hadoop02【尚硅谷】
HDFS
大数据学习笔记
一、HDFS产出背景及定义
- HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。 - HDFS定义
HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
优点:
1)高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性。
- 某一个副本丢失以后,它可以自动恢复。
2) 适合处理大数据
- 数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据
- 文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3)可构建在廉价机器上,通过多副本机制,提高可靠性。
缺点:
1) 不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储。
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3)不支持并发写入、文件随机修改。- 一个文件只能有一个写,不允许多个线程同时写;
- 仅支持数据append(追加),不支持文件的随机修改。
- HDFS组成架构
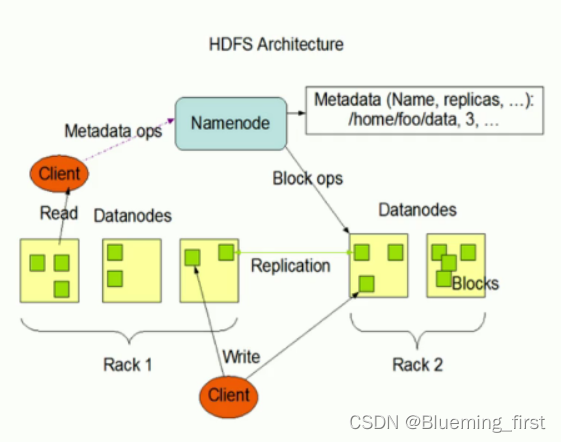
- NameNode(nn):就是Master,它是一个主管、管理者。
- 管理HDFS的名称空间;
- 配置副本策略;
- 管理数据块(block)映射信息;
- 处理客户端读写请求。
- DataNode(dn):就是Slave。NameNode下达命令,DataNode执行实际的操作。
- 存储实际的数据块;
- 执行数据块的读/写操作。
- Client:就是客户端。
- 文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
- 与NameNode交互,获取文件的位置信息;
- 与DataNode交互,读取或者写入数据;
- Client提供一些命令来管理HDFS,比如NameNode格式化;
- Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作。
- Secondary NameNode(2nn):并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
- 辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits(镜像和编辑日志),并推送给NameNode;
- 在紧急情况下,可辅助恢复NameNode只可恢复部分,并不是所有。
- HDFS文件块大小(面试重点)
HDFS中的文件在物理上是分块层出(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2.x版本中是128M,老版本中是64M。

思考:为什么块的大小不能设置太小,也不能设置太大?
1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。总结:HDFS块的大小设置主要取决于磁盘传输速率。
二、 HDFS的数据流(面试重点)
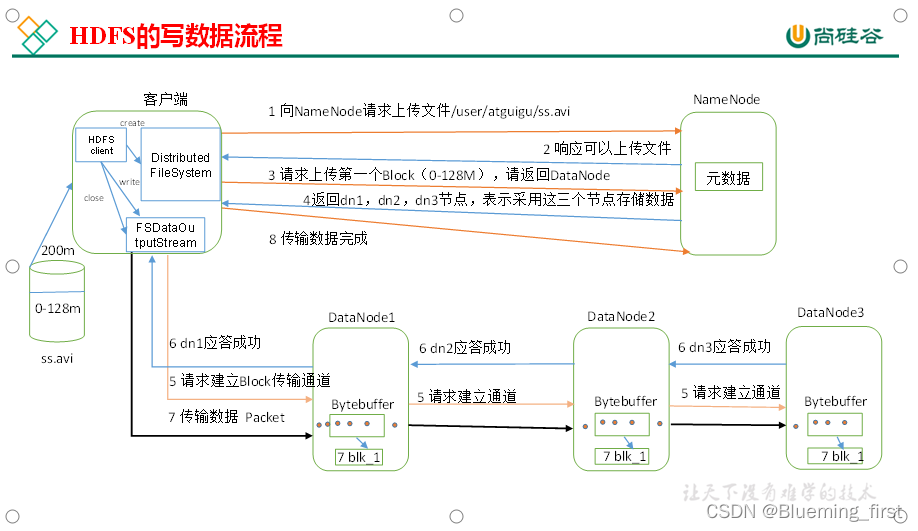
- HDFS写数据流程
- 客户端创建一个分布式文件系统,向NameNode请求上传文件,指定文件位置
- NameNode接收到请求,响应可以上传文件
- 客户端向NameNode请求上传一个Block(128M),请返回DataNode
- NameNode返回DataNode1、DataNode2、DataNode3结点,表示采用这三个节点存储数据。
- 客户端创建FS对象写数据,与DataNodes 建立Block传输通道。
- DataNodes应答成功
- 开始传输数据到DataNode
- 传输数据完成,关闭通道
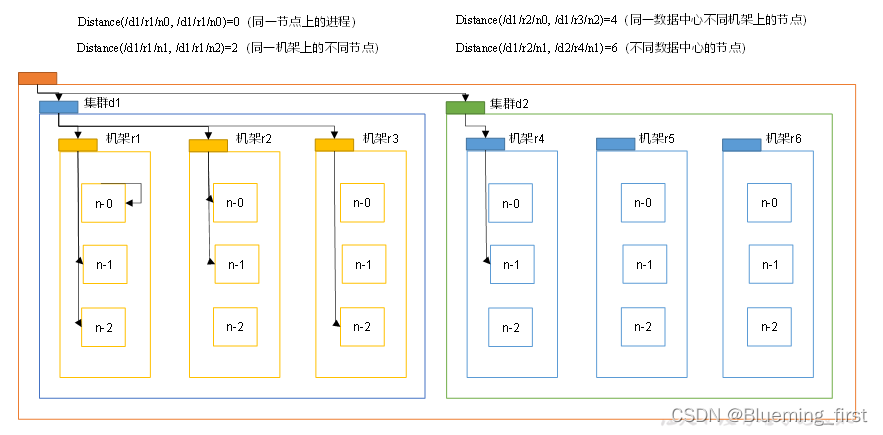
2. NameNode 如何选择DataNode
在HDFS写数据的过程中,namenode会选择距离待上传数据最近距离的DataNode接收数据。
节点距离计算
3. HDFS读数据流程
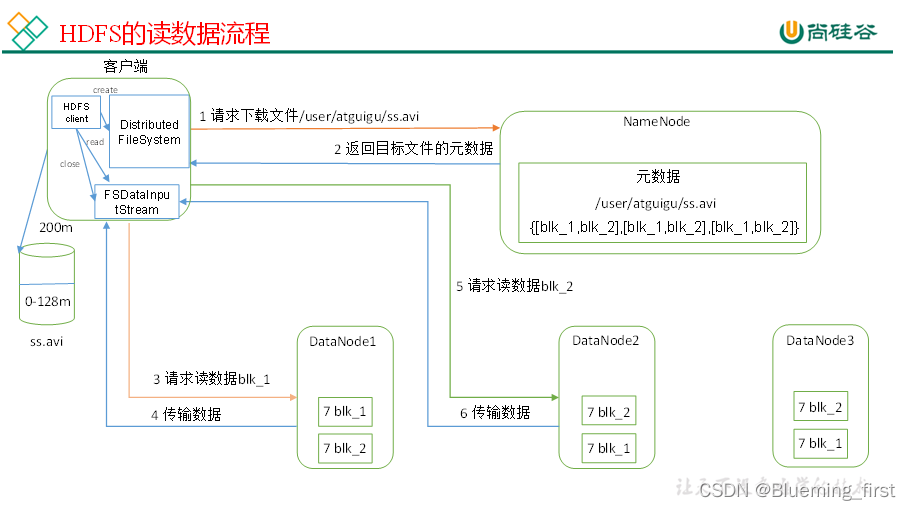
1. 客户端创建FileSystem,向NameNode请求下载文件
2. namenode返回目标文件的元数据信息(文件位置)
3. 客户端创建输入流Stream,向DataNode请求读数据block1
4. DataNode像客户端传输数据
5. 请求读取数据block2
6. DataNode将block2的数据返回给客户端
三、NameNode 和 SecondaryNameNode(面试开发重点)
- NN和2NN工作机制
NameNode中的元数据存储在哪里?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
- NameNode 和 SecondaryNameNode工作机制
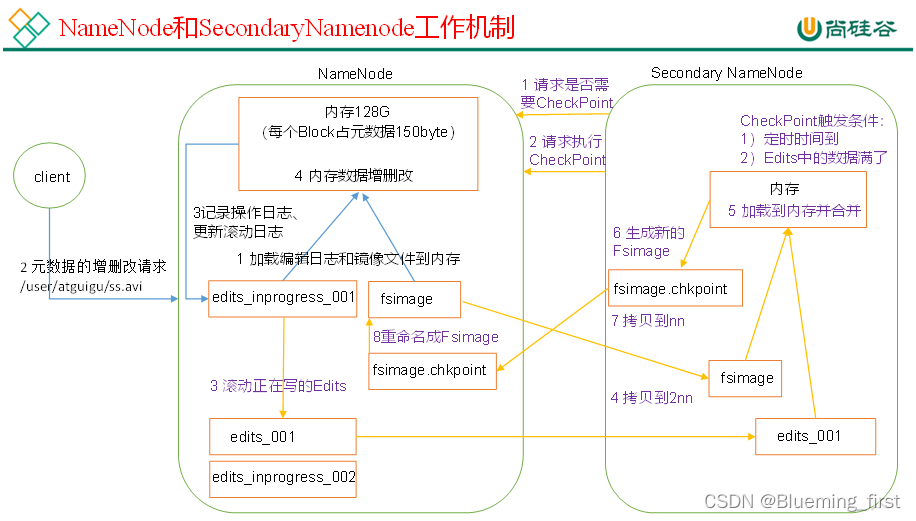
- 第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对数据进行增删改。- 第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
NN和2NN工作机制详解:
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了,默认1小时,100w条)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。
- Fsimage和Edits概念
- Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和问句inode的序列化信息。
- Edits文件:存放hdfs文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
- seen_txid文件保存的是一个数字,就是最后一个edits_的数字
- 每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息时最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。
四、NameNode故障机制
方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
方法二:使用importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
五、集群安全模型
- NameNode启动
NameNode启动时,首先会加载Fsimage文件到内存,然后执行Edits编辑日志中存储的操作。在内存创建成功后,就要创建一个新的FsImage和Edits文件。这时。NameNode开始监听DataNode请求。在这个过程期间,NameNode一直运行在安全模型,即NameNode的文件系统对于客户端来说是只读的。 - DataNode启动
系统中的数据块以块列表的形式存储在DataNode中。在完全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。 - 安全模式退出判断
如果满足**“最小副本条件”,NameNode会在30秒钟之后就退出安全模型**。最小副本条件是指在整个文件系统中99.9%的块满足最小副本级别。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以namenode就不会进入安全模式。
六、DataNode工作机制
- DataNode工作机制
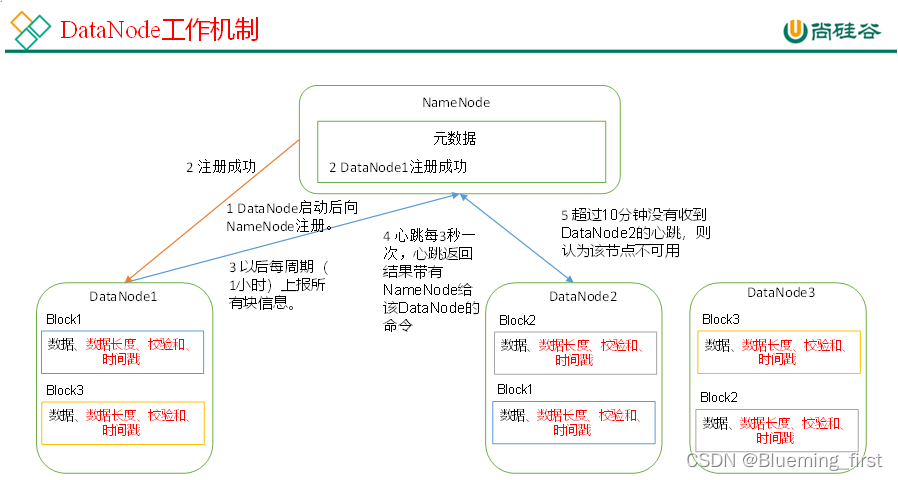
1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器。
- 数据完整性
1)当DataNode读取Block的时候,它会计算CheckSum。
2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
3)Client读取其他DataNode上的Block。
4)DataNode在其文件创建后周期验证CheckSum(校验:奇偶校验、crc校验位)
七、HDFS2.X新特性
- 集群间的数据拷贝 distcp命令
- 快照管理(相当于对目录做一个备份)
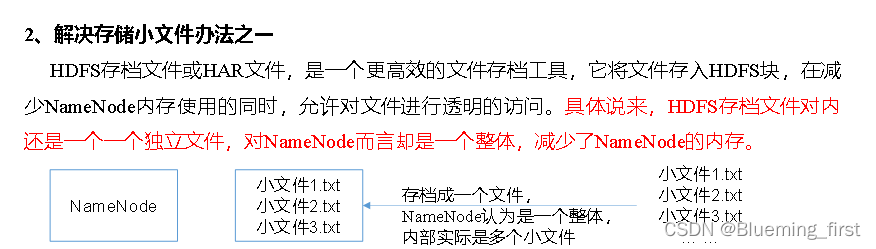
- 小文件存档
HDFS存储小文件的弊端
大量的小文件会耗尽NameNode中的大部分内存。但注意,存储小文件所需的磁盘容量和数据块的大小无关。
- 回收站
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。在HDFS内部的具体实现就是在NameNode中开启了一个后台线程Emptier,这个线程专门管理和监控系统回收站下面的所有文件/目录,对于已经超过生命周期的文件/目录,这个线程就会自动的删除它们
相关文章:
hadoop02【尚硅谷】
HDFS 大数据学习笔记 一、HDFS产出背景及定义 HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件&#x…...

Alist ——本地网盘管理器
Alist ——本地网盘管理器 一、下载工具 Alist https://github.com/alist-org/alist二、启动登录 进入下载好的文件中,在地址栏输入cmd进入命令行启动 进入命令行输入 alist start启动 记住密码,和端口进入浏览器 输入 :127.0.0.1:5244用…...

【白话科普】聊聊网络架构变革的关键——SDN
最近二狗子在网上冲浪的时候,不小心将 CDN 搜索成了 SDN,结果跳出来了一大堆相关的知识点。 好学的二狗子当然不会随随便便糊弄过去,于是认认真真学习了好久,终于了解了 SDN 是什么。 原来,SDN 的全称是 Software De…...

go gin学习记录4
环境 环境:mac m1,go version 1.17.2, goland, mysql 除了原生sql,和orm操作之外,go还有一类包,只用于生成sql,典型的如sqlbuilder,今天就来研究一下它。 安装sqlbuil…...
家政服务小程序实战开发教程015-填充用户信息
我们上一篇讲解了立即预约功能,存在的问题是,每次都需要用户填写联系信息。在我们前述篇章中已经介绍了用户注册的功能,在立即预约的时候我们需要把已经填写的用户信息提取出来,显示到表单对应的字段中。本篇我们就讲解一下如何提…...

python+selenium使用webdriver启动chrome出现闪退现象解决
这两天发现之前开发的爬虫程序出问题了:谷歌浏览器出现打开立即闪退的现象,代码未修改过,检查也没有任何问题! 查看chrome浏览器发现版本更新了 ↑(点击chrome浏览器右上角三个点,最下面帮助→Google Chr…...
新建idea项目
目录IDEA系列之创建各种项目 https://blog.csdn.net/LOVEQD123/article/details/105886077 idea 创建项目的三种方式 https://blog.csdn.net/weixin_50034122/article/details/118754521 创建空项目 https://blog.csdn.net/qq_44537956/article/details/123075134 创建 spri…...

Django框架之类视图
类视图 思考:一个视图,是否可以处理两种逻辑?比如get和post请求逻辑。 如何在一个视图中处理get和post请求 注册视图处理get和post请求 以函数的方式定义的视图称为函数视图,函数视图便于理解。但是遇到一个视图对应的路径提供…...
win11/10+Azure kinect DK配置 VS2019/2017/2015的方法(简单,亲测可以)
首先下载文件:文件的下载和安装方法参考我的博客(131条消息) WIN11/win10Azure Kinect DK详细驱动配置教程(亲测)_Vertira的博客-CSDN博客安装好VS2019,创建好控制台c工程。这些都很简单,不细说。配置:首先配置环境变量…...

子查询的相关例题
子查询的相关例题: 查询和Zlotkey相同部门的员工姓名和工资 SELECT e1.last_name,e1.first_name,e1.salary FROM employees e1 WHERE e1.department_id (SELECT e2.department_idFROM employees e2WHERE e2.last_nameZlotkey );查询工资比公司平均工资高的员工号…...

vue2.0与vue3.0及vue与react区别
vue2.0与3.0及vue与react区别vue2.0 与 vue3.0 区别1. 双向绑定原理2.Vue3支持碎片(Fragments)3.Composition API4.生命周期5.v-if和v-for的优先级6.typescript支持vue与 react区别共同点1.虚拟domdiff算法2.提供了响应式和组件化的视图组件。3.注意力集中保持在核心库…...
【SQL】MySQL秘籍
chihiro-notes 千寻简笔记 v0.1 内测版 📔 笔记介绍 大家好,千寻简笔记是一套全部开源的企业开发问题记录,毫无保留给个人及企业免费使用,我是作者星辰,笔记内容整理并发布,内容有误请指出,笔…...
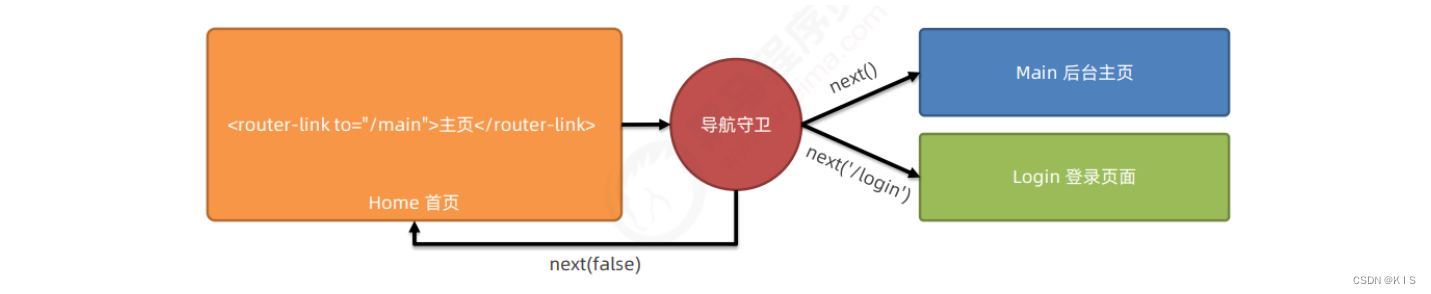
vue-router 的基本用法
vue-router 的基本用法 1.什么是 vue-router vue-router 是 vue.js 官方给出的路由解决方案。它只能结合 vue 项目进行使用,能够轻松的管理 SPA 项目中组件的切换。 vue-router 的官方文档地址:https://router.vuejs.org/zh/ 2.vue-router 安装和配置的…...

图像显著性目标检测
一、概述 1、定义 图像显著性检测(Saliency Detection,SD), 指通过智能算法模拟人的视觉系统特点,预测人类的视觉凝视点和眼动,提取图像中的显著区域(即人类感兴趣的区域),可以广泛用于目标识别、图像编辑以及图像检索等领域&am…...

力扣-查找重复的电子邮箱
大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。 文章目录前言一、题目:182. 查找重复的电子邮箱二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交SQL运行结果总结…...

如何选择正规可靠的ISO认证机构?
ISO认证其实早已融入我们生活中,因为日常生活很多产品都有认证标识,企业办理ISO体系就需要找第三方认证公司,市面上这种公司也有不少,但找到合适可靠、认真负责的还是不易,尤其是体系认证有年审,如何留住客…...

React源码解读之更新的创建
React 的鲜活生命起源于 ReactDOM.render ,这个过程会为它的一生储备好很多必需品,我们顺着这个线索,一探婴儿般 React 应用诞生之初的悦然。 更新创建的操作我们总结为以下两种场景 ReactDOM.rendersetStateforceUpdate ReactDom.render …...
【程序人生】从土木专员到网易测试工程师,薪资翻3倍,他经历了什么?
转行对于很多人来说,是一件艰难而又纠结的事情,或许缺乏勇气,或许缺乏魄力,或许内心深处不愿打破平衡。可对于我来说,转行是一件不可不为的事情,因为那意味着新的方向、新的希望。我是学工程管理的…...

C++——C++11第二篇
目录 可变参数模板 lambda表达式 lambda表达式语法 捕获列表说明 可变参数模板 可变参数:可以有0到n个参数,如之前学过的 Printf C11的新特性可变参数模板能够让您创建可以接受可变参数的函数模板和类模板 模板参数包 // Args是一个模板参数包&…...

14.最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 ""。示例 1:输入:strs ["flower","flow","flight"]输出:"fl"示例 2:输入&…...

GraphViz+CANdelaStudio实战:如何可视化你的State Diagram状态转换图
GraphVizCANdelaStudio实战:如何可视化你的State Diagram状态转换图 在汽车电子开发领域,状态机的设计和验证是核心工作之一。当你在CANdelaStudio中精心设计了复杂的状态转换逻辑后,如何让这些抽象的状态关系变得直观可理解?这就…...

BK1086/88 DSP收音机Arduino库详解
1. 项目概述PU2CLR BK108X 是一款专为 BEKEN BK1086 和 BK1088 高集成度数字信号处理(DSP)广播接收芯片设计的 Arduino 库。该库并非通用型通信封装,而是面向射频接收系统工程实践的底层控制框架,其核心价值在于将芯片复杂的寄存器…...

uniapp实战:uview Collapse组件动态数据加载后高度异常的3种解决方案
Uniapp实战:uView Collapse组件动态数据加载后高度异常的深度解决方案 在Uniapp开发中,uView UI库的Collapse折叠面板组件因其简洁易用而广受欢迎。但当我们需要动态加载数据并展开面板时,经常会遇到一个棘手的问题:面板高度计算不…...
:异常处理与自定义异常,程序报错时到底该怎么处理?)
Java 从入门到精通(十一):异常处理与自定义异常,程序报错时到底该怎么处理?
Java 从入门到精通(十一):异常处理与自定义异常,程序报错时到底该怎么处理? 很多人刚学 Java 时,对“异常”这件事的第一反应通常很直接: 代码报错了控制台一大片红字程序停了然后开始慌 于是很…...

独立创业自动化系统构建指南:从副业到被动收入的实践路径
独立创业自动化系统构建指南:从副业到被动收入的实践路径 【免费下载链接】opc-methodology 《一人企业方法论》第二版,也适合做其他副业(比如自媒体、电商、数字商品)的非技术人群。 项目地址: https://gitcode.com/GitHub_Tre…...

告别网络延迟!AutoGLM-Phone-9B本地化部署实战,手机也能流畅对话AI
告别网络延迟!AutoGLM-Phone-9B本地化部署实战,手机也能流畅对话AI 1. AutoGLM-Phone-9B简介与核心优势 1.1 专为移动端设计的轻量级大模型 AutoGLM-Phone-9B是一款革命性的多模态大语言模型,专为移动设备和边缘计算场景优化。与传统的云端…...

Globe.gl性能优化秘籍:如何高效处理大规模卫星数据可视化
Globe.gl性能优化秘籍:如何高效处理大规模卫星数据可视化 【免费下载链接】globe.gl UI component for Globe Data Visualization using ThreeJS/WebGL 项目地址: https://gitcode.com/gh_mirrors/gl/globe.gl Globe.gl是一个基于ThreeJS/WebGL的3D地球数据可…...

PlugY:重新定义暗黑破坏神2单机体验的技术突破
PlugY:重新定义暗黑破坏神2单机体验的技术突破 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 暗黑破坏神2作为ARPG游戏的里程碑之作,其单机模…...

[具身智能-244]:OpenCV目标跟踪应用程序调用OpenCV库函数实现该功能的主要流程
OpenCV 目标跟踪应用程序的实现流程,本质上是“初始化(定义目标) -> 循环更新(预测位置) -> 可视化(反馈结果)”的过程。这一流程完美体现了之前提到的“逻辑推演模式”:程序员…...

突破流放之路BD构建瓶颈:PoeCharm汉化版全功能技术指南
突破流放之路BD构建瓶颈:PoeCharm汉化版全功能技术指南 【免费下载链接】PoeCharm Path of Building Chinese version 项目地址: https://gitcode.com/gh_mirrors/po/PoeCharm 在流放之路复杂的角色构建系统中,如何让每一份资源投入都转化为实实在…...