redis实战-缓存三剑客穿透击穿雪崩解决方案
缓存穿透
定义
缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库,造成数据库压力,也让缓存没有发挥出应有的作用
解决方案
- 缓存空对象
当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,但是数据库中也没有数据,这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,这个数据即使数据库不存在,我们也把这个数据存入到redis中去,这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据就不会进入到缓存了,但这样缓存大量空对象也会消耗内存
- 布隆过滤器
布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,假设布隆过滤器判断这个数据不存在,则直接返回,优点在于节约内存空间,但会存在误判,即过滤器判断该数据不存在是准确的,但判断存在时就不一定准确,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突

解决思路
在原来的逻辑中,我们如果发现这个数据在mysql中不存在,直接就返回404了,这样是会存在缓存穿透问题的
现在的逻辑中:如果这个数据不存在,我们不会返回404 ,还是会把这个数据写入到Redis中,并且将value设置为空,欧当再次发起查询时,我们如果发现命中之后,判断这个value是否是null,如果是null,则是之前写入的数据,证明是缓存穿透数据,如果不是,则直接返回数据。
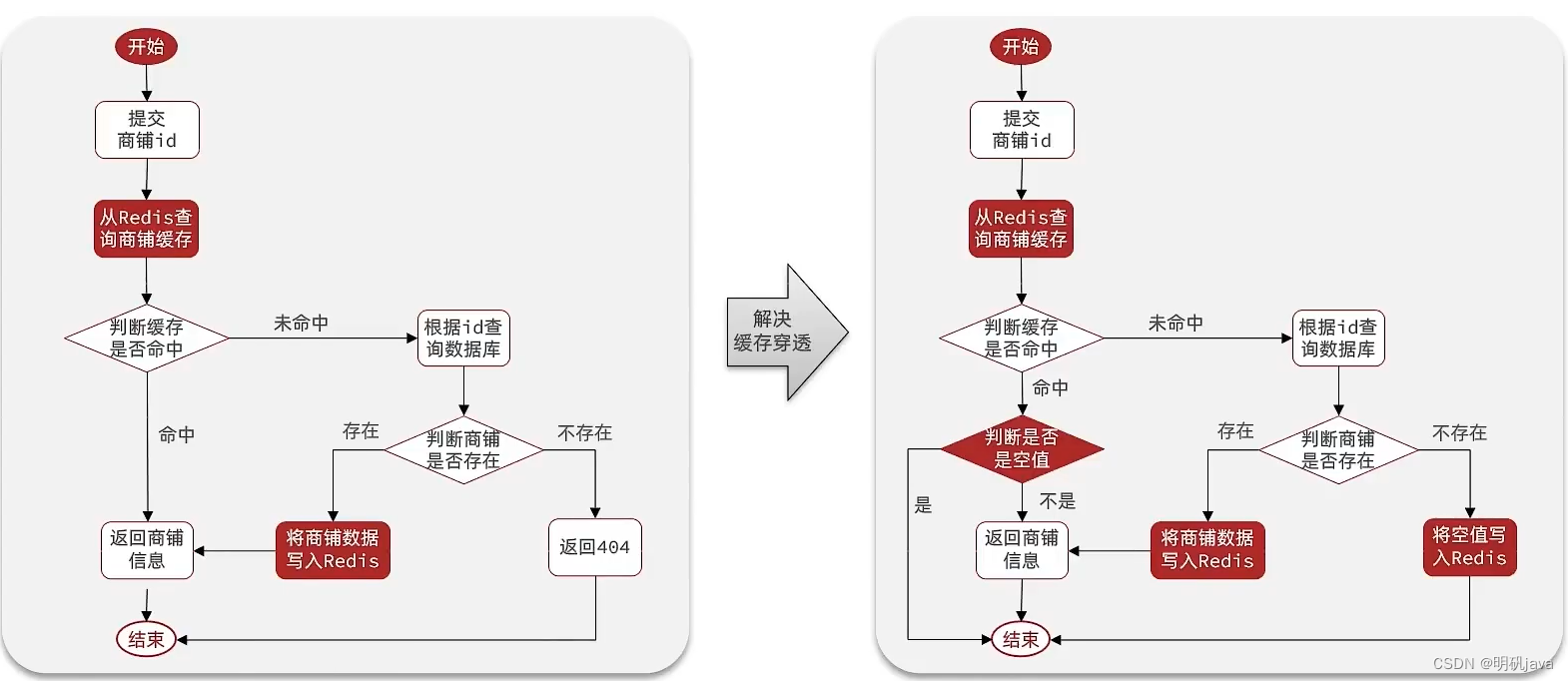
编码解决
由于布隆过滤器实现得较为复杂,本项目采用方案一即数据库不存在数据时直接缓存空对象,对查询商铺信息方法进行改造
@Overridepublic Result queryById(Long id) {//根据业务代码组装keyString key = CACHE_SHOP_KEY + id;//从redis中获取商铺信息String shopJson = stringRedisTemplate.opsForValue().get(key);//判断有值的情况if (StrUtil.isNotBlank(shopJson)) {//将json转化为shop对象直接返回Shop shop = JSONUtil.toBean(shopJson, Shop.class);return Result.ok(shop);}//对无值情况进行校验if(shopJson!=null){return Result.fail("店铺不存在");}Shop shop = getById(id);if (shop == null) {//将当前的key的空对象缓存到redis中,过期时间设置稍微短一点stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);return Result.fail("店铺不存在");}//将数据库查询的数据写入缓存,并设置过期时间stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);//返回return Result.ok(shop);}缓存雪崩
定义
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案
-
给不同的Key的TTL添加随机值,使得key不会同时失效
-
利用Redis集群提高服务的可用性
-
给缓存业务添加降级限流策略
-
给业务添加多级缓存
缓存击穿
定义
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。比如双十一做活动的热门商品数据
情景分析:假设线程1在查询缓存之后,本来应该去查询数据库,然后把这个数据重新加载到缓存的,此时只要线程1走完这个逻辑,其他线程就都能从缓存中加载这些数据了,但是假设在线程1没有走完的时候,后续的线程2,线程3,线程4同时过来访问当前这个方法, 那么这些线程都不能从缓存中查询到数据,那么他们就会同一时刻来访问查询缓存,都没查到,接着同一时间去访问数据库,同时的去执行数据库代码,对数据库访问压力过大

解决方案
-
互斥锁
因为锁能实现互斥性。假设线程过来,只能一个人一个人的来访问数据库,从而避免对于数据库访问压力过大,但这也会影响查询的性能,因为此时会让查询的性能从并行变成了串行,我们可以采用tryLock方法 + double check来解决这样的问题。这一方案的好处是保证了数据的强一致性,也就是每个线程查询的数据都是最新的数据
情景分析
假设现在线程1过来访问,他查询缓存没有命中,但是此时他获得到了锁的资源,那么线程1就会一个人去执行逻辑,假设现在线程2过来,线程2在执行过程中,并没有获得到锁,那么线程2就可以进行到休眠,直到线程1把锁释放后,线程2获得到锁,然后再来执行逻辑,此时就能够从缓存中拿到数据了。

编码实现
核心思路:相较于原来从缓存中查询不到数据后直接查询数据库而言,现在的方案是进行查询之后,如果从缓存没有查询到数据,则进行互斥锁的获取,获取互斥锁后,判断是否获得到了锁,如果没有获得到,则休眠,过一会再进行尝试,直到获取到锁为止,才能进行查询。如果获取到了锁的线程,再去进行查询,查询后将数据写入redis,再释放锁,返回数据,利用互斥锁就能保证只有一个线程去执行操作数据库的逻辑,防止缓存击穿

操作锁的代码:
核心思路就是利用redis的setnx方法来表示获取锁,该方法含义是redis中如果没有这个key,则插入成功,返回1,类似于mybatisplus的乐观锁,在stringRedisTemplate中返回true, 如果有这个key则插入失败,则返回0,在stringRedisTemplate返回false,我们可以通过true,或者是false,来表示是否有线程成功插入key,成功插入的key的线程我们认为他就是获得到锁的线程。
private boolean tryLock(String key) {Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag);
}private void unlock(String key) {stringRedisTemplate.delete(key);
}锁的代码应该尽量小规模,这里只在访问数据库的时候加上互斥锁
public Shop queryWithMutex(Long id) {//根据业务代码组装keyString key = CACHE_SHOP_KEY + id;//从redis中获取商铺信息String shopJson = stringRedisTemplate.opsForValue().get(key);//判断有值的情况if (StrUtil.isNotBlank(shopJson)) {//将json转化为shop对象直接返回Shop shop = JSONUtil.toBean(shopJson, Shop.class);return shop;}//对无值情况进行校验if (shopJson != null) {return null;}//拼装获取锁的keyString lockKey = LOCK_SHOP_KEY + id;Shop shop = null;try {//获取锁boolean b = tryLock(lockKey);//获取锁失败要休眠然后继续重试,看缓存中是否已经被别的线程写入数据if (!b) {Thread.sleep(50);return queryWithMutex(id);}shop = getById(id);if (shop == null) {//将当前的key的空对象缓存到redis中,过期时间设置稍微短一点stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);return null;}//将数据库查询的数据写入缓存,并设置过期时间stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);} catch (InterruptedException e) {throw new RuntimeException(e);} finally {unlock(lockKey);}//返回return shop;}-
逻辑过期方案
我们之所以会出现这个缓存击穿问题,主要原因是在于我们对key设置了过期时间,假设我们不设置过期时间,其实就不会有缓存击穿的问题,但是不设置过期时间,这样数据不就一直占用我们内存了吗,我们可以采用逻辑过期方案,让热点key常驻于内存。
情景分析
过期时间设置在redis的value中,注意:这个过期时间并不会直接作用于redis,而是我们后续通过逻辑去处理。假设线程1去查询缓存,然后从value中判断出来当前的数据已经过期了,此时线程1去获得互斥锁,那么其他线程会进行阻塞,获得了锁的线程他会开启一个新线程去进行 以前的重构数据的逻辑,直到新开的线程完成这个逻辑后,才释放锁,而线程1直接进行返回数据,并不会阻塞等待,假设现在线程3过来访问,由于线程线程2持有着锁,所以线程3无法获得锁,线程3也直接返回数据,只有等到新开的线程2把重建数据构建完后,其他线程才能走返回正确的数据。也就是该方案并不会像互斥锁那样,需要等待堵塞更新数据,导致性能下降,而是直接返回旧数据,但这也带来了数据的不一致性的问题。

编码实现
思路分析:当用户开始查询redis时,判断是否命中,如果没有命中则直接返回空数据,不查询数据库,而一旦命中后,将value取出,判断value中的过期时间是否满足,如果没有过期,则直接返回redis中的数据,如果过期,则在开启独立线程后直接返回之前的数据,独立线程去重构数据,重构完成后释放互斥锁。

由于需要有逻辑过期的时间变量,需要拓展变量,这里采用redisdata的方式直接将shop封装成redisdata的成员变量,同时该对象具有过期时间这个变量
@Data
public class RedisData {private LocalDateTime expireTime;private Object data;
}我们需要进行缓存预热,就是将热点key的数据提前存入redis中,这里使用单元测试将数据写入redis中,注意写入的是redisdata这个对象
@Overridepublic void saveShopToRedis(Long id, Long expireSeconds) {Shop show = getById(id);//封装redisdataRedisData redisData = new RedisData();redisData.setData(show);redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(redisData));}
这里开启线程去构建新数据,采用的是开启线程池,节约资源
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public Shop queryWithLogicalExpire( Long id ) {String key = CACHE_SHOP_KEY + id;// 1.从redis查询商铺缓存String json = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isBlank(json)) {// 3.存在,直接返回return null;}// 4.命中,需要先把json反序列化为对象RedisData redisData = JSONUtil.toBean(json, RedisData.class);Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);LocalDateTime expireTime = redisData.getExpireTime();// 5.判断是否过期if(expireTime.isAfter(LocalDateTime.now())) {// 5.1.未过期,直接返回店铺信息return shop;}// 5.2.已过期,需要缓存重建// 6.缓存重建// 6.1.获取互斥锁String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);// 6.2.判断是否获取锁成功if (isLock){CACHE_REBUILD_EXECUTOR.submit( ()->{try{//重建缓存this.saveShop2Redis(id,20L);}catch (Exception e){throw new RuntimeException(e);}finally {unlock(lockKey);}});}// 6.4.返回过期的商铺信息return shop;
}相关文章:
redis实战-缓存三剑客穿透击穿雪崩解决方案
缓存穿透 定义 缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库,造成数据库压力,也让缓存没有发挥出应有的作用 解决方案 缓存空对象 当我们客户端…...
Tomcat10安装及配置教程win11
Tomcat10安装及配置教程win11 Tomcat下载链接 Tomcat官网 Tomcat官网地址 https://tomcat.apache.org/ Tomcat的版本列表 点击上图中左侧红框内**Which version?**即可得下图 下载Tomcat 点击上图中左侧红框内红框内tomcat版本即可得下图,下载zip包 解压zip包…...

遗传算法解决TSP问题
一、求解问题概述 1.1 TSP问题 TSP问题是指旅行商问题(Traveling Salesman Problem)。在TSP问题中,假设有一名旅行商要在给定的一组城市之间进行旅行,每个城市只能被访问一次,并且旅行商必须最终返回出发城市。问题的…...
设计模式-工厂设计模式
核心思想 在简单工厂模式的基础上进一步的抽象化具备更多的可扩展和复用性,增强代码的可读性使添加产品不需要修改原来的代码,满足开闭原则 优缺点 优点 符合单一职责,每个工厂只负责生产对应的产品符合开闭原则,添加产品只需添…...
TM4C123库函数学习(3)---串口中断
前言 (1)学习本文之前,需要先学习前两篇文章。 (2)学习本文需要准备好TTL转USB模块。 函数介绍 ROM_GPIOPinConfigure() 配置GPIO引脚的复用功能。因为引脚不可能只有一个输出输入作用…...
opencv 进阶13-Fisherfaces 人脸识别-函数cv2.face.FisherFaceRecognizer_create()
Fisherfaces 人脸识别 PCA 方法是 EigenFaces 方法的核心,它找到了最大化数据总方差特征的线性组合。不可否认,EigenFaces 是一种非常有效的方法,但是它的缺点在于在操作过程中会损失许多特征信息。 因此,在一些情况下,…...
基于mysql5.7制作自定义的docker镜像,适用于xxl-job依赖的数据库,自动执行初始化脚本(ddl语句和dml语句)
一、背景 xxl-job-admin依赖mysql数据库,且需执行初始化脚本,包括ddl和dml语句。 具体的步骤总结如下: 1、新建数据库xxl_job2、创建mysql表table3、执行dml语句,包括新建admin用户及密码,创建执行器和任务。 毫无疑…...

LeetCodeHot100python版本:单调栈,栈,队列,堆
单调栈 739. 每日温度 42. 接雨水 双指针 单调栈(横向求解) 84. 柱状图中最大的矩形 栈和队列 队列:先入先出 栈:先入后出 两个栈 模拟 队列 一个队列 可以模拟 栈 20. 有效的括号 155. 最小栈 394. 字符串解码 堆 215. 数组中的第K个最大元素 3…...
JUC初识
JUC 是什么 java.util.concurrent 在并发编程中使用的工具包 从线程start 开始 package com.jhj.Thread;public class ThreadDemo {public static void main(String[] args) {Thread t1 new Thread(() -> {}, "t1");t1.start();} }start 方法调的是native sta…...
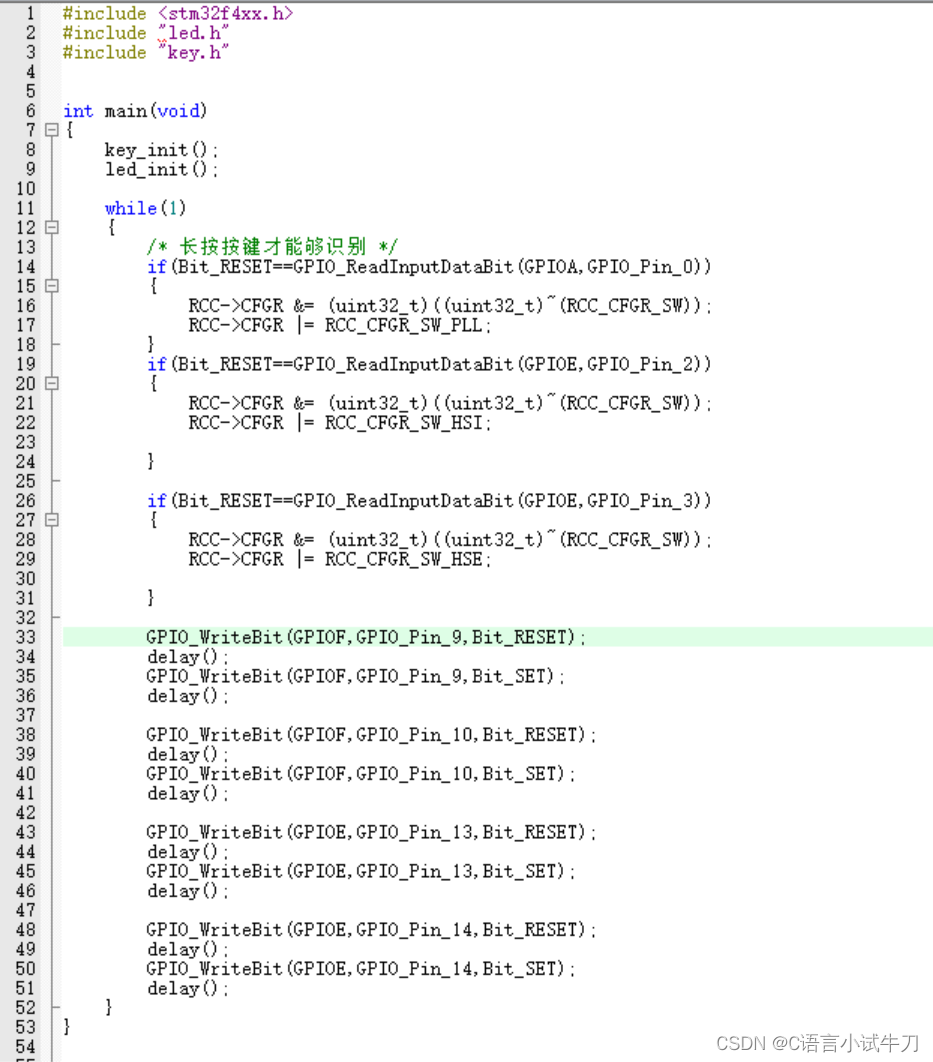
stm32之5.长按按键(使用时钟源)调整跑马灯速度
------------------------------ 源码 #include <stm32f4xx.h> #include "led.h" #include "delay.h" #include "my_str.h" #include "beep.h" #include "key.h" int main(void) { key_init(); Led_init();…...

element ui datePick时间日期一段时间,限制选择日期的范围
想限制只能选日期间隔为一年,联合选择器样式不好改,使用俩单独的 有两个办法限制 1.一个在外层使用form通过表单验证控制,出现错误提示(由于是两个单独的组件,触发验证的方式又为单个失去焦点,所以俩组件…...
kubernetes--技术文档-真--集群搭建-三台服务器一主二从(非高可用)-三服务器位于同交换机中
在使用k8s之前如果不太熟悉k8s的可以先看这个文章: kubernetes--技术文档--基本概念--《10分钟快速了解》_一单成的博客-CSDN博客 三节点相同安装操作: 1、设置hosts解析 根据角色在三个服务器中运行,设置自己的hostname。 标识…...
:性能优化)
高性能MySQL实战(三):性能优化
大家好,我是 方圆。这篇主要介绍对慢 SQL 优化的一些手段,而在讲解具体的优化措施之前,我想先对 EXPLAIN 进行介绍,它是我们在分析查询时必要的操作,理解了它输出结果的内容更有利于我们优化 SQL。为了方便大家的阅读&…...

198. 打家劫舍
题目 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。 给定一个代表每个房屋存放…...
Pydev·离线git包
Pydev离线git包 1.下载离线git包:eclipse.egit.repository-4.4.0.201606070830-r.zip 2.将解压后目录:eclipse.egit.repository-4.4.0.201606070830-r\plugins下的jar文件放到 ide\eclipse\plugins目录下 3.重启pydevIDE 百度搜索站长工具:h…...

Vue-12.集成postcss.config.js
PostCSS 介绍 PostCSS 是一个用于处理样式的工具,可以通过插件来定制其行为。以下是一些常用的 PostCSS 插件和 API 的介绍: Autoprefixer: 这是一个流行的 PostCSS 插件,用于自动添加浏览器前缀,以确保您的样式在不同浏览器中具…...

基于前端技术原生HTML、JS、CSS 电子病历编辑器源码
电子病历系统采取结构化与自由式录入的新模式,自由书写,轻松录入。实现病人医疗记录(包含有首页、病程记录、检查检验结果、医嘱、手术记录、护理记录等等。)的保存、管理、传输和重现,取代手写纸张病历。不仅实现了纸…...

Linux环境下远程访问SVN服务:SVN内网穿透的详细配置与操作指南
文章目录 前言1. Ubuntu安装SVN服务2. 修改配置文件2.1 修改svnserve.conf文件2.2 修改passwd文件2.3 修改authz文件 3. 启动svn服务4. 内网穿透4.1 安装cpolar内网穿透4.2 创建隧道映射本地端口 5. 测试公网访问6. 配置固定公网TCP端口地址6.1 保留一个固定的公网TCP端口地址6…...
创建k8s operator
目录 1.前提条件 2.进一步准备 2.1.安装golang 2.2.安装code(vscode的linux版本) 2.3.安装kubebuilder 3.开始创建Operator 3.1.什么是operator? 3.2.GV & GVK & GVR 3.3.创建operator 3.3.1. 生成工程框架 3.3.2.生成api(GVK) …...
python模拟登入某平台+破解验证码
概述 python模拟登录平台,遇见验证码识别!用最简单的方法seleniumda破解验证码,来自动登录平台 详细 python用seleniumxpath模拟登录破解验证码 先随便找个小说平台用户登陆 - 书海小说网用户登陆 - 书海小说网用户登陆 - 书海小说网 准…...

带标注的胶囊缺陷识别数据集,识别率68.9%,可识别印刷不良,裂纹,戳痕,划痕,挤压变形五种缺陷,219张图,支持yolo,coco json,voc xml,文末有模型训练代码
带标注的胶囊缺陷识别数据集,识别率68.9%,可识别印刷不良,裂纹,戳痕,划痕,挤压变形五种缺陷,219张图,支持yolo,coco json,voc xml,文末有模型训练代码 模…...

H5GG完整指南:如何用JavaScript和HTML5轻松修改iOS游戏内存
H5GG完整指南:如何用JavaScript和HTML5轻松修改iOS游戏内存 【免费下载链接】H5GG an iOS Mod Engine with JavaScript APIs & Html5 UI 项目地址: https://gitcode.com/gh_mirrors/h5/H5GG 你是否曾经想过修改iOS游戏中的数值,却因为复杂的越…...

TC2526 低功耗原边反馈开关电源芯片
概述 TC2526 是一款低功耗原边反馈(PSR)开关电源芯片,其内部集成了大功率 BJT 管,适用于隔离型的高效低功耗便携式设备充电器应用。TC2526 采用独特具有恒流恒压功能的原边反馈控制技术,以及独特的轻载调频技术降低轻载…...

Sunshine游戏串流实战手册:构建你的跨平台游戏共享生态系统
Sunshine游戏串流实战手册:构建你的跨平台游戏共享生态系统 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾想过在客厅大屏电视上畅玩书房电脑里的3A大作&…...

别再用strlen了!C++里sizeof和字符数组的坑,我帮你踩完了
别再用strlen了!C里sizeof和字符数组的坑,我帮你踩完了 在C编程中,处理字符串和字符数组时,sizeof和strlen这两个看似简单的概念常常让初学者陷入困惑。特别是在信息学竞赛或日常编程中,错误地使用它们可能导致难以察…...

IC设计五大典型Bug剖析:从CDC到软硬件协同的防御性设计
1. 项目概述:IC设计中的那些“老朋友”在芯片设计的江湖里混迹多年,我越来越觉得,我们这些IC工程师(ICer)的日常,与其说是在创造,不如说是在与各种层出不穷的“老朋友”——也就是bug——斗智斗…...

从SES价签到ESP32墨水屏驱动板:自制低成本电子价签全记录
1. 从废品到宝藏:SES电子价签的二次生命 第一次看到SES电子价签是在一家即将倒闭的超市里,成堆的废弃价签被当作垃圾处理。当时我就想:这些自带墨水屏的小玩意,能不能变废为宝?后来在二手平台以每片不到20元的价格收购…...

别再折腾内网穿透了!用EC600N 4G模块+华为云IoTDA,5分钟搞定远程宠物定位数据上传
5分钟实现宠物定位数据上云:EC600N 4G模块与华为云IoTDA实战指南 当你的宠物突然从视线中消失时,那种焦虑感是任何宠物主人都深有体会的。传统的蓝牙防丢器仅有几十米的有效范围,而GPS定位器又常受限于复杂的网络配置。现在,通过…...
)
用STM32F103C8T6做个触摸感应示波器?手把手教你ADC采集+OLED波形显示(附完整代码)
用STM32F103C8T6打造触摸感应示波器:从ADC采集到OLED波形显示的趣味实践 在嵌入式开发领域,将枯燥的技术参数转化为可视化的交互体验,往往能激发学习者的深层兴趣。今天我们要实现的,不仅是一个简单的信号采集系统,而是…...

探索高效存储:STM32F4系列SD卡读写与FATFS文件系统移植
探索高效存储:STM32F4系列SD卡读写与FATFS文件系统移植 【下载地址】SD卡读写与FATFS文件系统移植SPI模式 本仓库提供了一个完整的SD卡读写程序,并成功移植了FATFS文件系统,适用于STM32F4系列微控制器。通过SPI模式,您可以轻松实现…...