Pytorch-day04-模型构建-checkpoint
PyTorch 模型构建
- 1、GPU配置
- 2、数据预处理
- 3、划分训练集、验证集、测试集
- 4、选择模型
- 5、设定损失函数&优化方法
- 6、模型效果评估
#导入常用包
import os
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import transforms
#超参数定义
# 批次的大小
batch_size = 16 #可选32、64、128
# 优化器的学习率
lr = 1e-4
#运行epoch
max_epochs = 10
# 方案一:指定GPU的方式
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1' # 指明调用的GPU为0,1号# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu") # 指明调用的GPU为1号
# 数据读取
#cifar10数据集为例给出构建Dataset类的方式
from torchvision import datasets#“data_transform”可以对图像进行一定的变换,如翻转、裁剪、归一化等操作,可自己定义
data_transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])train_cifar_dataset = datasets.CIFAR10('cifar10',train=True, download=False,transform=data_transform)
test_cifar_dataset = datasets.CIFAR10('cifar10',train=False, download=False,transform=data_transform)#构建好Dataset后,就可以使用DataLoader来按批次读入数据了train_loader = torch.utils.data.DataLoader(train_cifar_dataset, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True)test_loader = torch.utils.data.DataLoader(test_cifar_dataset, batch_size=batch_size, num_workers=4, shuffle=False)
train_cifar_dataset.__getitem__(1)[0].size()
torch.Size([3, 32, 32])
#定义模型
# 方法一:预训练模型
import torchvision
Resnet50 = torchvision.models.resnet50(pretrained=True)
Resnet50.fc.out_features=10 # 修改分类得数量。
print(Resnet50)D:\Users\xulele\Anaconda3\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.warnings.warn(
D:\Users\xulele\Anaconda3\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet50_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet50_Weights.DEFAULT` to get the most up-to-date weights.warnings.warn(msg)ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): Bottleneck((conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer2): Sequential((0): Bottleneck((conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(3): Bottleneck((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer3): Sequential((0): Bottleneck((conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(3): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(4): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(5): Bottleneck((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer4): Sequential((0): Bottleneck((conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck((conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))(fc): Linear(in_features=2048, out_features=10, bias=True)
)
#训练&验证# 定义损失函数和优化器
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 损失函数:交叉熵
criterion = torch.nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(Resnet50.parameters(), lr=lr)
epoch = max_epochs
Resnet50 = Resnet50.to(device)
total_step = len(train_loader)
train_all_loss = []
val_all_loss = []for i in range(epoch):Resnet50.train()train_total_loss = 0train_total_num = 0train_total_correct = 0for iter, (images,labels) in enumerate(train_loader):images = images.to(device)labels = labels.to(device)outputs = Resnet50(images)loss = criterion(outputs,labels)train_total_correct += (outputs.argmax(1) == labels).sum().item()#backwordoptimizer.zero_grad()loss.backward()optimizer.step()train_total_num += labels.shape[0]train_total_loss += loss.item()print("Epoch [{}/{}], Iter [{}/{}], train_loss:{:4f}".format(i+1,epoch,iter+1,total_step,loss.item()/labels.shape[0]))Resnet50.eval()test_total_loss = 0test_total_correct = 0test_total_num = 0for iter,(images,labels) in enumerate(test_loader):images = images.to(device)labels = labels.to(device)outputs = Resnet50(images)loss = criterion(outputs,labels)test_total_correct += (outputs.argmax(1) == labels).sum().item()test_total_loss += loss.item()test_total_num += labels.shape[0]print("Epoch [{}/{}], train_loss:{:.4f}, train_acc:{:.4f}%, test_loss:{:.4f}, test_acc:{:.4f}%".format(i+1, epoch, train_total_loss / train_total_num, train_total_correct / train_total_num * 100, test_total_loss / test_total_num, test_total_correct / test_total_num * 100))train_all_loss.append(np.round(train_total_loss / train_total_num,4))test_all_loss.append(np.round(test_total_loss / test_total_num,4))# 方法二:自定义model
class DemoModel(nn.Module):def __init__(self):super(DemoModel, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x
#训练&验证# 定义损失函数和优化器
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 交叉熵
criterion = torch.nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(Resnet50.parameters(), lr=lr)
epoch = max_epochs
My_model = DemoModel()
My_model = My_model.to(device)
total_step = len(train_loader)
train_all_loss = []
val_all_loss = []
for i in range(epoch):My_model.train()train_total_loss = 0train_total_num = 0train_total_correct = 0for iter, (images,labels) in enumerate(train_loader):images = images.to(device)labels = labels.to(device)outputs = My_model(images)loss = criterion(outputs,labels)train_total_correct += (outputs.argmax(1) == labels).sum().item()#backwordoptimizer.zero_grad()loss.backward()optimizer.step()train_total_num += labels.shape[0]train_total_loss += loss.item()print("Epoch [{}/{}], Iter [{}/{}], train_loss:{:4f}".format(i+1,epoch,iter+1,total_step,loss.item()/labels.shape[0]))My_model.eval()test_total_loss = 0test_total_correct = 0test_total_num = 0for iter,(images,labels) in enumerate(test_loader):images = images.to(device)labels = labels.to(device)outputs = My_model(images)loss = criterion(outputs,labels)test_total_correct += (outputs.argmax(1) == labels).sum().item()test_total_loss += loss.item()test_total_num += labels.shape[0]print("Epoch [{}/{}], train_loss:{:.4f}, train_acc:{:.4f}%, test_loss:{:.4f}, test_acc:{:.4f}%".format(i+1, epoch, train_total_loss / train_total_num, train_total_correct / train_total_num * 100, test_total_loss / test_total_num, test_total_correct / test_total_num * 100))train_all_loss.append(np.round(train_total_loss / train_total_num,4))test_all_loss.append(np.round(test_total_loss / test_total_num,4))相关文章:

Pytorch-day04-模型构建-checkpoint
PyTorch 模型构建 1、GPU配置2、数据预处理3、划分训练集、验证集、测试集4、选择模型5、设定损失函数&优化方法6、模型效果评估 #导入常用包 import os import numpy as np import torch from torch.utils.data import Dataset, DataLoader from torchvision.transfor…...
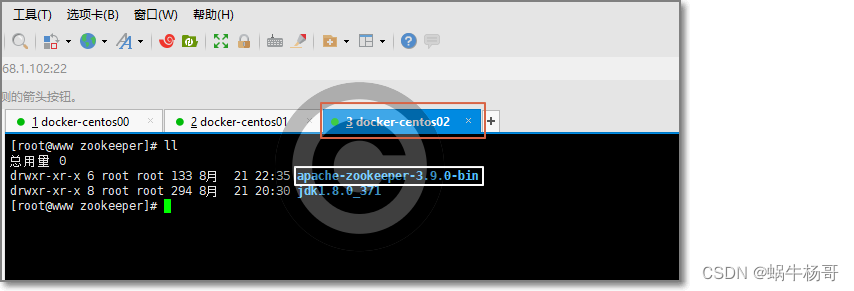
使用Xshell7控制多台服务同时安装ZK最新版集群服务
一: 环境准备: 主机名称 主机IP 节点 (集群内通讯端口|选举leader|cline端提供服务)端口 docker0 192.168.1.100 node-0 2888 | 3888 | 2181 docker1 192.168.1.101 node-1 2888 | 388…...

python numpy array dtype和astype类型转换的区别
Python3 本身对整数的支持做了提升,可以支持无限长度的整数:比如: b 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffPython的模块numpy array定义的数组在windows和MACOS上默认长度是…...

浮动属性样式
🍓浮动属性 属性名称中文注释备注float设置盒子浮动left左浮动,right右浮动,none不浮动clear清除浮动left清除左浮动,right清除右浮动,both左右浮动都清除(注意:clear清除浮动一般只有作用在块…...

keepalived双机热备 (四十五)
一、概述 Keepalived 是一个基于 VRRP 协议来实现的 LVS 服务高可用方案,可以解决静态路由出现的单点故障问题。 原理 在一个 LVS 服务集群中通常有主服务器(MASTER)和备份服务器(BACKUP)两种角色的服务器…...
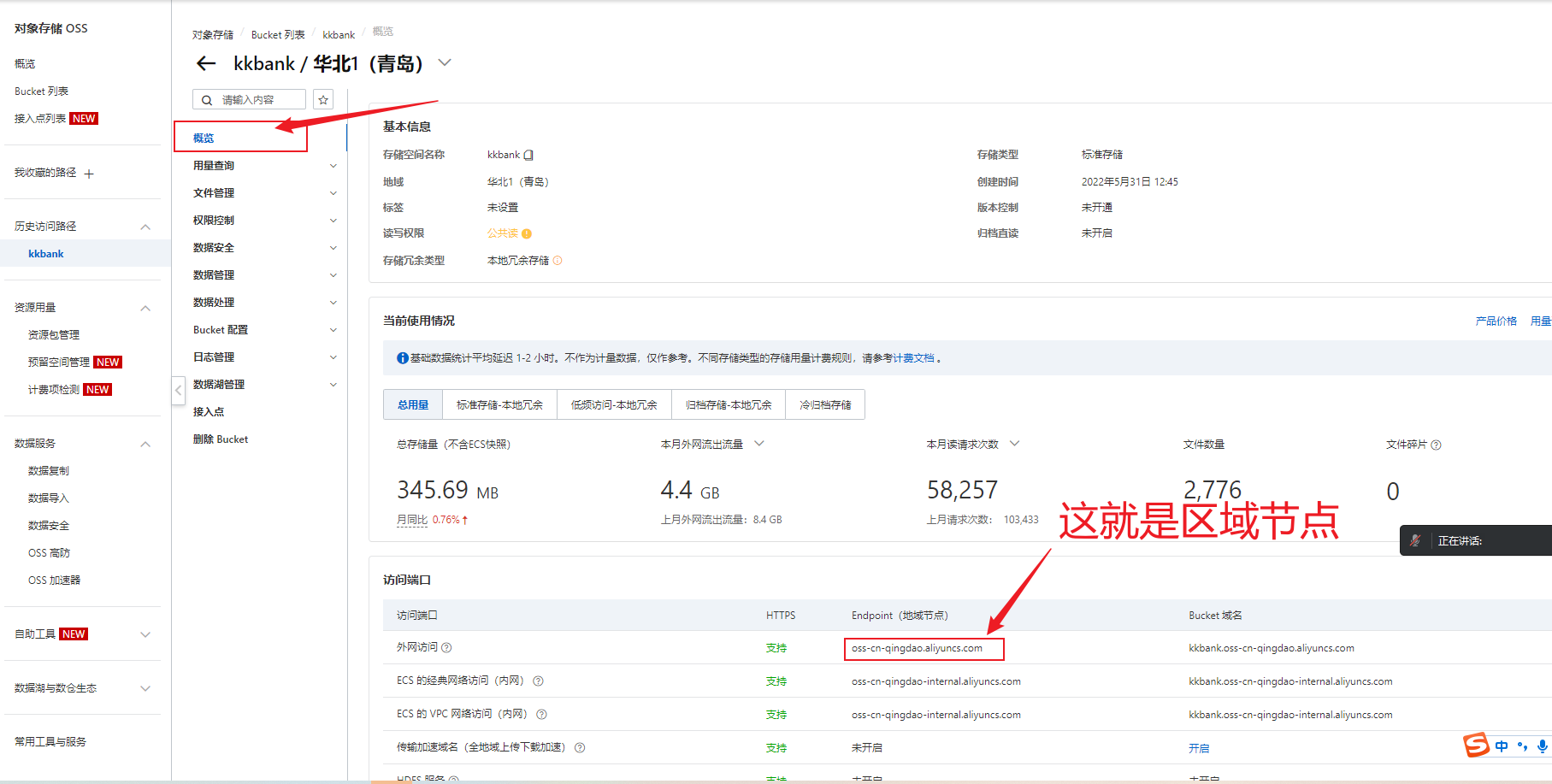
SpringBoot整合阿里云OSS,实现图片上传
在项目中,将图片等文件资源上传到阿里云的OSS,减少服务器压力。 项目中导入阿里云的SDK <dependency><groupId>com.aliyun.oss</groupId><artifactId>aliyun-sdk-oss</artifactId><version>3.10.2</version>…...

Dynaminc Programming相关
目录 3.1 最长回文子串(中等):标志位 3.2 最大子数组和(中等):动态规划 3.3 爬楼梯(简单):动态规划 3.4 买卖股票的最佳时机(简单)࿱…...
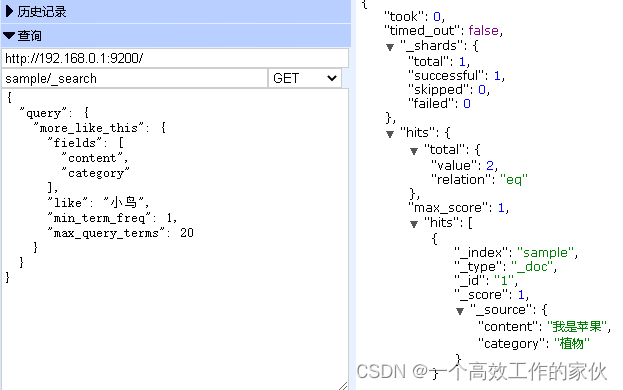
使用 Elasticsearch 轻松进行中文文本分类
本文记录下使用 Elasticsearch 进行文本分类,当我第一次偶然发现 Elasticsearch 时,就被它的易用性、速度和配置选项所吸引。每次使用 Elasticsearch,我都能找到一种更为简单的方法来解决我一贯通过传统的自然语言处理 (NLP) 工具和技术来解决…...

MNN学习笔记(八):使用MNN推理Mediapipe模型
1.项目说明 最近需要用到一些mediapipe中的模型功能,于是尝试对mediapipe中的一些模型进行转换,并使用MNN进行推理;主要模型包括:图像分类、人脸检测及人脸关键点mesh、手掌检测及手势关键点、人体检测及人体关键点、图像嵌入特征…...

主力吸筹指标及其分析和使用说明
文章目录 主力吸筹指标指标代码分析使用说明使用配图主力吸筹指标 VAR1:=REF(LOW,1); VAR2:=SMA(MAX(LOW-VAR1,0),3,1)/SMA(ABS(LOW-VAR1),3,1)*100; VAR3:=EMA(VAR2,3); VAR4:=LLV(LOW,34); VAR5:=HHV(VAR3,34); VAR7:=EMA(IF(LOW<=VAR4,(VAR3+VAR5*2)/2,0),3); /*底线:0,…...
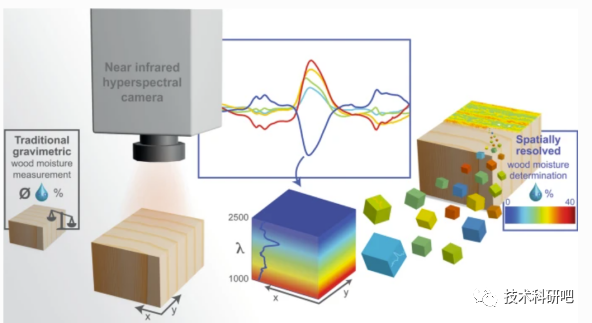
Python高光谱遥感数据处理与高光谱遥感机器学习方法教程
详情点击链接:Python高光谱遥感数据处理与高光谱遥感机器学习方法教程 第一:高光谱基础 一:高光谱遥感基本 01)高光谱遥感 02)光的波长 03)光谱分辨率 04)高光谱遥感的历史和发展 二:高光谱传感器与数据获取 01)高光谱遥感…...
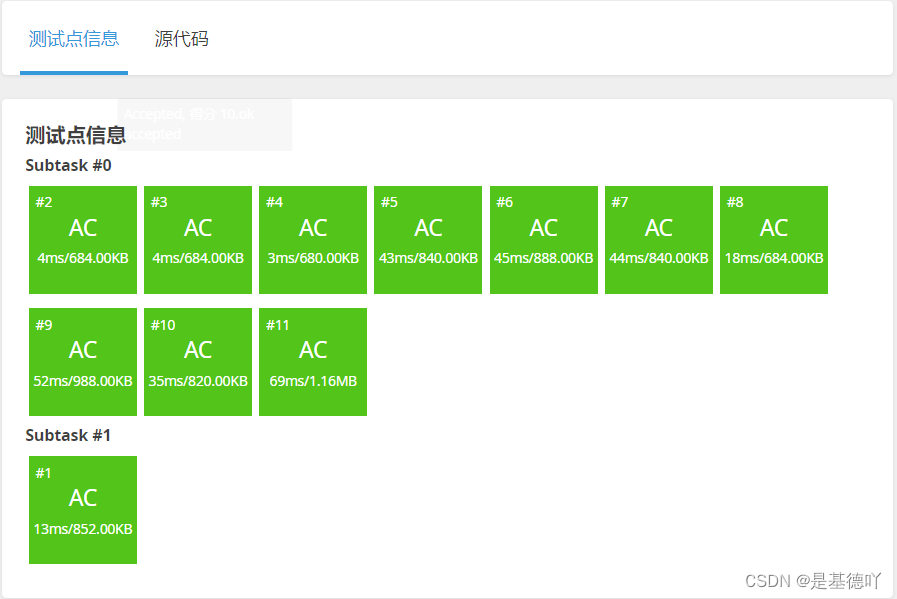
【洛谷】P1678 烦恼的高考志愿
原题链接:https://www.luogu.com.cn/problem/P1678 目录 1. 题目描述 2. 思路分析 3. 代码实现 1. 题目描述 2. 思路分析 将每个学校的分数线用sort()升序排序,再二分查找每个学校的分数线,通过二分找到每个同学估分附近的分数线。 最后…...

开机自启CPU设置定频
sudo apt-get install expect sudo apt-get install cpufrequtils具体步骤如下: 安装 cpufrequtils 工具 ⚫ sudo apt-get install cpufrequtils ⚫ 需要联网下载修改配置文件 ⚫ sudo vi /etc/init.d/cpufrequtils ⚫ 将 GOVERNOR“ondemand” 改为: &g…...
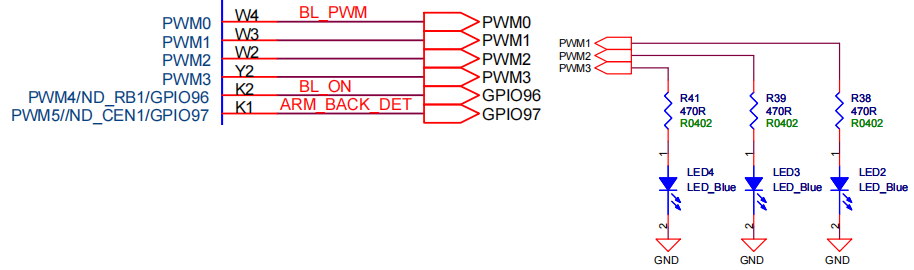
嵌入式Linux开发实操(十二):PWM接口开发
# 前言 使用pwm实现LED点灯,可以说是嵌入式系统的一个基本案例。那么嵌入式linux系统下又如何实现pwm点led灯呢? # PWM在嵌入式linux下的操作指令 实际使用效果如下,可以通过shell指令将开发板对应的LED灯点亮。 点亮3个LED,则分别使用pwm1、pwm2和pwm3。 # PWM引脚的硬…...

消息中间件介绍
消息队列已经逐渐成为企业IT系统内部通信的核心手段。它具有低耦合、可靠投递、广播、流量控制、最终一致性等一系列功能,成为异步RPC的主要手段之一。当今市面上有很多主流的消息中间件,如ActiveMQ、RabbitMQ,Kafka,还有阿里巴巴…...

[Unity] 基础的编程思想, 组件式开发
熟悉 C# 开发的朋友, 在刚进入 Unity 开发时, 不可避免的会有一些迷惑, 例如不清楚 Unity 自己的思想, 如何设计与架构一个应用程序之类的. 本篇文章简要的介绍一下 Unity 的基础编程思想. 独立 Unity 很少使用 C# 的标准库, 例如 C# 的网络, 事件驱动, 对象模型, 这些概念在 …...
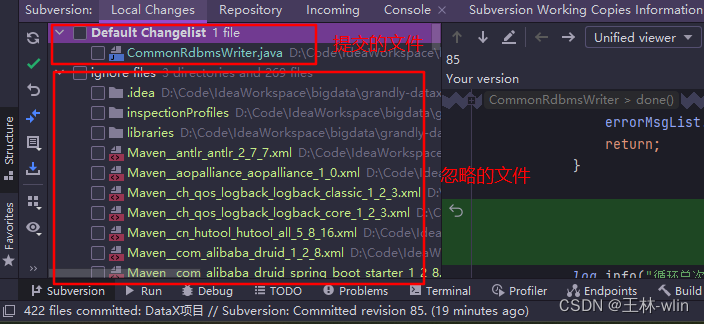
SVN 项目管理笔记
SVN 项目管理笔记 主要是介绍 SVN 管理项目的常用操作,方便以后查阅!!! 一、本地项目提交到SVN流程 在SVN仓库下创建和项目名同样的文件夹目录;选中本地项目文件,选择SVN->checkout,第一个是远程仓库项…...

Android获取手机已安装应用列表JAVA实现
最终效果: 设计 实现java代码: //获取包列表private List<String> getPkgList() {List<String> packages new ArrayList<String>();try {//使用命令行方式获取包列表Process p Runtime.getRuntime().exec("pm list packages");//取得命令行输出…...

【校招VIP】有一个比赛获奖项目和参与的开源小项目,秋招项目竞争力够不够?三个标准,自己都可以估算
有个24届的学生问我:现在没有实习,能不能参与大厂秋招?手里有两个项目,一个是比赛的获奖项目,一个是CSDN上博主做的开源小项目,这两个项目竞争力够不够? 其实项目这块,无非就是三个…...

量化开发学习入门-概念篇
1.网格交易法 网格交易法(Grid Trading)是一种基于价格波动和区间震荡的交易策略。它适用于市场处于横盘或震荡的情况下。 网格交易法的基本思想是在设定的价格区间内均匀地建立多个买入和卖出水平(网格),并在价格上…...
)
遥感图像处理实战:用eCognition多尺度分割搞定地物分类(附样本点与特征提取全流程)
遥感图像智能解译实战:eCognition多尺度分割与地物分类全流程解析 清晨的阳光透过窗帘缝隙洒在桌面上,我打开最新接收的卫星影像——这是一片混合了城市建筑、绿地和农田的复杂区域。作为遥感分析师,我们每天面对的都是这样充满信息量的图像&…...

代码生成器设计原理与实战:从模板引擎到自动化开发
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫xintaofei/codeg。乍一看这个名字,可能有点摸不着头脑,codeg是啥?是“代码生成器”的缩写吗?还是某种新的开发工具?点进去研究了一番&#x…...

MKS Robin Nano Marlin 2.0固件架构解析与性能调优指南
MKS Robin Nano Marlin 2.0固件架构解析与性能调优指南 【免费下载链接】Mks-Robin-Nano-Marlin2.0-Firmware The firmware of Mks Robin Nano, based on Marlin-2.0.x, adding the color GUI. 项目地址: https://gitcode.com/gh_mirrors/mk/Mks-Robin-Nano-Marlin2.0-Firmwa…...

收藏!小白程序员必看:读懂AI岗位JD,精准投递不陪跑
本文针对AI岗位认知模糊、JD理解困难等问题,为读者提供六步解析法,包括明确岗位性质、了解公司类型、评估薪资水平、硬性条件筛选、分析岗位职责和技能匹配。通过这些步骤,帮助读者精准定位适合自己的AI岗位,避免盲目投递。同时&a…...

构建多模型智能客服时如何借助 Taotoken 实现灵活路由与降级
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建多模型智能客服时如何借助 Taotoken 实现灵活路由与降级 在构建企业级智能客服系统时,服务的稳定性和响应能力至关…...
)
Python开发被内网卡脖子?5分钟用Docker搭个Pypiserver救急(含避坑指南)
Python内网开发救星:Docker化Pypiserver极速搭建指南 当你在客户现场调试代码时,突然发现内网环境无法连接PyPI官方源;当你在保密项目部署时,发现所有外网访问都被严格限制——这种"被卡脖子"的困境,相信不少…...

终极无人机仿真平台XTDrone:从入门到精通的完整指南
终极无人机仿真平台XTDrone:从入门到精通的完整指南 【免费下载链接】XTDrone UAV Simulation Platform based on PX4, ROS and Gazebo 项目地址: https://gitcode.com/gh_mirrors/xt/XTDrone XTDrone是一款基于PX4飞控、ROS机器人操作系统和Gazebo物理引擎的…...

如何在5分钟内掌握Illustrator智能填充神器Fillinger
如何在5分钟内掌握Illustrator智能填充神器Fillinger 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为复杂的图案填充耗费数小时吗?今天我要为你介绍一款能彻底改变…...

Snipe-IT终极指南:如何构建企业级IT资产管理系统
Snipe-IT终极指南:如何构建企业级IT资产管理系统 【免费下载链接】snipe-it A free open source IT asset/license management system 项目地址: https://gitcode.com/GitHub_Trending/sn/snipe-it 在当今数字化时代,企业IT资产管理已成为组织运营…...

CNN在卷什么:五大组件详解,一文讲透卷积神经网络,从LeNet到ResNet,为什么这5个组件是CNN的标配
CNN在卷什么:五大组件详解,一文讲透卷积神经网络 副标题: 从LeNet到ResNet,为什么这5个组件是CNN的标配 痛点:CNN的五大组件是什么? 学CNN的时候,你是不是分不清这些概念? 卷积层 vs 池化层:都是"滑动",有什么区别? BatchNorm 到底在做什么?为什么需要它…...