python爬虫10:selenium库
python爬虫10:selenium库
前言
python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。
申明
本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好影响。
目录结构
文章目录
- python爬虫10:selenium库
- 1. 概述与安装
- 1.1 概述
- 1.2 安装
- 2. 基本使用
- 2.1 声明浏览器对象
- 2.2 访问页面
- 2.3 关闭访问页面和浏览器:
- 2.4 查找节点方法:
- 2.5 节点交互:
- 2.6 动作链:
- 2.7 获取网页信息和节点信息:
- 2.8 执行js代码:
- 2.9 切换Frame:
- 2.10 延时等待:
- 2.11 切换窗口
- 3. 总结
1. 概述与安装
1.1 概述
selenium其实严格来说并不属于爬虫库,而是用于测试的库,不过这里我们就拿来当作爬虫库来用就行。
selenium相比于其他的爬虫库而言,更加综合,其既可以请求,也可以解析,并且过程是可视化的,即请求的时候,你可以看见程序打开浏览器,然后按照你设定的步骤进行。
1.2 安装
selenium的安装以前比较麻烦,需要自己去安装浏览器驱动,但是现在最新版本的selenium已经不需要我们自己装驱动了,当你运行代码的时候,会自动检测安装。
因此,只需要安装:
pip install selenium
可以用下面代码测试浏览器驱动是否安装(谷歌浏览器):
# 导包
from selenium import webdriver# 浏览器初始化
driver = webdriver.Chrome()
# 打开百度
driver.get('https://www.baidu.com')
# 打印源码
print(driver.page_source)
# 关闭
driver.quit()
其运行过程就是自动打开浏览器并打开百度搜索页面,然后返回源码。
2. 基本使用
2.1 声明浏览器对象
使用selenium,首先需要声明浏览器对象,除去我之前使用的chrome浏览器,还支持:Firefox、Edge等等,但是一般常用的是chrome浏览器,所以这里我只给出chrome浏览器的声明方法,其他的声明方法都类似,只需要修改浏览器名称即可。
# 导包
from selenium import webdriver# 声明浏览器对象
driver = webdriver.Chrome()
2.2 访问页面
这里不分什么get或者post,统一的只有get方法。语法如下:
driver.get(url)
# 示例:
driver.get('https://www.baidu.com')
2.3 关闭访问页面和浏览器:
# 关闭访问页面和浏览器
driver.close()
# 关闭驱动
driver.quit()
2.4 查找节点方法:
查找单个节点:
作用:只返回第一个匹配的节点。
方法如下:driver.find_element()
常用参数:
1. by需要导入from selenium.webdriver.common.by import By指定获取元素的方式,常见的如:By.NAME(标签name属性获取)、By.ID(标签id属性获取)、By.CLASS_NAME(标签class属性获取)、By.TAG_NAME(标签名字获取)、By.XPATH(通过xpath语法获取)、By.CSS_SELECTOR(通过css选择器获取)......2. value配合上面的by参数,填写相应的值即可
查找多个节点
方法名只是多了一个s,变为了driver.find_elements(),参数都是一样的。
2.5 节点交互:
常用的节点交互有两种:输入与点击,这也是我们在浏览器中最常用的两种了。方法分别如下:
# 输入内容
xxx.send_keys('内容')# xxx代表着一个节点
xxx.clear() #清除输入的内容
# 点击
xxx.click()
下面给大家一个案例: 打开百度,输入python并且点击搜索按钮进行搜索,之后再删除python,搜索java
# 导包
import time
from selenium import webdriver
from selenium.webdriver.common.by import By# 浏览器声明
driver = webdriver.Chrome()
# 打开百度
driver.get('https://www.baidu.com')
# 获取输入框节点
input_tag = driver.find_element(by=By.CLASS_NAME,value='s_ipt')
# 获取搜索按钮
search_tag = driver.find_element(by=By.XPATH,value='//input[@id="su"]')
# 输入python
input_tag.send_keys('python')
# 点击按钮
search_tag.click()
# 暂停2秒
time.sleep(2)
# 清楚python
input_tag.clear()
# 输入java
input_tag.send_keys('java')
# 搜索
search_tag.click()
# 暂停2秒
time.sleep(2)
# 退出
driver.close()
driver.quit()
运行结果如下动图所示:

2.6 动作链:
有些动作,如:拖拽、键盘按键等,没有具体的某个节点,这种方式就需要动作链来执行,你可以这样理解:你首先声明一个动作链对象,然后这个对象将一条一条的执行你写的代码。
这个方面需要大家自行查找官方文档,因为这个我日常用的不多,对于自己来说,也许只有破解验证码的时候才用得上,但是现在的验证码破解越来越难了,所以我基本上用不到这块。
2.7 获取网页信息和节点信息:
网页信息
网页源码:
方法: driver.page_source
作用:获取网页源码
网页标题:
方法:driver.title
作用:获取网页标题
节点信息:下面的xxx指的是的某个节点标签
获取属性:
方法: xxx.get_attribute('属性名字')
作用: 获取属性值
说明: xxx代表着节点
获取文本:
方法: xxx.text
作用: 获取文本值
获取其他信息:
获取id:
xxx.id
获取节点名称:
xxx.tag_name
获取节点在页面中的位置:
xxx.location (这个还是很有用的,对于滑动验证的验证码可以使用)
获取节点大小(宽和高):
xxx.size
2.8 执行js代码:
之前的功能,如:输入内容,点击按钮等,其他库可以使用其他方式实现,但是执行js代码确实selenium一个强大的功能。
比如:我们有时候爬取动态渲染的网页,如:百度图片,我们鼠标向下滑动,越来越多的图片加载出来,这就是动态渲染,或者我们有时候看见的“更多”(有些内容显示不全,点更多可以在当前页面查看全部内容)都是动态渲染,我们可以使用js代码模拟实现。
这个方面考察大家的js功底,如果不会的朋友也不用紧张,如果你需要啥功能可以在网上搜索,将网页的js代码拷贝下来即可。
语法如下:
driver.execute_script('js代码')
代码演示;(效果:直接滑动到网页底部)
from selenium import webdriver
from selenium.webdriver.common.by import By
import time# 浏览器声明
driver = webdriver.Chrome()
# 打开一个网页
driver.get('https://tieba.baidu.com/f?kw=%B6%B7%CD%BC&fr=ala0&tpl=5')
# 执行js代码
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(5)
# 关闭
driver.close()
driver.quit()
结果演示:
2.9 切换Frame:
网页标签中有一个标签叫做frame标签,相当于一个子网页,而使用selenium打开网页默认在父级frame里面,因此想要获取子frame中的内容需要切换frame,方法如下:
driver.switch_to.frame(frame_reference=id或者name)
2.10 延时等待:
selenium打开网页,有时候需要注意网速是否良好,因为有时候你没有获取想要获取的信息就是因为网速不好。
除去使用time模块中的等待外,我们还可以使用selenium自带的延时等待。
隐式等待:
当查找的节点没有第一时间出现时,会等待指定时间后再来获取。
方法如下:
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
# 浏览器声明
driver = webdriver.Chrome()
# 延时等待
driver.implicitly_wait(10) # 如果没有找到元素,等待10秒中
# 找元素
driver.find_element(by=By.TAG_NAME,value='div')
显示等待::
隐式等待效果并不好,因为如果在等待过程中加载出来了我们需要的标签,但是我们仍然得等待一定的时间。因此,我们需要更好的等待方式----显示等待。
作用:它指定最长等待时间,如果在这个时间内加载出来了节点,则直接获取节点,或则抛出超时异常。
方法如下:
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 浏览器声明
driver = webdriver.Chrome()
# 显示等待
# 创建等待对象
wait = WebDriverWait(driver,10) #第二个参数是最大等待时间
tag = wait.until(EC.presence_of_element_located((By.ID,'q'))) # 这个作用:直到获取到id为q的节点
EC除去presence_of_element_located外,还有很多条件,具体的可以见官方库,但是使用方法都是这样。
2.11 切换窗口
有时候,我们用selenium请求了第一个网页后,又再次请求一个新的网页(或者你在第一个网页点击了某个按钮跳转到新网页),此时selenium权柄还停留在第一个网页,而我们想要获取第二个网页的信息,就需要切换权柄。
方法如下:
driver.window_handles # 查看所有的窗口权柄,返回一个列表,按照先后顺序出值
driver.current_window_handle # 当前的窗口权柄,和上面的可以对应看
driver.switch_to.window(xxx) # 切换窗口权柄,里面的xxx可以这么写 driver.window_handles[x](其中x为索引),具体的代码演示可以看下一篇的案例
3. 总结
本篇讲解了selenium的基础操作,由于selenium并不单单可以用于爬虫,还可以用于测试这个工作,因此其内容还有很多我们并没有涉及,这一点就需要靠大家根据自己的实际需求进行学习了。
下一篇进行实战讲解。
相关文章:
python爬虫10:selenium库
python爬虫10:selenium库 前言 python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。 申明 本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产…...

c++ java rgb与nv21互转
目录 jni函数 c++ rgb转nv21,可以转,不报错,但是转完只有黑白图 java yuv420保存图片,先转nv21,再保存ok: c++ yuv420月bgr互转,测试ok jni函数 JNIEXPORT void JNICALL Java_com_tencent_blazefacencnn_BlazeFaceNcnn_encode(JNIEnv *env,jobject thiz, jobject in…...
简介)
多视图聚类(multi-view clustering)简介
多视图聚类 目前大概有以下几种: 多视图k-means聚类多视图谱聚类多视图图聚类多视图子空间聚类 (multi-view subspace clustering)深度学习多视图聚类 (deep multi-view clustering) 其中多视图子空间聚类具有不错的数据表征能力。 对于多视图子空间聚类而言&…...

wazhu配置以及漏洞复现
目录 1.wazhu配置 进入官网下载 部署wazhu 修改网络适配器 重启 本地开启apache wazhu案例复现 前端页面 执行 1.wazhu配置 进入官网下载 Virtual Machine (OVA) - Installation alternatives (wazuh.com) 部署wazhu 修改网络适配器 重启 service network restart 本地…...

javaweb项目部署linux服务器遇到的问题
其他有关本次部署内容请参考本站其他文章 javaweb项目要用war包 IntelliJ IDEA 可以打包out里的子目录 D:\D盘文件\浏览器\webshop\out\artifacts\webshop_war_exploded>jar cvf webshop.war * 方法来源视频 18、web项目的打包与发布_哔哩哔哩_bilibili myeclipse项目…...
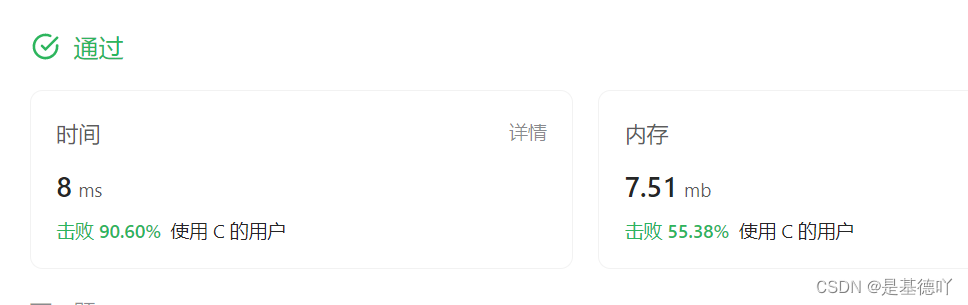
【数据结构OJ题】环形链表
原题链接:https://leetcode.cn/problems/linked-list-cycle/description/ 目录 1. 题目描述 2. 思路分析 3. 代码实现 1. 题目描述 2. 思路分析 整体思路:定义快慢指针fast,slow,如果链表确实有环,fast指针一定会…...
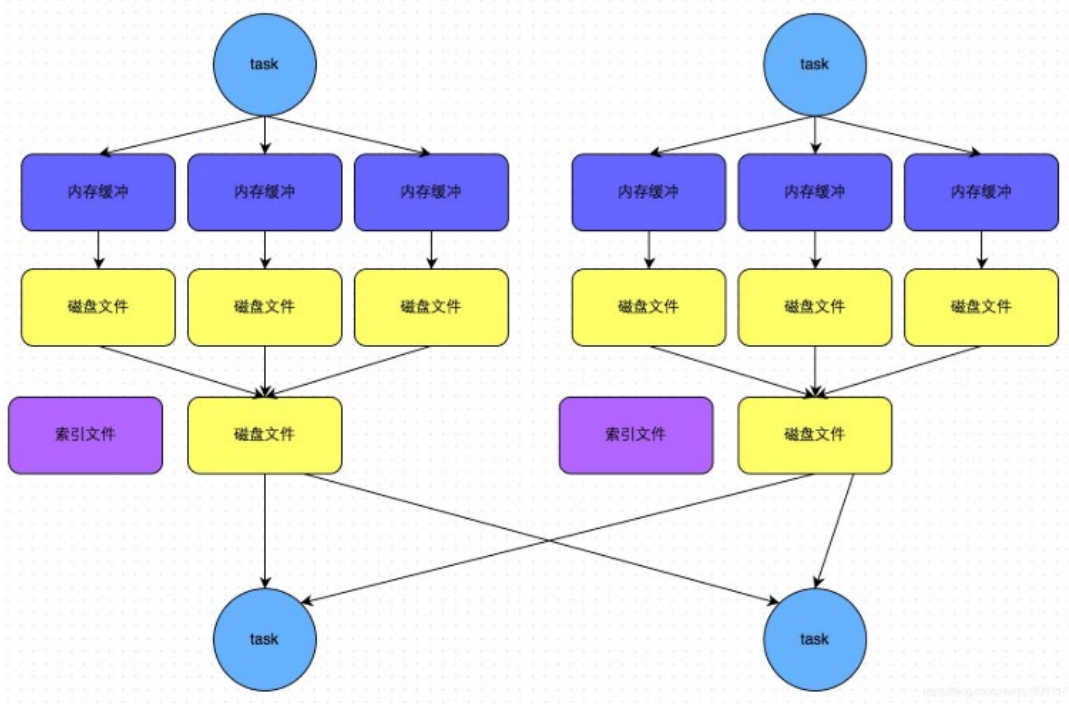
PySpark-核心编程
2. PySpark——RDD编程入门 文章目录 2. PySpark——RDD编程入门2.1 程序执行入口SparkContext对象2.2 RDD的创建2.2.1 并行化创建2.2.2 获取RDD分区数2.2.3 读取文件创建 2.3 RDD算子2.4 常用Transformation算子2.4.1 map算子2.4.2 flatMap算子2.4.3 reduceByKey算子2.4.4 Wor…...

vue 在IOS移动端中 windon.open 等跳转外部链接后,返回不触发vue生命周期、mounted等相关事件-解决方法
做了一个列表的h5页面,通过点击列表跳转到外部链接,然后返回是回到原来页面状态,类似缓存。发现在ios端返回后,vue 的mounted() 、create()、路由监听等方法都不会执行。在安卓和pc 端都能正常调用。 解决方案:监听pa…...
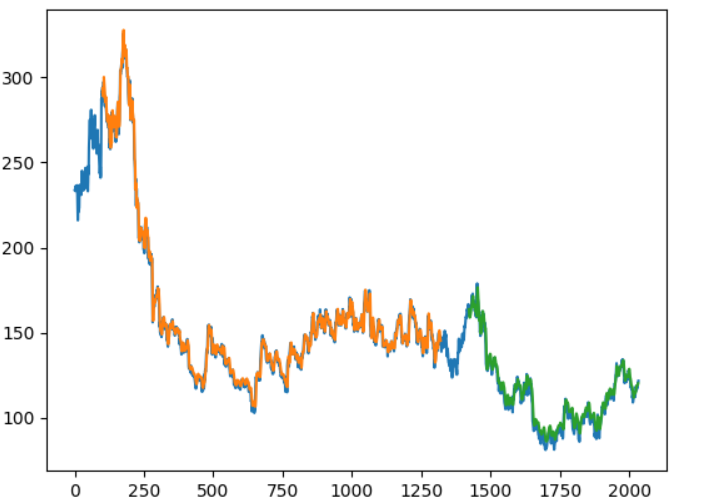
股票预测和使用LSTM(长期-短期-记忆)的预测
一、说明 准确预测股市走势长期以来一直是投资者和交易员难以实现的目标。虽然多年来出现了无数的策略和模型,但有一种方法最近因其能够捕获历史数据中的复杂模式和依赖关系而获得了显着的关注:长短期记忆(LSTM)。利用深度学习的力…...
Docker搭建个人网盘、私有仓库
1、使用mysql:5.6和 owncloud 镜像,构建一个个人网盘 [rootlocalhost ~]# docker pull mysql:5.6 [rootlocalhost ~]# docker pull owncloud [rootlocalhost ~]# docker run -itd --name mysql --env MYSQL_ROOT_PASSWORD123456 mysql:5.6 [rootlocalhost ~]# doc…...
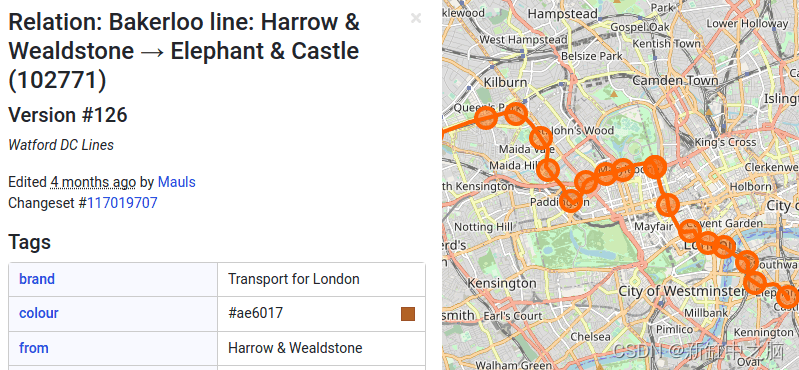
3种获取OpenStreetMap数据的方法【OSM】
OpenStreetMap 是每个人都可以编辑的世界地图。 这意味着你可以纠正错误、添加新地点,甚至自己为地图做出贡献! 这是一个社区驱动的项目,拥有数百万注册用户。 这是一个社区驱动的项目,旨在在开放许可下向每个人提供所有地理数据。…...
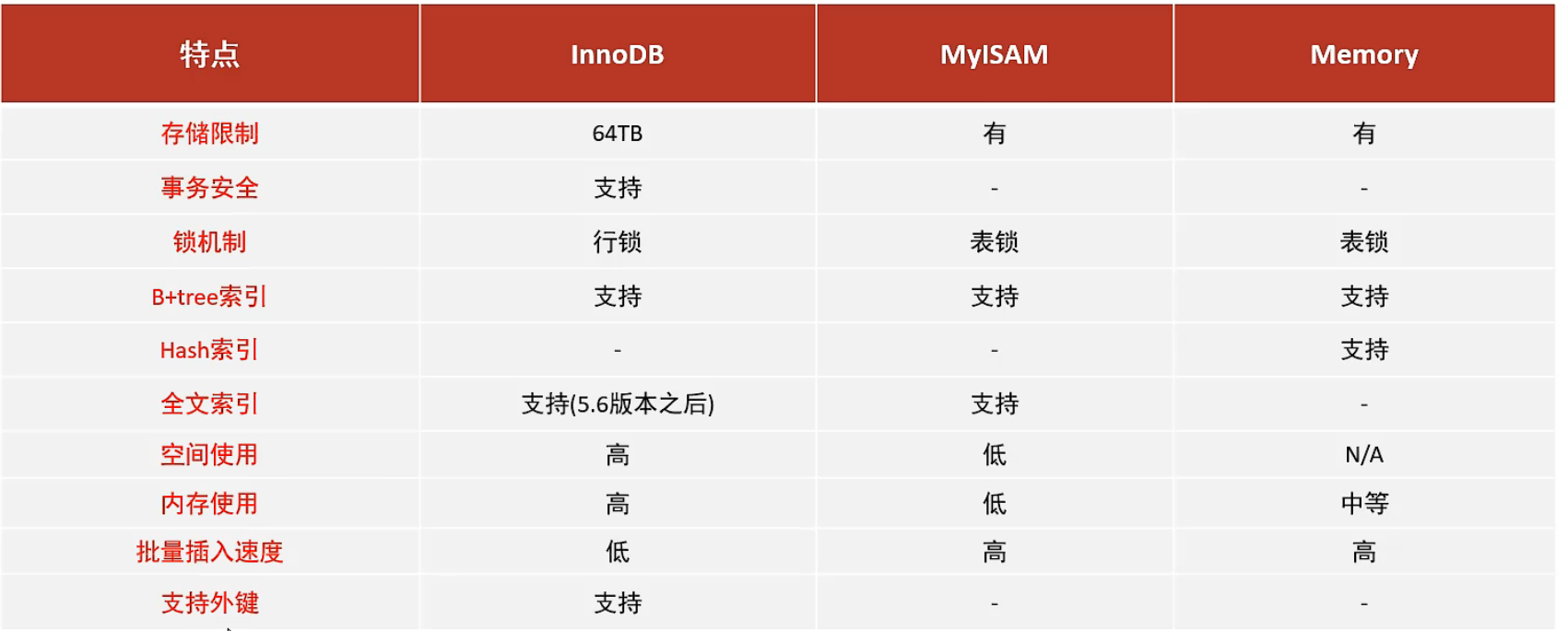
数据处理与统计分析——MySQL与SQL
这里写目录标题 1、初识数据库1.1、什么是数据库1.2、数据库分类1.3、相关概念1.4、MySQL及其安装1.5、基本命令 2、基本命令2.1、操作数据库2.2、数据库的列类型2.3、数据库的字段属性2.4 创建和删除数据库表2.5、数据库存储引擎2.6、修改数据库 3、MySQL数据管理3.1、外键 My…...

OpenCV之特征点匹配
特征点选取 特征点探测方法有goodFeaturesToTrack(),cornerHarris()和SURF()。一般使用goodFeaturesToTrack()就能获得很好的特征点。goodFeaturesToTrack()定义: void goodFeaturesToTrack( InputArray image, OutputArray corners,int maxCorners, double qualit…...

浅谈开关柜绝缘状态检测与故障诊断
贾丽丽 安科瑞电气股份有限公司 上海嘉定 201801 摘要:电力开关柜作为电力系统的关键设备广泛应用于输电配电网络,其运行可靠性直接影响着电力系统供电质量及安全性能。开关柜绝缘状态检测与故障诊断是及时维修、更换和预防绝缘故障的重要技术手段。在阐述开关柜绝…...

Mybatis 动态 SQL
动态 SQL 1. if 标签2. trim 标签3. where 标签4. set 标签5. foreach 标签 1. if 标签 if 标签有很多应用场景, 例如: 在用户进行注册是有些是必填项有些是选填项, 这就会导致前端传入的参数不固定如果还是将参数写死就很难处理, 这时就可以使用 if 标签进行判断 <insert …...

Android studio之 build.gradle配置
在使用Android studio创建项目会出现两个build.gradle: 一. Project项目级别的build.gradle (1)、buildscript{}闭包里是gradle脚本执行所需依赖,分别是对应的maven库和插件。 闭包下包含: 1、repositories闭包 2、d…...
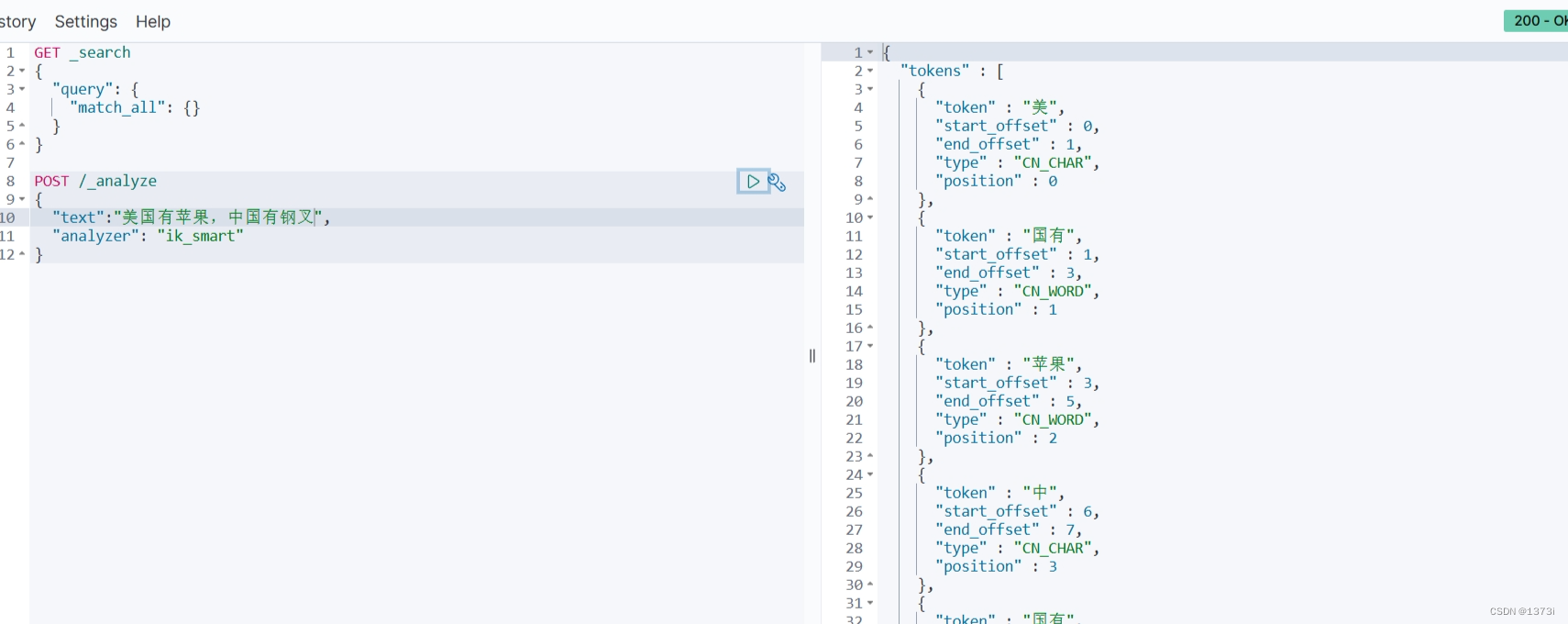
【ElasticSearch】一键安装IK分词器无需其他操作
要注意的时下面命令中的es是我容器的名称,要换成你对应的es容器名 docker exec -it es /bin/bash # 进入容器 ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis- ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.1…...

在Ubuntu上启动一个简单的用户登录接口服务
一个简单的用户登录接口 我使用 Python 和 Flask 框架来创建这个接口 首先,确保你已经安装了 Python 和 Flask。如果没有安装,可以通过以下命令在 Ubuntu 上安装: sudo apt update sudo apt install python3 python3-pip pip3 install Fla…...
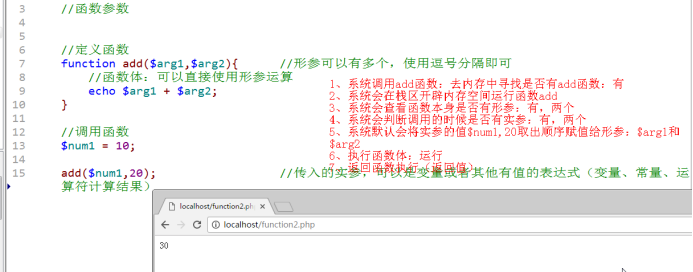
【PHP】函数-作用域可变函数匿名函数闭包常用系统函数
文章目录 函数定义&使用命名规则参数种类默认值引用传递函数返回值return关键字 作用域global关键字静态变量 可变函数匿名函数闭包常用系统函数输出函数时间函数数学函数与函数相关函数 函数 函数:function,是一种语法结构,将实现某一个…...

Python使用pymysql和sqlalchemy访问MySQL的区别
Python使用pymysql和sqlalchemy访问MySQL的区别 1. 两个数据库连接工具的对比 pymysql和sqlalchemy是两个Python中经常用于与MySQL数据库交互的库。都可以连接MySQL数据库,但它们有明显的区别。 (1)特点 pymysql是一个Python模块…...

告别图形界面:在Linux终端中高效管理百度网盘文件的完整指南
1. 为什么需要命令行管理百度网盘? 很多开发者都遇到过这样的场景:远程连接到Linux服务器时,需要快速上传日志文件到网盘,或者从网盘下载数据集到服务器。传统做法是先把文件下载到本地电脑,再用SFTP工具上传到服务器—…...

从硬盘拷贝文件到内存,CPU真的在‘摸鱼’吗?聊聊DMA背后的性能优化实战
从硬盘拷贝文件到内存,CPU真的在‘摸鱼’吗?聊聊DMA背后的性能优化实战 当你在服务器上执行一个简单的文件读取操作时,是否曾好奇过背后发生了什么?传统认知中,CPU需要亲自搬运每个字节的数据,但实际上现代…...
)
告别编译迷茫:手把手教你读懂UEFI固件开发中的DSC文件(以EDK2 vUDK2018为例)
告别编译迷茫:手把手教你读懂UEFI固件开发中的DSC文件(以EDK2 vUDK2018为例) 当你第一次打开EDK2项目中的DSC文件时,是否被那些看似杂乱无章的配置项和宏定义搞得晕头转向?作为UEFI固件开发的核心配置文件,…...

Docker多阶段构建与镜像优化实战
Docker多阶段构建与镜像优化实战:从1GB到50MB的瘦身之旅 🐳 镜像太大?构建太慢?安全隐患太多?本文通过真实 Node.js + Python 项目,手把手教你用多阶段构建把 Docker 镜像从 1GB 压缩到 50MB,附带完整的优化策略和踩坑指南。 一、为什么你的 Docker 镜像这么大? 很多…...

轻量级容器化部署工具Ship:简化中小团队应用部署流程
1. 项目概述:一个面向开发者的轻量级容器化部署工具最近在和朋友聊起中小团队或个人开发者的部署痛点时,大家普遍觉得,虽然Kubernetes(K8s)生态强大,但对于一个快速迭代的独立项目或小团队来说,…...
)
LaTeX引用中文文献总出乱码?可能是你BibTeX引擎和编码没选对(XeLaTeX+BibTeX实战)
LaTeX中文文献引用乱码全解析:从编码原理到XeLaTeX实战方案 当你熬夜赶论文时,参考文献列表突然变成一堆乱码方块,引用标记全部显示为"??"——这种崩溃瞬间,每个用LaTeX写过中文论文的人都经历过。传统解决方案往往停…...

EdgeRemover:Windows系统终极Edge浏览器管理完全指南
EdgeRemover:Windows系统终极Edge浏览器管理完全指南 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemover 你是否…...
)
为什么你的Perplexity Science搜索总错过最新预印本?——基于arXiv/medRxiv/SSRN实时源的3层校验机制(含Python自动化脚本)
更多请点击: https://intelliparadigm.com 第一章:为什么你的Perplexity Science搜索总错过最新预印本?——基于arXiv/medRxiv/SSRN实时源的3层校验机制(含Python自动化脚本) Perplexity Science 依赖第三方索引快照…...

终极Blender 3MF插件:如何快速实现3D打印文件的无缝转换
终极Blender 3MF插件:如何快速实现3D打印文件的无缝转换 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat Blender3mfFormat是一款专为Blender设计的开源插件&a…...

利用大语言模型实现数据自动标注:Autolabel 实战指南
1. 项目概述:用大模型自动标注数据,告别人工标注的苦差事 如果你做过机器学习项目,尤其是监督学习,那你一定对数据标注这个环节又爱又恨。爱的是,有了高质量标注数据,模型性能才有保障;恨的是&a…...