基于IDEA使用maven创建hibernate项目
1、创建maven项目

2、导入hibernate需要的jar包
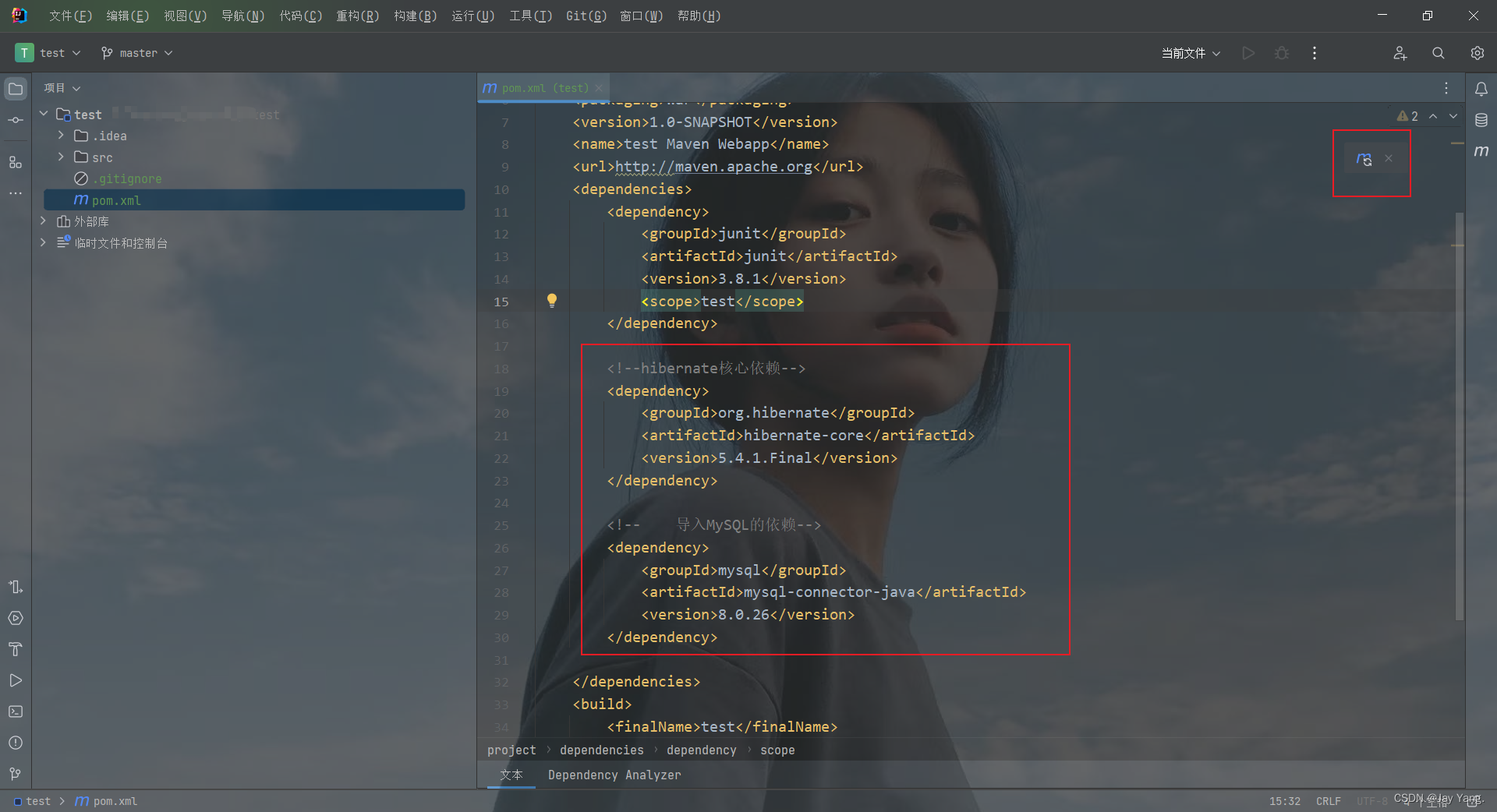
<!--hibernate核心依赖--><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-core</artifactId><version>5.4.1.Final</version></dependency><!-- 导入MySQL的依赖--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.26</version></dependency>3、新建所需的文件夹,如果有就不用添加
resources文件夹
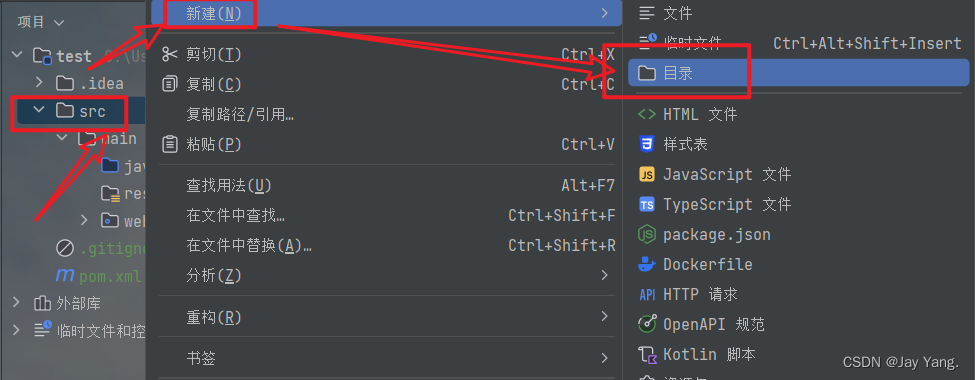
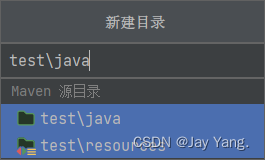
hibernate文件
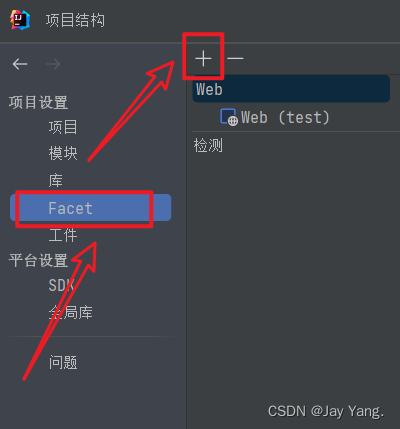

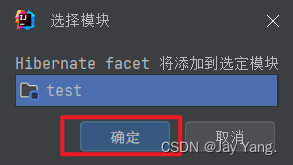
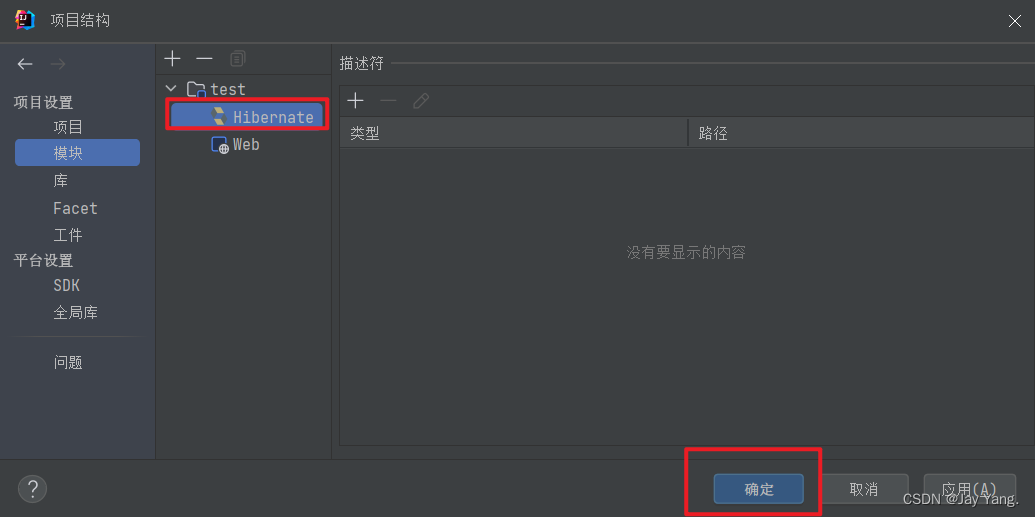

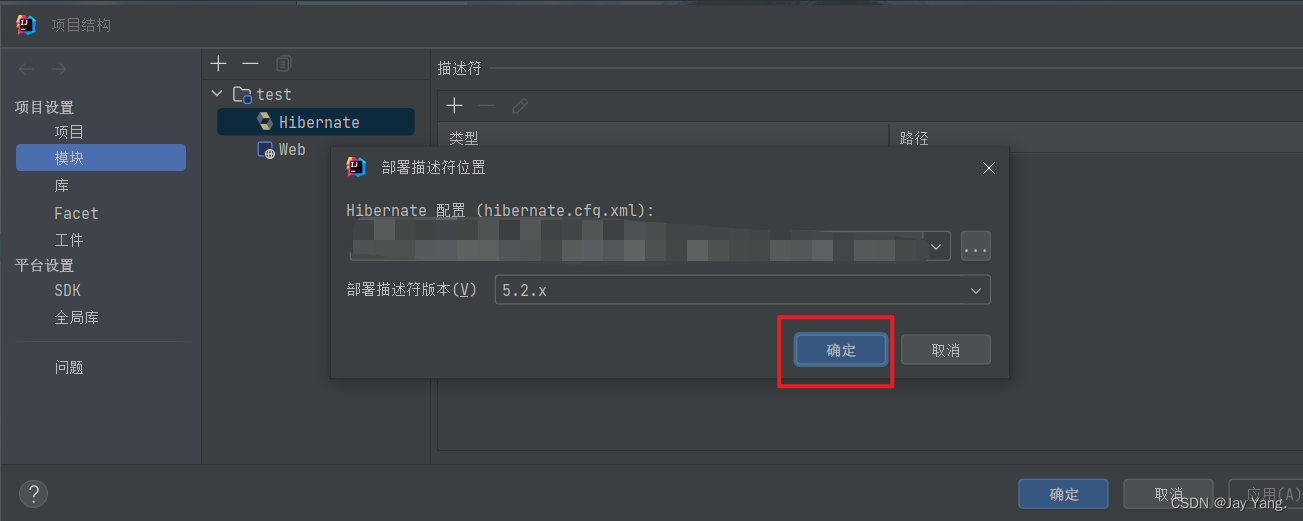
4、完整的结构如下

5、对hibernate的文件进行设置
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC"-//Hibernate/Hibernate Configuration DTD//EN""http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration><session-factory><!--配置所使用的Hibernate方言--><property name="hibernate.dialect">org.hibernate.dialect.MySQL5Dialect</property><property name="hibernate.connection.driver_class">com.mysql.cj.jdbc.Driver</property><!-- Hibernate 连接数据库的基本信息 --><property name="connection.username">数据库用户名</property><property name="connection.password">数据库密码</property><property name="connection.driver_class">com.mysql.cj.jdbc.Driver</property><property name="connection.url">数据库连接地址</property><!-- Hibernate 的基本配置 --><!-- Hibernate 使用的数据库方言 --><property name="dialect">org.hibernate.dialect.MySQLInnoDBDialect</property><!-- 运行时是否打印 SQL --><!-- <property name="show_sql">true</property>--><property name="hibernate.show_sql">true</property><!-- 运行时是否格式化 SQL --><!-- <property name="format_sql">true</property>--><property name="hibernate.format_sql">true</property><!-- 生成数据表的策略 --><!-- <property name="hbm2ddl.auto">update</property>--><!-- 加载Hibernate时,验证数据库表结构与Hibernate映射的结构是否匹配。如果不匹配,会抛出异常--><property name="hbm2ddl.auto">validate</property><!-- 设置 Hibernate 的事务隔离级别 --><property name="connection.isolation">2</property><!-- 删除对象后, 使其 OID 置为 null --><property name="use_identifier_rollback">true</property><!-- 配置 C3P0 数据源 --><property name="hibernate.c3p0.max_size">10</property><property name="hibernate.c3p0.min_size">5</property><property name="c3p0.acquire_increment">2</property><property name="c3p0.idle_test_period">2000</property><property name="c3p0.timeout">2000</property><property name="c3p0.max_statements">10</property><!-- 设定 JDBC 的 Statement 读取数据的时候每次从数据库中取出的记录条数 --><property name="hibernate.jdbc.fetch_size">100</property><!-- 设定对数据库进行批量删除,批量更新和批量插入的时候的批次大小 --><property name="jdbc.batch_size">30</property><!-- 需要关联的 hibernate 映射文件 .hbm.xml,使用hbm.xml的时候使用 --><!-- 扫描com.cx.bank.ORM包以查找带注解的实体类 --><mapping class="数据库对应实体类的路径"/></session-factory>
</hibernate-configuration>6、连接数据库
前提是已经新建好数据库,使用IDEA连接数据库
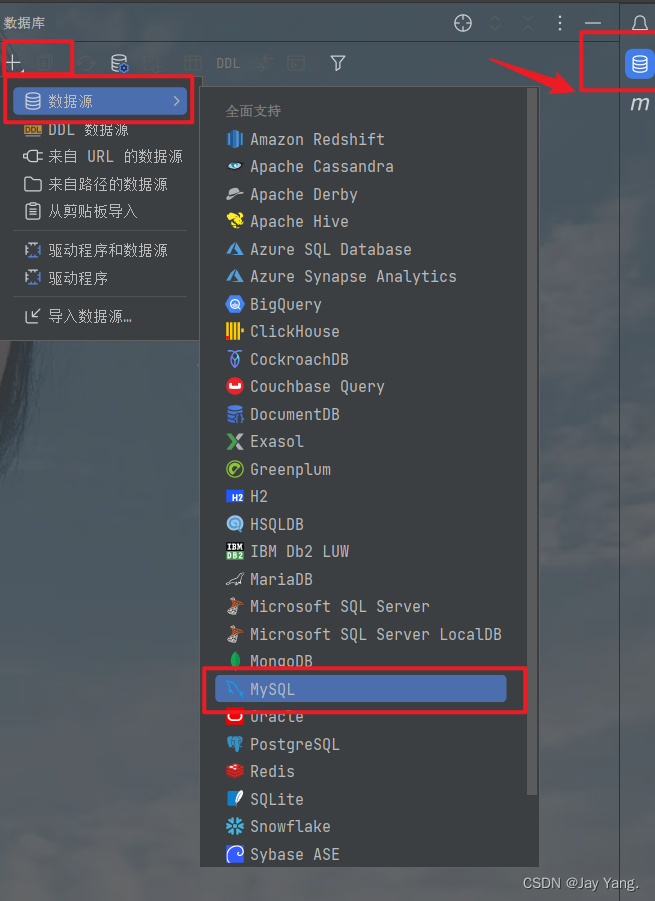
填写数据库名,用户名,密码,然后测试,测试成功后点击ok

7、将需要的表与类完成数据映射的关系
7.1、使用hbm.xml来实现映射
新建好了数据库后,若没有建表,可以写了 “类名.hbm.xml” 文件后,有hibernate 自动建表。
如果使用 “类名.hbm.xml” 来实现映射的话,可以在表对应的实体类的包下,新建 “类名.hbm.xml” 文件来实现映射。
示例:
<hibernate-mapping><class name="com.hibernate.User">实体类映射成表 表名默认为User<id name="id">映射表的主键为实体的id属性<generator class="uuid"/>主键按uuid方式生成</id><property name="name"/>实体的其它属性映射表的一般字段<property name="password"/><property name="createTime"/><property name="expireTime"/></class>
</hibernate-mapping>7.2、使用注解来实现映射
如果已经提前建好数据库和表,这里可以使用idea的工具自动生成。
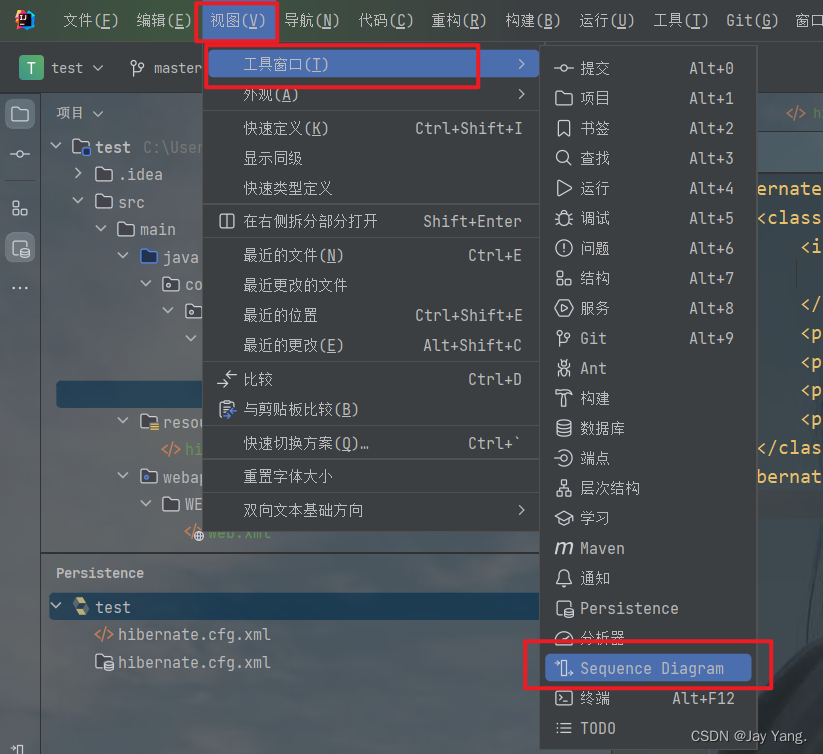
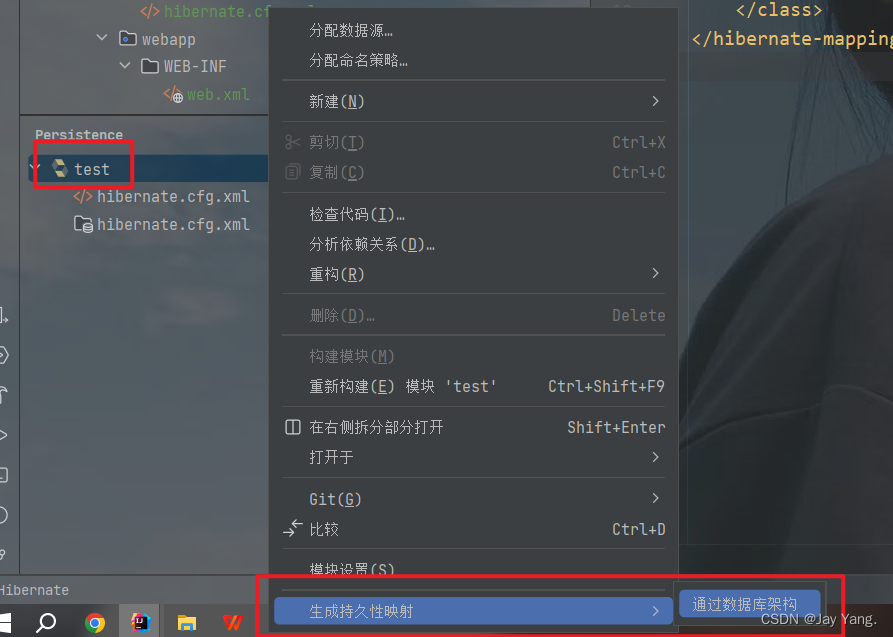


自动在指定的包下生成了实体类,自行添加有参和无参构造方法等其他方法。
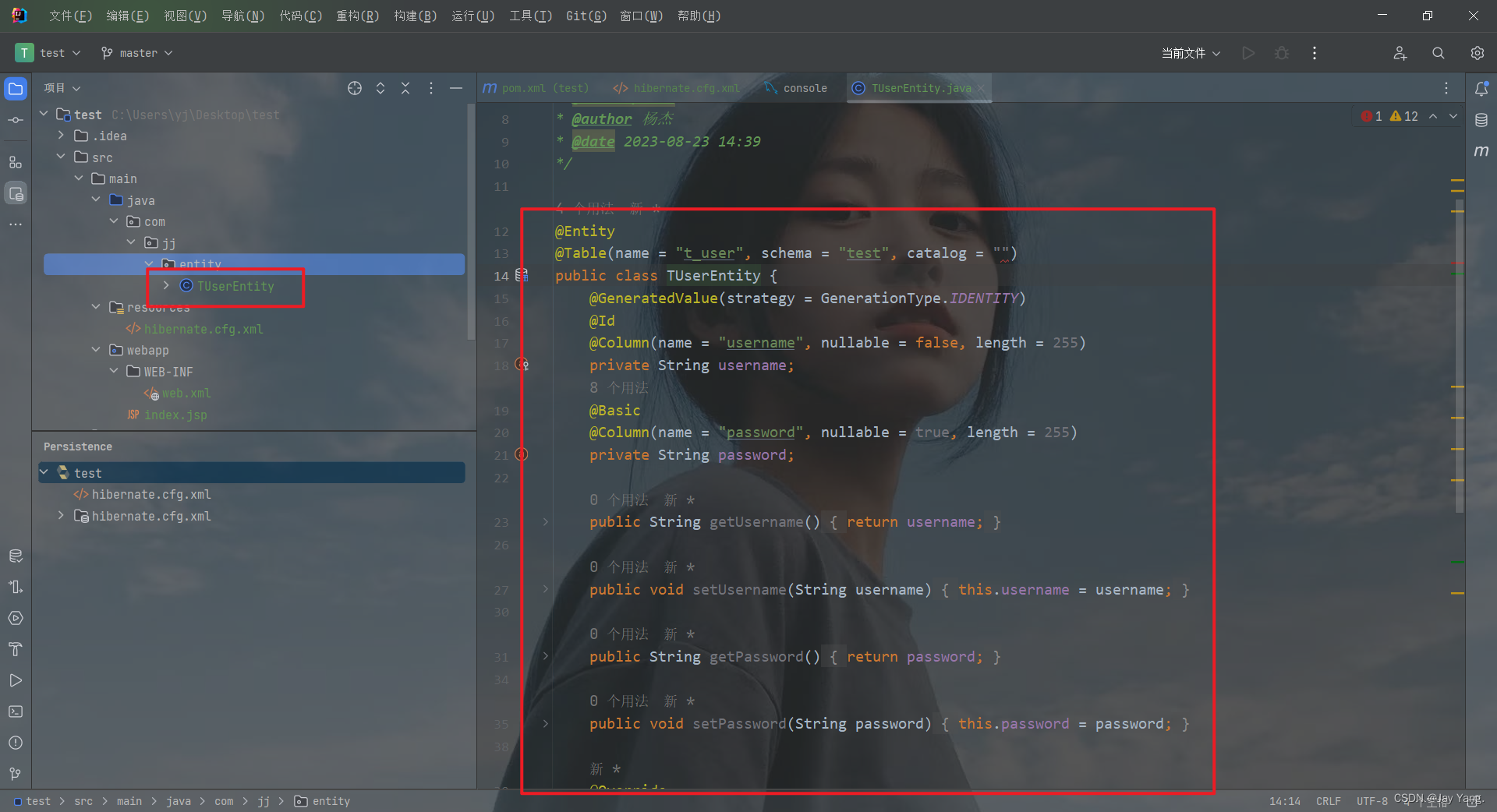
在 hibernate.cfg.xml 里修改映射类
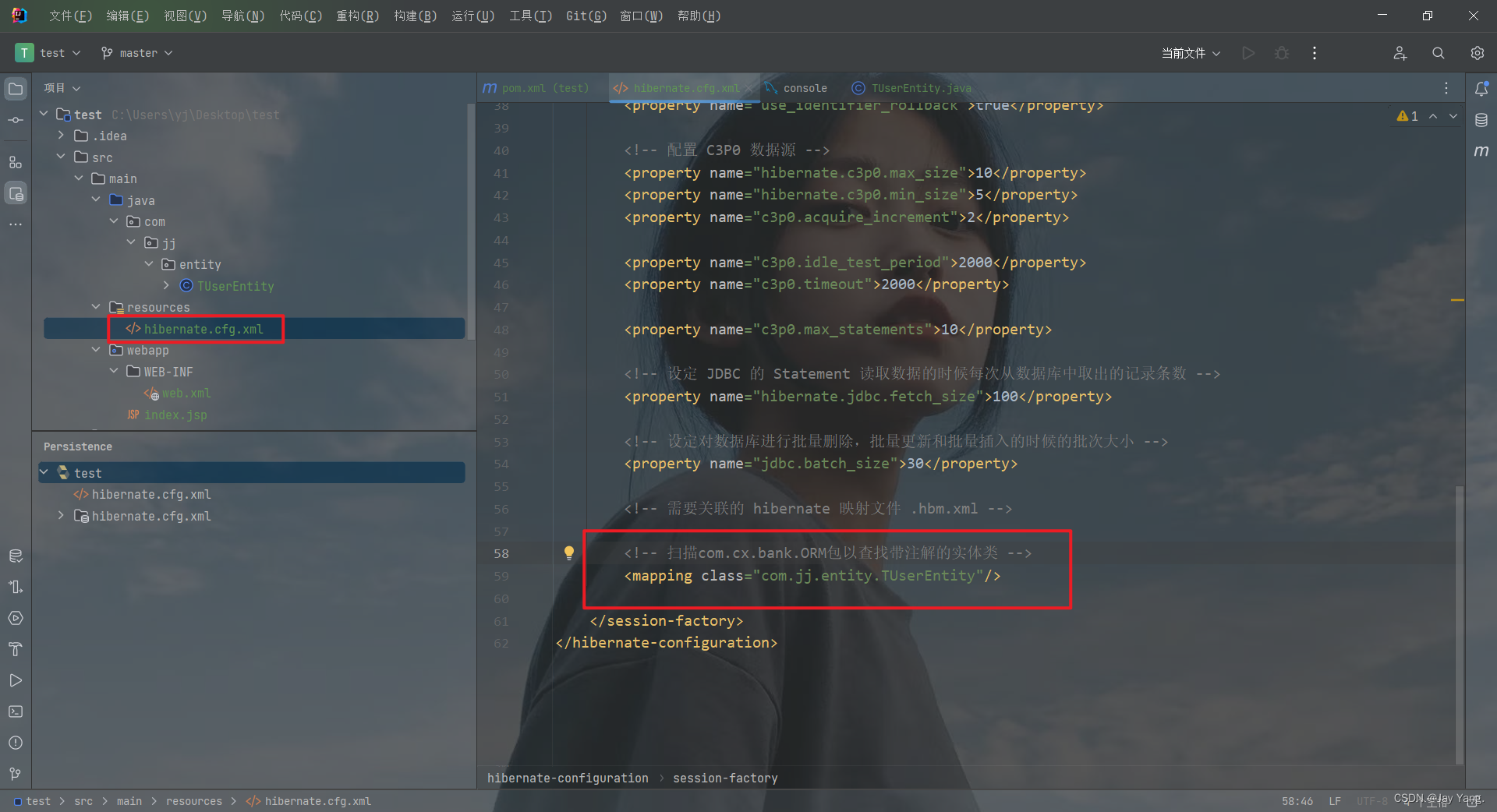
8、测试
8.1、在持久层的类中书写某个持久层的方法
public String findByName(String userName) {Session session = HibernateUtil.openSession();try {String hql = "from User where userName = :name";User user = session.createQuery(hql, User.class).setParameter("name", userName).uniqueResult();if (user != null) {return user.getUserName();} else {return null;}} finally {// 确保session被关闭if (session != null && session.isOpen()) {session.close();}}}8.2、测试方法
@Testpublic void findByName() {System.out.println(FileDao.findByName("jj"));}
9、相关工具类
HibernateUtil
public class HibernateUtil {private static final SessionFactory sessionFactory = buildSessionFactory();private static SessionFactory buildSessionFactory() {try {// 使用hibernate.cfg.xml创建SessionFactoryStandardServiceRegistry standardRegistry = new StandardServiceRegistryBuilder().configure("hibernate.cfg.xml").build();Metadata metadata = new MetadataSources(standardRegistry).getMetadataBuilder().build();return metadata.getSessionFactoryBuilder().build();} catch (Exception e) {e.printStackTrace();throw new RuntimeException("SessionFactory creation failed!");}}public static SessionFactory getSessionFactory() {return sessionFactory;}public static Session openSession() {return sessionFactory.openSession();}public static void closeSession(Session session) {if (session != null && session.isOpen()) {session.close();}}
}
相关文章:
基于IDEA使用maven创建hibernate项目
1、创建maven项目 2、导入hibernate需要的jar包 <!--hibernate核心依赖--><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-core</artifactId><version>5.4.1.Final</version></dependency><!--…...

使用Termux在安卓手机上搭建Hexo博客网站,并发布到公网访问
文章目录 1. 安装 Hexo2. 安装cpolar内网穿透3. 公网远程访问4. 固定公网地址 Hexo 是一个用 Nodejs 编写的快速、简洁且高效的博客框架。Hexo 使用 Markdown 解析文章,在几秒内,即可利用靓丽的主题生成静态网页。 下面介绍在Termux中安装个人hexo博客并…...

宝塔 杀死 java服务 netstat -tlnp | grep :7003 kill 2205698
7003 是端口 netstat -tlnp | grep :7003 kill 2205698...

Python3 数据类型转换
Python3 数据类型转换 有时候,我们需要对数据内置的类型进行转换,数据类型的转换,一般情况下你只需要将数据类型作为函数名即可。 Python 数据类型转换可以分为两种: 隐式类型转换 - 自动完成显式类型转换 - 需要使用类型函数来…...

Cookie 和 Session 的工作流程
目录 一、Cookie是什么? 二、Session是什么? 三、Cookie的工作流程 四、Session的工作流程 五、Session和Cookie的区别和联系 一、Cookie是什么? Cookie是一种在网站和用户之间交换信息的机制。它是由Web服务器发送给用户浏览器的小型文本文件ÿ…...
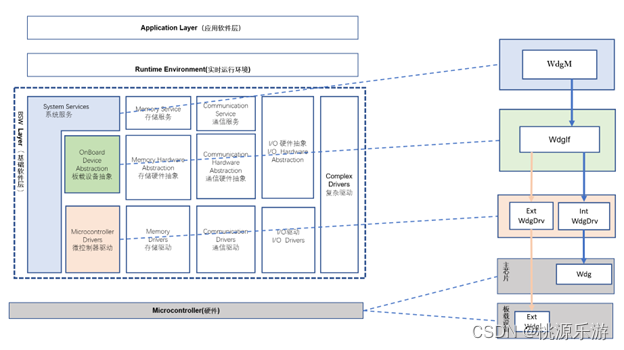
AutoSAR配置与实践(基础篇)3.6 BSW的WatchDog功能
3.6 BSW的WatchDog功能 一、WatchDog功能介绍1.1 WatchDog 模块组成1.2 内外部看门狗区别和原理1.3 常见看门狗校验方式一、WatchDog功能介绍 1.1 WatchDog 模块组成 WatchDog 即看门狗功能。这个看门狗不是真正看家的狗,而是软件的一个模块,但是因为功能类似故以此起名。主…...

运维高级第6次作业
1.安装docker服务,配置镜像加速器 Docker安装与镜像加速器配置_ZRSAI的博客-CSDN博客 2.下载系统镜像(Ubuntu、 centos) 执行该命令后,Docker会自动从Docker Hub镜像库中下载Ubuntu镜像,并将其保存到本地计算机上: [ro…...
)
MongoDB使用GridFS存储大数据(Java)
MongoDB 是一个灵活的 NoSQL 数据库,能够存储大量的数据。但是,当涉及到特别大的数据项,比如大文件、视频或大型图片时,MongoDB 提供了一个特殊的方法来存储这些数据:GridFS。 简介: 1. 什么是 GridFS&am…...
内网穿透实战应用-windwos10系统搭建我的世界服务器,内网穿透实现联机游戏Minecraft
文章目录 1. Java环境搭建2.安装我的世界Minecraft服务3. 启动我的世界服务4.局域网测试连接我的世界服务器5. 安装cpolar内网穿透6. 创建隧道映射内网端口7. 测试公网远程联机8. 配置固定TCP端口地址8.1 保留一个固定tcp地址8.2 配置固定tcp地址 9. 使用固定公网地址远程联机 …...

pytorch基于ray和accelerate实现多GPU数据并行的模型加速训练
在pytorch的DDP原生代码使用的基础上,ray和accelerate两个库对于pytorch并行训练的代码使用做了更加友好的封装。 以下为极简的代码示例。 ray ray.py #codingutf-8 import os import sys import time import numpy as np import torch from torch import nn im…...
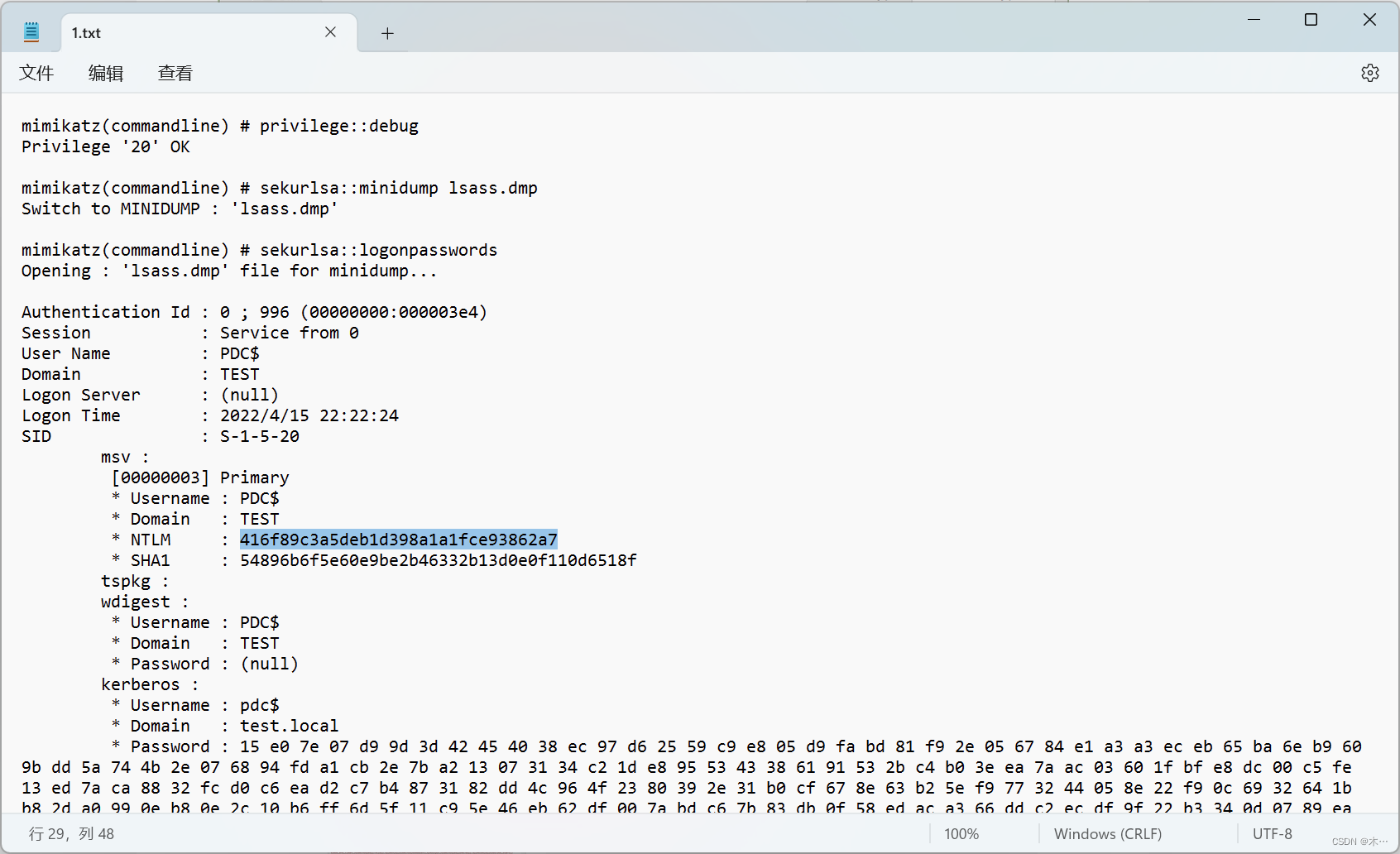
[蓝帽杯 2022 初赛]domainhacker
打开流量包,追踪TCP流,看到一串url编码 放到瑞士军刀里面解密 最下面这一串会觉得像base64编码 删掉前面两个字符就可以base64解码 依次类推,提取到第13个流,得到一串编码其中里面有密码 导出http对象 发现最后有个1.rar文件 不出…...

在 Pytorch 中使用 TensorBoard
机器学习的训练过程中会产生各类数据,包括 “标量scalar”、“图像image”、“统计图diagram”、“视频video”、“音频audio”、“文本text”、“嵌入Embedding” 等等。为了更好地追踪和分析这些数据,许多可视化工具应运而生,比如之前介绍的…...

Grafana Dashboard 备份方案
文章目录 Grafana Dashboard 备份方案引言工具简介支持的组件要求配置备份安装使用 pypi 安装grafana备份工具配置环境变量使用Grafana Backup Tool 进行备份恢复备份 Grafana Dashboard恢复 Grafana Dashboard结论Grafana Dashboard 备份方案 引言 每个使用 Grafana 的同学都…...

opencv-疲劳检测-眨眼检测
#导入工具包 from scipy.spatial import distance as dist from collections import OrderedDict import numpy as np import argparse import time import dlib import cv2FACIAL_LANDMARKS_68_IDXS OrderedDict([("mouth", (48, 68)),("right_eyebrow",…...

2023-08-24力扣每日一题
链接: 1267. 统计参与通信的服务器 题意: 同行同列可以发生通信,求能发生通信的机器数量 解: 标记每行/每列的机器个数即可 实际代码: #include<bits/stdc.h> using namespace std; class Solution { pub…...

蚂蚁数科持续发力PaaS领域,SOFAStack布局全栈软件供应链安全产品
8月18日,记者了解到,蚂蚁数科再度加码云原生PaaS领域,SOFAStack率先完成全栈软件供应链安全产品及解决方案的布局,包括静态代码扫描Pinpoint、软件成分分析SCA、交互式安全测试IAST、运行时防护RASP、安全洞察Appinsight等&#x…...

Java后端开发面试题——消息中间篇
RabbitMQ-如何保证消息不丢失 交换机持久化: Bean public DirectExchange simpleExchange(){// 三个参数:交换机名称、是否持久化、当没有queue与其绑定时是否自动删除 return new DirectExchange("simple.direct", true, false); }队列持久化…...

C++ Windows API IsDebuggerPresent的作用
IsDebuggerPresent 是 Windows API 中的一个函数,它用于检测当前运行的程序是否正在被调试。当程序被如 Visual Studio 这样的调试器附加时,此函数会返回 TRUE;否则,它会返回 FALSE。 这个函数经常被用在一些安全相关的场景或是防…...

【JVM 内存结构 | 程序计数器】
内存结构 前言简介程序计数器定义作用特点示例应用场景 主页传送门:📀 传送 前言 Java 虚拟机的内存空间由 堆、栈、方法区、程序计数器和本地方法栈五部分组成。 简介 JVM(Java Virtual Machine)内存结构包括以下几个部分&#…...
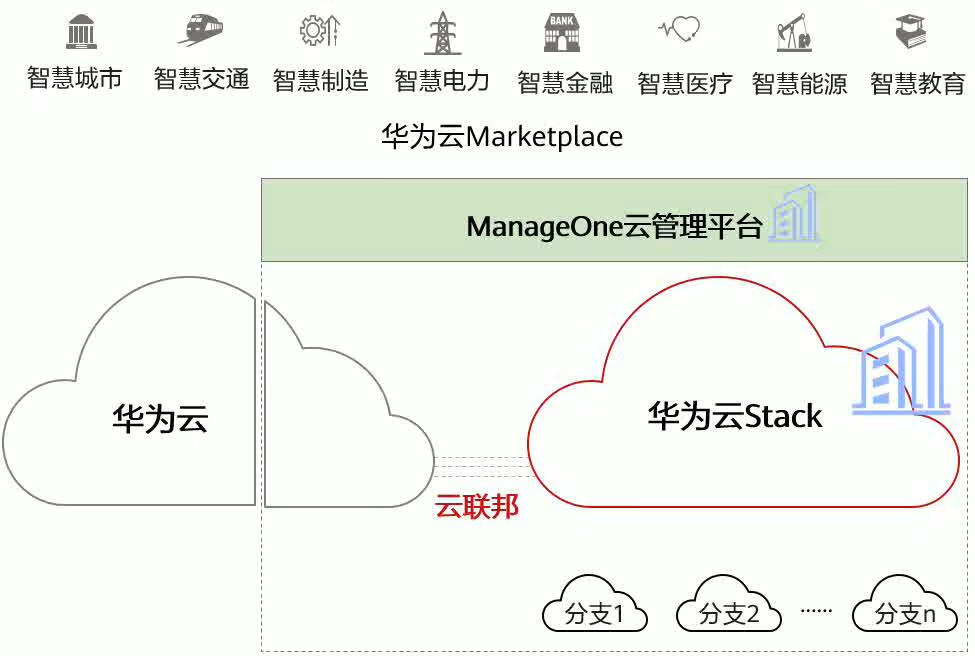
华为云Stack的学习(一)
一、华为云Stack架构 1.HCS 物理分散、逻辑统一、业务驱动、运管协同、业务感知 2.华为云Stack的特点 可靠性 包括整体可靠性、数据可靠性和单一设备可靠性。通过云平台的分布式架构,从整体系统上提高可靠性,降低系统对单设备可靠性的要求。 可用性…...
详解:终于搞懂管道、消息队列、共享内存到底在干什么)
Linux 进程间通信(IPC)详解:终于搞懂管道、消息队列、共享内存到底在干什么
很多人第一次学 Linux 进程间通信(IPC)时,都会有一种感觉:概念很多 API 很杂 学完还是不知道到底什么时候该用什么最容易出现的问题是:管道和消息队列有什么区别?为什么共享内存最快?信号量到底…...

开源阅读鸿蒙版:打造您的个性化无广告数字图书馆
开源阅读鸿蒙版:打造您的个性化无广告数字图书馆 【免费下载链接】legado-Harmony 开源阅读鸿蒙版仓库 项目地址: https://gitcode.com/gh_mirrors/le/legado-Harmony legado-Harmony是一款专为鸿蒙系统设计的开源电子书阅读器,它为您提供纯净的阅…...

电子项目布线指南:从导线、电缆到连接器的核心选型与避坑
1. 项目概述:为什么“线”比“电路”本身更重要?干了十几年电子项目,从学生时代的第一个闪烁LED,到后来复杂的机器人系统和工业控制器,我踩过最多的坑,往往不是芯片选型或代码逻辑,而是那些看起…...

SAP UI5 里没有 BehaviorSubject,但有更贴近企业 UI 的状态流
问题: SAP UI5 的开发技术里,有类似 Angular 中 BehaviorSubject 的概念和用法? 我今天理解这个问题时,不能直接问 SAP UI5 里有没有一个类叫 BehaviorSubject,因为这个问法会把 Angular 和 SAP UI5 的编程范式强行拉到同一个坐标系里。更准确的问题应该是,SAP UI5 里有…...

Graph-CoT:图神经网络结合思维链,实现复杂图结构推理
1. 项目概述:当图神经网络遇上思维链推理最近在复现和优化一些图相关的推理任务时,我反复遇到了一个瓶颈:传统的图神经网络模型在处理需要多步逻辑推理的问题时,比如社交网络中的影响力传播预测、知识图谱上的复杂问答,…...

利用Taotoken实现AI应用的高可用与容灾路由设计思路
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken实现AI应用的高可用与容灾路由设计思路 应用场景类,探讨在构建对稳定性要求高的生产级AI应用时࿰…...
)
用Java+GDAL+OpenCV玩转遥感图像:手把手教你实现Landsat标准假彩色合成(附完整代码)
JavaGDALOpenCV遥感图像处理实战:Landsat标准假彩色合成全流程解析 遥感图像处理正逐渐从专业软件向通用编程语言生态迁移。对于熟悉Java的开发者而言,利用GDAL和OpenCV这两个强大的库,完全可以构建自主可控的遥感处理流程。本文将完整展示如…...

开发上下文管理工具:原理、实现与工程实践
1. 项目概述:一个为开发者量身定制的上下文管理工具如果你和我一样,每天要在多个项目、多种技术栈、甚至多个开发环境之间反复横跳,那你一定对“上下文切换”这个词深恶痛绝。我说的不是操作系统的上下文切换,而是我们开发者大脑里…...

使用Taotoken后API调用延迟与稳定性体感观察报告
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后API调用延迟与稳定性体感观察报告 1. 引言:从直接对接模型到使用聚合平台 在开发基于大语言模型的应用…...

Claude新政,抛弃最忠实的Agent用户
Anthropic 过河拆桥,终将遭反噬。 Anthropic 将 Agent SDK 用量从订阅中剥离,按 API 零售价另给固定额度。重度用户的可用量缩水近十倍。同一周,OpenAI 向企业用户推出 Codex 两个月免费迁移。ASI 决赛圈的第一场定价战,开打了。 …...