【Python学习笔记】44.Python3 MongoDB和urllib
前言
本章介绍Python的MongoDB和urllib。
Python MongoDB
MongoDB 是目前最流行的 NoSQL 数据库之一,使用的数据类型 BSON(类似 JSON)。
PyMongo
Python 要连接 MongoDB 需要 MongoDB 驱动,这里我们使用 PyMongo 驱动来连接。
pip 安装
pip 是一个通用的 Python 包管理工具,提供了对 Python 包的查找、下载、安装、卸载的功能。
安装 pymongo:
$ python3 -m pip3 install pymongo
也可以指定安装的版本:
$ python3 -m pip3 install pymongo==3.5.1
更新 pymongo 命令:
$ python3 -m pip3 install --upgrade pymongo
easy_install 安装
旧版的 Python 可以使用 easy_install 来安装,easy_install 也是 Python 包管理工具。
$ python -m easy_install pymongo
更新 pymongo 命令:
$ python -m easy_install -U pymongo
测试 PyMongo
接下来我们可以创建一个测试文件 demo_test_mongodb.py,代码如下:
demo_test_mongodb.py 文件代码:
#!/usr/bin/python3import pymongo
执行以上代码文件,如果没有出现错误,表示安装成功。
创建数据库
创建一个数据库
创建数据库需要使用 MongoClient 对象,并且指定连接的 URL 地址和要创建的数据库名。
如下实例中,我们创建的数据库 csdndb :
实例
#!/usr/bin/python3import pymongomyclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["csdndb"]
注意: 在 MongoDB 中,数据库只有在内容插入后才会创建! 就是说,数据库创建后要创建集合(数据表)并插入一个文档(记录),数据库才会真正创建。
判断数据库是否已存在
我们可以读取 MongoDB 中的所有数据库,并判断指定的数据库是否存在:
实例
#!/usr/bin/python3import pymongomyclient = pymongo.MongoClient('mongodb://localhost:27017/')dblist = myclient.list_database_names()
# dblist = myclient.database_names()
if "csdndb" in dblist:print("数据库已存在!")
注意:database_names 在最新版本的 Python 中已废弃,Python3.7+ 之后的版本改为了 list_database_names()。
创建集合
MongoDB 中的集合类似 SQL 的表。
创建一个集合
MongoDB 使用数据库对象来创建集合,实例如下:
实例
#!/usr/bin/python3import pymongomyclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["csdndb"]mycol = mydb["sites"]
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
判断集合是否已存在
我们可以读取 MongoDB 数据库中的所有集合,并判断指定的集合是否存在:
实例
#!/usr/bin/python3import pymongomyclient = pymongo.MongoClient('mongodb://localhost:27017/')mydb = myclient['csdndb']collist = mydb. list_collection_names()
# collist = mydb.collection_names()
if "sites" in collist: # 判断 sites 集合是否存在print("集合已存在!")
注意:collection_names 在最新版本的 Python 中已废弃,Python3.7+ 之后的版本改为了 list_collection_names()。
Python urllib
Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。
本文主要介绍 Python3 的 urllib。
urllib 包 包含以下几个模块:
urllib.request- 打开和读取 URL。urllib.error- 包含 urllib.request 抛出的异常。urllib.parse- 解析 URL。urllib.robotparser- 解析 robots.txt 文件。
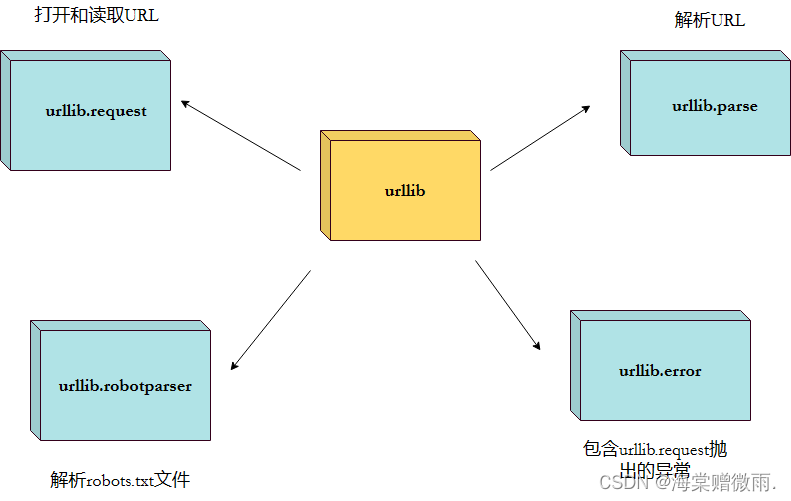
urllib.request
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。
urllib.request 可以模拟浏览器的一个请求发起过程。
我们可以使用 urllib.request 的 urlopen 方法来打开一个 URL,语法格式如下:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
- url:url 地址。
- data:发送到服务器的其他数据对象,默认为 None。
- timeout:设置访问超时时间。
- cafile 和 capath:cafile 为 CA 证书, capath 为 CA 证书的路径,使用 HTTPS 需要用到。
- cadefault:已经被弃用。
- context:ssl.SSLContext类型,用来指定 SSL 设置。
实例
from urllib.request import urlopenmyURL = urlopen("https://www.csdn.com/")
print(myURL.read())
以上代码使用 urlopen 打开一个 URL,然后使用 read() 函数获取网页的 HTML 实体代码。
read() 是读取整个网页内容,我们可以指定读取的长度:
实例
from urllib.request import urlopenmyURL = urlopen("https://www.csdn.com/")
print(myURL.read(300))
除了 read() 函数外,还包含以下两个读取网页内容的函数:
- readline() - 读取文件的一行内容
from urllib.request import urlopenmyURL = urlopen("https://www.csdn.com/")
print(myURL.readline()) #读取一行内容
- readlines() - 读取文件的全部内容,它会把读取的内容赋值给一个列表变量。
from urllib.request import urlopenmyURL = urlopen("https://www.csdn.com/")
lines = myURL.readlines()
for line in lines:print(line)
我们在对网页进行抓取时,经常需要判断网页是否可以正常访问,这里我们就可以使用 getcode() 函数获取网页状态码,返回 200 说明网页正常,返回 404 说明网页不存在:
实例
import urllib.requestmyURL1 = urllib.request.urlopen("https://www.csdn.com/")
print(myURL1.getcode()) # 200try:myURL2 = urllib.request.urlopen("https://www.csdn.com/no.html")
except urllib.error.HTTPError as e:if e.code == 404:print(404) # 404
如果要将抓取的网页保存到本地,可以使用 Python3 File write() 方法 函数:
实例
from urllib.request import urlopenmyURL = urlopen("https://www.csdn.com/")
f = open("csdn_urllib_test.html", "wb")
content = myURL.read() # 读取网页内容
f.write(content)
f.close()
执行以上代码,在本地就会生成一个 csdn_urllib_test.html 文件,里面包含了 https://www.csdn.com/ 网页的内容。
URL 的编码与解码可以使用 urllib.request.quote() 与 urllib.request.unquote() 方法:
实例
import urllib.requestencode_url = urllib.request.quote("https://www.csdn.com/") # 编码
print(encode_url)unencode_url = urllib.request.unquote(encode_url) # 解码
print(unencode_url)
输出结果为:
https%3A//www.csdn.com/
https://www.csdn.com/
模拟头部信息
我们抓取网页一般需要对 headers(网页头信息)进行模拟,这时候需要使用到 urllib.request.Request 类:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
- url:url 地址。
- data:发送到服务器的其他数据对象,默认为 None。
- headers:HTTP 请求的头部信息,字典格式。
- origin_req_host:请求的主机地址,IP 或域名。
- unverifiable:很少用整个参数,用于设置网页是否需要验证,默认是False。。
- method:请求方法, 如 GET、POST、DELETE、PUT等。
实例 - py3_urllib_test.py 文件代码
import urllib.request
import urllib.parseurl = 'https://www.csdn.com/?s=' # csdn教程搜索页面
keyword = 'Python 教程'
key_code = urllib.request.quote(keyword) # 对请求进行编码
url_all = url+key_code
header = {'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
} #头部信息
request = urllib.request.Request(url_all,headers=header)
reponse = urllib.request.urlopen(request).read()fh = open("./urllib_test_csdn_search.html","wb") # 将文件写入到当前目录中
fh.write(reponse)
fh.close()
执行以上 Python 代码,会在当前目录生成 urllib_test_csdn_search.html 文件,打开 urllib_test_csdn_search.html 文件(可以使用浏览器打开)。
表单 POST 传递数据,我们先创建一个表单,代码如下,我这里使用了 PHP 代码来获取表单的数据:
实例 - py3_urllib_test.php 文件代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>csdn教程(csdn.com) urllib POST 测试</title>
</head>
<body>
<form action="" method="post" name="myForm">Name: <input type="text" name="name"><br>Tag: <input type="text" name="tag"><br><input type="submit" value="提交">
</form>
<hr>
<?php
// 使用 PHP 来获取表单提交的数据,你可以换成其他的
if(isset($_POST['name']) && $_POST['tag'] ) {echo $_POST["name"] . ', ' . $_POST['tag'];
}
?>
</body>
</html>
实例
import urllib.request
import urllib.parseurl = 'https://www.csdn.com/try/py3/py3_urllib_test.php' # 提交到表单页面
data = {'name':'csdn', 'tag' : 'csdn教程'} # 提交数据
header = {'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
} #头部信息
data = urllib.parse.urlencode(data).encode('utf8') # 对参数进行编码,解码使用 urllib.parse.urldecode
request=urllib.request.Request(url, data, header) # 请求处理
reponse=urllib.request.urlopen(request).read() # 读取结果fh = open("./urllib_test_post_csdn.html","wb") # 将文件写入到当前目录中
fh.write(reponse)
fh.close()
执行以上代码,会提交表单数据到 py3_urllib_test.php 文件,输出结果写入到 urllib_test_post_csdn.html 文件。
打开 urllib_test_post_csdn.html 文件(可以使用浏览器打开)。
urllib.error
urllib.error 模块为 urllib.request 所引发的异常定义了异常类,基础异常类是 URLError。
urllib.error 包含了两个方法,URLError 和 HTTPError。
URLError 是 OSError 的一个子类,用于处理程序在遇到问题时会引发此异常(或其派生的异常),包含的属性 reason 为引发异常的原因。
HTTPError 是 URLError 的一个子类,用于处理特殊 HTTP 错误例如作为认证请求的时候,包含的属性 code 为 HTTP 的状态码, reason 为引发异常的原因,headers 为导致 HTTPError 的特定 HTTP 请求的 HTTP 响应头。
对不存在的网页抓取并处理异常:
实例
import urllib.request
import urllib.errormyURL1 = urllib.request.urlopen("https://www.csdn.com/")
print(myURL1.getcode()) # 200try:myURL2 = urllib.request.urlopen("https://www.csdn.com/no.html")
except urllib.error.HTTPError as e:if e.code == 404:print(404) # 404
urllib.parse
urllib.parse 用于解析 URL,格式如下:
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)
urlstring 为 字符串的 url 地址,scheme 为协议类型,
allow_fragments 参数为 false,则无法识别片段标识符。相反,它们被解析为路径,参数或查询组件的一部分,并 fragment 在返回值中设置为空字符串。
实例
from urllib.parse import urlparseo = urlparse("https://www.csdn.com/?s=python+%E6%95%99%E7%A8%8B")
print(o)
以上实例输出结果为:
ParseResult(scheme='https', netloc='www.csdn.com', path='/', params='', query='s=python+%E6%95%99%E7%A8%8B', fragment='')
从结果可以看出,内容是一个元组,包含 6 个字符串:协议,位置,路径,参数,查询,判断。
我们可以直接读取协议内容:
实例
from urllib.parse import urlparseo = urlparse("https://www.csdn.com/?s=python+%E6%95%99%E7%A8%8B")
print(o.scheme)
以上实例输出结果为:
https
完整内容如下:
| 属性 | 索引 | 值 | 值(如果不存在) |
|---|---|---|---|
| scheme | 0 | URL协议 | scheme 参数 |
| netloc | 1 | 网络位置部分 | 空字符串 |
| path | 2 | 分层路径 | 空字符串 |
| params | 3 | 最后路径元素的参数 | 空字符串 |
| query | 4 | 查询组件 | 空字符串 |
| fragment | 5 | 片段识别 | 空字符串 |
| username | 用户名 | None | |
| password | 密码 | None | |
| hostname | 主机名(小写) | None | |
| port | 端口号为整数(如果存在) | None |
urllib.robotparser
urllib.robotparser 用于解析 robots.txt 文件。
robots.txt(统一小写)是一种存放于网站根目录下的 robots 协议,它通常用于告诉搜索引擎对网站的抓取规则。
urllib.robotparser 提供了 RobotFileParser 类,语法如下:
class urllib.robotparser.RobotFileParser(url='')
这个类提供了一些可以读取、解析 robots.txt 文件的方法:
- set_url(url) - 设置 robots.txt 文件的 URL。
- read() - 读取 robots.txt URL 并将其输入解析器。
- parse(lines) - 解析行参数。
- can_fetch(useragent, url) - 如果允许 useragent 按照被解析 robots.txt 文件中的规则来获取url 则返回 True。
- mtime() -返回最近一次获取 robots.txt 文件的时间。 这适用于需要定期检查 robots.txt文件更新情况的长时间运行的网页爬虫。
- modified() - 将最近一次获取 robots.txt 文件的时间设置为当前时间。
- crawl_delay(useragent) -为指定的useragent 从 robots.txt 返回 Crawl-delay形参。 如果此形参不存在或不适用于指定的 useragent 或者此形参的 robots.txt 条目存在语法错误,则返回 None。
- request_rate(useragent) -以 named tuple RequestRate(requests, seconds)的形式从 robots.txt 返回 Request-rate 形参的内容。 如果此形参不存在或不适用于指定的 useragent或者此形参的 robots.txt 条目存在语法错误,则返回 None。
- site_maps() - 以 list() 的形式从 robots.txt 返回 Sitemap 形参的内容。如果此形参不存在或者此形参的 robots.txt 条目存在语法错误,则返回 None。
实例
>>> import urllib.robotparser
>>> rp = urllib.robotparser.RobotFileParser()
>>> rp.set_url("http://www.musi-cal.com/robots.txt")
>>> rp.read()
>>> rrate = rp.request_rate("*")
>>> rrate.requests
3
>>> rrate.seconds
20
>>> rp.crawl_delay("*")
6
>>> rp.can_fetch("*", "http://www.musi-cal.com/cgi-bin/search?city=San+Francisco")
False
>>> rp.can_fetch("*", "http://www.musi-cal.com/")
True
相关文章:
【Python学习笔记】44.Python3 MongoDB和urllib
前言 本章介绍Python的MongoDB和urllib。 Python MongoDB MongoDB 是目前最流行的 NoSQL 数据库之一,使用的数据类型 BSON(类似 JSON)。 PyMongo Python 要连接 MongoDB 需要 MongoDB 驱动,这里我们使用 PyMongo 驱动来连接。…...
LVS中的keepalived高可用
文章目录前言一、Keepalived简介二、keepalived工作原理三、配置文件四、实验1.某台Real Server down2.LVS本身down实验过程:五、代码详细演示整体过程调度器安装软件、设置测试keepalived对后端RS的健康检测backup服务主机设置前言 一、Keepalived简介 Keepalived是…...

【Vue3】组件数据懒加载
组件数据懒加载-基本使用 目标:通过useIntersectionObserver优化新鲜好物和人气推荐模块 电商类网站,尤其是首页,内容有好几屏,而如果一上来就加载所有屏的数据,并渲染所有屏的内容会导致首页加载很慢。 数据懒加载&a…...
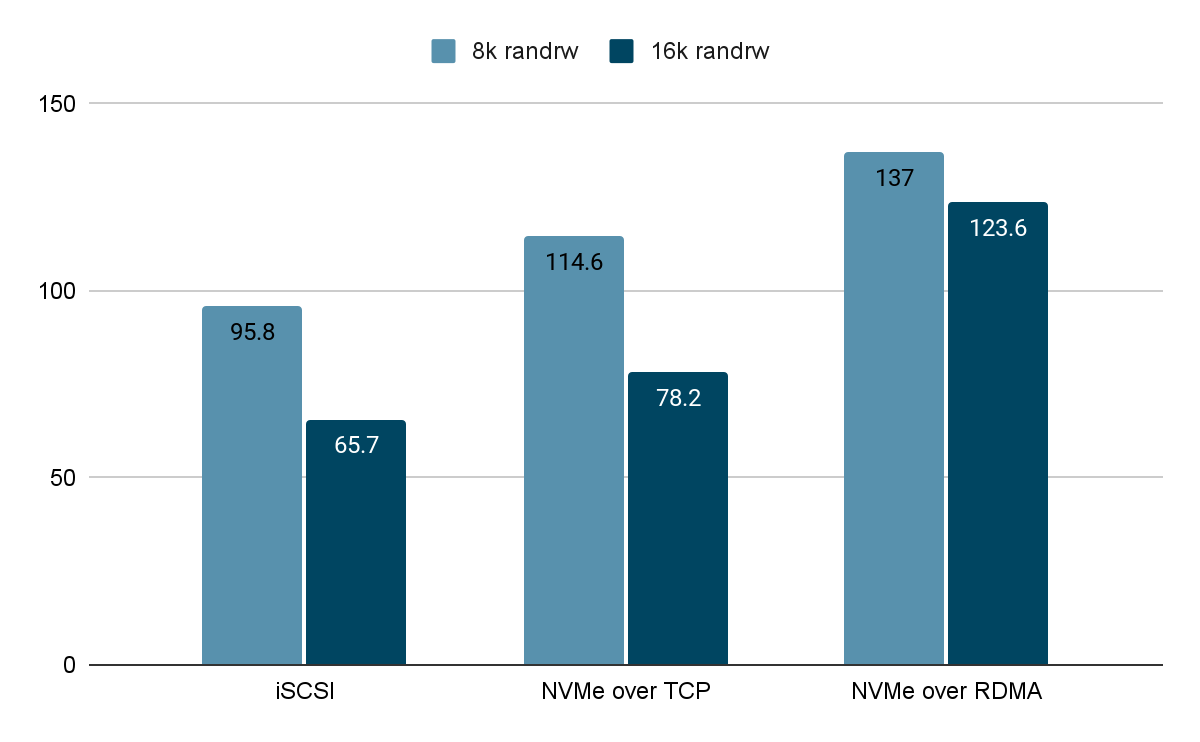
基于 SmartX 分布式存储的 iSCSI 与两种 NVMe-oF 技术与性能对比
作者:深耕行业的 SmartX 金融团队本文重点SmartX 分布式块存储 ZBS 提供 2 种存算分离架构下的数据接入协议,分别是 iSCSI 和 NVMe-oF。其中,iSCSI 虽然具有很多优势,但不适合支持高性能的工作负载,这也是 SmartX 选择…...

Anaconda 安装 Pytorch
下载Anaconda,最新版本的即可,默认安装,最好不要安装在C盘,否则后面C盘容量会很大。 安装Pytorch 打开 Anaconda Prompt ,先切换镜像源为国内清华镜像源,这样安装包的时候下载速度会快一些,也容易成功一些。 在 Anaconda Prompt 命令行依次输入以下四条命令切换到清华镜…...
从零开始使用MMSegmentation训练Segformer
从零开始使用MMSegmentation训练Segformer 写在前面:最新想要用最新的分割算法如:Segformer or SegNeXt 在自己的数据集上进行训练,但是有不是搞语义分割出身的,而且也没有系统的学过MMCV以及MMSegmentation。所以就折腾了很久&am…...

会利用信息差赚钱的人才是聪明人
毕业后找不到工作,穷到只剩下时间,大小做了20多份副业兼职,终于找到了可靠的渠道, 我是专科生,学历不好,专业拉胯。毕业后,我找了两三份工作。要么工资太低,只能交房租,…...

【机器学习】Adaboost
1.什么是Adaboost AdaBoost(adapt boost),自适应推进算法,属于Boosting方法的学习机制。是一种通过改变训练样本权重来学习多个弱分类器并进行线性结合的过程。它的自适应在于:被前一个基本分类器误分类的样本的权值会…...
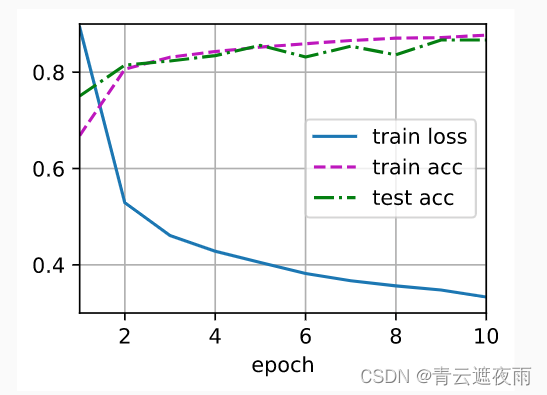
深度学习神经网络基础知识(二)权重衰减、暂退法(Dropout)
专栏:神经网络复现目录 深度学习神经网络基础知识(二) 本文讲述神经网络基础知识,具体细节讲述前向传播,反向传播和计算图,同时讲解神经网络优化方法:权重衰减,Dropout等方法,最后进行Kaggle实…...

[面试直通版]网络协议面试核心之HTTP,HTTPS,DNS-DNS安全
点击->计算机网络复习的文章集<-点击 目录 典型问题: 部分现象 DNS劫持 DNS欺骗 DDoS攻击 典型问题: 什么是DNS劫持,DNS欺骗,是什么原理如何防范DNS攻击? 部分现象 错误域名解析到纠错导航页面错误域名解析…...

【OJ】A+B=X
📚Description: 数列S中有n个整数,判断S中是否存在两个数A、B,使之和等于X。 ⏳Input: 第一行为T,输入包括T组测试数据。 每组数据第一行包括两个数字n和X,第二行有n个整数,表示数列S,(1&l…...

Python实现性能自动化测试,还可以如此简单
Python实现性能自动化测试,还可以如此简单 目录:导读 一、思考❓❔ 二、基础操作🔨🔨 三、综合案例演练🔨🔨 四、总结💡💡 写在最后 一、思考❓❔ 1.什么是性能自动化测试? 性…...

Leetcode力扣秋招刷题路-0080
从0开始的秋招刷题路,记录下所刷每道题的题解,帮助自己回顾总结 80. 删除有序数组中的重复项 II 给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长…...
Java实现JDBC工具类DbUtils的抽取及程序实现数据库的增删改操作
封装DbUtils 工具类 不知道我们发现没有,不管是对数据库进行查询,还是标准的JDBC 步骤,其开端都是先实现JDBC 的加载注册,接着是获取数据库的连接,最后都是实现关闭连接,释放资源的操作。那我们何不直接把…...

【docker】拉取镜像环境报错解决#ERROR: Get https://registry-1.docker.io/v2/
🍁博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 文章目录问题报错原因解决方法问题 ERROR…...
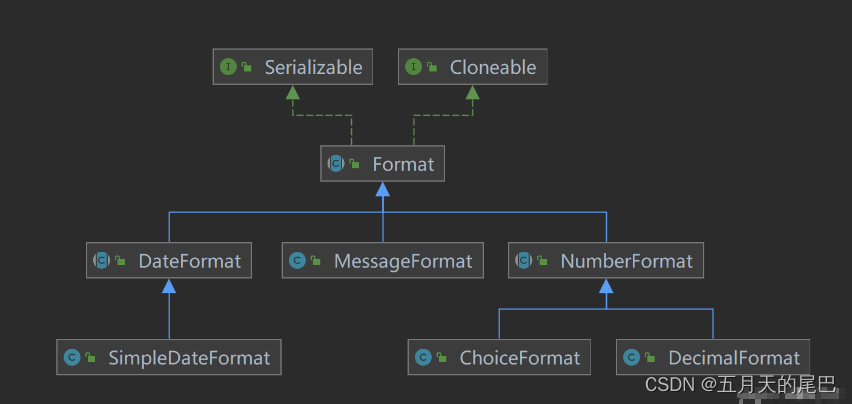
java中NumberFormat 、DecimalFormat的介绍及使用,java数字格式化,BigDecimal数字格式化
文章目录前言一、NumberFormat1、概述2、实例化方法3、货币格式化4、百分比格式化5、NumberFormat的坑5.1、不同的格式化对象处理相同数值返回结果不同问题源码分析:二、DecimalFormat1、概述2、常用方法3、字符及含义0与#的区别分组分隔符的使用“%” 将数字乘以10…...

2023什么是分销商城系统?营销,核心功能
大家好,我是你们熟悉而又陌生的好朋友梦龙,一个创业期的年轻人 分销商城是指由网络营销运营商提供的,用于协助供给商搭建、管理及运作其网络销售渠道,协助分销商获取货源渠道的平台。简单来说,就是企业应用无线裂变分…...

天翼数字生活C++客户端实习
面试C客户端实习的岗位,相对不难 面试官:实习主要做的是国产操作系统下的应用,主要做的是视频监控、安防相关的工具,具体就是一个叫做 天翼云眼的软件,目前在windows下和电视下都有对应的应用,就是现在想在…...

Java 接口
文章目录1、接口的概念2、接口的定义3、接口的使用4、接口和抽象类1、接口的概念 类是一种具体的实现体,而接口定义了一种规范(抽象方法),接口定义了某一批类所需要遵循的规范,接口不关心类内部的属性和方法的具体实现…...

【React】react-router 路由详解
🚩🚩🚩 💎个人主页: 阿选不出来 💨💨💨 💎个人简介: 一名大二在校生,学习方向前端,不定时更新自己学习道路上的一些笔记. 💨💨💨 💎目…...

利用快马AI快速原型:十分钟搭建软件下载站首页与详情页
最近在帮朋友做一个软件下载站的原型,要求能快速上线测试用户反馈。传统开发方式从设计到编码至少需要一周,但这次我用InsCode(快马)平台的AI生成功能,十分钟就搞定了基础框架,分享下具体实现思路。 首页布局设计 首页需要突出展示…...

你的Selenium爬虫被‘环境调试’弹窗卡住了吗?试试先清理浏览器缓存和Cookie
Selenium爬虫环境指纹污染解决方案:从缓存清理到浏览器隔离 环境指纹污染:爬虫开发者面临的新挑战 上周三凌晨3点,我的自动化数据采集系统突然发出警报——所有Selenium爬虫实例同时失效,目标网站清一色返回"环境异常"提…...

如何为Windows系统安装macOS风格的高清光标主题包
如何为Windows系统安装macOS风格的高清光标主题包 【免费下载链接】macOS-cursors-for-Windows Tested in Windows 10 & 11, 4K (125%, 150%, 200%). With 2 versions, 2 types and 3 different sizes! 项目地址: https://gitcode.com/gh_mirrors/ma/macOS-cursors-for-W…...

RevokeMsgPatcher革新性防撤回解决方案:让重要消息不再消失
RevokeMsgPatcher革新性防撤回解决方案:让重要消息不再消失 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitco…...

面试:synchronized用过吗,其原理是什么
一、基础回答 1. 用过吗?用来做什么? 用过。synchronized 是 Java 内置的悲观锁关键字,用来解决多线程并发安全问题,保证同一时刻只有一个线程执行被锁定的代码,避免线程安全问题(如原子性、可见性、有序性…...
)
别再忍受龟速下载!保姆级教程:Ubuntu 18.04一键更换阿里云/清华源(附SSH无桌面操作)
Ubuntu 18.04国内软件源极速配置指南:告别蜗牛速度的终极方案 每次执行apt update时盯着缓慢爬升的进度条,是否让你产生砸键盘的冲动?作为国内Ubuntu用户,默认国际源的龟速下载堪称开发效率的头号杀手。本文将彻底解决这个痛点——…...

SQL检查开发提效:sql-lint让数据库操作更可靠
SQL检查开发提效:sql-lint让数据库操作更可靠 【免费下载链接】sql-lint An SQL linter 项目地址: https://gitcode.com/gh_mirrors/sq/sql-lint 当你在深夜排查线上SQL错误时,当团队因SQL风格不统一争论时,当执行DELETE语句忘记WHERE…...
)
保姆级教程:用AntV L7快速搭建可交互的3D地图(附四川地图JSON数据下载)
从零构建3D地图可视化:AntV L7实战指南与四川地貌呈现 第一次看到3D地图在城市规划、气象监测或商业分析中的应用时,那种立体数据跃然屏上的震撼感,让我立刻想动手尝试。作为蚂蚁集团推出的地理空间数据可视化引擎,AntV L7确实能让…...

QQ空间历史说说一键导出终极指南:GetQzonehistory完整备份解决方案
QQ空间历史说说一键导出终极指南:GetQzonehistory完整备份解决方案 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾想永久保存QQ空间里的青春记忆?那些深…...

Tsuru平台API文档工具终极比较:Swagger与ReDoc的完整指南
Tsuru平台API文档工具终极比较:Swagger与ReDoc的完整指南 【免费下载链接】tsuru Open source and extensible Platform as a Service (PaaS). 项目地址: https://gitcode.com/gh_mirrors/ts/tsuru 在当今云原生应用开发领域,Tsuru平台作为一款开…...