pytorch基于ray和accelerate实现多GPU数据并行的模型加速训练
在pytorch的DDP原生代码使用的基础上,ray和accelerate两个库对于pytorch并行训练的代码使用做了更加友好的封装。
以下为极简的代码示例。
ray
ray.py
#coding=utf-8
import os
import sys
import time
import numpy as np
import torch
from torch import nn
import torch.utils.data as Data
import ray
from ray.train.torch import TorchTrainer
from ray.air.config import ScalingConfig
import onnxruntime# bellow code use AI model to simulate linear regression, formula is: y = x1 * w1 + x2 * w2 + b
# --- DDP RAY --- # # model structure
class LinearNet(nn.Module):def __init__(self, n_feature):super(LinearNet, self).__init__()self.linear = nn.Linear(n_feature, 1)def forward(self, x):y = self.linear(x)return y# whole train task
def train_task():print("--- train_task, pid: ", os.getpid())# device settingdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("device:", device)device_ids = torch._utils._get_all_device_indices()print("device_ids:", device_ids)if len(device_ids) <= 0:print("invalid device_ids, exit")return# prepare datanum_inputs = 2num_examples = 1000true_w = [2, -3.5]true_b = 3.7features = torch.tensor(np.random.normal(0, 1, (num_examples, num_inputs)), dtype=torch.float)labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b + torch.tensor(np.random.normal(0, 0.01, size=num_examples), dtype=torch.float)# load databatch_size = 10dataset = Data.TensorDataset(features, labels)data_iter = Data.DataLoader(dataset, batch_size, shuffle=True)for X, y in data_iter:print(X, y)breakdata_iter = ray.train.torch.prepare_data_loader(data_iter)# model define and initmodel = LinearNet(num_inputs)ddp_model = ray.train.torch.prepare_model(model)print(ddp_model)# cost functionloss = nn.MSELoss()# optimizeroptimizer = torch.optim.SGD(ddp_model.parameters(), lr=0.03)# trainnum_epochs = 6for epoch in range(1, num_epochs + 1):batch_count = 0sum_loss = 0.0for X, y in data_iter:output = ddp_model(X)l = loss(output, y.view(-1, 1))optimizer.zero_grad()l.backward()optimizer.step()batch_count += 1sum_loss += l.item()print('epoch %d, avg_loss: %f' % (epoch, sum_loss / batch_count))# save modelprint("save model, pid: ", os.getpid())torch.save(ddp_model.module.state_dict(), "ddp_ray_model.pt")def ray_launch_task():num_workers = 2scaling_config = ScalingConfig(num_workers=num_workers, use_gpu=True)trainer = TorchTrainer(train_loop_per_worker=train_task, scaling_config=scaling_config)results = trainer.fit()def predict_task():print("--- predict_task")# prepare datanum_inputs = 2num_examples = 20true_w = [2, -3.5]true_b = 3.7features = torch.tensor(np.random.normal(0, 1, (num_examples, num_inputs)), dtype=torch.float)labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b + torch.tensor(np.random.normal(0, 0.01, size=num_examples), dtype=torch.float)model = LinearNet(num_inputs)model.load_state_dict(torch.load("ddp_ray_model.pt"))model.eval()x, y = features[6], labels[6]pred_y = model(x)print("x:", x)print("y:", y)print("pred_y:", y)if __name__ == "__main__":print("==== task begin ====")print("python version:", sys.version)print("torch version:", torch.__version__)print("model name:", LinearNet.__name__)ray_launch_task()# predict_task()print("==== task end ====")accelerate
acc.py
#coding=utf-8
import os
import sys
import time
import numpy as np
from accelerate import Accelerator
import torch
from torch import nn
import torch.utils.data as Data
import onnxruntime# bellow code use AI model to simulate linear regression, formula is: y = x1 * w1 + x2 * w2 + b
# --- accelerate --- # # model structure
class LinearNet(nn.Module):def __init__(self, n_feature):super(LinearNet, self).__init__()self.linear = nn.Linear(n_feature, 1)def forward(self, x):y = self.linear(x)return y# whole train task
def train_task():print("--- train_task, pid: ", os.getpid())# device settingdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("device:", device)device_ids = torch._utils._get_all_device_indices()print("device_ids:", device_ids)if len(device_ids) <= 0:print("invalid device_ids, exit")return# prepare datanum_inputs = 2num_examples = 1000true_w = [2, -3.5]true_b = 3.7features = torch.tensor(np.random.normal(0, 1, (num_examples, num_inputs)), dtype=torch.float)labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b + torch.tensor(np.random.normal(0, 0.01, size=num_examples), dtype=torch.float)# load databatch_size = 10dataset = Data.TensorDataset(features, labels)data_iter = Data.DataLoader(dataset, batch_size, shuffle=True)for X, y in data_iter:print(X, y)break# model define and initmodel = LinearNet(num_inputs)# cost functionloss = nn.MSELoss()# optimizeroptimizer = torch.optim.SGD(model.parameters(), lr=0.03)accelerator = Accelerator()model, optimizer, data_iter = accelerator.prepare(model, optimizer, data_iter) # automatically move model and data to gpu as config# trainnum_epochs = 3for epoch in range(1, num_epochs + 1):batch_count = 0sum_loss = 0.0for X, y in data_iter:output = model(X)l = loss(output, y.view(-1, 1))optimizer.zero_grad()accelerator.backward(l)optimizer.step()batch_count += 1sum_loss += l.item()print('epoch %d, avg_loss: %f' % (epoch, sum_loss / batch_count))# save modeltorch.save(model, "acc_model.pt")def predict_task():print("--- predict_task")# prepare datanum_inputs = 2num_examples = 20true_w = [2, -3.5]true_b = 3.7features = torch.tensor(np.random.normal(0, 1, (num_examples, num_inputs)), dtype=torch.float)labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b + torch.tensor(np.random.normal(0, 0.01, size=num_examples), dtype=torch.float)model = torch.load("acc_model.pt")model.eval()x, y = features[6], labels[6]pred_y = model(x)print("x:", x)print("y:", y)print("pred_y:", y)if __name__ == "__main__":# launch method: use command line# for example# accelerate launch ACC.py print("python version:", sys.version)print("torch version:", torch.__version__)print("model name:", LinearNet.__name__)train_task()predict_task()print("==== task end ====")相关文章:

pytorch基于ray和accelerate实现多GPU数据并行的模型加速训练
在pytorch的DDP原生代码使用的基础上,ray和accelerate两个库对于pytorch并行训练的代码使用做了更加友好的封装。 以下为极简的代码示例。 ray ray.py #codingutf-8 import os import sys import time import numpy as np import torch from torch import nn im…...
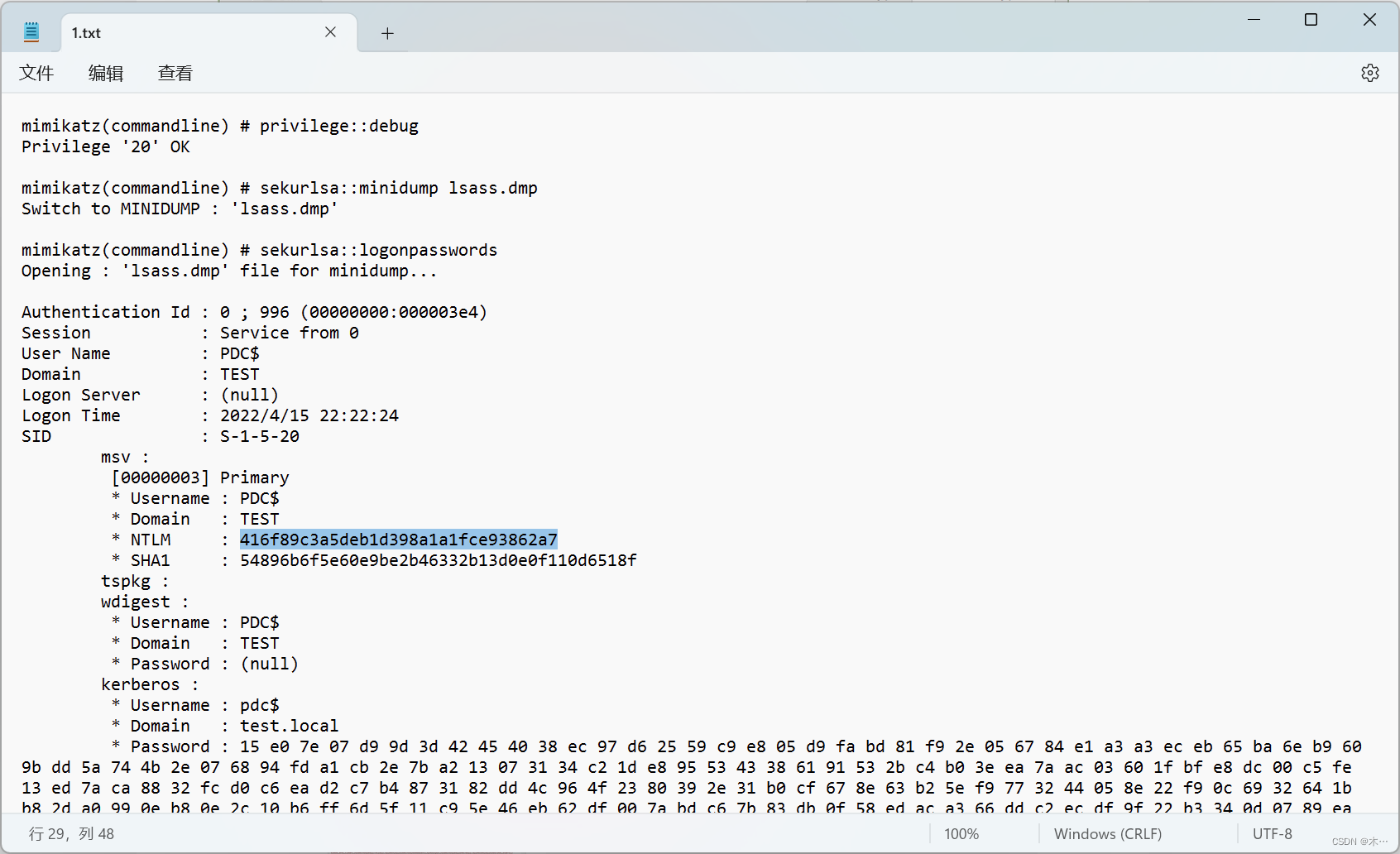
[蓝帽杯 2022 初赛]domainhacker
打开流量包,追踪TCP流,看到一串url编码 放到瑞士军刀里面解密 最下面这一串会觉得像base64编码 删掉前面两个字符就可以base64解码 依次类推,提取到第13个流,得到一串编码其中里面有密码 导出http对象 发现最后有个1.rar文件 不出…...

在 Pytorch 中使用 TensorBoard
机器学习的训练过程中会产生各类数据,包括 “标量scalar”、“图像image”、“统计图diagram”、“视频video”、“音频audio”、“文本text”、“嵌入Embedding” 等等。为了更好地追踪和分析这些数据,许多可视化工具应运而生,比如之前介绍的…...

Grafana Dashboard 备份方案
文章目录 Grafana Dashboard 备份方案引言工具简介支持的组件要求配置备份安装使用 pypi 安装grafana备份工具配置环境变量使用Grafana Backup Tool 进行备份恢复备份 Grafana Dashboard恢复 Grafana Dashboard结论Grafana Dashboard 备份方案 引言 每个使用 Grafana 的同学都…...

opencv-疲劳检测-眨眼检测
#导入工具包 from scipy.spatial import distance as dist from collections import OrderedDict import numpy as np import argparse import time import dlib import cv2FACIAL_LANDMARKS_68_IDXS OrderedDict([("mouth", (48, 68)),("right_eyebrow",…...

2023-08-24力扣每日一题
链接: 1267. 统计参与通信的服务器 题意: 同行同列可以发生通信,求能发生通信的机器数量 解: 标记每行/每列的机器个数即可 实际代码: #include<bits/stdc.h> using namespace std; class Solution { pub…...

蚂蚁数科持续发力PaaS领域,SOFAStack布局全栈软件供应链安全产品
8月18日,记者了解到,蚂蚁数科再度加码云原生PaaS领域,SOFAStack率先完成全栈软件供应链安全产品及解决方案的布局,包括静态代码扫描Pinpoint、软件成分分析SCA、交互式安全测试IAST、运行时防护RASP、安全洞察Appinsight等&#x…...

Java后端开发面试题——消息中间篇
RabbitMQ-如何保证消息不丢失 交换机持久化: Bean public DirectExchange simpleExchange(){// 三个参数:交换机名称、是否持久化、当没有queue与其绑定时是否自动删除 return new DirectExchange("simple.direct", true, false); }队列持久化…...

C++ Windows API IsDebuggerPresent的作用
IsDebuggerPresent 是 Windows API 中的一个函数,它用于检测当前运行的程序是否正在被调试。当程序被如 Visual Studio 这样的调试器附加时,此函数会返回 TRUE;否则,它会返回 FALSE。 这个函数经常被用在一些安全相关的场景或是防…...

【JVM 内存结构 | 程序计数器】
内存结构 前言简介程序计数器定义作用特点示例应用场景 主页传送门:📀 传送 前言 Java 虚拟机的内存空间由 堆、栈、方法区、程序计数器和本地方法栈五部分组成。 简介 JVM(Java Virtual Machine)内存结构包括以下几个部分&#…...
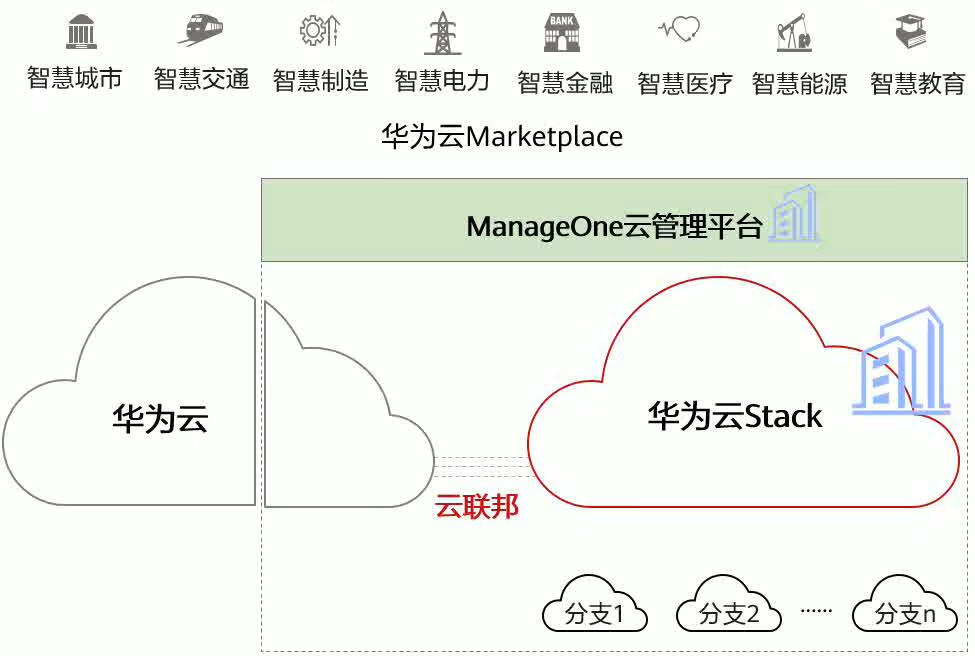
华为云Stack的学习(一)
一、华为云Stack架构 1.HCS 物理分散、逻辑统一、业务驱动、运管协同、业务感知 2.华为云Stack的特点 可靠性 包括整体可靠性、数据可靠性和单一设备可靠性。通过云平台的分布式架构,从整体系统上提高可靠性,降低系统对单设备可靠性的要求。 可用性…...

人类反馈强化学习RLHF;微软应用商店推出AI摘要功能
🦉 AI新闻 🚀 微软应用商店推出AI摘要功能,快速总结用户对App的评价 摘要:微软应用商店正式推出了AI摘要功能,该功能能够将数千条在线评论总结成一段精练的文字,为用户选择和下载新应用和游戏提供参考。该…...

day1:前端缓存问题
❝ 「目标」: 持续输出!每日分享关于web前端常见知识、面试题、性能优化、新技术等方面的内容。篇幅不会过长,方便理解和记忆。 ❞ ❝ 「主要面向群体:」前端开发工程师(初、中、高级)、应届、转行、培训等同学 ❞ Day…...
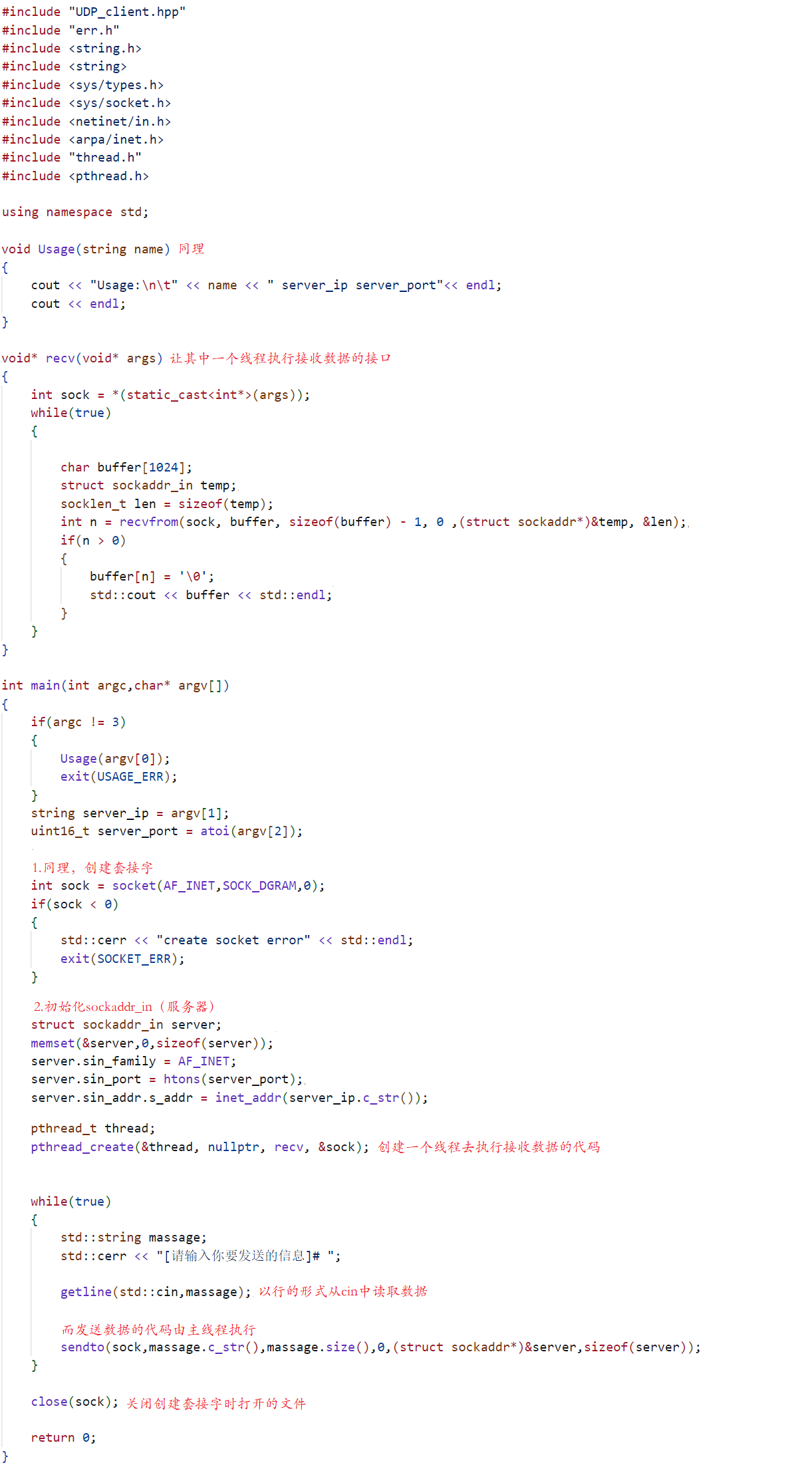
学习网络编程No.4【socket编程实战】
引言 北京时间:2023/8/19/23:01,耍了好几天,主要归咎于《我欲封天》这本小说,听了几个晚上之后逐渐入门,在闲暇时间又看了一下,小高潮直接来临,最终在三个昼夜下追完了,哈哈哈&…...
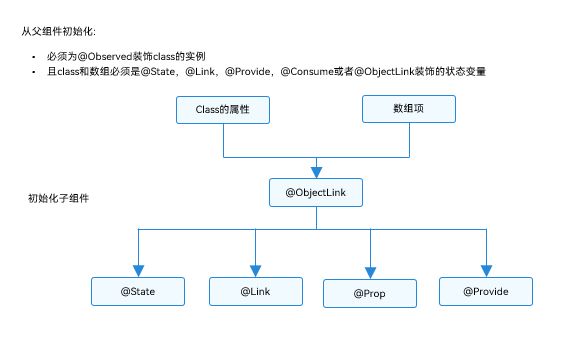
HarmonyOS学习路之方舟开发框架—学习ArkTS语言(状态管理 四)
Observed装饰器和ObjectLink装饰器:嵌套类对象属性变化 上文所述的装饰器仅能观察到第一层的变化,但是在实际应用开发中,应用会根据开发需要,封装自己的数据模型。对于多层嵌套的情况,比如二维数组,或者数…...

arcgis--坐标系
1、arcgis中,投影坐标系的y坐标一定是7位数,X坐标有两种:6位和8位。 6位:省略带号,这是中央经线形式的投影坐标,一般投影坐标中会带CM字样;8位:包括带号,一般投影坐标中…...
)
LFS学习系列 第5章. 编译交叉工具链(1)
5.1 介绍 本章介绍如何构建交叉编译器及其相关工具。尽管这里的交叉编译是“伪造”、“假装”的,但其原理与真正的交叉工具链相同。 本章中编译的程序将安装在$LFS/tools目录下,以使它们与以下章节中安装的文件分离。而另一方面,库被安装到…...
网络互联与互联网 - TCP 协议详解
文章目录 1 概述2 TCP 传输控制协议2.1 报文格式2.2 三次握手,建立连接2.3 四次挥手,释放连接 3 扩展3.1 实验演示3.2 网工软考 1 概述 在 TCP/IP 协议簇 中有两个传输协议 TCP:Transmission Control Protocol,传输控制协议&…...
开源在线图片设计器,支持PSD解析、AI抠图等,基于Puppeteer生成图片
Github 开源地址: palxiao/poster-design 项目速览 git clone https://github.com/palxiao/poster-design.git cd poster-design npm run prepared # 快捷安装依赖指令 npm run serve # 本地运行将同时运行前端界面与图片生成服务(3000与7001端口),合成图片时…...
在Linux系统上安装和配置Redis数据库,无需公网IP即可实现远程连接的详细解析
文章目录 1. Linux(centos8)安装redis数据库2. 配置redis数据库3. 内网穿透3.1 安装cpolar内网穿透3.2 创建隧道映射本地端口 4. 配置固定TCP端口地址4.1 保留一个固定tcp地址4.2 配置固定TCP地址4.3 使用固定的tcp地址连接 Redis作为一款高速缓存的key value键值对的数据库,在…...

电容触摸传感与微控制器互动:打造万圣节智能蝙蝠装饰
1. 项目概述:当电容触摸遇上万圣节蝙蝠又到了一年一度可以名正言顺“吓唬人”的季节。每年万圣节,除了南瓜灯和糖果,我总想搞点不一样的、能和人互动的装饰。市面上的那些一动就吱呀乱叫的塑料道具,总觉得少了点灵魂和“技术含量”…...

职场新人不会写自我介绍?3分钟AI生成直接拿面试
刚步入职场的新人,写简历是不是最怕碰到“自我评价”或“自我介绍”这一栏?盯着空白屏幕憋了一下午,最后只能干巴巴地敲下“性格开朗、吃苦耐劳、具有团队合作精神”这种假大空的话。好不容易搞定简历投递出去,结果总是石沉大海&a…...

【信息科学与工程学】【物理/化学科学和工程技术】知识体系 第四十一篇 数据中心基础设施领域中的力学知识 01
编号:001 类别 结构力学 (静力学与动力学) 领域 计算基础设施 / 机房设施 力学模型配方 将服务器机架简化为一个底部固定、顶部自由的悬臂梁模型。在地震激励下,该模型转化为一个单自由度阻尼受迫振动系统。主要考虑水平方向的地震力作用。 数学分析 通过建立运动微分…...

SC4541SKTRT 2MHz 2.9V~22V升/降压单线LED驱动器Semtech电子元器件IC芯片
SC4541SKTRT是Semtech(升特)推出的高频LED驱动器芯片,该器件集升压与降压拓扑于一体,支持2.9V至22V超宽输入电压并具备25V输出电压能力,利用内置肖特基二极管和功率开关,将外部电路减至最少,实现…...

RocketMQ 源码解析——Controller 高可用切换架构
延伸阅读:🔍「RocketMQ 中文社区」 持续更新源码解析/最佳实践,提供 RocketMQ 专家 AI 答疑服务 一、原理及核心概念浅述 1.1 核心架构 1.2 核心概念 controller:负责管理broker间的主备关系,可以挂在namesrv中&…...

【免费下载】 PyTorch框架入门PPT下载
PyTorch框架入门PPT下载 【下载地址】PyTorch框架入门PPT下载 PyTorch框架入门PPT下载 项目地址: https://gitcode.com/open-source-toolkit/a64b8 资源介绍 本仓库提供了一个名为“PyTorch框架入门PPT”的资源文件下载。该PPT文件旨在帮助初学者快速入门PyTorch框架&a…...
:图灵的答案)
从沙子到车辙(1.3):图灵的答案
1.3 图灵的答案 那个跑步穿过剑桥的人 1935 年,剑桥大学国王学院。一个 23 岁的研究生躺在草地上,望着天空,想着一件事: 什么是"计算"? 他叫艾伦图灵(Alan Turing)。 这个年轻人…...

【NotebookLM戏剧研究辅助实战指南】:20年戏剧学者亲授AI赋能文本细读的5大黄金工作流
更多请点击: https://intelliparadigm.com 第一章:NotebookLM戏剧研究辅助的底层逻辑与学科适配性 NotebookLM 以“语义锚点驱动”为核心机制,将用户上传的原始文本(如莎士比亚手稿影印本OCR结果、梅兰芳口述史转录稿、《奥尼尔书…...

巅峰共鸣,实力同频|盖茨中国热烈祝贺张雪机车WSBK捷克站双冠耀世,改写37年垄断史!
引擎轰鸣震彻赛道,中国红闪耀世界舞台!2026 年 5 月 17 日,WSBK 捷克莫斯特站 WorldSSP 组别圆满落幕,中国品牌张雪机车再创历史,车手 Valentin Debise 驾驶自研 ZX820RR 赛车,包揽两回合冠军,斩…...

PyCharm 运行 FastAPI 接口请求阻塞?竟是后台多进程残留导致
问题描述在 PyCharm 中启动 FastAPI 项目进程后,使用 Postman 发起接口请求出现明显阻塞现象,不仅请求迟迟无法得到响应,项目控制台也完全接收不到任何请求日志,接口调用彻底失效。 问题根源分析日常开发中习惯性直接关闭运行终端…...