Python爬虫实战案例——第二例
某某美剧剧集下载(从搜索片名开始)
本篇文章主要是为大家提供某些电影网站的较常规的下载电影的分析思路与代码思路(通过爬虫下载电影),我们会从搜索某部影片的关键字开始直到成功下载某一部电影。
地址:aHR0cHM6Ly93d3cuOTltZWlqdXR0LmNvbS9pbmRleC5odG1s
先来分析页面

打开开发者工具,然后再搜索框输入任意内容开始搜索影片(如搜索战火)并抓包

从XHR来看的话返回的都是js文件,所以我们可以先考虑document中的html文档是否包含了我们需要的有效数据。

document中只返回了一个包,并且通过预览来看的话我们可以看到通过关键字搜索出来的电影是存在于这个html中的,所以我们就可以直接通过xpath解析将这些电影的片名解析出来,便于后面我们对影片进行选择。然后就可以进入到电影的详情页面(xpath解析出详情页的url)了。例如此处我们选择《兄弟连》这部电影。

进入到详情页之后,我们需要判断这部影片是否已经更新完成,因为下面我们需要选择播放线路,不同的播放线路已更新的剧集可能不同,但是经过对多部影片的详情页分析(此处不再贴图,大家自己去观察)发现,已完结的影片是不会存在上述问题的。但是正在连载中的影片可能就存在这样的问题,所以我们需要判断一下已经连载的剧集与这些播放线路中的剧集集数是否相等,如果相等的话才是可用的线路,否则是不可用的线路。当然也有可能存在一条线路都无法播放的情况,这个就是服务器的问题了,咱们客户端这边是没办法处理的。之后我们就要根据选择的线路去到播放页面就可以准备下载电视剧了。
此处我们选择的是九九云线路,来到播放页面之后通过抓包我们会发现并没有媒体文件,但是存在着m3u8与ts的包,因此我们能够判断出这个站点的视频是被分割成很多分的片段了。

接下来就是要想办法把这些ts视频下载下来了,通常情况下,这些文件的url会存在于一个m3u8的文件之中,所以我们需要先将m3u8下载下来。从播放页面的源码中我们可以解析出m3u8文件的下载地址(为了方便此处我就不再去请求源码了,直接从elements中看,大家平时的时候一定是养成习惯把源码下载到本地进行分析)

然后将next后面的url解析出来再进行请求,就会看到里面存在着一个新的m3u8文件的地址。

接下来就是通过正则将这个文件中存在的这个地址提取出来进行拼接再进行请求就能够获取到所有的ts文件所在的地址了。

下一步就是将这些ts文件的地址提取出来,同样我们选择正则进行提取(或者使用专门处理m3u8的第三方包进行提取),提取出来后拼接成正常的链接,存放到一个列表中,然后再遍历列表依次请求这些url并按照顺序将视频进行保存。

保存之后通过ffmpeg对视频进行合成,关于ffmpeg的配置请大家自行查阅一下相关资料。

合成后的视频

由于时间关系,只下载了200个片段进行合成,有兴趣的朋友可以改写成并发请求的方式下载所有的片段进行合成。完整代码如下:
import os.path
import re
import requests
import urllib3
from lxml import etreeclass SendRequest:"""基本请求模板,待完善"""urllib3.disable_warnings()def __init__(self):self.ABS_PATH = os.path.abspath(os.path.dirname(__file__))self.url = ''self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'}self.cookies = {} # cookie设置self.data = {} # 表单数据self.page = 1 # 翻页控制参数self.session = requests.session()# self.movie = '测试'# print(f'{self.ABS_PATH}/{self.movie}(临时文件)/{self.movie}.m3u8')# print(f'{self.ABS_PATH}/{self.movie}/{self.movie}.mp4')@propertydef UGetRequest(self):response = self.session.get(url=self.url, headers=self.headers, cookies=self.cookies, verify=False)return response@UGetRequest.setterdef UGetRequest(self, kwargs: dict):if kwargs.get('url'):self.url = kwargs.get('url')if kwargs.get('referer'):self.headers['referer'] = kwargs.get('referer')@propertydef UPostRequest(self):response = self.session.post(url=self.url, headers=self.headers, cookies=self.cookies, data=self.data,verify=False)return response@UPostRequest.setterdef UPostRequest(self, kwargs: dict):if kwargs.get('url'):self.url = kwargs.get('url')if kwargs.get('referer'):self.headers['referer'] = kwargs.get('referer')class MeiJu99(SendRequest):def __init__(self):super().__init__()def synthesis(self):"""合成视频"""if not os.path.exists(self.movie):os.mkdir(self.movie)cmd = f'ffmpeg.exe -f concat -safe 0 -i {self.ABS_PATH}\\{self.movie}(临时文件)\\{self.movie}.m3u8 -c copy {self.ABS_PATH}\\{self.movie}\\{self.movie}.mp4'os.system(cmd)def download_mvs(self, total_mv_urls):"""下载所有片段"""if not os.path.exists(self.movie+'(临时文件)'):os.mkdir(self.movie+'(临时文件)')num = 1# 按照ffmpeg的格式将ts文件的路径写入到一个m3u8文件之中用于合成视频new_m3u8_file = open(self.movie+'(临时文件)'+'/'+self.movie+'.m3u8', 'a', encoding='utf-8')for url in total_mv_urls:self.UGetRequest = {'url': url}res = self.UGetRequestwith open(self.movie+'(临时文件)'+'/'+str(num)+'.ts', 'wb')as f:f.write(res.content)new_m3u8_file.write("file '%s\%s\%d.ts'" % (self.ABS_PATH, self.movie+'(临时文件)', num))new_m3u8_file.write('\n')print(str(num) + '下载成功')num+=1if num == 201:breaknew_m3u8_file.close()self.synthesis()def play_page(self, play_pages_url):"""播放页面提取下载链接"""self.UGetRequest = {'url': play_pages_url}response = self.UGetRequesttext_html = response.content.decode()with open('playpage.html', 'w', encoding='utf-8')as f:f.write(text_html)m3u8_url = re.findall('var next="(.*?)";var prePage=', text_html)[0] # 提取播放页面中的m3u8文件的地址self.UGetRequest = {'url': m3u8_url}m3u8_file = self.UGetRequest.contentwith open('1.m3u8', 'wb')as f:f.write(m3u8_file)# 请求上方获取到的m3u8_url以获取存放了ts地址的m3u8last_m3u8_url = m3u8_url.split('/2')[0] + re.search('/\d+/\w+/[\d+kb/]*\w+/index\.m3u8', m3u8_file.decode()).group()self.UGetRequest = {'url': last_m3u8_url}response = self.UGetRequest.content.decode()# 解析并保存所有的ts地址total_mv_urls = [m3u8_url.split('/2')[0]+i for i in re.findall('/\d+/\w+/\d+\w+/hls/\w+\.ts', response)]self.download_mvs(total_mv_urls)def index(self, index_url):"""电影详情页面"""self.UGetRequest = {'url': index_url}response = self.UGetRequesttext_html = response.content.decode()with open('index.html', 'w', encoding='utf-8')as f:f.write(text_html)tree = etree.HTML(text_html)using_lines = tree.xpath('//*[@id="playTab"]/div[1]/ul//li//text()') # 可使用线路(名称)play_tab = tree.xpath('//*[@id="playTab"]/div') # 下载线路mv_information = ''.join(tree.xpath('//*[@id="zanpian-score"]/ul//text()')) # 电影信息status = ''.join(tree.xpath('//*[@id="zanpian-score"]/ul/li[2]//text()'))if '完结' not in status:numbers_sets = ''.join(re.findall('集数:共(.*?)集 每集\d+分钟|状态:更新至(.*?)集', mv_information)[0])for i, tab in zip(range(len(using_lines)), play_tab[1:]):tab_num = len(tab.xpath('./ul/li'))if tab_num == int(numbers_sets):print('%d.' % (i+1), using_lines[i]+'(可用)', end='\t')else:print('%d.' % (i+1), using_lines[i]+'(不可用)', end='\t')else:for i, tab in zip(range(len(using_lines)), play_tab[1:]):print('%d.' % (i + 1), using_lines[i], end='\t')print()download_num = int(input('请选择下载线路(输入编号):'))play_pages_urls = ['https://www.99meijutt.com'+i for i in play_tab[download_num].xpath('./ul//li/a/@href')]for play_pages_url in play_pages_urls:self.play_page(play_pages_url)breakdef search(self):"""搜索页面采集"""titles = []self.UPostRequest = {'url': 'https://www.99meijutt.com/search.php'}self.data['searchword'] = input('请输入影片关键字或主演名:')response = self.UPostRequesttext_html = response.content.decode()with open('search.html', 'w', encoding='utf-8') as f:f.write(text_html)tree = etree.HTML(text_html)div_lst = tree.xpath('//*[@id="content"]/div')print('搜索到的电影如下:')for i, div in zip(range(1, len(div_lst)), div_lst): # 遍历数组与div列表为标题设置编号title = div.xpath('./div[1]/a/@title')[0]if i % 2 != 0 and i != len(div_lst)-1:print(str(i) + '.' + title, end='\t\t')else:print(str(i) + '.' + title)titles.append(title)num = int(input('请输入您要下载的电影序号:'))self.movie = titles[num-1]index_url = 'https://www.99meijutt.com' + div_lst[num-1].xpath('./div[1]/a/@href')[0]self.index(index_url)if __name__ == '__main__':mj = MeiJu99()mj.search()
相关文章:
Python爬虫实战案例——第二例
某某美剧剧集下载(从搜索片名开始) 本篇文章主要是为大家提供某些电影网站的较常规的下载电影的分析思路与代码思路(通过爬虫下载电影),我们会从搜索某部影片的关键字开始直到成功下载某一部电影。 地址:aHR0cHM6Ly93d3cuOTltZWlqdXR0LmNvbS9pbmRleC5od…...

深入理解Spring的ImportBeanDefinitionRegistrar接口及其应用
0 导言 ImportBeanDefinitionRegistrar接口在动态注册Bean定义方面发挥着重要作用。本篇博客将深入探讨ImportBeanDefinitionRegistrar接口的作用、用法以及实际应用场景。 1 简介 ImportBeanDefinitionRegistrar接口是Spring Framework中的一个关键接口,位于org…...

【面试题】你理解中JS难理解的基本概念是什么?
前端面试题库 (面试必备) 推荐:★★★★★ 地址:前端面试题库 作用域与闭包 作用域 作用域是当前的执行上下文,值和表达式在其中“可见”或可被访问。如果一个变量或表达式不在当前的作用域中࿰…...
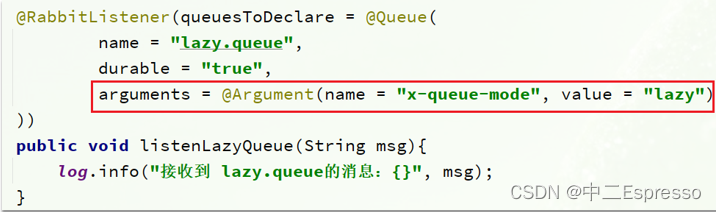
微服务中间件--MQ服务异步通信
MQ服务异步通信 MQ服务异步通信a.消息可靠性1) 生产者消息确认2) 消息持久化3) 消费者消息确认4) 消费者失败重试4.a) 本地重试4.b) 失败策略 b.死信交换机1) 初识死信交换机2) TTL3) 延迟队列a) 安装延迟队列插件b) SpringAMQP使用延迟队列插件 c.惰性队列1) 消息堆积问题2) 惰…...

爆火「视频版ControlNet」开源了!靠提示词精准换画风,全华人团队出品
“视频版ControlNet”来了! 让蓝衣战神秒变迪士尼公举: 视频处理前后,除了画风以外,其他都不更改。 女孩说话的口型都保持一致。 正在插剑的姜文,也能“下一秒”变猩球崛起了。 这就是由全华人团队打造的最新视频处理…...

常用的数据可视化工具有哪些?要操作简单的
随着数据量的剧增,对分析效率和数据信息传递都带来了不小的挑战,于是数据可视化工具应运而生,通过直观形象的图表来展现、传递数据信息,提高数据分析报表的易读性。那么,常用的操作简单数据可视化工具有哪些࿱…...
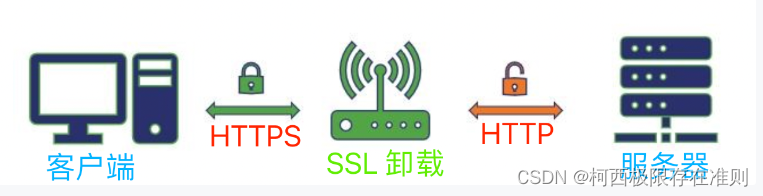
ssl卸载原理
SSL卸载,也称为SSL解密,是一种将SSL加密数据流卸成非加密的明文数据流的过程。SSL卸载通常在负载均衡器、代理服务器、WAF等设备中实现,可以提高传输效率和安全性。 SSL卸载的原理是将SSL数据流拦截下来,通过设备内置的证书进行解…...

【C语言】动态内存管理,详细!!!
文章目录 前言一、为什么存在动态内存分配二、动态内存开辟函数的介绍1.malloc2.calloc3.realloc4.free 三、动态内存开辟中的常见错误1.误对NULL进行解引用操作2.对于动态开辟的空间进行了越界访问3.对于非动态开辟的内存进行了free操作4.只free掉动态开辟内存的一部分5.多次f…...

2023年国赛 高教社杯数学建模思路 - 案例:退火算法
文章目录 1 退火算法原理1.1 物理背景1.2 背后的数学模型 2 退火算法实现2.1 算法流程2.2算法实现 建模资料 ## 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 退火算法原理 1.1 物理背景 在热力学上&a…...
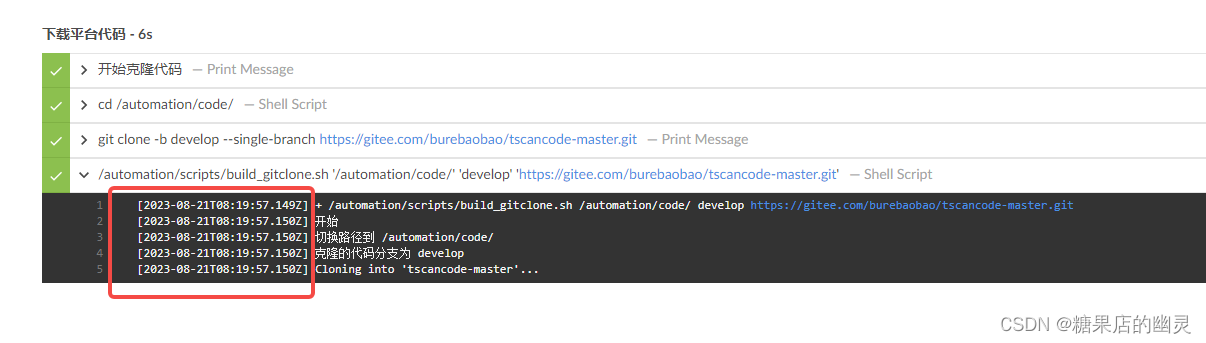
jenkins 日志输出显示时间戳的方式
网上很多方式比较片面,最新版插件直接使用即可无需更多操作。 使用方式如下: 1.安装插件 Timestamper 2.更新全局设置 系统设置-找到 Timestamper 勾选 Enabled for all Pipeline builds 也可修改时间戳格式。 帮助信息中显示 When checked, timesta…...
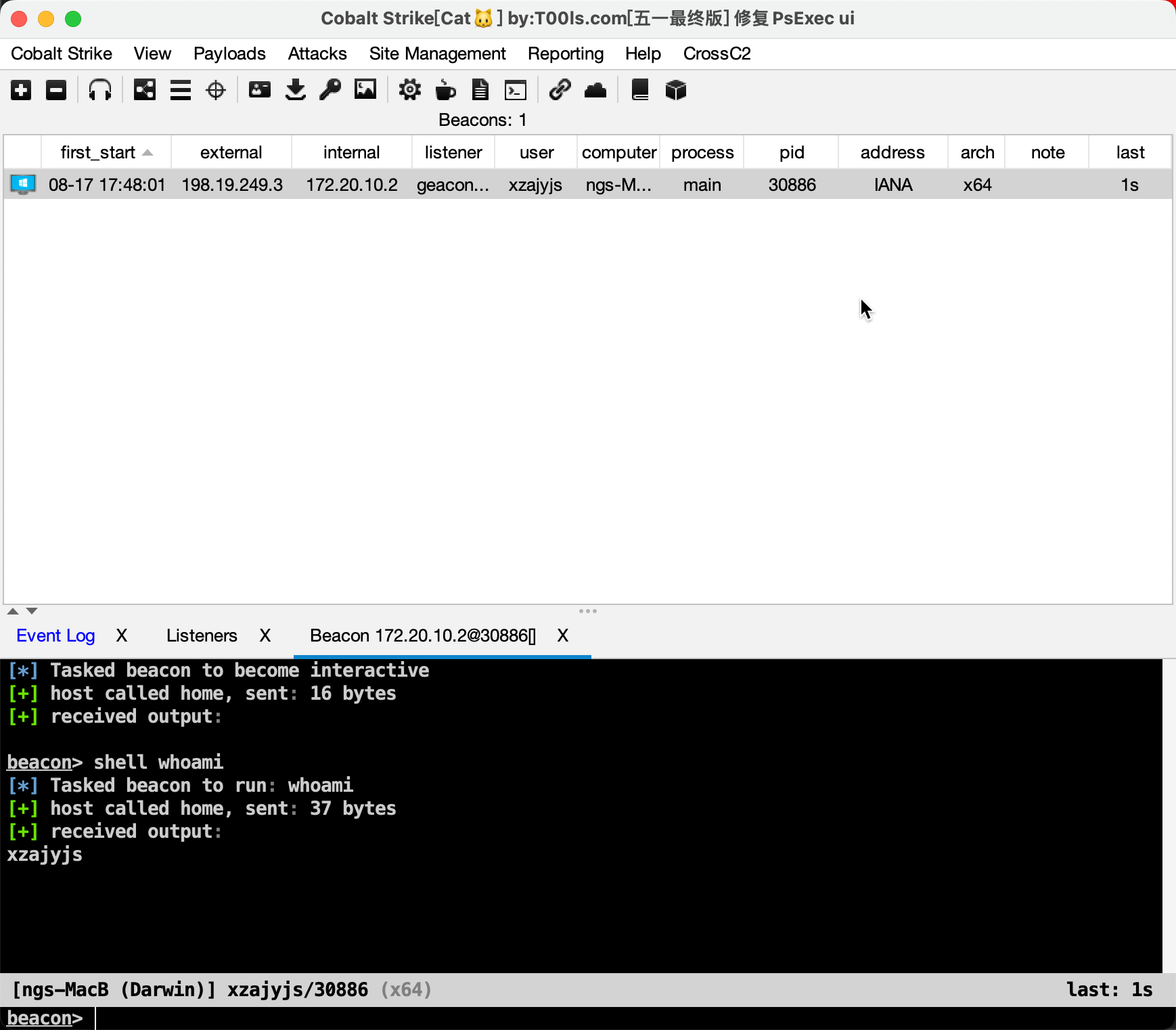
geacon_pro配合catcs4.5上线Mac、Linux
我的个人博客: xzajyjs.cn 一些链接 Try师傅的catcs4.5项目: https://github.com/TryGOTry/CobaltStrike_Cat_4.5,最新版解压密码见:https://www.nctry.com/2708.html geacon_pro: https://github.com/testxxxzzz/geacon_pro BeaconTool.jar: https:/…...
)
vue 实现腾讯地图搜索选点功能(附加搜索联想功能)
注意:开发环境、正式环境需在腾讯地图配置ip地址白名单、域名白名单 封装map组件: <template><iframe width"100%" style"border: none;width: 100%;height: 100%;" :src"map_src"></iframe> </t…...
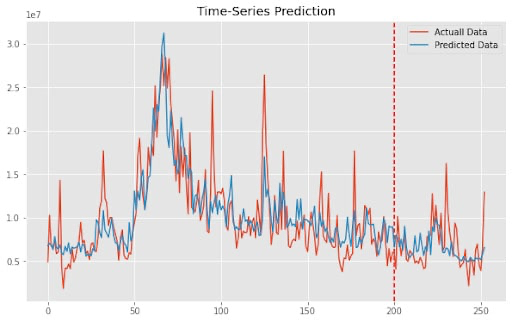
解密长短时记忆网络(LSTM):从理论到PyTorch实战演示
目录 1. LSTM的背景人工神经网络的进化循环神经网络(RNN)的局限性LSTM的提出背景 2. LSTM的基础理论2.1 LSTM的数学原理遗忘门(Forget Gate)输入门(Input Gate)记忆单元(Cell State)…...
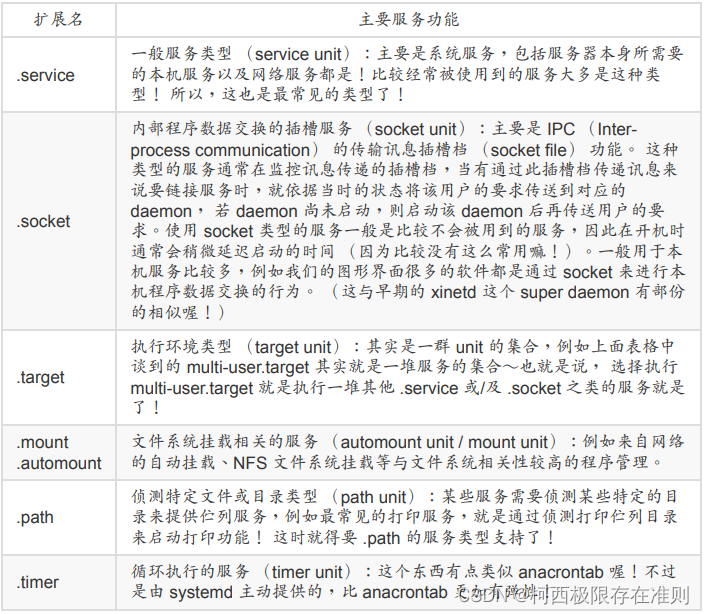
17.1.2 【Linux】systemd使用的unit分类
systemd 有什么好处? 平行处理所有服务,加速开机流程: 旧的 init 启动脚本是“一项一项任务依序启动”的模式,因此不相依的服务也是得要一个一个的等待。但目前我们的硬件主机系统与操作系统几乎都支持多核心架构了,s…...
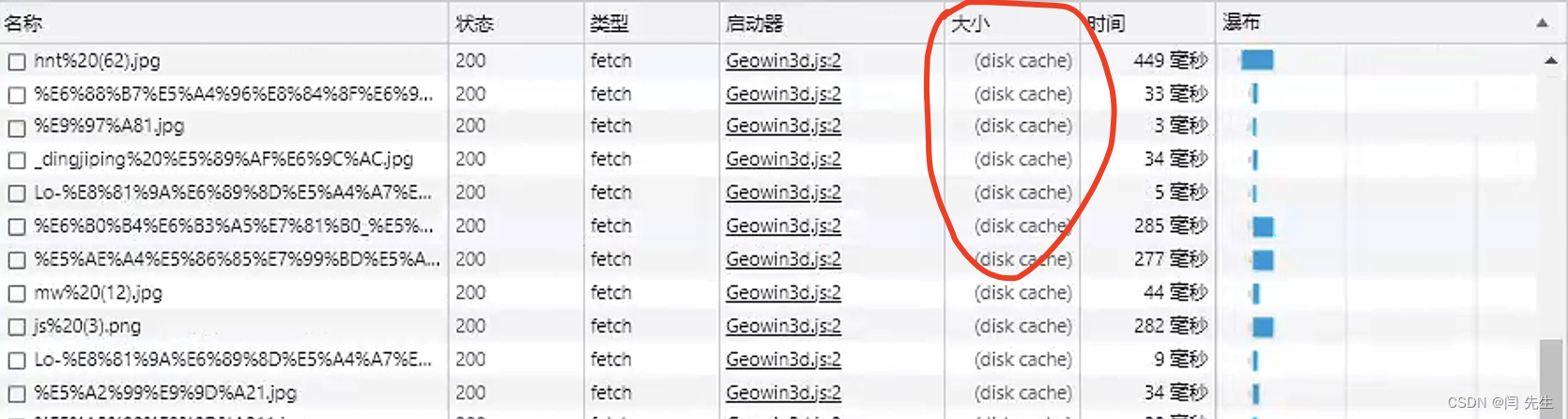
vue离线缓存资源文件
本文章主要是解决大文件,实时请求资源浪费网络资源的问题 从而有效的将解决用户体验的问题 话不多说上才艺 ⬇️⬇️⬇️⬇️⬇️⬇️⬇️ 找到项目中的 index.html 文件,并在 html 标签中加入 manifest"manifest.appcache" 安装 appcache-manifest 包 npm ins…...

2023华为杯研赛数学建模A题B题C题D题E题F题资料 华为杯
本次比赛我们将会全程更新华为杯研赛赛题思路模型及代码,大家查看文末名片获取 之前华为杯相关的资料和助攻可以查看 2022华为杯数学建模研赛选题建议和思路分析_方形件组批优化问题_UST数模社_的博客-CSDN博客 我们华为杯更新的流程如下: A题思路&a…...

星际争霸之小霸王之小蜜蜂(六)--让子弹飞
目录 前言 一、添加子弹设置 二、创建子弹 三、创建绘制和移动子弹函数 四、让子弹飞 五、效果 总结 前言 小蜜蜂的基本操作已经完成了,现在开始编写子弹的代码了。 一、添加子弹设置 在我的预想里,我们的小蜜蜂既然是一只猫,那么放出的子弹…...
opencv简单使用
cv2库安装, conda install opencv-python注意cv2使用时,路径不能有中文。(不然会一直’None’ _ update # 处理中文路径问题 def cv_imread(file_path): #使用之前需要导入numpy、cv2库,file_path为包含中文的路径return cv2.imd…...
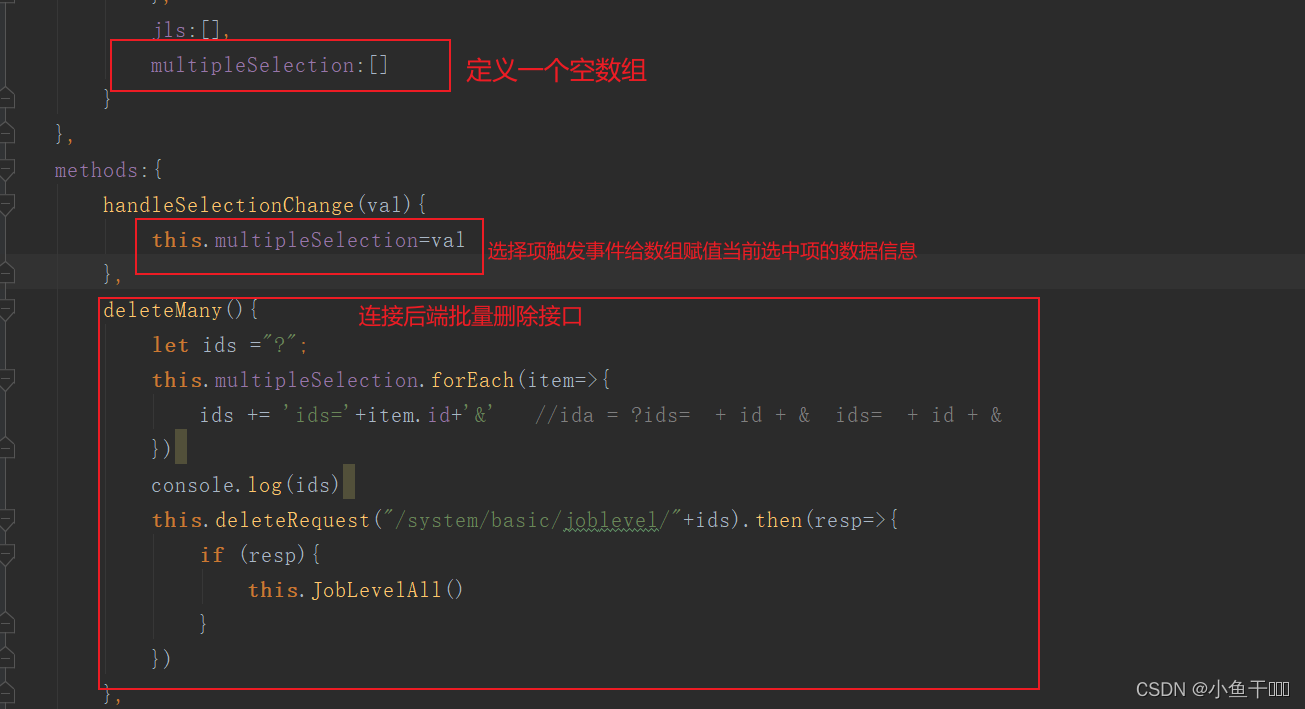
SpringBoot 微人事 职称管理模块(十三)
职称管理前端页面设计 在职称管理页面添加输入框 export default {name: "JobLevelMarna",data(){return{Jl:{name:""}}}}效果图 添加一个下拉框 v-model的值为当前被选中的el-option的 value 属性值 <el-select v-model"Jl.titlelevel" …...

动态规划之0-1背包问题
动态规划之0-1背包问题 文章目录 动态规划之0-1背包问题一、先给出代码二、讲解第一步:初始化第二步:动态规划,填表第三步:回溯,找到选择方案总结 三、进阶(用一维数组解决问题) 一、先给出代码…...

告别重复劳动:用这个Maya Mel脚本插件,5分钟搞定Arnold材质批量调节
告别重复劳动:Maya Mel脚本插件在Arnold材质批量调节中的高效应用 在三维动画和视觉特效制作中,材质调节往往是项目后期最耗时的环节之一。当导演皱着眉头说"这个场景的金属感太强了"或者客户反馈"整体色调需要更暖一些"时…...

【声纳技术手册】3 三维水声传播的快速计算:从海底山脉到水平折射
三维水声传播的快速计算:从海底山脉到水平折射 副标题:当我们在深海中"听见"一座山——3D射线追踪、Normal Mode Coupling与剪切波效应的直觉之旅 写在前面:为什么我们需要三维? 别急,我们先从一个你熟悉的场景开始想象。 想象你站在一个巨大的游泳池边,水面…...

【免费下载】 MATLAB从入门到精通教程 - PDF文档下载指南【matlab下载】
MATLAB从入门到精通教程 - PDF文档下载指南 欢迎来到《MATLAB从入门到精通教程》的资源页面!本资源旨在为所有想要深入学习MATLAB编程语言的学者和工程师提供一份详尽、全面的学习资料。这份权威的PDF文档是英文版,非常适合希望掌握MATLAB核心功能及高级…...

终极Windows APK安装器:3分钟学会在电脑上安装Android应用
终极Windows APK安装器:3分钟学会在电脑上安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否想在Windows电脑上直接运行Android应用&am…...

【亲测免费】 开启高效OCR之旅:Delphi集成Tesseract 4.0完全指南
开启高效OCR之旅:Delphi集成Tesseract 4.0完全指南 【下载地址】Delphi调用Tesseract4.0进行OCR识别已打包全部DLL 本仓库提供了通过Delphi环境调用Google的Tesseract OCR引擎4.0版本的示例代码和所有必要的DLL文件。Tesseract是一款强大的开源文字识别系统…...

三极管的削波失真是什么
削波失真(Clipping Distortion)是指当放大电路(如三极管、运放)的输出信号幅度超过了其供电电压或输出动态范围的极限时,信号的顶部和/或底部被“削平”而发生的失真现象。1. 它是如何发生的?以一个共射放大…...

企业无线网络进阶:FreeRadius服务器配置与TLS证书实战
1. 为什么企业无线网络需要FreeRadius与TLS证书 想象一下你公司的Wi-Fi像是一个没有门禁的公共广场,任何人都能随意进出。这种情况对于企业网络来说简直是灾难——数据泄露、带宽被占、内网渗透风险接踵而至。而FreeRadiusTLS证书的方案,就相当于给这个广…...

Linux依赖冲突回溯生产排障流程
Linux依赖冲突回溯生产排障流程这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在依赖冲突回溯,重点讨论库版本关系、安装失败和升级影响。在真实生产环境中,依赖冲突回溯相关问题往往不会以单一错误形式出现,而是混杂在日志、…...

除了Omnipeek,你的8812BU网卡还能怎么玩?Win10下的另类WiFi抓包与网络分析实践
超越Omnipeek:8812BU网卡在Win10下的高阶WiFi分析实战指南 对于已经掌握Omnipeek基础操作的技术爱好者而言,8812BU这块双频无线网卡的价值远不止于单一工具的应用。它实际上是一把打开无线网络分析大门的万能钥匙,能够适配多种专业软件&#…...

Browser-Use 实战指南:让 AI 自己操控浏览器的 7 个实用场景
Browser-Use 实战指南:让 AI 自己操控浏览器的 7 个实用场景 你打开浏览器,搜索、填表、采集数据、截图、下载文件。这些每天重复的动作,能不能让 AI 替你干? Browser-Use 给了一个相当干脆的答案:把浏览器交给 AI&…...