【SQL】MySQL秘籍

chihiro-notes
千寻简笔记
v0.1 内测版
📔 笔记介绍
大家好,千寻简笔记是一套全部开源的企业开发问题记录,毫无保留给个人及企业免费使用,我是作者星辰,笔记内容整理并发布,内容有误请指出,笔记源码已开源,前往Gitee搜索《chihiro-notes》,感谢您的阅读和关注。
作者各大平台直链: GitHub | Gitee | CSDN|
文章目录
- 📔 笔记介绍
- 初级篇
- 应用题
- 表操作
- 创建一个表
- 增加表字段
- 增删改
- 插入一条数据
- 插入一条数据
- 删除一条数据
- 更新一条数据库
- 查询篇
- 查询所有数据
- 条件查询: user_id = 123 的数据
- 条件查询:查询 user_id = 123 或 456 的数据
- 应用题
- 中级篇
- 常用条件查询
- 模糊查询
- 联查
- 关键字:UNION ALL
- 关键字:DISTINCT
- 【Java代码】xml 循环set数组
- 关键字:EXISTS
- 关键字:CASE WHEN
- 存储过程
- 利用生成假数据
- 创建存储过程
- 调用存储过程
- 删除存储过程
- 应用题
- 有关时间的语句
- x日期 - y日期 小于等于 40天
- 计算两个时间相差的天数
- sql如何计算一个日期某个周期后的日期
- select语句查询近一周的数据
- SQL利用Case When Then多条件判断
- MySQL内连接(INNER JOIN)
- between
- 索引-理论篇
- 存储方式区分
- B-树索引:BTREE
- 哈希索引:Hash
- 逻辑区分
- 普通索引:INDEX
- 唯一索引:UNIQUE
- 主键索引:PRIMARY KEY
- 空间索引:SPATIAL
- 全文索引:FULLTEXT
- 实际使用
- 单列索引
- 多列索引/复合索引
- 删除索引
- 索引-实践篇
- 增删查
- 添加索引
- 查看索引
- 删除索引
- 索引失效
- 一、隐式的类型转换,索引失效
- 二、查询条件包含or,可能导致索引失效
- 三、like通配符可能导致索引失效
- 四、查询条件不满足联合索引的最左匹配原则
- 五、在索引列上使用mysql的内置函数
- 六、对索引进行列运算(如,+、-、*、/),索引不生效
- 七、索引字段上使用(!= 或者 < >),索引可能失效
- 八、索引字段上使用is null, is not null,索引可能失效
- 九、左右连接,关联的字段编码格式不一样
- 十、优化器选错了索引
- 3.3 索引速度对比
初级篇
SQL DML 和 DDL
- 可以把 SQL 分为两个部分:数据操作语言 (DML) 和 数据定义语言 (DDL)。
- SQL (结构化查询语言)是用于执行查询的语法。
- 但是 SQL 语言也包含用于更新、插入和删除记录的语法。
应用题
表操作
- 创建表
创建一个表
DROP TABLE IF EXISTS key_value;
CREATE TABLE key_value(_key VARCHAR(255) COMMENT '键' ,_value VARCHAR(255) COMMENT '值'
) COMMENT = '键值对';
增加表字段
ALTER TABLE
给表条件一个字段
ALTER TABLE 表名 ADD `字段名` VARCHAR ( 128 ) COMMENT '备注';
ALTER TABLE t_user ADD `user_name` VARCHAR ( 128 ) COMMENT '用户名称';
增删改
查询和更新指令构成了 SQL 的 DML 部分:
SELECT - 从数据库表中获取数据
UPDATE - 更新数据库表中的数据
DELETE - 从数据库表中删除数据
INSERT INTO - 向数据库表中插入数据
插入一条数据
插入一条数据
INSERT INTO 语句
INSERT INTO 语句用于向表格中插入新的行。
//语法:
INSERT INTO 表名称 VALUES (值1, 值2,....)
//我们也可以指定所要插入数据的列:
INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....)
INSERT INTO key_value VALUES ("1","2222");
INSERT INTO key_value (_key,_value) VALUES ("2","键值对");
删除一条数据
DELETE 语句
DELETE 语句用于删除表中的行。
//语法:
DELETE FROM 表名称 WHERE 列名称 = 值
DELETE FROM key_value WHERE _key = "2";
SELECT * FROM key_value;
更新一条数据库
Update 语句
Update 语句用于修改表中的数据。
语法:
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
UPDATE key_value set _key = "我不想做主键" WHERE _key= "1";
SELECT * from key_value;
查询篇
查询所有数据
现在我们希望从 “Persons” 表中选取所有的列。 请使用符号 * 取代列的名称,就像这样:
SELECT * FROM Persons
条件查询: user_id = 123 的数据
SELECTtu.id,tu.user_name
FROMtu.t_user AS tu
WHEREtu.user_id = 123;
条件查询:查询 user_id = 123 或 456 的数据
SELECTtu.id,tu.user_name
FROMt_user AS tu
WHEREtu.user_id = 123OR tu.user_id = 456;
应用题
问:你怎么快速找出两条相同的数据?字段为id
SELECTcid.id,cid.id ,cid.name
FROMchihiro_id AS cid
GROUP BYcid.id HAVING COUNT(cid.id )>1;
验证是否正确:
SELECTcid.id,cid.id ,cid.name
FROMchihiro_id AS cid
WHEREcid.id = 34170
OR cid.id = 15022
;
删除重复的id
DELETE FROM chihiro_id
WHEREid = 317021266123 OR id = 317021266123
;
中级篇
常用条件查询
模糊查询
select * from chihiro_area;
SELECT * FROM `chihiro_area` WHERE 1=1 and name LIKE '%北';
SELECT name,area_code FROM chihiro_area WHERE 1=1 and area_code LIKE '11%';
select * from chihiro_area where parent_code LIKE '1100%';
select * from chihiro_area WHERE name LIKE '北京%';
联查
SELECT * from sys_user;
SELECT * from sys_dept;select su.dept_id,su.user_name,sd.dept_name,sd.email
from sys_user AS su
INNER JOIN sys_dept AS sd ON su.dept_id = sd.dept_id;
关键字:UNION ALL
多字段查询
-- 用于多字段查询
SELECTlc.id,lc.first_hearing_address AS hearingAddress
FROMt_layer_case AS lc
WHERElc.first_hearing_address != ''
UNION ALL
SELECTlc.id,lc.second_hearing_address AS hearingAddress
FROMt_layer_case AS lc
WHERElc.second_hearing_address != ''
UNION ALL
SELECTlc.id,lc.executive_court AS hearingAddress
FROMt_layer_case AS lc
WHERElc.executive_court != ''
Union all 查询完统计
select a,b,c from (select a, b, c from aaunion all select a1 as a, b1 as b, c1 as c from bb
) a group by c
关键字:DISTINCT
-- 去重手机号
SELECT DISTINCT first_economics_officer_contact AS "economicsOfficerContact",first_economics_officer AS "economicsOfficer"
FROMt_layer_case
WHEREfirst_economics_officer_contact is not null
【Java代码】xml 循环set数组
<if test="caseTypeSet != null">AND lc.case_type IN<foreach collection="caseTypeSet" item="item" open="(" separator="," close=")">#{item}</foreach>
</if>
关键字:EXISTS
实际场景:查询表a中a.id,在表b中是否存在车辆;
AND EXISTS(SELECT tpc.types_of_property_clues FROM t_property_clues AS tpc WHERE tpc.types_of_property_clues = '车辆' AND tpc.case_id = lc.id)
-- 判断
SELECTCOUNT(*) AS number,hearingAddress
FROM(SELECTlc.id,lc.first_hearing_address AS hearingAddress FROMt_layer_case AS lcLEFT JOIN t_entrusted_client AS ec ON ec.id = lc.entrusted_client_idLEFT JOIN t_upcoming AS tu ON tu.case_id = lc.idWHERE1 = 1 AND lc.first_hearing_address != '' AND EXISTS(SELECT tpc.types_of_property_clues FROM t_property_clues AS tpc WHERE tpc.types_of_property_clues = '车辆' AND tpc.case_id = lc.id)UNION ALLSELECTlc.id,lc.second_hearing_address AS hearingAddress FROMt_layer_case AS lcLEFT JOIN t_entrusted_client AS ec ON ec.id = lc.entrusted_client_idLEFT JOIN t_upcoming AS tu ON tu.case_id = lc.idWHERE1 = 1 AND lc.second_hearing_address != '' AND EXISTS(SELECT tpc.types_of_property_clues FROM t_property_clues AS tpc WHERE tpc.types_of_property_clues = '车辆' AND tpc.case_id = lc.id)UNION ALLSELECTlc.id,lc.executive_court AS hearingAddress FROMt_layer_case AS lcLEFT JOIN t_entrusted_client AS ec ON ec.id = lc.entrusted_client_idLEFT JOIN t_upcoming AS tu ON tu.case_id = lc.idLEFT JOIN ( SELECT id, case_id, types_of_property_clues FROM t_property_clues WHERE types_of_property_clues = '车辆' GROUP BY case_id ) AS tpc ON tpc.case_id = lc.id WHERE1 = 1 AND lc.executive_court != '' AND EXISTS(SELECT tpc.types_of_property_clues FROM t_property_clues AS tpc WHERE tpc.types_of_property_clues = '车辆' AND tpc.case_id = lc.id)) table1
GROUP BYhearingAddress
ORDER BYCOUNT(*) DESC LIMIT 10
关键字:CASE WHEN
查询结果等于0 就返回一1 ,其他返回0
SELECTtfm.id AS id,(CASE WHEN SUM(trs.repayment_amount_instalment * (lawyer_fee_proportion/100))-SUM(trs.repayment_amount* (lawyer_fee_proportion/100)) = 0 THEN 1 ELSE 0 END) AS fee_clear,
FROMt_financial_management AS tfm
存储过程
利用生成假数据
创建存储过程
delimiter //
create procedure batchInsert()
begindeclare num int; set num=1;while num<=1000000 doinsert into key_value(`username`,`password`) values(concat('测试用户', num),'123456');set num=num+1;end while;
end
//
delimiter ; #恢复;表示结束
调用存储过程
写好了存储过程就可以进行调用了,可以通过命令调用:
CALL batchInsert;
也可以在数据库工具的中Functions的栏目下,找到刚刚创建的存储过程直接执行。
删除存储过程
drop procedure batchInsert;
应用题
有关时间的语句
-- 改成日期的时间戳
SELECT NOW();
SELECT UNIX_TIMESTAMP(NOW());
SELECT UNIX_TIMESTAMP('2022-12-27');
x日期 - y日期 小于等于 40天
-- 当前时间大于开庭时间,代表已开庭
SELECT tlc.first_hearing_time AS courtDate,CASE WHEN NOW()> tlc.first_hearing_time THEN "1" ELSE "0" END AS isOpenACourtSession
FROM t_layer_case AS tlc
WHEREtlc.first_hearing_time IS NOT NULL
ANDABS(DATEDIFF(first_hearing_time,"2022-12-27 16:56:13" )) <=40;计算两个时间相差的天数
ABS(DATEDIFF(tpc.appeal_time_of_closure_and_registration,NOW())) AS "累计查封时间",
sql如何计算一个日期某个周期后的日期
-- 查询x日期,y年后的日期
SELECT DATE_ADD(NOW(),INTERVAL 3 YEAR);
select语句查询近一周的数据
select * from table where
DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(column_time);
SQL利用Case When Then多条件判断
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
WHEN 条件3 THEN 结果3
WHEN 条件4 THEN 结果4
…
WHEN 条件N THEN 结果N
ELSE 结果X
ENDCase具有两种格式。简单Case函数和Case搜索函数。
–简单Case函数
CASE sex
WHEN ‘1’ THEN ‘男’
WHEN ‘2’ THEN ‘女’
ELSE ‘其他’ END
–Case搜索函数
CASE WHEN sex = ‘1’ THEN ‘男’
WHEN sex = ‘2’ THEN ‘女’
ELSE ‘其他’ END
CASE WHEN bn.endDay < 60 THEN 1WHEN bn.endDay < 30 THEN 2WHEN bn.endDay < 15 THEN 3ELSE"不提醒"END AS "level",
MySQL内连接(INNER JOIN)
SELECTtpc.id,tpc.case_id,tpc.entrusted_client_id,tpc.types_of_property_clues,tpc.property_clue_information,CASE WHEN bn.endDay < 60 THEN 1WHEN bn.endDay < 30 THEN 2WHEN bn.endDay < 15 THEN 3ELSE"不提醒"END AS "level",tlc.defendant_name,tlc.first_case_number,tlc.second_case_number,tlc.execution_case_number
FROMt_property_clues AS tpc
INNER JOIN(SELECTtpcc.id AS id,DATE_ADD(tpcc.appeal_time_of_closure_and_registration,INTERVAL tpcc.appeal_legal_time_of_closure YEAR) AS endTime,ABS(DATEDIFF(DATE_ADD(tpcc.appeal_time_of_closure_and_registration,INTERVAL tpcc.appeal_legal_time_of_closure YEAR),NOW())) AS endDayFROMt_property_clues AS tpcc
)AS bn ON bn.id = tpc.id
LEFT JOINt_layer_case AS tlc ON tlc.id = tpc.case_id
WHERE1=1
AND ABS(DATEDIFF(bn.endTime,NOW())) < 60
;
between
between value1 and value2 (筛选出的条件中包括value1,但是不包括vaule2,也就是说
索引-理论篇
存储方式区分
- MySQL 索引可以从存储方式、逻辑角度和实际使用的角度来进行分类。
- 根据存储方式的不同,MySQL 中常用的索引在物理上分为 B-树索引和HASH索引两类,两种不同类型的索引各有其不同的适用范围。
B-树索引:BTREE
-
B-树索引又称为 BTREE 索引,目前大部分的索引都是采用 B-树索引来存储的。
-
B-树索引是一个典型的数据结构,其包含的组件主要有以下几个。
叶子节点:包含的条目直接指向表里的数据行。叶子节点之间彼此相连,一个叶子节点有一个指向下一个叶子节点的指针。
分支节点:包含的条目指向索引里其他的分支节点或者叶子节点。
根节点:一个 B-树索引只有一个根节点,实际上就是位于树的最顶端的分支节点。
基于这种树形数据结构,表中的每一行都会在索引上有一个对应值。因此,在表中进行数据查询时,可以根据索引值一步一步定位到数据所在的行。
B-树索引可以进行全键值、键值范围和键值前缀查询,也可以对查询结果进行 ORDER BY 排序。但 B-树索引必须遵循左边前缀原则,要考虑以下几点约束:
- 查询必须从索引的最左边的列开始。
- 查询不能跳过某一索引列,必须按照从左到右的顺序进行匹配。
- 存储引擎不能使用索引中范围条件右边的列。
哈希索引:Hash
-
哈希(Hash)一般翻译为“散列”,也有直接音译成“哈希”的,就是把任意长度的输入(又叫作预映射,pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。
-
哈希索引也称为散列索引或 HASH 索引。MySQL 目前仅有 MEMORY 存储引擎和 HEAP 存储引擎支持这类索引。其中,MEMORY 存储引擎可以支持 B-树索引和 HASH 索引,且将 HASH 当成默认索引。
-
HASH 索引不是基于树形的数据结构查找数据,而是根据索引列对应的哈希值的方法获取表的记录行。哈希索引的最大特点是访问速度快,但也存在下面的一些缺点:
- MySQL 需要读取表中索引列的值来参与散列计算,散列计算是一个比较耗时的操作。也就是说,相对于 B-树索引来说,建立哈希索引会耗费更多的时间。
- 不能使用 HASH 索引排序。
- HASH 索引只支持等值比较,如“=”“IN()”或“<=>”。
- HASH 索引不支持键的部分匹配,因为在计算 HASH 值的时候是通过整个索引值来计算的。
逻辑区分
根据索引的具体用途,MySQL 中的索引在逻辑上分为以下五类
- 普通索引:INDEX
- 唯一索引:UNIQUE
- 主键索引:PRIMARY KEY
- 空间索引:SPATIAL
- 全文索引:FULLTEXT
普通索引:INDEX
- 普通索引是 MySQL 中最基本的索引类型,它没有任何限制,唯一任务就是加快系统对数据的访问速度。
- 普通索引允许在定义索引的列中插入重复值和空值。
- 创建普通索引时,通常使用的关键字是 INDEX 或 KEY。
基本语法如下:
CREATE INDEX index_id
ON my_chihiro(id);
唯一索引:UNIQUE
-
唯一索引与普通索引类似,不同的是唯一索引不仅用于提高性能,而且还用于数据完整性,唯一索引不允许将任何重复的值插入表中
-
唯一索引列的值必须唯一,允许有空值。
-
如果是组合索引,则列值的组合必须唯一。
-
创建唯一索引通常使用 UNIQUE 关键字。
基本语法如下:
CREATE UNIQUE INDEX index_id
ON my_chihiro(id);
主键索引:PRIMARY KEY
- 主键索引就是专门为主键字段创建的索引,也属于索引的一种。
- 主键索引是一种特殊的唯一索引,不允许值重复或者值为空。
- 创建主键索引通常使用 PRIMARY KEY 关键字。不能使用 CREATE INDEX 语句创建主键索引。
空间索引:SPATIAL
- 空间索引是对空间数据类型的字段建立的索引,使用 SPATIAL 关键字进行扩展。
- 创建空间索引的列必须将其声明为 NOT NULL,空间索引只能在存储引擎为 MyISAM 的表中创建。
- 空间索引主要用于地理空间数据类型 GEOMETRY。
基本语法如下:my_chihiro 表的存储引擎必须是 MyISAM,line 字段必须为空间数据类型,而且是非空的。
CREATE SPATIAL INDEX index_line
ON my_chihiro(line);
全文索引:FULLTEXT
- 全文索引主要用来查找文本中的关键字,只能在 CHAR、VARCHAR 或 TEXT 类型的列上创建。在 MySQL 中只有 MyISAM 存储引擎支持全文索引。
- 全文索引允许在索引列中插入重复值和空值。
- 不过对于大容量的数据表,生成全文索引非常消耗时间和硬盘空间。
基本语法如下:index_info 的存储引擎必须是 MyISAM,info 字段必须是 CHAR、VARCHAR 和 TEXT。
CREATE FULLTEXT INDEX index_info
ON my_chihiro(info);
实际使用
在实际应用中,索引通常分为
- 单列索引
- 复合索引/多列索引/组合索引
单列索引
- 单列索引就是索引只包含原表的一个列。在表中的单个字段上创建索引,单列索引只根据该字段进行索引。
- 单列索引可以是普通索引,也可以是唯一性索引,还可以是全文索引。只要保证该索引只对应一个字段即可。
基本语法如下:address 字段的数据类型为 VARCHAR(20),索引的数据类型为 CHAR(6),查询时可以只查询 address 字段的前 6 个字符,而不需要全部查询。
CREATE INDEX index_addr
ON my_chihiro(address(6));
多列索引/复合索引
- 组合索引也称为复合索引或多列索引。
- 相对于单列索引来说,组合索引是将原表的多个列共同组成一个索引。
- 多列索引是在表的多个字段上创建一个索引。该索引指向创建时对应的多个字段,可以通过这几个字段进行查询。
- 注意只有查询条件中使用了这些字段中第一个字段时,索引才会被使用。
基本语法如下:索引创建好了以后,查询条件中必须有 name 字段才能使用索引
CREATE INDEX index_na
ON tb_student(name,address);
无论是创建单列索引还是复合索引,都应考虑在查询的WHERE子句中可能经常使用的列作为过滤条件。
如果仅使用一列,则应选择单列索引,如果在WHERE子句中经常使用两个或多个列作为过滤器,则复合索引将是最佳选择。 一个表可以有多个单列索引,但这些索引不是组合索引。
一个组合索引实质上为表的查询提供了多个索引,以此来加快查询速度。比如,在一个表中创建了一个组合索引(c1,c2,c3),在实际查询中,系统用来实际加速的索引有三个:单个索引(c1)、双列索引(c1,c2)和多列索引(c1,c2,c3)。
删除索引
DROP INDEX命令, 可以使用SQL DROP 命令删除索引,删除索引时应小心,因为性能可能会降低或提高。
基本语法如下:
DROP INDEX index_name;
索引-实践篇
增删查
添加索引
alter table chihiro_member_info add index idx_name (name);
查看索引
SHOW INDEX FROM chihiro_member_info;
删除索引
DROP INDEX <索引名> ON <表名>
DROP INDEX idx_name ON chihiro_member_info;
索引失效
有时候我们明明加了索引了,但是索引却不生效。在哪些场景,索引会不生效呢?主要有以下十大经典场景:
一、隐式的类型转换,索引失效
我们有一个索引,字段(name)类型为varchar字符串类型,如果查询条件传了一个数字去,会导致索引失效。
EXPLAIN SELECT * FROM chihiro_member_info WHERE name = 1;

如果给数字加上’',也就是说,传的是一个字符串,就正常走索引。
EXPLAIN SELECT * FROM chihiro_member_info WHERE name = 1;

分析:为什么第一条语句未加单引号就不走索引了呢?这是因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为浮点数再做比较。隐式的类型转换,索引会失效。
二、查询条件包含or,可能导致索引失效
我们在来看一条sql语句,name添加了索引,但是openid没有添加索引。我们使用or,下面的sql是不走索引的。
EXPLAIN SELECT * FROM chihiro_member_info WHERE name = "123" or openid = "123";

分析:对于
or+没有索引的openid这种情况,假设它走name的索引,但是走到openid查询条件时,它还得全表扫描,也就是需要三步过程:全表扫描+索引扫描+合并。如果它一开始就走全表扫描,直接一遍扫描就完事。Mysql优化器处于效率与成本考虑,遇到or条件,让索引失效。
当 name和role都是索引时,使用一张表中的多个索引时,mysql会将多个索引合并在一起。
EXPLAIN SELECT * FROM chihiro_member_info WHERE name = "123" or role = "123";

注意:如果
or条件的列都加了索引,**索引可能会走也可能不走,**大家可以自己试一试哈。但是平时大家使用的时候,还是要注意一下这个or,学会用explain分析。遇到不走索引的时候,考虑拆开两条SQL。
三、like通配符可能导致索引失效
并不是用了 like通配符索引一定会失效,而是 like查询是以 %开头,才会导致索引失效。
EXPLAIN SELECT * FROM chihiro_member_info WHERE name LIKE '%陈';

把 %放到后面,索引还是正常走的。
EXPLAIN SELECT * FROM chihiro_member_info WHERE name LIKE '陈%';
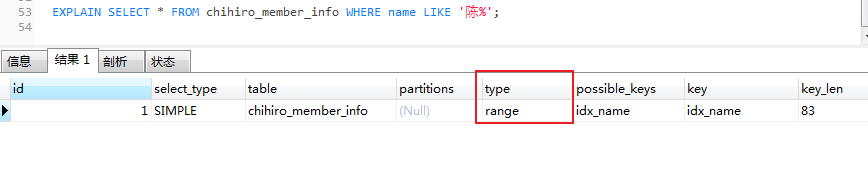
分析:既然
like查询以%开头,会导致索引失效。我们如何优化?
- 使用覆盖索。
- 把
%放后面。
四、查询条件不满足联合索引的最左匹配原则
Mysql建立联合索引时,会遵循左前缀匹配原则,既最左优先。如果你建立一个(a,b,c)的联合索引,相当于简历了(a)、(a,b)、(a,b,c)。
我们先添加一个联合索引:
alter table chihiro_member_info add index idx_name_role_openid (name,role,openid);
查看表的索引:
SHOW INDEX FROM chihiro_member_info;
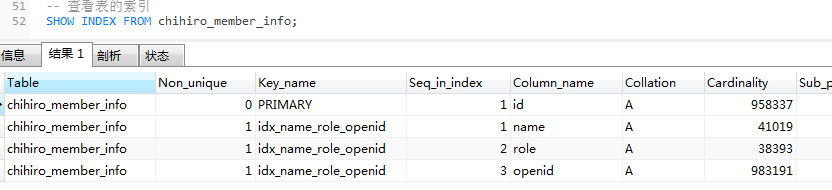
有一个联合索引idx_name_role_openid,我们执行这个SQL,查询条件是role,索引是无效:
EXPLAIN SELECT * FROM chihiro_member_info WHERE role = 0;

在联合索引中,查询条件满足最左匹配原则时,索引才正常生效。
EXPLAIN SELECT * FROM chihiro_member_info WHERE name = "刘";

五、在索引列上使用mysql的内置函数
我们先给创建时间添加一个索引。
ALTER TABLE chihiro_member_info ADD INDEX idx_create_time(create_time);
虽然create_time加了索引,但是因为使用了mysql的内置函数DATE_ADD(),导致直接全表扫描了。
EXPLAIN SELECT * FROM chihiro_member_info WHERE DATE_ADD(create_time,INTERVAL 1 DAY) = '2022-10-10 00:00:00';

分析:一般这种情况怎么优化呢?可以把**内置函数的逻辑转移到右边,**如下:
EXPLAIN SELECT * FROM chihiro_member_info WHERE create_time = DATE_ADD('2022-10-10 00:00:00',INTERVAL -1 DAY);

六、对索引进行列运算(如,+、-、*、/),索引不生效
给 role字段(tinyint)添加一个索引。
-- 添加索引
ALTER TABLE chihiro_member_info ADD INDEX idex_role(role);
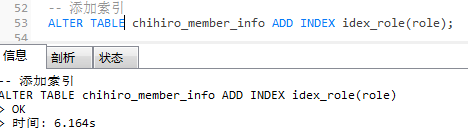
虽然role加了索引,但是因为它进行运算,索引直接迷路了。如图:
EXPLAIN SELECT * FROM chihiro_member_info WHERE role+1 = 1;

分析:不可以对索引列进行运算,可以在代码处理好,再传参进去。
七、索引字段上使用(!= 或者 < >),索引可能失效
给 role字段(tinyint)添加一个索引。
-- 添加索引
ALTER TABLE chihiro_member_info ADD INDEX idex_role(role);
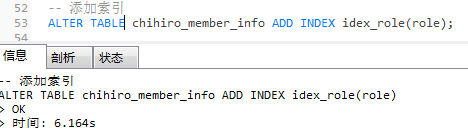
注意:我在mysql 5.7.26测试,测试结果有所不同,可以根据mysql版本去测试。
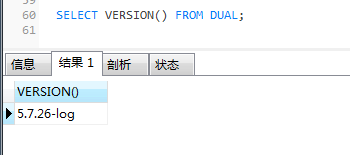
查看mysql版本
SELECT VERSION() FROM DUAL;
!=:正常走的索引。
EXPLAIN SELECT * FROM chihiro_member_info WHERE role != 2;

<>:正常走的索引。
EXPLAIN SELECT * FROM chihiro_member_info WHERE role <> 2;

分析:其实这个也是跟mySQL优化器有关,如果优化器觉得即使走了索引,还是需要扫描很多很多行的哈,它觉得不划算,**不如直接不走索引。**平时我们用
!=或者< >,not in的时候,可以先使用EXPLAIN去看看索引是否生效。
八、索引字段上使用is null, is not null,索引可能失效
给 role字段(tinyint)添加一个索引和 name字段(varchar)添加索引。
-- 添加索引
ALTER TABLE chihiro_member_info ADD INDEX idex_role(role);
ALTER TABLE chihiro_member_info ADD INDEX idex_name(name);
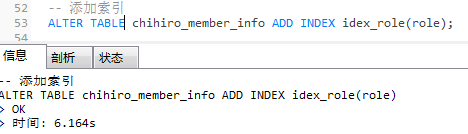
单个字段 role字段加上索引,查询 role 为空的语句,会走索引:
EXPLAIN SELECT * FROM chihiro_member_info WHERE role is not null;

两字字段用 or链接起来,索引就失效了。

分析:很多时候,也是因为数据量问题,导致了MySQL优化器放弃走索引。同时,平时我们用
explain分析SQL的时候,如果type=range,需要注意一下,因为这个可能因为数据量问题,导致索引无效。
九、左右连接,关联的字段编码格式不一样
新建两个表,一个user,一个user_job:
CREATE TABLE `user` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL,`age` int(11) NOT NULL,PRIMARY KEY (`id`),KEY `idx_name` (`name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;CREATE TABLE `user_job` (`id` int(11) NOT NULL,`userId` int(11) NOT NULL,`job` varchar(255) DEFAULT NULL,`name` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_name` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
user表的name字段编码是utf8mb4,而user_job表的name字段编码为utf8。
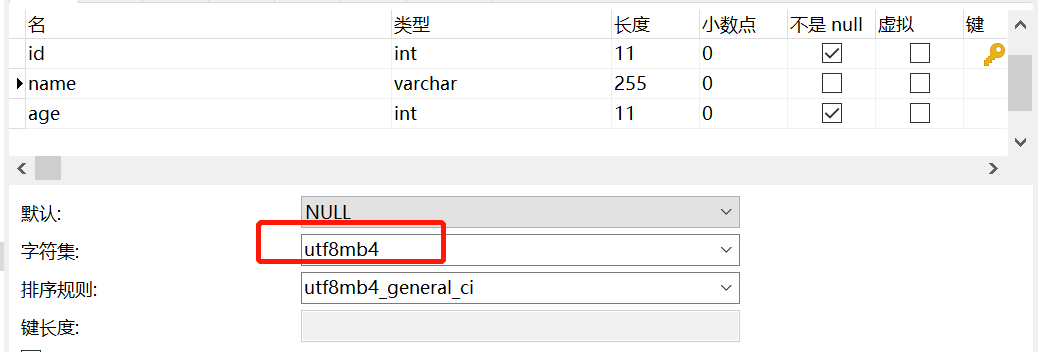
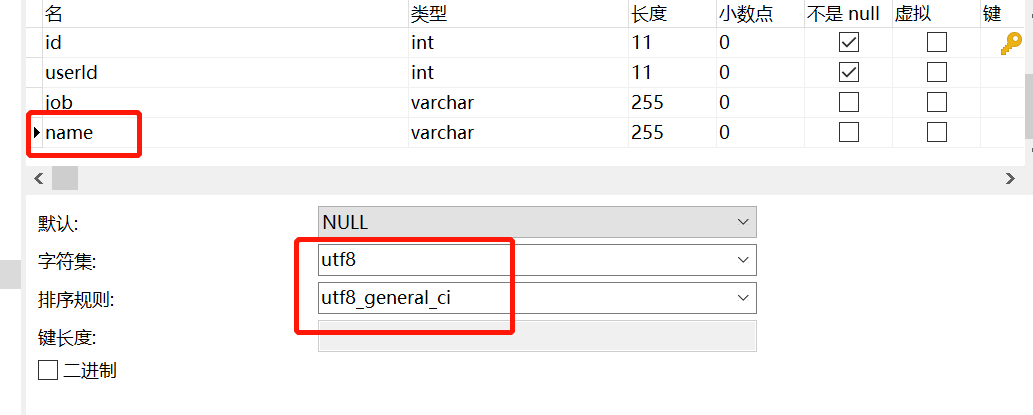
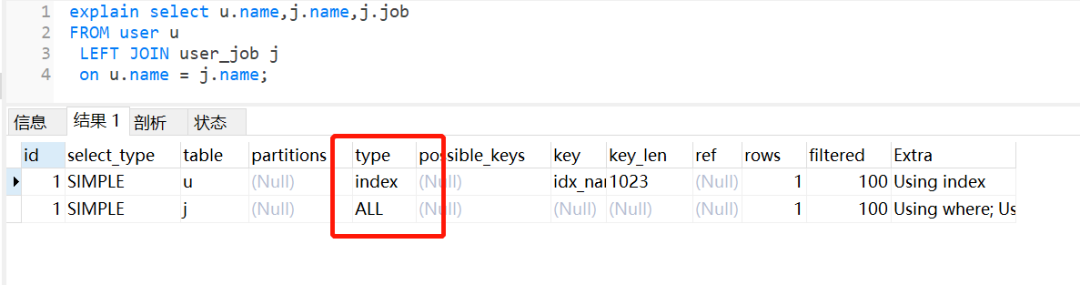
执行左外连接查询,user_job表还是走全表扫描。
如果把它们的name字段改为编码一致,相同的SQL,还是会走索引。
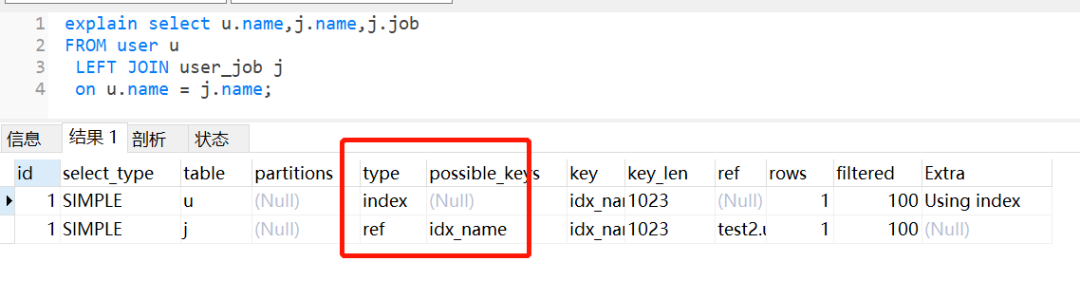
分析:所以大家在做表关联时,注意一下关联字段的编码问题。
十、优化器选错了索引
MySQL 中一张表是可以支持多个索引的。你写SQL语句的时候,没有主动指定使用哪个索引的话,用哪个索引是由MySQL来确定的。
我们日常开发中,不断地删除历史数据和新增数据的场景,有可能会导致MySQL选错索引。那么有哪些解决方案呢?
- 使用force index 强行选择某个索引;
- 修改你的SQl,引导它使用我们期望的索引;
- 优化你的业务逻辑;
- 优化你的索引,新建一个更合适的索引,或者删除误用的索引。
3.3 索引速度对比
测试数据量量400万,字段包含:id、username、password
-- 数据量量400万,字段包含:id、username、password-- 没有索引下查询
SELECT * FROM key_value;select * from key_value WHERE username = '测试用户388888'
-- > OK
-- > 时间: 1.496sselect * from key_value WHERE username = '测试用户388888'
-- > OK
-- > 时间: 1.503sselect * from key_value WHERE username = '测试用户388888'
-- > OK
-- > 时间: 1.475s-- 创建索引后:
SELECT * from key_value WHERE username = '测试用户388888';SELECT * from key_value WHERE username = '测试用户388888'
-- > OK
-- > 时间: 0.005sSELECT * from key_value WHERE username = '测试用户3588828';
-- > OK
-- > 时间: 0.005s-- 测试查找主键id
-- 主键也是有索引的是,所以非常快
SELECT * from key_value WHERE id = 123333;
-- > OK
-- > 时间: 0.004s
相关文章:
【SQL】MySQL秘籍
chihiro-notes 千寻简笔记 v0.1 内测版 📔 笔记介绍 大家好,千寻简笔记是一套全部开源的企业开发问题记录,毫无保留给个人及企业免费使用,我是作者星辰,笔记内容整理并发布,内容有误请指出,笔…...
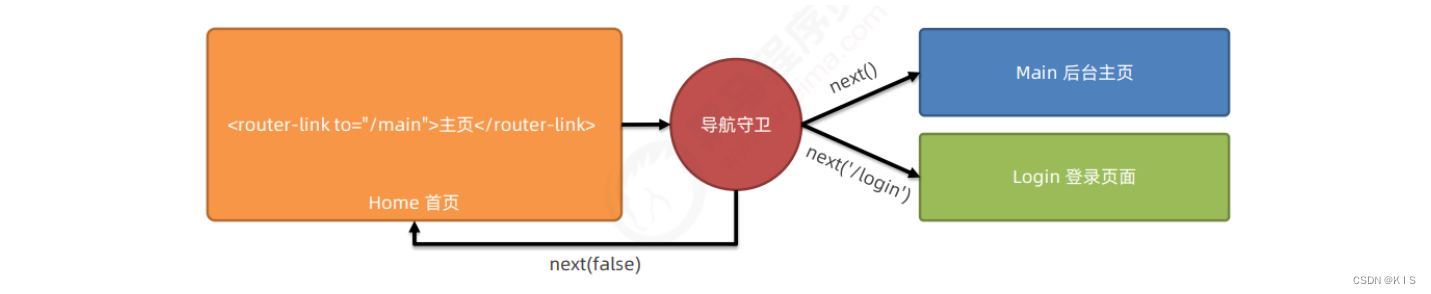
vue-router 的基本用法
vue-router 的基本用法 1.什么是 vue-router vue-router 是 vue.js 官方给出的路由解决方案。它只能结合 vue 项目进行使用,能够轻松的管理 SPA 项目中组件的切换。 vue-router 的官方文档地址:https://router.vuejs.org/zh/ 2.vue-router 安装和配置的…...

图像显著性目标检测
一、概述 1、定义 图像显著性检测(Saliency Detection,SD), 指通过智能算法模拟人的视觉系统特点,预测人类的视觉凝视点和眼动,提取图像中的显著区域(即人类感兴趣的区域),可以广泛用于目标识别、图像编辑以及图像检索等领域&am…...

力扣-查找重复的电子邮箱
大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。 文章目录前言一、题目:182. 查找重复的电子邮箱二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交SQL运行结果总结…...

如何选择正规可靠的ISO认证机构?
ISO认证其实早已融入我们生活中,因为日常生活很多产品都有认证标识,企业办理ISO体系就需要找第三方认证公司,市面上这种公司也有不少,但找到合适可靠、认真负责的还是不易,尤其是体系认证有年审,如何留住客…...

React源码解读之更新的创建
React 的鲜活生命起源于 ReactDOM.render ,这个过程会为它的一生储备好很多必需品,我们顺着这个线索,一探婴儿般 React 应用诞生之初的悦然。 更新创建的操作我们总结为以下两种场景 ReactDOM.rendersetStateforceUpdate ReactDom.render …...
【程序人生】从土木专员到网易测试工程师,薪资翻3倍,他经历了什么?
转行对于很多人来说,是一件艰难而又纠结的事情,或许缺乏勇气,或许缺乏魄力,或许内心深处不愿打破平衡。可对于我来说,转行是一件不可不为的事情,因为那意味着新的方向、新的希望。我是学工程管理的…...

C++——C++11第二篇
目录 可变参数模板 lambda表达式 lambda表达式语法 捕获列表说明 可变参数模板 可变参数:可以有0到n个参数,如之前学过的 Printf C11的新特性可变参数模板能够让您创建可以接受可变参数的函数模板和类模板 模板参数包 // Args是一个模板参数包&…...

14.最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 ""。示例 1:输入:strs ["flower","flow","flight"]输出:"fl"示例 2:输入&…...

【免费教程】 SWMM在城市水环境治理中的应用及案例分析
SWMMSWMM(storm water management model,暴雨洪水管理模型)是一个动态的降水-径流模拟模型,主要用于模拟城市某一单一降水事件或长期的水量和水质模拟。EPA(Environmental Protection Agency,环境保护署&am…...

SortableJS/Sortable拖拽组件,使用详细(Sortablejs安装使用)
简述 作为一名前端开发人员,在工作中难免会遇到拖拽功能,分享一个github上一个不错的拖拽js库,能满足我们在项目开发中的需要,支持Vue和React,下面是SortableJS的使用详细; 这个是sortableJS中文官方文档&…...

Heartbeat+Nginx实验
HeartbeatNginx实验 Heartbeat是什么? Heartbeat是 Linux-HA 工程的一个组件,自1999 年开始到现在,发布了众多版本,是目前开源 Linux-HA项 目成功的一个例子,在行业内得到了广泛的应用 构建规划: 两台后…...
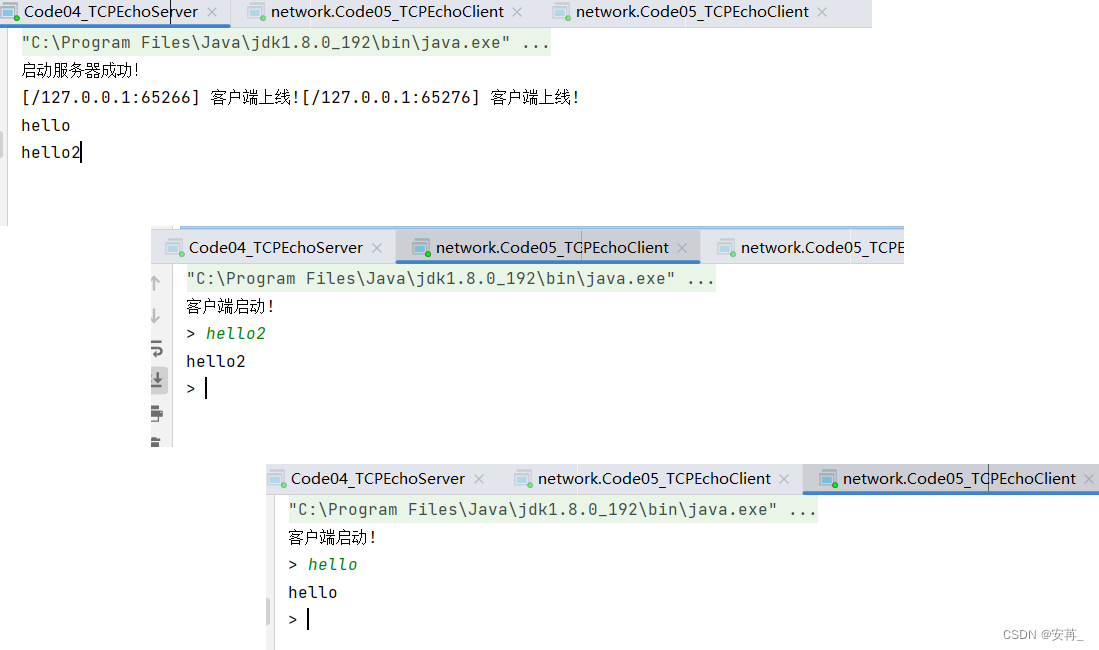
JavaEE|网络编程之套接字 TCP
文章目录一、ServerSocket API构造方法常用方法二、Socket API构造方法常用方法注意事项三、TCP中的长短连接E1:一发一收(短连接)E2:请求响应(短连接)E3:多线程下的TCP回响服务器说明:这部分说实话有点懵&a…...

Robot Framework自动化测试---元素定位
不要误认为Robot framework 只是个web UI测试工具,更正确的理解Robot framework是个测试框架,之所以可以拿来做web UI层的自动化是国为我们加入了selenium2的API。比如笔者所处工作中,更多的是拿Robot framework来做数据库的接口测试…...

ASP.NET Core中的路由
传统路由 app.MapControllerRoute( name: "default", pattern: "{controllerHome}/{actionIndex}/{id?}"); MapControllerRoute用于创建单个路由。 单个路由命名为 default 路由 。大多数具有控制器和视图的应用都使用类似 default 路由的路由模板。 之所…...

VBA提高篇_26 Textbox多行_ListBox_ComboBox
文章目录1. 文本框多行换行2. ListBox: 列表框2.1 列表框中添加条目的三种方法:3. ComboBox 组合框: 属性方法等同于以上ListBox1. 文本框多行换行 MultiLine: 控制文本框多行自动换行() Enterkeybehevior: True 代表允许在文本框中使用回车键换行 WordWrap: True 代表自动换…...
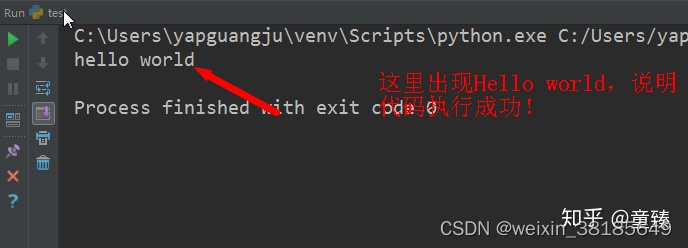
python环境配置
python环境配置一、ADB环境配置1、ADB下载路径:2、点击下载3、解压并放到本地磁盘4、配置ADB环境变量二、Python环境配置1、Python下载路径:2、点击下载(默认下载最新的)3、解压并放到本地磁盘4、配置Python环境变量5、配置pip环境变量三、Pycharm安装1、pycharm下载路径:2、点…...
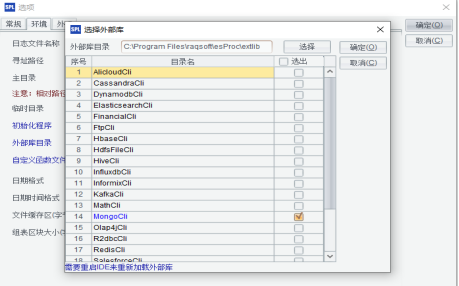
集算器连接外部库
1. 配置jar包将以下jar包从报表的类路径(【安装根目录】\report\lib或【安装根目录】\report\web\webapps\demo\WEB-INF\lib)中拷贝到集算器目录(【安装根目录】\esProc\ extlib\mongoCli);润乾外部库核心jar为:scu-mo…...
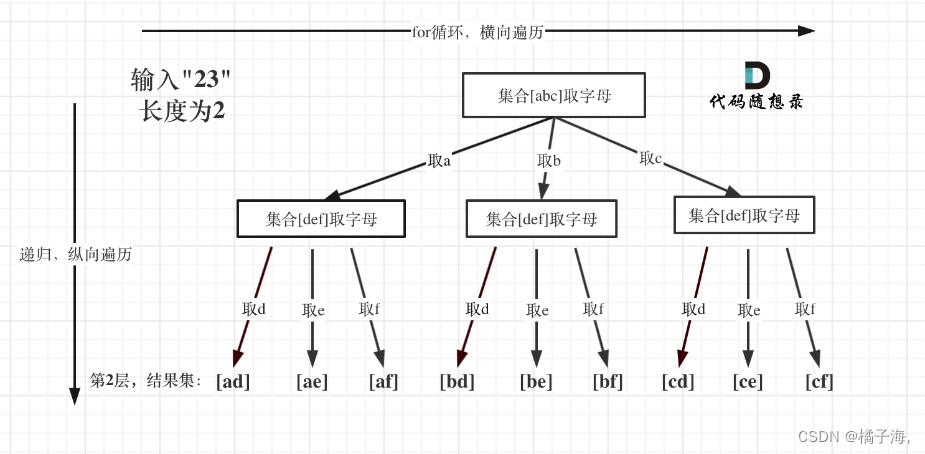
力扣刷题|216.组合总和 III、17.电话号码的字母组合
文章目录LeetCode 216.组合总和题目链接🔗思路LeetCode 17.电话号码的字母组合题目链接🔗思路LeetCode 216.组合总和 题目链接🔗 LeetCode 216.组合总和 思路 本题就是在[1,2,3,4,5,6,7,8,9]这个集合中找到和为n的k个数的组合。 相对于7…...
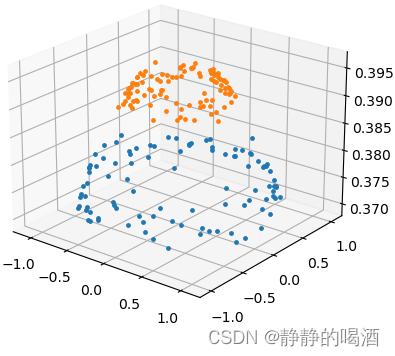
机器学习笔记之谱聚类(一)k-Means聚类算法介绍
机器学习笔记之谱聚类——K-Means聚类算法介绍引言回顾:高斯混合模型聚类任务基本介绍距离计算k-Means\text{k-Means}k-Means算法介绍k-Means\text{k-Means}k-Means算法示例k-Means\text{k-Means}k-Means算法与高斯混合模型的关系k-Means\text{k-Means}k-Means算法的…...

2026届学术党必备的十大降重复率工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下,各种各样的降AI工具纷纷出现,其关键功能是借助文本改写、句式重…...
)
SEO_从零开始构建可持续的SEO优化体系(468 )
SEO从零开始:构建可持续的SEO优化体系 在互联网时代,搜索引擎优化(SEO)已经成为每一个网站拥有良好流量和知名度的关键。特别是在百度这样的大型搜索引擎上,一个良好的SEO优化体系不仅能提高网站的排名,还…...

电机速度计算
1. M法计算速度值详解:原理、公式与应用 概述 M法,也称为频率测量法,是一种通过在固定时间内统计脉冲数量来计算速度的常用方法。这种方法特别适用于中高速运动的测量场景,在电机控制、编码器测速等领域有着广泛的应用。 …...

ATtiny85轻量级图形库应用与优化
1. Tiny Graphics Library:ATtiny85上的轻量级图形解决方案在嵌入式开发中,为资源受限的MCU添加图形显示功能一直是个挑战。今天我要分享的是一个特别适合ATtiny85等低资源处理器的图形库——Tiny Graphics Library。这个库最大的特点就是完全不需要显示…...

C语言函数指针与回调函数实战指南
1. 函数指针:C语言的瑞士军刀在C语言的世界里,指针堪称是这门语言的灵魂所在。我们熟悉整型指针、字符指针、结构体指针,但函数指针这个强大的工具却常常被开发者忽视。实际上,函数指针是理解回调函数的基础,也是实现C…...

Kali 2025.4上部署HexStrike AI踩坑实录:从MCP连接失败到完美运行的完整排错指南
Kali 2025.4上部署HexStrike AI踩坑实录:从MCP连接失败到完美运行的完整排错指南 HexStrike AI作为新一代AI驱动的渗透测试框架,理论上只需几条命令就能完成部署。但现实往往比文档复杂得多——特别是当你在深夜赶项目,却发现MCP客户端死活连…...

3个创新维度破解直播回放获取难题:douyin-downloader深度解构与实战指南
3个创新维度破解直播回放获取难题:douyin-downloader深度解构与实战指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and brows…...

Java SpringBoot+Vue3+MyBatis 图书进销存管理系统系统源码|前后端分离+MySQL数据库
摘要 随着信息技术的快速发展,传统图书进销存管理方式逐渐暴露出效率低下、数据冗余和人工操作繁琐等问题。图书行业对高效、精准的管理系统需求日益增长,尤其在库存管理、销售统计和数据分析方面,亟需一套智能化解决方案。基于前后端分离架构…...

构建高性能WebSocket聊天应用:libwebsockets实战指南
构建高性能WebSocket聊天应用:libwebsockets实战指南 【免费下载链接】libwebsockets canonical libwebsockets.org networking library 项目地址: https://gitcode.com/gh_mirrors/li/libwebsockets Libwebsockets是一个简单易用、MIT许可证、纯C语言编写的…...

SQLMesh表对比功能:如何在开发和生产环境间进行数据差异分析
SQLMesh表对比功能:如何在开发和生产环境间进行数据差异分析 【免费下载链接】sqlmesh Scalable and efficient data transformation framework - backwards compatible with dbt. 项目地址: https://gitcode.com/gh_mirrors/sq/sqlmesh SQLMesh的表对比功能…...