也不会被客户端访问。 这样的话,定期删除和堕性删除可能都彻底的清理掉。如果…...

Kotlin 高阶函数详解
高阶函数 在 Kotlin 中,函数是一等公民,高阶函数是 Kotlin 的一大难点,如果高阶函数不懂的话,那么要学习 Kotlin 中的协程、阅读 Kotlin 的源码是非常难的,因为源码中有太多高阶函数了。 高阶函数的定义 高阶函数的…...

DL——week2
要学明白的知识点: np.dot()的作用 两个数组的点积,即对应元素相乘 numpy.dot(a,b,outNone) a: ndarray 数组 b: ndarray 数组 out: ndarray, 可选,用来保存dot()的计算结果 numpy Ndarray对象 N维数组对象ndarray&am…...

如何撰写骨灰级博士论文?这是史上最全博士论文指导!
博士论文的写作是博士研究生主要要完成的工作。由于存在着较高的难度,较长的写作周期,以及在创新,写作规范,实际及理论意义等方面有着比较高的要求,博士论文的完成一般说来是有相当难度的。一篇好的博士论文不仅是一本…...

08.SpringBoot请求相应
文章目录 1 请求1.1 Postman1.2 简单参数1.2.1 原始方式1.2.2 SpringBoot方式1.2.3 参数名不一致 1.3 实体参数1.3.1 简单实体对象1.3.2 复杂实体对象 1.4 数组集合参数1.4.1 数组1.4.2 集合 1.5 日期参数1.6 JSON参数1.7 路径参数 2 响应2.1 ResponseBody注解2.2 统一响应结果…...

C#详解-Contains、StartsWith、EndsWith、Indexof、lastdexof
目录 简介: 过程: 举例1.1 举例1.2 总结: 简介: 在C#中Contains、StarsWith和EndWith、IndexOf都是字符串函数。 1.Contains函数用于判断一个字符串是否包含指定的子字符串,返回一个布尔值(True或False)。 2.StartsWith函数用于判断一…...

FATE框架中pipline基础教程
目录 1. 用pipline上传数据2. 用 Pipeline 进行 Hetero SecureBoost 的训练和预测3. 用 Pipeline 构建神经网络模型3.1 Homo-NN Quick Start: A Binary Classification Task3.2 Hetero-NN Quick Start: A Binary Classification Task 4. 自定义数据集示例:实现一个简…...
Atlas 元数据管理
Atlas 元数据管理 1.Atlas入门 1.1概述 元数据原理和治理功能,用以构建数据资产的目录。对这个资产进行分类和管理,形成数据字典。 提供围绕数据资产的协作功能。 表和表之间的血缘依赖 字段和字段之间的血缘依赖 1.2架构图 导入和导出࿱…...

编程题练习@8-23
分享8月23日两道编程题: 1 开幕式排列 题目描述 导演在组织进行大运会开幕式的排练,其中一个环节是需要参演人员围成一个环形。 演出人员站成了一圈,出于美观度的考虑,导演不希望某一个演员身边的其他人比他低太多或者高太多。 现…...

static相关知识点详解
文章目录 一. 修饰成员变量二. 修饰成员方法三. 修饰代码块四. 修饰类 一. 修饰成员变量 static 修饰的成员变量,称为静态成员变量,该变量不属于某个具体的对象,是所有对象所共享的。 public class Student {private String name;private sta…...

Redisson 分布式锁
Redis是基础客户端库,可用于执行基本操作。 Redisson是基于Redis的Java客户端,提供高级功能如分布式锁、分布式集合和分布式对象。 Redisson提供更友好的API,支持异步和响应式编程,提供内置线程安全和失败重试机制。 实现步骤…...
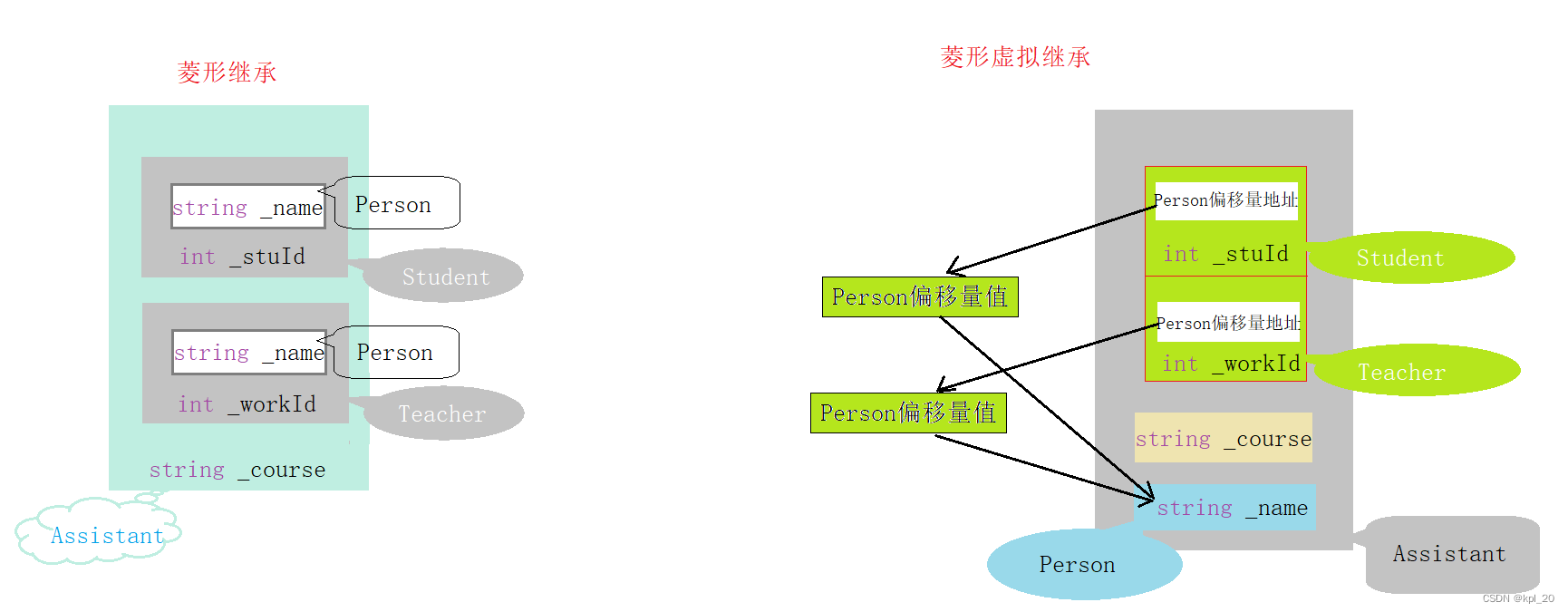
继承(C++)
继承 一、初识继承概念“登场”语法格式 继承方式九种继承方式组合小结(对九种组合解释) 二、继承的特性赋值转换 一一 切片 / 切割作用域 一一 隐藏 / 重定义 三、派生类的默认成员函数派生类的默认成员函数1. 构造函数2. 拷贝构造3. 赋值运算符重载4. …...

文心一言 VS 讯飞星火 VS chatgpt (80)-- 算法导论7.4 5题
五、如果用go语言,当输入数据已经“几乎有序”时,插入排序速度很快。在实际应用中,我们可以利用这一特点来提高快速排序的速度。当对一个长度小于 k 的子数组调用快速排序时,让它不做任何排序就返回。当上层的快速排序调用返回后&…...

SpringCloud 概述
文章目录 SpringCloud 概述一、微服务中的相关概念1、服务注册与发现2、负载均衡3、熔断4、链路追踪5、API网关 二、SpringCloud的介绍三、SpringCloud的架构1、SpringCloud中的核心组件(1)Spring Cloud Netflix组件(2)Spring Clo…...
Apache ShenYu 学习笔记一
1、简介 这是一个异步的,高性能的,跨语言的,响应式的 API 网关。 官网文档:Apache ShenYu 介绍 | Apache ShenYu仓库地址:GitHub - apache/shenyu: Apache ShenYu is a Java native API Gateway for service proxy, pr…...

uniapp 禁止遮罩层下的页面滚动
使用 touchmove.stop.prevent"toMoveHandle" 事件修饰符 若需要禁止蒙版下的页面滚动,可使用 touchmove.stop.prevent"moveHandle",moveHandle 可以用来处理 touchmove 的事件,也可以是一个空函数。将这个方法直接丢到弹…...

postgresql 分组
postgresql 数据汇总 分组汇总聚合函数注意 总结 分组统计总结 高级分组总结 分组汇总 聚合函数 聚合函数(aggregate function)针对一组数据行进行运算,并且返回单个结果。PostgreSQL 支持以下常见的聚合函数: • AVG - 计算一…...
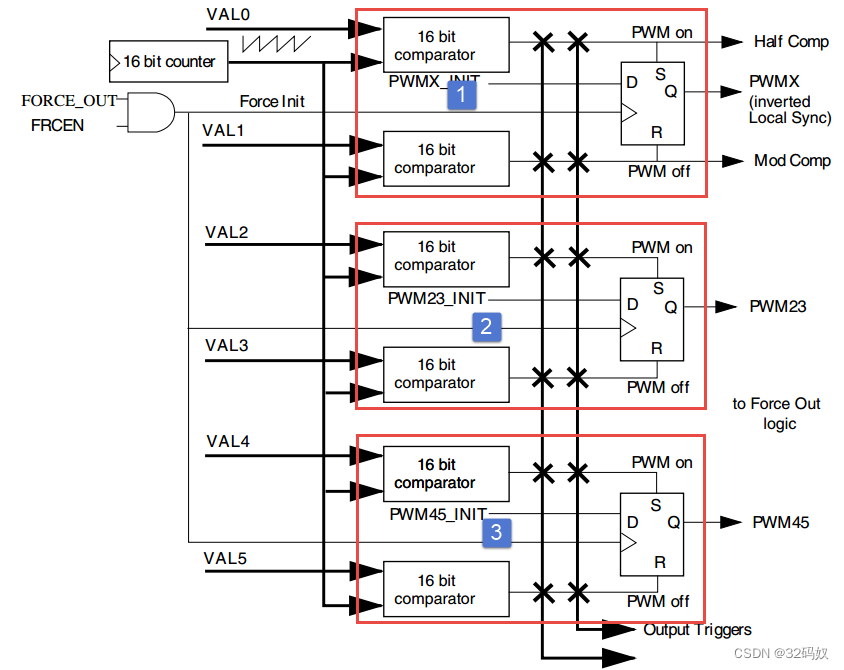
RT1052的EPWM
文章目录 1 EPWM介绍1.1 引脚1.2 时钟1.3 比较寄存器 2 函数 1 EPWM介绍 RT1052 具有 4 个 eFlexPWM(eFlexWM1~eFlex_PWM4)。 每个 eFlexPWM 可以产生四路互补 PWM即产生 8 个 PWM,也可以产生相互独立的 PWM 波。四路分别是模块0-3每个 eFlexPWM 具有各自的故障检…...
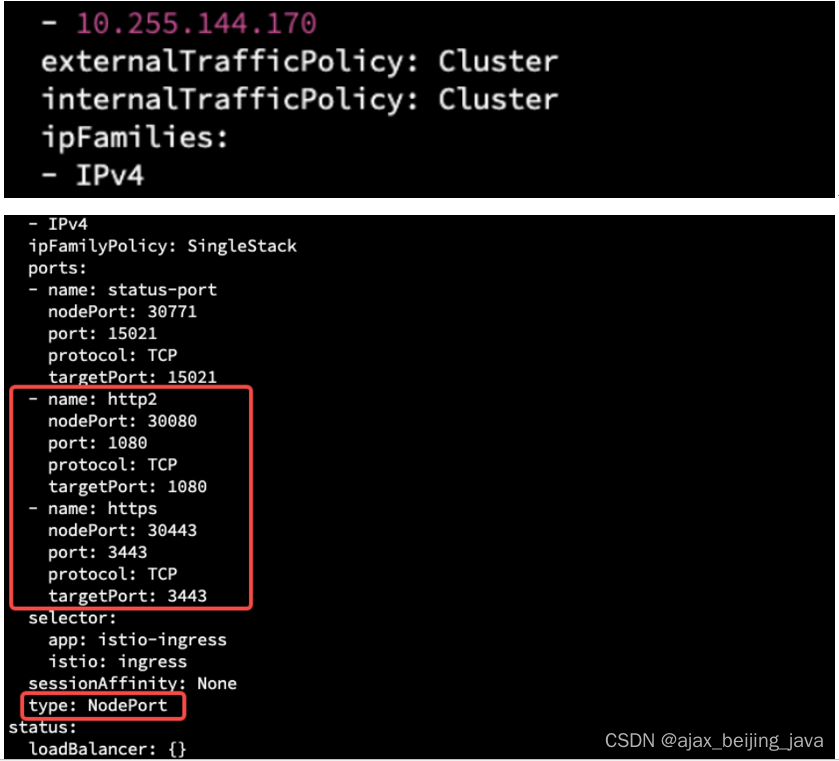
k8s 安装istio (一)
前置条件 已经完成 K8S安装过程十:Kubernetes CNI插件与CoreDNS服务部署 部署 istio 服务网格与 Ingress 服务用到了 helm 与 kubectl 这两个命令行工具,这个命令行工具依赖 ~/.kube/config 这个配置文件,目前只在 kubernetes master 节点中…...

Agent-Layer:构建多智能体协作系统的中间层框架设计与实践
1. 项目概述:Agent-Layer 是什么,以及它想解决什么问题最近在开源社区里,一个名为lopushok9/Agent-Layer的项目引起了我的注意。乍一看这个标题,你可能会想,这又是一个关于“智能体”或“代理”的框架吧?确…...

SpringBoot快速入门指南
Spring Boot 是一个基于 Spring 框架的“约定优于配置”的快速应用开发框架,旨在简化基于 Spring 的应用初始搭建和开发过程。它通过自动配置、起步依赖和嵌入式容器等特性,使开发者能够快速创建独立的、生产级别的 Spring 应用程序。 一、 核心特性与快…...

终极邮件营销自动化指南:工程师如何快速搭建高效邮件营销系统
终极邮件营销自动化指南:工程师如何快速搭建高效邮件营销系统 【免费下载链接】Marketing-for-Engineers A curated collection of marketing articles & tools to grow your product. 项目地址: https://gitcode.com/gh_mirrors/ma/Marketing-for-Engineers…...

AI 驱动单元测试生成:智能优先级与自动化验证实践
1. 项目概述如果你和我一样,长期在维护一个中大型的 TypeScript 项目,那么“补单元测试”这件事,大概率是你技术债清单上那个永远在滚动、却很少被真正划掉的任务。手动写测试枯燥耗时,尤其是面对那些遗留的、逻辑复杂的业务函数时…...

全网珍藏网安学习网站大全,一次性整理齐全,错过容易被删速收藏!
我们学习网络安全,很多学习路线都有提到多逛论坛,阅读他人的技术分析帖,学习其挖洞思路和技巧。但是往往对于初学者来说,不知道去哪里寻找技术分析帖,也不知道网络安全有哪些相关论坛或网站,所以在这里给大…...

混合人工智能架构可以将神经形态系统转变为可靠的发现机器。
基于ON-OFF神经元的高阶伊辛机架构。图片来源:Nature Communications (2026)。DOI:10.1038/s41467-026-71937-4来源:https://techxplore.com/news/2026-05-hybrid-ai-architecture-neuromorphic-reliable.html主导世界的AI机器可以分为三大类…...

【Kanzi 资源系统完全笔记】
一、Resource 的类层次结构Kanzi 中所有资源(Resource)都继承自 Object 基类。下图是常见的资源继承体系(根据图片整理):Object└── Resource├── GPUResource # 位于 GPU 显存中的资源(纹理、…...

工业HMI系统核心技术解析与TI解决方案实践
1. 工业HMI系统概述人机界面(HMI)系统是现代工业自动化不可或缺的核心组件,它如同工厂的"神经中枢",将复杂的机器语言转化为直观的可视化信息。想象一下,当操作员站在一台大型工业设备前,不再需要…...

高速SerDes设计中BER预测的智能应力输入方法
1. 高速串行链路设计中的BER预测挑战在当今高速数字系统设计中,SerDes(串行器/解串器)技术已成为主流接口方案,数据传输速率已突破10Gbps大关。随着速率提升,信号完整性(SI)问题日益突出,其中误码率(BER)预…...

Cortex-R52内存管理与实时性优化技术解析
1. Cortex-R52内存管理架构解析Cortex-R52作为Armv8-R架构的旗舰级实时处理器,其内存管理系统针对高可靠性场景进行了深度优化。与传统MMU不同,R52采用了增强型MPU(Memory Protection Unit)设计,通过16-24个可编程保护…...